

Curriculum vitae et studiorum Giulia Venturi - Istituto di Linguistica ...
Curriculum vitae et studiorum Giulia Venturi - Istituto di Linguistica ...
Curriculum vitae et studiorum Giulia Venturi - Istituto di Linguistica ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
<strong>Curriculum</strong> <strong>vitae</strong> <strong>et</strong> <strong>stu<strong>di</strong>orum</strong><br />
<strong>Giulia</strong> <strong>Venturi</strong><br />
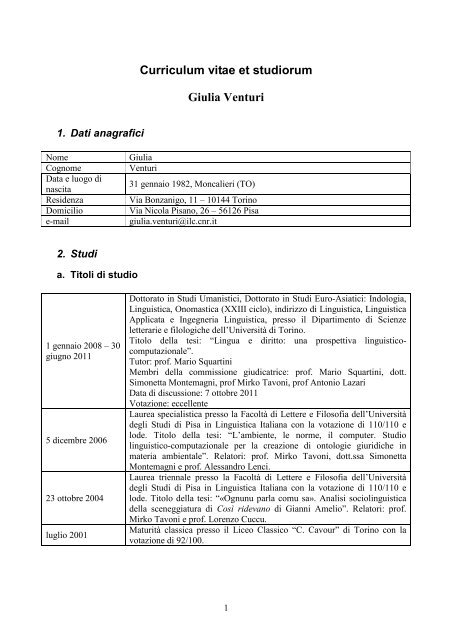
1. Dati anagrafici<br />
Nome<br />
Cognome<br />
Data e luogo <strong>di</strong><br />
nascita<br />
Residenza<br />
Domicilio<br />
e-mail<br />
<strong>Giulia</strong><br />
<strong>Venturi</strong><br />
31 gennaio 1982, Moncalieri (TO)<br />
Via Bonzanigo, 11 – 10144 Torino<br />
Via Nicola Pisano, 26 – 56126 Pisa<br />
giulia.venturi@ilc.cnr.it<br />
2. Stu<strong>di</strong><br />
a. Titoli <strong>di</strong> stu<strong>di</strong>o<br />
1 gennaio 2008 – 30<br />
giugno 2011<br />
5 <strong>di</strong>cembre 2006<br />
23 ottobre 2004<br />
luglio 2001<br />
Dottorato in Stu<strong>di</strong> Umanistici, Dottorato in Stu<strong>di</strong> Euro-Asiatici: Indologia,<br />
<strong>Linguistica</strong>, Onomastica (XXIII ciclo), in<strong>di</strong>rizzo <strong>di</strong> <strong>Linguistica</strong>, <strong>Linguistica</strong><br />
Applicata e Ingegneria <strong>Linguistica</strong>, presso il Dipartimento <strong>di</strong> Scienze<br />
l<strong>et</strong>terarie e filologiche dell’Università <strong>di</strong> Torino.<br />
Titolo della tesi: “Lingua e <strong>di</strong>ritto: una prosp<strong>et</strong>tiva linguisticocomputazionale”.<br />
Tutor: prof. Mario Squartini<br />
Membri della commissione giu<strong>di</strong>catrice: prof. Mario Squartini, dott.<br />
Simon<strong>et</strong>ta Montemagni, prof Mirko Tavoni, prof Antonio Lazari<br />
Data <strong>di</strong> <strong>di</strong>scussione: 7 ottobre 2011<br />
Votazione: eccellente<br />
Laurea specialistica presso la Facoltà <strong>di</strong> L<strong>et</strong>tere e Filosofia dell’Università<br />
degli Stu<strong>di</strong> <strong>di</strong> Pisa in <strong>Linguistica</strong> Italiana con la votazione <strong>di</strong> 110/110 e<br />
lode. Titolo della tesi: “L’ambiente, le norme, il computer. Stu<strong>di</strong>o<br />
linguistico-computazionale per la creazione <strong>di</strong> ontologie giuri<strong>di</strong>che in<br />
materia ambientale”. Relatori: prof. Mirko Tavoni, dott.ssa Simon<strong>et</strong>ta<br />
Montemagni e prof. Alessandro Lenci.<br />
Laurea triennale presso la Facoltà <strong>di</strong> L<strong>et</strong>tere e Filosofia dell’Università<br />
degli Stu<strong>di</strong> <strong>di</strong> Pisa in <strong>Linguistica</strong> Italiana con la votazione <strong>di</strong> 110/110 e<br />
lode. Titolo della tesi: “«Ognunu parla comu sa». Analisi sociolinguistica<br />
della sceneggiatura <strong>di</strong> Così ridevano <strong>di</strong> Gianni Amelio”. Relatori: prof.<br />
Mirko Tavoni e prof. Lorenzo Cuccu.<br />
Maturità classica presso il Liceo Classico “C. Cavour” <strong>di</strong> Torino con la<br />
votazione <strong>di</strong> 92/100.<br />
1
. Corsi <strong>di</strong> formazione e aggiornamento<br />
26-30 gennaio 2009<br />
Partecipazione alla SIT (Scuola Invernale TRIPLE) sul tema “Il lessico:<br />
m<strong>et</strong>o<strong>di</strong> <strong>di</strong> analisi, modelli e applicazioni”, tenuta presso il Dipartimento <strong>di</strong><br />
<strong>Linguistica</strong> dell’Università <strong>di</strong> Roma Tre.<br />
3. Borse <strong>di</strong> stu<strong>di</strong>o<br />
1 aprile 2007 – 31 marzo 2008<br />
1 aprile 2008 – 31 marzo 2009<br />
1 aprile 2009 – 31 marzo 2010<br />
Borsa <strong>di</strong> stu<strong>di</strong>o presso l’<strong>Istituto</strong> <strong>di</strong> <strong>Linguistica</strong> Computazionale<br />
“Antonio Zampolli” (ILC-CNR) <strong>di</strong> Pisa per la tematica “M<strong>et</strong>o<strong>di</strong><br />
e tecniche per l’estrazione automatica <strong>di</strong> informazione<br />
semantico-lessicale da collezioni documentali <strong>di</strong> ambito<br />
giuri<strong>di</strong>co e biome<strong>di</strong>co, con particolare enfasi sull’acquisizione<br />
<strong>di</strong> informazione relativa agli eventi <strong>di</strong> dominio”, sotto la<br />
responsabilità scientifica della dott.ssa Simon<strong>et</strong>ta Montemagni.<br />
4. Assegni <strong>di</strong> ricerca<br />
1 aprile 2010 – 30 s<strong>et</strong>tembre 2010<br />
1 ottobre 2010 – 28 febbraio 2011<br />
1 marzo 2011 - 30 aprile 2011<br />
1 luglio 2011 – 30 giugno 2012<br />
Assegno <strong>di</strong> ricerca presso l’<strong>Istituto</strong> <strong>di</strong> Ricerche sulle<br />
Attività Terziarie (IRAT-CNR) <strong>di</strong> Napoli nell’ambito del<br />
prog<strong>et</strong>to nazionale CNR “Migrazioni”, all’interno della<br />
linea <strong>di</strong> ricerca “Tecnologie avanzate e Integrazione<br />
linguistico-culturale nella scuola”, per la tematica<br />
“Sviluppo <strong>di</strong> m<strong>et</strong>odologie e tecniche per il monitoraggio<br />
della comp<strong>et</strong>enza linguistica italiana <strong>di</strong> alunni stranieri<br />
della scuola primaria e secondaria me<strong>di</strong>ante tecnologie<br />
avanzate nel campo della linguistica computazionale”,<br />
sotto la responsabilità scientifica della dott.ssa Simon<strong>et</strong>ta<br />
Montemagni.<br />
Assegno <strong>di</strong> ricerca presso la Scuola Superiore Sant’Anna<br />
<strong>di</strong> Pisa per la tematica “Law and Language: strumenti <strong>di</strong><br />
