autoreferat rozprawy doktorskiej - Politechnika Warszawska
autoreferat rozprawy doktorskiej - Politechnika Warszawska
autoreferat rozprawy doktorskiej - Politechnika Warszawska

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
POLITECHNIKA WARSZAWSKA<br />
Wydział Elektroniki<br />
i Technik Informacyjnych<br />
AUTOREFERAT ROZPRAWY<br />
DOKTORSKIEJ<br />
mgr in˙z. Rafał Pietruch<br />
Badanie zrozumiało´sci mowy u osób laryngektomowanych na<br />
podstawie obrazów akustycznych oraz ekspresji twarzy<br />
Warszawa 2009<br />
Promotor<br />
Prof. nzw. dr hab. in˙z. Antoni Grzanka
Streszczenie<br />
W pracy zaprezentowano metody i narz˛edzia do analizy wypowiedzi pacjentów po<br />
całkowitym wyci˛eciu krtani. Badania przeprowadzono u osób zdrowych i laryngektomowanych<br />
na podstawie zapisów sygnału mowy oraz nagrań wideo twarzy. Opracowany i prezentowany<br />
system badań parametrów głosu stosowany jest do wyznaczania post˛epów rehabilitacji<br />
foniatrycznej. Przeprowadzone analizy sygnału audio dotyczyły cz˛estotliwo´sci podstawowej,<br />
formantów F1 i F2 oraz czasu artykulacji sze´sciu samogłosek polskich. Napisany został<br />
program wizualizuj ˛acy widmo czasowo-cz˛estotliwo´sciowe mowy oraz ´sledz ˛acy parametry<br />
ekspresji twarzy. Wykonano tak˙ze analiz˛e parametrów ekspresji twarzy w czasie wypowiedzi.<br />
Wyznaczono szeroko´sć i wysoko´sć otwarcia ust oraz rozwarcie ˙zuchwy. Analizie poddano<br />
zapisy pochodz ˛ace od trzech grup osób posługuj ˛acych si˛e pseudoszeptem, mow ˛a zast˛epcz ˛a<br />
oraz głosem naturalnym. W pracy zaobserwowano i opisano wymierne ró˙znice mi˛edzy<br />
tymi trzema rodzajami głosu. Wykazano, ˙ze najwi˛eksza trudno´sć jest obserwowana podczas<br />
wypowiadania samogłosek izolowanych w pseudoszepcie. Natomiast w ekspresji nie<br />
znaleziono patologicznych oznak pooperacyjnych zarówno u pacjentów z wykształcon ˛a<br />
mow ˛a zast˛epcz ˛a jak i posługuj ˛acych si˛e pseudoszeptem. Wyniki ukazuj ˛a wielkie mo˙zliwo´sci<br />
wykorzystania ´scie˙zki wideo przy automatycznym rozpoznawaniu lub poprawie zrozumiało´sci<br />
głosu pooperacyjnego.<br />
Słowa kluczowe: analiza mowy, ekspresja twarzy, laryngektomia, zrozumiało´sć mowy<br />
zast˛epczej<br />
2
Spis tre´sci<br />
1. Wst˛ep . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5<br />
1.1. Podstawy medyczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5<br />
1.2. Cel pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6<br />
2. Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8<br />
2.1. Model wytwarzania mowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8<br />
2.1.1. Mowa naturalna i przełykowa . . . . . . . . . . . . . . . . . . . . . . . . . . . 8<br />
2.1.2. Pseudoszept i model zakłóceń . . . . . . . . . . . . . . . . . . . . . . . . . . . 9<br />
2.2. Stanowisko pomiarowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10<br />
2.2.1. Mikrofon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10<br />
2.2.2. Kamera wideo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11<br />
2.2.3. Zapis nagrań . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11<br />
2.3. Materiał badawczy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11<br />
3. Algorytmy i implementacja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13<br />
3.1. Metody analizy ´scie˙zki d´zwi˛ekowej . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13<br />
3.1.1. Estymacja widma czasowo-cz˛estotliwo´sciowgo . . . . . . . . . . . . . . . . . 13<br />
3.1.2. ´Sledzenie formantów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14<br />
3.1.3. Analiza statystyczna formantów . . . . . . . . . . . . . . . . . . . . . . . . . . 14<br />
3.2. Metody analizy ruchomych obrazów twarzy . . . . . . . . . . . . . . . . . . . . . . . . 15<br />
3.2.1. Wyszukiwanie i ´sledzenie elementów twarzy . . . . . . . . . . . . . . . . . . . 15<br />
3.2.2. Ekstrakcja parametrów ekspresji . . . . . . . . . . . . . . . . . . . . . . . . . 16<br />
3.3. Rozpoznawanie samogłosek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17<br />
4. Wyniki eksperymentów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19<br />
4.1. Analiza sygnału mowy bezkrtaniowców . . . . . . . . . . . . . . . . . . . . . . . . . . 19<br />
4.2. Wyniki dla parametrów ekspresji twarzy . . . . . . . . . . . . . . . . . . . . . . . . . . 20<br />
4.3. Badanie korelacji parametrów audio i wideo . . . . . . . . . . . . . . . . . . . . . . . 21<br />
5. Dyskusja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23<br />
3
6. Podsumowanie <strong>rozprawy</strong> . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26<br />
Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
1. Wst˛ep<br />
Utrata krtani, a wi˛ec brak mo˙zliwo´sci porozumiewania si˛e głosem, jest dla wielu ludzi<br />
ci˛e˙zkim do zaakceptowania kalectwem. Zmienia całkowicie ˙zycie pacjentów przyczyniaj ˛ac<br />
si˛e do zmniejszenia aktywno´sci zawodowej oraz izolacji od społeczeństwa. Ogromn ˛a pomoc<br />
w zaakceptowaniu nowej sytuacji przynosi ponad wszystko skuteczna rehabilitacja głosu.<br />
Proponowana tematyka <strong>rozprawy</strong> <strong>doktorskiej</strong> dotyczy badania mowy osób po operacji<br />
usuni˛ecia krtani. W pracy podj˛eto si˛e zadania poł ˛aczenia ´scie˙zki d´zwi˛ekowej z obrazami<br />
ekspresji twarzy. Uwzgl˛edniono analiz˛e ruchów elementów twarzy podczas wypowiedzi<br />
bezkrtaniowców. Informacje wizualne odgrywaj ˛a znaczn ˛a rol˛e przy odbiorze i zrozumieniu<br />
głosu ludzkiego przez otoczenie. Zaproponowano metodyk˛e badań zmierzaj ˛ac ˛a do znalezienia<br />
zale˙zno´sci mi˛edzy ekspresj ˛a twarzy a mow ˛a, które mog ˛a znale´zć zastosowanie praktyczne<br />
podczas rehabilitacji i oceny zrozumiało´sci wypowiedzi pacjentów.<br />
Na cele pracy powstało stanowisko pomiarowe oraz oprogramowanie komputerowe.<br />
Oprogramowanie, które oznaczono skrótem AVW jest innowacyjn ˛a aplikacj ˛a komputerow ˛a<br />
do przetwarzania strumieni audio i wideo. Program mo˙ze być stosowany w rehabilitacji<br />
pacjentów po operacji krtani.<br />
1.1. Podstawy medyczne<br />
Rak krtani kończy si˛e najcz˛e´sciej jej cz˛e´sciowym lub całkowitym usuni˛eciem. Kalectwo<br />
to znacznie utrudnia, w wielu przypadkach uniemo˙zliwia, wytwarzanie d´zwi˛ecznego głosu.<br />
Mimo, i˙z patologia nie dotyka samych artykulatorów to zamyka ´zródło strumienia powietrza<br />
i fal akustycznych. Układ potrzebuje wtedy alternatywnego ´zródła energii. Układ rezonansowy,<br />
czyli nasada, jest nadal sprawny czynno´sciowo.<br />
