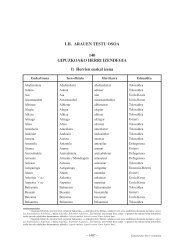
- Page 1 and 2:
euskalarien nazioarteko jardunaldia
- Page 3 and 4:
C EUSKO JAURLARITZAKO KULTURA SAILA
- Page 5 and 6:
Euskaltzaindiak, Jardunaldiak antol
- Page 7 and 8:
JARDUNALDIEN Egunoroko berriak Jose
- Page 9 and 10:
JARDUNALDIEN EGUNOROKO BERRIAK val
- Page 11 and 12:
JARDUNALDIEN EGUNOROKO BERRIAK alde
- Page 13 and 14:
SESSIONS PROGRAM August 25th to 29t
- Page 15 and 16:
PROGRAMA DE SESIONES Del 25 al 29 d
- Page 17 and 18:
PROGRAMME DES SESSIONS Du 25 au 29
- Page 19 and 20:
HASIERA EGUNA FIRST DAY DIA DE APER
- Page 21 and 22:
FR. LUIS VILLASANTE XVII. mende hor
- Page 23 and 24:
FR. LUIS VILLASANTE Horra zergatik
- Page 25 and 26:
FR. LUIS VILLASANTE Altube jaunak b
- Page 27 and 28:
EUSKARARI BURUZKO IKERKETAK GAUR EG
- Page 29 and 30:
EUSKARARI BURUZKO IKERKETAK GAUR EG
- Page 31 and 32:
EUSKARARI BURUZKO IKERKETAK GAUR EG
- Page 33 and 34:
EUSKARARI BURUZKO IKERKETAK GAUR EG
- Page 35 and 36:
EUSKARARI BURUZKO IKERKETAK GAUR EG
- Page 37 and 38:
PEDRO MIGEL ETXENIKE dutelako bakar
- Page 39 and 40:
KULTUR KONTSEILARIAREN AGURRA Euska
- Page 41 and 42:
KULTUR KONTSEILARIAREN AGURRA Mais
- Page 43 and 44:
KARLOS GARAIKOETXEA zenean, mespres
- Page 45 and 46:
KARLOS GARAIKOETXEA egingo. Bainan
- Page 47 and 48:
II TXOSTENA PAPER PONENCIA EXPOSE
- Page 49 and 50:
ANDRE MARTINET Nous trouvons d'abor
- Page 51 and 52:
ANDRE MARTINET L'opposition des aff
- Page 53 and 54:
ANDRE MARTINET renforcée par la pr
- Page 55 and 56:
ANDRE MARTINET sentaient une seule
- Page 57 and 58:
ANDRE MARTINET l'aspiration se main
- Page 59 and 60:
ANDRE MARTINET tuée a une durée s
- Page 61 and 62:
ANDRE MARTINET Frikatiba ildokari h
- Page 63 and 64:
ANDRE MARTINET En una tercera fase,
- Page 65 and 66:
EUSKAL FONETIKA Kilburn MACMURRAUGH
- Page 67 and 68:
EUSKAL FONETIKA modernoetan batez e
- Page 69 and 70:
EUSKAL FONETIKA nas sin descartar l
- Page 71 and 72:
ENRIQUE KNORR No han faltado alguno
- Page 73 and 74:
ENRIQUE KNORR Estos autores o escri
- Page 75 and 76:
ENRIQUE KNORR Me valdré de algunos
- Page 77 and 78:
sentan a la Junta, confesando que a
- Page 79 and 80: género de obras, y particularmente
- Page 81 and 82: § 2.° De la voz en general. 1.°
- Page 83 and 84: chi, Pacho, de Francisco;Juaniz, Ju
- Page 85 and 86: D. 3.° Igualmente se anotarán en
- Page 87 and 88: nifica «maíz», en cierta parte d
- Page 89 and 90: no convendrá en este punto usar de
- Page 91 and 92: llana, se hará esta advertencia: g
- Page 93 and 94: J 9.º Las frases y refranes se han
- Page 95 and 96: Apantamientos para las notas o adic
- Page 97 and 98: E. 9.º Quando una voz es universal
- Page 99 and 100: ENRIQUE KNORR y la 4. a, la de hall
- Page 101 and 102: ENRIQUE KNORR 3.° El tercer medio
- Page 103 and 104: ENRIQUE KNORR vaciar los que se enc
