modeliranje in simuliranje samopodobnega prometa v ...
modeliranje in simuliranje samopodobnega prometa v ...
modeliranje in simuliranje samopodobnega prometa v ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
FAKULTETA ZA ELEKTROTEHNIKO,<br />
RAČUNALNIŠTVO IN INFORMATIKO<br />
Matjaž Fras<br />
MODELIRANJE IN SIMULIRANJE<br />
SAMOPODOBNEGA PROMETA V<br />
TELEKOMUNIKACIJSKIH OMREŽJIH<br />
Magistrsko delo<br />
Maribor, oktober 2007
Magistrsko delo<br />
Avtor: Matjaž Fras<br />
Naslov: Modeliranje <strong>in</strong> <strong>simuliranje</strong> <strong>samopodobnega</strong> <strong>prometa</strong> v telekomunikacijskih omrežjih<br />
UDK: 621.391:004.7<br />
Gesla: omrežni promet, samopodobnost, Hurstov parameter, dolgo območje odvisnosti,<br />
porazdelitev verjetnosti<br />
Število izvodov: 5<br />
Število strani: 91
ZAHVALA<br />
Zahvaljujem se mentorju red. prof. dr.<br />
Žarku Čučeju za pomoč <strong>in</strong> vodenje pri<br />
opravljanju magistrske naloge ter somentorju<br />
doc. dr. Jožetu Mohorku za nasvete <strong>in</strong> pomoč<br />
pri delu.<br />
Zahvaljujem se tudi staršem za spodbude<br />
pri študiju.
VSEBINA<br />
I<br />
VSEBINA<br />
1. UVOD .................................................................................................................. 1<br />
1.1 Def<strong>in</strong>icije ....................................................................................................... 1<br />
1.2 Pregled stanja ................................................................................................ 2<br />
1.3 Cilji <strong>in</strong> vseb<strong>in</strong>a ............................................................................................... 3<br />
2. MERJENJE OMREŽNEGA PROMETA Z VOHLJAČEM ............................... 5<br />
3. ANALIZA OMREŽNEGA PROMETA .............................................................. 7<br />
3.1 Samopodobnost ............................................................................................. 7<br />
3.2 Lastnosti <strong>samopodobnega</strong> procesa ................................................................ 9<br />
3.2.1 Dolgo območje odvisnosti ..................................................................... 9<br />
3.2.2 Potrditev dolgega območja odvisnosti ................................................. 12<br />
3.2.3 Dolgo območje odvisnosti <strong>in</strong> samopodobnost ..................................... 14<br />
3.2.4 Šum 1/f ................................................................................................. 14<br />
3.2.5 Hurstov pojav ....................................................................................... 15<br />
3.2.6 Počasi padajoča varianca ..................................................................... 15<br />
3.3 Počasi pojemajoče porazdelitve .................................................................. 16<br />
3.3.1 Paretova porazdelitev ........................................................................... 17<br />
3.3.2 Statistične lastnosti Paretove porazdelitve ........................................... 18<br />
3.3.3 Weibullova porazdelitev ...................................................................... 19<br />
4. OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA .............. 21<br />
4.1 Določanje Hurstovega parametra ................................................................ 21<br />
4.1.1 Variančna metoda ................................................................................ 22<br />
4.1.2 R/S metoda ........................................................................................... 24<br />
4.1.3 Metoda periodograma .......................................................................... 25<br />
4.2 Določanje parametrov porazdelitev verjetnosti ........................................... 26<br />
5. DOLOČANJE OSNOVNIH PARAMETROV .................................................. 28<br />
5.1 Ocenjevanje Hurstovega parametra ............................................................. 29<br />
5.2 Določanje porazdelitev verjetnosti časa med paketi ................................... 34<br />
5.3 Določanje porazdelitev verjetnosti velikosti paketov.................................. 36<br />
5.3.1 Odvisnost srednje vrednosti <strong>prometa</strong> od parametra oblike .................. 37
II<br />
VSEBINA<br />
5.3.2 Ocenitev parametra oblike (α).............................................................. 38<br />
5.3.3 Predlog metode ocenjevanja porazdelitve verjetnosti velikosti<br />
paketov ................................................................................................. 38<br />
6. GENERIRANJE OMREŽNEGA PROMETA V OPNET-U ............................. 42<br />
6.1 Simulacijsko okolje OPNET ....................................................................... 42<br />
6.2 Modeliranje <strong>prometa</strong> v simulacijskem okolju OPNET ............................... 42<br />
6.2.1 Porazdelitve verjetnosti ........................................................................ 42<br />
6.2.2 Aplikacijski podatkovni model ............................................................ 43<br />
6.2.3 Generator golih paketov ....................................................................... 43<br />
6.2.4 Zunanja datoteka .................................................................................. 43<br />
6.3 Generator golih paketov .............................................................................. 44<br />
6.3.1 Fraktalni točkovni procesi .................................................................... 45<br />
6.3.2 Proces obnovljenih fraktalov ................................................................ 47<br />
6.4 IP postaja ..................................................................................................... 48<br />
6.5 Simulacije v OPNET-u ................................................................................ 48<br />
6.5.1 Vpliv parametra H na modelirani promet ............................................ 49<br />
6.5.2 Vpliv parametra časovne enote pojavljanja fraktalov na modeliran<br />
promet ................................................................................................... 51<br />
6.5.3 Modeliranje testnega signala 1 ............................................................. 52<br />
6.5.4 Modeliranje testnega signala 3 ............................................................. 56<br />
6.5.5 Primerjava izmerjenih <strong>in</strong> modeliranih signalov ................................... 59<br />
7. VPLIV SAMOPODOBNEGA PROMETA NA ZMOGLJIVOST OMREŽJA 63<br />
8. ZAKLJUČEK ..................................................................................................... 67<br />
LITERATURA ........................................................................................................... 69<br />
DODATEK A ............................................................................................................. 72<br />
DODATEK B ............................................................................................................. 75<br />
DODATEK C ............................................................................................................. 76<br />
ŽIVLJENJEPIS .......................................................................................................... 78
MODELIRANJE IN SIMULIRANJE SAMOPODOBNEGA PROMETA V TELEKOMUNIKACIJSKIH<br />
OMREŽJIH<br />
III<br />
MODELIRANJE IN SIMULIRANJE SAMOPODOBNEGA PROMETA V<br />
TELEKOMUNIKACIJSKIH OMREŽJIH<br />
UDK: 621.391:004.7<br />
Povzetek: V zadnjih desetih letih so bili razviti novi modeli omrežnega <strong>prometa</strong> v<br />
Internetnem okolju, ki se razlikujejo od tradicionalnih modelov, kot sta Poissonov <strong>in</strong><br />
Markov. Magistrsko delo opisuje ocenjevanje parametrov <strong>samopodobnega</strong> <strong>prometa</strong><br />
za <strong>modeliranje</strong> v OPNET-u. Promet v omrežju izmerimo s pomočjo namenske<br />
programske opreme za zajemanje <strong>prometa</strong>. S pomočjo analize izmerjenega <strong>prometa</strong><br />
ocenimo Hurstov parameter za čas med paketi s tremi različnimi metodami:<br />
variančno metodo, R/S metodo <strong>in</strong> metodo periodograma. Določimo še porazdelitve<br />
verjetnosti ter pripadajoče parametre porazdelitve za čas med paketi <strong>in</strong> velikost<br />
paketov. S pomočjo avtokorelacijske funkcije pripišemo prometu lastnost dolgega<br />
(LRD) ali kratkega območja odvisnosti (SRD). V simulacijskem okolju OPNET s<br />
pomočjo generatorja golih paketov (Raw Packet Generator – RPG) <strong>in</strong> IP postaje<br />
modeliramo izmerjene signale z različnimi verjetnostnimi porazdelitvami.<br />
Ključne besede: omrežni promet, samopodobnost, Hurstov parameter, dolgo<br />
območje odvisnosti, porazdelitev verjetnosti<br />
MODELING AND SIMULATION OF SELFSIMILAR TRAFFIC IN<br />
TELECOMMUNICATIONS NETWORKS<br />
UDK: 621.391:004.7<br />
Abstract: Over the last ten years, new models of network traffic <strong>in</strong> the Internet<br />
environment have been developed, which are different to traditional models such are<br />
Poisson and Markov. This Master of Science describes the estimat<strong>in</strong>g of measured<br />
self-similar traffic’s parameters for model<strong>in</strong>g <strong>in</strong> OPNET. Network traffic was<br />
captured us<strong>in</strong>g a sniffer. We estimated the Hurst parameter (H) for the arrival<br />
process with free different methods, and the fitted distributions for the measured data<br />
(packet size and <strong>in</strong>ter-arrival processes). Us<strong>in</strong>g the autocorrelation function of the<br />
process, we determ<strong>in</strong>ed long-range (SRD) or short-range dependence (LRD).<br />
F<strong>in</strong>ally, we modeled the measured test signal <strong>in</strong> OPNET us<strong>in</strong>g raw packet generator<br />
(RPG), and IP stations.<br />
Key words: network traffic, self-similarity, Hurst parameter, long-range dependence,<br />
probability distribution
IV<br />
MODELING AND SIMULATION OF SELF‐SIMILAR TRAFFIC IN TELECOMMUNICATIONS<br />
NETWORKS
UPORABLJENI SIMBOLI<br />
V<br />
UPORABLJENI SIMBOLI<br />
Samopodobnost <strong>in</strong> dolgo območje odvisnosti:<br />
X(t)<br />
X(k)<br />
E[X]<br />
t<br />
x<br />
H<br />
a<br />
σ 2<br />
γ(k)<br />
k<br />
r(k)<br />
r (m) (k)<br />
m<br />
X (m)<br />
var(X)<br />
b<br />
f<br />
λ k<br />
f(λ)<br />
S 2 (n)<br />
S(n)<br />
α<br />
X 0 … X N-1<br />
ˆ β<br />
Ĥ<br />
X () n<br />
S x<br />
zvezni stohastični proces<br />
diskretni stohastični proces<br />
srednja vrednost stohastičnega procesa<br />
čas<br />
naključna spremenljivka<br />
Hurstov parameter<br />
faktor razpona<br />
varianca<br />
kovariančna funkcija<br />
razmik (»lag«)<br />
avtokorelacijska funkcija<br />
avtokorelacijska funkcija agregiranega procesa<br />
velikost neprekrivajočega bloka<br />
agregiran proces<br />
varianca<br />
dolž<strong>in</strong>a časovnega zaporedja (»bucket«)<br />
frekvenca<br />
frekvenca v radianih (frekvenčni prostor)<br />
spektralna gostota<br />
varianca pri R/S metodi<br />
standardna deviacija pri R/S metodi<br />
pozitivni eksponent<br />
diskretno časovno zaporedje dolž<strong>in</strong>e N<br />
vrednost ocenjenega naklona asimptotične premice<br />
vrednost ocenjenega parametra H<br />
aritmetična srednja vrednost opazovanega zaporedja dolž<strong>in</strong>e n<br />
vzorčni prostor
VI<br />
UPORABLJENI SIMBOLI<br />
Porazdelitev verjetnosti:<br />
α<br />
k<br />
λ<br />
p(x)<br />
f(x)<br />
F(x)<br />
F ( x )<br />
Diff(x)<br />
F n (x)<br />
parameter oblike<br />
parameter lokacije<br />
parameter <strong>in</strong>tenzivnosti pri eksponentni porazdelitvi verjetnosti<br />
verjetnost<br />
porazdelitvena funkcija<br />
kumulativna porazdelitvena funkcija<br />
komplementarna kumulativna porazdelitvena funkcija<br />
porazdelitvena diferenca<br />
numerična porazdelitvena funkcija<br />
Fraktalni točkovni procesi:<br />
dN(t)<br />
T s<br />
F(T)<br />
S(f)<br />
α<br />
T 0<br />
f 0<br />
λ<br />
γ<br />
A<br />
M<br />
T<br />
točkovni proces<br />
trajanje <strong>in</strong>tervala<br />
<strong>in</strong>deks razpršenosti<br />
spektralna gostota moči<br />
fraktalni eksponent<br />
pozitivna časovna konstanta<br />
pozitivna frekvenčna konstanta<br />
povprečna <strong>in</strong>tenzivnost<br />
fraktalni eksponent<br />
parameter rezanja<br />
število izvorov<br />
časovna enota pojavljanja fraktalov<br />
Merske enote:<br />
b<br />
B<br />
p<br />
s<br />
bit<br />
Byte = 8 bitov = 1 zlog<br />
paket<br />
sekunda
UPORABLJENE KRATICE<br />
VII<br />
UPORABLJENE KRATICE<br />
AAR<br />
ACF<br />
CCDF<br />
CDF<br />
DFT<br />
ECDF<br />
FARIMA<br />
FMMP<br />
FOTS<br />
FPP<br />
FRP<br />
FSM<br />
FTP<br />
HTTP<br />
IP<br />
LAN<br />
LRD<br />
MTU<br />
P2MR<br />
PDF<br />
POP<br />
PSTN<br />
QoS<br />
R/S<br />
RPG<br />
SAR<br />
SRD<br />
SMTP<br />
TCP<br />
UDP<br />
WAN<br />
WWW<br />
Average Arrival Rate (povprečna hitrost prihodov)<br />
Autocorrelation Function (avtokorelacijska funkcija)<br />
Complementary Cumulative Distribution Function (komplementarna kumulativna<br />
porazdelitvena funkcija)<br />
Cumulative Distribution Function (kumulativna porazdelitvena funkcija)<br />
Discrete Fourier Transformation (diskretna Fourierova transformacija)<br />
Empirical Cumulative Distribution Function (empirična kumulativna<br />
porazdelitvena funkcija)<br />
Fractal Autoregressive Integrated Mov<strong>in</strong>g Average (fraktalno avtoregresivno<br />
pomično povprečje)<br />
Fractal Modulated Poisson Process (fraktalno moduliran Poissonov proces)<br />
Fractal Onset Time Scale (časovna enota pojavljanja fraktalov)<br />
Fractal Po<strong>in</strong>t Process (fraktalni točkovni proces)<br />
Fractal Renewal Processes (procesi obnavljanja fraktalov)<br />
F<strong>in</strong>ite State Mach<strong>in</strong>e (končni avtomat)<br />
File Transfer Protocol (protokol za prenos datotek)<br />
Hypertext Transfer Protocol (protokol za prenos hiperteksta)<br />
Internet Protocol (<strong>in</strong>ternetni protokol)<br />
Local Area Network (lokalno omrežje)<br />
Long Range Dependence (dolgo območje odvisnosti)<br />
Maximal Transmission Unit (največja prenosna enota)<br />
Peak to Mean Ratio (razmerje med nivojem konic <strong>in</strong> srednjo vrednostjo)<br />
Probability Density Function (porazdelitvena funkcija)<br />
Post Office Protocol (poštni protokol)<br />
Public Switched Telephone Network (javno komutirano telefonsko omrežje)<br />
Quality of Service (kakovost storitev)<br />
Rescaled Adjusted Range (prilagojena lestvica)<br />
Raw Packet Generator (generator golih paketov)<br />
Source Activity Ratio (razmerje aktivnosti izvorov)<br />
Short Range Dependence (kratko območje odvisnosti)<br />
Simple Mail Transfer Protocol (preprosti protokol za prenos pošte)<br />
Transmission Control Protocol (protokol za nadzor prenosa)<br />
User Datagram Protocol (uporabniški datagramski protokol)<br />
Wide Area Network (prostrano omrežje)<br />
World Wide Web (svetovni splet)
VIII<br />
UPORABLJENE KRATICE
UVOD<br />
1<br />
1. UVOD<br />
Priča smo nenehni <strong>in</strong> hitri rasti telekomunikacijskih omrežij, v katerih se večajo<br />
zahteve uporabnikov po novih aplikacijah <strong>in</strong> storitvah. Zahteve se nanašajo na vedno<br />
večje zmogljivosti omrežja. Zmogljivost telekomunikacijskega omrežja je zelo<br />
odvisna od zasnove ter uporabljene programske <strong>in</strong> strojne opreme. Merjenje,<br />
analiziranje, <strong>modeliranje</strong> <strong>in</strong> <strong>simuliranje</strong> omrežja so orodja, ki omogočajo načrtovanje<br />
ali nadgradnjo omrežij z optimalnimi zmogljivostmi.<br />
1.1 Def<strong>in</strong>icije<br />
Naloga načrtovalca telekomunikacijskega omrežja je zgraditi novo ali nadgraditi že<br />
obstoječe omrežje na podlagi zahtev naročnika (uporabnika omrežja), ki bo<br />
zadovoljilo vse potrebe naročnika, hkrati pa mora biti tudi ekonomično. Izgradnja ali<br />
nadgraditev omrežja poteka v naslednjih fazah:<br />
• merjenje,<br />
• analiziranje,<br />
• <strong>modeliranje</strong>,<br />
• <strong>simuliranje</strong>,<br />
• izgradnja omrežja.<br />
Merjenje je postopek, pri katerem skušamo natančno zajeti parametre<br />
telekomunikacijskega omrežja. Ti parametri so lahko parametri omrežnih naprav,<br />
parametri omrežnega <strong>prometa</strong>, aplikacije itd. Meritve lahko izvajamo le v realnem<br />
času, merilni rezultati veljajo le za čas merjenja, povrh pa za njih potrebujemo precej<br />
drago opremo. Možne so le v izgrajenih omrežjih, zato so neposredno uporabne le pri<br />
nadgradnji. Pri načrtovanju novih omrežij izvedene meritve lahko upoštevamo le kot<br />
izkušnjo, na njih pa lahko le potrdimo uspešnost načrtovanja, ko so izgrajena.<br />
Modeliranje je – običajno poenostavljeno – matematično opisovanje omrežja.<br />
Model podaja <strong>in</strong>formacije, potrebne za razumevanje delovanja omrežja, <strong>in</strong><br />
<strong>in</strong>formacije o odzivu omrežja na številne dejavnike. Pri izdelavi modela uporabimo<br />
parametre, ki smo jih dobili z meritvami <strong>in</strong> analizami obstoječih omrežij. Model<br />
mora upoštevati vsaj ključne parametre <strong>in</strong> lastnosti omrežja. Tako mora biti čim bolj<br />
podoben realnemu sistemu, hkrati pa ne sme zahtevati preveč procesne zmogljivosti.<br />
Pravilnost modela telekomunikacijskega omrežja je zelo pomembna, zato ga<br />
preverimo s primerjavo simuliranih <strong>in</strong> izmerjenih lastnosti omrežja. To primerjavo<br />
imenujemo validacija. Modeli so lahko determ<strong>in</strong>istični ali stohastični. Pri<br />
determ<strong>in</strong>ističnem modelu so vhodni <strong>in</strong> izhodni podatki določene vrednosti, pri<br />
stohastičnih modelih pa so vhodni ali izhodni parametri podani s spremenljivkami, ki<br />
jih določimo s statističnimi metodami.<br />
Simulacija je izvajanje algoritma delovanja sistema, ki ga določa model. Zanje<br />
uporabljamo različne programske pakete, ki jih imenujemo simulacijska orodja. S<br />
širjenjem računalniške tehnologije so postala nepogrešljiva orodja raziskovalnega<br />
dela na mnogih področjih znanosti, tudi na področju telekomunikacij. Simulacije<br />
delimo v dve skup<strong>in</strong>i glede na vrsto modela:
2 UVOD<br />
• analogne,<br />
• diskretne.<br />
Pri analognih simulacijah uporabljamo zvezne modele, ki jih opišemo z<br />
zveznimi funkcijami, na primer z navadnimi ali parcialnimi diferencialnimi<br />
enačbami. Danes tudi analogne modele simuliramo na digitalnih računalnikih.<br />
Uporabljamo jih v primerih, ko proučujemo vpliv povratne vezave (vpliv vhoda na<br />
izhod), prenosne funkcije pa so zvezne funkcije. Analogne simulacije najdemo na<br />
primer v vremenskih <strong>in</strong> letalskih simulatorjih.<br />
Diskretne simulacije oziroma diskretno dogodkovne simulacije so enostavnejše<br />
v primerjavi z analognimi, saj njihovo stanje opišemo z diskretnimi spremenljivkami<br />
stanj, kar pomeni, da stanja sistema nastopajo diskretno <strong>in</strong> ne zvezno kot v primeru<br />
zveznih simulacij. Torej se v simulaciji obravnavajo dogodki le takrat, ko se<br />
spremenijo lastnosti opazovanega procesa, kar pomeni, da lahko v zelo kratkem času<br />
simuliramo daljša časovna obdobja. V istem času se lahko pojavi več diskretnih<br />
dogodkov hkrati. Ker so enostavnejše, so tudi manj natančne, ampak še vedno dovolj<br />
natančne, da zagotovijo zadovoljive rezultate. Diskretne dogodkovne simulacije<br />
uporabljamo v telekomunikacijah <strong>in</strong> računalniških omrežjih, kosovni proizvodnji itd.<br />
[1], [2].<br />
Delitev simulacij je v nasprotju z delitvijo, ki jo uporabljamo pri teoriji<br />
diskretnih sistemov <strong>in</strong> signalov, kjer obravnavamo časovno diskretne <strong>in</strong> amplitudno<br />
diskretne signale, ki bi po prej opisani delitvi spadali v področje analognih simulacij.<br />
Merjenje, analiziranje, <strong>modeliranje</strong> <strong>in</strong> <strong>simuliranje</strong> so metode, ki nam podajajo<br />
osnovne <strong>in</strong>formacije o telekomunikacijskem omrežju. Omogočajo nam vpogled v<br />
omrežje ter s tem razumevanje omrežja, testiranje različnih situacij (zamašitve, ozka<br />
grla), testiranje različnih scenarijev (hipotez), preizkušanje <strong>in</strong> iskanje novih izvedb<br />
ali modelov telekomunikacijskega omrežja, naprav ali protokolov.<br />
Pomembno vlogo v omrežjih ima omrežni promet, ki ga lahko opišemo s<br />
pomočjo stohastičnih modelov. V takšnih modelih so prisotne spremenljivke, ki jih<br />
opisujemo s funkcijo verjetnosti. Pri tem posamezne vrednosti naključne<br />
spremenljivke nimajo nobenega pomena. Zato je za ocenitev prave vrednosti<br />
naključne spremenljivke potrebno poznati veliko število posameznih podatkov.<br />
Poznavanje omrežnega <strong>prometa</strong> ter samega vpliva na zmogljivost omrežja je<br />
izrednega pomena, zato je nujno znanje o modeliranju omrežnega <strong>prometa</strong> v<br />
simulacijah. V simulacijah je tako pomembno modelirati promet, ki bo najboljši<br />
približek izmerjenega <strong>prometa</strong> v smislu srednje vrednosti v bitih ali paketih na<br />
časovno enoto, nivoja konic ali variance. Za opis omrežnega <strong>prometa</strong> so bili razviti<br />
<strong>in</strong> se še vedno razvijajo različni modeli, ki so nam v pomoč pri modeliranju<br />
omrežnega <strong>prometa</strong>.<br />
1.2 Pregled stanja<br />
V zadnjih 15-ih letih je bilo opravljenega veliko dela na področju raziskovanja<br />
omrežnega <strong>prometa</strong>, na podlagi katerega je bil vpeljan nov opis, <strong>in</strong> sicer s pomočjo<br />
samopodobnosti <strong>in</strong> dolgega območja odvisnosti (Long Range Dependence – LRD).<br />
Pionirji na tem področju so Leland, Will<strong>in</strong>ger <strong>in</strong> drugi [3], ki so opis <strong>samopodobnega</strong><br />
omrežnega <strong>prometa</strong> podali leta 1994. Pojavilo se je raziskovanje izmerjenega<br />
omrežnega <strong>prometa</strong>, analiziranje <strong>prometa</strong> ter tudi <strong>simuliranje</strong> <strong>samopodobnega</strong><br />
<strong>prometa</strong> s pomočjo simulacijskih orodij.<br />
Statistične analize <strong>prometa</strong> v omrežjih ethernet [4] so pokazale, da lahko promet<br />
opišemo s pomočjo samopodobnosti, ki temelji na fraktalih. Nov opis se je pojavil
UVOD<br />
3<br />
kot alternativa tedanjim uporabljenim modelom, kot sta bila Poissonov <strong>in</strong> Markov<br />
[5]. Pri tem se je pokazalo, da so počasi pojemajoče porazdelitve (»heavy tailed<br />
distributions«) bolj primerne za opisovanje procesa rojevanja paketov, torej<br />
opisovanja časa med paketi. Sčasoma sta Paretova kot tudi Weibullova počasi<br />
pojemajoča porazdelitev postali glavni porazdelitvi verjetnosti za opisovanje<br />
naključnih procesov v omrežjih, tako časa med paketi kot tudi velikosti paketov [6],<br />
[7], [8], [9].<br />
Pojavil se je tudi drugačen odziv na raziskovanje samopodobnosti <strong>in</strong> dolgega<br />
območja odvisnosti, <strong>in</strong> sicer z oceno Hurstovega parametra, ki predstavlja merilo<br />
samopodobnosti [6], [10], [11]. Razvitih je bilo veliko različnih metod ocenitve tega<br />
parametra, katerih rezultati so velikokrat različni ali si celo nasprotujejo [12], [13].<br />
V zadnjem desetletju je bilo opravljenih veliko analiz izmerjenega <strong>prometa</strong> v<br />
različnih omrežjih različnih tehnologij, s katerimi so raziskovalci ugotovili, da lahko<br />
omrežni promet najuč<strong>in</strong>koviteje opišejo z lastnostjo samopodobnosti <strong>in</strong> dolgega<br />
območja odvisnosti [14], [15], [16], [17], [18]. Raziskovalci so proučevali opis<br />
<strong>prometa</strong> različnih aplikacij <strong>in</strong> protokolov, kot je npr. WWW [9] <strong>in</strong> HTTP [19] ali<br />
promet videa [20] ter opis <strong>samopodobnega</strong> <strong>prometa</strong> v različnih omrežnih<br />
tehnologijah [21], [22], [23]. Merjenje, analiziranje <strong>in</strong> <strong>simuliranje</strong> <strong>samopodobnega</strong><br />
omrežnega <strong>prometa</strong> je bilo <strong>in</strong> še vedno ostaja eden glavnih raziskovalnih izzivov<br />
zadnjih let, saj je rdeča nit številnih raziskav po svetu.<br />
Eden pomembnih ciljev raziskovalcev je tudi <strong>modeliranje</strong> <strong>samopodobnega</strong><br />
<strong>prometa</strong> v simulacijskih okoljih, kot je simulacijsko okolje OPNET [11], [24], [25],<br />
[26]. Razvitih je bilo več modelov generiranja <strong>samopodobnega</strong> <strong>prometa</strong>, <strong>in</strong> sicer na<br />
podlagi fraktalno točkovnih modelov [27], [28], ki nam omogočajo <strong>modeliranje</strong><br />
takega <strong>prometa</strong> v simulacijskem okolju OPNET. Ta nam omogoča <strong>simuliranje</strong><br />
<strong>samopodobnega</strong> <strong>prometa</strong> v različnih topologijah omrežja, z različnimi napravami ter<br />
protokoli [26]. Ker je samopodoben promet specifičen, ima tudi takšen vpliv na<br />
zmogljivosti omrežja, kot na primer na zakasnitve, na čakalne vrste ter na<br />
zagotovitev kvalitete storitev. Vpliv <strong>samopodobnega</strong> <strong>prometa</strong> na zmogljivosti<br />
omrežja je bila tema številnih raziskovalnih del [7], [29], [30] <strong>in</strong> bo deležna velike<br />
pozornosti tudi v prihodnosti.<br />
1.3 Cilji <strong>in</strong> vseb<strong>in</strong>a<br />
Namen magistrske naloge je <strong>modeliranje</strong> <strong>in</strong> <strong>simuliranje</strong> izmerjenega <strong>samopodobnega</strong><br />
omrežnega <strong>prometa</strong> v simulacijskem okolju OPNET. V različnih naključnih omrežjih<br />
bomo izmerili realni omrežni promet <strong>in</strong> ga na osnovi opravljene analize klasificirali v<br />
smislu samopodobnosti. Z opravljeno analizo bomo z različnimi metodami ocenili<br />
statistične parametre (Hurstov parameter, porazdelitve verjetnosti <strong>in</strong> njene<br />
parametre), ki bodo služili za <strong>modeliranje</strong> izmerjenega <strong>prometa</strong> v simulacijskem<br />
okolju OPNET. Uspešnost modeliranja izmerjenega <strong>prometa</strong> bomo ocenili s<br />
primerjavo izmerjenega <strong>in</strong> modeliranega <strong>prometa</strong> z merili, kot so npr. srednja<br />
vrednost <strong>prometa</strong> v bitih <strong>in</strong> paketih na časovno enoto. Na koncu bomo skušali<br />
pokazati, zakaj je pomembno v simulacijah omrežja modelirati promet, ki bo dober<br />
približek izmerjenega <strong>prometa</strong>.<br />
Drugo poglavje predstavlja merjenje omrežnega <strong>prometa</strong> z namensko<br />
programsko opremo, ki jo popularno imenujemo vohljač. Predstavlja orodje, s<br />
katerim zajamemo omrežni promet (velikost paketov, čas prihoda, IP naslove…) na<br />
podlagi katerega bomo opravili analizo <strong>prometa</strong>.