formalizzazione linguistica del <strong>di</strong>alogo giu<strong>di</strong>ziale in<br />
ambito comunitario”, sotto la responsabilità scientifica del<br />
professor Antonio Lazari.<br />
5. Attività professionale<br />
15 s<strong>et</strong>tembre 2008 –<br />
15 <strong>di</strong>cembre 2008<br />
Contratto <strong>di</strong> collaborazione presso il laboratorio TRIPLE (Tavolo <strong>di</strong><br />
Ricerca sulla Parola e il Lessico) del Dipartimento <strong>di</strong> <strong>Linguistica</strong><br />
dell’Università <strong>di</strong> Roma Tre per condurre uno stu<strong>di</strong>o comparativo degli<br />
schemi <strong>di</strong> annotazione morfosintattica per la lingua italiana scritta e parlata.<br />
6. Altre attività<br />
2012<br />
Co-organizzatore del First Shared Task on Dependency Parsing of<br />
Legal Texts, tenuto nell’ambito del 4 th Workshop on Semantic<br />
Processing of Legal Texts (SPLeT-2012).<br />
2
2012<br />
2011<br />
Dal 11 febbraio 2011<br />
Membro del program committee del 4 th Workshop on Semantic<br />
Processing of Legal Texts (SPLeT-2012), tenuto in occasione della 8 th<br />
Language Resources and Evaluation Conference (LREC 2012), 27<br />
maggio, Istanbul.<br />
Co-organizzatore del task Domain Adaptation for Dependency<br />
Parsing 1 , nell’ambito <strong>di</strong> Evalita 2011 (Evaluation of NLP and Speech<br />
Tools for Italian), finalizzato a m<strong>et</strong>tere a confronto m<strong>et</strong>o<strong>di</strong> e tecniche <strong>di</strong><br />
adattamento dei dependency parsers oggi allo stato dell’arte<br />
nell’annotazione sintattica <strong>di</strong> testi giuri<strong>di</strong>ci.<br />
Membro dell’Osservatorio per il recepimento e l’attuazione della<br />
Guida per la redazione degli atti amministrativi redatta dal gruppo <strong>di</strong><br />
lavoro attivo presso l’<strong>Istituto</strong> <strong>di</strong> Teoria e Tecniche dell’Informazione<br />
Giuri<strong>di</strong>ca (ITTIG) <strong>di</strong> Firenze.<br />
7. Seminari tenuti<br />
2 <strong>di</strong>cembre 2010<br />
15 aprile 2008<br />
30 marzo 2007<br />
“Lingua e <strong>di</strong>ritto: una prosp<strong>et</strong>tiva linguistico-computazionale” tenuto<br />
presso la sede dell’ITTIG-CNR (<strong>Istituto</strong> <strong>di</strong> Teoria e Tecniche<br />
dell’Informazione Giuri<strong>di</strong>ca) a Firenze, nell’ambito del seminario<br />
“Informazione giuri<strong>di</strong>ca e tecnologie linguistiche <strong>di</strong>gitali”, presentazione <strong>di</strong><br />
alcuni profili dell’attività <strong>di</strong> ricerca svolta da ITTIG, agli studenti ed ai<br />
dottoran<strong>di</strong> dell’Università degli Stu<strong>di</strong> della Tuscia.<br />
“Due modelli computazionali per la rappresentazione della conoscenza<br />
semantico-lessicale a confronto: WordN<strong>et</strong> e FrameN<strong>et</strong>” tenuto a Torino<br />
nell’ambito delle attività della Scuola <strong>di</strong> Dottorato.<br />
“M<strong>et</strong>o<strong>di</strong> e strumenti per l’estrazione automatica <strong>di</strong> informazione semanticolessicale<br />
da un corpus documentale giuri<strong>di</strong>co in materia ambientale. Dalla<br />
costruzione <strong>di</strong> un glossario terminologico <strong>di</strong> dominio all’acquisizione <strong>di</strong><br />
classi <strong>di</strong> eventi giuri<strong>di</strong>ci e ambientali” presso la sede dell’ITTIG-CNR<br />
(<strong>Istituto</strong> <strong>di</strong> Teoria e Tecniche dell’Informazione Giuri<strong>di</strong>ca) a Firenze.<br />
8. Lingue straniere conosciute<br />
Inglese<br />
Francese<br />
First Certificate in English (FCE)<br />
Diplome d'Etudes en langue française (DELF), unità A1, A2, A3<br />
9. Partecipazione a prog<strong>et</strong>ti scientifici<br />
Anno Prog<strong>et</strong>to Attività svolta<br />
“Prog<strong>et</strong>to IC.P10 Migrazioni”, linea<br />
<strong>di</strong> Ricerca n.1 “Differenze<br />
Linguistiche e Difficoltà<br />
d’integrazione”, sotto-linea <strong>di</strong> ricerca<br />
1 aprile 2010 –<br />
28 febbraio 2011<br />
Definizione <strong>di</strong> una m<strong>et</strong>odologia<br />
per il monitoraggio delle<br />
comp<strong>et</strong>enze linguistiche <strong>di</strong><br />
studenti apprendenti attraverso<br />
1 http://www.evalita.it/2011/tasks/dependency_parsing<br />
3
2008 - 2009<br />
1 aprile 2007 –<br />
30 giugno 2008<br />
1 aprile 2007 –<br />
31 marzo 2009<br />
n.1.4 “Tecnologie avanzate e<br />
Integrazione linguistico-culturale<br />
nella scuola”.<br />
Prog<strong>et</strong>tazione e sviluppo <strong>di</strong><br />
funzionalità avanzate <strong>di</strong> annotazione<br />
semantica del testo legislativo<br />
integrate nel “NIR E<strong>di</strong>tor”,<br />
all’interno dell’accordo<br />
collaborazione tra l’<strong>Istituto</strong> <strong>di</strong><br />
<strong>Linguistica</strong> Computazionale (ILC) e<br />
l’<strong>Istituto</strong> <strong>di</strong> Teoria e Tecniche<br />
dell’Informazione Giuri<strong>di</strong>ca (ITTIG).<br />
Prog<strong>et</strong>to europeo DALOS (Drafting<br />
Legislation with Ontology-based<br />
Support, eParticipation project n.<br />
2006/01/024), WP3 “Text-to-<br />
Knowledge Extraction and<br />
Connection to the Ontology”.<br />
Partners coinvolti: <strong>Istituto</strong> <strong>di</strong><br />
<strong>Linguistica</strong> Computazionale del CNR<br />
<strong>di</strong> Pisa (coor<strong>di</strong>natore, Italia);<br />
Department of Computer Science<br />
University of Sheffield – USFD<br />
(UK); Autonomous University of<br />