- Page 105 and 106: ENRIQUE KNORR Con la obra escrita a
- Page 107 and 108: ENRIQUE KNÖRR su nativa lengua, pu
- Page 109 and 110: ENRIQUE KNORR son indispensables en
- Page 111 and 112: ENRIQUE KNORR Comisión 4.ª Diccio
- Page 113 and 114: ENRIQUE KNÖRR Disimúleme Vd. con
- Page 115 and 116: MOGUELEN LAU GUTUN BERRI PRESTAMERO
- Page 117 and 118: MOGUELEN LAU GUTUN BERRI PRESTAMERO
- Page 119 and 120: MOGUELEN LAU GUTUN BERRI PRESTAMERO
- Page 121 and 122: HIRUGARREN JARDUNA THIRD SESSION TE
- Page 123 and 124: COMPARACION: LEXICO-ESTADISTICA Y T
- Page 125 and 126: COMPARACION: LÉXICÖ-ESTADISTICA l
- Page 127 and 128: COMPARACION: LÉXICÖ-ESTADISTICA l
- Page 129: CÖMPARACION: LEXICO-ESTADISTICA am
- Page 133 and 134: COMPARACION: LÉXICO-ESTADISTICA am
- Page 135 and 136: COMPARACIÖN: LEXICO-ESTADISTICA de
- Page 137 and 138: COMPARACION: LEXICO-ESTADISTICA muy
- Page 139 and 140: 1. síntesis: medio COMPARACIÖN: L
- Page 141 and 142: • COMPARACION: LEXICO-ESTADISTICA
- Page 143 and 144: DRO IV vietn. esquim. COMPARACION:
- Page 145 and 146: Ñ C1 e II 1 / 1 1 / / / / / 1 Irpl
- Page 147 and 148: CÖMPARACIÖN: LEXICÖ-ESTADISTICA
- Page 149 and 150: CÖMPARACION: LEXICO-ESTADISTICA HY
- Page 151 and 152: IV TXOSTENA PAPER PONENCIA EXPOSE
- Page 153 and 154: TERENCE H. WILBUR to some degree ma
- Page 155 and 156: TERENCE H. WILBUR affixes. ( I have
- Page 157 and 158: TERENCE H. WILBUR 16. Ez bide da ur
- Page 159 and 160: TERENCE H. WILBUR one assumes, like
- Page 161 and 162: TERENCE H. WILBUR focussed noun phr
- Page 163 and 164: TERENCE H . WILBUR Lengthy consider
- Page 165 and 166: TERENCE H. WILBUR described as Moda
- Page 167 and 168: TERENCE H. WILBUR This accounts for
- Page 169 and 170: TERENCE H. WILBUR RÉSUMÉ Ce trava
- Page 171 and 172: COMMON HAMITO-SEMITIC AND BASQUE WI
- Page 173 and 174: COMMON HAMITO-SEMITIC AND BASQUE WI
- Page 175 and 176: COMMON HAMITO-SEMITIC AND BASQUE WI
- Page 177 and 178: COMMON HAMITO -SEMITIC AND BASQUE W
- Page 179 and 180: COMMON HAMITO-SEMITIC AND bASQUE WI
- Page 181 and 182:
OUTLINE OF A LEXICOSTATISTICAL STUD
- Page 183 and 184:
OUTLINE OF A LEXICOSTATISTICAL STUD
- Page 185 and 186:
OUTLINE OF A LEXICOSTATISTICAL STUD
- Page 187 and 188:
OUTLINE OF A LEXICOSTATISTICAL STUD
- Page 189 and 190:
OUTLINE OF A LEXICOSTATISTICAL STUD
- Page 191 and 192:
OUTLINE OF A LEXICOSTATISTICAL STUD
- Page 193 and 194:
OUTLINE OF A LEXICOSTATISTICAL STUD
- Page 195 and 196:
EUSCARO - CAUCASICA * Jan BRAUN No
- Page 197 and 198:
EUSCARO - CAUCASICA 8. georg kurcxa
- Page 199 and 200:
EUSCARO - CAUCASICA 4. georg. kence
- Page 201 and 202:
EUSCARO - CAUCASICA Ene ustez badit
- Page 203 and 204:
GUNTER BRETTSCHNEIDER infinitive di
- Page 205 and 206:
GUNTER BRETTSCHNEIDER lenguas aglut
- Page 207 and 208:
GUNTER BRETTSCHNEIDER tipológico
- Page 209 and 210:
