Apress.Expert.Oracle.Database.Architecture.9i.and.10g.Programming.Techniques.and.Solutions.Sep.2005
CHAPTER 11 ■ INDEXES 433 if ( (++cnt%100) == 0 ) { exec sql commit; } } exec sql whenever notfound continue; exec sql commit; exec sql close c; The Pro*C was precompiled with a PREFETCH of 100, making this C code analogous to the PL/SQL code in Oracle 10g. ■Note In Oracle 10g Release 1 and above, a simple FOR X IN ( SELECT * FROM T ) in PL/SQL will silently array fetch 100 rows at a time, whereas in Oracle9i and before, it fetches just a single row at a time. Therefore, if you want to reproduce this example on Oracle9i and before, you will need to modify the PL/SQL code to also array fetch with the BULK COLLECT syntax. Both would fetch 100 rows at a time and then single row insert the data into another table. The following tables summarize the differences between the various runs, starting with the single user test in Table 11-1. Table 11-1. Performance Test for Use of Reverse Key Indexes with PL/SQL and Pro*C: Single User Reverse No Reverse Reverse No Reverse PL/SQL PL/SQL Pro*C Pro*C Transaction/second 38.24 43.45 17.35 19.08 CPU time (seconds) 25 22 33 31 Buffer busy waits number/time 0/0 0/0 0/0 0/0 Elapsed time (minutes) 0.42 0.37 0.92 0.83 Log file sync number/time 6/0 1,940/7 1,940/7 From the first single-user test, we can see that PL/SQL was measurably more efficient than Pro*C in performing this operation, a trend we’ll continue to see as we scale up the user load. Part of the reason Pro*C won’t scale as well as PL/SQL will be the log file sync waits that Pro*C must wait for, but which PL/SQL has an optimization to avoid. It would appear from this single-user test that reverse key indexes consume more CPU. This makes sense because the database must perform extra work as it carefully reverses the bytes in the key. But, we’ll see that this logic won’t hold true as we scale up the users. As we introduce contention, the overhead of the reverse key index will completely disappear. In fact, even by the time we get the two-user test, the overhead is mostly offset by the contention on the right-hand side of the index, as shown in Table 11-2.
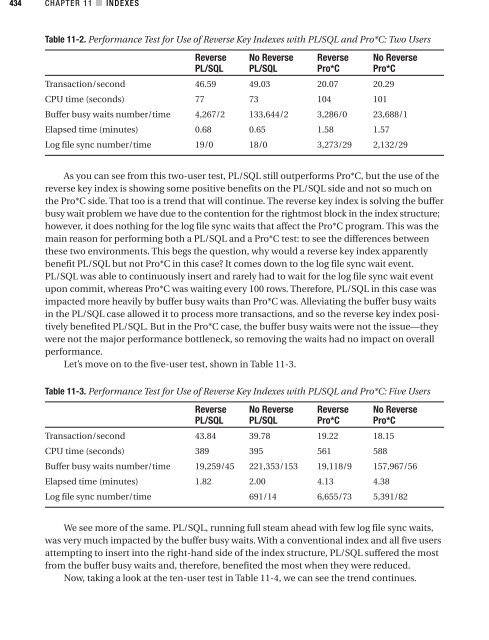
434 CHAPTER 11 ■ INDEXES Table 11-2. Performance Test for Use of Reverse Key Indexes with PL/SQL and Pro*C: Two Users Reverse No Reverse Reverse No Reverse PL/SQL PL/SQL Pro*C Pro*C Transaction/second 46.59 49.03 20.07 20.29 CPU time (seconds) 77 73 104 101 Buffer busy waits number/time 4,267/2 133,644/2 3,286/0 23,688/1 Elapsed time (minutes) 0.68 0.65 1.58 1.57 Log file sync number/time 19/0 18/0 3,273/29 2,132/29 As you can see from this two-user test, PL/SQL still outperforms Pro*C, but the use of the reverse key index is showing some positive benefits on the PL/SQL side and not so much on the Pro*C side. That too is a trend that will continue. The reverse key index is solving the buffer busy wait problem we have due to the contention for the rightmost block in the index structure; however, it does nothing for the log file sync waits that affect the Pro*C program. This was the main reason for performing both a PL/SQL and a Pro*C test: to see the differences between these two environments. This begs the question, why would a reverse key index apparently benefit PL/SQL but not Pro*C in this case? It comes down to the log file sync wait event. PL/SQL was able to continuously insert and rarely had to wait for the log file sync wait event upon commit, whereas