4 UVOD<br />
Analizo stohastičnih procesov podaja tretje poglavje s pomočjo matematičnih<br />
orodij, kot sta statistika <strong>in</strong> verjetnost. Sledijo def<strong>in</strong>icije osnovnih pojmov, kot so<br />
samopodobnost, dolgo območje odvisnosti ter opis <strong>in</strong> potrditev njihovih lastnosti.<br />
Temu sledi še kratek pregled eksponentne <strong>in</strong> počasi pojemajočih porazdelitev<br />
(Paretova <strong>in</strong> Weibullova porazdelitev).<br />
Četrto poglavje opisuje pregled različnih metod za ocenjevanje parametrov<br />
stohastičnih procesov. Opisali bomo metode za ocenjevanje Hurstovega parametra<br />
ter nato še metodo za določanje porazdelitve verjetnosti <strong>in</strong> njenih parametrov na<br />
osnovi histograma. Natančneje bomo opisali tri metode za ocenjevanje Hurstovega<br />
parametra, <strong>in</strong> sicer variančno <strong>in</strong> R/S metodo ter metodo periodograma.<br />
Ocenitev osnovnih parametrov s pomočjo vohljača izmerjenega <strong>prometa</strong> v<br />
omrežju, z različnimi metodami, predstavlja peto poglavje. Predstavili smo tri testne<br />
signale, ki smo jih skušali modelirati v simulacijskem okolju na podlagi ocenjenih<br />
parametrov. Predstavljene so metode ocenitve Hurstovega parametra <strong>in</strong> določitve<br />
avtokorelacijske funkcije, ki nam služi kot analiza dolgega območja odvisnosti,<br />
katero potrdimo z metodo »bucket shuffl<strong>in</strong>g«. Analizo rezultatov opravimo tako za<br />
proces prihodov paketov kot za velikost paketov. Pri določanju porazdelitve velikosti<br />
paketov smo zaradi maksimalne dolž<strong>in</strong>e paketov predlagali novo metodo, s katero<br />
smo lahko natančneje določili parametre izbrane porazdelitve verjetnosti.<br />
V šestem poglavju podajamo kratek opis simulacijskega orodja OPNET, njegove<br />
delovne postaje <strong>in</strong> rezultate simulacij. Izmerjen promet smo modelirali na dva nač<strong>in</strong>a<br />
s pomočjo dveh različnih postaj iz knjižnice simulacijskega orodja. Ti dve postaji sta<br />
generator paketov (Raw Packet Generator – RPG) <strong>in</strong> IP postaja. Pri modeliranju<br />
<strong>prometa</strong> z RPG postajo smo velikost paketov opisali s porazdelitvijo verjetnosti,<br />
proces prihodov paketov (število paketov na časovno enoto) pa s pomočjo<br />
Hurstovega parametra. Pri modeliranju z IP postajo smo tako velikost kot čas med<br />
paketi opisali s pomočjo porazdelitve verjetnosti. Pri vseh simulacijah smo uporabili<br />
tako eksponentne kot počasi pojemajoče porazdelitve.<br />
Sedmo poglavje predstavlja vpliv <strong>samopodobnega</strong> <strong>prometa</strong> na zmogljivost<br />
omrežja, kar je tudi vzrok za potrebe po natančnem <strong>in</strong> pravilnem modeliranju<br />
omrežnega <strong>prometa</strong>. Modeliran promet v tem poglavju temelji na pridobljenem<br />
znanju celotnega raziskovalnega dela.<br />
Sledi še komentar rezultatov <strong>in</strong> ugotovitve, pridobljene skozi celotno<br />
raziskovalno delo.
MERJENJE OMREŽNEGA PROMETA Z VOHLJAČEM<br />
5<br />
2. MERJENJE OMREŽNEGA PROMETA Z VOHLJAČEM<br />
Merjenje <strong>in</strong> zajemanje omrežnega <strong>prometa</strong> nam podajata <strong>in</strong>formacije o dogajanju v<br />
telekomunikacijskem ali računalniškem omrežju. Izmerjen promet lahko<br />
ovrednotimo na podlagi opravljene analize s pomočjo matematičnih orodij.<br />
Matematična orodja, primerna za analizo <strong>in</strong> <strong>modeliranje</strong> omrežnega <strong>prometa</strong>,<br />
izhajajo predvsem iz verjetnosti <strong>in</strong> statistike. Z analizo omrežnega <strong>prometa</strong> skušamo<br />
dobiti <strong>in</strong>formacije o stanju omrežja, ki jih uporabimo za izboljšanje omrežja <strong>in</strong> izrabo<br />
virov omrežja, gradnjo <strong>in</strong> razvoj novih omrežij <strong>in</strong> protokolov, zagotovitev kakovosti<br />
storitev v omrežjih…<br />
Promet v omrežjih merimo s posebnimi <strong>in</strong>strumenti – analizatorji, v<br />
računalniških omrežjih pa lahko promet merimo tudi s pomočjo posebnih programov,<br />
ki jih imenujemo vohljači. V nalogi smo se osredotočili na merjenje omrežnega<br />
<strong>prometa</strong> s slednjimi.<br />
Vohljači so namenska programska orodja, ki jih uporabljamo za analiziranje<br />
omrežnega <strong>prometa</strong> <strong>in</strong> protokolov ter za razvoj le-teh. Uporabljamo jih tudi za<br />
odkrivanje <strong>in</strong> odpravo pomanjkljivosti v omrežjih. Vohljači zajemajo dejanski<br />
omrežni promet tako, da postavijo omrežno kartico v promiskuitetni nač<strong>in</strong> delovanja.<br />
V tem nač<strong>in</strong>u delovanja vohljač sprejme vse pakete v omrežju, torej tudi tiste, ki niso<br />
naslovljeni nanj. Vohljači so zelo priljubljeno <strong>in</strong> nepogrešljivo orodje vsakega<br />
hekerja. Z njimi je mogoče spremljati celotni omrežni promet v omrežju. Poznamo<br />
več vrst vohljačev, ki so prosto dostopni na svetovnem spletu. Nekaj najbolj znanih<br />
vohljačev:<br />
• Ethereal,<br />
• Wireshark,<br />
• dSniff,<br />
• Ettercap,<br />
• AiroPeek.<br />
Wireshark [31], [32] je eden izmed najpreprostejših, najpreglednejših <strong>in</strong> najbolj<br />
priljubljenih prosto dosegljivih vohljačev na spletu. Je nadgradnja že obstoječega<br />
programskega paketa Ethereal, ki je dodan tudi k simulacijskemu paketu OPNET<br />
(slika 2.1).<br />
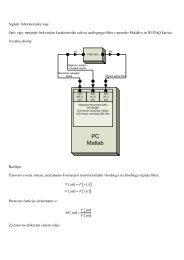
Vohljač Wireshark lahko deluje v operacijskem sistemu Microsoft W<strong>in</strong>dows,<br />
L<strong>in</strong>ux, Solaris… Omogoča sprotno spremljanje <strong>in</strong> pregledovanje <strong>prometa</strong> <strong>in</strong> zapis v<br />
velikem številu različnih datotečnih formatov (tcpdump , NAI's Sniffer,<br />
SnifferPro, NetXray…). Poleg tega zmore še nekaj dodatnih funkcij, kot so<br />
osnovne statistične analize, na primer povprečna vrednost <strong>prometa</strong> <strong>in</strong> grafična<br />
predstavitev rezultatov (slika 2.2).
6 MERJENJE OMREŽNEGA PROMETA Z VOHLJAČEM<br />
Slika 2.1:<br />
Grafični vmesnik programskega paketa Wireshark, s katerim lahko spremljamo <strong>in</strong>/ali<br />
zajamemo omrežni promet.<br />
Slika 2.2:<br />
Grafični prikaz omrežnega <strong>prometa</strong>, ki smo ga zajeli s pomočjo vohljača.<br />
Potek omrežnega <strong>prometa</strong> (slika 2.2) si lahko predstavljamo kot signal, ki ga<br />
določata dva naključna procesa, <strong>in</strong> sicer (i) naključni proces velikosti paketov <strong>in</strong> (ii)<br />
naključni proces časa med paketi. Promet, ponazorjen s signalom, opišemo s<br />
statističnimi parametri, kot so srednja vrednost, razmerje med maksimalno <strong>in</strong> srednjo<br />
vrednostjo ali varianca.
ANALIZA OMREŽNEGA PROMETA<br />
7<br />
3. ANALIZA OMREŽNEGA PROMETA<br />
V podatkovnih omrežjih imamo opraviti z najrazličnejšimi omrežnimi napravami, ki<br />
vsebujejo najrazličnejše aplikacije. Te aplikacije med seboj izmenjujejo <strong>in</strong>formacije<br />
(podatke), kar ustvari omrežni promet znotraj omrežja. Analiziranje <strong>in</strong> <strong>modeliranje</strong><br />
omrežnega <strong>prometa</strong> v simulacijah postaja eden glavnih izzivov pri načrtovanju<br />
telekomunikacijskih omrežij <strong>in</strong> razvoju komunikacijskih omrežnih naprav. Iz<br />
analiziranja omrežnega <strong>prometa</strong> so se razvila matematična orodja <strong>in</strong> modeli, s<br />
katerimi skušamo opisovati omrežni promet tako v lokalnih (LAN) kot tudi v<br />
prostranih omrežjih (WAN). Ker si lahko izvore <strong>prometa</strong> v omrežju predstavljamo<br />
kot naključne procese, moramo poznati orodja, s katerimi lahko ovrednotimo<br />
naključne procese.<br />
Pri analizi omrežnega <strong>prometa</strong> v več<strong>in</strong>i primerov ugotovimo, da je promet<br />
podoben v daljših (ure, m<strong>in</strong>ute) <strong>in</strong> krajših časovnih obdobjih (sekunde, milisekunde).<br />
Zaradi teh lastnosti označujemo takšen promet kot samopodoben.<br />
3.1 Samopodobnost<br />
V 90. letih prejšnjega stoletja so začeli razvijati nove modele omrežnega <strong>prometa</strong>, ki<br />
so pričeli izpodrivati uporabo naključnih procesov, kot sta Poissonov <strong>in</strong> Markov.<br />
Poissonov model je dobra aproksimacija telefonskih klicev v PSTN omrežjih. Čase<br />
med klici <strong>in</strong> dolž<strong>in</strong>o klicev dobro opiše eksponentna porazdelitev verjetnosti.<br />
Dodaten razlog za široko uporabo Poissonovega modela je tudi analitična rešljivost,<br />
za razliko od mnogih ostalih modelov, pri katerih potrebujemo numerično računanje<br />
<strong>in</strong> aproksimacije. Model določa le parameter λ, to je število dogodkov na časovno<br />
enoto (dogodki/sekundo).<br />
Def<strong>in</strong>iranje samopodobnosti <strong>prometa</strong> izpodriva Poissonov model iz modeliranja<br />
omrežnega <strong>prometa</strong>, ker ni bil ustrezen za natančen opis izbruhov v realnem<br />
prometu. Na široki časovni skali so se pojavljale konice, ki so se izkazale za<br />
škodljive. To je zelo pomembno v primerih multimedijskih aplikacij, pri katerih<br />
skušamo zagotoviti kakovost storitev (QoS). Zaradi tega so se razvili novi modeli, ki<br />
so bili sposobni napovedati realnejše zakasnitve <strong>in</strong> izgube paketov.<br />
Samopodobnost (»self-similarity«) lahko na preprost nač<strong>in</strong> opišemo z naslednjo<br />
splošno def<strong>in</strong>icijo [15], [16], [21]:<br />
Def<strong>in</strong>icija 1: (Samopodobnost – splošna def<strong>in</strong>icija)<br />
Naj bo X(t) stohastični proces z zveznim parametrom t; X = {X(t), t ∈ T}. X(t)<br />
imenujemo samopodobni proces s parametrom H za vrednosti med 0 <strong>in</strong> 1, če je za<br />
vsako pozitivno vrednost faktorja razpona a skaliran proces s časovnim merilom at<br />
enak a -H X(at). Potem ima skaliran proces enako porazdelitev kot orig<strong>in</strong>alni proces<br />
X(t).<br />
□<br />
−H<br />
X() t = a X( at), ∀t∈T, ∀ a > 0, 0≤ H < 1<br />
(3.1)
8 ANALIZA OMREŽNEGA PROMETA<br />
To pomeni, da če imamo časovno zaporedje točk t 1 , t 2 , …, t k <strong>in</strong> pozitivno konstanto<br />
a, ima proces a -H (X at1 , X at2 , …, X atk ) enako verjetnostno porazdelitev kot orig<strong>in</strong>alni<br />
proces (X t1 , X t2 , …, X tk ). Pomeni, da je opazovani vzorec samopodoben ne glede na<br />
skalo opazovanja. V bistvu se v realizacijah vzorec ne ponavlja povsem, ampak daje<br />
opazovalcu le takšen vtis. Merilo samopodobnosti je parameter H, ki ga imenujemo<br />
Hurstov parameter.<br />
Kadar proces X(t) zadovolji enačbo 3.1, ne more biti nikoli stacionarni, ampak<br />
dopušča stacionarne prirastke. Naslednja def<strong>in</strong>icija samopodobnosti, ki vsebuje<br />
stacionarno zaporedje, je namenjena standardnim časovnim zaporedjem [6], [10],<br />
[15], [21], [33].<br />
Def<strong>in</strong>icija 2: (Samopodobnost časovnega zaporedja)<br />
Naj bo X = (X t , t = 0, 1, 2, …) kovariančno stacionarni stohastični proces s<br />
stacionarno srednjo vrednostjo µ = E[X t ], končno varianco σ 2 = E[(X t – µ) 2 ],<br />
avtokovariančno funkcijo γ(k) = E[(X t – µ)(X t+k – µ)], ki je odvisna le od vrednosti k,<br />
<strong>in</strong> avtokorelacijsko funkcijo r(k) [6], [15], [16]:<br />
[( −μ)( −μ)<br />
]<br />
γ ( k ) E Xt Xt+<br />
k<br />
rk ( ) = = , k=<br />
0,1,2, K<br />
2 2<br />
σ E ⎡<br />
⎣( Xt<br />
− μ ) ⎤<br />
⎦<br />
(3.2)<br />
Potem se avtokorelacijska funkcija asimptotično približuje<br />
− β<br />
rk ( ) ≈ k L( k), k→ ∞ , 0< β < 1,<br />
1<br />
(3.3)<br />
kjer je L 1 (k) počasi se sprem<strong>in</strong>jajoča funkcija v neskončnosti <strong>in</strong> za katero velja<br />
lim = L ( tx) / L ( t) = 1 pri vseh x > 0 (npr. L 1 (t) = konstanta, L 1 (t) = log(t)). Če<br />
t→∞<br />
1 1<br />
časovno zaporedje izpolnjuje pogoj v enačbi 3.3, potem takšno časovno zaporedje<br />
opisujemo kot samopodobno časovno zaporedje.<br />
□<br />
Merilo samopodobnosti predstavlja Hurstov parameter, katerega določimo iz<br />
parametra β <strong>in</strong> sicer:<br />
β<br />
H = 1 − , 0< β < 1<br />
(3.4)<br />
2<br />
Iz enačbe 3.4 sledi, da se v primeru <strong>samopodobnega</strong> časovnega zaporedja vrednost<br />
Hurstovega parametra giblje med vrednostjo 0,5 <strong>in</strong> 1.<br />
Def<strong>in</strong>icija 3: (Agregiran proces)<br />
Za vsak m = 1, 2, 3, … def<strong>in</strong>irajmo agregiran proces X (m) = (X k (m) , k = 1, 2, …, m), ki<br />
ga dobimo iz stacionarnega procesa X s pomočjo povprečenja neprekrivajočih blokov<br />
velikosti m. Za vsak m = 1, 2, 3, … je X k<br />
(m)<br />
podan z:<br />
( m)<br />
1<br />
Xk = ( Xkm− m+<br />
1<br />
+ ... + Xkm<br />
), k = 1,2,3, ...<br />
(3.5)<br />
m<br />
□<br />
Def<strong>in</strong>irajmo še pojma striktno <strong>in</strong> asimptotično samopodoben proces drugega reda<br />
[10], [15]:
ANALIZA OMREŽNEGA PROMETA<br />
9<br />
Def<strong>in</strong>icija 4: (Samopodoben proces drugega reda)<br />
Proces X imenujemo striktno samopodoben proces drugega reda s parametrom<br />
samopodobnosti H = 1 – β/2, če imajo ustrezni agregirani procesi X (m) enako<br />
korelacijsko strukturo kot X <strong>in</strong> var( X ( m)<br />
) = σ 2 m<br />
−β za vse vrednosti m = 1, 2, … :<br />
( m<br />
r ) ( k) = r( k),<br />
za vse m= 1, 2, ... k = 1, 2, ... (3.6)<br />
Proces X imenujemo asimptotično samopodoben proces drugega reda s parametrom<br />
samopodobnosti H = 1 – β/2, če za dovolj velike vrednosti k velja:<br />
( m<br />
r ) ( k) →r( k),<br />
m→∞ (3.7)<br />
□<br />
Iz def<strong>in</strong>icije 4 sledi, da je proces X samopodoben proces drugega reda v striktnem ali<br />
asimptotičnem pomenu, če so pripadajoči agregirani procesi X (m) enaki procesu X ali<br />
pa postanejo od njega nerazločljivi v smislu avtokorelacijske funkcije. Najbolj<br />
striktna značilnost <strong>samopodobnega</strong> procesa, tako striktnega kot asimptotičnega je, da<br />
imajo agregirani procesi X (m) neizrojeno korelacijsko strukturo, ko gre m → ∞. To je<br />
v nasprotju s Poissonovim stohastičnim modelom, kjer njegov agregiran proces X (m)<br />
teži k šumu drugega reda pri m → ∞:<br />
( m<br />
r ) ( k) →0, m→∞ , k = 0,1, 2,...<br />
(3.8)<br />
Promet z izbruhi je samopodoben, če so značilne konice izbruhov <strong>prometa</strong> vidne na<br />
vseh ali vsaj več<strong>in</strong>i časovnih skal opazovanja <strong>prometa</strong>. V tem se samopodobni model<br />
razlikuje od Poissonovega ali Markovega, ki sicer lahko prikažeta izbruhe v prometu,<br />
vendar se ti s povprečenjem v dovolj dolgem časovnem <strong>in</strong>tervalu zgladijo. Razliko<br />
med samopodobnim prometom <strong>in</strong> prometom, generiranim s Poissonovim modelom,<br />
prikazuje slika 3.1.<br />
3.2 Lastnosti <strong>samopodobnega</strong> procesa<br />
Samopodobnost lahko preverimo na več različnih nač<strong>in</strong>ov, <strong>in</strong> sicer s pomočjo<br />
dolgega območja odvisnosti (Long Range Dependence – LRD), šumom 1/f,<br />
Hurstovim pojavom <strong>in</strong> s počasi padajočo varianco [15].<br />
3.2.1 Dolgo območje odvisnosti<br />
Model samopodobnosti je uč<strong>in</strong>kovit model za predstavitev omrežnega <strong>prometa</strong> v<br />
današnjih telekomunikacijskih <strong>in</strong> računalniških omrežjih. Samopodobnost lahko<br />
vsebuje lastnost dolgega območja odvisnosti, pri katerem je vrednost novega stanja<br />
zelo močno odvisna od prejšnjih stanj, kar pomeni, da imamo opravka s tako<br />
imenovanim spom<strong>in</strong>skim efektom. V primeru procesa z lastnostjo dolgega območja<br />
odvisnosti imajo pretekla stanja značilen vpliv na sedanje stanje. Značilnost takega<br />
procesa je visok nivo spremenljivosti na različnih časovnih skalah. V primeru<br />
agregiranega procesa na dolgih časovnih skalah proces ne teži h glajenju.<br />
Def<strong>in</strong>irajmo stohastični proces, ki izpolnjuje relacijo (3.3), ter avtokorelacijsko<br />
funkcijo samopodobnosti drugega reda s predpisom r(k) = γ(k)/σ 2 . Za vrednosti<br />
0 < H < 1, H ≠ 0,5 velja<br />
−2H<br />
−2<br />
rk ( ) ≈ H(2H−1) k , r→ ∞ (3.9)
10 ANALIZA OMREŽNEGA PROMETA<br />
Slika 3.1:<br />
Primerjava <strong>samopodobnega</strong> <strong>prometa</strong> (levo) <strong>in</strong> s<strong>in</strong>tetičnega <strong>prometa</strong>, ki ga ustvari<br />
Poissonov model (desno) na različnih časovnih skalah (100, 10, 1, 0,1 <strong>in</strong> 0,01s).<br />
Samopodoben promet vsebuje izbruhe na vseh časovnih skalah za razliko od<br />
s<strong>in</strong>tetičnega <strong>prometa</strong>, generiranega s Poissonovim modelom, ki teži h glajenju na daljših<br />
časovnih skalah <strong>in</strong> vsebuje vedno manj izbruhov [3].
ANALIZA OMREŽNEGA PROMETA<br />
11<br />
Za vrednosti 0,5 < H < 1 se avtokorelacijska funkcija r(k) asimptotično obnaša kot<br />
ck -β za vrednosti 0 < β < 1, kjer je konstanta c > 0, β = 2 – 2H <strong>in</strong> velja<br />
∑ ∞<br />
k=<br />
−∞<br />
r ( k)<br />
= ∞<br />
(3.10)<br />
Avtokorelacijska funkcija pada počasi (hiperbolično), kar pomeni, da ni sumabilna.<br />
Proces, katerega avtokorelacijska funkcija r(k) pada hiperbolično <strong>in</strong> izpolnjuje pogoj<br />
3.9, označujemo kot stacionarni proces X(t) z dolgim območjem odvisnosti. Kadar<br />
ima avtokorelacijska funkcija r(k) procesa X(t) končno vsoto, potem govorimo o<br />
procesu s kratkim območjem odvisnosti. Eksponentno padanje avtokorelacijske<br />
funkcije<br />
k<br />
r( k)<br />
≈ ρ , k → ∞,<br />
0 < ρ < 1<br />
(3.11)<br />
povzroči, da ima avtokorelacijska funkcija končno vsoto<br />
∑ ∞<br />
k=<br />
−∞<br />
0 < r ( k)<br />
< ∞<br />
(3.12)<br />
Glavno vlogo pri takšnem opisu ima parameter H, ki predstavlja merilo<br />
samopodobnosti. Z izbiro velikosti parametra H lahko določimo naslednje predpise,<br />
ki poleg dolgega območja odvisnosti predpisujejo še kratko območje odvisnosti, <strong>in</strong><br />
sicer [6], [12], [15], [30]:<br />
• 0 < H < 0,5 →SRD – kratko območje odvisnosti,<br />
• 0,5 < H < 1 →LRD – dolgo območje odvisnosti.<br />
Primer modela z lastnostjo kratkega območja odvisnosti sta Poissonov <strong>in</strong> Markov<br />
model. Primer poteka avtokorelacijske funkcije procesa s kratkim <strong>in</strong> dolgim<br />
območjem odvisnosti prikazuje slika 3.2.<br />
Slika 3.2:<br />
Primerjava med avtokorelacijsko funkcijo procesa z lastnostjo kratkega območja<br />
odvisnosti (levo) <strong>in</strong> procesa z lastnostjo dolgega območja odvisnosti (desno) [34].<br />
Dolgo območje odvisnosti (LRD) procesa z lastnostjo samopodobnosti se kaže v<br />
procesih, pri katerih se vrednost parametra H nahaja v mejah med 0,5 <strong>in</strong> 1. Pri tem<br />
avtokorelacijska funkcija pada hiperbolično <strong>in</strong> ne eksponentno, kot se to zgodi pri<br />
procesih s kratkim območjem odvisnosti (SRD). Avtokorelacijska funkcija zato ni<br />
sumabilna.