Najprostsz ˛a form ˛a wytworzenia mowy przez pacjentów po operacji usuni˛ecia krtani<br />
jest wykształcenie pseudoszeptu ustno-gardłowego. Mowa ta wytwarzana jest za pomoc ˛a<br />
powietrza zawartego w jamie ustnej. Pseudoszept charakteryzuje si˛e brakiem d´zwi˛eczno´sci,<br />
a głoski wypowiadane przez chorego maj ˛a krótki czas trwania. Samogłoski praktycznie nie<br />
5
s ˛a wypowiadane ze wzgl˛edu na brak cz˛estotliwo´sci harmonicznych. Mowa ta charakteryzuje<br />
si˛e słab ˛a dynamik ˛a i jest mało zrozumiała przez otoczenie. Upo´sledzenie o tym charakterze<br />
znacznie komplikuje komunikowanie si˛e ludzi larynkektomowanych z otoczeniem.<br />
W mowie przełykowej rol˛e generatora drgań przejmuj ˛a fałdy ´sluzówki górnego odcinka<br />
przełyku. W tym miejscu powstaje gło´snia rzekoma czyli pseudogło´snia. Fale akustyczne<br />
powstaj ˛ace w pseudogło´sni podlegaj ˛a formowaniu w jamach rezonansowych przy pomocy<br />
ruchów narz ˛adów artykulacyjnych podobnie do mowy naturalnej. Niezb˛edne do artykulacji<br />
powietrze dostaje si˛e do gardła dolnego na drodze inspiracji lub połkni˛ecia [11, 4]. Nast˛epnie<br />
w wyniku fali antyperystaltycznej wypchni˛ete powietrze przeciska si˛e przez usta przełyku<br />
tworz ˛ac fonacj˛e.<br />
1.2. Cel pracy<br />
Poszukiwanie metod poprawy zrozumiało´sci nale˙zało zacz ˛ać od wypracowania<br />
wska´zników jako´sci interwencji pooperacyjnej. To wyznaczyło cel tej pracy, jakim jest<br />
znalezienie dobrych wska´zników stopnia zrozumiało´sci mowy poprzez poł ˛aczenie informacji<br />
uzyskanej z toru głosowego z obrazami wideo. W niniejszej pracy wykonano eksperymenty<br />
ł ˛acz ˛ace oba zbiory danych, wyznaczaj ˛ac wpływ ekspresji twarzy na parametry mowy<br />
zast˛epczej i pseudoszeptu. Prezentowane rozwi ˛azania stanowi ˛a baz˛e do wykonania urz ˛adzeń<br />
wykorzystuj ˛acych analizy wideo do poprawy zrozumiało´sci mowy ludzi po operacji wyci˛ecia<br />
krtani. W przyszło´sci implementacja sprz˛etowa cz˛e´sci omawianego systemu mo˙ze ułatwić<br />
swobodne komunikowanie si˛e bezkrtaniowców z otoczeniem.<br />
Celami niniejszej pracy były nast˛epuj ˛ace zadania:<br />
— opracowanie hybrydowego systemu analizy mowy bezkrtaniowców opieraj ˛acego si˛e<br />
na ´scie˙zce wideo oraz sygnale audio,<br />
— implementacja algorytmów ekstrakcji cech samogłosek polskich z uwzgl˛ednieniem mowy<br />
pacjentów po laryngektomii,<br />
— badania statystyczne charakteru głosu bezkrtaniowców i ró˙znic wzgl˛edem mowy naturalnej<br />
na podstawie obiektywnych parametrów,<br />
— ukazanie skuteczno´sci prezentowanych metod przy rozpoznawaniu i poprawie<br />
zrozumiało´sci mowy patologicznej.<br />
Metodologia pracy została oparta na nast˛epuj ˛acych tezach.<br />
6
— Patologia narz ˛adu mowy nie wpływa na sposób poruszania zewn˛etrznymi artykulatorami<br />
mowy i tym samym ekspresja twarzy u osób po laryngektomii pozostaje niezmieniona.<br />
— Parametry wideo uzupełniaj ˛a informacj˛e akustyczn ˛a, niweluj ˛a wpływ niedoskonało´sci<br />
mowy patologicznej, poprawiaj ˛a skuteczno´sć estymacji parametrów głosek oraz<br />
rozpoznawania mowy.<br />
Praca zawiera wyniki badań, uzyskane w ramach realizacji projektu badawczego<br />
promotorskiego numer N N518 0929 33, finansowanego przez Ministerstwo Nauki<br />
i Szkolnictwa Wy˙zszego.
2. Metodologia<br />
Model powstawania fali akustycznej w trakcie głosowym powinien ł ˛aczyć w sobie cechy<br />
mowy naturalnej i głosu ludzi laryngektomowanych. Pomiary wykonane w pracy, ograniczono<br />
do analiz sze´sciu podstawowych samogłosek polskich. Pozwoliło to na uproszczenie modelu i<br />
zastosowanie go dla dwóch rodzajów mowy, naturalnej i przełykowej.<br />
2.1. Model wytwarzania mowy<br />
W rozprawie <strong>doktorskiej</strong> do zamodelowania procesu wytwarzania mowy zastosowano<br />
znany szeroko w literaturze proces aurotegresji, którego współczynniki estymowane s ˛a<br />
z wykorzystaniem algorytmu adaptacyjnego. W przypadku formowania si˛e samogłosek<br />
zazwyczaj pomija si˛e wpływ jamy nosowej [5, 12]. Taki model pozwala na wykorzystanie<br />
szeroko stosowanej predykcji liniowej do wyznaczania parametrów filtru modeluj ˛acego<br />
trakt głosowy [25]. Filtr ma wtedy równanie procesu autoregresywnego (AR), w którym<br />
charakterystyk˛e widma wyznaczaj ˛a bieguny filtru. W modelu traktu głosowego przyj˛ete<br />
zostało, i˙z szum biały jest ´zródłem procesu autoregresji. Do wyznaczania parametrów modelu<br />
u˙zyto algorytmu adaptacyjnego WRLS [10].<br />
2.1.1. Mowa naturalna i przełykowa<br />
W pracy podzielono trakt głosowy na N = 10 jednakowo długich elementów<br />
o ró˙znych przekrojach poprzecznych (podobnie jak w ksi ˛a˙zce [23]). W pracy pomini˛eto<br />
wpływ przestrzeni jam nosowych na kształtowanie charakterystyki sygnału mowy<br />
[9]. Wyprowadzenie równania elementu transmitancji traktu mo˙zna znale´zć w [23].<br />
Przyporz ˛adkowanie współczynników odbicia do odpowiednich sekcji przedstawione jest w [8].<br />
Uproszczony model tworzenia sygnału mowy pozwala na zastosowanie filtru kratowego<br />
estymuj ˛acego parametry traktu głosowego. Przy przekształcaniu współczynników odbicia<br />
na odpowiednie przekroje poprzeczne traktu głosowego, przyj˛eto, i˙z w miejscu powstawania<br />
fali akustycznej przekrój poprzeczny wynosi 1. W [3] autorzy zauwa˙zaj ˛a, i˙z rejon ten<br />
8
jest najmniej czuły na zmiany obj˛eto´sciowe w trakcie generowania mowy w porównaniu<br />
z pozostałymi elementami traktu. W pracy przyj˛eto, i˙z przy przej´sciu fali przez usta na zewn ˛atrz<br />
traktu głosowego nast˛epuje całkowite ujemne odbicie fali akustycznej (współczynnik odbicia<br />
wynosi 1). Filtr kratowy równowa˙zny jest filtrowi transwersalnemu. Przekształcenie mi˛edzy<br />
parametrami obu modeli opisane w [29]. Dla cz˛estotliwo´sci próbkowania 8kHz, przyj˛eto<br />
liczb˛e współczynników filtru równ ˛a 10. Na drodze mi˛edzy ustami a mikrofonem pomija si˛e<br />
wszelkie zjawiska odbicia fali. Przyjmuje si˛e jedynie opó´znienie sygnału, które mo˙zna pomin ˛ać<br />
w dalszych rozwa˙zaniach. Zaniedbuje si˛e tak˙ze charakterystyk˛e cz˛estotliwo´sciow ˛a mikrofonu.<br />
Miejscem wytwarzania zast˛epczych drgań w przypadku mowy zast˛epczej s ˛a usta przełyku.<br />
Podobnie jak dla mowy naturalnej ´zródło fali d´zwi˛ekowej znajduje si˛e na pocz ˛atku<br />
modelowanego traktu głosowego. Istnieje wi˛ec mo˙zliwo´sć zastosowania tego samego modelu<br />
tworzenia samogłosek jak w przypadku mowy naturalnej.<br />
2.1.2. Pseudoszept i model zakłóceń<br />
