- Page 1 and 2:
Springer Texts in Statistics Gareth
- Page 4 and 5:
Gareth James • Daniela Witten •
- Page 6:
To our parents: Alison and Michael
- Page 9 and 10:
viii Preface disciplines who wish t
- Page 11 and 12:
x Contents 3 Linear Regression 59 3
- Page 13 and 14:
xii Contents 6.6 Lab 2: Ridge Regre
- Page 15 and 16:
xiv Contents 10.5 Lab 2: Clustering
- Page 17 and 18:
2 1. Introduction Wage 50 100 200 3
- Page 19 and 20:
4 1. Introduction Predicted Probabi
- Page 21 and 22:
6 1. Introduction of least squares,
- Page 23 and 24:
8 1. Introduction in order to contr
- Page 25 and 26:
10 1. Introduction In general, we w
- Page 27 and 28:
12 1. Introduction of A and B is de
- Page 29 and 30:
14 1. Introduction Name Auto Boston
- Page 31 and 32:
16 2. Statistical Learning Sales 5
- Page 33 and 34:
18 2. Statistical Learning Income Y
- Page 35 and 36:
20 2. Statistical Learning In this
- Page 37 and 38:
22 2. Statistical Learning Income Y
- Page 39 and 40:
24 2. Statistical Learning Income Y
- Page 41 and 42:
26 2. Statistical Learning additive
- Page 43 and 44:
28 2. Statistical Learning tistical
- Page 45 and 46:
30 2. Statistical Learning where ˆ
- Page 47 and 48:
32 2. Statistical Learning We now m
- Page 49 and 50:
34 2. Statistical Learning Y −10
- Page 51 and 52:
36 2. Statistical Learning 0.0 0.5
- Page 53 and 54:
38 2. Statistical Learning o o o o
- Page 55 and 56:
40 2. Statistical Learning o o o o
- Page 57 and 58:
42 2. Statistical Learning Error Ra
- Page 59 and 60:
44 2. Statistical Learning The matr
- Page 61 and 62:
46 2. Statistical Learning We will
- Page 63 and 64:
48 2. Statistical Learning [3,] 3 7
- Page 65 and 66:
50 2. Statistical Learning > plot(c
- Page 67 and 68:
52 2. Statistical Learning 2.4 Exer
- Page 69 and 70:
54 2. Statistical Learning (b) What
- Page 71 and 72:
56 2. Statistical Learning 9. This
- Page 74 and 75:
3 Linear Regression This chapter is
- Page 76 and 77:
3.1 Simple Linear Regression 3.1 Si
- Page 78 and 79:
3.1 Simple Linear Regression 63 3 2
- Page 80 and 81:
3.1 Simple Linear Regression 65 con
- Page 82 and 83:
3.1 Simple Linear Regression 67 In
- Page 84 and 85:
Quantity Value Residual standard er
- Page 86 and 87:
3.2 Multiple Linear Regression 71 a
- Page 88 and 89:
3.2 Multiple Linear Regression 73 Y
- Page 90 and 91:
3.2 Multiple Linear Regression 75 T
- Page 92 and 93:
3.2 Multiple Linear Regression 77 w
- Page 94 and 95:
3.2 Multiple Linear Regression 79 i
- Page 96 and 97:
3.2 Multiple Linear Regression 81 S
- Page 98 and 99:
3.3 Other Considerations in the Reg
- Page 100 and 101:
x i = 3.3 Other Considerations in t
- Page 102 and 103:
3.3 Other Considerations in the Reg
- Page 104 and 105:
3.3 Other Considerations in the Reg
- Page 106 and 107:
3.3 Other Considerations in the Reg
- Page 108 and 109:
3.3 Other Considerations in the Reg
- Page 110 and 111:
3.3 Other Considerations in the Reg
- Page 112 and 113:
3.3 Other Considerations in the Reg