12 ANALIZA OMREŽNEGA PROMETA<br />
3.2.2 Potrditev dolgega območja odvisnosti<br />
Analizo dolgega območja odvisnosti spremljata dva problema, <strong>in</strong> sicer zapleteno<br />
določanje dolgega območja odvisnosti ter pogosto vprašljiva identifikacija <strong>in</strong><br />
potrditev te lastnosti. Prevladujoč nač<strong>in</strong> določanja, tako kratkega kot dolgega<br />
območja odvisnosti, je s pomočjo vrednosti Hurstovega parametra. Glede na to, da ne<br />
obstaja točno določen nač<strong>in</strong> izračuna Hurstovega parametra, lahko le-tega ocenimo.<br />
Za ocenitev imamo na voljo več razvitih metod, ki nam podajajo odstopajoče<br />
ocenjene vrednosti parametra H. To še posebej velja za ocenjene vrednosti okoli<br />
vrednosti 0,5, ki predstavlja mejo med procesi z lastnostjo dolgega <strong>in</strong> kratkega<br />
območja odvisnosti. Thomas Karagianiss [12], [13] predlaga za potrditev dolgega<br />
območja odvisnosti metodo, imenovano »bucket shuffl<strong>in</strong>g«. Le-to bi lahko opisali<br />
kot mešanje zajetih podatkov. Avtor navedenih člankov predlaga to metodo kot test<br />
<strong>in</strong> validacijo dolgega območja odvisnosti. Metoda temelji na naključni zamenjavi<br />
določenih delov časovnega zaporedja, ki ga razdelimo na dele dolž<strong>in</strong>e b. Nato lahko<br />
izvedemo dva nač<strong>in</strong>a mešanja časovnega zaporedja:<br />
• eksterno mešanje,<br />
• <strong>in</strong>terno mešanje.<br />
Eksterno mešanje temelji na naključni zamenjavi delov časovnega zaporedja, pri<br />
katerem ostaja vseb<strong>in</strong>a vsakega dela zaporedja nedotaknjena. S tem dobimo novo<br />
naključno zaporedje, sestavljeno iz naključno razdeljenih delov časovnega zaporedja.<br />
Z naključno zamenjavo delov časovnega zaporedja z lastnostjo dolgega območja<br />
odvisnosti dosežemo, da avtokorelacijska funkcija izkazuje dolgo območje<br />
odvisnosti (hiperbolično upadanje) le znotraj dela časovnega zaporedja dolž<strong>in</strong>e b.<br />
Interno mešanje časovnega zaporedja dolž<strong>in</strong>e b temelji na naključni zamenjavi<br />
posameznih vzorcev časovnega zaporedja znotraj delov zaporedja, pri čemer<br />
zaporedje delov časovnega zaporedja ostaja enako. Kot rezultat <strong>in</strong>ternega mešanja<br />
deformiramo lastnost kratkega območja odvisnosti, ob tem pa ostane lastnost dolgega<br />
območja skoraj nespremenjena. Naključni proces ali naključno časovno zaporedje z<br />
dolgim območjem odvisnosti ne vpliva na avtokorelacijsko funkcijo z <strong>in</strong>ternim<br />
mešanjem. V tem primeru sta avtokorelacijska funkcija orig<strong>in</strong>alnega časovnega<br />
zaporedja <strong>in</strong> <strong>in</strong>terno zmešanega časovnega zaporedja podobni.<br />
Validacijo samopodobnosti s pomočjo robustne metode »bucket shuffl<strong>in</strong>g«<br />
opravimo za naključni proces ali časovno zaporedje s spodaj opisanim postopkom.<br />
Slika 3.3:<br />
Časovno diskretni naključni proces <strong>in</strong> pripadajoča avtokorelacijska funkcija, ki kaže na<br />
lastnost dolgega območja odvisnosti [13].<br />
Za naključni proces ali časovno zaporedje na sliki 3.3 določimo avtokorelacijsko<br />
funkcijo. Počasi hiperbolično padajoča avtokorelacijska funkcija <strong>in</strong> nedoločljiva
ANALIZA OMREŽNEGA PROMETA<br />
13<br />
vsota avtokorelacijske funkcije kažeta na lastnost dolgega območja odvisnosti.<br />
Vendar, kot smo že omenili, sam potek avtokorelacijake funkcije ni dovolj za<br />
potrditev dolgega območja odvisnosti.<br />
Za validacijo samopodobnosti naključnega procesa opravimo metodo »bucket<br />
shuffl<strong>in</strong>g«. Najprej izvedemo eksterno mešanje z velikostjo delov zaporedja, enako<br />
1. S tem dosežemo popolnoma naključno porazdelitev časovnega zaporedja, kar je<br />
razvidno iz avtokorelacijske funkcije, prikazane na sliki 3.4. Drugič opravimo<br />
eksterno mešanje delov časovnih zaporedij z določeno dolž<strong>in</strong>o b. V primeru dolgega<br />
območja odvisnosti časovnega zaporedja se pojavi avtokorelacijska funkcija, ki pada<br />
hiperbolično do vrednosti b. V primeru opazovanja nad vrednostjo b vrednost<br />
avtokorelacijske funkcije teži k vrednosti 0 (slika 3.4).<br />
Slika 3.4:<br />
Avtokorelacijska funkcija eksterno mešanega časovnega zaporedja z vrednostjo<br />
časovnega dela 1 (»bucket« = 1 - levo) <strong>in</strong> 50 (»bucket« = 50 - desno) [13].<br />
Na koncu izvedemo še <strong>in</strong>terno mešanje, torej naključno pomešamo časovno<br />
zaporedje znotraj razdeljenih delov. V primeru časovnega zaporedja z lastnostjo<br />
dolgega območja odvisnosti <strong>in</strong>terno mešanje ne bo vplivalo na obnašanje<br />
avtokorelacijske funkcije ali pa bo nanjo vplivalo v zelo majhni meri. Tako ima<br />
avtokorelacijska funkcija <strong>in</strong>terno mešanega časovnega zaporedja podobno obnašanje<br />
kot avtokorelcijska funkcija orig<strong>in</strong>alnega časovnega zaporedja. Avtokorelacijsko<br />
funkcijo <strong>in</strong>ternega naključnega mešanja z dolž<strong>in</strong>o delov časovnega zaporedja 50<br />
prikazuje slika 3.5.<br />
Slika 3.5:<br />
Avtokorelacijska funkcija <strong>in</strong>terno zmešanega časovnega zaporedja z dolž<strong>in</strong>o časovnega<br />
zaporedja 50 (»bucket« = 50) [13].
14 ANALIZA OMREŽNEGA PROMETA<br />
3.2.3 Dolgo območje odvisnosti <strong>in</strong> samopodobnost<br />
Poudariti moramo, da obstajajo procesi, ki so samopodobni, ampak ne izkazujejo<br />
lastnosti dolgega območja odvisnosti <strong>in</strong> obratno [15]. Kot primer lahko navedemo<br />
Brownovo gibanje z Gaussovim šumom, ki je tipičen primer <strong>samopodobnega</strong><br />
procesa, vendar ne vsebuje lastnosti dolgega območja odvisnosti. Zaporedja tipa<br />
FARIMA (Fractal Autoregressive Integrated Mov<strong>in</strong>g Average) imajo lastnost<br />
dolgega območja odvisnosti, ampak ne kažejo lastnosti samopodobnosti v smislu<br />
porazdelitve [6]. V primeru asimptotične samopodobnosti v širšem smislu s<br />
predpisom 0,5 < H < 1 v def<strong>in</strong>iciji samopodobnost vsebuje dolgo območje odvisnosti<br />
<strong>in</strong> obratno. Zaradi tega za samopodoben model <strong>prometa</strong> velikokrat uporabljamo tako<br />
izraz samopodobnost kot dolgo območje odvisnosti.<br />
3.2.4 Šum 1/f<br />
Šum 1/f predstavlja signal ali proces z močjo spektralne gostote, ki je proporcionalna<br />
1/f α , kjer f predstavlja frekvenco, α pa pozitivni eksponent, ponavadi v mejah med<br />
vrednostjo 0 <strong>in</strong> 2. Šum 1/f nam omogoča ocenitev Hurstovega parametra v<br />
frekvenčnem območju, <strong>in</strong> sicer s pomočjo periodograma [12], [15]. Spektralna<br />
gostota časovnega zaporedja predstavlja alternativno predstavitev odvisnosti med<br />
vrednostmi procesa v različnih časih. Naj bo X 0 , X 1 , …, X N-1 diskretno časovno<br />
zaporedje dolž<strong>in</strong>e N, ki opisuje obnašanje procesa na <strong>in</strong>tervalu dolž<strong>in</strong>e N – 1. Takšen<br />
<strong>in</strong>terval diskretnega časovnega zaporedja lahko predstavimo kot eno iteracijo<br />
neskončno ponovljivega vzorca, ki opisuje X v odvisnosti od časa. Takšen proces<br />
lahko transformiramo iz časovnega prostora v frekvenčni prostor s pomočjo<br />
diskretne Fourierove transformacije (DFT). Rezultat transformacije je dekompozicija<br />
X v uteženo vsoto trigonometričnih funkcij s frekvenco λ k = 2πk/N v radianih na<br />
merjen <strong>in</strong>terval, kjer je k = 0, 1, … [(N – 1)/2].<br />
Periodogram je grafična predstavitev Fourierove transformacije avtokorelacijske<br />
funkcije v frekvenčnem prostoru. Samopodobnost lahko pokažemo s pomočjo<br />
periodograma, ki omogoča izračun spektralne gostote signala z obnašanjem<br />
spektralne gostote blizu izvora. Proces X vsebuje lastnost samopodobnosti, če velja<br />
[15]:<br />
−<br />
f ( λ) ≈ λ γ L ( λ), λ → 0<br />
(3.13)<br />
kjer je 0 < γ < 1 <strong>in</strong> je funkcija L 2 (λ) počasi sprem<strong>in</strong>jajoča se v točki 0. Spektralno<br />
gostoto f(λ) izračunamo s pomočjo naslednje enačbe<br />
f<br />
2<br />
jkλ<br />
( λ ) = ∑r(<br />
k)<br />
e<br />
(3.14)<br />
k<br />
V primeru procesa z lastnostjo dolgega območja odvisnosti vrednost vsote<br />
avtokorelacijske funkcije teži k neskončnosti pri frekvenci 0.<br />
f(0) = ∑ r( k)<br />
=∞<br />
(3.15)<br />
V primeru kratkega območja odvisnosti (SRD) je v primeru približevanja frekvence<br />
k 0 (λ = 0) spektralna gostota pozitivna <strong>in</strong> končna.<br />
k
ANALIZA OMREŽNEGA PROMETA<br />
15<br />
3.2.5 Hurstov pojav<br />
Samopodobnost lahko <strong>in</strong>terpretiramo z empiričnim zakonom, ki ga imenujemo<br />
Hurstov zakon ali Hurstov pojav [15], [35]. Za opazovan proces (X k : k = 0, 1, 2, …,<br />
n) s srednjo vrednostjo <strong>in</strong> varianco S 2 (n) je prilagojena lestvica ali R/S statistika<br />
podana s:<br />
1<br />
Rn ( ) / Sn ( ) = [ max(0, W1, W2,..., Wn) − m<strong>in</strong>(0, W1, W2,..., Wn)<br />
] (3.16)<br />
Sn ( )<br />
Pri tem def<strong>in</strong>iramo:<br />
( )<br />
Wk<br />
= X1+ X2 + L + Xk<br />
− kX( n), k = 1, 2,..., n (3.17)<br />
Standardno deviacijo S(n) opazovanj X 1 , X 2 , …, X n def<strong>in</strong>iramo:<br />
Sn ( ) =<br />
n<br />
2<br />
∑ ( X<br />
k<br />
− X( n))<br />
(3.18)<br />
k = 0<br />
n<br />
Hurstov parameter predstavimo s prilagojeno lestvico:<br />
R / S _ statistika = R( n)/ S( n)<br />
Leta 1951 je Hurst odkril, da lahko veliko naravnih časovnih zaporedij asimptotično<br />
predstavimo z relacijo:<br />
⎡Rn<br />
( ) ⎤ H<br />
E⎢<br />
→ cn<br />
1<br />
, n →∞<br />
Sn ( )<br />
⎥<br />
(3.19)<br />
⎣ ⎦<br />
s tipično vrednostjo Hurstovega parametra 0,73 <strong>in</strong> pozitivno konstanto c 1 , ki je<br />
neodvisna od vrednosti n.<br />
Leta 1968 sta Mandelbrot <strong>in</strong> Van Ness dokazala, da<br />
⎡Rn<br />
( ) ⎤<br />
⎢ → →∞<br />
Sn ( )<br />
⎥<br />
⎣ ⎦<br />
0,5<br />
E c2n , n<br />
(3.20)<br />
s končno pozitivno konstanto c 2 , neodvisno od vrednosti n, zadošča zgornjemu<br />
predpisu, če opazovan proces X(k) izhaja iz procesa s kratkim območjem odvisnosti<br />
(Short Range Dependence – SRD). Razliko med zgornjima predpisoma Hursta <strong>in</strong><br />
Mandelbrot-Van Nessa označujemo kot Hurstov efekt ali Hurstov pojav, ki nam služi<br />
za testiranje samopodobnosti.<br />
3.2.6 Počasi padajoča varianca<br />
Lastnost <strong>samopodobnega</strong> <strong>prometa</strong> je počasi padajoča varianca. Varianca povprečne<br />
vrednosti poskusa upada počasneje, kot upadajo recipročne vrednosti:<br />
( )<br />
−<br />
var( X m<br />
β<br />
) ≈ c3m<br />
, m → ∞,<br />
0 < β < 1, c3<br />
> 0<br />
(3.21)
16 ANALIZA OMREŽNEGA PROMETA<br />
Pri tem dopustimo poenostavitve iz relacij (3.3) <strong>in</strong> (3.13), da sta funkciji L 1 <strong>in</strong> L 2<br />
počasi sprem<strong>in</strong>jajoči se oziroma asimptotični konstanti. Če avtokorelacijska funkcija<br />
agregiranega procesa X (m) izpolnjuje pogoj (3.3) ali v primeru spektralne gostote<br />
pogoj (3.13), potem varianca procesa var(X (m) ) za vrednosti m ≥ 1 zadovolji:<br />
( )<br />
−<br />
var( X m ) ≈ c4m<br />
β , m → ∞,<br />
c4<br />
> 0<br />
(3.22)<br />
kjer je c 4 pozitivna konstanta, neodvisna od vrednosti m, vrednost β se nahaja med 0<br />
<strong>in</strong> 1 ter je v razmerju s parametrom γ v pogoju (3.3) s predpisom β = 1 – γ.<br />
Stacionarni proces z agregiranim procesom X (m) , ki teži k šumu drugega reda,<br />
izpolnjuje naslednji pogoj<br />
var( X ) ≈ c m , m→∞ (3.23)<br />
( m) −1<br />
5<br />
kjer je c 5 pozitivna konstanta, neodvisna od vrednosti m.<br />
Lastnost počasi padajoče variance agregiranega procesa izkoriščamo za<br />
ocenjevanje Hurstovega parametra.<br />
3.3 Počasi pojemajoče porazdelitve<br />
Naključne procese opisujemo s porazdelitvami verjetnosti. Poleg že prej ugotovljenih<br />
lastnosti samopodobnosti <strong>in</strong> dolgega območja odvisnosti omrežnega <strong>prometa</strong> lahko<br />
procesa velikosti paketov <strong>in</strong> prihoda paketov opišemo tudi s pomočjo porazdelitev.<br />
Porazdelitve verjetnosti, ki omogočajo opis <strong>samopodobnega</strong> <strong>prometa</strong><br />
telekomunikacijskih omrežij, se imenujejo počasi pojemajoče porazdelitve. Pri<br />
počasi pojemajočih porazdelitvah vrednost upada hiperbolično, kar je v nasprotju s<br />
hitro pojemajočimi porazdelitvami, kot je to eksponentna porazdelitev, kjer<br />
porazdelitev upada eksponentno.<br />
Promet so dolgo časa opisovali z eksponentno porazdelitvijo, saj je ta dobro<br />
opisovala Poissonov proces. Poissonov proces je primeren za opisovanje<br />
telefonskega <strong>prometa</strong>, časa med posameznimi klici <strong>in</strong> dolž<strong>in</strong>e klicev. Ker Poissonov<br />
proces vsebuje lastnost kratkega območja odvisnosti, velja enako tudi za<br />
eksponentno porazdelitev, ki jo opisujemo z naslednjo porazdelitveno funkcijo:<br />
x<br />
1<br />
−<br />
p( x)<br />
= ⋅ e μ<br />
(3.24)<br />
μ<br />
Parameter 1/µ večkrat nadomestimo s parametrom λ, ki ga imenujemo parameter<br />
<strong>in</strong>tenzivnosti. Slika 3.6 prikazuje vpliv parametra λ na potek eksponentne gostote<br />
verjetnosti <strong>in</strong> pripadajoče kumulativne porazdelitvene funkcije.
ANALIZA OMREŽNEGA PROMETA<br />
17<br />
Slika 3.6:<br />
Eksponentna gostota verjetnosti <strong>in</strong> kumulativna porazdelitev z različnimi vrednostmi<br />
parametra λ [36].<br />
Počasi pojemajočo porazdelitev poznamo tudi pod imenom skalirno <strong>in</strong>variantna<br />
porazdelitev. Naključna spremenljivka X ima počasi pojemajočo porazdelitev<br />
verjetnosti, če je njena komplementarna kumulativna porazdelitvena funkcija enaka<br />
[6], [14], [42], [45]<br />
−α<br />
Fx () = PX ( > x) = 1 −Fx () ≈ cx , 0< α ≤ 2, c> 0 (3.25)<br />
kjer je α parameter oblike <strong>in</strong> c je pozitivna konstanta. Za počasi pojemajočo<br />
porazdelitev verjetnosti vrednost α znaša 0 < α ≤ 2 <strong>in</strong> ima za te vrednosti neskončno<br />
varianco. Za vrednosti 0 < α ≤ 1 ima počasi pojemajoča porazdelitev neomejeno<br />
srednjo vrednost. Zato nas s stališča modeliranja omrežnega <strong>prometa</strong> zanimajo le<br />
vrednosti parametra 1 < α < 2. Funkcijska odvisnost počasi pojemajoče porazdelitve<br />
je počasi padajoča hiperbola. To pomeni, da se izidi naključne spremenljivke s<br />
počasi pojemajočo porazdelitvijo verjetnosti sprem<strong>in</strong>jajo ekstremno. Torej obstaja<br />
zelo majhna verjetnost, ki pa ni zanemarljiva, da je izid poskusa zelo (ekstremno)<br />
'velik', saj je ob poskusu zelo velika verjetnost, da bo izid poskusa zelo 'majhen'. Med<br />
osnovni počasi pojemajoči porazdelitvi sodita Paretova <strong>in</strong> Weibullova porazdelitev.<br />
3.3.1 Paretova porazdelitev<br />
Paretova porazdelitev je najpreprostejša počasi pojemajoča porazdelitev verjetnosti,<br />
ki je dobila ime po italijanskem ekonomistu Vilfredu Paretu. Podamo jo z naslednjo<br />
gostoto verjetnosti:<br />
α −α−1<br />
px ( ) = αk ⋅x , k≤ x, α, k> 0<br />
(3.26)<br />
Parameter α imenujemo tudi parameter oblike (»shape«), parameter k imenujemo<br />
parameter lokacije (»local«). Slednji je najmanjša možna vrednost naključne<br />
spremenljivke x. Vpliv parametrov na gostoto verjetnosti <strong>in</strong> kumulativno<br />
porazdelitev prikazuje slika 3.7.
18 ANALIZA OMREŽNEGA PROMETA<br />
Slika 3.7:<br />
Paretova gostota verjetnosti <strong>in</strong> kumulativna porazdelitev z različnimi vrednostmi<br />
parametra oblike α pri konstantni vrednosti parametra lokacije k = 1 [37].<br />
Kumulativno porazdelitveno funkcijo Paretove porazdelitve zapišemo z naslednjo<br />
enačbo:<br />
⎛k<br />
⎞<br />
Fx () = PX ( ≤ x) = 1− ⎜ ⎟<br />
(3.27)<br />
⎝x<br />
⎠<br />
Inverzna kumulativna fukcija F -1 Paretove porazdelitve verjetnosti je def<strong>in</strong>irana pod<br />
pogojem, da je F kumulativna porazdelitev zvezne naključne spremenljivke <strong>in</strong> je<br />
striktno naraščajoča na <strong>in</strong>tervalu I z vrednostjo F = 0 na levi strani <strong>in</strong>tervala I <strong>in</strong> F = 1<br />
na desni strani <strong>in</strong>tervala I. Interval I je lahko neomejen. Za Paretovo porazdelitev je<br />
<strong>in</strong>verzna kumulativna porazdelitev enaka<br />
1<br />
F<br />
1<br />
k(1 x)<br />
α<br />
3.3.2 Statistične lastnosti Paretove porazdelitve<br />
α<br />
− = − (3.28)<br />
Matematično upanje E(X) ali srednja vrednost µ Paretove porazdelitve z gostoto<br />
verjetnosti p(x) izračunamo<br />
l<br />
l<br />
α −α−1<br />
( ) μ ( ) ( α )<br />
∫<br />
EX = = pxxdx= k ⋅ x xdx=<br />
k<br />
− α+<br />
1<br />
l<br />
α<br />
α ⎡ x ⎤ αk<br />
− α+ 1 − α+<br />
1<br />
= αk ⎢ ⎥ = ( l −k<br />
),<br />
⎣− α + 1⎦<br />
− α + 1<br />
k<br />
∫<br />
k<br />
(3.29)<br />
kjer sta parametra k <strong>in</strong> l spodnja <strong>in</strong> zgornja meja <strong>in</strong>tegrala (enačba 3.28). Če<br />
maksimum naključne spremenljivke X ni omejen (l je neskončen), izračunamo<br />
limito zgornjega izraza<br />
α<br />
⎧ αk<br />
αk<br />
− α+ 1 − α+<br />
1 ⎪ , α > 1<br />
EX ( ) = μ = lim ( l − k ) = ⎨α<br />
−1<br />
l→∞<br />
− α + 1<br />
⎪<br />
⎩ ∞, α ≤1<br />
(3.30)<br />
Za podan parameter oblike α > 1 <strong>in</strong> srednje vrednosti µ za neskončno porazdelitev<br />
lahko izračunamo parameter lokacije na naslednji nač<strong>in</strong>:
ANALIZA OMREŽNEGA PROMETA<br />
19<br />
μ( α −1)<br />
k = (3.31)<br />
α<br />
V primeru omejene porazdelitve z maksimalno vrednostjo l ni analitične rešitve za<br />
izračun vrednosti parametra k. Numerična metoda za določitev vrednosti k je iskanje<br />
ničle v naslednjem izrazu:<br />
α 1<br />
( ) 0<br />
1 l − α+<br />
k α<br />
− k − μ =<br />
(3.32)<br />
− α +<br />
Varianca Paretove porazdelitve je v primeru izbire parametra oblike α med<br />
vrednostma 0 <strong>in</strong> 2 neskončna.<br />
([ ]<br />
2<br />
)<br />
2<br />
Var( X ) = σ = E X − E( X ) =∞,<br />
0< α < 2 (3.33)<br />
Aritmetično sred<strong>in</strong>o za 10000 vzorcev Paretove porazdelitve naključne<br />
spremenljivke s srednjo vrednostjo 6 prikazuje slika 3.8.<br />
vrednost naključne<br />
spremenljivke<br />
5000<br />
4000<br />
3000<br />
2000<br />
1000<br />
0<br />
1<br />
101<br />
201<br />
301<br />
401<br />
501<br />
601<br />
701<br />
801<br />
901<br />
srednja vrednost<br />
90<br />
80<br />
70<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
0<br />
1<br />
85<br />
169<br />
253<br />
337<br />
421<br />
505<br />
589<br />
673<br />
757<br />
841<br />
925<br />
aritmetična sred<strong>in</strong>a<br />
pričakovana vrednost<br />
Slika 3.8:<br />
Naključni proces, opisan s Paretovo verjetnostno porazdelitvijo z α = 1,2 (parameter<br />
oblike) <strong>in</strong> k = 10 (parameter lokacije) s 1000 vzorčnimi točkami (levo) ter pripadajoča<br />
aritmetična sred<strong>in</strong>a <strong>in</strong> pričakovana vrednost naključnega procesa (desno).<br />
3.3.3 Weibullova porazdelitev<br />
Weibullovo porazdelitev imenujemo po Veloddi Weibullu <strong>in</strong> je poleg Paretove<br />
porazdelitve osnovna počasi pojemajoča porazdelitev verjetnosti. Weibullovo<br />
porazdelitev opisujemo z naslednjo porazdelitveno funkcijo.<br />
α −1<br />
α ⎛ x ⎞ −( x )<br />
k<br />
px ( ) = ⋅⎜<br />
⎟ ⋅e , x≥ 0, α, k><br />
0<br />
k ⎝k<br />
⎠<br />
(3.34)<br />
Parameter α imenujemo tudi parameter oblike. Parameter k imenujemo parameter<br />
lokacije. Vpliv parametrov na porazdelitev vidimo na sliki 3.9. Kumulativno<br />
porazdelitveno funkcijo Weibullove porazdelitve verjetnosti zapišemo z naslednjo<br />
enačbo:<br />
( x α<br />
− )<br />
k<br />
F( x) = P( X ≤ x) = 1 −e , x≥ 0, α, k > 0 (3.35)
20 ANALIZA OMREŽNEGA PROMETA<br />
Slika 3.9:<br />
Weibullova gostota verjetnosti <strong>in</strong> kumulativna porazdelitev za različne parametre<br />
oblike α <strong>in</strong> parametre lokacije k [38].
OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
21<br />
4. OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
Naključni proces statistično ovrednotimo s pomočjo Hurstovega parametra ali z<br />
določanjem porazdelitvene funkcije. Kot smo že omenili, je promet skupek dveh<br />
stohastičnih procesov, <strong>in</strong> sicer procesa velikosti paketov <strong>in</strong> procesa časa med prihodi<br />
paketov. Modeliranje izmerjenega <strong>prometa</strong> bomo izvedli na dva nač<strong>in</strong>a, <strong>in</strong> sicer<br />
bomo proces velikosti paketov opisali s pomočjo porazdelitev verjetnosti, medtem ko<br />
bomo naključni proces prihodov paketov opisali s parametrom samopodobnosti H ter<br />
čas med paketi s porazdelitvami verjetnosti. Najprej se bomo posvetili ocenjevanju<br />
Hurstovega parametra stohastičnega procesa.<br />
4.1 Določanje Hurstovega parametra<br />
Hurstovega parametra H kot merilo samopodobnosti ne moremo natančno izračunati,<br />
ampak ga lahko le ocenimo. Obstaja kar nekaj različnih metod, s katerimi dobimo<br />
ocene parametra H, ki med seboj bolj ali manj odstopajo. Pri tem nimamo kriterijev,<br />
ki bi določili, katera metoda nam daje najboljši rezultat.<br />
Metode za ocenjevanje Hurstovega parametra lahko v 'grobi' osnovi razdelimo<br />
na dve kategoriji, <strong>in</strong> sicer ocenjevanje v časovnem prostoru <strong>in</strong> ocenjevanje v<br />
frekvenčnem ali valčnem prostoru [12].<br />
Metode ocenjevanja v časovnem prostoru temeljijo na primerjavi orig<strong>in</strong>alnega<br />
procesa <strong>in</strong> povprečenega procesa z metodo agregacije:<br />
• variančna metoda (»variance method«) je grafična metoda, ki temelji na<br />
lastnosti počasi padajoče variance (poglavje 3.2.5), kjer v logaritemsko<br />
merilo rišemo varianco v odvisnosti od velikosti bloka m agregiranega<br />
procesa. V primeru samopodbnosti je naklon premice β večji kot –1 (H =<br />
1 – β/2).<br />
• R/S metoda (»rescaled adjusted range method«) ali prilagojena lestvica<br />
je prav tako grafična metoda, ki temelji na lastnosti Hurstovega pojava,<br />
opisanega v poglavju 3.2.4. Prilagojena lestvica je območje parcialnega<br />
seštevanja odklona časovnega zaporedja od srednje vrednosti.<br />
• varianca ostankov (»variance of residuals«) uporablja metodo<br />
najmanjših kvadratov prilagojene premice parcialnim seštevkom za vsak<br />
blok m agregiranega procesa.<br />
Metode za ocenjevanje v frekvenčnem ali valčnem (»wavelet«) prostoru so:<br />
• metoda periodograma (»periodogram method«) temelji na šumu 1/f <strong>in</strong><br />
Fourierovi transformaciji, opisani v poglavju 3.2.3. Je grafična metoda v<br />
logaritemskem merilu, <strong>in</strong> sicer za odvisnost spektralne gostote od<br />
frekvence.<br />
• metoda po Whittleu (»Whittle estimator«) temelji na m<strong>in</strong>imizaciji<br />
verjetnosti funkcije, uporabljene v metodi periodograma. Ni grafična<br />
metoda.<br />
• metoda Arby-Veitch (»AV method«) za ocenitev Hurstovega eksponenta<br />
uporablja valčno transformacijo naključnega zaporedja. Z metodo
22 OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
najmanjših kvadratov določimo premico valčnim koeficientom na<br />
različnih časovnih skalah, s pomočjo katere določimo parameter H.<br />
Primer:<br />
Za časovno diskretni naključni proces, ki ga prikazuje slika 4.1, ocenimo vrednost<br />
Hurstovega parametra z zgoraj opisanimi metodami.<br />
0.6<br />
vrednost naključne<br />
spremenljivke<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
1<br />
369<br />
737<br />
1105<br />
1473<br />
1841<br />
2209<br />
2577<br />
2945<br />
3313<br />
3681<br />
4049<br />
4417<br />
4785<br />
5153<br />
5521<br />
5889<br />
6257<br />
6625<br />
6993<br />
vzorčne točke<br />
Slika 4.1:<br />
Časovno diskretni naključni proces, za katerega določimo Hurstov parameter z<br />
različnimi ocenjevalnimi metodami.<br />
Tabela 4.1 prikazuje vrednosti Hurstovega parametra ocenjenega z različnimi<br />
metodami. Ocenitev je bila izvedena s pomočjo odprtokodne aplikacije Selfis [12],<br />
[13].<br />
Tabela 4.1: Vrednosti Hurstovega parametra ocenjene s pomočjo različnih ocenjevalnih metod.<br />
variančna R/S varianca metoda Whittle metoda<br />
metoda metoda ostankov periodograma estimator Arby‐Veitch<br />
ocenjen H 0,806 0,825 1,116 0,810 0,686 0,656<br />
Poskusi ocenjevanja parametra H z različnimi metodami nam dajo rezultate, ki<br />
kažejo na precejšnje odstopanje. Najbolj odstopa rezultat, ocenjen z metodo varianca<br />
ostankov, ki je presegel vrednost 1. V nadaljevanju se bomo osredotočili na opis<br />
osnovnih <strong>in</strong> največkrat uporabljenih metod za ocenjevanje Hurstovega parametra:<br />
variančna metoda, R/S metoda <strong>in</strong> metoda periodogram. Za <strong>modeliranje</strong> procesa<br />
bomo vrednost Hurstovega parametra izračunali kot aritmetično sred<strong>in</strong>o vseh<br />
ocenjenih parametrov z osnovnimi metodami.<br />
4.1.1 Variančna metoda<br />
Variančna metoda temelji na grafičnem določanju Hurstovega parametra. Lastnost<br />
samopodobnosti je, da varianca agregiranega procesa X (m) (m = 1, 2, 3, …) pada<br />
l<strong>in</strong>earno (za velike vrednosti m) v logaritemskem grafu glede na vrednost<br />
neprekrivajočega bloka m. Graf variančne metode narišemo tako, da na x-os<br />
nanašamo velikost neprekrivajočih blokov m v logaritemskem merilu, na y-os pa<br />
nanašamo vrednost variance agregiranega procesa var(X (m) ) prav tako v<br />
logaritemskem merilu. Skozi izračunane točke v grafu narišemo prilegajočo premico
OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
23<br />
po metodi najmanjših kvadratov, pri tem pa zanemarimo majhne vrednosti<br />
prekrivajočih blokov m agregiranega procesa [39].<br />
Vrednost ocenjenega naklona ˆ β asimptotične premice med – 1 <strong>in</strong> 0 odgovarja<br />
samopodobnosti, iz katere lahko izračunamo vrednost parametra H:<br />
ˆ<br />
ˆ β<br />
H = 1− (4.1)<br />
2<br />
Ocenjevanje parametra H s pomočjo variančne metode poteka v naslednjih fazah.<br />
• Orig<strong>in</strong>alno časovno zaporedje X = (X k : 1, 2, …, N) razdelimo v N/m blokov<br />
velikosti m.<br />
• Izračunamo povprečno vrednost za vsak blok<br />
km<br />
( m)<br />
1<br />
Xk<br />
= ∑ X, k = 1,2,3,..., N M<br />
(4.2)<br />
m i = ( k − 1) m + 1<br />
• Izračunamo srednjo vrednost variance agregacijskega zaporedja<br />
( m) ( m) N<br />
( m)<br />
X = ( Xk<br />
: k=<br />
0,1,2,... ) : var( X )<br />
m<br />
1 1<br />
= −<br />
Nm / /<br />
Nm / Nm /<br />
( m) 2 ( m) 2<br />
∑( Xk<br />
) ( ∑Xk<br />
)<br />
k= 1 Nm k=<br />
1<br />
(4.3)<br />
• Srednjo vrednost variance izračunamo za različne velikosti neprekrivajočih<br />
blokov m.<br />
• Narišemo logaritemski graf variance v odvisnosti od velikosti blokov m.<br />
• Točkam v grafu narišemo prilegajočo premico s koeficientom – β, 0 < β < 1.<br />
Ocenimo parameter β prilegajoče premice.<br />
• Izračunamo Hurstov parameter iz predpisa<br />
ˆ<br />
ˆ β<br />
H = 1− (4.4)<br />
2<br />
Slika 4.2:<br />
Primer grafa za ocenjevanje Hurstovega parametra s pomočjo variančne metode ter<br />
premica s koeficientom β = – 1, ki predstavlja mejo območja samopodobnosti, ki je<br />
označeno s sivo barvo [9].
24 OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
Slika 4.2 prikazuje območje samopodobnosti v primeru uporabe variančne metode<br />
ocenjevanja parametra H. Metoda ocenjevanja parametra H s pomočjo variančne<br />
metode je nezanesljiva v primerih majhnih časovnih vzorcev. V nasprotnem primeru,<br />
torej v primeru časovnega vzorca z velikim številom točk, pa daje uporabno <strong>in</strong> zelo<br />
zanesljivo oceno samopodobnosti [15].<br />
4.1.2 R/S metoda<br />
Statistična samopodobnost pomeni, da so statistične lastnosti celotnega<br />
podatkovnega zaporedja enake za celotno serijo kot tudi za podobmočje znotraj<br />
celotnega območja (npr. območje razdelimo na dve podobmočji, ki bi morali imeti<br />
podobne statistične lastnosti). Prav to lastnost deljenja celotnega območja na<br />
podobmočja izkoristimo za ocenjevanje Hurstovega parametra pri R/S metodi.<br />
Celotno območje razdelimo na posamezna podobmočja <strong>in</strong> ocenimo prilagojeno<br />
lestvico (»rescaled adjusted range«). Tako prilagojeno lestvico izračunamo na<br />
celotnem podatkovnem območju, nato podatkovno območje razdelimo <strong>in</strong> spet<br />
ocenimo prilagojeno lestvico itd. Prilagojene lestvice za vsako podobmočje<br />
povprečimo. Proces cepljenja območja se ustavi, ko so podobmočja dovolj majhna,<br />
da še lahko ocenimo prilagojeno lestvico (m<strong>in</strong>imalno 8 podatkovnih točk) [33], [39].<br />
Za podano območje opazovanja {X 1 , X 2 , …, X n } s srednjo vrednostjo µ = E{X i }<br />
def<strong>in</strong>irajmo zaporedje delnih vsot:<br />
Wj<br />
= ( X1+ X2+ ... + X<br />
j) − jX( n) , j = 1,2,... , n<br />
(4.5)<br />
kjer je X()<br />
n aritmetična srednja vrednost prvih n opazovanj.<br />
Območje R(n) def<strong>in</strong>iramo:<br />
R( n) = max(0, W, W ,..., W ) − m<strong>in</strong>(0, W, W ,..., W )<br />
(4.6)<br />
1 2 n<br />
1 2<br />
Standardno deviacijo S(n) opazovanj X 1 , X 2 , …, X n def<strong>in</strong>iramo :<br />
n<br />
Sn ( ) =<br />
n<br />
2<br />
∑ ( Xk<br />
− X( n))<br />
(4.7)<br />
k = 0<br />
n<br />
Hurstov parameter predstavlja prilagojena lestvica:<br />
R / S _ statistika = R( n)/ S( n)<br />
Pričakovana vrednost predpisa R(n)/S(n) asimptotično zadovolji predpis:<br />
⎡Rn<br />
( ) ⎤ H<br />
E⎢<br />
→ cn , n →∞<br />
Sn ( )<br />
⎥<br />
⎣ ⎦<br />
(4.8)<br />
kjer je Hurstov parameter H > 0,5 <strong>in</strong> pozitivna konstanta c > 0.<br />
Strm<strong>in</strong>a premice grafa log(R/S) <strong>in</strong> log(m) predstavlja Hurstov parameter (H).<br />
Primer ocenjevanja Hurstovega parametra z R/S metodo <strong>in</strong> območje samopodobnosti<br />
prikazuje slika 4.3.
OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
25<br />
Slika 4.3:<br />
Primer grafa za ocenjevanje Hurstovega parametra s pomočjo R/S metode ter mejni<br />
premici, ki predstavljata mejo območja samopodobnosti, ki je označeno s sivo barvo<br />
[9].<br />
4.1.3 Metoda periodograma<br />
Ena izmed metod ocenjevanja Hurstovega parametra je tudi metoda periodograma<br />
(poglavje 3.2.3), ki temelji na uporabi diskretne Fourierove transformacije spektralne<br />
gostote [15]. Spektralno gostoto f(λ) kot funkcijo avtokorelacijske funkcije r(k) <strong>in</strong><br />
varianco σ 2 podamo s:<br />
2 k=∞<br />
σ<br />
ik<br />
f( λ) = ∑ ρ( k) e λ ,<br />
(4.9)<br />
2π<br />
k=−∞<br />
kjer je λ frekvenca <strong>in</strong> σ 2 varianca. Za šibko stacionarno časovno zaporedje pravimo,<br />
da ima dolgo območje odvisnosti, če njegovo spektralno gostoto opišemo z naslednjo<br />
enačbo:<br />
f( λ) ≈ C f<br />
λ −β<br />
,<br />
(4.10)<br />
ko gre frekvenca λ proti 0 <strong>in</strong> je parameter C f pozitivna konstanta. Parameter β je<br />
neposredno povezan s Hurstovim parametrom, <strong>in</strong> sicer β = 2H – 1.<br />
Periodogram podamo z naslednjo zvezo:<br />
2<br />
ikλ<br />
⎤<br />
N<br />
1 ⎡<br />
I( λk) = ( Xk)<br />
e<br />
2π N<br />
⎢∑ ⎥<br />
(4.11)<br />
⎣k<br />
= 1 ⎦<br />
Za podatkovno zaporedje s končno varianco lahko z zgornjo enačbo izračunamo<br />
spektralno gostoto. Parameter H lahko ocenimo s pomočjo periodograma, <strong>in</strong> sicer v<br />
logaritemskem merilu blizu njegovega izhodišča (slika 4.4).
26 OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
Slika 4.4:<br />
Primer grafa za ocenjevanje Hurstovega parametra s pomočjo metode periodograma ter<br />
premico, ki predstavlja mejo območja samopodobnosti, ki je označeno s sivo barvo [9].<br />
4.2 Določanje parametrov porazdelitev verjetnosti<br />
Določanje porazdelitev verjetnosti, ki najbolje opisujejo statistične lastnosti<br />
naključnega procesa, temelji na histogramih. Ti nam služijo kot referenca pri izbiri<br />
najbolj prilegajoče porazdelitve ter izračunu parametrov izbrane porazdelitve.<br />
Histogram je stopničasti približek zvezne funkcije gostote verjetnosti. V primeru, ko<br />
je funkcija porazdelitve verjetnosti F x (x) odvedljiva, lahko določimo porazdelitev<br />
gostote verjetnosti f x (x) z odvajanjem F x (x) [46].<br />
oziroma z limitno aproksimacijo odvoda<br />
f<br />
x<br />
dFx<br />
( x)<br />
= (4.12)<br />
dx<br />
f<br />
x<br />
= lim<br />
Δx→0<br />
Fx<br />
( x + Δx)<br />
− Fx<br />
( x)<br />
Δx<br />
(4.13)<br />
Zgornji predpis vodi k aproksimaciji porazdelitve gostote verjetnosti pri diskretnih<br />
naključnih spremenljivkah, ki jih imenujemo teoretični histogrami. Pri teoretičnem<br />
histogramu območje f x (x), a < x < b, razdelimo na K <strong>in</strong>tervalov tako, da je x 0 = a <strong>in</strong><br />
x k = b, pri čemer velja, da je x i-1 < x i , i = 1, 2, …, K. i-ti <strong>in</strong>terval je določen z<br />
Δx i = x i - x i-1 . V tem primeru je teoretični histogram nad vsemi x določen z:<br />
F ( x ) − F ( x )<br />
f x x i K<br />
ˆ x i x i−1<br />
x<br />
= lim ,<br />
i−1<br />
<<br />
i, = 1, 2,...,<br />
Δx→0<br />
xi<br />
− xi−<br />
1<br />
(4.14)<br />
Zgornja enačba podaja verjetnost, da se vrednost naključne spremenljivke nahaja<br />
znotraj <strong>in</strong>tervala Δx i . Intervali Δx i so lahko določeni na različne nač<strong>in</strong>e, <strong>in</strong> sicer sta<br />
najpogostejša primera <strong>in</strong>tervalov enake dolž<strong>in</strong>e <strong>in</strong> <strong>in</strong>tervalov enakih gostot<br />
verjetnosti.
OCENJEVANJE PARAMETROV STOHASTIČNEGA PROCESA<br />
27<br />
Za določanje verjetnostnih porazdelitev naključnega procesa določimo<br />
pripadajoči histogram z določeno šir<strong>in</strong>o <strong>in</strong>tervala. Nato izberemo porazdelitve ter<br />
njene parametre, ki se najbolje prilegajo narisanemu histogramu. Pri tem težko<br />
najdemo porazdelitev, ki bi se natančno prilegala histogramu. V tem primeru se<br />
pojavi napaka med empirično porazdelitvijo naključnega zaporedja <strong>in</strong> teoretično<br />
porazdelitvijo, ki smo jo izbrali s pomočjo histograma. Razliko, ki se pojavi med<br />
empirično <strong>in</strong> numerično porazdelitveno funkcijo, lahko prikažemo s pomočjo<br />
porazdelitvene diference. Razvitih je bilo kar nekaj programskih orodij, ki nam<br />
omogočajo vnos naključnih podatkov procesa, risanje histograma, izbiro pripadajoče<br />
porazdelitve verjetnosti <strong>in</strong> njenih parametrov. Določanje porazdelitve verjetnosti <strong>in</strong><br />
njenih parametrov naključnih procesov lahko izvedemo s tako imenovanimi<br />
metodami prileganja krivulj [40]. Gre za programsko opremo, namenjeno prav<br />
določanju porazdelitev ter pripadajočih parametrov naključnih procesov. V našem<br />
primeru smo določanje porazdelitev izvedli s pomočjo programskega paketa EasyFit<br />
(slika 4.5) podjetja Mathwave [41] .<br />
Slika 4.5:<br />
Histogram naključnega zaporedja <strong>in</strong> izbira najbolj prilegajoče se porazdelitve.
28 DOLOČANJE OSNOVNIH PARAMETROV<br />
5. DOLOČANJE OSNOVNIH PARAMETROV<br />
S pomočjo vohljača smo v naključno izbranih omrežjih izmerili različne omrežne<br />
promete, ki smo jih klasificirali v smislu samopodobnosti ter določili lastnost<br />
dolgega območja odvisnosti. V fazi analize bomo določili potrebne parametre<br />
izmerjenih signalov, ki jih bomo uporabili v fazi modeliranja. Primere izmerjenih<br />
prometov prikazujejo slike 5.1, 5.2 <strong>in</strong> 5.3. Osnovne lastnosti izmerjenih signalov<br />
vsebuje tabela 5.1.<br />
Tabela 5.1: Osnovni parametri izmerjenih testnih signalov (prometov).<br />
dolž<strong>in</strong>a<br />
signala (s)<br />
št. paketov pov. vred.<br />
(p/s)<br />
pov. velikost<br />
paketov (B)<br />
št. zlogov<br />
(B)<br />
pov. vred.<br />
(B/s)<br />
signal 1 241,5 8601 35,612 401 3457214 114517,6<br />
signal 2 294,6 79 0,268 199 15740 53,432<br />
signal 3 240 5771 24 567 3272607 108909,2<br />
Slika 5.1: Izmerjen testni signal (signal 1).<br />
Slika 5.2: Izmerjen testni signal (signal 2).
DOLOČANJE OSNOVNIH PARAMETROV<br />
29<br />
Slika 5.3: Izmerjen testni signal (signal 3).<br />
Vsak izmerjen testni signal bomo obravnavali kot skupek dveh naključnih procesov,<br />
procesa velikosti paketov <strong>in</strong> prihodov paketov. Oba bomo skušali matematično<br />
ovrednotiti (porazdelitve verjetnosti, Hurstov parameter) ter na podlagi analize<br />
napraviti klasifikacijo v smislu samopodobnosti. Iz zgornjih slik vidimo, da se testni<br />
signali že na prvi pogled zelo razlikujejo. Prvi testni signal namreč spom<strong>in</strong>ja na<br />
signale, ki kažejo lastnost samopodobnosti, za razliko od drugega signala, kjer se<br />
promet pojavi le v krajših časovnih razdelkih. Testni signal 1 smo izmerili na<br />
računalniku, povezanem v omrežje, ki je imel aktiven program za deljenje datotek<br />
preko <strong>in</strong>terneta (eMule). Testni signal 2 prikazuje promet replikacijske aplikacije,<br />
kjer se prenosi podatkov pojavijo v posameznih trenutkih (transakcije). Testni signal<br />
3 smo izmerili na računalniku, povezanem v omrežje, na katerem se je med meritvijo<br />
izvajala aplikacija deskanja po svetovnem spletu (WWW). V testnem signalu 3 se<br />
pojavljajo posamezne konice, ki ekstremno odstopajo od srednje vrednosti.<br />
5.1 Ocenjevanje Hurstovega parametra<br />
Ocenjevanje Hurstovega parametra kot merila samopodobnosti izvedemo z<br />
opisanimi metodami, <strong>in</strong> sicer z variančno metodo, R/S metodo <strong>in</strong> metodo<br />
periodograma. Hurstov parameter določamo za število prihodov paketov na časovno<br />
enoto.<br />
Poleg ocenjevana Hurstovga parametra bomo izrisovali tudi avtokorelacijsko<br />
funkcijo, ki nam bo podala <strong>in</strong>formacijo o dolgem ali kratkem območju odvisnosti. V<br />
primeru, da bo avtokorelacijska funkcija kazala lastnost dolgega območja odvisnosti,<br />
bomo to potrdili z metodo »bucket shuffl<strong>in</strong>g«.
30 DOLOČANJE OSNOVNIH PARAMETROV<br />
Ocenjevanje Hurstovega parametra <strong>in</strong> avtokorelacijska funkcija testnega signala 1:<br />
število paketov na časovno<br />
enoto<br />
število paketov na časovno<br />
enoto (T=10ms)<br />
10<br />
8<br />
6<br />
4<br />
2<br />
0<br />
1<br />
2417<br />
4833<br />
7249<br />
9665<br />
12081<br />
14497<br />
16913<br />
19329<br />
21745<br />
čas (ms)<br />
log 10 (R/S)<br />
6<br />
5<br />
4<br />
3<br />
2<br />
1<br />
0<br />
0 5 10<br />
log 10 (m)<br />
log 10 (varianca)<br />
0<br />
‐2<br />
‐4<br />
‐6<br />
‐8<br />
0 5 10<br />
log 10 (periodogram)<br />
2<br />
0<br />
‐10 ‐5 ‐2 0<br />
‐4<br />
‐6<br />
‐8<br />
‐10<br />
‐10<br />
log 10 (m)<br />
log10 (frekvenca)<br />
‐12<br />
Slika 5.4:<br />
Število paketov na časovno enoto (zgoraj levo) <strong>in</strong> ocenjevanje Hurstovega parametra z<br />
variančno metodo (spodaj levo), R/S metodo (zgoraj desno) <strong>in</strong> metodo periodograma<br />
(spodaj desno).<br />
Tabela 5.2: Hurstovi parametri za signal 1 ocenjeni s pomočjo različnih metod.<br />
signal 1 variančna metoda metoda R/S metoda periodograma<br />
Hurstov parameter (H) 0,592 0,580 0,477<br />
r(k)<br />
1.2<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
‐0.2<br />
1<br />
7<br />
13<br />
19<br />
25<br />
31<br />
37<br />
43<br />
49<br />
55<br />
61<br />
67<br />
73<br />
79<br />
85<br />
91<br />
97<br />
k<br />
Slika 5.5:<br />
Avtokorelacijska funkcija testnega signala.
DOLOČANJE OSNOVNIH PARAMETROV<br />
31<br />
Ocenjevanje Hurstovega parametra <strong>in</strong> avtokorelacijska funkcija testnega signala 2:<br />
število paketov na časovno<br />
enoto<br />
število paketov na časovno<br />
enoto (T=100ms)<br />
8<br />
6<br />
4<br />
2<br />
0<br />
1<br />
296<br />
591<br />
886<br />
1181<br />
1476<br />
1771<br />
2066<br />
2361<br />
2656<br />
čas (ms)<br />
log 10 (R/S)<br />
4.5<br />
4<br />
3.5<br />
3<br />
2.5<br />
2<br />
1.5<br />
1<br />
0.5<br />
0<br />
0 2 4 6 8<br />
log 10 (m)<br />
log 10 (varianca)<br />
0<br />
‐1<br />
‐2<br />
‐3<br />
‐4<br />
‐5<br />
‐6<br />
‐7<br />
‐8<br />
0 2 4 6 8<br />
log 10 (periodogram)<br />
0<br />
‐8 ‐6 ‐4 ‐2<br />
‐2<br />
0<br />
‐4<br />
‐6<br />
‐8<br />
‐10<br />
‐12<br />
log 10 (m)<br />
log 10 (frekvenca)<br />
Slika 5.6:<br />
Število paketov na časovno enoto (zgoraj levo) <strong>in</strong> ocenjevanje Hurstovega parametra z<br />
variančno metodo (spodaj levo), R/S metodo (zgoraj desno) <strong>in</strong> metodo periodograma<br />
(spodaj desno).<br />
Tabela 5.3: Hurstovi parametri za signal 2 ocenjeni s pomočjo različnih metod.<br />
signal 2 variančna metoda metoda R/S metoda periodograma<br />
Hurstov parameter (H) 0,630 0,608 0,626<br />
r(k)<br />
1.2<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
‐0.2<br />
1<br />
7<br />
13<br />
19<br />
25<br />
31<br />
37<br />
43<br />
49<br />
55<br />
61<br />
67<br />
73<br />
79<br />
85<br />
91<br />
97<br />
k<br />
Slika 5.7: Avtokorelacijska funkcija testnega signala 2.
32 DOLOČANJE OSNOVNIH PARAMETROV<br />
Ocenjevanje Hurstovega parametra <strong>in</strong> avtokorelacijska funkcija testnega signala 3:<br />
število paketov na časovno<br />
enoto<br />
100<br />
število paketov na časovno<br />
enoto (T=10ms)<br />
80<br />
60<br />
40<br />
20<br />
0<br />
1<br />
2185<br />
4369<br />
6553<br />
8737<br />
10921<br />
13105<br />
15289<br />
17473<br />
19657<br />
21841<br />
čas (ms)<br />
log 10 (R/S)<br />
7<br />
6<br />
5<br />
4<br />
3<br />
2<br />
1<br />
0<br />
0 5 10 15<br />
log 10 (m)<br />
log 10 (varianca)<br />
3<br />
2<br />
1<br />
0<br />
‐1<br />
‐2<br />
‐3<br />
‐4<br />
‐5<br />
‐6<br />
‐7<br />
0 2 4 6 8 10<br />
log 10 (m)<br />
log 10 (periodogram)<br />
4<br />
2<br />
0<br />
‐10 ‐5<br />
‐2<br />
0<br />
‐4<br />
‐6<br />
log 10 (frekvenca)<br />
‐8<br />
Slika 5.8:<br />
Število paketov na časovno enoto (zgoraj levo) <strong>in</strong> ocenjevanje Hurstovega parametra z<br />
variančno metodo (spodaj levo), R/S metodo (zgoraj desno) <strong>in</strong> metodo periodograma<br />
(spodaj desno).<br />
Tabela 5.4: Hurstovi parametri za signal ocenjeni s pomočjo različnih metod.<br />
signal 3 variančna metoda metoda R/S metoda periodograma<br />
Hurstov parameter (H) 0,630 0,723 0,843<br />
1.5<br />
1<br />
r(k)<br />
0.5<br />
0<br />
‐0.5<br />
1<br />
8<br />
15<br />
22<br />
29<br />
36<br />
43<br />
50<br />
57<br />
64<br />
71<br />
78<br />
85<br />
92<br />
99<br />
k<br />
Slika 5.9: Avtokorelacijska funkcija testnega signala 3.
DOLOČANJE OSNOVNIH PARAMETROV<br />
33<br />
Z analizo samopodobnosti z različnimi uporabljenimi metodami ugotovimo, da<br />
testni signal 1 ima lastnost samopodobnosti (slika 5.4), saj je ocenjen Hurstov<br />
parameter večji od vrednosti 0,5 (tabela 5.2). Iz poteka avtokorelacijske funkcije<br />
vidimo, da nima lastnosti dolgega območja odvisnosti (slika 5.5). Enake lastnosti ima<br />
prav tako tudi testni signal 2 (sliki 5.6 <strong>in</strong> 5.7), vendar bi za natančnejšo analizo<br />
potrebovali več zajetih paketov. Lastnost samopodobnosti <strong>in</strong> dolgega območja<br />
odvisnosti ima tesni signal 3 (sliki 5.8 <strong>in</strong> 5.9). Slednjo lastnost testnega signala 3<br />
bomo v nadaljevanju potrdili z metodo »bucket shuffl<strong>in</strong>g«.<br />
Za naključni proces najprej izvedemo eksterno mešanje zaporedja, <strong>in</strong> sicer z<br />
dolž<strong>in</strong>o delov zaporedja 1. S tem dosežemo naključno mešanje zaporedja, ki ga<br />
prikazuje slika 5.10, ter njegovo avtokorelacijsko funkcijo.<br />
vrednost naključne<br />
spremenljivke<br />
70<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
0<br />
1<br />
1640<br />
3279<br />
4918<br />
6557<br />
8196<br />
9835<br />
11474<br />
13113<br />
14752<br />
vzorčne točke<br />
r(k)<br />
1.2<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
‐0.2<br />
1<br />
10<br />
19<br />
28<br />
37<br />
46<br />
55<br />
64<br />
73<br />
82<br />
91<br />
100<br />
k<br />
Slika 5.10: Eksterno naključno mešanje časovnega zaporedja z vrednostjo »bucket« = 1.<br />
Izvedemo eksterno mešanje podatkov zaporedja z dolž<strong>in</strong>o delov časovnega<br />
zaporedja, enako 50 (slika 5.11 – levo). V tem primeru se pojavi dolgo območje<br />
odvisnosti le znotraj deljenih delov orig<strong>in</strong>alnega procesa (slika 5.11 – desno).<br />
vrednost naključne<br />
spremenljivke<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
0<br />
1<br />
821<br />
1641<br />
2461<br />
3281<br />
4101<br />
4921<br />
5741<br />
6561<br />
7381<br />
vzorčne točke<br />
r(k)<br />
1.2<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
‐0.2<br />
1<br />
10<br />
19<br />
28<br />
37<br />
46<br />
55<br />
64<br />
73<br />
82<br />
91<br />
100<br />
k<br />
Slika 5.11: Eksterno naključno mešanje časovnega zaporedja z vrednostjo »bucket« = 50.<br />
Nato izvedemo <strong>in</strong>terno mešanje zaporedja naključnega procesa, <strong>in</strong> sicer z dolž<strong>in</strong>o<br />
časovnih delov, enako 50. Pri tem dosežemo mešanje zaporedja znotraj časovnih<br />
delov, zaporedje časovnih delov pa ostane enako (slika 5.12 – levo).<br />
Avtokorelacijska funkcija označi proces kot proces z dolgim območjem odvisnosti<br />
(slika 5.12 – desno).