Pro*C was waiting every 100 rows. Therefore, PL/SQL in this case was impacted more heavily by buffer busy waits than Pro*C was. Alleviating the buffer busy waits in the PL/SQL case allowed it to process more transactions, and so the reverse key index positively benefited PL/SQL. But in the Pro*C case, the buffer busy waits were not the issue—they were not the major performance bottleneck, so removing the waits had no impact on overall performance. Let’s move on to the five-user test, shown in Table 11-3. Table 11-3. Performance Test for Use of Reverse Key Indexes with PL/SQL and Pro*C: Five Users Reverse No Reverse Reverse No Reverse PL/SQL PL/SQL Pro*C Pro*C Transaction/second 43.84 39.78 19.22 18.15 CPU time (seconds) 389 395 561 588 Buffer busy waits number/time 19,259/45 221,353/153 19,118/9 157,967/56 Elapsed time (minutes) 1.82 2.00 4.13 4.38 Log file sync number/time 691/14 6,655/73 5,391/82 We see more of the same. PL/SQL, running full steam ahead with few log file sync waits, was very much impacted by the buffer busy waits. With a conventional index and all five users attempting to insert into the right-hand side of the index structure, PL/SQL suffered the most from the buffer busy waits and, therefore, benefited the most when they were reduced. Now, taking a look at the ten-user test in Table 11-4, we can see the trend continues.
- Page 427 and 428: 382 CHAPTER 10 ■ DATABASE TABLES
- Page 429 and 430: 384 CHAPTER 10 ■ DATABASE TABLES
- Page 431 and 432: 386 CHAPTER 10 ■ DATABASE TABLES
- Page 433 and 434: 388 CHAPTER 10 ■ DATABASE TABLES
- Page 435 and 436: 390 CHAPTER 10 ■ DATABASE TABLES
- Page 437 and 438: 392 CHAPTER 10 ■ DATABASE TABLES
- Page 439 and 440: 394 CHAPTER 10 ■ DATABASE TABLES
- Page 441 and 442: 396 CHAPTER 10 ■ DATABASE TABLES
- Page 443 and 444: 398 CHAPTER 10 ■ DATABASE TABLES
- Page 445 and 446: 400 CHAPTER 10 ■ DATABASE TABLES
- Page 447 and 448: 402 CHAPTER 10 ■ DATABASE TABLES
- Page 449 and 450: 404 CHAPTER 10 ■ DATABASE TABLES
- Page 451 and 452: 406 CHAPTER 10 ■ DATABASE TABLES
- Page 453 and 454: 408 CHAPTER 10 ■ DATABASE TABLES
- Page 455 and 456: 410 CHAPTER 10 ■ DATABASE TABLES
- Page 457 and 458: 412 CHAPTER 10 ■ DATABASE TABLES
- Page 459 and 460: 414 CHAPTER 10 ■ DATABASE TABLES
- Page 461 and 462: 416 CHAPTER 10 ■ DATABASE TABLES
- Page 463 and 464: 418 CHAPTER 10 ■ DATABASE TABLES
- Page 466 and 467: CHAPTER 11 ■ ■ ■ Indexes Inde
- Page 468 and 469: CHAPTER 11 ■ INDEXES 423 value of
- Page 470 and 471: CHAPTER 11 ■ INDEXES 425 One of t
- Page 472 and 473: CHAPTER 11 ■ INDEXES 427 We then
- Page 474 and 475: CHAPTER 11 ■ INDEXES 429 we ended
- Page 476 and 477: CHAPTER 11 ■ INDEXES 431 The data
- Page 480 and 481: CHAPTER 11 ■ INDEXES 435 Table 11
- Page 482 and 483: CHAPTER 11 ■ INDEXES 437 When Sho
- Page 484 and 485: CHAPTER 11 ■ INDEXES 439 an 8KB b
- Page 486 and 487: CHAPTER 11 ■ INDEXES 441 select *
- Page 488 and 489: CHAPTER 11 ■ INDEXES 443 select *
- Page 490 and 491: CHAPTER 11 ■ INDEXES 445 Indicate
- Page 492 and 493: CHAPTER 11 ■ INDEXES 447 an index
- Page 494 and 495: CHAPTER 11 ■ INDEXES 449 Table 11
- Page 496 and 497: CHAPTER 11 ■ INDEXES 451 9 1, 'M'
- Page 498 and 499: CHAPTER 11 ■ INDEXES 453 column w
- Page 500 and 501: CHAPTER 11 ■ INDEXES 455 Bitmap j
- Page 502 and 503: CHAPTER 11 ■ INDEXES 457 INSERT a
- Page 504 and 505: CHAPTER 11 ■ INDEXES 459 7 l_last
- Page 506 and 507: CHAPTER 11 ■ INDEXES 461 ops$tkyt
- Page 508 and 509: CHAPTER 11 ■ INDEXES 463 If we co