Barcelona - IDT-UAB (Spagna);<br />
Leiden University (Paesi Bassi);<br />
European University Institute<br />
(Unione Europea); The Leibniz<br />
Center for Law University of<br />
Amsterdam UvA (Paesi Bassi);<br />
Camera dei Deputati Italian<br />
Parliament (Italia).<br />
Durata: 18 mesi (1/1/2007-<br />
30/6/2008).<br />
Prog<strong>et</strong>to europeo BOOTSTREP<br />
(Bootstrapping of Ontologies and<br />
Terminologies Strategic Research<br />
Project, FP6 n. 028099), WP4 “Bio-<br />
Events”.<br />
Partners coinvolti: <strong>Istituto</strong> <strong>di</strong><br />
<strong>Linguistica</strong> Computazionale del CNR<br />
<strong>di</strong> Pisa (coor<strong>di</strong>natore, Italia); School<br />
of Computer Science, The University<br />
of Manchester (UK); European<br />
Bioinformatics Institute, Cambridge<br />
(UK).<br />
Durata: 3 anni (1/4/2006-31/3/2009).<br />
a) l’analisi delle loro produzioni<br />
scritte in ambito scolastico e b)<br />
la misura della <strong>di</strong>stanza<br />
linguistica tra tali produzioni e i<br />
materiali <strong>di</strong>dattici a loro offerti<br />
nella scuola.<br />
Sviluppo e sperimentazione <strong>di</strong><br />
una grammatica formale per<br />
l’annotazione semantica <strong>di</strong><br />
<strong>di</strong>sposizioni legislative <strong>di</strong><br />
mo<strong>di</strong>fica finalizzata al<br />
consolidamento <strong>di</strong> atti legislativi<br />
Attività <strong>di</strong> specializzazione <strong>di</strong><br />
uno strumento <strong>di</strong> estrazione<br />
terminologica automatica e<br />
organizzazione formale della<br />
conoscenza a partire da<br />
collezioni <strong>di</strong> testi, attraverso<br />
l’adattamento del sistema alle<br />
caratteristiche del linguaggio<br />
giuri<strong>di</strong>co.<br />
Definizione <strong>di</strong> uno schema per<br />
l’annotazione <strong>di</strong> informazione<br />
semantica relativa a eventi<br />
biome<strong>di</strong>ci rilevanti a partire da<br />
un corpus <strong>di</strong> abstracts biome<strong>di</strong>ci.<br />
4
<strong>Curriculum</strong> dell’attività scientifica e <strong>di</strong> ricerca<br />
1. Principali linee <strong>di</strong> attività e ricerca<br />
L’attività <strong>di</strong> ricerca è finalizzata a m<strong>et</strong>tere a punto m<strong>et</strong>o<strong>di</strong> <strong>di</strong> estrazione e formalizzazione <strong>di</strong><br />
conoscenza <strong>di</strong> dominio contenuta in collezioni <strong>di</strong> testi giuri<strong>di</strong>ci attraverso l’impiego <strong>di</strong> strumenti <strong>di</strong><br />
Trattamento Automatico del Linguaggio.<br />
Le attività sono in particolare rivolte alla definizione <strong>di</strong> m<strong>et</strong>odologie per<br />
a. l’analisi delle caratteristiche linguistiche <strong>di</strong> <strong>di</strong>verse vari<strong>et</strong>à <strong>di</strong> testi, con particolare riguardo<br />
all’analisi comparativa delle specificità della lingua del <strong>di</strong>ritto risp<strong>et</strong>to alle caratteristiche del<br />
linguaggio comune;<br />
b. l’estrazione automatica <strong>di</strong> terminologia <strong>di</strong> dominio da testi giuri<strong>di</strong>ci finalizzata<br />
all’organizzazione formale della conoscenza terminologico-lessicale acquisita in ontologie<br />
<strong>di</strong> dominio;<br />
c. la rappresentazione formale dell’informazione semantica contenuta in testi <strong>di</strong> linguaggi<br />
specialistici, con particolare riguardo al caso dei testi giuri<strong>di</strong>ci;<br />
d. il monitoraggio linguistico <strong>di</strong> <strong>di</strong>verse tipologie <strong>di</strong> testi, con particolare attenzione alla misura<br />
della leggibilità <strong>di</strong> testi giuri<strong>di</strong>ci;<br />
e. l’analisi comparativa tra schemi <strong>di</strong> annotazione morfosintattica esistenti per la lingua<br />
italiana scritta e parlata.<br />
a. Analisi delle caratteristiche linguistiche <strong>di</strong> <strong>di</strong>verse vari<strong>et</strong>à <strong>di</strong> testi, con<br />
particolare riguardo all’analisi comparativa delle specificità della lingua<br />
del <strong>di</strong>ritto risp<strong>et</strong>to alle caratteristiche del linguaggio comune<br />
L’obi<strong>et</strong>tivo <strong>di</strong> tale linea <strong>di</strong> ricerca consiste nel definire una m<strong>et</strong>odologia <strong>di</strong> analisi linguistica <strong>di</strong> testi<br />
giuri<strong>di</strong>ci in grado <strong>di</strong> m<strong>et</strong>tere in luce le peculiarità della lingua del <strong>di</strong>ritto risp<strong>et</strong>to alle caratteristiche<br />
proprie del linguaggio comune.<br />
Le ricerche sono al centro delle attività portate avanti nell’ambito del Dottorato. Ve<strong>di</strong> [4, 15, 16]<br />
della sezione Pubblicazioni.<br />
La m<strong>et</strong>odologia consiste nello stu<strong>di</strong>o comparativo delle caratteristiche linguistiche <strong>di</strong> collezioni <strong>di</strong><br />
testi giuri<strong>di</strong>ci e <strong>di</strong> quelle <strong>di</strong> <strong>di</strong>verse tipologie <strong>di</strong> testi, come ad esempio testi giornalistici, testi<br />
narrativi, testi <strong>di</strong> facile l<strong>et</strong>tura, materiali <strong>di</strong>dattici, ecc... raccolte grazie all’uso <strong>di</strong> strumenti <strong>di</strong><br />
Trattamento Automatico del Linguaggio. Tale stu<strong>di</strong>o si concentra sull’analisi delle caratteristiche<br />
linguistiche delle seguenti tipologie <strong>di</strong> testi giuri<strong>di</strong>ci:<br />