Proponowany model wyznaczania parametrów akustycznych jest niewystarczaj ˛acy<br />
w przypadku analizy pseudoszeptu. Dotyczy to szczególnie artykulacji głosek z jednoczesnym<br />
wydychaniem powietrza przez otwór tracheotomijny. W [21] autor wykazał konieczno´sć<br />
wyznaczania parametrów akustycznych samogłosek z poł ˛aczeń spółgłoska-samogłoska (CV).<br />
Tak˙ze w tym przypadku, zaproponowany model akustyczny nie odpowiada rzeczywistemu<br />
sposobowi tworzenia si˛e głosu, w którym ´zródłem fali d´zwi˛ekowej mog ˛a być ró˙zne<br />
artykulatory w zale˙zno´sci od wypowiadanej spółgłoski poprzedzaj ˛acej.<br />
W modelu nale˙załoby uwzgl˛ednić ruchome poło˙zenie ´zródła fali d´zwi˛ekowej wzdłu˙z<br />
traktu. Zjawisko to zostało zbadane w [16], gdzie zostały wskazane ró˙znice wzgl˛edem modelu<br />
mowy naturalnej. Autor wykazał, i˙z w tym przypadku na charakterystyk˛e mowy wpływaj ˛a<br />
w znacznym stopniu zera filtru głosowego. Dlatego dla dokładnego odzwierciedlenia procesów<br />
zachodz ˛acych w tym przypadku nale˙załoby zmienić model filtru na ARMA.<br />
Model traktu głosowego dla osób laryngektomowanych powinien uwzgl˛edniać wpływ<br />
otworu tracheotomijnego. Na podstawie widm samogłosek przedstawionych w [21] autor<br />
wyci ˛agn ˛ał wniosek, ˙ze cichy pseudoszept podczas wymawiania samogłosek zamaskowany<br />
jest szumami wydobywaj ˛acymi si˛e z rurki tracheotomijnej. Odgłosy oddychania, nakładaj ˛ac<br />
si˛e na mow˛e, czyni ˛a j ˛a mniej zrozumiał ˛a, dlatego wa˙zn ˛a umiej˛etno´sci ˛a bezkrtaniowców jest<br />
synchronizacja oddechu z mow ˛a.<br />
9
Przegl ˛ad stosowanych rurek tracheotomijnych pozwala na przyj˛ecie bardzo prostego<br />
modelu generacji szumu wydostaj ˛acego si˛e z tracheostomy. Szumy powstaj ˛a w wi˛ekszo´sci<br />
u wej´scia rurki podczas turbulencji powietrza dostaj ˛acego si˛e do jej wn˛etrza. Strumień<br />
powietrza oraz powstałe szumy przebywaj ˛a nast˛epnie długo´sć rurki LR o stałej ´srednicy<br />
by wydostać si˛e u jej wylotu na zewn ˛atrz. Taki prosty model generacji szumów pozwala<br />
nam przewidzieć widmo zakłóceń wydobywaj ˛acych si˛e z otworu. Widmo to powinno<br />
mieć maksima powtarzaj ˛ace si˛e w odst˛epach b˛ed ˛acych odwrotno´sci ˛a czasu potrzebnego<br />
na przebycie dwóch długo´sci rurki tracheotomijnej przez fal˛e d´zwi˛ekow ˛a. Równanie 2.1<br />
opisuje model kształtowania widma szumów powstaj ˛acych podczas turbulencji u wylotu rurki<br />
tracheotomijnej.<br />
2.2. Stanowisko pomiarowe<br />
He(z) = φ+<br />
NR+1 (z)<br />
φ + 0 (z) = (1 + γ0)(1 + γNR )<br />
1 + z −NRγ0γNR<br />
(2.1)<br />
Stanowisko pomiarowe wykorzystane na cele <strong>rozprawy</strong> <strong>doktorskiej</strong> powstało we<br />
współpracy z Zakładem Audiologii Foniatrii i Otoneurologii Uniwersytetu Medycznego<br />
w Łodzi. Słu˙zy ono do rejestracji nagrań audio-wideo bezkrtaniowców, wizualizacji próbek<br />
głosu oraz ´sledzenia ekspresji twarzy. Rejestracji nagrań wykonano w dwóch cz˛e´sciach.<br />
Pierwsz ˛a seri˛e nagrań wykonano w wyciszonej kabinie. W drugim etapie wykorzystano mały<br />
pokój z d´zwi˛ekochłonnymi drzwiami oraz szczelnym okienkiem mi˛edzy pokojem operatora.<br />
W pomieszczeniu z pierwszego etapu nagrań poziom sygnału wzgl˛edem szumów wahał si˛e<br />
w granicach 42±2dB (SNR). W modelu zostało przyj˛ete, ˙ze tor foniczny nie zniekształca<br />
charakterystyki sygnału w badanym zakresie cz˛estotliwo´sci (20Hz do 4kHz). W obu etapach<br />
nagrań kamera ustawiona była na statywie w odległo´sci 1.5 metra od siedz ˛acego pacjenta.<br />
Podczas rejestracji zoom kamery ustawiono tak, aby w czasie całego nagrania widoczna była<br />
cz˛e´sć twarzy pacjentów od wysoko´sci łuku brwiowego do podbródka.<br />
2.2.1. Mikrofon<br />
Mikrofon zewn˛etrzny podł ˛aczony został do kanału lewego wej´scia mikrofonowego kamery.<br />
Rejestracje mowy w zale˙zno´sci od etapów nagrań wykonano przy u˙zyciu trzech rodzajów<br />
mikrofonów. W pierwszej cz˛e´sci nagrań u˙zyto zewn˛etrznego mikrofonu elektretowego.<br />
10
Do zasilenia mikrofonu u˙zyto baterii 1.5V. W celu wytłumienia gło´snych fragmentów<br />
i przystosowania mocy sygnału do wej´scia kamery (wzmocnienie 20dB) zastosowano<br />
dodatkowy potencjometr. Mikrofon umieszczono w odległo´sci 12 ± 4cm od ust badanych<br />
osób. Po awarii skonstruowanego mikrofonu w czasie prowadzenia nagrań zdecydowano si˛e na<br />
u˙zycie dwóch mikrofonów wbudowanych w kamer˛e wideo, która znajdowała si˛e w odległo´sci<br />
1.5m od głowy pacjentów. Aby unikn ˛ać niespodziewanych awarii na cele drugiego etapu<br />
nagrań zakupiono mikrofon zewn˛etrzny dedykowany dla kamer wideo [22]. Ustawiono go<br />
w odległo´sci 20cm od kamery oraz w odległo´sci 1.5m od ust osób nagrywanych. Mikrofon<br />
wykorzystany w drugim etapie nagrań jest opisany w instrukcji [22].<br />
2.2.2. Kamera wideo<br />
Nagrań dokonano za pomoc ˛a kamery cyfrowej Panasonic NV-DS63EGE [19].<br />
Pozostawiono domy´slne ustawienia kamery z wyj ˛atkiem zbli˙zenia, które ustawiono tak,<br />
aby spełnić wymagania co do widoczno´sci całej twarzy pacjenta z jednoczesn ˛a minimalizacj ˛a<br />
obszaru tła. Dane zapisano na karcie MiniDV, z zapisanym d´zwi˛ekiem w formacie PCM<br />
z rozdzielczo´sci ˛a 16 bitów i cz˛estotliwo´sci ˛a próbkowania 48 kHz. Rozdzielczo´sć obrazu<br />
zapisanego na karcie w formacie AVI wynosiła 720x576. Uzyskano cz˛esto´sć od´swie˙zania<br />
równ ˛a 25fps. Kopiowania filmu z kamery na komputer wykonano przy u˙zyciu interfejsu<br />
IEEE1394.<br />
2.2.3. Zapis nagrań<br />
Nagrania zostały zarchiwizowane na płytach CD i DVD. Podzielone zostały na oddzielne<br />
pliki dla ka˙zdego pacjenta. W pierwszym etapie nagrania skomprymowane zostały do formatu<br />
MPEG2 w rozdzielczo´sci 352x288 pikseli. D´zwi˛ek o 16-bitowej kwantyzacji został poddany<br />
konwersji cz˛estotliwo´sci próbkowania z 48 do 8kHz. W tym przypadku zapis d´zwi˛eku<br />
uległ kompresji do formatu MPEG Audio (wersja 1, warstwa 2) bazuj ˛acym na modelu<br />
psychoakustycznym.<br />
2.3. Materiał badawczy<br />
W pracy wykorzystanych zostało 62 nagrań pacjentów po całkowitym usuni˛eciu krtani<br />
oraz 11 zdrowych osób z grupy kontrolnej. Materiał lingwistyczny stanowiły samogłoski<br />
11
izolowane oraz dodatkowo wybrane słowa jednosylabowe i dwusylabowe z list wg<br />
Zakrzewskiego, Pruszewicza i Kubzdeli [28]. Nale˙zy podkre´slić, ˙ze badania na cele<br />
prowadzonej pracy zostały zaakceptowane przez komisj˛e etyczn ˛a. Wszyscy pacjenci bior ˛acy<br />
udział w projekcie wyrazili zgod˛e na korzystanie z zebranych nagrań w celach naukowych.