GUNTER BRETTSCHNEIDER ges»), el va
- Page 211 and 212:
(21) (23) x GUNTER BRETTSCHNEIDER d
- Page 213 and 214:
GUNTER BRETTSCHNEIDER particular. E
- Page 215 and 216:
ONCEPTUALIZACIO GUNTER BRETTSCHNEID
- Page 217 and 218:
verb-final in subordinare clauses f
- Page 219 and 220:
GUNTER BRETTSCHNEIDER Cettes apprOc
- Page 221 and 222:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 223 and 224:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 225 and 226:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 227 and 228:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 229 and 230:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 231 and 232:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 233 and 234:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 235 and 236:
LA RELACION ENTRE EL VASCO Y EL IBE
- Page 237 and 238:
JEAN-BAPTISTE ETCHARREN En conclusi
- Page 239 and 240:
EUSKAL ETA KARTVELIAR IZEN BATZUREN
- Page 241 and 242:
EUSKAL ETA KARTVELIAR BATZUREN KIDE
- Page 243 and 244:
EUSKAL ETA KARTVELIAR BATZUREN KIDE
- Page 245 and 246:
EUSKAL ETA KARTVELIAR BATZUREN KIDE
- Page 247 and 248:
LAUGARREN JARDUNA FOURTH SESSION CU
- Page 249 and 250:
JACQUES ALLIERES linguistiques. Ajo
- Page 251 and 252:
JACQUES ALLIERES légion, et encore
- Page 253 and 254:
JACQUES ALLIERES mentionnés tout
- Page 255 and 256:
JACQUES ALLIERES ja eginik. Horrela
- Page 257 and 258:
V TXOSTENA PAPER PONENCIA EXPOSE
- Page 259 and 260:
ROBERT TRASK particularly interesti
- Page 261 and 262:
ROBERT TRASK Now consider the form
- Page 263 and 264:
ROBERT TRASK Intransitive verbs adh
- Page 265 and 266:
In Milafranga, one must say ROBERT
- Page 267 and 268:
ROBERT TRASK (The same occurs with
- Page 269 and 270:
ROBERT TRASK Prefix Suffix Pronoun
- Page 271 and 272:
ROBERT TRASK differ in the way the
- Page 273 and 274:
ROBERT TRASK (37) Nere ama hil da.
- Page 275 and 276:
ROBERT TRASK Acknowledgements: I wo
- Page 277 and 278:
ROBERT TRASK JACOBSEN, W. H. Jr.: (
- Page 279 and 280:
AUTOUR DES FORMES ALLOCUTIVES DU BA
- Page 281 and 282:
AUTOUR DES FORMES ALLOCUTIVES DU BA
- Page 283 and 284:
AUTOUR DES FORMES ALLOCUTIVES DU BA
- Page 285 and 286:
AUTOUR DES FORMES ALLOCUTIVES DU BA
- Page 287 and 288:
AUTOUR DES FORMES ALLOCUTIVES DU BA
- Page 289 and 290:
AUTOUR DES FORMES ALLOCUTIVES DU BA
- Page 291 and 292:
AUTOUR DES FORMES ALLOCUTIVES DU BA
- Page 293 and 294:
AUTOUR DES FORMES ALLOCUTIVES DU RA
- Page 295 and 296:
PATXI ALTUNA denboraz pixka bat ald
- Page 297 and 298:
PATXI ALTUNA datzala azken horren a
- Page 299 and 300:
PATXI ALTUNA 6. Some adjetives seem
- Page 301 and 302:
EIBARKO ADITZ-LAGUNTZAILEAREN PARAD
- Page 303 and 304:
3 3 NI ORAINA NAIZ NO/ N JATA JATA/
- Page 305 and 306:
[5] NI Z HI HA (Bera) GU IRAGANA NI
- Page 307 and 308:
(Singular) Gauza bar NERI (Plural)