- atti normativi emanati dalla Comunità Europea (es. <strong>di</strong>r<strong>et</strong>tive europee, decisioni europee,<br />
ecc.), dallo stato italiano (es. decr<strong>et</strong>i ministeriali, leggi nazionali, ecc.) e dalla regione (es.<br />
leggi regionali);<br />
- atti amministrativi emanati dalla Comunità Europea (es. raccomandazioni, comunicazioni,<br />
ecc.), dallo stato italiano (es. circolari ministeriali, or<strong>di</strong>nanze, ecc.) e dalla regione (es.<br />
deliberazioni della giunta regionale, circolari, ecc.);<br />
- la Costituzione italiana.<br />
Assumendo una prosp<strong>et</strong>tiva multilingue, è stata inoltre condotta un’analisi delle caratteristiche<br />
linguistiche <strong>di</strong> una collezione <strong>di</strong> atti normativi comunitari in lingua inglese. Anche in questo caso è<br />
5
stata adottata un’ottica comparativa, m<strong>et</strong>tendo a confronto le caratteristiche dell’inglese giuri<strong>di</strong>co<br />
comunitario con quelle dell’inglese comune rintracciate in una collezione <strong>di</strong> testi giornalistici.<br />
Inoltre, le caratteristiche dell’inglese e dell’italiano giuri<strong>di</strong>co (comunitario) sono state confrontate<br />
tra loro per analizzarne similarità e <strong>di</strong>vergenze significative.<br />
L’obi<strong>et</strong>tivo ultimo <strong>di</strong> tale linea <strong>di</strong> ricerca è quello <strong>di</strong> suggerire come una fase <strong>di</strong> analisi linguistica<br />
costituisca il passo preliminare per ogni successiva fase <strong>di</strong> formalizzazione della conoscenza <strong>di</strong><br />
dominio e organizzazione strutturata in ontologie giuri<strong>di</strong>che.<br />
Inoltre, i risultati <strong>di</strong> questo tipo <strong>di</strong> analisi sono fondamentali per adattare gli strumenti <strong>di</strong><br />
Trattamento Automatico del Linguaggio alle specificità linguistiche del dominio giuri<strong>di</strong>co, in<br />
un’ottica <strong>di</strong> domain adaptation. Ve<strong>di</strong> [25, 28, 29] della sezione Pubblicazioni.<br />
b. Estrazione automatica <strong>di</strong> terminologia <strong>di</strong> dominio da testi giuri<strong>di</strong>ci<br />
finalizzata all’organizzazione formale della conoscenza terminologicolessicale<br />
acquisita in ontologie <strong>di</strong> dominio<br />
Le ricerche si sono concentrate sull’estensione delle potenzialità <strong>di</strong> strumenti <strong>di</strong> estrazione <strong>di</strong><br />
terminologia e organizzazione formale della conoscenza da collezioni testuali, adattandoli alle<br />
caratteristiche dei testi giuri<strong>di</strong>ci. Una serie <strong>di</strong> esperimenti in questa <strong>di</strong>rezione sono stati condotti su<br />
<strong>di</strong>verse tipologie <strong>di</strong> testi giuri<strong>di</strong>ci: una collezione <strong>di</strong> atti normativi e amministrativi comunitari,<br />
statali e regionali in materia ambientale; una collezione <strong>di</strong> atti normativi comunitari in materia <strong>di</strong><br />
protezione del consumatore, nell’ambito del prog<strong>et</strong>to europeo DALOS (DrAfting Legislation with<br />
Ontology-based Support, eParticipation project n. 2006/01/024).<br />
I risultati delle ricerche condotte sono esposti in [1, 2, 7, 10, 11, 12, 30] della sezione Pubblicazioni.<br />
Allo scopo <strong>di</strong> trattare in modo adeguato una delle maggiori specificità del lessico giuri<strong>di</strong>co, quella<br />
cioè <strong>di</strong> includere termini appartenenti alla realtà sia giuri<strong>di</strong>ca sia extragiuri<strong>di</strong>ca, è stata messa a<br />
punto una particolare strategia <strong>di</strong> estrazione terminologica. Tale strategia, utilizzando quello che in<br />
l<strong>et</strong>teratura è noto come approccio contrastivo, è in grado <strong>di</strong> estrarre terminologia rilevante da testi<br />
giuri<strong>di</strong>ci, separando in modo automatico terminologia tecnico-giuri<strong>di</strong>ca, terminologia del dominio<br />
legislato e terminologia appartenente al linguaggio comune. Essa è stata sperimentata con successo<br />
su <strong>di</strong>verse collezioni <strong>di</strong> testi giuri<strong>di</strong>ci: una collezione <strong>di</strong> atti normativi e amministrativi comunitari<br />
in materia ambientale; una collezione <strong>di</strong> sentenze in materia <strong>di</strong> danno alla persona, nell’ambito <strong>di</strong><br />
una collaborazione informale con il Lider-Lab della Scuola Superiore Sant’Anna <strong>di</strong> Pisa.<br />
I risultati delle ricerche condotte sono esposti in [19, 20, 21, 22] della sezione Pubblicazioni.<br />
c. Rappresentazione formale dell’informazione semantica contenuta in<br />
testi <strong>di</strong> linguaggi specialistici, con particolare riguardo al caso dei testi<br />
giuri<strong>di</strong>ci<br />
Questa linea <strong>di</strong> ricerca è finalizzata a m<strong>et</strong>tere a punto m<strong>et</strong>o<strong>di</strong> in grado <strong>di</strong> rendere esplicita<br />
l’informazione semantica contenuta in collezioni <strong>di</strong> testi, formalizzandola e strutturandola sulla base<br />
<strong>di</strong> modelli <strong>di</strong> rappresentazione formale del significato.<br />
Un’attenzione particolare è de<strong>di</strong>cata a definire una m<strong>et</strong>odologia <strong>di</strong> rappresentazione formale del<br />
contenuto semantico-lessicale <strong>di</strong> testi giuri<strong>di</strong>ci sulla base della Frame Semantics Theory <strong>di</strong> Charles<br />