3. Algorytmy i implementacja<br />
3.1. Metody analizy ´scie˙zki d´zwi˛ekowej<br />
W ramach pracy powstał program komputerowy o nazwie AVW. Jest to aplikacja, która<br />
analizuje zapis mowy z plików audio lub wideo. Analizie podlega tylko kanał lewy sygnału<br />
audio. Program wy´swietla widmo czasowo-cz˛estotliwo´sciowe w oknie w czasie odtwarzania<br />
pliku. Posiada szereg funkcjonalno´sci ułatwiaj ˛acych analiz˛e materiału. Aplikacja napisana<br />
została w j˛ezyku C++ za pomoc ˛a graficznego ´srodowiska programistycznego Visual C++.<br />
Program jest wielodokumentow ˛a aplikacj ˛a MFC korzystaj ˛ac ˛a z bibliotek DirectX 9.0 SDK<br />
[20]. Aplikacja AVW umo˙zliwia analiz˛e sygnałów mowy zapisanych w plikach w formatach<br />
WAV, AVI, MPEG.<br />
Pomiary na cele <strong>rozprawy</strong> obejmowały takie parametry artykulacji samogłosek, jak<br />
formanty F 1 i F 2 b˛ed ˛ace według [13] głównymi parametrami nosz ˛acymi informacj˛e<br />
o samogłoskach.<br />
Na cele <strong>rozprawy</strong> zaimplementowano skrypt w ´srodowisku MatLab wyznaczaj ˛acy<br />
cz˛estotliwo´sci podstawowe dla mowy naturalnej jak i przełykowej. Algorytm wykorzystuje<br />
pierwszy wiersz macierzy autokorelacji sygnału przefiltrowany z u˙zyciem filtru<br />
dolnoprzepustowego.<br />
3.1.1. Estymacja widma czasowo-cz˛estotliwo´sciowgo<br />
Odwrotny model traktu głosowego przekształcony jest do filtru transwersalnego opartego<br />
o liniow ˛a predykcj˛e. Mamy tu do czynienia z problemem wybielania sygnału, który sprowadza<br />
si˛e do znalezienia transmitancji filtru odwrotnego. Do wyznaczenia estymat współczynników<br />
zastosowano adaptacyjny algorytm rekurencyjny WRLS (z ang. Weighted Recursive Least<br />
Square) podany przez Haykin’a [10]. W algorytmie korzysta si˛e z kryterium LS, najmniejszych<br />
kwadratów. Z otrzymanej charakterystyki cz˛estotliwo´sciowej filtru, posiadaj ˛acego jedynie<br />
bieguny, obliczane s ˛a cz˛estotliwo´sci formantowe. W przypadku grupy kontrolnej sygnał mowy<br />
13
poddany był preemfazie z u˙zyciem filtru górnoprzepustowego o transmitancji Hpre(z) =<br />
1 − 0.9735z −1 . W przypadku mowy zast˛epczej wykonanie preemfazy nie jest wymagane<br />
ze wzgl˛edu na wyrównan ˛a charakterystyk˛e cz˛estotliwo´sciow ˛a ´zródła głosu przełykowego.<br />
3.1.2. ´Sledzenie formantów<br />
W pracy zastosowano algorytm Christensena [6] do znajdowania w widmie LPC kolejnych<br />
kandydatów na cz˛estotliwo´sci formantowe. Metoda polega na wyszukaniu minimów drugiej<br />
pochodnej widma. Maksymalna liczba kandydatów równa jest liczbie biegunów w modelu<br />
filtru głosowego i dla 10 współczynników filtra wynosi 5. Według [25] w pa´smie cz˛estotliwo´sci<br />
do 4kHz mog ˛a wyst ˛apić maksymalnie 4 formanty. Mo˙ze si˛e wi˛ec zdarzyć, ˙ze liczba<br />
kandydatów na formanty jest mniejsza lub wi˛eksza (maksymalnie o 1) od liczby szukanych<br />
formantów. Do odrzucenia kandydata b ˛ad´z przydzielenia mniejszej ilo´sci kandydatów<br />
do formantów zaimplementowany został algorytm najmniejszego kosztu przej´scia mi˛edzy<br />
kolejnymi warto´sciami formantów. Algorytm ten bierze pod uwag˛e cz˛estotliwo´sci kandydatów<br />
na formanty oraz ´srednie z warto´sci 9-ciu poprzednich formantów.<br />
3.1.3. Analiza statystyczna formantów<br />
Do wyznaczenia formantów dla wypowiedzianej samogłoski, nale˙zy wybrać<br />
reprezentatywny fragment nagrania. Najprostsz ˛a metod ˛a jest r˛eczne zaznaczenie<br />
na periodogramie granic samogłoski analizuj ˛ac widmo czasowo-cz˛estotliwo´sciowe i nat˛e˙zenie<br />
d´zwi˛eku.<br />
W programie AVW zaznaczony fragment mo˙ze być dalej automatycznie zaw˛e˙zony<br />
uwzgl˛edniaj ˛ac energi˛e sygnału. W niniejszej pracy zaimplementowano metod˛e wyznaczaj ˛ac ˛a<br />
w zaznaczonym fragmencie maksimum oraz minimum pochodnej energii sygnału po czasie.<br />
Punkt maksymalnej pochodnej powinien poprzedzać punkt minimalnej pochodnej a czas<br />
mi˛edzy obydwoma punktami powinien stanowić co najmniej połow˛e długo´sci zaznaczonego<br />
fragmentu.<br />
Z opisanej operacji wynikaj ˛a cztery zbiory punktów zmienno´sci poszczególnych<br />
formantów. Dla ka˙zdego formantu wyznaczany jest rozkład jego warto´sci w danym fragmencie,<br />
a z niego obliczana jest mediana oraz rozst˛ep mi˛edzykwartylowy. Mediana warto´sci formantów<br />
z odcinka czasowego brana jest pod uwag˛e jako warto´sć formantu dla wypowiadanej w danym<br />
momencie samogłoski. Warto´sć ta brana jest dalej do obliczeń statystycznych.<br />
14
3.2. Metody analizy ruchomych obrazów twarzy<br />
Poł ˛aczenie analizy sygnału mowy ze ´scie˙zk ˛a wideo jest coraz szerzej stosowan ˛a metod ˛a<br />
przy automatycznym rozpoznawaniu mowy w trudnych warunkach akustycznych [7, 14, 15].<br />
Wykazano, i˙z przy zakłóceniach i szumach w torze audio, analiza wideo niesie ze sob ˛a wiele<br />
korzystnych informacji.<br />
Algorytmy lokalizacji elementów twarzy w obrazie i metody ´sledzenia zmian parametrów<br />
ekspresji zaimplementowano w formie filtra DirectShow doł ˛aczanego do systemu jako<br />
biblioteka dynamiczna. Zestaw funkcji filtra implementuje poszczególne kroki segmentacji<br />
obrazu w celu rozpoznania i umiejscowienia twarzy i ust. Filtr analizuje obraz podczas<br />
odtwarzania ´scie˙zki wideo i przesyła aktualne parametry do programu głównego. Jako<br />
deskryptory wizualne wybrano iloczyn wysoko´sci i szeroko´sci otwarcia ust oraz wielko´sć<br />
opisuj ˛ac ˛a rozwarcie ˙zuchwy.<br />
3.2.1. Wyszukiwanie i ´sledzenie elementów twarzy<br />
W systemie opracowanym przez autora <strong>rozprawy</strong> zaimplementowano własne metody<br />
lokalizacji elementów twarzy w obrazach. Obraz wst˛epnie przetworzony jest z przestrzeni<br />
RGB do HSV [17]. Dla kolejnych klatek wideo algorytm wyznacza charakterystyczne obszary.<br />
Dla ka˙zdego piksela wyznaczane s ˛a takie cechy, jak nat˛e˙zenie koloru czerwonego, stopień<br />
zaciemnienia, ruch odzwierciedlany poprzez lokalne ró˙znice mi˛edzy kolejnymi klatkami,<br />
ró˙znice mi˛edzy pikselami w pionie oraz poziomie. Ka˙zda z cech jest porównywana z warto´sci ˛a<br />
graniczn ˛a w celu jednoznacznego przydzielenia piksela do obszaru lub otoczenia. Warto´sć<br />
granicy ustalana jest dynamicznie tak, aby wielko´sci obszarów d ˛a˙zyły do zdefiniowanej<br />
