RESEARCH METHOD COHEN ok
RESEARCH METHOD COHEN ok RESEARCH METHOD COHEN ok
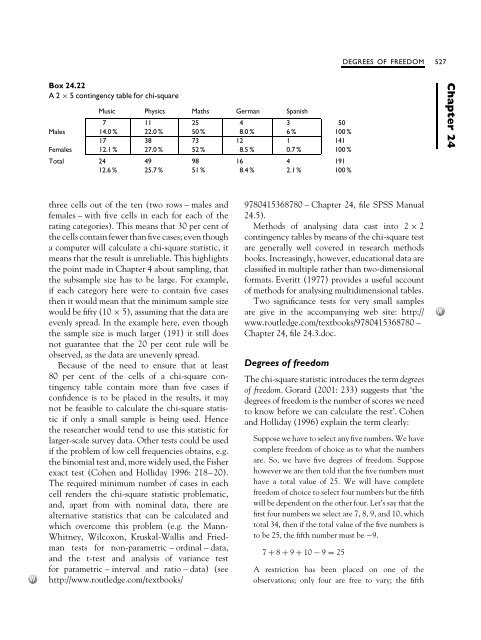
DEGREES OF FREEDOM 527 Box 24.22 A2× 5contingencytableforchi-square Music Physics Maths German Spanish 7 11 25 4 3 50 Males 14.0 % 22.0 % 50 % 8.0 % 6% 100 % 17 38 73 12 1 141 Females 12.1 % 27.0 % 52 % 8.5 % 0.7 % 100 % Total 24 49 98 16 4 191 12.6 % 25.7 % 51 % 8.4 % 2.1 % 100 % Chapter 24 three cells out of the ten (two rows – males and females – with five cells in each for each of the rating categories). This means that 30 per cent of the cells contain fewer than five cases; even though acomputerwillcalculateachi-squarestatistic,it means that the result is unreliable. This highlights the point made in Chapter 4 about sampling, that the subsample size has to be large. For example, if each category here were to contain five cases then it would mean that the minimum sample size would be fifty (10 × 5), assuming that the data are evenly spread. In the example here, even though the sample size is much larger (191) it still does not guarantee that the 20 per cent rule will be observed, as the data are unevenly spread. Because of the need to ensure that at least 80 per cent of the cells of a chi-square contingency table contain more than five cases if confidence is to be placed in the results, it may not be feasible to calculate the chi-square statistic if only a small sample is being used. Hence the researcher would tend to use this statistic for larger-scale survey data. Other tests could be used if the problem of low cell frequencies obtains, e.g. the binomial test and, more widely used, the Fisher exact test (Cohen and Holliday 1996: 218–20). The required minimum number of cases in each cell renders the chi-square statistic problematic, and, apart from with nominal data, there are alternative statistics that can be calculated and which overcome this problem (e.g. the Mann- Whitney, Wilcoxon, Kruskal-Wallis and Friedman tests for non-parametric – ordinal – data, and the t-test and analysis of variance test for parametric – interval and ratio – data) (see http://www.routledge.com/textbooks/ 9780415368780 – Chapter 24, file SPSS Manual 24.5). Methods of analysing data cast into 2 × 2 contingency tables by means of the chi-square test are generally well covered in research methods books. Increasingly, however, educational data are classified in multiple rather than two-dimensional formats. Everitt (1977) provides a useful account of methods for analysing multidimensional tables. Two significance tests for very small samples are give in the accompanying web site: http:// www.routledge.com/textbooks/9780415368780 – Chapter 24, file 24.3.doc. Degrees of freedom The chi-square statistic introduces the term degrees of freedom.Gorard(2001:233)suggeststhat‘the degrees of freedom is the number of scores we need to know before we can calculate the rest’. Cohen and Holliday (1996) explain the term clearly: Suppose we have to select any five numbers. We have complete freedom of choice as to what the numbers are. So, we have five degrees of freedom. Suppose however we are then told that the five numbers must have a total value of 25. We will have complete freedom of choice to select four numbers but the fifth will be dependent on the other four. Let’s say that the first four numbers we select are 7, 8, 9, and 10, which total 34, then if the total value of the five numbers is to be 25, the fifth number must be −9. 7 + 8 + 9 + 10 − 9 = 25 A restriction has been placed on one of the observations; only four are free to vary; the fifth
528 QUANTITATIVE DATA ANALYSIS has lost its freedom. In our example then df = 4, that is N − 1 = 5 − 1 = 4. Suppose now that we are told to select any five numbers, the first two of which have to total 9, and the total value of all five has to be 25. One restriction is apparent when we wish the total of the first two numbers to be 9. Another restriction is apparent in the requirement that all five numbers must total 25. In other words we have lost two degrees of freedom in our example. It leaves us with df = 3, that is, N − 2 = 5 − 2 = 3. (Cohen and Holliday 1996: 113) For a cross-tabulation (a contingency table), degrees of freedom refer to the freedom with which the researcher is able to assign values to the cells, given fixed marginal totals, usually given as (number of rows − 1) + (number of columns − 1). There are many variants of this, and readers will need to consult more detailed texts to explore this issue. We do not dwell on degrees of freedom here, as it is automatically calculated and addressed in subsequent calculations by most statistical software packages such as SPSS. Measuring association Much educational research is concerned with establishing interrelationships among variables. We may wish to know, for example, how