Fillmore e sui principi organizzativi del prog<strong>et</strong>to FrameN<strong>et</strong>. Al centro dell’attività <strong>di</strong> ricerca è<br />
6
pertanto la specializzazione e l’adattamento al dominio giuri<strong>di</strong>co <strong>di</strong> un modello <strong>di</strong> rappresentazione<br />
del significato originariamente sviluppato per la formalizzazione del linguaggio comune. Basato<br />
sulla nozione <strong>di</strong> semantic frame (centrale nella teoria <strong>di</strong> Fillmore), intesa come schematizzazione<br />
formale <strong>di</strong> un contesto conoscitivo-tipo (il frame) scomponibile in singoli elementi conoscitivi (gli<br />
slots), tale approccio può consentire <strong>di</strong> risolvere alcuni problemi <strong>di</strong> rappresentazione formale della<br />
conoscenza giuri<strong>di</strong>ca ben noti e riconosciuti nella comunità <strong>di</strong> ricerca in Artificial Intelligence and<br />
Law (AI&Law) ma lasciati sino ad oggi per lo più irrisolti.<br />
È questa una linea ricerca portata avanti nell’ambito del Dottorato. Alcuni risultati preliminari <strong>di</strong><br />
questa linea <strong>di</strong> ricerca sono contenuti in [5, 8, 18, 27, 28, 36, 37] della sezione Pubblicazioni.<br />
Nell’ambito dello sviluppo <strong>di</strong> un modulo integrato in un sistema finalizzato al consolidamento<br />
semi-automatico del testo normativo vigente, è stata definita una grammatica formale per rendere<br />
espliciti all’interno del testo legislativo i tipi <strong>di</strong> <strong>di</strong>sposizione <strong>di</strong> mo<strong>di</strong>fica (i.e. abrogazione,<br />
sostituzione e integrazione) e per identificare la tipologia <strong>di</strong> ogg<strong>et</strong>ti (linguistico-testuali) mo<strong>di</strong>ficati<br />
(es. comma, l<strong>et</strong>tera, ecc.). Tale linea <strong>di</strong> ricerca è stata condotta nell’ambito delle attività <strong>di</strong><br />
prog<strong>et</strong>tazione e sviluppo <strong>di</strong> funzionalità avanzate del “NIR E<strong>di</strong>tor”, un e<strong>di</strong>tore per la redazione<br />
assistita <strong>di</strong> testi <strong>di</strong> legge, svolte all’interno dell’accordo <strong>di</strong> collaborazione tra l’<strong>Istituto</strong> <strong>di</strong> <strong>Linguistica</strong><br />
Computazionale (ILC) e l’<strong>Istituto</strong> <strong>di</strong> Teoria e Tecniche dell’Informazione Giuri<strong>di</strong>ca (ITTIG) e<br />
rivolte allo sviluppo del sistema MELT (M<strong>et</strong>adata Extraction from Legal Texts).<br />
I risultati <strong>di</strong> questa attività sono contenuti in [17, 35] della sezione Pubblicazioni.<br />
Inoltre, ricerche finalizzate alla formalizzazione della conoscenza <strong>di</strong> dominio contenuta in<br />
collezioni documentali sono state condotte anche a partire da testi <strong>di</strong> l<strong>et</strong>teratura biome<strong>di</strong>ca in lingua<br />
inglese. Le attività, svolte nell’ambito del prog<strong>et</strong>to europeo BOOTStrep (Bootstrapping Of<br />
Ontologies and Terminologies Strategic Research Project, FP6 – 028099), si sono concentrate in<br />
particolare sulla definizione <strong>di</strong> un modello per la rappresentazione formale dell’informazione<br />
relativa agli eventi biologici più rilevanti contenuti in abstracts <strong>di</strong> articoli biome<strong>di</strong>ci.<br />
I risultati sono contenuti in [3, 9, 13, 14, 31, 32, 33] della sezione Pubblicazioni.<br />
d. Monitoraggio linguistico <strong>di</strong> <strong>di</strong>verse tipologie <strong>di</strong> testi, con particolare<br />
attenzione alla misura della leggibilità <strong>di</strong> testi giuri<strong>di</strong>ci<br />
Questa linea <strong>di</strong> ricerca è finalizzata a usare strumenti <strong>di</strong> Trattamento Automatico del Linguaggio per<br />
monitorare in modo automatico il grado <strong>di</strong> leggibilità/complessità <strong>di</strong> <strong>di</strong>verse tipologie <strong>di</strong> testi, quali<br />
materiali <strong>di</strong>dattici, produzioni scritte da studenti nella scuola primaria e secondaria, articoli<br />
giornalistici, ecc… (cfr. [24] nella sezione Pubblicazioni)<br />
Essa è stata inizialmente condotta nell’ambito del prog<strong>et</strong>to CNR “Migrazioni”, all’interno della<br />
linea <strong>di</strong> ricerca “Tecnologie avanzate e Integrazione linguistico-culturale nella scuola”.<br />
I risultati sono contenuti in [6, 39, 41] della sezione Pubblicazioni.<br />
Un’attenzione particolare è de<strong>di</strong>cata a stabilire in modo automatico il livello <strong>di</strong> leggibilità <strong>di</strong> testi<br />
giuri<strong>di</strong>ci, sulla base <strong>di</strong> una serie <strong>di</strong> in<strong>di</strong>catori linguistici (es. la tipologia <strong>di</strong> vocabolario usato, le<br />
strutture sintattiche impiegate, ecc…). Al momento, tale strategia è stata sperimentata su <strong>di</strong> una<br />
collezione <strong>di</strong> atti amministrativi (cfr. [40] nella sezione Pubblicazioni) allo scopo <strong>di</strong> in<strong>di</strong>viduare i<br />
passi particolarmente critici che necessitano <strong>di</strong> una riscrittura. Questa esperienza si inserisce<br />
nell’ambito delle attività <strong>di</strong> monitoraggio del costituendo Osservatorio per il recepimento e<br />
l’attuazione della Guida per la redazione degli atti amministrativi redatta dal gruppo <strong>di</strong> lavoro<br />
attivo presso l’<strong>Istituto</strong> <strong>di</strong> Teoria e Tecniche dell’Informazione Giuri<strong>di</strong>ca (ITTIG) <strong>di</strong> Firenze.<br />