proporcji w stosunku do całego obrazu.<br />
Do poprawnego działania algorytmu liczba pikseli dla ka˙zdego regionu powinna być<br />
stała dla wszystkich klatek. W zwi ˛azku z tym granice przyporz ˛adkowuj ˛ace ka˙zdy piksel<br />
do ka˙zdej z grup lub ich otoczeń, s ˛a dynamicznie zmieniane. Z góry zakłada si˛e, ˙ze histogramy<br />
s ˛a wyrównane dla wszystkich warto´sci. Warto´sci graniczne uaktualniane s ˛a liniowo wzgl˛edem<br />
bł˛edu b˛ed ˛acym ró˙znic ˛a mi˛edzy warto´sci ˛a zadan ˛a liczby pikseli a warto´sci ˛a otrzyman ˛a w<br />
aktualnej klatce. Przynale˙zno´sć piksela do elementu twarzy wyliczana jest jako warto´sć<br />
logiczna z przynale˙zno´sci do zbiorów b˛ed ˛acych sum ˛a logiczn ˛a pikseli zaczerwienionych i<br />
zró˙znicowanych w pionie plus ciemnych i poruszaj ˛acych si˛e.<br />
15
Obrys twarzy znajdowany jest z wykorzystaniem faktu, i˙z obszar twarzy stanowi<br />
najbardziej zaczerwieniony region obrazu i ograniczony jest konturem ró˙znicowym z lewej<br />
i prawej strony. Warunki te brane s ˛a pod uwag˛e przy zało˙zeniach dotycz ˛acych umiejscowienia<br />
i wielko´sci twarzy w obrazie oraz jednolitego białego tła.<br />
W celu wypełnienia luk dla wysoko´sci, gdzie obrys nie został znaleziony, obrysy poddane<br />
zostały filtracji z u˙zyciem filtru dolnoprzepustowego. Punkty lewego i prawego obrysu twarzy<br />
ł ˛aczone s ˛a nast˛epnie odcinkami. Z punktów ´srodkowych odcinków mi˛edzy prawym a lewym<br />
obrysem (dla poszczególnych wysoko´sci) za pomoc ˛a transformaty Hought’a [17] znajdowana<br />
jest linia główna symetrii obrysu twarzy. Punkty najbardziej oddalone od linii głównej<br />
s ˛a eliminowane, aby nie wprowadzały zaburzeń. Końcowe równanie linii symetrii twarzy<br />
estymowane jest za pomoc ˛a metody najmniejszych kwadratów.<br />
Linia symetrii obrysu głowy wykorzystana jest dalej do znajdowania punktów symetrii<br />
elementów twarzy. W tym celu tworzone s ˛a odcinki obrazu ograniczone przez kontur<br />
głowy i prostopadłe do symetrii obrysu twarzy. Dla ka˙zdego odcinka wyznacza si˛e wektor<br />
autokorelacji. Nast˛epnie znajdowany jest punkt b˛ed ˛acy ´srodkiem ci˛e˙zko´sci tego wektora.<br />
Nast˛epnie bada si˛e otoczenie punktu ci˛e˙zko´sci w badanym odcinku. Je´sli suma punktów<br />
otoczenia osi ˛aga zało˙zony pułap przyjmuje si˛e tzw. symetri˛e „nieparzyst ˛a”, oznaczaj ˛ac ˛a<br />
wyst˛epowanie nieparzystej liczby skupień obszarów symetrycznych. Je´sli suma punktów<br />
jest mniejsza od zadanej liczby, wtedy zakłada si˛e tzw. „parzyst ˛a” symetri˛e, która oznacza<br />
wyst˛epowanie parzystej liczby skupień obszarów symetrycznych. Ze znalezionych punktów<br />
symetrii dla ka˙zdego odcinka wylicza si˛e równanie linii symetrii twarzy w taki sam sposób jak<br />
dla symetrii obrysu.<br />
Znajdowanie konkretnych elementów twarzy nast˛epuje na podstawie informacji<br />
o pseudo-parzysto´sci punktów symetrii. Przykładowo usta powinny stanowić jeden obszar<br />
(nieparzysta liczba), a oczy dwa obszary (parzysta liczba).<br />
3.2.2. Ekstrakcja parametrów ekspresji<br />
Z modelu akustycznego znane s ˛a stosunki pomi˛edzy kolejnymi polami przekrojów<br />
poprzecznych. Aby podać wymiary traktu głosowego w jednostkach odpowiadaj ˛acym długo´sci,<br />
nale˙zy przyj ˛ać za wiadome jedno z pól przekroju. Przekrój pierwszego elementu traktu<br />
głosowego, czyli powierzchnia otwarcia ust SL, jest głównym elementem wideo maj ˛acym swój<br />
odpowiednik w parametrach akustycznych. Parametr ten podany jest w stosunku do kwadratu<br />
16
odległo´sci mi˛edzy oczyma osoby na obrazie L 2 0. Parametr L0 jest niezmienny i mo˙ze być łatwo<br />
zmierzony w jednostce długo´sci dla ka˙zdego pacjenta. Na potrzeby rozpoznawania samogłosek<br />
z parametrów wideo mierzono w pracy tak˙ze szeroko´sć rozwarcia ˙zuchwy LJ. Nie został<br />
jednak zaimplementowany ˙zaden algorytm do ´sledzenia tej warto´sci w obrazie wideo. Parametr<br />
ten nie jest wykorzystywany przy fuzji ze współczynnikami akustycznymi.<br />
Jako deskryptory wizualne {v1, v2} samogłosek wybrane zostały: iloczyn wysoko´sci (LH)<br />
i szeroko´sci (LW ) otwarcia ust oraz rozwarcie ˙zuchwy. Oba parametry znormalizowane zostały<br />
w stosunku do odległo´sci mi˛edzy oczyma pacjenta (L0) zgodnie z 3.1.<br />
v1 = 4LHLW<br />
L0 2<br />
v2 = LJ − LJ m<br />
L0<br />
− 1<br />
(3.1)<br />
Rozwarcie ˙zuchwy liczono jako przyrost odległo´sć od linii ł ˛acz ˛acej oczy do czubka brody<br />
(LJ) w stosunku do tej warto´sci w pozycji neutralnej (LJ m).<br />
Równocze´snie z automatycznym ´sledzeniem elementów twarzy pomiary parametrów<br />
wideo musiały być dodatkowo wykonane r˛ecznie. Klatki filmowe odpowiadaj ˛ace fragmentom<br />
akustycznym o tym samym czasie w ´scie˙zce wideo zapisywane były do plików obrazkowych.<br />
Za pomoc ˛a programu GIMP wykonano pomiary odległo´sci charakterystycznych twarzy (w<br />
pikselach) i znormalizowano wymiary do odległo´sci mi˛edzy oczyma nagrywanych osób.<br />
3.3. Rozpoznawanie samogłosek<br />
Do rozpoznawania samogłosek u˙zyto dwóch jednokierunkowych sieci neuronowych o<br />
dwóch wej´sciach. Dla parametrów akustycznych na wej´scie sieci podawano odpowiednio<br />
znormalizowane warto´sci formantów F1, F2 (3.2).<br />
a1 =<br />
a2 =<br />
F 2<br />
− 1.5<br />
1000<br />
F 1<br />
− 0.7 (3.2)<br />
1000<br />
Funkcj ˛a przej´scia w pierwszej warstwie była funkcja tansig. Na wyj´sciu sieci skorzystano z<br />
funkcji liniowej. Do uczenia sieci u˙zyto algorytmu propagacji wstecznej opartego na kryterium<br />
minimalizacji bł˛edu ´sredniokwadratowego (MSE). Obydwie sieci neuronowe dla parametrów<br />
audio i wideo zostały nauczone na podstawie danych z grupy kontrolnej tak, aby warto´sć<br />
17
na wyj´sciu sieci odpowiadaj ˛acym wypowiadanej samogłosce wyniosła 1 a na pozostałych<br />
wyj´sciach -1. Dla sieci klasyfikuj ˛acej samogłoski na podstawie deskryptorów akustycznych<br />
liczba wyj´sć sieci była równa liczbie samogłosek. W przypadku parametrów wideo liczba<br />
wyj´sć została zredukowana do czterech. Sieć nie potrafiła rozró˙znić samogłosek ’a’ od ’e’ oraz<br />
i od y, poniewa˙z parametry wideo przyjmowały podobne warto´sci przy ich wypowiadaniu. Dla<br />
ka˙zdej z podanych par przydzielono jedno z wyj´sć sieci.