34 DOLOČANJE OSNOVNIH PARAMETROV<br />
vrednost naključne<br />
spremenljivke<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
0<br />
1.2<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
vzorčne točke ‐0.2<br />
1<br />
821<br />
1641<br />
2461<br />
3281<br />
4101<br />
4921<br />
5741<br />
6561<br />
7381<br />
r(k)<br />
1<br />
11<br />
21<br />
31<br />
41<br />
51<br />
61<br />
71<br />
81<br />
91<br />
101<br />
k<br />
Slika 5.12: Interno naključno mešanje časovnega zaporedja z vrednostjo »bucket« = 50.<br />
Napravimo še primerjavo med avtokorelacijsko funkcijo orig<strong>in</strong>alnega stohastičnega<br />
procesa <strong>in</strong> avtokorelacijsko funkcijo orig<strong>in</strong>alnega procesa, nad katerim smo izvedli<br />
<strong>in</strong>terno mešanje zaporedja dolž<strong>in</strong>e 50.<br />
1.2<br />
1<br />
r(k)<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
<strong>in</strong>terno<br />
naključno<br />
mešanje<br />
orig<strong>in</strong>alni<br />
proces<br />
‐0.2<br />
1<br />
9<br />
17<br />
25<br />
33<br />
41<br />
49<br />
57<br />
65<br />
73<br />
81<br />
89<br />
97<br />
k<br />
Slika 5.13:<br />
Primerjava avtokorelacijske funkcije orig<strong>in</strong>alnega procesa <strong>in</strong> avtokorelacijske funkcije<br />
<strong>in</strong>terno zmešanega orig<strong>in</strong>alnega procesa z dolž<strong>in</strong>o naključnih delov 50.<br />
Iz slike 5.13, ki prikazuje avtokorelacijsko funkcijo orig<strong>in</strong>alnega procesa <strong>in</strong> <strong>in</strong>terno<br />
mešanega procesa, vidimo, da sta poteka zelo podobna, kar potrdi lastnost dolgega<br />
območja odvisnosti naključnega procesa testnega signala 3.<br />
5.2 Določanje porazdelitev verjetnosti časa med paketi<br />
Porazdelitev verjetnosti bomo določali tako za velikost paketov kot za čas med<br />
paketi. Z ocenitvijo Hurstovega parametra smo sicer že opisali proces prihodov<br />
paketov, vendar bomo to opravili še z izbiro porazdelitve verjetnosti za čas med<br />
paketi.<br />
Določanje porazdelitev verjetnosti izvedemo s pomočjo programskega paketa<br />
EasyFit [41], ki nam omogoča vnos podatkov o naključnem procesu ter izračun več<br />
kot dvajsetih porazdelitev verjetnosti <strong>in</strong> njihovih parametrov. V primeru določanja<br />
porazdelitve časa med paketi <strong>in</strong>formacijo o času med paketi iz vohljača prenesemo v<br />
program EasyFit. Program nam določi najprimernejše porazdelitve verjetnosti ter
DOLOČANJE OSNOVNIH PARAMETROV<br />
35<br />
izračuna parametre izbrane porazdelitve (slika 5.14). Slika 5.15 prikazuje poteke<br />
porazdelitve, kumulativne porazdelitve, razliko med empirično <strong>in</strong> teoretično<br />
porazdelitvijo v P-P grafu ter diferenčno porazdelitev za počasi pojemajočo <strong>in</strong><br />
eksponentno porazdelitev.<br />
Slika 5.14:<br />
Določanje porazdelitve za čas med paketi.<br />
Slika 5.15:<br />
Za naključni proces časa med paketi na osnovi histograma določimo porazdelitev <strong>in</strong><br />
parametre te porazdelitve (levo – zgoraj), kumulativno porazdelitev (desno – zgoraj),<br />
razliko med empirično <strong>in</strong> teoretično porazdelitvijo v P-P grafu (levo – spodaj) ter<br />
diferenčno porazdelitev (desno – spodaj).
36 DOLOČANJE OSNOVNIH PARAMETROV<br />
Pri določanju porazdelitev najprej iz vohljača prenesemo zaporedje časov med paketi<br />
<strong>in</strong> jih preoblikujemo v primerno obliko za programski paket EasyFit. Ta nam izriše<br />
histogram ter funkcije, ki se mu najbolje prilegajo.<br />
P-P je graf razlike empirične kumulativne porazdelitvene funkcije (ECDF) <strong>in</strong><br />
teoretične kumulativne porazdelitvene funkcije (CDF). P-P graf uporabljamo za<br />
ponazoritev ujemanja določene porazdelitve z opazovanimi podatki. Diferenčna<br />
porazdelitev je graf, v katerem lahko prav tako kot v P-P grafu opazujemo razliko<br />
med empirično kumulativno porazdelitveno funkcijo <strong>in</strong> numerično porazdelitveno<br />
funkcijo.<br />
Diff ( x) = F ( x) − F( x)<br />
(5.1)<br />
Ta graf skupaj s P-P grafom uporabljamo za ugotavljanje <strong>in</strong> določitev prileganja<br />
teoretične porazdelitve opazovanim podatkom.<br />
5.3 Določanje porazdelitev verjetnosti velikosti paketov<br />
n<br />
Določanje porazdelitve verjetnosti velikosti paketov ter njenih parametrov izvedemo<br />
na enak nač<strong>in</strong>, kot smo to opravili za čas med paketi. Napisanih je bilo kar nekaj<br />
člankov o povezavi velikosti datotek [7], [8], [9] <strong>in</strong> opisov s počasi pojemajočimi<br />
porazdelitvami, <strong>in</strong> sicer s Paretovo porazdelitvijo [6].<br />
Opravljene meritve omrežnega <strong>prometa</strong> [7] v LAN <strong>in</strong> WAN omrežjih so<br />
pokazale, da omrežni promet izkazuje spremenljivost na širokem območju časovne<br />
skale. Variabilnost velja tudi za velikost prenesenih datotek znotraj omrežja.<br />
Pokazano je bilo tudi, da počasi pojemajoče porazdelitve najbolje opisujejo naključni<br />
proces velikosti prenesenih datotek, kar pomeni, da se lahko znotraj omrežja pojavijo<br />
zelo velike datoteke, ki imajo sicer zelo majhno verjetnost, vendar te verjetnosti ne<br />
smemo zanemariti. Pokazano je bilo, da velikost datotek v primeru WWW [9]<br />
najbolje opisuje Paretova porazdelitev z velikostjo parametra oblike α = 1 <strong>in</strong> v<br />
primeru aplikacije FTP [5] prav tako Paretova porazdelitev z velikostjo parametra<br />
oblike 0,9 < α < 1,1.<br />
Za primer opisa velikosti datotek s pomočjo počasi pojemajoče Paretove<br />
porazdelitve, ki smo jo opisali v 3. poglavju, še enkrat zapišimo kumulativno<br />
porazdelitveno funkcijo<br />
α<br />
⎛k<br />
⎞<br />
F( x) = P[ X ≤ x]<br />
= 1 − ⎜ ⎟ ,<br />
(5.2)<br />
⎝ x ⎠<br />
kjer je k najmanjša možna pozitivna vrednost naključne spremenljivke x. Torej se<br />
parameter k nanaša na najmanjše možne pakete, ki se lahko pojavijo v omrežju. Teh<br />
ni težko najti v izmerjenih rezultatih meritev omrežja s pomočjo vohljača. Paretovo<br />
porazdelitev smo opisali že v poglavju 3.3, kjer smo ugotovili, da ima tako Paretova<br />
kot vse počasi pojemajoče porazdelitve precej drugačne lastnosti kot bolj pogosto<br />
uporabljene porazdelitve (npr. normalna ali eksponentna porazdelitev). Če je α ≤ 2,<br />
ima porazdelitev neskončno varianco, v primeru α ≤ 1 pa ima porazdelitev<br />
neskončno srednjo vrednost. Ko vrednost parametra α pada, imamo na koncu<br />
porazdelitve velik delež verjetnosti. To pomeni, da naključna spremenljivka, ki jo<br />
opisujemo s počasi pojemajočo porazdelitvijo, povzroča ekstremno velike<br />
podatkovne datoteke z nezanemarljivo verjetnostjo.
DOLOČANJE OSNOVNIH PARAMETROV<br />
37<br />
5.3.1 Odvisnost srednje vrednosti <strong>prometa</strong> od parametra oblike<br />
Srednjo vrednost Paretove porazdelitve opisuje naslednja enačba:<br />
k ⋅α<br />
EX ( ) = , 1< α < 2<br />
α −1<br />
(5.3)<br />
kjer je k parameter lokacije <strong>in</strong> α parameter oblike. V primeru opisovanja velikosti<br />
paketov s počasi pojemajočo Paretovo porazdelitvijo verjetnosti imamo <strong>in</strong>formacijo<br />
o najmanjšem paketu v omrežju, zato na srednjo vrednost vpliva le izbrana vrednost<br />
parametra oblike α. Torej izbira velikosti parametra vpliva neposredno na srednjo<br />
vrednost <strong>prometa</strong>. V naslednjem poizkusu bomo pokazali odvisnost srednje vrednosti<br />
od velikosti parametra oblike Paretove porazdelitve.<br />
Primer:<br />
Modelirajmo promet s pomočjo porazdelitve časa med paketi, <strong>in</strong> sicer z<br />
eksponentno porazdelitvijo verjetnosti s parametrom <strong>in</strong>tenzivnosti λ = 0,05.<br />
Naključni proces velikosti paketov bomo opisali s pomočjo Paretove porazdelitve s<br />
parametrom lokacije 400 (najmanjši paket v omrežju v bitih), parameter oblike α<br />
bomo sprem<strong>in</strong>jali med vrednostjo 0,8 <strong>in</strong> 2. Pri tem bomo opazovali vpliv parametra<br />
oblike na srednjo vrednost modeliranega <strong>prometa</strong> (slika 5.16).<br />
srednja vrednost (b/s)<br />
700000<br />
600000<br />
500000<br />
400000<br />
300000<br />
200000<br />
100000<br />
0<br />
0.8 1 1.2 1.4 1.6 1.8 2<br />
parameter oblike (α)<br />
Slika 5.16:<br />
Srednja vrednost <strong>prometa</strong> v odvisnosti parametra oblike α Paretove porazdelitve za<br />
velikost paketov v območju med 0,8 <strong>in</strong> 2.<br />
Slika 5.16 prikazuje vpliv parametra oblike na srednjo vrednost modeliranega<br />
<strong>prometa</strong>, predvsem v območju med 0,8 <strong>in</strong> 1,2. Med vrednostmi nad 1,2 do 2 ima<br />
parameter oblike manjši vpliv na srednjo vrednost <strong>prometa</strong>. Poizkus dokazuje<br />
pomembnost natančne ocenitve parametra oblike, saj že vsako najmanjše odstopanje<br />
povzroči zelo veliko odstopanje modeliranega <strong>prometa</strong> v smislu srednje vrednosti. V<br />
primeru, da smo ocenili parameter oblike 0,9 namesto 1, smo napravili kar<br />
nekajkratno stoodstotno napako. Torej smo za natančno <strong>modeliranje</strong> prisiljeni k<br />
natančni ocenitvi parametra oblike Paretove porazdelitve verjetnosti. V nasprotnem<br />
primeru bomo deležni velike napake v smislu odstopanja srednje vrednosti, ki se bo<br />
pojavila med izmerjenim <strong>in</strong> modeliranim omrežnim prometom. Za določitev<br />
vrednosti parametra α imamo na voljo več metod, ki so opisane v naslednjem<br />
poglavju.
38 DOLOČANJE OSNOVNIH PARAMETROV<br />
5.3.2 Ocenitev parametra oblike (α)<br />
Med najbolj priljubljenimi metodami za ocenjevanje parametra α Paretove<br />
porazdelitve je CCDF metoda, ki temelji na grafični predstavitvi komplementarne<br />
kumulativne porazdelitve v logaritemskem merilu. Počasi pojemajočo distribucijo v<br />
tem grafu lahko opišemo kot [6], [42]:<br />
dlog F( x)<br />
lim =− α<br />
(5.6)<br />
x→∞<br />
dlog<br />
x<br />
Za velike vrednosti x komplementarna kumulativna funkcija teži k ravni premici z<br />
naklonom, enakim negativni vrednosti parametra oblike ( – α). Slika 5.17 je primer<br />
ocenitve parametra oblike α [6]. Iz te slike vidimo primer določanja komplementarno<br />
kumulativne porazdelitvene funkcije velikosti datotek v omrežju v logaritemskem<br />
merilu. Skozi točke komplementarne porazdelitve določimo premico, katere naklon<br />
odgovarja velikosti parametra oblike Paretove porazdelitve. Naklon premice je enak<br />
– 1,2, kar pomeni, da je parameter oblike enak 1,2.<br />
Slika 5.17: Komplementarna kumulativna porazdelitvena funkcija velikosti datotek v<br />
logaritemskem grafu.<br />
Zraven te metode obstaja še ena zelo pomembna metoda izračuna parametra oblike<br />
Paretove porazdelitve, <strong>in</strong> sicer Hillov estimator [43], ki se uporablja v ekonomiji,<br />
f<strong>in</strong>ancah <strong>in</strong> v telekomunikacijah.<br />
V našem primeru bomo določili parameter oblike Paretove porazdelitve s<br />
pomočjo programa EasyFit, kot v primeru določanja porazdelitve časa med paketi.<br />
5.3.3 Predlog metode ocenjevanja porazdelitve verjetnosti velikosti<br />
paketov<br />
Iz meritev <strong>in</strong> analize omrežnega <strong>prometa</strong> [5], [9] so raziskovalci opravili meritve za<br />
velikost prenesenih datotek znotraj LAN ali WAN omrežja. V primeru vohljača<br />
dobimo <strong>in</strong>formacije o paketih <strong>in</strong> ne o datotekah, ki se pretakajo znotraj omrežja.
DOLOČANJE OSNOVNIH PARAMETROV<br />
39<br />
Torej ocena potrebnih parametrov za <strong>modeliranje</strong> <strong>prometa</strong> izhaja iz velikosti paketov<br />
<strong>in</strong> časa med paketi.<br />
Z analizo velikosti paketov smo dobili podobne rezultate, kot jih navajajo drugi<br />
avtorji v svojih delih [23], [44], ki jih prikazuje slika 5.18.<br />
Slika 5.18: Primer histograma velikosti paketov izmerjenega <strong>prometa</strong> ter določanje porazdelitve<br />
velikosti paketov.<br />
Iz histograma zajetega <strong>prometa</strong> (slika 5.18) vidimo, da v omrežju prevladuje veliko<br />
število paketov z m<strong>in</strong>imalno velikostjo ter nezanemarljivo število velikih paketov z<br />
maksimalno velikostjo. V primeru izbire počasi pojemajočih porazdelitev izgubimo<br />
<strong>in</strong>formacijo o največjih paketih, verjetnost katerih pa ni zanemarljiva. V primeru na<br />
sliki 5.18 je takšnih paketov približno 15 %. To pomeni, da z neprimerno izbiro<br />
porazdelitev 'odrežemo' največje pakete, ki imajo največji dopr<strong>in</strong>os h količ<strong>in</strong>i<br />
prenesenih bitov v omrežju.<br />
M<strong>in</strong>imalna <strong>in</strong> maksimalna dolž<strong>in</strong>a paketov v omrežju je odvisna od<br />
komunikacijskega protokola <strong>in</strong> tehnologije omrežja. Dolž<strong>in</strong>a maksimalnega paketa je<br />
lahko določena standardno kot v primeru Ethernet tehnologije ali pa se dolž<strong>in</strong>a<br />
najdaljšega paketa določi ob vzpostavitvi komunikacije, kot je to v primeru serijskih<br />
povezav tipa točka-točka. Maksimalno dolž<strong>in</strong>o paketa označujemo tudi kot največjo<br />
prenosno enoto (Maximum Transmission Unit – MTU), ki pripomore k boljši izrabi<br />
podatkovne pasovne šir<strong>in</strong>e. Internetni protokol (IP), kot osrednji omrežni protokol, je<br />
bil razvit za različne omrežne tehnologije <strong>in</strong> ne predpisuje maksimalne dolž<strong>in</strong>e<br />
paketov, saj zato poskrbi nižji nivo. V primeru daljših datagramov se na nižjem<br />
nivoju izvede fragmentacija pakete datagramov v maksimalne dolž<strong>in</strong>e za prenos med<br />
oddajnikom <strong>in</strong> sprejemnikom. Fragmentacija je deljenje datagramov v manjše enote<br />
(maksimalne pakete), ki jih lahko pošljemo po podatkovni poti. IP protokol dodatno<br />
označi fragmentirane maksimalne pakete, kar služi za sestavljanje sprejetih paketov v<br />
orig<strong>in</strong>alni datagram na sprejemni strani. Tako iz orig<strong>in</strong>alnega datagrama dolž<strong>in</strong>e X<br />
dobimo zaporedje X/MTU paketov maksimalne dolž<strong>in</strong>e ter še dodaten paket, ki<br />
predstavlja ostanek.<br />
Naša ideja ocenjevanja porazdelitve velikosti paketov temelji na<br />
defragmentaciji, <strong>in</strong> sicer na osnovi izmerjenih rezultatov s pomočjo vohljača. Tako
40 DOLOČANJE OSNOVNIH PARAMETROV<br />
bomo skušali v izmerjenih paketih izvesti defragmentacijo zajetih paketov, ki<br />
pripadajo datagramu, prenesenemu iz izvornega do ciljnega IP naslova.<br />
Slika 5.19:<br />
Podatki, zajeti z vohljačem, <strong>in</strong> iskanje maksimalne dolž<strong>in</strong>e paketov ter seštevanje le-teh.<br />
Z vohljačem zajet promet smo preuredili na sledeči nač<strong>in</strong>. Poiskali smo maksimalno<br />
dolž<strong>in</strong>o paketa, ki v primeru testnega signala 1 znaša 1502 B. Nato smo temu paketu<br />
prišteli naslednjo dolž<strong>in</strong>o paketa istega IP naslova. V primeru, da je ta paket ponovno<br />
znašal 1502 B, smo iskali naslednji paket istega IP naslova. Postopek smo ponavljali<br />
tako dolgo, dokler nismo našli paketa s tega IP naslova, ki ni imel maksimalne<br />
dolž<strong>in</strong>e (slika 5.19). Slika 5.20 prikazuje razliko med histogramoma <strong>in</strong> izbrano<br />
porazdelitvijo v primeru neupoštevanja <strong>in</strong> upoštevanja predlagane metode.<br />
Slika 5.20: Primerjava histogramov <strong>in</strong> vrednosti parametrov porazdelitev v primeru upoštevanja<br />
maksimalne dolž<strong>in</strong>e paketov (leva slika) <strong>in</strong> seštevanje maksimalnih paketov s<br />
predlagano metodo (desna slika).
DOLOČANJE OSNOVNIH PARAMETROV<br />
41<br />
Slika 5.21: Primerjava modeliranih prometov z določenima porazdelitvama <strong>in</strong> pripadajočimi<br />
parametri na sliki 5.20 (scenarij 1: Paretova porazdelitev α = 0,89459, k = 432; scenarij<br />
2: Paretova porazdelitev α = 1,0695, k = 432). Srednja vrednost izmerjenega <strong>prometa</strong><br />
znaša 114517,6 b/s.<br />
Iz slike 5.21 vidimo, da v primeru upoštevanja maksimalne dolž<strong>in</strong>e paketov (MTU =<br />
1502 B) modeliramo promet, katerega srednja vrednost zelo odstopa od izmerjenega<br />
<strong>prometa</strong>. Srednja vrednost modeliranega signala znaša 389163,7 b/s (389,2 kb/s). V<br />
primeru uporabe metode seštevanja, ki smo jo opisali zgoraj, se srednja vrednost<br />
modeliranega signala približa srednji vrednosti izmerjenega signala 114517,6 b/s<br />
(114,5 kb/s). Srednja vrednost modeliranega signala v simulaciji 'scenarij 1' je<br />
znašala 121732 b/s (121,7 kb/s).<br />
V OPNET simulacijah s pomočjo generatorja <strong>prometa</strong> (opis še sledi) generiramo<br />
le efektivni promet, kateremu se nato doda še zaglavje za vsak paket. Zato smo iz<br />
zajetega <strong>prometa</strong> vsakemu paketu odšteli dolž<strong>in</strong>o zaglavja, ki v primeru IP protokola<br />
znaša 20 B. Z odštevanjem dolž<strong>in</strong>e glave <strong>in</strong> defragmentacijo maksimalnih paketov<br />
smo preuredili podatke o velikosti paketov o zajetem prometu, ki smo jih uporabili v<br />
analizi ter ocenitvi potrebnih parametrov.
42 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
6. GENERIRANJE OMREŽNEGA PROMETA V OPNETU<br />
6.1 Simulacijsko okolje OPNET<br />
OPNET Modeler je vodilno razvojno simulacijsko okolje v <strong>in</strong>dustriji, ki je<br />
namenjeno modeliranju <strong>in</strong> simuliranju komunikacijskih omrežij. Omogoča<br />
konstruiranje <strong>in</strong> študij komunikacijskih <strong>in</strong>frastruktur, naprav, protokolov, aplikacij. Z<br />
njim pa je omogočen tudi grafični nač<strong>in</strong> opisa topologije omrežij, tako žičnih kot<br />
brezžičnih. Grafični predstavitvi omrežja je namenjen urejevalnik omrežja. Temu<br />
sledi urejevalnik naprav, ki zagotovi vpogled v arhitekturo posameznih naprav s<br />
podatkovnimi toki med funkcijskimi elementi – moduli. Najnižji nivo predstavlja<br />
procesni urejevalnik, ki temelji na specifikaciji naprav s končnimi avtomati (F<strong>in</strong>ite<br />
State Mach<strong>in</strong>e – FSM). Vsako stanje v procesnem modulu vključuje C/C++ kodo, ki<br />
jo je mogoče sprem<strong>in</strong>jati. S tem je zagotovljen nadzor nad vsakim nivojem,<br />
neodvisno od tega, v kakšne podrobnosti se spustimo. Modeler je podprt s knjižnico<br />
naprav, ki pokriva vsa področja telekomunikacij z naprednimi tehnologijami <strong>in</strong><br />
ponuja rešitev za proučevanje ter <strong>simuliranje</strong> najbolj zapletenih situacij v omrežjih.<br />
Kot mnogi drugi raziskovalci <strong>samopodobnega</strong> omrežnega <strong>prometa</strong> smo tudi mi za<br />
izvedbo simulacij uporabili simulacijsko okolje OPNET Modeler [14], [24], [25],<br />
[26].<br />
6.2 Modeliranje <strong>prometa</strong> v simulacijskem okolju OPNET<br />
V programu OPNET Modeler imamo možnost generiranja <strong>samopodobnega</strong><br />
podatkovnega <strong>prometa</strong> na naslednje nač<strong>in</strong>e:<br />
• porazdelitve verjetnosti,<br />
• aplikacijski podatkovni model,<br />
• generator golih paketov,<br />
• zunanja datoteka.<br />
6.2.1 Porazdelitve verjetnosti<br />
Nekatere postaje iz knjižnice v programskem paketu OPNET omogočajo <strong>modeliranje</strong><br />
<strong>prometa</strong> z izbiro statističnih karakteristik, ki jim določimo osnovne parametre. Z<br />
izbiro počasi pojemajočih porazdelitev, kot sta Paretova <strong>in</strong> Weibullova, lahko<br />
modeliramo samopodoben promet. Na voljo imamo okoli 15 najrazličnejših<br />
porazdelitev verjetnosti. Slika 6.1 prikazuje možnost modeliranja <strong>prometa</strong> z<br />
generatorjem <strong>prometa</strong>, ki temelji na porazdelitvah verjetnosti za čas med paketi <strong>in</strong><br />
velikostjo paketov.
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
43<br />
Slika 6.1:<br />
Modeliranje <strong>prometa</strong> z generatorjem <strong>prometa</strong> na osnovi verjetnostnih porazdelitev.<br />
Dodajamo lahko neomejeno število vrstic, ki def<strong>in</strong>irajo med seboj neodvisne<br />
generatorje <strong>prometa</strong>. Končni modeliran promet je skupek (superpozicija) posameznih<br />
generatorjev <strong>prometa</strong>. Obstajajo modeli generiranja <strong>samopodobnega</strong> <strong>prometa</strong> s<br />
superpozicijo neodvisnih Bernoullijevih izvorov. Osnovni problem teh modelov je<br />
iskanje pravih parametrov modela želenih karakteristik.<br />
6.2.2 Aplikacijski podatkovni model<br />
OPNET Modeler vsebuje skup<strong>in</strong>o osnovnih modelov generiranja <strong>prometa</strong>, ki<br />
temeljijo na standardnih aplikacijah, kot so: FTP, HTTP, email itd. Zraven ponujenih<br />
modelov lahko sami izdelamo aplikacijo z želenimi lastnostmi. Standardni modeli so<br />
zasnovani na arhitekturi strežnik-odjemalec, ki jo najdemo v realnih omrežjih.<br />
Samopodoben promet lahko modeliramo na več nač<strong>in</strong>ov. Vse metode temeljijo na<br />
počasi pojemajočih porazdelitvah.<br />
6.2.3 Generator golih paketov<br />
Generator golih paketov (Raw Packet Generator – RPG) je podatkovni model izvora,<br />
implementiran posebej za <strong>modeliranje</strong> <strong>samopodobnega</strong> <strong>prometa</strong>. Postajo lahko<br />
uporabljamo za generiranje podatkovnega <strong>samopodobnega</strong> <strong>prometa</strong> na omrežnem<br />
(IP) <strong>in</strong> fizičnem nivoju standardnega modela. Generiranje <strong>samopodobnega</strong> <strong>prometa</strong><br />
temelji na implementaciji fraktalnih točkovnih procesov.<br />
6.2.4 Zunanja datoteka<br />
Za Ethernet postaje lahko določimo čas med paketi <strong>in</strong> velikost paketov iz zunanje<br />
datoteke. Tako lahko izdelamo samopodoben promet v drugih programskih okoljih<br />
(Matlab) <strong>in</strong> jih nato vnesemo v programski paket OPNET.