7
e. Analisi comparativa tra schemi <strong>di</strong> annotazione morfosintattica esistenti<br />
per la lingua italiana scritta e parlata<br />
La definizione <strong>di</strong> una m<strong>et</strong>odologia <strong>di</strong> analisi comparativa degli schemi <strong>di</strong> annotazione<br />
morfosintattica (PoS-tags<strong>et</strong>s) esistenti per la lingua italiana scritta e parlata è stata al centro<br />
dell’attività scientifica condotta nell’ambito della collaborazione con il laboratorio TRIPLE (Tavolo<br />
<strong>di</strong> Ricerca sulla Parola e il Lessico), attivo presso il Dipartimento <strong>di</strong> <strong>Linguistica</strong> dell’Università <strong>di</strong><br />
Roma Tre. I risultati dell’analisi realizzata secondo la m<strong>et</strong>odologia messa a punto hanno offerto la<br />
possibilità <strong>di</strong> condurre uno stu<strong>di</strong>o sulle <strong>di</strong>mensioni <strong>di</strong> variazione più <strong>di</strong>battute nella categorizzazione<br />
delle parti del <strong>di</strong>scorso (o classi <strong>di</strong> parole) per la lingua italiana.<br />
I risultati sono contenuti in [34, 38] della sezione Pubblicazioni.<br />
8
2. Elenco delle pubblicazioni<br />
a. Articoli in libri<br />
[1] Agnoloni T., Bacci L., Francesconi F., P<strong>et</strong>ers W., Montemagni S., <strong>Venturi</strong> G. (2009), A twolevel<br />
knowledge approach to support multilingual legislative drafting. In Joost Breuker,<br />
Pompeu Casanovas, Michel C.A. Klein, Enrico Francesconi (eds.), Law, Ontologies and the<br />
Semantic Web - Channelling the Legal Information Flood, Frontiers in Artificial Intelligence and<br />
Applications, Springer, Volume 188, ISBN 978-1-58603-942-4, pp. 177-198.<br />
[2] Lenci A., Montemagni S., Pirrelli V., <strong>Venturi</strong> G. (2009), Ontology learning from Italian legal<br />
texts. In Joost Breuker, Pompeu Casanovas, Michel C.A. Klein, Enrico Francesconi (eds.), Law,<br />
Ontologies and the Semantic Web - Channelling the Legal Information Flood, Frontiers in<br />
Artificial Intelligence and Applications, Springer, Volume 188, ISBN 978-1-58603-942-4, pp. 75-<br />
94.<br />
[3] <strong>Venturi</strong> G., Montemagni S., Marchi S., Sasaki Y., Thompson P., McNaught J. And Ananiadou<br />
S. (2009), Bootstrapping a Verb Lexicon for Biome<strong>di</strong>cal Information Extraction. In Alexander<br />
Gelbukh (ed.), Computational Linguistics and Intelligent Text Processing, LNCS 5449, Springer-<br />
Verlag Berlin Heidelberg, ISSN 0302-9743, ISBN 3-642-00381-8, pp. 137-148.<br />
[4] <strong>Venturi</strong> G. (2010), Legal Language and Legal Knowledge Management Applications, in E.<br />
Francesconi, S. Montemagni, W. P<strong>et</strong>ers and D. Tiscornia (eds.), Semantic Processing of Legal<br />
Texts, Springer-Verlag Berlin Heidelberg, LNAI 6036, ISSN 0302-9743, ISBN 3-642-12836-X, pp.<br />
3-26.<br />
[5] Agnoloni T., Fernández Barrera M., Sagri M.T., Tiscornia D. and <strong>Venturi</strong> G. (2010), When a<br />
FrameN<strong>et</strong>-style knowledge description me<strong>et</strong>s an ontological characterization of Fundamental<br />
Legal Concepts. In P. Casanovas, U. Pagallo, G. Ajani, G. Sartor (eds.), AI Approaches to the<br />
Complexity of Legal Systems (AICOL 2009), LNCS, ISSN 0302-9743, ISBN 3-642-16523-0,<br />
Springer, pp. 93-112.<br />
[6] Dell’Orl<strong>et</strong>ta F., Montemagni S., Vecchi E. M. e <strong>Venturi</strong> G. (2011), Tecnologie linguisticocomputazionali<br />
per il monitoraggio della comp<strong>et</strong>enza linguistica italiana degli alunni stranieri<br />
nella scuola primaria e secondaria. In Giovanni Carlo Bruno, Immacolata Caruso, Manuela<br />
Sanna, Immacolata Vellecco (a cura <strong>di</strong>.), Percorsi migranti: uomini, <strong>di</strong>ritto, lavoro, linguaggi,<br />
McGraw-Hill, ISBN 978-88-386-7296-5, pag. 319-336.<br />
b. Articoli in riviste<br />
[7] Dell’Orl<strong>et</strong>ta F., Lenci A., Marchi S., Montemagni S., Pirrelli V., <strong>Venturi</strong> G. (2008), Dal testo<br />
alla conoscenza e ritorno: estrazione terminologica e annotazione semantica <strong>di</strong> basi<br />
documentali <strong>di</strong> dominio. In «AIDA Informazioni», Atti del Convegno Nazionale Ass.I.Term “I-<br />
TerAnDo”, Università della Calabria, 5-7-giugno 2008, Roma : AIDA, n. 1-2/2008, ISSN 1121-<br />
0095, pp. 185-206.<br />
9
[8] <strong>Venturi</strong> G. (2011), Semantic annotation of Italian legal texts: a FrameN<strong>et</strong>-based approach,<br />
In: Ohara K. and Nikiforidou, K. (eds.), special issue of Constructions and Frames, John Benjamins<br />
Company, ISSN 1876-1933, E-ISSN 1876-1941, pp. 46-79.<br />
[9] Paul Thompson, Simon<strong>et</strong>ta Montemagni, John McNaught, Nicol<strong>et</strong>ta Calzolari, Riccardo del<br />
Gratta, Vivian Lee, Simone Marchi, Monica Monachini, Piotr Pezik, Valeria Quochi, Di<strong>et</strong>rich<br />
Rebholz-Schuhmann, C.J. Rupp, Yutaka Sasaki, <strong>Giulia</strong> <strong>Venturi</strong> and Sophia Ananiadou (2011), The<br />
BioLexicon: a large-scale terminological resource for biome<strong>di</strong>cal text mining. In Journal BMC<br />
Bionformatics, pp. 12-397.<br />
c. Articoli in atti <strong>di</strong> convegni<br />
[10] Agnoloni T., Bacci L., Francesconi E., Spinosa P., Tiscornia D., Montemagni S., <strong>Venturi</strong> G.<br />
(2007), Buil<strong>di</strong>ng an ontological support for multilingual legislative drafting. In Procee<strong>di</strong>ngs of<br />
the International Conference on Legal Knowledge and Information Systems (JURIX 2007),<br />