4. Wyniki eksperymentów<br />
W rozdziale przedstawione zostały wyniki badań statystycznych charakteru<br />
głosu bezkrtaniowców. Uwzgl˛edniono ró˙znice mi˛edzy mow ˛a naturaln ˛a, przełykow ˛a<br />
a pseudoszeptem. Rezultaty zamieszczone w tej cz˛e´sci rozszerzaj ˛a dotychczasow ˛a wiedz˛e<br />
o informacje na temat skuteczno´sci analizy i rozpoznawania mowy w oparciu o parametry<br />
akustyczne oraz wizualne. Przedstawione s ˛a tak˙ze wzajemne korelacje tych hybrydowych<br />
parametrów.<br />
4.1. Analiza sygnału mowy bezkrtaniowców<br />
Wst˛epna analiza widmowa zapisów audio samogłosek w pseudoszepcie ukazała<br />
mi˛edzyosobnicze ró˙znice w widmach poszczególnych samogłosek. Widma nie wykazuj ˛a tak˙ze<br />
podobieństwa do widm wyliczonych dla odpowiednich samogłosek mowy naturalnej. Mo˙zna<br />
natomiast zauwa˙zyć podobieństwa w kształtach widm dla ró˙znych samogłosek w ramach<br />
wypowiedzi jednego pacjenta.<br />
Cz˛estotliwo´sci formantowe s ˛a w przybli˙zeniu harmonicznymi pierwszego formantu.<br />
Dla pacjenta posiadaj ˛acego rurk˛e tracheotomijn ˛a współczynniki proporcji poszczególnych<br />
cz˛estotliwo´sci formantów wynosz ˛a w przybli˙zeniu 1:2:3:4:5. Inny charakter widma<br />
otrzymujemy dla pacjenta nieposiadaj ˛acego rurki tracheotomijnej. W tym przypadku<br />
widmo samogłosek przesuni˛ete jest ku ni˙zszym cz˛estotliwo´sciom a współczynniki proporcji<br />
poszczególnych cz˛estotliwo´sci formantowych wynosz ˛a w przybli˙zeniu 1:3:5:7:9.<br />
´Srednia cz˛estotliwo´sć podstawowa wyniosła dla mowy przełykowej 50Hz a dla mowy<br />
naturalnej 165Hz. Zaobserwowano ni˙zsz ˛a ´sredni ˛a cz˛estotliwo´sć podstawow ˛a F 0, ni˙z<br />
podawana w literaturze.<br />
W celu udowodnienia statystycznych ró˙znic mi˛edzy cz˛estotliwo´sciami formantowymi F 1<br />
i F 2 dla poszczególnych samogłosek mi˛edzy grup ˛a kontroln ˛a a pacjentami wykorzystano test<br />
T 2 (t - kwadrat) Hotelling’a [18]. Ró˙znice na poziomie wiarygodno´sci p < 0.05 osi ˛agni˛eto<br />
w przypadku samogłosek ’a’, ’o’ oraz ’u’. W przypadku samogłoski ’a’ F 1 przesuwa si˛e<br />
19
ku górnym cz˛estotliwo´sciom o około 20%. W przypadku tej samogłoski osi ˛agni˛eto ró˙znic˛e<br />
w F 1 na poziomie istotno´sci statystycznej p < 0.02 oraz p < 0.005 dla F 2.<br />
Przy zało˙zeniu kołowych przekrojów poprzecznych tuby akustycznej traktu głosowego,<br />
wykonane zostały analizy statystyczne dotycz ˛ace ´srednic przekrojów wynikaj ˛acych<br />
bezpo´srednio ze współczynników modelu akustycznego. Analizy statystyczne ´srednic<br />
przekrojów poprzecznych traktu głosowego wykonano za pomoc ˛a testu T 2 Hotelling’a. Istotne<br />
statystycznie ró˙znice w przekrojach poprzecznych mi˛edzy grup ˛a kontroln ˛a a pacjentami<br />
posługuj ˛acymi si˛e mow ˛a przełykow ˛a wyst ˛apiły dla samogłosek ’e’ oraz ’u’. W pracy wykonano<br />
tak˙ze analiz˛e składowych głównych przekrojów poprzecznych traktu głosowego.<br />
Wykonano uczenie sieci neuronowej rozpoznaj ˛acej sze´sć samogłosek polskich na<br />
podstawie dwóch pierwszych formantów. Dla mowy naturalnej b˛ed ˛acej zbiorem ucz ˛acym<br />
otrzymano wysok ˛a 98% skuteczno´sć rozpoznawania ka˙zdej z sze´sciu samogłosek polskich.<br />
W czasie symulacji sieci na zbiorze testowym dla mowy przełykowej skuteczno´sć ta wyniosła<br />
75%.<br />
4.2. Wyniki dla parametrów ekspresji twarzy<br />
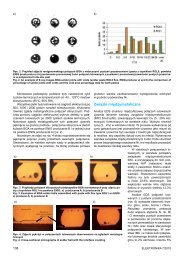
Rysunki 4.1 pokazuj ˛a skuteczno´sć działania filtru ´sledz ˛acego elementy twarzy. Widać<br />
na nich, ˙ze wykorzystany algorytm jest silnie zale˙zny od warunków nagrania, a zwłaszcza<br />
od ró˙znic w wygl ˛adzie osób. Wra˙zliwy jest na takie czynniki jak długie włosy, noszenie brody<br />
lub zało˙zone okulary.<br />
W rozdziale 3.3 ukazano mo˙zliwo´sć rozpoznawania czterech klas samogłosek na podstawie<br />
samych parametrów wideo za pomoc ˛a sieci neuronowej. Parametry wizualne zawieraj ˛ace<br />
powierzchni˛e ust i szeroko´sć rozwarcia szcz˛eki podzieliły samogłoski na cztery grupy<br />
{’a’, ’e’}, {’i’, ’y’}, {’u’}, {’o’} . Sieć została nauczona na podstawie danych z grupy<br />
porównawczej i klasyfikowała dane ucz ˛ace ze skuteczno´sci ˛a 93%. Skuteczno´sć rozpoznawania<br />
grup samogłosek dla grup eksperymentalnych w przypadku mowy przełykowej wyniosła 77%<br />
a dla pseudoszeptu 75%. Otrzymano zbli˙zone wyniki skuteczno´sci rozpoznawania dla obu grup<br />
pacjentów.<br />
20
4.3. Badanie korelacji parametrów audio i wideo<br />
Okre´slone zostało powi ˛azanie analiz audio z parametrami wizualnymi dla mowy<br />
naturalnej i zast˛epczej. Przedstawione zostały analizy składowych głównych zmian przekrojów<br />
poprzecznych traktu głosowego w zale˙zno´sci od pacjentów i samogłosek. Porównano wyniki<br />
analiz parametrów wideo w przypadku kolejnych grup, kontrolnej, pseudoszeptu i mowy<br />
przełykowej. Dla parametrów audio i hybrydowych umieszczono porównanie wyników analiz<br />
składowych głównych mi˛edzy grup ˛a kontroln ˛a a eksperymentaln ˛a. Z poł ˛aczonych danych<br />
dla grupy K i grupy EZ wykonano porównanie składowych głównych w przypadku analiz<br />
samych przekrojów poprzecznych z parametrami hybrydowymi zawieraj ˛acymi dodatkowo SL<br />
oraz LJ. W przypadku analizy składowych głównych pól przekrojów traktu głosowego pole<br />
w pobli˙zu ´zródła fonacji przyj˛eto jako warto´sć stał ˛a, niezmienn ˛a dla wszystkich pacjentów<br />
i samogłosek.<br />
Wyniki analiz ładunków składowych głównych pokazuj ˛a, które parametry s ˛a ze sob ˛a<br />
skorelowane. W kierunku okre´slonym przez pierwsz ˛a składow ˛a główn ˛a najwi˛eksze zmiany<br />
widoczne s ˛a dla wszystkich przekrojów poprzecznych. Natomiast w kierunku wyznaczonym<br />
przez drug ˛a składow ˛a zmieniaj ˛a si˛e oba parametry wizualne.