44 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
6.3 Generator golih paketov<br />
Za <strong>modeliranje</strong> <strong>samopodobnega</strong> <strong>prometa</strong> uporabimo generator golih paketov (RPG).<br />
V knjižnici RPG imamo na voljo tri različne RPG postaje. Ethernet RPG postaja<br />
omogoča komuniciranje na fizičnem nivoju, Ethernet RPG delovna postaja omogoča<br />
komunikacijo na IP nivoju, prav tako kot ppp RPG delovna postaja s serijskim<br />
vmesnikom. Za posamezne postaje lahko določimo naslednje parametre, ki jih<br />
prikazuje slika 6.2.<br />
Slika 6.2:<br />
Nastavljivi atributi generatorja paketov.<br />
• Povprečna hitrost prihodov (Average Arrival Rate – AAR): Def<strong>in</strong>ira<br />
povprečno vrednost <strong>in</strong>tenzivnosti prihodov skupnega <strong>prometa</strong>, ki je generiran<br />
kot skupek vseh izvorov paketov. Vpisana vrednost pomeni količ<strong>in</strong>o paketov<br />
na sekundo <strong>in</strong> skupaj s porazdelitvijo velikosti paketov vpliva na srednjo<br />
vrednost generiranega <strong>prometa</strong>.<br />
• Hurstov parameter (Hurst parameter): Predstavlja merilo samopodobnosti, ki<br />
ga določimo za proces števila prihodov paketov na časovno enoto.<br />
Karakterizira samopodobnost podatkovnega izvora. Ta parameter določa<br />
parameter oblike Paretove porazdelitve verjetnosti.<br />
• Časovna enota pojavljanja fraktalov (Fractal Onset Time Scale – FOTS):<br />
Predstavlja najmanjšo časovno enoto, znotraj katere se začnejo pojavljati<br />
fraktali. Skupaj s Hurstovim parametrom določa vrednost parametra lokacije<br />
Paretove porazdelitve. Vrednost časovne enote pojavljanja fraktalov (FOTS)<br />
v prometu Ethernet omrežja se nahaja med 100 ms <strong>in</strong> 1 sekundo.<br />
• Razmerje aktivnih izvorov (Source Activity Ratio – SAR): Def<strong>in</strong>ira odstotek<br />
časa, v katerem je vsaj eden od neodvisnih preklopnih on/off izvorov v<br />
aktivnem stanju. Vrednosti se nahajajo med 0 <strong>in</strong> 100. Ta parameter je težko<br />
določiti, zato veliko raziskovalcev priporoča izbiro vrednosti 75 %.<br />
• Razmerje med nivojem konic <strong>in</strong> srednjo vrednostjo (Peak to Mean Ratio –<br />
P2MR): Def<strong>in</strong>ira razmerje med vrednostmi konic <strong>prometa</strong> <strong>in</strong> srednjo
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
45<br />
vrednostjo omrežnega <strong>prometa</strong>. Vrednost tega parametra mora biti večja kot<br />
1. S tem parametrom prilagodimo želeno varianco skupnega <strong>prometa</strong>.<br />
• Velikost paketov (Packet Size): Velikost paketov def<strong>in</strong>iramo s porazdelitvijo<br />
verjetnosti velikosti paketov v bitih. Skupaj s parametrom AAR def<strong>in</strong>ira<br />
povprečno vrednost generiranega <strong>prometa</strong>. Za generiranje paketov so<br />
pomembne le velikosti paketov med 26 B <strong>in</strong> 1480 B (46 B <strong>in</strong> 1500 B z IP<br />
zaglavjem). Paketi, manjši od 46 B, bodo avtomatsko spremenjeni na<br />
m<strong>in</strong>imalno dolž<strong>in</strong>o paketov, paketi, večji od maksimalne dolž<strong>in</strong>e paketov<br />
1500 B, bodo fragmentirani v manjše pakete, katerim bodo dodana tudi<br />
pripadajoča IP zaglavja.<br />
• Začetni čas (Start Time): Čas začetka generiranja <strong>prometa</strong>.<br />
6.3.1 Fraktalni točkovni procesi<br />
Generiranje <strong>samopodobnega</strong> <strong>prometa</strong> z generatorji <strong>prometa</strong> temelji na fraktalnih<br />
točkovnih procesih (Fractal Po<strong>in</strong>t Processes – FPP), ki nam omogočajo <strong>modeliranje</strong><br />
<strong>samopodobnega</strong> <strong>prometa</strong> v simulacijskem okolju OPNET [28].<br />
Stacionarni proces v širšem pomenu X = {X n , n ∈ Z + } imenujemo asimptotično<br />
samopodoben proces drugega reda, če proces X nima neizrojene korelacijske<br />
strukture, kar pomeni, da agregiran proces orig<strong>in</strong>alnega procesa X preko veliko<br />
<strong>in</strong>tervalov ne vpliva na korelacijsko strukturo. Označimo z dN(t) točkovni proces <strong>in</strong> z<br />
t<br />
N ( t)<br />
= ∫ dN(<br />
s)<br />
pripadajoči števni proces (število prihodov v času t). Def<strong>in</strong>iramo<br />
o<br />
časovno zaporedje X = {X n , n ∈ Z + } kot<br />
[ nT ] − N[ ( n 1 ]<br />
X ( n)<br />
≡ N<br />
− )<br />
(6.1)<br />
s<br />
T s<br />
število prihodov med n-tim <strong>in</strong>tervalom trajanja T s . Tako točkovni proces dN(t)<br />
ponuja proces za konstruiranje X. Domnevamo, da je proces X stacionaren v širšem<br />
pomenu s povprečjem µ = E(X), varianco σ 2 = Var[X n ] <strong>in</strong> avtokorelacijsko funkcijo<br />
r(k,T s ) = Cov(X n , X n+k )/σ 2 . Označimo s F(T) <strong>in</strong>deks razpršenosti štetja, ki ga<br />
def<strong>in</strong>iramo kot F(T) = Var[N(t)]/E[N(t)]. Oznaka S(f) predstavlja spektralno gostoto<br />
moči točkovnega procesa dN(t).<br />
Če je proces X asimptotično samopodoben proces drugega reda, potem kaže vsaj<br />
tri lastnosti naslednjih karakteristik preko širokega območja časovne ali frekvenčne<br />
skale:<br />
α<br />
( T)<br />
≈ a T (počasi padajoča varianca) (6.2)<br />
F<br />
1<br />
−(1−α<br />
)<br />
r(<br />
k,<br />
Ts ) ≈ a2k<br />
(dolgo območje odvisnosti) (6.3)<br />
−α<br />
S( f ) ≈ a3<br />
f (šum 1/f) (6.4)<br />
za vrednosti parametra 0 < α < 1 ter pozitivne konstante α i (i = 1, 2, 3, …). Konstanto<br />
α imenujemo fraktalni eksponent, ki je v relaciji s Hurstovim parametrom, <strong>in</strong> sicer<br />
α = 2H – 1. Če je proces X konstruiran iz modela FPP, potem je X asimptotično<br />
samopodoben proces drugega reda:<br />
α<br />
F( T ) = 1+<br />
( T / T0 ) , T ≥ 0<br />
(6.5)
46 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
α + 1 α + 1<br />
α+<br />
1<br />
[( k + 1)<br />
− 2k<br />
+ ( k −1)<br />
] , k = 1,2,3, K<br />
α<br />
TS<br />
1<br />
r(<br />
k,<br />
T ) = ⋅<br />
(6.6)<br />
s α α<br />
T + T 2<br />
S<br />
0<br />
− α<br />
[ 1 + ( f / f ) ] , f 0<br />
S ( f ) = λ<br />
0<br />
><br />
(6.7)<br />
kjer sta T 0 <strong>in</strong> f 0 pozitivni konstanti <strong>in</strong> λ=E[N(t)]/t povprečna <strong>in</strong>tenzivnost.<br />
Razvitih je bilo več izvorov generiranja <strong>samopodobnega</strong> <strong>prometa</strong>, ki temeljijo na<br />
fraktalno točkovnih procesih. V simulacijskem okolju OPNET imamo vgrajenih več<br />
FPP modelov (slika 6.3) [27], [28]:<br />
Slika 6.3:<br />
Delitev fraktalno točkovnih procesov (FPP) na več podprocesov.<br />
Procese obnavljanja fraktalov sestavljata dve skup<strong>in</strong>i, <strong>in</strong> sicer procesi obnavljanja<br />
fraktalov (Fractal Renewal Processes – FRP) <strong>in</strong> superpozicija procesov obnavljanja<br />
fraktalov (sup-FRP). Model Sup-FRP je konstruiran iz več M FRP procesov, ki jih<br />
bomo natančneje opisali v nadaljevanju.<br />
FMPP (Fractal Modulated Poisson Processes) sestavlja dve skup<strong>in</strong>i procesov.<br />
Zelo pomemben <strong>in</strong> velikokrat uporabljen je model On-Off, ki temelji na M med seboj<br />
neodvisnih preklopnih (On/Off) procesih, ki lahko zavzamejo le dve stanji.<br />
Def<strong>in</strong>iramo lahko tri različne oblike On/Off FMPP procesov glede na njihove<br />
porazdelitve (PowOn-PowOff, PowOn-ExpOff <strong>in</strong> ExpON-PowOn). Za posamezne<br />
postaje lahko določimo parametre, prikazane v tabeli 6.1 glede na izbran fraktalni<br />
točkovni proces.<br />
Tabela 6.1:<br />
Določanje parametrov glede na izbran fraktalni točkovni proces.<br />
Sup‐FRP<br />
PowOn ExpON PowOn<br />
F‐FSNDP F‐FSNDP<br />
H‐FSNDP<br />
PowOff PowOff ExpOff<br />
EF FF<br />
H X X X X X X X<br />
µ X X X X X X X<br />
FOTS X X X X X X X<br />
P2MR X X<br />
SAR X X X
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
47<br />
6.3.2 Proces obnavljanja fraktalov<br />
Superpozicija procesov obnavljanja fraktalov (Sub-FRP) je def<strong>in</strong>irana kot<br />
superpozicija M neodvisnih verjetnostno identičnih procesov obnavljanja fraktalov.<br />
FRP je tok točkovnih procesov obnavljanja fraktalov, ki sestavljajo model sup-FRP z<br />
osnovnimi gostotami verjetnosti vmesnih prihodov p(τ). Uporabimo naslednjo<br />
gostoto verjetnosti:<br />
p<br />
⎧γA<br />
⎨<br />
⎩ γe<br />
e<br />
−1<br />
−γt<br />
/ A<br />
( t)<br />
=<br />
−γ<br />
γ −(<br />
γ + )<br />
A t<br />
0 ≤ t ≤ A⎫<br />
1 ⎬<br />
t ≥ A ⎭<br />
(6.8)<br />
kjer je 1 < γ < 2. Proces FRP označujemo kot Sup-FRP proces, pri katerem je število<br />
izvorov obnavljanja fraktalov (M) enako 1.<br />
Slika 6.4:<br />
Proces Sup-FRP kot superpozicija M neodvisnih identičnih procesov obnavljanja<br />
fraktalov [28].<br />
Sup FRP ima tri parametre, <strong>in</strong> sicer γ, A <strong>in</strong> M. γ je fraktalni eksponent, A je parameter<br />
rezanja <strong>in</strong> M je število izvorov. Te tri poglavitne parametre povežemo s parametri v<br />
OPNET-u, <strong>in</strong> sicer s Hurstovim parametrom, <strong>in</strong>tenziteto prihodov λ <strong>in</strong> časovno enoto<br />
pojavljanja fraktalov T, na sledeči nač<strong>in</strong>:<br />
λ<br />
H = ( 3 − γ ) / 2<br />
(6.9)<br />
−1<br />
-γ<br />
-1 -1<br />
= Mγ[ 1 + ( γ −1)<br />
e ] A<br />
(6.10)<br />
-1 2 1 2<br />
T α − −<br />
2 e γ −<br />
= γ ( γ −1) (2 −γ)(3 − γ)[1 + ( γ − 1) e γ ] A<br />
α , (6.11)<br />
kjer je γ = 2 – β. Hurstov parameter H je v povezavi s parametrom β s predpisom<br />
β = 2H – 1. Modelu FRP v OPNET-u nastavljamo Hurstov parameter (H), povprečno<br />
<strong>in</strong>tenziteto paketov na sekundo (λ) <strong>in</strong> parameter časovne enote pojavljanja fraktalov<br />
(FOTS) v sekundah. Privzeta vrednost FOTS v OPNET-u je 1 s.
48 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
6.4 IP postaja<br />
IP postaja za razliko od RPG generatorja ni namenska postaja za generiranje<br />
<strong>samopodobnega</strong> omrežnega <strong>prometa</strong>, vendar lahko s pravo izbiro verjetnostnih<br />
porazdelitev prav tako modeliramo samopodoben promet. IP postaja je enostavna<br />
postaja za <strong>simuliranje</strong> razmer v IP omrežjih. Omrežni promet lahko generiramo s<br />
pomočjo generatorja <strong>prometa</strong>. V tem primeru promet def<strong>in</strong>iramo le z dvema<br />
porazdelitvama verjetnosti, <strong>in</strong> sicer:<br />
• čas med paketi: čas med paketi def<strong>in</strong>iramo z izbiro porazdelitve verjetnosti<br />
ter določitvijo njenih parametrov. Vpisana vrednost parametrov za izbrano<br />
porazdelitev določa naključni čas med paketi, ki skupaj s porazdelitvijo<br />
velikosti paketov vpliva na srednjo vrednost modeliranega <strong>prometa</strong>.<br />
• velikost paketov: velikost paketov def<strong>in</strong>iramo s porazdelitvijo verjetnosti<br />
velikosti paketov v bitih. Velikost paketov se nahaja med vrednostmi 26 B <strong>in</strong><br />
1480 B (46 B <strong>in</strong> 1500 B z IP zaglavjem), kot v primeru RPG postaje.<br />
Slika 6.5:<br />
IP postaja z nastavljivimi atributi.<br />
Slika 6.5 prikazuje parametre, s katerimi modeliramo promet IP postaje. Porazdelitev<br />
verjetnosti velikosti paketov <strong>in</strong> porazdelitev verjetnosti časa med paketi določata<br />
povprečno vrednost generiranega <strong>prometa</strong>.<br />
6.5 Simulacije v OPNETu<br />
V simulacijskem okolju bomo skušali modelirati testne izmerjene signale (promet),<br />
ki bodo temeljili na izmerjenih parametrih. Modelirali bomo le testna signala 1 <strong>in</strong> 3.<br />
Testnega signala 2 ne bomo modelirali zaradi premalo zajetih paketov. S<br />
simulacijami v programskem paketu OPNET bomo pokazali vpliv velikosti<br />
Hurstovega parametra na pogostost izbruhov v prometu. Večji je Hurstov parameter,<br />
več izbruhov vsebuje promet.
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
49<br />
6.5.1 Vpliv parametra H na modelirani promet<br />
Z RPG postajo smo modelirali promet z različnimi velikostmi Hurstovega parametra.<br />
Parametre modeliranih prometov prikazuje tabela 6.2, promete v p/s <strong>in</strong> b/s z<br />
različnimi vrednostmi parametra H prikazujejo slike od 6.6 do 6.9.<br />
Tabela 6.2: Parametri modeliranih signalov.<br />
FPP Hurstov pov. FOTS velikost paketov<br />
parameter vred. p/s (s)<br />
signal 1 Sup‐FRP 0,6 100 1 Pareto (α = 1,2; k = 10)<br />
signal 2 Sup‐FRP 0,7 100 1 Pareto (α = 1,2; k = 10)<br />
signal 3 Sup‐FRP 0,8 100 1 Pareto (α = 1,2; k = 10)<br />
signal 4 Sup‐FRP 0,9 100 1 Pareto (α = 1,2; k = 10)<br />
Slika 6.6:<br />
Samopodoben modeliran promet s parametrom H = 0,6 v paketih/s (levo) <strong>in</strong> v b/s<br />
(desno).<br />
Slika 6.7:<br />
Samopodoben modeliran promet s parametrom H = 0,7 v paketih/s (levo) <strong>in</strong> v b/s<br />
(desno).
50 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
Slika 6.8:<br />
Samopodoben modeliran promet s parametrom H = 0,8 v paketih/s (levo) <strong>in</strong> v b/s<br />
(desno).<br />
Slika 6.9:<br />
Samopodoben modeliran promet s parametrom H = 0,9 v paketih/s (levo) <strong>in</strong> v b/s<br />
(desno).<br />
Slika 6.11: Primerjava <strong>prometa</strong> (p/s) z različnimi vrednostmi parametra H (levo) ter povprečna<br />
vrednost paketov na sekundo v odvisnosti od parametra H (desno) (scenarij 1: H = 0,6;<br />
scenarij 2: H = 0,7; scenarij 3: H = 0,8; scenarij 4: H = 0,9).
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
51<br />
Slika 6.12:<br />
Primerjava <strong>prometa</strong> z različnimi vrednostmi parametra H (levo) ter povprečna vrednost<br />
bitov na sekundo v odvisnosti od parametra H (desno) (scenarij 1: H = 0,6; scenarij 2:<br />
H = 0,7; scenarij 3: H = 0,8; scenarij 4: H = 0,9).<br />
Iz slik 6.11 <strong>in</strong> 6.12, ki prikazujejo primerjavo modeliranih prometov z različnimi<br />
Hurstovimi parametri, razberemo, da promet v p/s z večjo vrednostjo parametra H<br />
vsebuje več izbruhov. Vendar vrednost Hurstovega parametra ne vpliva bistveno na<br />
srednjo vrednost paketov na sekundo kot tudi ne na srednjo vrednost bitov na<br />
sekundo.<br />
6.5.2 Vpliv parametra časovne enote pojavljanja fraktalov na<br />
modeliran promet<br />
Časovno enoto pojavljanja fraktalov (Fractal Onset Time Scale – FOTS) smo opisali<br />
kot najmanjšo časovno enoto, v kateri se pojavljajo fraktali. Vrednost FOTS v<br />
prometu ethernet omrežja se nahaja med vrednostmi 100 ms <strong>in</strong> 1 s. V naslednjem<br />
poizkusu bomo videli, kako izbira velikosti parametra FOTS vpliva na modeliran<br />
promet. Izbrali smo tri različne vrednosti FOTS, <strong>in</strong> sicer 1 s, 10 s <strong>in</strong> 100 s.<br />
Slika 6.13: Modeliran promet s Hurstovim parametrom H = 0,6 <strong>in</strong> tremi različnimi vrednostmi<br />
parametra FOTS (scenarij 1: FOTS = 1; scenarij 2: FOTS = 10; scenarij 3:<br />
FOTS = 100).
52 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
Iz modeliranega <strong>prometa</strong> na sliki 6.13 ne vidimo izrazitega vpliva parametra<br />
FOTS na modeliran promet. Vpliv velikosti parametra FOTS razberemo v<br />
modeliranem prometu, če opazujemo njegovo povprečno vrednost v bitih na<br />
sekundo, kar prikazuje slika 6.14. V primeru velike vrednosti parametra FOTS<br />
srednja vrednost zelo odstopa od želene, vendar preide po določenem času v želeno<br />
stacionarno stanje, kjer je ta prehodni čas odvisen prav od velikosti parametra FOTS.<br />
Večji je ta parameter, več časa je potrebno, da doseže modeliran promet želeno<br />
stacionarno vrednost.<br />
Slika 6.14: Modeliran promet (srednja vrednost v bitih na sekundo) s Hurstovim parametrom H =<br />
0,6 <strong>in</strong> tremi različnimi parametri FOTS (scenarij 1: FOTS = 1; scenarij 2: FOTS = 10;<br />
scenarij 3: FOTS = 100).<br />
6.5.3 Modeliranje testnega signala 1<br />
S pomočjo ocenjevanja Hurstovih parametrov ter določanja porazdelitve verjetnosti<br />
<strong>in</strong> njenih parametrov smo določili vse potrebne parametre za <strong>modeliranje</strong><br />
izmerjenega testnega signala 1, ki jih prikazuje tabela 6.3. Testni signal 1 smo<br />
modelirali na šest različnih nač<strong>in</strong>ov ter med seboj primerjali rezultate. Iz modeliranih<br />
prometov (signalov) smo nato izbrali promet, ki je najboljši približek izmerjenega<br />
<strong>prometa</strong>. Najprej smo modelirali dva <strong>prometa</strong> s pomočjo RPG postaje (Hurstov<br />
parameter za proces prihodov paketov ter Paretovo <strong>in</strong> eksponentno porazdelitev za<br />
velikosti paketov). Naslednje štiri modelirane promete smo modelirali s pomočjo IP<br />
postaje. V tretjem <strong>in</strong> četrtem scenariju smo za <strong>modeliranje</strong> uporabili Weibullovo <strong>in</strong><br />
eksponentno porazdelitev verjetnosti za časa med paketi <strong>in</strong> eksponentno porazdelitev<br />
za velikost paketov. Pri zadnjih dveh scenarijih smo za velikost paketov uporabili<br />
Paretovo porazdelitev, za čas med paketi pa Weibullovo <strong>in</strong> eksponentno verjetnostno<br />
porazdelitev. Slika 6.15 kaže izbiro porazdelitve verjetnosti za velikost paketov<br />
testnega signala 1. V primeru izbire porazdelitve verjetnosti za proces časa med<br />
paketi za najprimernejšo počasi pojemajoče verjetnostne porazdelitve izberemo<br />
Weibullovo namesto Paretovo verjetnostno porazdelitev ter za primerjavo še<br />
eksponentno porazdelitev (slika 6.16).
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
53<br />
Slika 6.15: Izbira Paretove (zelena krivulja) <strong>in</strong> eksponentne porazdelitve (modra krivulja) za<br />
velikost paketov. Primerjava gostote verjetnosti (levo – zgoraj), kumulativne<br />
porazdelitvene funkcije (desno – zgoraj), razlike med teoretičnima <strong>in</strong> empiričnima<br />
porazdelitvama v P-P grafu (levo – spodaj) <strong>in</strong> verjetnostne diference med teoretičnima<br />
<strong>in</strong> numeričnima porazdelitvama (desno – spodaj).<br />
Parametre modeliranih prometov ter izmerjenega <strong>prometa</strong> s pripadajočimi srednjimi<br />
vrednostmi prikazuje tabela 6.3.<br />
Tabela 6.3: Parametri izmerjenega testnega signala 1 <strong>in</strong> modeliranih testnih signalov.<br />
izmerjen<br />
signal<br />
modeliran<br />
signal 1<br />
modeliran<br />
signal 2<br />
modeliran<br />
signal 3<br />
modeliran<br />
signal 4<br />
modeliran<br />
signal 5<br />
modeliran<br />
signal 6<br />
dolž<strong>in</strong>a<br />
sig.(s)<br />
čas med paketi<br />
(parametri)<br />
velikost paketov<br />
(parametri)<br />
pov. vred.<br />
(p/s)<br />
pov. vred. (b/s)<br />
241,5 X X 35,612 114517,6<br />
241,5 H = 0,55<br />
241,5 H = 0,55<br />
241,5<br />
241,5<br />
241,5<br />
241,5<br />
eksponentna<br />
λ = 0,029<br />
Weibull α = 0,57<br />
β = 0,01894<br />
Weibull α = 0,57<br />
β = 0,01894<br />
eksponentna<br />
λ = 0,029<br />
Pareto α = 0,8373<br />
β = 272<br />
eksponentna<br />
λ = 3619,9<br />
eksponentna<br />
λ = 452,48<br />
eksponentna<br />
λ = 452,48<br />
Pareto α = 0,8373<br />
β = 34<br />
Pareto α = 0,8373<br />
β = 34<br />
49,46 231987,7<br />
36,71 140725,6<br />
35,66 135897,6<br />
33,05 126793,2<br />
52,27 298250,2<br />
55,12 315619,5
54 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
Slika 6.16: Izbira Weibullove (zelena krivulja) <strong>in</strong> eksponentne porazdelitve (modra krivulja).<br />
Primerjava gostote verjetnosti (levo – zgoraj), kumulativne porazdelitvene funkcije<br />
(desno – zgoraj), razlike med teoretičnima <strong>in</strong> empiričnima porazdelitvama v P-P grafu<br />
(levo – spodaj) <strong>in</strong> verjetnostne diference med teoretičnima <strong>in</strong> numeričnima<br />
porazdelitvama (desno – spodaj).<br />
Slika 6.17: Signali modelirani z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo verjetnostnih<br />
porazdelitev (p/s).
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
55<br />
Slika 6.18:<br />
Povprečna vrednost signalov modeliranih z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo<br />
verjetnostnih porazdelitev (p/s).<br />
Slika 6.19: Signali modeliranih z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo verjetnostnih<br />
porazdelitev (b/s).<br />
Slika 6.20:<br />
Povprečna vrednost signalov modeliranih z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo<br />
verjetnostnih porazdelitev (b/s).
56 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
Iz slik od 6.17 do 6.20 vidimo, da lahko promet modeliramo z različnimi nač<strong>in</strong>i<br />
modeliranja procesa prihodov paketov, <strong>in</strong> sicer s pomočjo Hurstovega parametra<br />
(RPG postaja) <strong>in</strong> s pomočjo verjetnostnih porazdelitev. Vseh šest modeliranih<br />
prometov se razlikuje tako po srednji vrednosti v paketih na sekundo kot v bitih na<br />
sekundo, razlikujejo pa se tudi po sami obliki. Predvsem odstopajo primeri, v katerih<br />
smo za proces velikost paketov izbrali Paretovo porazdelitev verjetnosti za velikost<br />
paketov, katera povzroči pojavljanje konic v modeliranem prometu (scenariji 1, 5, 6).<br />
Torej se izkaže Paretova porazdelitev primerna za <strong>modeliranje</strong> <strong>prometa</strong>, v katerem<br />
nastopajo konice, ki spremenijo delovanje <strong>in</strong> obnašanje omrežja. Testni signal, ki<br />
smo ga želeli modelirati, ne vsebuje konic ne v bitih na sekundo kot tudi ne v paketih<br />
na sekundo. Tako lahko iz rezultatov vidimo, da Paretova porazdelitev ni primerna<br />
za <strong>modeliranje</strong> <strong>prometa</strong>, ki ne vsebuje konic, katere zelo odstopajo od njegove<br />
srednje vrednosti.<br />
6.5.4 Modeliranje testnega signala 3<br />
Modeliranje testnega signala 3 smo izvedli na enak nač<strong>in</strong>, kot smo to izvedli v<br />
primeru testnega signala 1. Slika 6.21 prikazuje izbiro porazdelitev za velikost<br />
paketov, slika 6.22 pa prikazuje izbiro porazdelitve za čas med paketi. V tabeli 6.4 so<br />
zbrani parametri modeliranih signalov.<br />
Slika 6.21: Izbira Paretove (zelena krivulja) <strong>in</strong> eksponentne porazdelitve (modra krivulja).<br />
Primerjava gostote verjetnosti (levo – zgoraj), kumulativne porazdelitvene funkcije<br />
(desno – zgoraj), razlike med teoretičnima <strong>in</strong> empiričnima porazdelitvama v P-P grafu<br />
(levo – spodaj) <strong>in</strong> verjetnostne diference med teoretičnima <strong>in</strong> numeričnima<br />
porazdelitvama (desno – spodaj).