December 12-15, 2007, Leiden, The N<strong>et</strong>herlands.<br />
[11] Dell’Orl<strong>et</strong>ta F., Lenci A., Montemagni S., Marchi S., Pirrelli V., <strong>Venturi</strong> G. (2008), Acquiring<br />
Legal Ontologies from Domain-specific Texts. In Procee<strong>di</strong>ng of LangTech 2008, Rome, 28-29<br />
February, CD-ROM.<br />
[12] Lenci A., Montemagni S., Pirrelli V., <strong>Venturi</strong> G. (2007), NLP-based ontology learning from<br />
legal texts. A case study. In “Procee<strong>di</strong>ngs of the II Workshop on Legal Ontologies and Artificial<br />
Intelligence Techniques (LOAIT ’07)”, 4 June, Stanford University, Stanford, CA USA, pp. 113-<br />
130. http://www.ittig.cnr.it/loait/LOAIT07-Procee<strong>di</strong>ngs.pdf<br />
[13] Thompson P., Cotter P., Ananiadou S., McNaught J., Montemagni S., Trabucco A. and <strong>Venturi</strong><br />
G. (2008), Buil<strong>di</strong>ng a bio-event annotated corpus for the acquisition of semantic frames from<br />
biome<strong>di</strong>cal corpora. In Procee<strong>di</strong>ngs of the Sixth International Conference on Language Resources<br />
and Evaluation (LREC), Marrakech, Morocco, May 26-1 June, pp. 2159-2166. CD-ROM.<br />
[14] Thompson P., <strong>Venturi</strong> G., McNaught J., Montemagni S. and Ananiadou S. (2008),<br />
Categorising Modality in Biome<strong>di</strong>cal texts. In Procee<strong>di</strong>ngs of the Workshop “Buil<strong>di</strong>ng and<br />
Evaluating Resources for Biome<strong>di</strong>cal Text Mining”, held in conjunction with LREC 2008,<br />
Marrakech, Morocco, May 26-1, pp. 27-34, CD-ROM.<br />
[15] <strong>Venturi</strong> G. (2008), Linguistic analysis of a corpus of Italian legal texts. A NLP-based<br />
approach. In Karasimos <strong>et</strong> al. (eds.), Procee<strong>di</strong>ngs of the First Patras International Conference of<br />
Graduate Students in Linguistics (PICGL 2008), University of Patras Press, pp. 139-149<br />
[16] <strong>Venturi</strong> G. (2008), Parsing Legal texts. A contrastive study with a View to Knowledge<br />
Management Applications. In Procee<strong>di</strong>ngs of the Ist Workshop “Semantic Processing of Legal<br />
Texts”, held in conjunction with LREC, Marrakech, Morocco, May 26-1, CD-ROM.<br />
[17] Spinosa P., Giar<strong>di</strong>ello G., Cherubini M., Marchi S., <strong>Venturi</strong> G., Montemagni S. (2009), NLPbased<br />
M<strong>et</strong>adata Extraction for Legal Text Consolidation. In Procee<strong>di</strong>ngs of the “12th<br />
International Conference on Artificial Intelligence and Law” (ICAIL 2009), Barcellona, 8-12<br />
giugno.<br />
10
[18] <strong>Venturi</strong> G., Lenci A., Montemagni S., Vecchi E.M., Sagri M.T., Tiscornia D., Agnoloni T.<br />
(2009), Towards a FrameN<strong>et</strong> Resource for the Legal Domain. In Casellas N, Francesconi E.,<br />
Hoekstra R., Montemagni S. (eds.), Procee<strong>di</strong>ngs of the III Workshop on Legal Ontologies and<br />
Artificial Intelligence Techniques (LOAIT ’09), Barcellona, 8 giugno, Huygens E<strong>di</strong>torial, IDTseries,<br />
pp. 67-76.<br />
[19] Bonin F., Dell’Orl<strong>et</strong>ta F., <strong>Venturi</strong> G. and Montemagni S. (2010), A Contrastive Approach to<br />
Multi-word Extraction from Domain-specific Corpora. In Procee<strong>di</strong>ngs of the 7 th International<br />
Conference on Language Resources and Evaluation (LREC 2010), La Vall<strong>et</strong>ta, Malta, 19-21 May.<br />
[20] Bonin F., Dell’Orl<strong>et</strong>ta F., <strong>Venturi</strong> G. and Montemagni S. (2010), Singling out Legal<br />
Knowledge from World Knowledge. In Procee<strong>di</strong>ngs of the IV Workshop on Legal Ontologies<br />
and Artificial Intelligence Techniques (LOAIT ’10), Fiesole, 7 luglio 2010; anche pubblicato in<br />
«Informatica e <strong>di</strong>ritto», n. 1/2010, ISSN 0390-0975, pp. 217-229.<br />
[21] Bonin F., Dell’Orl<strong>et</strong>ta F., <strong>Venturi</strong> G. and Montemagni S. (2010), Contrastive filtering of<br />
domain specific multi–word terms from <strong>di</strong>fferent type of corpora. In Procee<strong>di</strong>ngs of Multiword<br />
Expressions: from Theory to Applications (MWE 2010), the 23 rd International Conference on<br />
Computational Linguistics (COLING2010), Beijing, China, August 28, pp. 76-79.<br />
[22] Bonin F., Dell’Orl<strong>et</strong>ta F., <strong>Venturi</strong> G. and Montemagni S. (2010), Lessico s<strong>et</strong>toriale e lessico<br />
comune nell’estrazione <strong>di</strong> terminologia specialistica da corpora <strong>di</strong> dominio. In atti del XLIV<br />
Congresso Internazionale <strong>di</strong> Stu<strong>di</strong> della Soci<strong>et</strong>à <strong>di</strong> <strong>Linguistica</strong> Italiana (SLI 2010), 27-29 s<strong>et</strong>tembre<br />
Viterbo, pp. 207-220.<br />
[23] Dell’Orl<strong>et</strong>ta F., <strong>Venturi</strong> G. and Montemagni S. (2011), ULISSE: an Unsupervised Algorithm<br />
for D<strong>et</strong>ecting Reliable Dependency Parses. In Procee<strong>di</strong>ngs of the 15 th Conference on<br />
Computational Natural Language Learning (CoNLL 2011), Portland, Oregon, USA, June 23-24, pp.<br />
115-124.<br />
[24] Dell’Orl<strong>et</strong>ta F., Montemagni S. and <strong>Venturi</strong> G. (2011), READ-IT: Assessing Readability of<br />
Italian Texts with a View to Text Simplification. In Procee<strong>di</strong>ngs of the Workshop on Speech and<br />
Language Processing for Assistive Technologies (SLPAT 2011), E<strong>di</strong>nburgh, July 30, pp. 73-83.<br />
[25] Dell’Orl<strong>et</strong>ta F., Marchi S., Montemagni S., <strong>Venturi</strong> G., Agnoloni T. e Francesconi E. (2012),<br />