- Page 510 and 511: CHAPTER 11 ■ INDEXES 465 ops$tkyt
- Page 512 and 513: CHAPTER 11 ■ INDEXES 467 Caveat o
- Page 514 and 515: CHAPTER 11 ■ INDEXES 469 ops$tkyt
- Page 516 and 517: CHAPTER 11 ■ INDEXES 471 Frequent
- Page 518 and 519: CHAPTER 11 ■ INDEXES 473 select *
- Page 520 and 521: CHAPTER 11 ■ INDEXES 475 If you s
- Page 522 and 523: CHAPTER 11 ■ INDEXES 477 we’ll
- Page 524 and 525: CHAPTER 11 ■ INDEXES 479 Predicat
- Page 526 and 527: CHAPTER 11 ■ INDEXES 481 ops$tkyt
434<br />
CHAPTER 11 ■ INDEXES<br />
Table 11-2. Performance Test for Use of Reverse Key Indexes with PL/SQL <strong>and</strong> Pro*C: Two Users<br />
Reverse No Reverse Reverse No Reverse<br />
PL/SQL PL/SQL Pro*C Pro*C<br />
Transaction/second 46.59 49.03 20.07 20.29<br />
CPU time (seconds) 77 73 104 101<br />
Buffer busy waits number/time 4,267/2 133,644/2 3,286/0 23,688/1<br />
Elapsed time (minutes) 0.68 0.65 1.58 1.57<br />
Log file sync number/time 19/0 18/0 3,273/29 2,132/29<br />
As you can see from this two-user test, PL/SQL still outperforms Pro*C, but the use of the<br />
reverse key index is showing some positive benefits on the PL/SQL side <strong>and</strong> not so much on<br />
the Pro*C side. That too is a trend that will continue. The reverse key index is solving the buffer<br />
busy wait problem we have due to the contention for the rightmost block in the index structure;<br />
however, it does nothing for the log file sync waits that affect the Pro*C program. This was the<br />
main reason for performing both a PL/SQL <strong>and</strong> a Pro*C test: to see the differences between<br />
these two environments. This begs the question, why would a reverse key index apparently<br />
benefit PL/SQL but not Pro*C in this case? It comes down to the log file sync wait event.<br />
PL/SQL was able to continuously insert <strong>and</strong> rarely had to wait for the log file sync wait event<br />
upon commit, whereas Pro*C was waiting every 100 rows. Therefore, PL/SQL in this case was<br />
impacted more heavily by buffer busy waits than Pro*C was. Alleviating the buffer busy waits<br />
in the PL/SQL case allowed it to process more transactions, <strong>and</strong> so the reverse key index positively<br />
benefited PL/SQL. But in the Pro*C case, the buffer busy waits were not the issue—they<br />
were not the major performance bottleneck, so removing the waits had no impact on overall<br />
performance.<br />
Let’s move on to the five-user test, shown in Table 11-3.<br />
Table 11-3. Performance Test for Use of Reverse Key Indexes with PL/SQL <strong>and</strong> Pro*C: Five Users<br />
Reverse No Reverse Reverse No Reverse<br />
PL/SQL PL/SQL Pro*C Pro*C<br />
Transaction/second 43.84 39.78 19.22 18.15<br />
CPU time (seconds) 389 395 561 588<br />
Buffer busy waits number/time 19,259/45 221,353/153 19,118/9 157,967/56<br />
Elapsed time (minutes) 1.82 2.00 4.13 4.38<br />
Log file sync number/time 691/14 6,655/73 5,391/82<br />
We see more of the same. PL/SQL, running full steam ahead with few log file sync waits,<br />
was very much impacted by the buffer busy waits. With a conventional index <strong>and</strong> all five users<br />
attempting to insert into the right-h<strong>and</strong> side of the index structure, PL/SQL suffered the most<br />
from the buffer busy waits <strong>and</strong>, therefore, benefited the most when they were reduced.<br />
Now, taking a look at the ten-user test in Table 11-4, we can see the trend continues.