delinquency is related to social class background; whether an association exists between the number of years spent in full-time education and subsequent annual income; whether there is a link between personality and achievement. What, for example, is the relationship, if any, between membership of a public library and social class status Is there a relationship between social class background and placement in different strata of the secondary school curriculum Is there a relationship between gender and success or failure in ‘first time’ driving test results There are several simple measures of association readily available to the researcher to help her test these sorts of relationships. We have selected the most widely used ones here and set them out in Box 24.23. Of these, the two most commonly used correlations are the Spearman rank order correlation for ordinal data and the Pearson product-moment correlation for interval and ratio data. At this point it is pertinent to say a few words about some of the terms used in Box 24.23 to describe the nature of variables. Cohen and Holliday (1982; 1996) provide worked examples of the appropriate use and limitations of the correlational techniques outlined in Box 24.23, together with other measures of association such as Kruskal’s gamma, Somer’s d, and Guttman’s lambda (see http://www.routledge.com/textbooks/ 9780415368780 – Chapter 24, file 24.13.ppt and SPSS Manual 24.6). Look at the words used at the top of Box 24.23 to explain the nature of variables in connection with the measure called the Pearson product moment, r. Thevariables,welearn,are‘continuous’andat the ‘interval’ or the ‘ratio’ scale of measurement. Acontinuousvariableisonethat,theoretically at least, can take any value between two points on a scale. Weight, for example, is a continuous variable; so too is time, so also is height. Weight, time and height can take on any number of possible values between nought and infinity, the feasibility of measuring them across such a range being limited only by the variability of suitable measuring instruments. Turning again to Box 24.23, we read in connection with the second measure shown there (rank order or Kendall’s tau) that the two continuous variables are at the ordinal scale of measurement. The variables involved in connection with the phi coefficient measure of association (halfway down Box 24.23) are described as ‘true dichotomies’ and at the nominal scale of measurement. Truly dichotomous variables (such as sex or driving test result) can take only two values (male or female; pass or fail). To conclude our explanation of terminology, readers should note the use of the term ‘discrete variable’ in the description of the third correlation ratio (eta) in Box 24.23. We said earlier that a continuous variable can take on any value between two points on a scale. A discrete variable, however,
- Page 496 and 497: HOW DOES CONTENT ANALYSIS WORK 477
- Page 498 and 499: HOW DOES CONTENT ANALYSIS WORK 479
- Page 500 and 501: HOW DOES CONTENT ANALYSIS WORK 481
- Page 502 and 503: A WORKED EXAMPLE OF CONTENT ANALYSI
- Page 504 and 505: A WORKED EXAMPLE OF CONTENT ANALYSI
- Page 506 and 507: COMPUTER USAGE IN CONTENT ANALYSIS
- Page 508 and 509: COMPUTER USAGE IN CONTENT ANALYSIS
- Page 510 and 511: GROUNDED THEORY 491 data, thereby c
- Page 512 and 513: GROUNDED THEORY 493 fragments are t
- Page 514 and 515: INTERPRETATION IN QUALITATIVE DATA
- Page 516 and 517: INTERPRETATION IN QUALITATIVE DATA
- Page 518 and 519: INTERPRETATION IN QUALITATIVE DATA
- Page 520 and 521: 24 Quantitative data analysis Intro
- Page 522 and 523: DESCRIPTIVE AND INFERENTIAL STATIST
- Page 524 and 525: DEPENDENT AND INDEPENDENT VARIABLES
- Page 526 and 527: EXPLORATORY DATA ANALYSIS: FREQUENC
- Page 528 and 529: EXPLORATORY DATA ANALYSIS: FREQUENC
- Page 530 and 531: EXPLORATORY DATA ANALYSIS: FREQUENC
- Page 532 and 533: EXPLORATORY DATA ANALYSIS: FREQUENC
- Page 534 and 535: STATISTICAL SIGNIFICANCE 515 alongt
- Page 536 and 537: STATISTICAL SIGNIFICANCE 517 hands
- Page 538 and 539: HYPOTHESIS TESTING 519 selection fr
- Page 540 and 541: EFFECT SIZE 521 differential measur
- Page 542 and 543: EFFECT SIZE 523 Box 24.17 The Leven
- Page 544 and 545: THE CHI-SQUARE TEST 525 The Effect
- Page 548 and 549: MEASURING ASSOCIATION 529 Box 24.23
- Page 550 and 551: MEASURING ASSOCIATION 531 found and
- Page 552 and 553: MEASURING ASSOCIATION 533 Box 24.26
- Page 554 and 555: MEASURING ASSOCIATION 535 Many usef
- Page 556 and 557: REGRESSION ANALYSIS 537 we know or
- Page 558 and 559: REGRESSION ANALYSIS 539 Box 24.32 S
- Page 560 and 561: REGRESSION ANALYSIS 541 Box 24.35 S