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
57<br />
Slika 6.22: Izbira Weibullove (zelena krivulja) <strong>in</strong> eksponentne porazdelitve (modra krivulja).<br />
Primerjava gostote verjetnosti (levo – zgoraj), kumulativne porazdelitvene funkcije<br />
(desno – zgoraj), razlike med teoretičnima <strong>in</strong> empiričnima porazdelitvama v P-P grafu<br />
(levo – spodaj) <strong>in</strong> verjetnostne diference med teoretičnima <strong>in</strong> numeričnima<br />
porazdelitvama (desno – spodaj).<br />
Tabela 6.4:<br />
izmerjen<br />
signal 1<br />
modeliran<br />
signal 1<br />
modeliran<br />
signal 2<br />
modeliran<br />
signal 3<br />
modeliran<br />
signal 4<br />
modeliran<br />
signal 5<br />
modeliran<br />
signal 6<br />
Parametri izmerjenega testnega signala 3 <strong>in</strong> modeliranih testnih signalov.<br />
dolž<strong>in</strong>a<br />
sig.(s)<br />
čas med paketi<br />
(parametri)<br />
velikost paketov<br />
(parametri)<br />
pov. vred.<br />
(p/s)<br />
pov. vred. (b/s)<br />
240 X X 24 108909,2<br />
240 H = 0,732<br />
240 H = 0,732<br />
240<br />
240<br />
240<br />
240<br />
eksponentna<br />
λ = 0,0458<br />
Weibull α = 0,304<br />
β = 0,00578<br />
Weibull α = 0,304<br />
β = 0,00578<br />
eksponentna<br />
λ = 0,0458<br />
Pareto α = 0,9835<br />
β = 432<br />
eksponentna<br />
λ = 7547,2<br />
eksponentna<br />
λ = 933,4<br />
eksponentna<br />
λ = 933,4<br />
Pareto α = 0,9835<br />
β = 34<br />
Pareto α = 0,9835<br />
β = 34<br />
28,92 91563,3<br />
39,94 254523,5<br />
49,00 311669,6<br />
48,67 309527,2<br />
43,85 132694,1<br />
45,97 145885,2
58 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
Slika 6.23: Signali modelirani z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo verjetnostnih<br />
porazdelitev (p/s).<br />
Slika 6.24:<br />
Povprečna vrednost signalov modeliranih z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo<br />
verjetnostnih porazdelitev (p/s).<br />
Slika 6.25: Signali modelirani z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo verjetnostnih<br />
porazdelitev (b/s).
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
59<br />
Slika 6.26:<br />
Povprečna vrednost signalov modeliranih z RPG <strong>in</strong> IP postajo ter različno komb<strong>in</strong>acijo<br />
verjetnostnih porazdelitev (b/s).<br />
Slike od 6.23 do 6.26 prikazujejo modelirane signale ter pripadajoče srednje<br />
vrednosti v p/s <strong>in</strong> b/s. Izmerjeni testni signal 3 vsebuje v svojem poteku posamezne<br />
konice. Kar je bilo v prvem primeru nezaželeno, postane v tem primeru zelo<br />
zaželeno. V veljavo stopijo počasi pojemajoče porazdelitve (Pareto), ki nam v<br />
modeliran promet vnesejo konice, ki jih vsebuje izmerjen promet. Tako so primeri<br />
(scenariji 3, 4, 5), kjer za <strong>modeliranje</strong> velikosti paketov uporabljamo eksponentno<br />
porazdelitev, neprimerni za <strong>modeliranje</strong> testnega signala 3, saj modeliran promet ne<br />
vsebuje konic. Odstopanje se pojavi tudi med srednjo vrednostjo izmerjenega <strong>in</strong><br />
modeliranega <strong>prometa</strong>.<br />
6.5.5 Primerjava izmerjenih <strong>in</strong> modeliranih signalov<br />
Na podlagi rezultatov, pridobljenih s simulacijo, bomo izbrali model <strong>prometa</strong>, ki je<br />
najboljši približek izmerjenega <strong>prometa</strong>. Za testni signal 1 smo ocenili Hurstov<br />
parameter ter na podlagi ocenjene vrednosti (H > 0,5) klasificirali promet kot<br />
samopodoben. Prometu pa ne moremo pripisati lastnosti dolgega območja odvisnosti,<br />
saj njegova avtokorelacijska funkcija ne pada hiperbolično <strong>in</strong> ima končno vsoto.<br />
Izmed modeliranih signalov smo za signal, ki najbolje opisuje ali je najboljši<br />
približek izmerjenega signala, izbrali modeliran signal 4, katerega čas med paketi<br />
smo opisali z Weibullovo počasi pojemajočo porazdelitvijo <strong>in</strong> velikost paketov z<br />
eksponentno porazdelitvijo verjetnosti.<br />
p/s<br />
80<br />
70<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
0<br />
1<br />
11<br />
21<br />
31<br />
41<br />
51<br />
61<br />
71<br />
81<br />
91<br />
101<br />
111<br />
121<br />
131<br />
141<br />
151<br />
161<br />
171<br />
181<br />
191<br />
201<br />
211<br />
221<br />
231<br />
čas (s)<br />
izmerjen promet<br />
modeliran promet<br />
Slika 6.27:<br />
Primerjava izmerjenega <strong>in</strong> modeliranega signala (p/s).
60 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
b/s<br />
300000<br />
250000<br />
200000<br />
150000<br />
100000<br />
50000<br />
0<br />
1<br />
11<br />
21<br />
31<br />
41<br />
51<br />
61<br />
71<br />
81<br />
91<br />
101<br />
111<br />
121<br />
131<br />
141<br />
151<br />
161<br />
171<br />
181<br />
191<br />
201<br />
211<br />
221<br />
231<br />
čas (s)<br />
modeliran promet<br />
izmerjen promet<br />
Slika 6.28:<br />
Primerjava izmerjenega <strong>in</strong> modeliranega signala (b/s).<br />
Sliki 6.27 <strong>in</strong> 6.28 prikazujeta primerjavo med izmerjenim testnim signalom 1 <strong>in</strong><br />
modeliranim prometov v p/s <strong>in</strong> b/s. Dodatno primerjavo izmerjenega <strong>in</strong> modeliranega<br />
signala smo izvedli s pomočjo določanja porazdelitve verjetnosti paketov <strong>in</strong> bitov na<br />
časovno enoto, ki je v našem primeru 1 s. Za izmerjeni <strong>in</strong> modelirani promet, ki smo<br />
ga nato izmerili, smo izračunali število paketov <strong>in</strong> število bitov na 1 s.<br />
Slika 6.29:<br />
Primerjava porazdelitve paketov na sekundo izmerjenega <strong>in</strong> modeliranega <strong>prometa</strong>. Na<br />
desni strani modeliran signal (normalna porazdelitev µ = 33,054, σ 2 = 11,352) <strong>in</strong> na levi<br />
izmerjen signal (normalna porazdelitev µ = 35,639, σ 2 = 9,8106).<br />
Slika 6.30: Primerjava porazdelitve bitov na sekundo izmerjenega <strong>in</strong> modeliranega <strong>prometa</strong>. Na<br />
desni strani modeliran signal (normalna porazdelitev µ = 136680, σ 2 = 29288) <strong>in</strong> na levi<br />
izmerjen signal (normalna porazdelitev µ = 1145800, σ 2 = 22177).
GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
61<br />
Iz slik 6.29 <strong>in</strong> 6.30 vidimo, da imata signala enako porazdelitev s podobnimi<br />
parametri, ki med seboj odstopajo. Odstopanje parametrov je posledica statističnih<br />
opisov naključnih procesov <strong>in</strong> napake pri izbiri verjetnostnih statistik ter ocenitve<br />
njihovih parametrov. Vendar rezultati pokažejo, da je modeliran signal dober<br />
približek izmerjenega signala.<br />
Izmed modeliranih signalov v drugem poizkusu smo za signal, ki je najboljši<br />
približek izmerjenega testnega signala 3, izbrali modeliran signal 5. Temu signalu<br />
smo čas med paketi določili z Weibullovo verjetnostno porazdelitvijo, velikost<br />
paketov pa s Paretovo porazdelitvijo verjetnosti. Sliki 6.31 <strong>in</strong> 6.32 prikazujeta<br />
primerjavo med izmerjenim testnim ignalom 3 <strong>in</strong> modeliranim prometov v p/s <strong>in</strong> b/s.<br />
600<br />
500<br />
400<br />
p/s<br />
300<br />
200<br />
100<br />
0<br />
1<br />
11<br />
21<br />
31<br />
41<br />
51<br />
61<br />
71<br />
81<br />
91<br />
101<br />
111<br />
121<br />
131<br />
141<br />
151<br />
161<br />
171<br />
181<br />
191<br />
201<br />
211<br />
221<br />
231<br />
čas (s)<br />
modeliran promet<br />
izmerjen promet<br />
Slika 6.31:<br />
Primerjava izmerjenega <strong>in</strong> modeliranega signala (p/s).<br />
b/s<br />
4000000<br />
3500000<br />
3000000<br />
2500000<br />
2000000<br />
1500000<br />
1000000<br />
500000<br />
0<br />
1<br />
12<br />
23<br />
34<br />
45<br />
56<br />
67<br />
78<br />
89<br />
100<br />
111<br />
122<br />
133<br />
144<br />
155<br />
166<br />
177<br />
188<br />
199<br />
210<br />
221<br />
232<br />
modeliran promet<br />
čas (s)<br />
izmerjen promet<br />
Slika 6.32:<br />
Primerjava izmerjenega <strong>in</strong> modeliranega signala (b/s).
62 GENERIRANJE OMREŽNEGA PROMETA V OPNET‐U<br />
Slika 6.33:<br />
Primerjava porazdelitve paketov na sekundo izmerjenega <strong>in</strong> modeliranega <strong>prometa</strong>. Na<br />
desni strani modeliran signal (Weibullova porazdelitev α = 1,5901, β = 32,656) <strong>in</strong> na<br />
levi izmerjen signal (normalna porazdelitev α = 1,0176, β = 15,175).<br />
Slika 6.34: Primerjava porazdelitve bitov na sekundo izmerjenega <strong>in</strong> modeliranega <strong>prometa</strong>. Na<br />
desni strani modeliran signal (Weibullova porazdelitev α = 0,845, β = 79548) <strong>in</strong> na levi<br />
izmerjen signal (normalna porazdelitev α = 0,59473, β = 17190).<br />
Primerjavo modeliranega <strong>in</strong> izmerjenega testnega signala 3 smo izvedli na enak<br />
nač<strong>in</strong> kot za testni signal 1. Prav tako smo izmerjenemu <strong>in</strong> modeliranemu signalu<br />
določili porazdelitev velikosti paketov <strong>in</strong> časa med paketi, <strong>in</strong> sicer v bitih <strong>in</strong> paketih<br />
na sekundo (slika 6.33 <strong>in</strong> 6.34). Tako za število bitov kot za število paketov na<br />
sekundo smo izbrali počasi pojemajočo verjetnostno porazdelitev, <strong>in</strong> sicer<br />
Weibullovo porazdelitev. Testni signal 3 smo modelirali s pomočjo porazdelitev<br />
Pareto, saj le-ti vnašajo v modeliran promet konice, ki jih vsebuje izmerjen promet.<br />
Primerjava porazdelitev verjetnosti je zelo težavna, saj se parametri med seboj<br />
razlikujejo. Veliko bolje je opazovati le histograme izmerjenih <strong>in</strong> modeliranih<br />
signalov. Vendar ob primerjavi srednje vrednosti opazimo, da v primerjavi paketov<br />
na sekundo modeliran signal nekoliko odstopa od srednje vrednosti paketov na<br />
sekundo izmerjenega signala. Ta razlika je veliko manjša kot v primeru bitov na<br />
sekundo.
VPLIV SAMOPODOBNEGA PROMETA NA ZMOGLJIVOST OMREŽJA<br />
63<br />
7. VPLIV SAMOPODOBNEGA PROMETA NA ZMOGLJIVOST<br />
OMREŽJA<br />
Zmogljivost omrežja je odvisna od omrežnih naprav <strong>in</strong> omrežnega <strong>prometa</strong>. Ta lahko<br />
vsebuje veliko izbruhov, ki vplivajo na čakalne vrste <strong>in</strong> pomnilnik, kar vpliva na<br />
zakasnitve <strong>in</strong> storitve v omrežju. Izbruhi v podatkovnem prometu lahko vplivajo na<br />
zakasnitve čakalnih vrst <strong>in</strong> na izgube paketov v primeru napolnitve pomnilnika.<br />
Izgube paketov v primeru napolnitve pomnilnika sicer lahko zmanjšamo s<br />
povečanjem pomnilnika, kar pa poveča zakasnitev v čakalnih vrstah. Pomnilniki v<br />
omrežnih napravah absorbirajo podatkovne izbruhe <strong>in</strong> pri tem vplivajo na kakovost<br />
storitev (QoS), ki so občutljive na zakasnitve. Sprem<strong>in</strong>janje zakasnitev ali tudi<br />
drhtenje signala je največkrat <strong>in</strong>terpretirana kot razlika v zakasnitvi od konca do<br />
konca dveh paketov v istem podatkovnem toku. S povečanjem velikosti pomnilnikov<br />
se povečuje tudi drhtenje, a s tem istočasno zmanjšamo možnost izgub posameznih<br />
paketov.<br />
Primer:<br />
V OPNET-u smo sestavili testno omrežje, s katerim bomo skušali pokazati vpliv<br />
modeliranega <strong>prometa</strong> na razmere v omrežju. Modelirali bomo samopodoben promet<br />
tako z eksponentno kot Paretovo porazdelitvijo. Topologijo testnega omrežja<br />
prikazuje slika 7.1. Postaji (selfsimilar_tx <strong>in</strong> exsponential_tx), s katerima bomo<br />
generirali promet, smo povezali na zvezdišče (hub_tx), tega pa nato na stikalo<br />
(switch_tx). Ti postaji generiran promet pošiljata sprejemnima postajama, ki sta<br />
povezani prav tako na zvezdišče (hub_rx) <strong>in</strong> stikalo (switch_rx), <strong>in</strong> sicer postaja<br />
selfsimilar_tx pošilja pakete postaji selfsimilar_rx, postaja exponential_tx pa postaji<br />
exponential_rx. Med stikaloma imamo povezavo 10 Mb/s, ostale povezave so pa 1<br />
Gb/s.<br />
Slika 7.1:<br />
Testno omrežje v simulacijskem okolju OPNET.
64 VPLIV SAMOPODOBNEGA PROMETA NA ZMOGLJIVOST OMREŽJA<br />
S postajo selfsimilar_tx <strong>in</strong> exponential_tx smo modelirali promet enake srednje<br />
vrednosti, <strong>in</strong> sicer okoli 110 kb/s. Samopodoben promet z lastnostjo dolgega<br />
območja odvisnosti smo modelirali s pomočjo Paretove porazdelitve verjetnosti za<br />
velikost paketov (α = 1,0689; β = 42) <strong>in</strong> Weilbullove porazdelitve verjetnosti za čas<br />
med paketi (α = 0,685; β = 0,01989). S porazdelitvama smo dosegli srednjo vrednost<br />
<strong>prometa</strong> 109,33 kb/s. S postajo exponential_tx smo modelirali samopodoben promet<br />
z lastnostjo kratke odvisnosti s srednjo vrednostjo 112,04 kb/s, <strong>in</strong> sicer z<br />
eksponentno porazdelitvijo za velikost paketov (λ = 350) <strong>in</strong> čas med paketi (λ =<br />
0,025). Promet, generiran s postajama selfsimilar_tx <strong>in</strong> exponential_tx, prikazuje<br />
slika 7.2.<br />
Slika 7.2:<br />
Prometa modelirana s postajama selfsimilar_tx <strong>in</strong> exponential_tx.<br />
Modelirana <strong>prometa</strong> imata približno enako srednjo vrednost, vendar imata zelo<br />
različno obliko, saj promet, modeliran s Paretovo porazdelitvijo verjetnosti, za<br />
velikosti paketov vsebuje konice (dolgo območje odvisnosti), ki jih lahko vidimo na<br />
sliki 7.2. Zanima nas, kako te konice vplivajo na zakasnitve v omrežju ter na<br />
pomnilnike v omrežnih napravah. Konice lahko povzročijo napolnitve pomnilnikov<br />
<strong>in</strong> s tem izgubo podatkov. Modeliran promete z eksponentno porazdelitvijo (kratko<br />
območje odvisnosti) je za razliko od <strong>prometa</strong>, modeliranega s Paretovo<br />
porazdelitvijo, bolj konstantne narave, saj ima manjšo varianco <strong>in</strong> ne vsebuje konic,<br />
ki bi zelo odstopale od srednje vrednosti modeliranega <strong>prometa</strong>.<br />
Skupno zakasnitev <strong>prometa</strong>, sprejetega na postajah selfsimilar_rx <strong>in</strong><br />
exponential_rx, prikazuje slika 7.3.
VPLIV SAMOPODOBNEGA PROMETA NA ZMOGLJIVOST OMREŽJA<br />
65<br />
Slika 7.3:<br />
Zakasnitve na sprejemni strani na postaji selfsimilar_rx <strong>in</strong> exponential_rx.<br />
Slika 7.3 prikazuje zakasnitve <strong>prometa</strong> na postaji exponential_rx <strong>in</strong> selfsimilar_rx. Iz<br />
zakasnitev v omrežju vidimo, da primer <strong>samopodobnega</strong> <strong>prometa</strong> z dolgim<br />
območjem odvisnosti vpliva na zakasnitve v večji meri kot samopodoben promet s<br />
kratkim območjem odvisnosti. Konice v prometu vplivajo na zakasnitve v omrežju<br />
brez ozkih grl, kjer imamo na voljo dovolj veliko pasovno šir<strong>in</strong>o (m<strong>in</strong> = 10Mb/s).<br />
Vendar se te zakasnitve pojavijo že na oddajni strani, <strong>in</strong> sicer zaradi zakasnitve<br />
čakalnih vrst. Zakasnitev čakalnih vrst je čas, ki je potreben za procesiranje paketov<br />
v omrežnih napravah, npr. v stikalu. Če je hitrost prihoda paketov v omrežno<br />
napravo večja kot ima omrežna naprava sposobnost oddajanja, jih omrežna naprava<br />
shrani v pomnilnik čakalne vrste, dokler jih ne odda. To se zgodi v primerih, ko ima<br />
promet veliko izbruhov.<br />
Zakasnitev čakalnih vrst je proporcionalna velikosti pomnilnika. Daljša je<br />
čakalna vrsta, daljše so zakasnitve paketov. Z zmanjšanjem velikosti pomnilnika<br />
dosežemo zmanjšanje čakalnih vrst, a se v tem primeru poveča verjetnost pojava, ki<br />
ga imenujemo napolnitev pomnilnika. Pakete, ki jih omrežna naprava ni sposobna<br />
shraniti, zato zavrže. Slika 7.4 prikazuje zakasnitve čakalnih vrst na postajah<br />
selfsimilar_tx <strong>in</strong> exponential_tx, s katerima smo generirali vhodna <strong>prometa</strong>.<br />
Iz primerjave skupne zakasnitve v testnem omrežju <strong>in</strong> zakasnitve čakalnih vrst<br />
vhodnih postaj lahko rečemo, da je prav zakasnitev čakalnih vrst tista, ki vpliva na<br />
celotno zakasnitev. Pri tem je zakasnitev v primeru <strong>samopodobnega</strong> <strong>prometa</strong> s<br />
kratkim območjem odvisnosti zanemarljivo majhna, kar je v nasprotju z zakasnitvijo<br />
<strong>prometa</strong> z dolgim območjem odvisnosti, modeliranim s pomočjo Paretove<br />
porazdelitve. Prav izbruhi so poglavitni vzrok za pojav zakasnitev v testnem<br />
omrežju.
66 VPLIV SAMOPODOBNEGA PROMETA NA ZMOGLJIVOST OMREŽJA<br />
Slika 7.4:<br />
Zakasnitev čakalnih vrst na oddajnih postajah.
ZAKLJUČEK<br />
67<br />
8. ZAKLJUČEK<br />
Cilj magistrske naloge je bilo <strong>modeliranje</strong> izmerjenega <strong>prometa</strong> v simulacijskem<br />
okolju OPNET, ki smo ga klasificirali ter mu določili parametre s pomočjo<br />
opravljene analize. Posvetili smo se predvsem modeliranju <strong>samopodobnega</strong> <strong>prometa</strong>,<br />
ki je postal v današnjem času osnovni model opisa omrežnega <strong>prometa</strong>. S pomočjo<br />
vohljača smo izmerili veliko vzorčnih signalov, ki smo jih skušali matematično<br />
oceniti <strong>in</strong> modelirati. Že iz samih meritev omrežnega <strong>prometa</strong> smo ugotovili, da<br />
lahko več<strong>in</strong>o izmerjenih signalov <strong>prometa</strong> označimo kot samopodobni promet. Izmed<br />
vseh izmerjenih primerov omrežnega <strong>prometa</strong> smo za analizo <strong>in</strong> <strong>modeliranje</strong><br />
uporabili le tri različne testne signale. Ti so vsebovali različne lastnosti <strong>in</strong> so bili<br />
primerni za prikaz različnih pristopov k modeliranju. V teoriji [6], [12], [15], [30] je<br />
lastnost dolgega ali kratkega območja odvisnosti predpisana z velikostjo Hurstovega<br />
parametra. In sicer v primeru Hurstovega parametra, manjšega od 0,5, proces vsebuje<br />
lastnost kratkega območja odvisnosti. V primeru Hurstovega parametra, večjega od<br />
0,5 <strong>in</strong> manjšega od 1, proces vsebuje lastnost dolgega območja odvisnosti. Z<br />
opravljenimi analizami omrežnega <strong>prometa</strong> smo pokazali, da se lahko pojavi primer<br />
(testni signal 1), ki ga označimo kot samopodoben promet (H > 0,5), vendar ne<br />
vsebuje lastnosti dolgega območja odvisnosti. S tem lahko postavimo kriterij<br />
Hurstovega parametra kot zadosten pogoj za določitev kratkega ali dolgega območja<br />
odvisnosti pod vprašaj. Lastnost dolgega <strong>in</strong> kratkega območja odvisnosti smo<br />
določili s pomočjo poteka avtokorelacijske funkcije <strong>in</strong> v primeru ugotovljene<br />
lastnosti dolgega območja odvisnosti to lastnost potrdili z metodo »bucket<br />
shuffl<strong>in</strong>g«, kot smo to opravili v primeru tretjega testnega signala.<br />
Za <strong>modeliranje</strong> na osnovi ocenjenih parametrov smo v OPNET-u skušali<br />
modelirati izmerjen promet. Zaradi premajhnega števila zajetih paketov ter s tem<br />
vprašljive pravilne ocene parametrov v primeru testnega signala 2, žal tega nismo<br />
modelirali v simulacijskem okolju OPNET. Ker je testni signal posledica posameznih<br />
transakcij v omrežju, bi bilo za <strong>modeliranje</strong> takšne vrste <strong>prometa</strong> veliko primerneje<br />
uporabiti postajo, pri kateri lahko z verjetnostno porazdelitvijo določimo aktivnost<br />
delovanja, s katero bi opisali čas med posameznimi transakcijami. Modeliranje<br />
izmerjenih testnih signalov 1 <strong>in</strong> 3 smo izvedli na dva nač<strong>in</strong>a, s pomočjo postaj iz<br />
knjižnice simulacijskega orodja OPNET, <strong>in</strong> sicer z RPG postajo <strong>in</strong> IP postajo. Za<br />
vsak testni signal smo izdelali šest različnih scenarijev (simulacij), pri katerih smo<br />
uporabili različne nač<strong>in</strong>e modeliranja procesa prihoda paketov (Hurstov parameter <strong>in</strong><br />
porazdelitve verjetnosti) ter porazdelitve verjetnosti za velikost paketov. Uporabili<br />
smo različne komb<strong>in</strong>acije porazdelitev verjetnosti, tako počasi pojemajoče<br />
porazdelitve (Paretova <strong>in</strong> Weibullova) kot tudi že 'odpisano' eksponentno<br />
porazdelitev. Iz simulacij smo videli, da je v primeru testnega signala 1<br />
(samopodoben promet s kratkim območjem odvisnosti) za <strong>modeliranje</strong> primerno <strong>in</strong><br />
pomembno izbrati eksponentno porazdelitev za velikost paketov, saj nam ne vnaša<br />
nezaželenih konic v modeliran promet. V primeru uporabe počasi pojemajoče<br />
porazdelitve pri opisu velikosti paketov se pojavijo v modeliranem prometu zraven<br />
nezaželenih konic velika odstopanja srednje vrednosti med izmerjenim <strong>in</strong><br />
modeliranim prometov. V primeru testnega signala 3 (samopodoben promet <strong>in</strong> dolgo
68 ZAKLJUČEK<br />
območje odvisnosti) si želimo v modeliranem prometu prav konice, ki jih dosežemo<br />
z uporabo počasi pojemajočih verjetnostnih porazdelitev za opis velikosti paketov.<br />
Tako je v primeru <strong>samopodobnega</strong> <strong>prometa</strong> z lastnostjo dolgega območja odvisnosti<br />
pomembna izbira počasi pojemajočih porazdelitev. Za opis časa med paketi se v<br />
obeh primerih izkažejo počasi pojemajoče porazdelitve (Weibullova) primernejše kot<br />
eksponente.<br />
Med izmerjenimi <strong>in</strong> modeliranimi signali (prometi) se pojavljajo odstopanja tako<br />
v smislu srednje vrednosti, pojavljanja konic <strong>in</strong> variance. Z metodo, ki smo jo razvili<br />
sami, smo dosegli dober približek modeliranega <strong>in</strong> izmerjenega <strong>prometa</strong>. Vsekakor<br />
pa ne moremo trditi, da je to optimalna metoda za ocenjevanje potrebnih parametrov<br />
izmerjenega <strong>prometa</strong>, pri kateri izhajamo iz podatkov o velikosti paketov v omrežju<br />
<strong>in</strong> ne o velikosti o prenesenih datotekah znotraj omrežja. Predvsem je težko pravilno<br />
oceniti parameter oblike počasi pojemajočih porazdelitev, saj že majhna napaka pri<br />
ocenitvi tega parametra povzroči veliko odstopanje v smislu srednje vrednosti<br />
skupnega <strong>prometa</strong>. Vendar se je razvita metoda pokazala kot dobra osnova za<br />
nadaljnje raziskovanje.<br />
V zadnjem delu magistrske naloge smo opisali vpliv <strong>samopodobnega</strong> <strong>prometa</strong> na<br />
zmogljivosti omrežja. S tem smo pokazali, da je pomembno poznavanje omrežnega<br />
<strong>prometa</strong>, prav tako pa tudi znanje modeliranja izmerjenega <strong>prometa</strong> v simulacijskih<br />
orodjih. Prikazali smo različen vpliv <strong>samopodobnega</strong> <strong>prometa</strong> s kratkim <strong>in</strong> dolgim<br />
območjem odvisnosti na zmogljivost omrežja. Modeliranje <strong>prometa</strong> <strong>in</strong> proučevanje<br />
vpliva na zmogljivost omrežja v poglavju 7 je bilo izvedeno na osnovi pridobljenega<br />
znanja skozi celotno raziskovalno delo.