- Page 309 and 310:
[9] NIK — — ZUK HIK HAREK GUK Z
- Page 311 and 312:
SUMMARY EIBARKO ADITZ-LAGUNTZAILEAR
- Page 313 and 314:
[1] XUKAKO ADITZ JOSKERA LUZAIDEKO
- Page 315 and 316:
XUKAKO ADITZ JOSKERA LUZAIDEKO MINT
- Page 317 and 318:
XUKAKO ADITZ JOSKERA LUZAIDEKO MINT
- Page 319 and 320:
Ziechu: Heldu ziechu C. XUKAKO ADIT
- Page 321 and 322:
XUKAKO ADITZ JOSKERA LUZAIDEKO MINT
- Page 323 and 324:
XUKAKO ADITZ JOSKERA LUZAIDEKO MINT
- Page 325 and 326:
BA- ETA EZ- FONETIKAREN ALDETIK 1 G
- Page 327 and 328:
BA- ETA EZ- FONETIKAREN ALDETIK 4.2
- Page 329 and 330:
BA- ETA EZ- FONETIKAREN ALDETIK Bor
- Page 331 and 332:
BA- ETA EZ- FONETIKAREN ALDETIK 5.3
- Page 333 and 334:
BA- ETA EZ- FONETIKAREN ALPETIK aho
- Page 335 and 336:
ALFONSO IRIGOYEN nos llevan a estab
- Page 337 and 338:
ALFONSO IRIGOYEN Esto, naturalmente
- Page 339 and 340:
ALFONSO IRIGOYEN id, Iudicio genera
- Page 341 and 342:
ALFONSO IRIGOYEN distinto proceso c
- Page 343 and 344:
ALFONSO IRIGOYEN para e] manuscrito
- Page 345 and 346:
ALFONSO IRIGOYEN mentaria con oiñ,
- Page 347 and 348:
ALFONSO IRIGOYEN primer haur puede
- Page 349 and 350:
ALFONSO IRIGOYEN aitzinian, «héme
- Page 351 and 352:
ALFONSO IRIGOYEN En el dicc. de Lha
- Page 353 and 354:
ALFONSO IRIGOYEN registradas más a
- Page 355 and 356:
ALFONSO IRIGOYEN foL 56v), «Don Se
- Page 357 and 358:
ALFONSO IRIGOYEN época romana, don
- Page 359 and 360:
ALFONSO IRIGOYEN prefijos-, conserv
- Page 361 and 362:
ALFONSO IRIGOYEN a Estella, donde y
- Page 363 and 364:
ALFONSO IRIGOYEN Bermeo y Lequeitio
- Page 365 and 366:
ALFONSO IRIGOYEN orrako y arako, es
- Page 367 and 368:
ALFONSO IRIGOYEN Junto a esta forma
- Page 369 and 370:
ALFONSO IRIGOYEN en Elorrio, donde
- Page 371 and 372:
ALFONSO IRIGOYEN apparaissent dans
- Page 373 and 374:
PIERRE LAFITTE direla usatzen hutsi
- Page 375 and 376:
TXOMIN PEILLEN famatuaren mikrofilm
- Page 377 and 378:
TXOMIN PEILLEN baterako ipuin asko
- Page 379 and 380:
TXOMIN PEILLEN ...) and a lot of de
- Page 381 and 382:
BOSTGARREN JARDUNA FIFTH SESSION QU
- Page 383 and 384:
PERSPECTIVE DE RECHERCHES FUTURES L
- Page 385 and 386:
PERSPECTlVE DE RECHERCHES FUTURES l
- Page 387 and 388:
PERSPECTIVE DE RECHERCHES FUTURES V
- Page 389 and 390:
PERSPECTIVE DE RECHERCHES FUTURES I
- Page 391 and 392:
LABURPENA PERSPECTIVE DE RECHERCHES
- Page 393 and 394:
AGERPENAK REPORTS COMUNICACIONES CO
- Page 395 and 396:
TADAO SHlMOMIYA languages before th
- Page 397 and 398:
LABURPENA TADAO SHIMOMIYA George Bo
- Page 399 and 400:
JEFFREY G. HEATH will deal here, ho
- Page 401 and 402:
JEFFREY G. HEATH with other typolog
- Page 403 and 404:
JEFFREY G. HEATH tested, but they s
- Page 405 and 406:
JEFFREY G. HEATH initial array of c
- Page 407 and 408:
JEFFREY G. HEATH as dative on the s
- Page 409 and 410:
JEFFREY G. HEATH morphologiquement,
