

eur op eanexhibitionofcreati vityandinnovation - Europe Direct Iasi
eur op eanexhibitionofcreati vityandinnovation - Europe Direct Iasi
eur op eanexhibitionofcreati vityandinnovation - Europe Direct Iasi

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
EUROINVENT 2013<br />
32.3.<br />
Speech segmentation method based on predictive n<strong>eur</strong>al<br />
Title EN<br />
networks - SROL_SegmRN<br />
Authors Zbancioc Marius, Feraru Monica<br />
Institute of Computer Science, Romanian Academy, <strong>Iasi</strong><br />
Institution<br />
Brach<br />
Patent no. ORDA Registration no. 3255/08.04.2013<br />
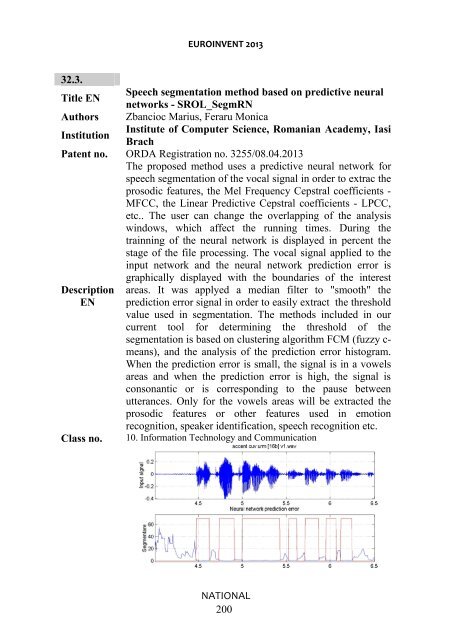
The pr<strong>op</strong>osed method uses a predictive n<strong>eur</strong>al network for<br />
speech segmentation of the vocal signal in order to extrac the<br />
prosodic features, the Mel Frequency Cepstral coefficients -<br />
MFCC, the Linear Predictive Cepstral coefficients - LPCC,<br />
etc.. The user can change the overlapping of the analysis<br />
windows, which affect the running times. During the<br />
trainning of the n<strong>eur</strong>al network is displayed in percent the<br />
stage of the file processing. The vocal signal applied to the<br />
input network and the n<strong>eur</strong>al network prediction error is<br />
graphically displayed with the boundaries of the interest<br />
Description areas. It was applyed a median filter to "smooth" the<br />
EN prediction error signal in order to easily extract the threshold<br />
value used in segmentation. The methods included in our<br />
current tool for determining the threshold of the<br />
segmentation is based on clustering algorithm FCM (fuzzy c-<br />
means), and the analysis of the prediction error histogram.<br />
When the prediction error is small, the signal is in a vowels<br />
areas and when the prediction error is high, the signal is<br />
consonantic or is corresponding to the pause between<br />
utterances. Only for the vowels areas will be extracted the<br />
prosodic features or other features used in emotion<br />
recognition, speaker identification, speech recognition etc.<br />
Class no. 10. Information Technology and Communication<br />
NATIONAL<br />
200