LITERATURA<br />
69<br />
LITERATURA<br />
[1] D. Hercog, Simulacija zmogljivosti telekomunikacijskih protokolov, specificiranih v<br />
jeziku SDL, Elektrotehniški vestnik 68(1): 13–19, Ljubljana, 2001.<br />
[2] I. Humar <strong>in</strong> J. Bešter, Modeliranje, simulacije ter simulacijsko okolje COMNET III,<br />
predstavitev 2003/2004,<br />
http://lt.fe.uni-lj.si/gradiva/NMVTKO/nmvtko_simulacije_comnet.pdf.<br />
[3] W. E. Leland, M. S. Taqqu, W. Will<strong>in</strong>ger <strong>in</strong> D. V. Wilson, On the self-similar nature<br />
of Ethernet traffic (Extended version), IEEE/ACM Transactions on Network<strong>in</strong>g,<br />
Vol.2, pp.1–15, 1994.<br />
[4] W. Will<strong>in</strong>ger <strong>in</strong> V. Paxson, Where mathematics meets the Internet, Notices of the<br />
American Mathematical Society 45(8): 961–970, 1998.<br />
[5] V. Paxon <strong>in</strong> S. Floyd, Wide area traffic: the failure of Poisson model<strong>in</strong>g, IEEE/ACM<br />
Transactions on Network<strong>in</strong>g, 3(3): 226–244, 1995.<br />
[6] K. Park <strong>in</strong> W. Will<strong>in</strong>ger, Self-Similar Network Traffic and Performance Evaluation,<br />
John Wiley & Sons, 2000.<br />
[7] K. Park, G. Kim <strong>in</strong> M. E. Crovella, On the Relationship Between File Sizes Transport<br />
Protocols, and Self-Similar Network Traffic, International Conference on Network<br />
Protocols, 171–180, 1996.<br />
[8] W. Will<strong>in</strong>ger, M. S. Taqqu, R. Sherman <strong>in</strong> D. V. Wilson, Self-similarity through highvariability:<br />
statistical analysis of Ethernet LAN traffic at the source level, IEEE/ACM<br />
Transactions on Network<strong>in</strong>g, 5(1): 71–86, 1997.<br />
[9] M. E. Crovella <strong>in</strong> A. Bestavros, Self-Similarity <strong>in</strong> World Wide Web Traffic Evidence<br />
and Possible Causes, IEEE/ACM Transactions on Network<strong>in</strong>g, 1997.<br />
[10] O. Rose, Estimation of the Hurst Parameter of Long Range Dependent Time Series,<br />
Research Report, 1996.<br />
[11] F. Xue <strong>in</strong> S. J. Ben You, The effect of aggregation on self-similar traffic, Department<br />
of Electrical and comput<strong>in</strong>g eng<strong>in</strong>eer<strong>in</strong>g, University of California.<br />
[12] T. Karagiannis, M. Molle <strong>in</strong> M. Faloutos, Understand<strong>in</strong>g the limitations of estimation<br />
methods for long-range dependence, University of California.<br />
[13] T. Karagiannis <strong>in</strong> M. Faloutos, Selfis: A tool for self-similarity and long range<br />
dependence analysis, University of California.<br />
[14] P. Sagger, Does Circuit Emulation <strong>in</strong> Metropolitan Gigabit Ethernets require Service<br />
Priority, Post Diploma Thesis NA-2005-02, Swiss Federal Institute of Technology,<br />
Zurich 2005.<br />
[15] H. Yõlmaz, IP over DVB: Management of self-similarity, Master of Science, Boğaziçi<br />
University, 2002.<br />
[16] M. Z. Jiang, Analysis of wireless data network traffic, Master of Applied Science,<br />
Simon Fraser University, Vancouver, Canada, 2000.<br />
[17] C. Groth, Modellierung und Simulation von Ethernet-Netzwerkverkehr, Master of<br />
Science, Universität Rostock, 2004.<br />
[18] B. Vujičić, Model<strong>in</strong>g and Characterization of Traffic <strong>in</strong> Public Safety Wireless<br />
Networks, Master of Applied science, Simon Fraser University, Vancouver, 2006.<br />
[19] E. Casilari, F. J. Gonzalez <strong>in</strong> F. Sandoval, Model<strong>in</strong>g of HTTP traffic, IEEE<br />
Communication Letters 5(6): 272–274, 2001.
70 LITERATURA<br />
[20] J. Beran, R. Sherman, M. S. Taqqu, <strong>in</strong> W. Will<strong>in</strong>ger, Long-range dependence <strong>in</strong><br />
variable bit rate video traffic, IEEE Transactions on Communications, vol. 43,<br />
1566–1579, 1995.<br />
[21] Q. Shao, Measurement and Analysis of Traffic <strong>in</strong> a Hybrid Satellite-Terrestrial<br />
Network, Master of Applied science, Simon Fraser University Vancouver Canada,<br />
2004.<br />
[22] J<strong>in</strong>-Yuan Chen, Self-Similarity of A Reverse-Filter Traffic Generator, Master of<br />
Science, Ch<strong>in</strong>a, 2003.<br />
[23] Q. Shao, Measurement and Analysis of Traffic <strong>in</strong> a Hybrid Satellite-Terrestrial<br />
Network, Master of Applied science, Simon Fraser University, Vancouver, 2004.<br />
[24] J. Potemans, B. Van den Broeck, Y. Guan, J. Theunis, E. Van Lil <strong>in</strong> A. Van de<br />
Capelle, Implementation of an Advanced Traffic Model <strong>in</strong> OPNET Modeler,<br />
OPNETWORK 2003, Wash<strong>in</strong>gton D.C., USA, 2003.<br />
[25] P. Leys, J. Potemans, B. Van den Broeck, J. Theunis, E. Van Lil <strong>in</strong> A. Van de Capelle,<br />
Use of the Raw Packet Generator <strong>in</strong> OPNET, OPNETWORK 2002, Wash<strong>in</strong>gton D.C.,<br />
USA, 2002.<br />
[26] M. Jiang, S. Hardy <strong>in</strong> Lj. Trajkovic, Simulat<strong>in</strong>g CDPD networks us<strong>in</strong>g OPNET,<br />
OPNETWORK 2000, Wash<strong>in</strong>gton D.C., August 2000.<br />
[27] B. Ryu <strong>in</strong> S. Lowen, Fractal Traffic Model for Internet Simulation, Proceed<strong>in</strong>gs of the<br />
Fifth IEEE Symposium on Computers and Communications (ISCC 2000).<br />
[28] B. K. Ryu <strong>in</strong> M. Nandikesan, Real Time Generation of Fractal ATM Traffic: Model,<br />
Algorithm, and Implementation, Department of Electrical Eng<strong>in</strong>eer<strong>in</strong>g and Center for<br />
Telecommunications Research, New York, 1996.<br />
[29] Z. Sah<strong>in</strong>oglu <strong>in</strong> S. Tek<strong>in</strong>ay, On Multimedia Networks: Self-Similar Traffic and<br />
Network Performance, New Jersey Institute of Technology, IEEE Communications<br />
Magaz<strong>in</strong>e, 1999.<br />
[30] R. Ritke, X. Hong <strong>in</strong> M. Gerla, Contradictory Relationship between Hurst parameter<br />
and Queue<strong>in</strong>g Performance (extended version), Telecommunication Systems, Vol 16<br />
(1, 2): pp. 159–175, 2001.<br />
[31] A. Orebaugh, G. Ramirez <strong>in</strong> J. Beale, Wireshark & Ethereal Network Protocol<br />
Analyzer Toolkit, Syngress Publish<strong>in</strong>g, Inc., 2007.<br />
[32] Free wireshark packet sniffer software [Onl<strong>in</strong>e]. Available: http://www.wireshark.org/<br />
[33] G. Fiche <strong>in</strong> G. Hebuterne, Communicat<strong>in</strong>g Systems & Networks: Traffic &<br />
Performance, Kogan Page Limited, 2004.<br />
[34] A. Adas, Traffic Models <strong>in</strong> Broadband Telecommunication Networks,<br />
Communications Magaz<strong>in</strong>e, IEEE , vol 35/7, 82–89, 1997.<br />
[35] M. Gospod<strong>in</strong>ov <strong>in</strong> E. Gospod<strong>in</strong>ova, The graphical methods for estimat<strong>in</strong>g Hurst<br />
parameter of self-similar network traffic, International conference on comput<strong>in</strong>g<br />
systems and tehnology – CompSysTech' 2005.<br />
[36] http://en.wikipedia.org/wiki/Exponential_distribution.<br />
[37] http://en.wikipedia.org/wiki/Pareto_distribution.<br />
[38] http://en.wikipedia.org/wiki/Weibull_distribution.<br />
[39] C. Williamson, Network Traffic Self-Similarity, Department of Computer Science,<br />
University of Saskatchewan.<br />
[40] Averill M. Law <strong>in</strong> Michael G. McComas, How the Expertfit distribution fitt<strong>in</strong>g<br />
software can make simulation models more valid, Proceed<strong>in</strong>gs of the 2001 W<strong>in</strong>ter<br />
Simulation Conference.<br />
[41] Free (demo) fitt<strong>in</strong>g tool EasyFit software [Onl<strong>in</strong>e]. Available: www.mathwave.com/.<br />
[42] S. Luo, G. A. Mar<strong>in</strong>, Realistic <strong>in</strong>ternet traffic simulation through mixture model<strong>in</strong>g<br />
and a case study, Proceed<strong>in</strong>gs of the 37th conference on W<strong>in</strong>ter simulation, 2005.<br />
[43] K. M. Rezaul <strong>in</strong> V. Grout, A Comparison of Methods for Estimat<strong>in</strong>g the Tail Index of<br />
Heavy-tailed Internet Traffic, Centre for Applied Internet Research, University of<br />
Wales.<br />
[44] H. Abrahamsson, Traffic measurement and analysis, Swedish Institute of Computer<br />
Science, SICS Technical Report, 1999.
LITERATURA<br />
71<br />
[45] G. Fiche <strong>in</strong> G. Hebuterne, Communicat<strong>in</strong>g Systems & Networks: Traffic &<br />
Performance, Kogan Page Limited, 2004.<br />
[46] R. Jamnik, Verjetnostni račun <strong>in</strong> statistika, DZS, Ljubljana, 1987.
72 DODATEK A<br />
DODATEK A<br />
Verjetnost <strong>in</strong> statistika<br />
Naključne spremenljivke <strong>in</strong> porazdelitve verjetnosti<br />
Naključna spremenljivka je lahko predstavljena kot preprosto numerično<br />
ovrednotenje naključnega dogodka. Naključna spremenljivka X(s) je preslikava<br />
elementov iz vzorčnega prostora S na realno os. Def<strong>in</strong>icijsko območje naključne<br />
spremenljivke X(s) je celotni vzorčni prostor S. Naključne spremenljivke so lahko<br />
zvezne (vzorčni prostor S je podmnožica realne osi) ali diskretne (vzorčni prostor so<br />
določena števila, lahko tudi neskončna množica) [46].<br />
Diskretna naključna spremenljivka X z zalogo vrednosti S x = {x 1 , x 2 , …, x n } ima<br />
pri poizkusu izmerjeno vrednost x i , kar označimo z A i ={X=x i }. Temu dogodku<br />
pripada verjetnost<br />
p( x) = P( X = x), i=<br />
1,2,..., n<br />
i<br />
Z množico vrednosti {p 1 , p 2 ,… , p n } opišemo porazdelitev verjetnosti po<br />
vzorčnem prostoru S x diskretne naključne spremenljivke X.<br />
Pri zveznih naključnih spremenljivkah vrednostim v vzorčnem prostoru S x ne<br />
moremo pripisati verjetnosti na enak nač<strong>in</strong> kot pri diskretnih naključnih<br />
spremenljivkah. Verjetnost želenega izida iz množice z neskončnim številom možnih<br />
izidov je namreč enaka nič. Pri zveznih naključnih spremenljivkah si pomagamo s<br />
pomočjo diferencialne verjetnosti oziroma z gostoto verjetnosti, kjer verjetnost<br />
dogodka zapišemo za določen <strong>in</strong>terval (x, x + dx). Pri zveznih spremenljivkah si tako<br />
pomagamo s pomočjo gostote verjetnosti f x (x) (Probability Density Function – PDF).<br />
Z znano gostoto verjetnosti f x (x) lahko preprosto izračunamo verjetnost, da X<br />
zavzame vrednost na <strong>in</strong>tervalu [a, b], a,b∈S x . Verjetnost je enaka plošč<strong>in</strong>i pod<br />
krivuljo f x (x) nad tem <strong>in</strong>tervalom.<br />
b<br />
Pa ( < X< b) =∫ f ( xdx )<br />
Če <strong>in</strong>terval, ki določa vzorčni prostor S x , povečamo čez vse meje, potem vsebuje<br />
vrednosti vsakega dogodka v poizkusu. To v jeziku verjetnosti pomeni gotov<br />
dogodek <strong>in</strong> velja tako za zvezne kot diskretne spremenljivke.<br />
∑<br />
i<br />
b<br />
∫<br />
a<br />
i<br />
a<br />
px ( ) = 1<br />
i<br />
f ( xdx ) = 1<br />
Lahko izračunamo verjetnost na <strong>in</strong>tervalu [– ∞, x], kar pomeni, da je naključna<br />
spremenljivka X znotraj tega <strong>in</strong>tervala. Verjetnost se sprem<strong>in</strong>ja z desno mejo<br />
<strong>in</strong>tervala. To funkcijo imenujemo kumulativna porazdelitvena funkcija (Cumulative<br />
Distribution Function – CDF). Def<strong>in</strong>irana je na sledeči nač<strong>in</strong>:
DODATEK A<br />
73<br />
x<br />
F( x) = P( −∞< X < x) = ∫ f<br />
X<br />
( xdx )<br />
Def<strong>in</strong>iramo lahko še komplementarno kumulativno porazdelitveno funkcijo<br />
(Complementary Cumulative Distribution Function – CCDF) F .<br />
−∞<br />
Fx () = PX ( > x) = 1 − Fx ()<br />
Pri karakterizaciji rezultatov eksperimentov naključnih spremenljivk imajo zelo<br />
pomembno vlogo vrednosti, kot so srednja vrednost, prvi <strong>in</strong> drugi moment ene<br />
naključne spremenljivke <strong>in</strong> povezani momenti dveh naključnih spremenljivk, kot sta<br />
korelacija <strong>in</strong> kovarianca.<br />
Statistična povprečja<br />
Pri vrednotenju rezultatov poskusov imajo statistične povprečne vrednosti<br />
naključnega procesa zelo pomembno vlogo. Pričakovano ali srednjo vrednost E[X]<br />
imenujemo prvi moment naključne spremenljivke X. Velikokrat jo označujemo tudi z<br />
besedno zvezo matematično upanje. Za diskretne naključne spremenljivke začetne<br />
momente višjih redov izračunamo po formuli<br />
m<br />
m<br />
E ⎡<br />
⎣<br />
X ⎤=<br />
⎦ ∑ xi fx( xi),<br />
za zvezne naključne spremenljivke pa s formulo<br />
m m<br />
E⎡ ⎣X ⎤= ⎦ ∫ x fx( x) dx.<br />
Sx<br />
Drugi začetni moment (m = 2) imenujemo tudi srednja kvadratična vrednost<br />
naključne spremenljivke X. Momente uporabljamo takrat, ko želimo približno<br />
okarakterizirati lastnosti gostote porazdelitve naključnih vrednosti.<br />
Poleg momentov je pomemben še centralni moment naključne spremenljivke, s<br />
katerim izračunamo pričakovano vrednost Y = (X – µ x ), kjer je µ x srednja vrednost<br />
spremenljivke X.<br />
i<br />
n<br />
n<br />
[ ] = ⎡( − μ ) ⎤ = ( −μ<br />
) ( )<br />
E Y E<br />
⎣<br />
X<br />
⎦ ∑ x f x<br />
∞<br />
x i x x i<br />
i=∞<br />
Tej pričakovani vrednosti pravimo n-ti centralni moment naključne spremenljivke.<br />
Pomemben je centralni moment pri m = 2, ki ga imenujemo varianca ali disperzija <strong>in</strong><br />
nam prikazuje razpršitev vrednosti okoli srednje vrednosti.<br />
2<br />
[ ] = ⎡ −<br />
var X E<br />
⎣<br />
( X μ x<br />
) ⎤<br />
⎦<br />
Koren iz variance je srednje kvadratično odstopanje ali tipična deviacija oziroma<br />
standardni odklon.<br />
σ = var[ X ]<br />
x<br />
Omenimo še porazdelitev vektorskih naključnih spremenljivk, kjer imamo zvezni<br />
naključni spremenljivki X <strong>in</strong> Y s povezano gostoto verjetnosti f xy (X, Y). Def<strong>in</strong>irajmo<br />
množico povezanih momentov:
74 DODATEK A<br />
∞<br />
∞<br />
EXY ( k n ) xy k n f ( x, y)<br />
dxdy<br />
= ∫∫ ,<br />
−∞ −∞<br />
XY<br />
kn∈<br />
N<br />
Posebej pomembna sta združeni moment <strong>in</strong> združeni centralni moment pri k = n = 1.<br />
Slednjega imenujemo kovarianca naključnih spremenljivk X <strong>in</strong> Y. Kovarianco dveh<br />
naključnih spremenljivk X <strong>in</strong> Y def<strong>in</strong>iramo:<br />
Cov( XY ) = E(( X −μ<br />
)( Y − μ ))<br />
X<br />
Y<br />
Korelacijski koeficient naključnih spremenljivk X <strong>in</strong> Y s srednjimi vrednosti µ x <strong>in</strong> µ y<br />
ter s standardnimi deviacijami σ x <strong>in</strong> σ y def<strong>in</strong>iramo kot:<br />
ρ<br />
XY ,<br />
cov( XY) E(( X − μX)( Y − μY))<br />
= =<br />
ρ ρ<br />
ρ ρ<br />
X Y X Y<br />
Stacionarni procesi<br />
Koncept stacionarnosti ima pri naključnih signalih podobno vlogo kot<br />
stacionarna stanja v analizi odzivov električnih vezij. Z njo predpostavljamo, da so<br />
statistike naključnega procesa v določenem smislu neodvisne od konkretne vrednosti<br />
časa.<br />
Stacionarni stohastični proces je stacionaren v striktnem pomenu, če so vse<br />
porazdelitve verjetnosti časovno neobčutljive za pomik. V tem primeru za poljubni<br />
premik T velja:<br />
PX ( < x, X < x,...) = PX ( < x , X < x,...)<br />
t1 1 t2 2 t1+ T 1+ T t2+<br />
T 2<br />
Stacionarni procesi drugega reda (»second order stationary process«) so procesi, ki<br />
imajo povprečno vrednost naključne spremenljivke neodvisno od časa<br />
[ ]<br />
E X() t = μ X<br />
,<br />
korelacijsko funkcijo pa neobčutljivo za pomik, torej odvisno le od razlike τ = t 2 - t 1 :<br />
[ ]<br />
E Xt1Xt2 = ρxx( τ )<br />
V teoriji signalov se pogosto srečujemo z naključnimi procesi. Zato so<br />
porazdelitve verjetnosti diskretne naključne spremenljivke <strong>in</strong> gostota verjetnosti<br />
zvezne spremenljivke poglavitne lastnosti nekega naključnega procesa, ki jih<br />
preprosto imenujemo kar porazdelitve. Poznamo veliko število najrazličnejših<br />
verjetnostnih porazdelitev, kot so normalna porazdelitev, Poissonova porazdelitev,<br />
eksponentna porazdelitev itd.
DODATEK B<br />
75<br />
DODATEK B<br />
Pregled osnovnih značilnosti porazdelitev [23]<br />
porazdelitev<br />
eksponentna<br />
gostota verjetnosti<br />
1<br />
−<br />
f ( x)<br />
= e ρ<br />
ρ<br />
x<br />
kumulativna porazdelitvena<br />
funkcija<br />
Fx ( ) = 1−<br />
e<br />
−x/<br />
ρ<br />
Weibullova<br />
1 ⎛ x ⎞<br />
f( x)<br />
= ⎜ − ⎟<br />
a⎝<br />
a⎠<br />
c−1<br />
e<br />
c<br />
−( x / a)<br />
F( x) = 1−<br />
c<br />
( x / a)<br />
e −<br />
Paretova<br />
f( x)<br />
=<br />
(k > 0, a > 0; x ≥ k) ( )<br />
ak<br />
a<br />
k 1<br />
x +<br />
⎛k<br />
⎞<br />
F( x) = 1− ⎜ ⎟<br />
⎝ x ⎠<br />
a<br />
logaritemsko-normalna<br />
1 −[ log( x) −ξ<br />
] 2 / 2σ<br />
f ( x)<br />
= e<br />
2<br />
x<br />
x 2πσ<br />
porazdelitev<br />
eksponentna<br />
Weibullova<br />
Paretova<br />
(k > 0, a > 0; x ≥ k)<br />
logaritemsko-normalna<br />
ocena maksimalnega verjetja<br />
1<br />
∑<br />
n xi<br />
n i=<br />
1<br />
ρ = = x<br />
1<br />
n c<br />
n n n<br />
c<br />
⎡<br />
c c<br />
∑ i ⎥ , ⎢⎜∑ i<br />
log<br />
i⎟⎜∑ i ⎟ ∑ log<br />
i<br />
i= 1 i= 1 i= 1 n i=<br />
1<br />
a ⎡1 x ⎤ c ⎛ x x ⎞⎛ x ⎞ 1<br />
n<br />
x ⎤<br />
= ⎢<br />
= − ⎥<br />
⎣ ⎦ ⎣⎝ ⎠⎝ ⎠<br />
⎦<br />
( )<br />
k = m<strong>in</strong> X , a=<br />
i<br />
i=<br />
1<br />
n<br />
∑<br />
i=<br />
1<br />
n −1<br />
X − nlog<br />
k<br />
n<br />
1<br />
ξ = ∑ log xi<br />
= log( x)<br />
n<br />
1/2<br />
n<br />
⎡1<br />
⎤<br />
σ = ⎢<br />
−<br />
n<br />
⎥ =<br />
⎣ i=<br />
1<br />
⎦<br />
2<br />
∑ (( log xi<br />
) ξ) var ( log ( x)<br />
)<br />
i<br />
−1
76 DODATEK C<br />
DODATEK C<br />
ČLANKI IN DRUGI SESTAVNI DELI<br />
1.08 Objavljeni znanstveni prispevek na konferenci<br />
1. Matjaž Fras, Jože Mohorko, "Estimat<strong>in</strong>g the parameters of measured self similar<br />
traffic for model<strong>in</strong>g <strong>in</strong> OPNET", V: 2007 IWSSIP & EC-SIPMCS : proceed<strong>in</strong>gs of<br />
2007 14th International Conference on Systems, Signals and Image Process<strong>in</strong>g<br />
(IWSSIP) and 6th EURASIP Conference Focused on Speech & Image Process<strong>in</strong>g,<br />
Multimedia Communication and Services (EC-SPIMCS), 27.-30. June, Maribor,<br />
Slovenia, Žarko Čučej, ur., Peter Plan<strong>in</strong>šič, ur., Dušan Gleich, ur., Maribor, Faculty<br />
of Electrical Eng<strong>in</strong>eer<strong>in</strong>g and Computer Science, 2007, str. 83-86. [COBISS.SI-ID<br />
11452182]<br />
2. Jože Mohorko, Matjaž Fras, Žarko Čučej, "Model<strong>in</strong>g methods <strong>in</strong> OPNET<br />
simulations of tactical command and control <strong>in</strong>formation systems", V: 2007 IWSSIP<br />
& EC-SIPMCS : proceed<strong>in</strong>gs of 2007 14th International Conference on Systems,<br />
Signals and Image Process<strong>in</strong>g (IWSSIP) and 6th EURASIP Conference Focused on<br />
Speech & Image Process<strong>in</strong>g, Multimedia Communication and Services (EC-<br />
SPIMCS), 27.-30. June, Maribor, Slovenia, Žarko Čučej, ur., Peter Plan<strong>in</strong>šič, ur.,<br />
Dušan Gleich, ur., Maribor, Faculty of Electrical Eng<strong>in</strong>eer<strong>in</strong>g and Computer Science,<br />
2007, str. 467-470. [COBISS.SI-ID 11452694]<br />
3. Jože Mohorko, Matjaž Fras, Žarko Čučej, "Model<strong>in</strong>g of IRIS replication<br />
mechanism <strong>in</strong> tactical communication network with OPNET", V: Proceed<strong>in</strong>gs,<br />
OPNETWORK 2007 - the eleventh annual OPNET technology Conference, August<br />
27th-31st, 2007, Wash<strong>in</strong>gton, D.C., Wash<strong>in</strong>gton, 2007, 5 f. [COBISS.SI-ID<br />
11619862]<br />
4. Matjaž Fras, Jože Mohorko, Žarko Čučej, "Simuliranje taktičnih omrežij z<br />
upoštevanjem modela širjenja radijskih valov", V: Zbornik šestnajste mednarodne<br />
Elektrotehniške <strong>in</strong> računalniške konference ERK 2007, 24. - 26. september 2007,<br />
Portorož, Slovenija, (Zbornik ... Elektrotehniške <strong>in</strong> računalniške konference ERK ...),<br />
Baldomir Zajc, ur., Andrej Trost, ur., Ljubljana, IEEE Region 8, Slovenska sekcija<br />
IEEE, 2007, str. 184-187. [COBISS.SI-ID 11695382]<br />
1.09 Objavljeni strokovni prispevek na konferenci<br />
5. Matjaž Fras, Marjan Hrastnik, Andrej Sarjaš, "Matematični model sistema za<br />
regulacijo ravnovesja", V: Avtomatizacija v <strong>in</strong>dustriji <strong>in</strong> gospodarstvu : zbornik tretje<br />
konference AIG'03, 10. <strong>in</strong> 11. april 2003, Maribor, Slovenija, Boris Tovornik, ur.,<br />
Nenad Mušk<strong>in</strong>ja, ur., [Maribor], Društvo avtomatikov Slovenije, 2003, str. 331-335.<br />
[COBISS.SI-ID 7882518]
DODATEK C<br />
77<br />
MONOGRAFIJE IN DRUGA ZAKLJUČENA DELA<br />
2.11 Diplomsko delo<br />
6. Matjaž Fras, Kakovost storitev <strong>in</strong>ternetnega protokola: zahteve, mehanizmi <strong>in</strong><br />
implementacija v korporacijskih omrežjih : diplomsko delo univerzitetnega<br />
študijskega programa, (Fakulteta za elektrotehniko, računalništvo <strong>in</strong> <strong>in</strong>formatiko,<br />
Diplomska dela univerzitetnega študija), Maribor, [M. Fras], 2005. [COBISS.SI-ID<br />
9708054]
78 ŽIVLJENJEPIS<br />
ŽIVLJENJEPIS<br />
Rojen 13. 3. 1980 v Mariboru, očetu Ivanu <strong>in</strong> materi Dušanki Fras. Sedaj prebiva v<br />
Jakobskem Dolu, Flekušek 12.<br />
1987 – 1995 obiskoval Osnovno šolo Jakobski Dol<br />
1995 – 1999 obiskoval Srednjo elektro‐računalniško šolo v Mariboru, smer<br />
elektronika, ki jo je leta 1999 z uspešno maturo tudi zaključil.<br />
1999 – 2005 študiral na Univerzi v Mariboru, Fakulteti za elektrotehniko,<br />
računalništvo <strong>in</strong> <strong>in</strong>formatiko, smer Avtomatika.<br />
julij 2005<br />
oktober 2005<br />
september 2006<br />
zaključil univerzitetni študij z zagovorom diplomske naloge ''Kakovost<br />
storitev <strong>in</strong>ternetnega protokola: zahteve, mehanizmi <strong>in</strong> implementacija v<br />
korporacijskem omrežju''.<br />
vpisal podiplomski študij na Univerzi v Mariboru, Fakulteti za<br />
elektrotehniko, računalništvo <strong>in</strong> <strong>in</strong>formatiko, smer Elektrotehnika.<br />
Mentor red. prof. dr. Žarko Čučej.<br />
se zaposlil na Univerzi v Mariboru, Fakulteti za elektrotehniko,<br />
računalništvo <strong>in</strong> <strong>in</strong>formatiko kot raziskovalec v laboratoriju za obdelavo<br />
signalov <strong>in</strong> dalj<strong>in</strong>skega vodenja.
ŽIVLJENJEPIS<br />
79