- Page 411 and 412:
SHOTA DZIDZIGURI entre vosotros otr
- Page 413 and 414:
SHOTA DZIDZIGURI Zytsar, es «Intro
- Page 415 and 416:
SHOTA DZIDZIGURI Georgia also wishe
- Page 417 and 418:
SALOME GABUNIA Dans le présent rap
- Page 419 and 420:
SALOME GABUNIA recherches récentes
- Page 421 and 422:
SALOME GABUNIA To study in detail t
- Page 423 and 424:
ON EUSCARO-CAUCASIAN LINGUISTIC REL
- Page 425 and 426:
ON EUSCARO-CAUCASIAN LINGUISTIC REL
- Page 427 and 428:
ON EUSCARO-CAUCASIAN LINGUISTIC REL
- Page 429 and 430:
LINGUISTIQUE THEORIQUE - LINGUISTIQ
- Page 431 and 432:
LINGUISTIQUE THEORIQUE-LINGUISTIQUE
- Page 433 and 434:
LINGUISTIQUE THEORIQUE - LINGUISTIQ
- Page 435 and 436:
LINGUISTIQUE THEORIQUE - LINGUISTIQ
- Page 437 and 438:
LINGUISTIQUE THEORIQUE - LINGUISTIQ
- Page 439 and 440:
LINGUISTIQUE THEORIQUE - LINGUISTIQ
- Page 441 and 442:
LINGUISTIQUE THEORIQUE - LINGUISTIQ
- Page 443 and 444:
Ma. JOSE AZURMENDI - FC0. JOSE OLAR
- Page 445 and 446:
Ma JOSE AZURMENDI - FCO. JOSE OLART
- Page 447 and 448:
Ma JOSE AZURMENDI - FCO. JOSE OLART
- Page 449 and 450:
Ma JOSE AZURMENDI • FCO. JOSE OLA
- Page 451 and 452:
Ma JOSE AZURMENDI - FCO. JOSE OLART
- Page 453 and 454:
M" JOSE AZURMENDI - FCO. JOSE OLART
- Page 455 and 456:
2. Silaba moeta ezberdinetako maizt
- Page 457 and 458:
S1LABA MOETA CV - CVV KORPUS MONOSI
- Page 459 and 460:
SILABA MOETA V - VV KORPUS MONOSILA
- Page 461 and 462:
Mª JOSE AZURMENDI - FCO. JOSE OLAR
- Page 463 and 464:
Mª. JOSE AZURMENDI . FCO. JOSE OLA
- Page 465 and 466:
E/ FONEMA KORPUS V - VV VC - VVC CV
- Page 467 and 468:
^ /0/ FONEMA KORPUS V - VY VC - VVC
- Page 469 and 470:
INI FONEMA KORPUS V - VV VC - VVC C
- Page 471 and 472:
lT/ FONEMA KORPUS V - VV VC - VVC C
- Page 473 and 474:
D/ FONEMA KORPUS y - VV VC - VVC CV
- Page 475 and 476:
Z/ FONEMA KORPUS V - VV VC - VVC CV
- Page 477 and 478:
514 Mª JOSE AZURMENDI - FCO. JOSE
- Page 479 and 480:
M.ª JOSE AZURMENDI . FCO. JOSE OLA
- Page 481 and 482:
— Jacques Alliéres HIZLARIAK REP
- Page 483 and 484:
—Kilburn MacMurraugh Sacramenton
- Page 485 and 486:
— Odon de Apraiz Buesa GONBIDATUA
- Page 487 and 488:
IDAZKARITZA IRAUNKORRA SECRETARY BU
- Page 489 and 490:
Abaitua, 25. Abiven, 212. Adema, 26
- Page 491 and 492:
Etxahun, 39, 40, 361. Etxaide, 36,
- Page 493 and 494:
250, 252, 255, 277, 278, 286, 287,
- Page 495 and 496:
Wais, 164. Wald, 292, 293, 304. Wal
- Page 497 and 498:
Elustondo Etxeberria, Mikel. Azpeit
- Page 499 and 500:
AURKIBIDEA INDEX INDICE INDEX
- Page 501 and 502:
HIRUGARREN JARDUNA — THIRD SESSIO
- Page 503 and 504:
ARGAZKIAK PHOTOGRAPHYS FOTOGRAFIAS
- Page 505 and 506:
2. Gernikako Mahaia. Aita Villasant
- Page 507 and 508:
6. Jean Haritschelhar bere txostena
- Page 509 and 510:
10. Antonio Tovar Leioan. 11. Teren
- Page 511 and 512:
14. Luis Mitxelena bere txostena ir