- Page 562 and 563: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 564 and 565: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 566 and 567: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 568 and 569: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 570 and 571: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 572 and 573: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 574 and 575: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 576 and 577: MEASURES OF DIFFERENCE BETWEEN GROU
- Page 578 and 579: 25 Multidimensional measurement and
- Page 580 and 581: FACTOR ANALYSIS 561 Box 25.1 Rank o
- Page 582 and 583: FACTOR ANALYSIS 563 Box 25.3 The st
- Page 584 and 585: FACTOR ANALYSIS 565 Box 25.5 Ascree
- Page 586 and 587: FACTOR ANALYSIS 567 Box 25.7 The ro
- Page 588 and 589: FACTOR ANALYSIS 569 The school
- Page 590 and 591: FACTOR ANALYSIS: AN EXAMPLE 571 sco
- Page 592 and 593: FACTOR ANALYSIS: AN EXAMPLE 573 Box
- Page 594 and 595: FACTOR ANALYSIS: AN EXAMPLE 575 Box
DEGREES OF FREEDOM 527<br />
Box 24.22<br />
A2× 5contingencytableforchi-square<br />
Music Physics Maths German Spanish<br />
7 11 25 4 3 50<br />
Males 14.0 % 22.0 % 50 % 8.0 % 6% 100 %<br />
17 38 73 12 1 141<br />
Females 12.1 % 27.0 % 52 % 8.5 % 0.7 % 100 %<br />
Total 24 49 98 16 4 191<br />
12.6 % 25.7 % 51 % 8.4 % 2.1 % 100 %<br />
Chapter 24<br />
three cells out of the ten (two rows – males and<br />
females – with five cells in each for each of the<br />
rating categories). This means that 30 per cent of<br />
the cells contain fewer than five cases; even though<br />
acomputerwillcalculateachi-squarestatistic,it<br />
means that the result is unreliable. This highlights<br />
the point made in Chapter 4 about sampling, that<br />
the subsample size has to be large. For example,<br />
if each category here were to contain five cases<br />
then it would mean that the minimum sample size<br />
would be fifty (10 × 5), assuming that the data are<br />
evenly spread. In the example here, even though<br />
the sample size is much larger (191) it still does<br />
not guarantee that the 20 per cent rule will be<br />
observed, as the data are unevenly spread.<br />
Because of the need to ensure that at least<br />
80 per cent of the cells of a chi-square contingency<br />
table contain more than five cases if<br />
confidence is to be placed in the results, it may<br />
not be feasible to calculate the chi-square statistic<br />
if only a small sample is being used. Hence<br />
the researcher would tend to use this statistic for<br />
larger-scale survey data. Other tests could be used<br />
if the problem of low cell frequencies obtains, e.g.<br />
the binomial test and, more widely used, the Fisher<br />
exact test (Cohen and Holliday 1996: 218–20).<br />
The required minimum number of cases in each<br />
cell renders the chi-square statistic problematic,<br />
and, apart from with nominal data, there are<br />
alternative statistics that can be calculated and<br />
which overcome this problem (e.g. the Mann-<br />
Whitney, Wilcoxon, Kruskal-Wallis and Friedman<br />
tests for non-parametric – ordinal – data,<br />
and the t-test and analysis of variance test<br />
for parametric – interval and ratio – data) (see<br />
http://www.routledge.com/textbo<strong>ok</strong>s/<br />
9780415368780 – Chapter 24, file SPSS Manual<br />
24.5).<br />
Methods of analysing data cast into 2 × 2<br />
contingency tables by means of the chi-square test<br />
are generally well covered in research methods<br />
bo<strong>ok</strong>s. Increasingly, however, educational data are<br />
classified in multiple rather than two-dimensional<br />
formats. Everitt (1977) provides a useful account<br />
of methods for analysing multidimensional tables.<br />
Two significance tests for very small samples<br />
are give in the accompanying web site: http://<br />
www.routledge.com/textbo<strong>ok</strong>s/9780415368780 –<br />
Chapter 24, file 24.3.doc.<br />
Degrees of freedom<br />
The chi-square statistic introduces the term degrees<br />
of freedom.Gorard(2001:233)suggeststhat‘the<br />
degrees of freedom is the number of scores we need<br />
to know before we can calculate the rest’. Cohen<br />
and Holliday (1996) explain the term clearly:<br />
Suppose we have to select any five numbers. We have<br />
complete freedom of choice as to what the numbers<br />
are. So, we have five degrees of freedom. Suppose<br />
however we are then told that the five numbers must<br />
have a total value of 25. We will have complete<br />
freedom of choice to select four numbers but the fifth<br />
will be dependent on the other four. Let’s say that the<br />
first four numbers we select are 7, 8, 9, and 10, which<br />
total 34, then if the total value of the five numbers is<br />
to be 25, the fifth number must be −9.<br />
7 + 8 + 9 + 10 − 9 = 25<br />
A restriction has been placed on one of the<br />
observations; only four are free to vary; the fifth