Rysunek 4.1. Wyniki działania filtru FaceFilter ´sledz ˛acego oczy i obrys ust.<br />
22
5. Dyskusja<br />
W mowie przełykowej obszary wyst˛epowania samogłosek polskich na płaszczy´znie<br />
F 1 − F 2 układaj ˛a si˛e podobnie jak w mowie naturalnej. ´Swiadczy to o ich wła´sciwej<br />
artykulacji. Zaobserwowano jednak w tym przypadku, ˙ze warto´sci formantów dla trzech<br />
samogłosek s ˛a podwy˙zszone w porównaniu z mow ˛a naturaln ˛a na statystycznym poziomie<br />
istotno´sci. Na podstawie rezultatów mo˙zna stwierdzić, i˙z wyci˛ecie krtani i zast ˛apienie jej<br />
alternatywnym ´zródłem fonacji wpływa na charakterystyk˛e akustyczn ˛a traktu głosowego.<br />
Na przykładzie formantu F 1 stwierdzono, ˙ze skraca si˛e efektywna długo´sć traktu głosowego<br />
[24]. Wyniki analiz statystycznych formantów F 1 i F 2 oraz przekrojów poprzecznych<br />
pokazały, ˙ze w zale˙zno´sci od tego, czy analizowano formanty, czy te˙z przekroje poprzeczne,<br />
inne samogłoski zró˙znicowane były mi˛edzy grup ˛a kontroln ˛a a mow ˛a przełykow ˛a. Potwierdza<br />
to wpływ efektywnej długo´sci traktu głosowego na przesuni˛ecie si˛e formantów w wy˙zsze<br />
cz˛estotliwo´sci.<br />
Za pomoc ˛a konwencjonalnej metody wyznaczania cz˛estotliwo´sci formantowych nie udało<br />
si˛e wyznaczyć warto´sci dla pseudoszeptu. Pojawiaj ˛ace si˛e maksima widma zwi ˛azane były z<br />
szumami wydostaj ˛acymi si˛e z otworu tracheotomijnego i nie odzwierciedlały zmian kształtów<br />
traktu głosowego. Wi˛eksz ˛a rozró˙znialno´sć poszczególnych samogłosek dla pseudoszeptu<br />
uzyskano w przypadku zł ˛aczeń CV, lecz w tym przypadku ze wzgl˛edu na bardzo krótki czas<br />
trwania samogłosek nie udało si˛e zebrać wystarczaj ˛acej ilo´sci danych.<br />
Zmiany charakteru głosu po laryngektomii widoczne s ˛a przede wszystkim w cz˛estotliwo´sci<br />
podstawowej, której warto´sć obni˙za si˛e znacznie po zast ˛apieniu krtani ustami przełyku.<br />
Pomiary tonu podstawowego mowy przełykowej wykazały du˙zo ni˙zsze cz˛estotliwo´sci<br />
w porównaniu z mow ˛a naturaln ˛a. Wyznaczona ´srednia formantu F 0, wynosz ˛aca 50Hz, jest<br />
ni˙zsza od raportowanej w [27], gdzie otrzymano wynik równy 69Hz. Zakres zmienno´sci<br />
F 0 od 30 do 75Hz zawiera si˛e w danych raportowanym przez innych autorów. Według [1]<br />
ton przełykowy mo˙ze osi ˛agać cz˛estotliwo´sci od 32 do 233Hz. W przypadku rejestracji<br />
głosu pacjenci mówili swobodnie wytwarzaj ˛ac naturaln ˛a barw˛e głosu. Mo˙ze to ´swiadczyć,<br />
23
i˙z ni˙zsze cz˛estotliwo´sci tonu przełykowego s ˛a łatwiejsze do wytworzenia i bardziej naturalne<br />
dla pacjentów.<br />
Wyniki analizy składowych głównych zmian przekrojów poprzecznych traktu głosowego<br />
pokazały, ˙ze głównym czynnikiem wpływaj ˛acym na wielko´sci pól przekrojów jest przyj˛ecie<br />
jednego z nich jako wielko´sci znanej. Zauwa˙zono, ˙ze estymowane wymiary pól przekrojów<br />
poprzecznych traktu głosowego ró˙zni ˛a si˛e w znacznym stopniu od ich rzeczywistych<br />
odpowiedników.<br />
Algorytm ´sledzenia elementów twarzy jest silnie zale˙zny od warunków nagrania,<br />
a zwłaszcza od ró˙znic w wygl ˛adzie osób. Wra˙zliwy jest na takie czynniki jak długie włosy,<br />
noszenie brody lub zało˙zone okulary. Kompresja obrazów wpływa negatywnie na skuteczno´sć<br />
prezentowanych metod, powoduje przekłamania w kształcie wyznaczanych elementów twarzy,<br />
takich jak usta. Wielo´sć artefaktów powoduje wi˛eksze bł˛edy w estymacji linii symetrii z obrysu<br />
twarzy i jej elementów.<br />
Badania wykazały, ˙ze przy analizie pseudoszeptu dla głosek izolowanych ´scie˙zka wizualna<br />
daje o wiele lepsze efekty ni˙z analiza mowy. Wyniki eksperymentu ukazały du˙ze znaczenie<br />
pomiarów parametrów ekspresji twarzy przy analizie mowy patologicznej.<br />
Jak wykazały pomiary, sygnał wideo nie niesie ze sob ˛a wystarczaj ˛acej ilo´sci<br />
informacji, potrzebnej do rozpoznania ka˙zdej z samogłosek polskich. Mo˙ze być za to<br />
uzupełnieniem informacji akustycznej w warunkach zniekształcenia, b ˛ad´z zaszumienia sygnału<br />
mowy. Prezentowana metoda wprowadza znaczne polepszenie wska´zników skuteczno´sci<br />
rozpoznawania samogłosek w porównaniu z analiz ˛a samego toru audio, zwłaszcza dla<br />
pacjentów posługuj ˛acych si˛e pseudoszeptem.<br />
Uzyskane rezultaty klasyfikacji zbli˙zone s ˛a do skuteczno´sci rozpoznawania mowy<br />
bazuj ˛acego na współczynnikach akustycznych. Problemy z rozró˙znianiem dwóch par<br />
samogłosek {’a’, ’e’} oraz {’i’, ’y’}, wynikaj ˛a ze sposobu ich kształtowania polegaj ˛acym<br />
na innym poło˙zeniu j˛ezyka, nie maj ˛acym znacz ˛acego odzwierciedlenia w ruchach<br />
zewn˛etrznych cz˛e´sci twarzy.<br />
Nie stwierdzono istnienia bezpo´srednich korelacji mi˛edzy parametrami wideo<br />
a przekrojami poprzecznymi, choć w rzeczywisto´sci mo˙zna było si˛e ich spodziewać.<br />
Prawdopodobnie jest to spowodowane wadami metody wyznaczania przekrojów traktu<br />
ze współczynników predykcji. Wady te omówione zostały w [26]. Próba zało˙zenia,<br />
i˙z pole ostatniego przekroju poprzecznego traktu równe jest polu powierzchni otwarcia<br />
24
ust oraz korekcja pozostałych przekrojów proporcjonalnie do pierwszego nie przyniosła<br />
zadowalaj ˛acych rezultatów. Osi ˛agni˛ete nowe przekroje nie odpowiadały rzeczywistym<br />
przekrojom traktu.
6. Podsumowanie <strong>rozprawy</strong><br />
Przedstawiony system analizy mowy bezkrtaniowców, został opracowany<br />
z wykorzystaniem algorytmów ekstrakcji parametrów hybrydowych akustycznych i wideo.<br />
W przypadku analizy samogłosek mowy przełykowej wykazano przesuni˛ecie dwóch<br />
pierwszych formantów w wy˙zsze cz˛estotliwo´sci w porównaniu z mow ˛a naturaln ˛a. Ró˙znice<br />
na statystycznym poziomie istotno´sci osi ˛agni˛eto w przypadku głosek ’a’, ’o’ oraz ’u’. Zjawisko<br />
to zwi ˛azane jest ze skróceniem traktu głosowego u osób laryngektomowanych. Sprawia, i˙z w<br />
celu rozpoznawania samogłosek nale˙zy zastosować inne parametry klasyfikacji w zale˙zno´sci<br />
od rodzaju mowy, naturalnej lub przełykowej. Ni˙zsza rozpoznawalno´sć mowy zast˛epczej<br />
zwi ˛azana jest przede wszystkim z przesuni˛eciem cz˛estotliwo´sci formantowych. Wpływa te˙z<br />
na ni ˛a wi˛eksza nieregularno´sć, zniekształcenia oraz wi˛eksze szumy wyst˛epuj ˛ace w mowie<br />
bezkrtaniowców. Do systemu rozpoznawania mowy laryngektomowanych nale˙zy zastosować<br />
sieć neuronow ˛a nauczon ˛a na podstawie zbioru składaj ˛acego si˛e z próbek dla tego samego<br />
rodzaju mowy.<br />
Zaobserwowano ni˙zsz ˛a ´sredni ˛a cz˛estotliwo´sć podstawow ˛a F 0, ni˙z podawana w literaturze.<br />
Mimo, i˙z pomi˛edzy poszczególnymi pracami istniej ˛a zasadnicze ró˙znice, nie mo˙zna odrzucić<br />
mo˙zliwo´sci, ˙ze na wyniki wpływa zastosowanie własnej wersji algorytmu opartego na analizie<br />
macierzy kowariancji opisanego w rozdziale 3.1.2.<br />
Zostało stwierdzone, i˙z formanty samogłosek izolowanych w pseudoszepcie<br />
ustno-gardłowym s ˛a trudne do wykrycia ze wzgl˛edu na maskuj ˛acy efekt odgłosów oddychania<br />
w postaci szumów z otworu tracheotomijnego. Zaobserwowano wy˙zsz ˛a skuteczno´sć<br />
rozpoznawania samogłosek wyst˛epuj ˛acych w sylabach z poprzedzaj ˛acymi spółgłoskami.<br />
Niestety nie zebrano wystarczaj ˛acej liczby próbek, aby było mo˙zliwe porównanie statystyczne<br />
pseudoszeptu z mow ˛a naturaln ˛a lub przełykow ˛a.<br />