Domain Adaptation for Dependency Parsing at Evalita 2011. In Working Notes of EVALITA<br />
2011, 24th-25th January 2012, Rome, Italy, ISSN 2240-5186.<br />
[26] Basili R., Lenci A., De Cao D. e <strong>Venturi</strong> G. (2012), Frame Labeling over Italian Texts. In<br />
Working Notes of EVALITA 2011, 24th-25th January 2012, Rome, Italy, ISSN 2240-5186.<br />
[27] Lenci A., Montemagni S., <strong>Venturi</strong> G. e Cutrullà M.R. (2012), Enriching the ISST–TANL<br />
Corpus with Semantic Frames. In Procee<strong>di</strong>ngs of the 8 th International Conference on Language<br />
Resources and Evaluation (LREC 2012), Istanbul, Turkey, 21-27 May.<br />
[28] <strong>Venturi</strong> G. (2012), Design and Development of TEMIS: a Syntactically and Semantically<br />
Annotated Corpus of Italian Legislative Texts. In Procee<strong>di</strong>ngs of the 4 th Workshop “Semantic<br />
Processing of Legal Texts”, held in conjunction with LREC 2012, Istanbul, Turkey, 27 May.<br />
[29] Dell’Orl<strong>et</strong>ta F., Marchi S., Montemagni S., B. Plank e <strong>Venturi</strong> G. (2012), The SPLeT–2012<br />
Shared Task on Dependency Parsing of Legal Texts. In Procee<strong>di</strong>ngs of the 4 th Workshop<br />
11
“Semantic Processing of Legal Texts”, held in conjunction with LREC 2012, Istanbul, Turkey, 27<br />
May.<br />
d. Deliverables e rapporti tecnici<br />
[30] Montemagni S., Marchi S., <strong>Venturi</strong> G., Bartolini R., Bertagna F., Ruffolo P., P<strong>et</strong>ers W.,<br />
Tiscornia D. (2007), Report on Ontology learning tool and testing. Prog<strong>et</strong>to Europeo DALOS<br />
(Drafting Legislation with Ontology-Based Support), Deliverable 3.3, Dicembre.<br />
[31] Montemagni S., Trabucco A., <strong>Venturi</strong> G. (2007), Bio-Event Linguistic Annotation Tool.<br />
User Manual. BOOTStrep project (Bootstrapping Of Ontologies and Terminologies STrategic<br />
REsearch Project, FP6 - 028099), WP4, S<strong>et</strong>tembre.<br />
[32] Montemagni S., Trabucco A., <strong>Venturi</strong> G., Thompson P., Cotter P., Ananiadou S., McNaught J.,<br />
Kim J., Rebholz D., Pezik P. (2007), Event annotation of domain corpora. BOOTStrep project<br />
(Bootstrapping Of Ontologies and Terminologies STrategic REsearch Project, FP6 - 028099),<br />
Deliverable 4.1, March.<br />
[33] Montemagni S., <strong>Venturi</strong> G., Thompson P., Ananiadou S., McNaught J., Kim J., Rebholz D.,<br />
Pezik P. (2008), Augmented version of the bio-lexicon extended with bio-event information<br />
and term-to-term weighted links, BOOTStrep project (Bootstrapping Of Ontologies and<br />
Terminologies STrategic REsearch Project, FP6 - 028099), Deliverable 4.2, November.<br />
[34] <strong>Venturi</strong> G. (2009), Rassegna comparativa degli schemi <strong>di</strong> annotazione morfosintattica per<br />
la lingua italiana, Rapporto Tecnico TRIPLE - RTT/1, febbraio, <strong>di</strong>sponibile sul sito TRIPLE alla<br />
pagina http://host.uniroma3.it/laboratori/triple/Risorse_Resources.html<br />
e. Comunicazioni orali<br />
[35] Cherubini M., Giar<strong>di</strong>ello G., Marchi S., Montemagni S., Spinosa P., <strong>Venturi</strong> G. (2008), NLPbased<br />
M<strong>et</strong>adata Annotation of Textual Amendments, tenuta in occasione del “Workshop on<br />
Legislative XML 2008 (LXML-2008): the Law in the Semantic Web and beyond” nell’ambito del<br />
JURIX (21th International Conference on Legal Knowledge and Information System) 2008, 10<br />
<strong>di</strong>cembre.<br />
[36] <strong>Venturi</strong> G. (2009), Towards an Italian Legal FrameN<strong>et</strong>, tenuta in occasione <strong>di</strong> “Frames and<br />
Constructions. A conference in honor of Charles J. Fillmore”, 31 July-2 August, University of<br />
California, Berkeley.<br />
[37] <strong>Venturi</strong> G. (2009), Towards an Italian Legal FrameN<strong>et</strong>. Exploring evidence for exten<strong>di</strong>ng<br />
and specializing FrameN<strong>et</strong> to the legal domain, tenuta in occasione della “FrameN<strong>et</strong> Masterclass<br />
and Workshop”, presso l’Università Cattolica del Sacro Cuore, 3 <strong>di</strong>cembre, Milano.<br />
[38] <strong>Venturi</strong> G. (2010), Word classes and morphosyntactic annotation schemes. A comparison<br />
of the Italian Part-Of-Speech tags<strong>et</strong>s, tenuta in occasione <strong>di</strong> Word classes. Nature, typology,<br />
computational representation, 2 nd TRIPLE International Conference, March 24-26, Roma.<br />
[39] Dell’Orl<strong>et</strong>ta F., Montemagni S., Vecchi E., <strong>Venturi</strong> G. (2010), Tecnologie linguisticocomputazionali<br />
per il monitoraggio delle comp<strong>et</strong>enze linguistiche <strong>di</strong> apprendenti l'italiano<br />
12
come L2, tenuta in occasione <strong>di</strong> “IT.L2: Italiano lingua seconda nell'Università, nella Scuola e sul<br />
Territorio”, 12-13 novembre, Vercelli.<br />
[40] <strong>Venturi</strong> G. (2011), Le tecnologie linguistico-computazionali nella misura della leggibilità<br />
<strong>di</strong> atti amministrativi, tenuta in occasione del convegno “La redazione degli atti amministrativi:<br />
linguisti e giuristi a confronto”, 11 febbraio, Accademia della Crusca, Firenze.<br />
[41] <strong>Venturi</strong> G. (2011), Tecnologie linguistico-computazionali per il monitoraggio della<br />
comp<strong>et</strong>enza linguistica italiana degli alunni stranieri nella scuola primaria e secondaria,<br />
tenuta in occasione del seminario “Migrazioni/linguaggi” del prog<strong>et</strong>to CNR Migrazioni, 30 marzo,<br />
Roma.<br />
13













