1. Is there a benefit in combining web-scale counts with the standard features used instate-of-the-art supervised approaches?2. How well do web-based models per<strong>for</strong>m on new domains or when labeled data isscarce?We address these questions on two generation and two analysis tasks, using both existingN-gram data and a novel web-scale N-gram corpus that includes part-of-speech in<strong>for</strong>mation(Section 5.2). While previous work has combined web-scale features with otherfeatures in specific classification problems [Modjeska et al., 2003; Yang et al., 2005; Vadasand Curran, 2007b; Tratz and Hovy, 2010], we provide a multi-task, multi-domain comparison.Some may question why supervised learning with standard features is needed at all <strong>for</strong>generation problems. Why not solely rely on direct evidence from a giant corpus? Forexample, <strong>for</strong> the task of prenominal adjective ordering (Section 5.3), a system that needs todescribe a ball that is both big and red can simply check that big red is more common onthe web than red big, and order the adjectives accordingly.It is, however, suboptimal to only use simple counts from N-gram data. For example,ordering adjectives by direct web evidence per<strong>for</strong>ms 7% worse than our best supervisedsystem (Section 5.3.2). No matter how large the web becomes, there will always be plausibleconstructions that never occur. For example, there are currently no pages indexedby Google with the preferred adjective ordering <strong>for</strong> bedraggled 56-year-old [professor].Also, in a particular domain, words may have a non-standard usage. Systems trained onlabeled data can learn the domain usage and leverage other regularities, such as suffixes andtransitivity <strong>for</strong> adjective ordering.With these benefits, systems trained on labeled data have become the dominant technologyin academic NLP. There is a growing recognition, however, that these systems arehighly domain dependent. For example, parsers trained on annotated newspaper text per<strong>for</strong>mpoorly on other genres [Gildea, 2001]. While many approaches have adapted NLPsystems to specific domains [Tsuruoka et al., 2005; McClosky et al., 2006b; Blitzer et al.,2007; Daumé III, 2007; Rimell and Clark, 2008], these techniques assume the system knowson which domain it is being used, and that it has access to representative data in that domain.These assumptions are unrealistic in many real-world situations; <strong>for</strong> example, whenautomatically processing a heterogeneous collection of web pages. How well do supervisedand unsupervised NLP systems per<strong>for</strong>m when used uncustomized, out-of-the-box on newdomains, and how can we best design our systems <strong>for</strong> robust open-domain per<strong>for</strong>mance?Our results show that using web-scale N-gram data in supervised systems advancesthe state-of-the-art per<strong>for</strong>mance on standard analysis and generation tasks. More importantly,when operating out-of-domain, or when labeled data is not plentiful, using web-scaleN-gram data not only helps achieve good per<strong>for</strong>mance – it is essential.5.2 Experiments and Data5.2.1 Experimental DesignWe again evaluate the benefit of N-gram data on multi-class classification problems. Foreach task, we have some labeled data indicating the correct output <strong>for</strong> each example. Weevaluate with accuracy: the percentage of examples correctly classified in test data. We69
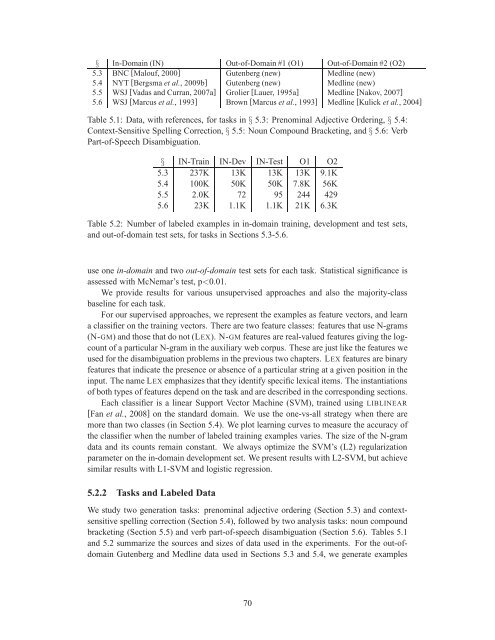
§ In-Domain (IN) Out-of-Domain #1 (O1) Out-of-Domain #2 (O2)5.3 BNC [Malouf, 2000] Gutenberg (new) Medline (new)5.4 NYT [Bergsma et al., 2009b] Gutenberg (new) Medline (new)5.5 WSJ [Vadas and Curran, 2007a] Grolier [Lauer, 1995a] Medline [Nakov, 2007]5.6 WSJ [Marcus et al., 1993] Brown [Marcus et al., 1993] Medline [Kulick et al., 2004]Table 5.1: Data, with references, <strong>for</strong> tasks in § 5.3: Prenominal Adjective Ordering, § 5.4:Context-Sensitive Spelling Correction, § 5.5: Noun Compound Bracketing, and§5.6: VerbPart-of-Speech Disambiguation.§ IN-Train IN-Dev IN-Test O1 O25.3 237K 13K 13K 13K 9.1K5.4 100K 50K 50K 7.8K 56K5.5 2.0K 72 95 244 4295.6 23K 1.1K 1.1K 21K 6.3KTable 5.2: Number of labeled examples in in-domain training, development and test sets,and out-of-domain test sets, <strong>for</strong> tasks in Sections 5.3-5.6.use one in-domain and two out-of-domain test sets <strong>for</strong> each task. Statistical significance isassessed with McNemar’s test, p
- Page 1 and 2:
University of AlbertaLarge-Scale Se
- Page 5 and 6:
Table of Contents1 Introduction 11.