Zadaniem eksperymentu było zbadanie w jakim stopniu patologia narz ˛adu głosowego<br />
wpływa na ekspresj˛e mowy. W pracy potwierdzono tez˛e o niezmienno´sci ekspresji twarzy<br />
bezkrtaniowców ze wzgl˛edu na rodzaj mowy. Za pomoc ˛a sieci neuronowej klasyfikuj ˛acej<br />
grupy samogłosek ze wzgl˛edu na parametry wideo otrzymano zbli˙zone wyniki skuteczno´sci<br />
26
ozpoznawania dla obu grup pacjentów. Ró˙znica pomi˛edzy skuteczno´sci ˛a rozpoznawania<br />
w grupie posługuj ˛acej si˛e pseudoszeptem a mow ˛a przełykow ˛a wyniosła 2%. Parametry<br />
wideo uzupełniaj ˛a informacje akustyczn ˛a. Niweluj ˛a wpływ niedoskonało´sci pseudoszeptu.<br />
Zwi˛ekszaj ˛a skuteczno´sć rozpoznawania pseudoszeptu. Zaprezentowane wyniki badań ukazuj ˛a<br />
skuteczno´sć analizy ekspresji twarzy przy rozpoznawaniu samogłosek w pseudoszepcie<br />
ustno-gardłowym. Prezentowane metody mog ˛a być przydatne w poprawie zrozumiało´sci<br />
pseudoszeptu.<br />
Na podstawie informacji z obrazu wideo na temat otwarcia ust nie udało si˛e ustalić<br />
przekroju traktu głosowego na jego pocz ˛atku. Nie została potwierdzona bezpo´srednia zale˙zno´sć<br />
mi˛edzy współczynnikami akustycznymi a parametrami wideo. Na aktualnym etapie badań nie<br />
zostało wyeliminowane z modelu zało˙zenie o jednakowym, ostatnim przekroju poprzecznym<br />
u wszystkich osób. Zało˙zenie to wprowadza do modelu znaczny bł ˛ad.<br />
Warto wspomnieć, i˙z w przypadku rozpoznawania j˛ezyka polskiego badania znajduj ˛a si˛e<br />
na etapie pocz ˛atkowym [14]. W pracy wykorzystano bardzo obszerny materiał badawczy<br />
nagrań audio-wideo głosu osób laryngektomowanych. Dotychczas nie pojawiła si˛e praca<br />
badaj ˛aca tak du˙z ˛a grup˛e polskich pacjentów ze wzgl˛edu na parametry akustyczne mowy<br />
zwi ˛azane z ekspresj ˛a twarzy. W systemie zaimplementowano własn ˛a metod˛e ´sledzenia<br />
elementów twarzy, która po dopracowaniu powinna konkurować z innymi rozwi ˛azaniami.<br />
Jedynie subiektywne, statystyczne analizy słuchowe mog ˛a stwierdzić przydatno´sć<br />
opracowanych metod w poprawie zrozumiało´sci mowy patologicznej. Najwa˙zniejszym<br />
kryterium oceny zrozumiało´sci mowy jest liczba słów rozpoznawana przez osoby słuchaj ˛ace<br />
wypowiedzi ludzi laryngektomowanych. Niestety w dotychczasowych badaniach nie<br />
uwzgl˛edniono subiektywnych ocen zrozumiało´sci mowy. Kolejnym krokiem, jaki nale˙załoby<br />
podj ˛ać w pracy jest zweryfikowanie zaproponowanych wska´zników zrozumiało´sci mowy<br />
za pomoc ˛a znormalizowanych testów, w których mowa rozpoznawana jest przez grup˛e<br />
osób słuchaj ˛acy lub ogl ˛adaj ˛acych materiał badawczy. Subiektywne pomiary zrozumiało´sci<br />
mowy z wykorzystaniem materiału audiowizualnego (mówi ˛acej twarzy) były ju˙z wcze´sniej<br />
wykonywane [2].
Bibliografia<br />
[1] C. B. Angermeier and B. Weinberg. Some Aspects of Fundamental Frequency Control Esophageal<br />
Speakers. Journal of Speech and Hearing Research, 46:85–91, 1981.<br />
[2] J. Beskow, K. Elenius, and S. MacGlashan. Olga - a dialogue system with an animated talking<br />
agent. In Proceedings of EUROSPEECH’97, Rhodes, Greece, 1997.<br />
[3] W. Borodziewicz and K. Jaszczak. Cyfrowe przetwarzanie sygnałów. WNT, Warszawa, 1987.<br />
[4] D.H. Brown, F.J.M. Hilgers, J.C. Irish, and A.J.M. Balm. Potlaryngectomy voice rehabilitation:<br />
state of the art at the millenium. World J. Surg., 27:824–831, 2003.<br />
[5] T. Cervera, J. L. Miralles, and J. González A. Acoustical analysis of spanish vowels produced<br />
by laryngectomized subjects. Journal of Speech, Language, and Hearing Research, 44:988–996,<br />
2001.<br />
[6] J. M. Christensen and B. Weinberg. Vowel duration characteristics of esphageal speech. Journal<br />
of Speech and Hearing Research, 19:678–689, 1976.<br />
[7] B. Dalton, R. Kaucic, and A. Blake. Automatic Speechreeding Using Dynamic Contours, volume<br />
150 of NATO ASI. Series F, Computer and systems sciences, pages 373–382. Springer-Verlag,<br />
Berlin Heidelberg, 1996.<br />
[8] G. Fant. The relationship between area functions and the acoustic signal. Phonetica, 37:55–86,<br />
1980.<br />
[9] J. L. Flanagan. Speech Analysis, Synthesis and Perception. Springer-Verlag, New York, 2 edition,<br />
1972.<br />
[10] S. Haykin. Adaptive filter theory. Prentice Hall, Inc., Upper Saddle River, 1991.<br />
[11] M. Hołejko-S. Rehabilitacja głosu i mowy bezkrtaniowców metod ˛a wokalistyczn ˛a. Master’s<br />
thesis, Akademia Medyczna, Warszawa, 1971. praca dyplomowa.<br />
[12] R. A. Kazi, V. M. N. Prasad, J. Kanagalingam, C. M. Nutting, P. Clarke, P. Rhys-Evans, and K. J.<br />
Harrington. Assesment of the formant frequencies in normal and laryngectomized individuals<br />
using linear predictive coding. Journal of Voice, 21(6):661–8., 2007.<br />
[13] W. Klein, R. Plomp, and W. Pols. Vowel spectra, vowel spacer, and vowel identification. Journal<br />
of Acoustical Society of America, 48(4):999–1009, 1970.<br />
[14] M. Kubanek. METODA ROZPOZNAWANIA AUDIO-WIDEO MOWY POLSKIEJ W OPARCIU O<br />
UKRYTE MODELE MARKOWA. PhD thesis, Cz˛estochowa, 2005.<br />
28
[15] J. Luettin, N. A. Thacker, and S. W. Beet. Active Shape Models for Visual Speech Feature<br />
Extraction, volume 150 of NATO ASI. Series F, Computer and systems sciences, pages 383–390.<br />
Springer-Verlag, Berlin Heidelberg, 1996.<br />
[16] R. Myrick and R. Yantorno. Vocal tract modeling as related to the use of an artificial larynx.<br />
Bioengineering Conference, 1993., Proceedings of the 1993 IEEE Nineteenth Annual Northeast,<br />
pages 75–77, Mar 1993.<br />
[17] M. Nixon and A. Aguado. Feature Extraction & Image Processing. Newnes, Oxford, 2002.<br />
[18] W. Oktaba. Metody statystyki matematycznej w do´swiadczalnictwie. Państwowe Wydawnictwo<br />
Naukowe, Warszawa, 1980.<br />
[19] Panasonic. Service Manual, Digital Video Camcorder NV-DS65EGE. Matsushita Electric<br />
Industrial Co., Ltd., 2003.<br />
[20] M. Pence. Programming Microsoft DirectShow for Digital Video and Television. Microsoft<br />
Corporation, 2003.<br />
[21] R. Pietruch, M. Michalska, W. Konopka, and A. Grzanka. Methods for formant extraction<br />
in speech of patients after total laryngectomy. Biomedical Signal Processing and Control,<br />
1/2:107–112, 2006.<br />
[22] Rode. VideoMic Instruction Manual. Rode Microphones.<br />
[23] S. Saito. Speech Science and Technology. Ohmsha, Ltd., Tokyo, 1992.<br />
[24] M. Sisty and B. Weinberg. Formant frequency characteristics of esophageal speech. Journal of<br />
Speech and Hearing Research, 15:439–448, 1972.<br />
[25] R. Tadeusiewicz. Sygnał mowy. Wydawnictwa Komunikacji i Ł ˛aczno´sci, Warszawa, 1988.<br />
[26] H. Wakita. Normalization of vowels by vocal-tract length and its application to<br />
vowel identification. IEEE Transactions on Acoustics, Speech and Signal Processing,<br />
ASSP-25(2):183–192, April 1977.<br />
[27] Bernd Weinberg and Suzanne Bennett. Selected acoustic characteristics of esophageal speech<br />
produced by female laryngectomees. Journal of Speech and Hearing Research, 15:211–216,<br />
March 1972.<br />
[28] A. Zakrzewski, A. Pruszewicz, and H. Kubzdela. New articulation lists matched phonematically<br />
and structurally. Otolaryngol Pol., 25(3):297–306, 1971.<br />
[29] T. Zieliński. Od teorii do cyfrowego przetwarzania sygnałów. WEAIiE AGH, Kraków, 2002.<br />
29