2H 2015
intel-xeon-phi-sw-ecosystem-guide-2h-2015-public3 intel-xeon-phi-sw-ecosystem-guide-2h-2015-public3
Comparative Performance LAMMPS* Rhodopsin Benchmark; 512K Atoms LAMMPS* Rhodopsin Benchmark Performance (Mixed Precision); Includes External NVIDIA* Results 2/K20X + 1S AMD* 1 0 1 Node 32 Nodes 2S Intel® Xeon® processor E5-2697v2 (LAMMPS Baseline) 2S Intel® Xeon® processor E5-2697v2 (LAMMPS IA Package) 2S E5-2697v2 + Intel® Xeon Phi coprocessor 7120A Turbo Off (LAMMPS IA Package) Cray XK7: 1S AMD Opteron* 6274 + NVIDIA Tesla* K20X; Cray Gemini* Interconnect, PCIe* 2.0 (LAMMPS GPU Package) http://www.nvidia.com/docs/IO/122634/computational-chemistrybenchmarks.pdf) For configuration details, go here. 1.21X 1.75X 1 1 .9X 1.2X 1.72X 1.22X SOURCE: INTEL MEASURED RESULTS AS OF JULY, 2014 CLUSTER BENCHMARK Application: LAMMPS* 32 NODES Description: Simulation of molecular systems with classical models. Wide variety of academic, government, and industry users. Popular due to its versatility and support for a wide range of forcefields/potential models: Materials Science, Chemistry, Biophysics, Solid Mechanics, Granular Flow, etc. More at http://lammps.sandia.gov/ Availability: • Code: In main LAMMPS repository. • Recipe: Available here. APPROVED FOR PUBLIC PRESENTATION Usage Model: Load balancer offloads part of neighbor-list and nonbond force calculations to Intel® Xeon Phi coprocessor for concurrent calculations with CPU. Highlights: Improved results with Intel® Xeon® processor E5-2697 v2 and Intel Xeon Phi coprocessor 7120A. Dynamic load balancing allows for concurrent: • Data transfer between host and coprocessor. • Calculations of neighbor-list, non-bond, bond, and long-range terms. Same routines in LAMMPS Intel Package also run faster on CPU. Results: Up to 1.75X performance improvement utilizing Intel® Xeon® processors and Intel® Xeon Phi coprocessors with application optimization on a single node compared to the baseline configuration. Performance gains continue to hold at 1.72X when scaling up to 32 nodes, out-performing the alternative configuration. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to http://www.intel.com/performance *Other names and brands may be claimed as the property of others 30
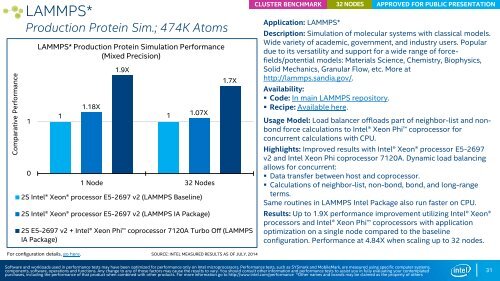
Comparative Performance LAMMPS* Production Protein Sim.; 474K Atoms 1 0 LAMMPS* Production Protein Simulation Performance (Mixed Precision) 1 1.18X 1.9X 1 Node 32 Nodes 2S Intel® Xeon® processor E5-2697 v2 (LAMMPS Baseline) 2S Intel® Xeon® processor E5-2697 v2 (LAMMPS IA Package) 2S E5-2697 v2 + Intel® Xeon Phi coprocessor 7120A Turbo Off (LAMMPS IA Package) 1 1.07X 1.7X CLUSTER BENCHMARK Application: LAMMPS* 32 NODES Description: Simulation of molecular systems with classical models. Wide variety of academic, government, and industry users. Popular due to its versatility and support for a wide range of forcefields/potential models: Materials Science, Chemistry, Biophysics, Solid Mechanics, Granular Flow, etc. More at http://lammps.sandia.gov/. Availability: • Code: In main LAMMPS repository. • Recipe: Available here. APPROVED FOR PUBLIC PRESENTATION Usage Model: Load balancer offloads part of neighbor-list and nonbond force calculations to Intel® Xeon Phi coprocessor for concurrent calculations with CPU. Highlights: Improved results with Intel® Xeon® processor E5-2697 v2 and Intel Xeon Phi coprocessor 7120A. Dynamic load balancing allows for concurrent: • Data transfer between host and coprocessor. • Calculations of neighbor-list, non-bond, bond, and long-range terms. Same routines in LAMMPS Intel Package also run faster on CPU. Results: Up to 1.9X performance improvement utilizing Intel® Xeon® processors and Intel® Xeon Phi coprocessors with application optimization on a single node compared to the baseline configuration. Performance at 4.84X when scaling up to 32 nodes. For configuration details, go here. SOURCE: INTEL MEASURED RESULTS AS OF JULY, 2014 Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to http://www.intel.com/performance *Other names and brands may be claimed as the property of others 31
- Page 1 and 2: 2H 2015
- Page 3 and 4: Intel® Modern Code Developer Chall
- Page 5 and 6: New or Updated Proof Points NEW pro
