Direct Numerical Simulation of Autoignition in a Jet in a Cross-Flow ...
Direct Numerical Simulation of Autoignition in a Jet in a Cross-Flow ... Direct Numerical Simulation of Autoignition in a Jet in a Cross-Flow ...
Chapter 2Parallel Scaling and parallelefficiency metrics2.1 Measurement of Parallel EfficiencyParallel code scaling focuses on one of two forms: strong scaling or weak scaling.The goal of strong scaling is to reduce execution time for a fixed total problem sizeby adding processors (and hence reducing problem size per worker/MPI rank). Onthe other hand, ideal weak scaling behavior is to keep the execution time constantby adding processors in proportion to an increasingly larger problem size (andhence keeping problem size per worker fixed).Parallel efficiency,η, for a problem run on N 1 processes/MPI ranks is definedrelative to a reference run on N 2 ranks asη p = N 1 t(N 1 )N 2 t(N 2 ) ,where t(N) is the execution time on N ranks.In order to ensure core utilization we measure the MPI-threading efficiencywhich we define asη t = N 1 t(N 1 )N 2 t(N 2 ) ,where N 1 is the number of cores for the one MPI rank/thread per core configurationand N 2 = 2N 1 in the two threads/core and N 2 = 4N 1 in the four threads/coreconfigurations. Note that a net speedup is obtained for threading efficiency ofmore than 50% in the two threads/core configuration and more than 25% in thefour threads/core.2.1.1 Core-level MPI Threading EfficiencyInstantiation of two and four MPI-ranks per core is enabled on Mira and hence fullcore compute power utilization is assured through the use of more than one rank per4
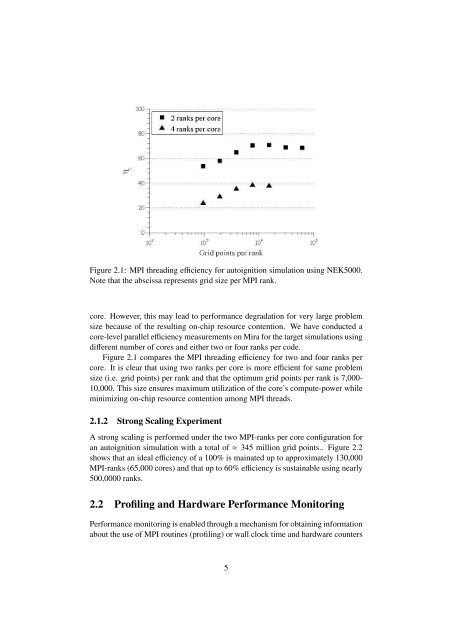
Figure 2.1: MPI threading efficiency for autoignition simulation using NEK5000.Note that the abscissa represents grid size per MPI rank.core. However, this may lead to performance degradation for very large problemsize because of the resulting on-chip resource contention. We have conducted acore-level parallel efficiency measurements on Mira for the target simulations usingdifferent number of cores and either two or four ranks per code.Figure 2.1 compares the MPI threading efficiency for two and four ranks percore. It is clear that using two ranks per core is more efficient for same problemsize (i.e. grid points) per rank and that the optimum grid points per rank is 7,000-10,000. This size ensures maximum utilization of the core’s compute-power whileminimizing on-chip resource contention among MPI threads.2.1.2 Strong Scaling ExperimentA strong scaling is performed under the two MPI-ranks per core configuration foran autoignition simulation with a total of≈ 345 million grid points.. Figure 2.2shows that an ideal efficiency of a 100% is mainated up to approximately 130,000MPI-ranks (65,000 cores) and that up to 60% efficiency is sustainable using nearly500,0000 ranks.2.2 Profiling and Hardware Performance MonitoringPerformance monitoring is enabled through a mechanism for obtaining informationabout the use of MPI routines (profiling) or wall clock time and hardware counters5
- Page 1 and 2: ANL/ALCF/ESP-13/3Direct Numerical S
- Page 3 and 4: ANL/ALCF/ESP-13/3Direct Numerical S
- Page 5 and 6: AbstractAutoignition in turbulent f
- Page 7 and 8: Chapter 1IntroductionUnderstanding
- Page 9: 1.1.1 Summary of Numerical Simulati
- Page 13 and 14: • A utility hpmcount, which start
- Page 15 and 16: is a trend of increasing access to
- Page 17 and 18: BibliographyCohen, S. and Hindmarsh
Figure 2.1: MPI thread<strong>in</strong>g efficiency for autoignition simulation us<strong>in</strong>g NEK5000.Note that the abscissa represents grid size per MPI rank.core. However, this may lead to performance degradation for very large problemsize because <strong>of</strong> the result<strong>in</strong>g on-chip resource contention. We have conducted acore-level parallel efficiency measurements on Mira for the target simulations us<strong>in</strong>gdifferent number <strong>of</strong> cores and either two or four ranks per code.Figure 2.1 compares the MPI thread<strong>in</strong>g efficiency for two and four ranks percore. It is clear that us<strong>in</strong>g two ranks per core is more efficient for same problemsize (i.e. grid po<strong>in</strong>ts) per rank and that the optimum grid po<strong>in</strong>ts per rank is 7,000-10,000. This size ensures maximum utilization <strong>of</strong> the core’s compute-power whilem<strong>in</strong>imiz<strong>in</strong>g on-chip resource contention among MPI threads.2.1.2 Strong Scal<strong>in</strong>g ExperimentA strong scal<strong>in</strong>g is performed under the two MPI-ranks per core configuration foran autoignition simulation with a total <strong>of</strong>≈ 345 million grid po<strong>in</strong>ts.. Figure 2.2shows that an ideal efficiency <strong>of</strong> a 100% is ma<strong>in</strong>ated up to approximately 130,000MPI-ranks (65,000 cores) and that up to 60% efficiency is susta<strong>in</strong>able us<strong>in</strong>g nearly500,0000 ranks.2.2 Pr<strong>of</strong>il<strong>in</strong>g and Hardware Performance Monitor<strong>in</strong>gPerformance monitor<strong>in</strong>g is enabled through a mechanism for obta<strong>in</strong><strong>in</strong>g <strong>in</strong>formationabout the use <strong>of</strong> MPI rout<strong>in</strong>es (pr<strong>of</strong>il<strong>in</strong>g) or wall clock time and hardware counters5


