- Page 2 and 3: Commission of the Russian Federatio
- Page 4 and 5: Contents Preface...................
- Page 6 and 7: Elmir YAKUBOV. Developing Digital C
- Page 8 and 9: PREFACE The 2 nd International Conf
- Page 10 and 11: MESSAGES Message from Irina Bokova,
- Page 12 and 13: Message from Grigory Ordzhonikidze,
- Page 14 and 15: Message from Alexander Avdeyev, Min
- Page 16 and 17: Message from Andrei Fursenko, Minis
- Page 18 and 19: Message from Abulfas Karayev, Minis
- Page 20 and 21: PLENARY MEETINGS Adama SAMASSÉKOU,
- Page 22 and 23: supporting multilingualism, particu
- Page 24 and 25: to the idea of respect for linguist
- Page 26 and 27: Evgenia MIKHAILOVA Rector, North-Ea
- Page 28 and 29: anked third (after Moscow and St. P
- Page 30 and 31: • the Institute of Languages and
- Page 32 and 33: The NEFU Development Programme incl
- Page 34 and 35: marginalisation, and to enhance the
- Page 36 and 37: Second, institutes are needed to a)
- Page 38 and 39: • targeting federal funding and s
- Page 40 and 41: • providing telecommunication net
- Page 42 and 43: Education Primary, secondary and hi
- Page 44 and 45: • digitising documents and museum
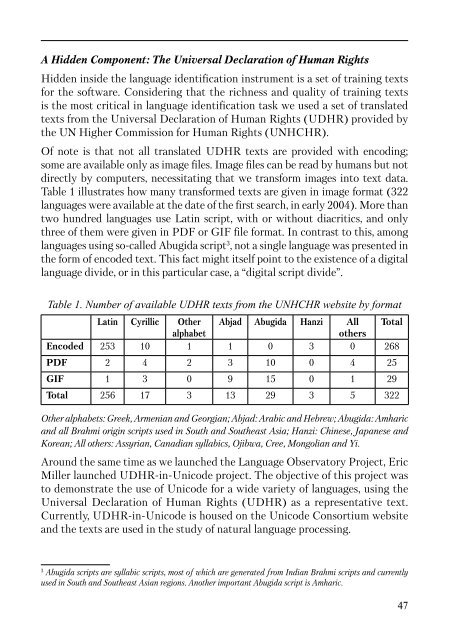
- Page 46 and 47: The ICT Industry Issues of linguist
- Page 50 and 51: If anyone in a community speaks the
- Page 52 and 53: Here we propose a two-dimensional c
- Page 54 and 55: Table 3. Language composition of th
- Page 56 and 57: Also we need a deeper analysis of t
- Page 58 and 59: at measuring the linguistic diversi
- Page 60 and 61: Multilingual Moments of Truth: Mome
- Page 62 and 63: things in place it is possible to d
- Page 64 and 65: Copyright and Public Domain Where d
- Page 66 and 67: Thus it is important that we create
- Page 68 and 69: Organizing Information About the Wo
- Page 70 and 71: virtual library of language resourc
- Page 72 and 73: We have also developed software tha
- Page 74 and 75: We should recall that most of the w
- Page 76 and 77: Fig.8 - Language of publication of
- Page 78 and 79: In 2008, we compared the first 30 l
- Page 80 and 81: translators and to human translator
- Page 82 and 83: The African Linguistic Mosaic The l
- Page 84 and 85: Factors Militating Against the Pres
- Page 86 and 87: Taking into account the work on the
- Page 88 and 89: priorities in the Language Plan of
- Page 90 and 91: Gilvan Müller de OLIVEIRA Director
- Page 92 and 93: In this particular aspect the Portu
- Page 94 and 95: • Bilingual education programmes
- Page 96 and 97: Javier LÓPEZ SÁNCHEZ Director Gen
- Page 98 and 99:
linkages and coordination of effort
- Page 100 and 101:
The following proposals for action
- Page 102 and 103:
existence (Deshpande 1979). When Bu
- Page 104 and 105:
All the above academic, language an
- Page 106 and 107:
centres for Indian Language Technol
- Page 108 and 109:
Natalia GENDINA Director, Research
- Page 110 and 111:
Activities of social institutions,
- Page 112 and 113:
• publication in 2008 under the a
- Page 114 and 115:
• interactivity - active interact
- Page 116 and 117:
5. Всеобщая деклара
- Page 118 and 119:
The proportion of native speakers r
- Page 120 and 121:
• destruction of the genetic fund
- Page 122 and 123:
humanitarian practices for the pres
- Page 124 and 125:
SECTION 1. INSTRUMENTS FOR LANGUAGE
- Page 126 and 127:
social status In a multilingual sit
- Page 128 and 129:
Virach SORNLERTLAMVANICH Principle
- Page 130 and 131:
Figure 1. Community Co-Creation Cul
- Page 132 and 133:
Yunseok RHEE Professor, Hankuk Univ
- Page 134 and 135:
3. Approaches for Web-Based Languag
- Page 136 and 137:
integration mentioned prior). For a
- Page 138 and 139:
capacity to read and write. Worse s
- Page 140 and 141:
To accommodate orature in cyberspac
- Page 142 and 143:
Nicholas THIEBERGER Senior Research
- Page 144 and 145:
others,but be used as a foundation
- Page 146 and 147:
4. Delivery of Archival Material, P
- Page 148 and 149:
6. Current Status of the PARADISEC
- Page 150 and 151:
an occasional mass backup of signif
- Page 152 and 153:
Dietrich SCHÜLLER Consultant, Vien
- Page 154 and 155:
carriers into safe digital reposito
- Page 156 and 157:
National: Other successful, althoug
- Page 158 and 159:
6. Schüller, Dietrich. Audiovisual
- Page 160 and 161:
eing produced and exposed all aroun
- Page 162 and 163:
news, among others. The very nature
- Page 164 and 165:
Attempt to Validate the Hypothesis
- Page 166 and 167:
Elmir YAKUBOV Director, Khasavyurt
- Page 168 and 169:
uilding up a cult of ethnic excepti
- Page 170 and 171:
Figure 1. Representation of additio
- Page 172 and 173:
PT Sans is a grotesque font of mode
- Page 174 and 175:
Google Web Fonts API Stats monitors
- Page 176 and 177:
the low spread (at the time) of the
- Page 178 and 179:
Dzhavdet Suleymanov Professor, Kaza
- Page 180 and 181:
about this package. Due to our expe
- Page 182 and 183:
• Annotated texts, dictionaries,
- Page 184 and 185:
we identify structures, circuits, a
- Page 186 and 187:
Yakut Epic in Cyberspace: Olonkho I
- Page 188 and 189:
Its Information Gathering & Process
- Page 190 and 191:
Olonkho: Television allows to broad
- Page 192 and 193:
Here are some of the Olonkho-relate
- Page 194 and 195:
texts totalling some two million wo
- Page 196 and 197:
Anatoly ZHOZHIKOV Director, New Inf
- Page 198 and 199:
facilitate both the preservation of
- Page 200 and 201:
SECTION 2. INSTITUTES TO PROMOTE LI
- Page 202 and 203:
“Vision 2013 By 2013… • UArct
- Page 204 and 205:
together university and college Pre
- Page 206 and 207:
• UArctic Studies Catalogue • G
- Page 208 and 209:
“2. Teaching of language and cult
- Page 210 and 211:
Sergei BAKEYKIN Executive Director,
- Page 212 and 213:
the fact that in 2010, Evgeny Kuzmi
- Page 214 and 215:
The Conference final document -“T
- Page 216 and 217:
and how to promote social/digital i
- Page 218 and 219:
From this perspective I could under
- Page 220 and 221:
one local language and to register
- Page 222 and 223:
• Permit to many repertoires to i
- Page 224 and 225:
• Funding institutions with diffi
- Page 226 and 227:
Zhanna SHAIMUKHANBETOVA Director Ge
- Page 228 and 229:
• quantitative (the proportion of
- Page 230 and 231:
humanity and giving support to expr
- Page 232 and 233:
Irina DOBRYNINA Director, National
- Page 234 and 235:
language being endangered. Only 41%
- Page 236 and 237:
their promotion online. The “E-bo
- Page 238 and 239:
Institutions of primary, secondary
- Page 240 and 241:
Of course, we could not cover every
- Page 242 and 243:
These numbers, however, could be co
- Page 244 and 245:
2. the Repertory Catalogue of books
- Page 246 and 247:
• the Repertory Catalogue of book
- Page 248 and 249:
Indigenous worldviews, mythologies
- Page 250 and 251:
In 2010, a first project - organize
- Page 252 and 253:
Katsuko T. NAKAHIRA Assistant Profe
- Page 254 and 255:
We did the research of exchange stu
- Page 256 and 257:
Figure 3. PBL environment system ar
- Page 258 and 259:
Figure 4. The relation of elapsed t
- Page 260 and 261:
Discussion and Summary Through thes
- Page 262 and 263:
Anatoly ZHOZHIKOV Director, New Inf
- Page 264 and 265:
To make it happen, a number of wide
- Page 266 and 267:
Liudmila ZAIKOVA Director, Centre t
- Page 268 and 269:
Interregional Library Cooperation C
- Page 270 and 271:
Sargylana IGNATYEVA Rector, Arctic
- Page 272 and 273:
education, systematizing research i
- Page 274 and 275:
From a genetic point of view Romani
- Page 276 and 277:
the extension of the centre’s nam
- Page 278 and 279:
• The web presentation of the Cou
- Page 280 and 281:
Romani-dominated chats elements of
- Page 282 and 283:
3. Conclusion This limited but to s
- Page 284 and 285:
The political and economic laws tha
- Page 286 and 287:
Affairs, the National Academy of Sc
- Page 288 and 289:
national minorities the right of eq
- Page 290 and 291:
Preschool education marks the most
- Page 292 and 293:
to service a limited number of area
- Page 294 and 295:
Another example of mutually benefic
- Page 296 and 297:
• Chukchi Peninsula Eskimo societ
- Page 298 and 299:
161). Sea hunting off Uelen is cons
- Page 300 and 301:
The widows of the Gemavye brothers,
- Page 302 and 303:
Importantly, these statistics do no
- Page 304 and 305:
Expanding the Outreach of Yukaghir
- Page 306 and 307:
(Russian Federation), the developme
- Page 308 and 309:
“cultural diversity as a source o
- Page 310 and 311:
i. to continue searching for fair a