- Page 114 and 115:
3.3 Other Considerations in the Reg
- Page 116 and 117:
3.3 Other Considerations in the Reg
- Page 118 and 119:
3.4 The Marketing Plan 103 units wh
- Page 120 and 121:
y x 2 y x 2 3.5 Comparison of Linea
- Page 122 and 123:
3.5 Comparison of Linear Regression
- Page 124 and 125:
3.6 Lab: Linear Regression 109 p=1
- Page 126 and 127:
3.6 Lab: Linear Regression 111 Coef
- Page 128 and 129:
3.6 Lab: Linear Regression 113 > pl
- Page 130 and 131:
3.6 Lab: Linear Regression 115 > lm
- Page 132 and 133:
3.6 Lab: Linear Regression 117 > lm
- Page 134 and 135:
3.6 Lab: Linear Regression 119 Shel
- Page 136 and 137:
3.7 Exercises 121 (b) Answer (a) us
- Page 138 and 139:
3.7 Exercises 123 10. This question
- Page 140 and 141:
3.7 Exercises 125 (d) Create a scat
- Page 142 and 143:
4 Classification The linear regress
- Page 144 and 145:
4.2 Why Not Linear Regression? 129
- Page 146 and 147:
4.3 Logistic Regression 131 0 500 1
- Page 148 and 149:
4.3 Logistic Regression 133 β 1 do
- Page 150 and 151:
4.3 Logistic Regression 135 Coeffic
- Page 152 and 153:
4.3 Logistic Regression 137 Default
- Page 154 and 155:
4.4 Linear Discriminant Analysis 13
- Page 156 and 157:
4.4 Linear Discriminant Analysis 14
- Page 158 and 159:
4.4 Linear Discriminant Analysis 14
- Page 160 and 161:
4.4 Linear Discriminant Analysis 14
- Page 162 and 163:
4.4 Linear Discriminant Analysis 14
- Page 164 and 165:
4.4 Linear Discriminant Analysis 14
- Page 166 and 167:
4.5 A Comparison of Classification
- Page 168 and 169:
4.5 A Comparison of Classification
- Page 170 and 171:
4.6 Lab: Logistic Regression, LDA,
- Page 172 and 173:
4.6 Lab: Logistic Regression, LDA,
- Page 174 and 175:
4.6 Lab: Logistic Regression, LDA,
- Page 176 and 177:
4.6 Lab: Logistic Regression, LDA,
- Page 178 and 179:
4.6 Lab: Logistic Regression, LDA,
- Page 180 and 181:
4.6 Lab: Logistic Regression, LDA,
- Page 182 and 183:
4.6 Lab: Logistic Regression, LDA,
- Page 184 and 185:
4.7 Exercises 169 we will use obser
- Page 186 and 187:
Applied 4.7 Exercises 171 10. This
- Page 188:
4.7 Exercises 173 return(result) Th
- Page 191 and 192:
176 5. Resampling Methods 5.1 Cross
- Page 193 and 194:
178 5. Resampling Methods Mean Squa
- Page 195 and 196:
180 5. Resampling Methods LOOCV 10
- Page 197 and 198:
182 5. Resampling Methods Mean Squa
- Page 199 and 200:
184 5. Resampling Methods has highe
- Page 201 and 202:
186 5. Resampling Methods Error Rat
- Page 203 and 204:
188 5. Resampling Methods Y −2
- Page 205 and 206:
190 5. Resampling Methods Obs X Y Z
- Page 207 and 208:
192 5. Resampling Methods > mean((m
- Page 209 and 210:
194 5. Resampling Methods first is
- Page 211 and 212:
196 5. Resampling Methods Next, we
- Page 213 and 214:
198 5. Resampling Methods (f) When
- Page 215 and 216:
200 5. Resampling Methods predict.g
- Page 218 and 219:
6 Linear Model Selection and Regula
- Page 220 and 221:
6.1 Subset Selection 205 6.1 Subset