- Page 7 and 8:
7 Alignment-Based Discriminative St
- Page 9 and 10:
List of Figures2.1 The linear class
- Page 11 and 12:
drawn in by establishing a partial
- Page 13 and 14:
(2) “He saw the trophy won yester
- Page 15 and 16:
actual sentence said, “My son’s
- Page 17 and 18:
Uses Web-Scale N-grams Auto-Creates
- Page 19 and 20:
spelling correction, and the identi
- Page 21 and 22:
Chapter 2Supervised and Semi-Superv
- Page 23 and 24:
emphasis on “deliverables and eva
- Page 25 and 26:
Figure 2.1: The linear classifier h
- Page 27 and 28: The above experimental set-up is so
- Page 29 and 30: and discriminative models therefore
- Page 31 and 32: their slack value). In practice, I
- Page 33 and 34: One way to find a better solution i
- Page 35 and 36: Figure 2.2: Learning from labeled a
- Page 37 and 38: algorithm). Yarowsky used it for wo
- Page 39 and 40: Learning with Natural Automatic Exa
- Page 41 and 42: positive examples from any collecti
- Page 43 and 44: generated word clusters. Several re
- Page 45 and 46: One common disambiguation task is t
- Page 47 and 48: 3.2.2 Web-Scale Statistics in NLPEx
- Page 49 and 50: For each target wordv 0 , there are
- Page 51 and 52: ut without counts for the class pri
- Page 53 and 54: Accuracy (%)10090807060SUPERLMSUMLM
- Page 55 and 56: We also follow Carlson et al. [2001
- Page 57 and 58: Set BASE [Golding and Roth, 1999] T
- Page 59 and 60: pronoun (#3) guarantees that at the
- Page 61 and 62: 807876F-Score747270Stemmed patterns
- Page 63 and 64: anaphoricity by [Denis and Baldridg
- Page 65 and 66: ter, we present a simple technique
- Page 67 and 68: We seek weights such that the class
- Page 69 and 70: each optimum performance is at most
- Page 71 and 72: We now show that ¯w T (diag(¯p)
- Page 73 and 74: Training ExamplesSystem 10 100 1K 1
- Page 75 and 76: Since we wanted the system to learn
- Page 77: Chapter 5Creating Robust Supervised
- Page 81 and 82: Adjective ordering is also needed i
- Page 83 and 84: Accuracy (%)10095908580757065601001
- Page 85 and 86: System IN O1 O2Baseline 66.9 44.6 6
- Page 87 and 88: 90% of the time in Gutenberg. The L
- Page 89 and 90: VBN/VBD distinction by providing re
- Page 91 and 92: other tasks we only had a handful o
- Page 93 and 94: without the need for manual annotat
- Page 95 and 96: DSP uses these labels to identify o
- Page 97 and 98: Semantic classesMotivated by previo
- Page 99 and 100: empirical Pr(n|v) in Equation (6.2)
- Page 101 and 102: Verb Plaus./Implaus. Resnik Dagan e
- Page 103 and 104: SystemAccMost-Recent Noun 17.9%Maxi
- Page 105 and 106: Chapter 7Alignment-Based Discrimina
- Page 107 and 108: ious measures to learn the recurren
- Page 109 and 110: how labeled word pairs can be colle
- Page 111 and 112: Figure 7.1: LCSR histogram and poly
- Page 113 and 114: 0.711-pt Average Precision0.60.50.4
- Page 115 and 116: Fr-En Bitext Es-En Bitext De-En Bit
- Page 117 and 118: Chapter 8Conclusions and Future Wor
- Page 119 and 120: 8.3 Future WorkThis section outline
- Page 121 and 122: My focus is thus on enabling robust
- Page 123 and 124: [Bergsma and Cherry, 2010] Shane Be
- Page 125 and 126: [Church and Mercer, 1993] Kenneth W
- Page 127 and 128: [Grefenstette, 1999] Gregory Grefen
- Page 129 and 130:
[Koehn, 2005] Philipp Koehn. Europa
- Page 131 and 132:
[Mihalcea and Moldovan, 1999] Rada
- Page 133 and 134:
[Ristad and Yianilos, 1998] Eric Sv
- Page 135 and 136:
[Wang et al., 2008] Qin Iris Wang,
- Page 137:
NNP noun, proper, singular Motown V