- Page 7 and 8: Intel® Xeon Phi Coprocessors Softw
- Page 9 and 10: Intel® Xeon® Processor E5-2697 v2
- Page 11 and 12: Memory Capacity (GB) Memory Compari
- Page 13 and 14: A Growing Ecosystem: The Intel® Xe
- Page 15 and 16: Comparative Performance LAMMPS* Sti
- Page 17 and 18: Comparative Performance Johns Hopki
- Page 19 and 20: Comparative Performance 1 0 BLAST*
- Page 21 and 22: Comparative Performance NAMD* 2.10
- Page 23 and 24: Comparative Performance LAMMPS* Liq
- Page 25 and 26: Comparative Performance LAMMPS* Rho
- Page 27 and 28: Comparative Performance LAMMPS* Liq
- Page 29: Comparative Performance LAMMPS* Rho
- Page 33 and 34: Comparative Performance AMBER* 14 P
- Page 35 and 36: Comparative Performance AMBER* 14 P
- Page 37 and 38: Comparative Performance Burrows-Whe
- Page 39 and 40: Comparative Performance NWChem* CCS
- Page 41 and 42: Discover and design like never befo
- Page 43 and 44: Comparative Performance miniGhost*
- Page 45 and 46: Comparative Performance Quantum ESP
- Page 47 and 48: Comparative Performance ANSYS Mecha
- Page 49 and 50: Comparative Performance ANSYS Mecha
- Page 51 and 52: Comparative Performance ANSYS Mecha
- Page 53 and 54: Comparative Performance Sandia Mant
- Page 55 and 56: Comparative Increase Autodesk Maya*
- Page 57 and 58: Comparative Performance OpenLB* Cyl
- Page 59 and 60: CLUSTER BENCHMARKS New Data Center
- Page 61 and 62: Comparative Performance Monte Carlo
- Page 63 and 64: Comparative Performance QuantLib* S
- Page 65 and 66: Comparative Performance Monte Carlo
- Page 67 and 68: Comparative Performance Monte Carlo
- Page 69 and 70: Comparative Performance Monte Carlo
- Page 71 and 72: Comparative Performance Xcelerit* L
- Page 73 and 74: Comparative Increase 1 0 Iso3DFD* 1
- Page 75 and 76: Comparative Performance Petrobras*
- Page 77 and 78: CLUSTER BENCHMARK Data Center Serve
- Page 79 and 80: Comparative Performance BerkeleyGW*
Comparative Performance<br />
LAMMPS*<br />
Production Protein Sim.; 474K Atoms<br />
1<br />
0<br />
LAMMPS* Production Protein Simulation Performance<br />
(Mixed Precision)<br />
1<br />
1.18X<br />
1.9X<br />
1 Node 32 Nodes<br />
2S Intel® Xeon® processor E5-2697 v2 (LAMMPS Baseline)<br />
2S Intel® Xeon® processor E5-2697 v2 (LAMMPS IA Package)<br />
2S E5-2697 v2 + Intel® Xeon Phi coprocessor 7120A Turbo Off (LAMMPS<br />
IA Package)<br />
1<br />
1.07X<br />
1.7X<br />
CLUSTER BENCHMARK<br />
Application: LAMMPS*<br />
32 NODES<br />
Description: Simulation of molecular systems with classical models.<br />
Wide variety of academic, government, and industry users. Popular<br />
due to its versatility and support for a wide range of forcefields/potential<br />
models: Materials Science, Chemistry, Biophysics,<br />
Solid Mechanics, Granular Flow, etc. More at<br />
http://lammps.sandia.gov/.<br />
Availability:<br />
• Code: In main LAMMPS repository.<br />
• Recipe: Available here.<br />
APPROVED FOR PUBLIC PRESENTATION<br />
Usage Model: Load balancer offloads part of neighbor-list and nonbond<br />
force calculations to Intel® Xeon Phi coprocessor for<br />
concurrent calculations with CPU.<br />
Highlights: Improved results with Intel® Xeon® processor E5-2697<br />
v2 and Intel Xeon Phi coprocessor 7120A. Dynamic load balancing<br />
allows for concurrent:<br />
• Data transfer between host and coprocessor.<br />
• Calculations of neighbor-list, non-bond, bond, and long-range<br />
terms.<br />
Same routines in LAMMPS Intel Package also run faster on CPU.<br />
Results: Up to 1.9X performance improvement utilizing Intel® Xeon®<br />
processors and Intel® Xeon Phi coprocessors with application<br />
optimization on a single node compared to the baseline<br />
configuration. Performance at 4.84X when scaling up to 32 nodes.<br />
For configuration details, go here.<br />
SOURCE: INTEL MEASURED RESULTS AS OF JULY, 2014<br />
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems,<br />
components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated<br />
purchases, including the performance of that product when combined with other products. For more information go to http://www.intel.com/performance *Other names and brands may be claimed as the property of others<br />
31


