

Traitement automatique du signal ECG pour l'aide au diagnostic de ...
Traitement automatique du signal ECG pour l'aide au diagnostic de ...
Traitement automatique du signal ECG pour l'aide au diagnostic de ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
CHAPITRE 5. EFFET DES OUTLIERS 47<br />
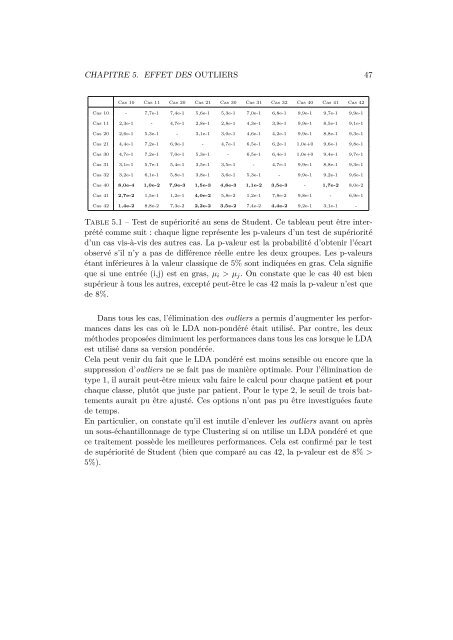
Cas 10 Cas 11 Cas 20 Cas 21 Cas 30 Cas 31 Cas 32 Cas 40 Cas 41 Cas 42<br />
Cas 10 - 7,7e-1 7,4e-1 5,6e-1 5,3e-1 7,0e-1 6,8e-1 9,9e-1 9,7e-1 9,9e-1<br />
Cas 11 2,3e-1 - 4,7e-1 2,8e-1 2,8e-1 4,3e-1 3,9e-1 9,9e-1 8,5e-1 9,1e-1<br />
Cas 20 2,6e-1 5,3e-1 - 3,1e-1 3,0e-1 4,6e-1 4,2e-1 9,9e-1 8,8e-1 9,3e-1<br />
Cas 21 4,4e-1 7,2e-1 6,9e-1 - 4,7e-1 6,5e-1 6,2e-1 1,0e+0 9,6e-1 9,8e-1<br />
Cas 30 4,7e-1 7,2e-1 7,0e-1 5,3e-1 - 6,5e-1 6,4e-1 1,0e+0 9,4e-1 9,7e-1<br />
Cas 31 3,1e-1 5,7e-1 5,4e-1 3,5e-1 3,5e-1 - 4,7e-1 9,9e-1 8,8e-1 9,3e-1<br />
Cas 32 3,2e-1 6,1e-1 5,8e-1 3,8e-1 3,6e-1 5,3e-1 - 9,9e-1 9,2e-1 9,6e-1<br />
Cas 40 8,0e-4 1,0e-2 7,9e-3 1,5e-3 4,8e-3 1,1e-2 3,5e-3 - 1,7e-2 8,0e-2<br />
Cas 41 2,7e-2 1,5e-1 1,2e-1 4,0e-2 5,8e-2 1,2e-1 7,8e-2 9,8e-1 - 6,9e-1<br />
Cas 42 1,4e-2 8,8e-2 7,3e-2 2,2e-2 3,5e-2 7,4e-2 4,4e-2 9,2e-1 3,1e-1 -<br />
Table 5.1 – Test <strong>de</strong> supériorité <strong>au</strong> sens <strong>de</strong> Stu<strong>de</strong>nt. Ce table<strong>au</strong> peut être interprété<br />
comme suit : chaque ligne représente les p-valeurs d’un test <strong>de</strong> supériorité<br />
d’un cas vis-à-vis <strong>de</strong>s <strong>au</strong>tres cas. La p-valeur est la probabilité d’obtenir l’écart<br />
observé s’il n’y a pas <strong>de</strong> différence réelle entre les <strong>de</strong>ux groupes. Les p-valeurs<br />
étant inférieures à la valeur classique <strong>de</strong> 5% sont indiquées en gras. Cela signifie<br />
que si une entrée (i,j) est en gras, µi > µj. On constate que le cas 40 est bien<br />
supérieur à tous les <strong>au</strong>tres, excepté peut-être le cas 42 mais la p-valeur n’est que<br />
<strong>de</strong> 8%.<br />
Dans tous les cas, l’élimination <strong>de</strong>s outliers a permis d’<strong>au</strong>gmenter les performances<br />
dans les cas où le LDA non-pondéré était utilisé. Par contre, les <strong>de</strong>ux<br />
métho<strong>de</strong>s proposées diminuent les performances dans tous les cas lorsque le LDA<br />
est utilisé dans sa version pondérée.<br />
Cela peut venir <strong>du</strong> fait que le LDA pondéré est moins sensible ou encore que la<br />
suppression d’outliers ne se fait pas <strong>de</strong> manière optimale. Pour l’élimination <strong>de</strong><br />
type 1, il <strong>au</strong>rait peut-être mieux valu faire le calcul <strong>pour</strong> chaque patient et <strong>pour</strong><br />
chaque classe, plutôt que juste par patient. Pour le type 2, le seuil <strong>de</strong> trois battements<br />
<strong>au</strong>rait pu être ajusté. Ces options n’ont pas pu être investiguées f<strong>au</strong>te<br />
<strong>de</strong> temps.<br />
En particulier, on constate qu’il est inutile d’enlever les outliers avant ou après<br />
un sous-échantillonnage <strong>de</strong> type Clustering si on utilise un LDA pondéré et que<br />
ce traitement possè<strong>de</strong> les meilleures performances. Cela est confirmé par le test<br />
<strong>de</strong> supériorité <strong>de</strong> Stu<strong>de</strong>nt (bien que comparé <strong>au</strong> cas 42, la p-valeur est <strong>de</strong> 8% ><br />
5%).