- Page 222 and 223:
6.1 Subset Selection 207 p = 20, th
- Page 224 and 225:
6.1 Subset Selection 209 #Variables
- Page 226 and 227:
6.1 Subset Selection 211 C p 10000
- Page 228 and 229:
6.1 Subset Selection 213 will lead
- Page 230 and 231:
6.2 Shrinkage Methods 215 obvious w
- Page 232 and 233:
6.2 Shrinkage Methods 217 regressio
- Page 234 and 235:
6.2 Shrinkage Methods 219 discussed
- Page 236 and 237:
6.2 Shrinkage Methods 221 respectiv
- Page 238 and 239:
6.2 Shrinkage Methods 223 Mean Squa
- Page 240 and 241:
6.2 Shrinkage Methods 225 To simpli
- Page 242 and 243:
6.2 Shrinkage Methods 227 (β j ) 0
- Page 244 and 245:
6.3 Dimension Reduction Methods 229
- Page 246 and 247:
6.3 Dimension Reduction Methods 231
- Page 248 and 249:
6.3 Dimension Reduction Methods 233
- Page 250 and 251:
6.3 Dimension Reduction Methods 235
- Page 252 and 253:
6.3 Dimension Reduction Methods 237
- Page 254 and 255:
6.4 Considerations in High Dimensio
- Page 256 and 257:
6.4 Considerations in High Dimensio
- Page 258 and 259:
6.4 Considerations in High Dimensio
- Page 260 and 261:
6.5 Lab 1: Subset Selection Methods
- Page 262 and 263:
6.5 Lab 1: Subset Selection Methods
- Page 264 and 265:
6.5 Lab 1: Subset Selection Methods
- Page 266 and 267:
6.6 Lab 2: Ridge Regression and the
- Page 268 and 269:
6.6 Lab 2: Ridge Regression and the
- Page 270 and 271:
6.6 Lab 2: Ridge Regression and the
- Page 272 and 273:
6.7 Lab 3: PCR and PLS Regression 2
- Page 274 and 275:
6.8 Exercises 259 final seven-compo
- Page 276 and 277:
6.8 Exercises 261 (a) As we increas
- Page 278 and 279:
6.8 Exercises 263 (d) Repeat (c), u
- Page 280 and 281:
7 Moving Beyond Linearity So far in
- Page 282 and 283:
|| 7.1 Polynomial Regression 267 De
- Page 284 and 285:
|| 7.2 Step Functions 269 Piecewise
- Page 286 and 287:
7.4 Regression Splines 271 7.4 Regr
- Page 288 and 289:
7.4 Regression Splines 273 plot is
- Page 290 and 291:
7.4 Regression Splines 275 Natural
- Page 292 and 293:
7.5 Smoothing Splines 277 Wage 50 1
- Page 294 and 295:
7.5 Smoothing Splines 279 to the nu
- Page 296 and 297:
7.6 Local Regression 281 Local Regr
- Page 298 and 299:
7.7 Generalized Additive Models 283
- Page 300 and 301:
7.7 Generalized Additive Models 285
- Page 302 and 303:
7.8 Lab: Non-linear Modeling 287 25
- Page 304 and 305:
7.8 Lab: Non-linear Modeling 289 po
- Page 306 and 307:
7.8 Lab: Non-linear Modeling 291 po
- Page 308 and 309:
7.8.2 Splines 7.8 Lab: Non-linear M
- Page 310 and 311:
7.8 Lab: Non-linear Modeling 295 In
- Page 312 and 313:
7.9 Exercises 297 It is easy to see
- Page 314 and 315:
7.9 Exercises 299 5. Consider two c
- Page 316:
7.9 Exercises 301 (a) Generate a re
- Page 319 and 320:
304 8. Tree-Based Methods Years < 4
- Page 321 and 322:
306 8. Tree-Based Methods have been
- Page 323 and 324:
308 8. Tree-Based Methods R5 R2 t4
- Page 325 and 326:
310 8. Tree-Based Methods Years < 4
- Page 327 and 328:
312 8. Tree-Based Methods E =1− m
- Page 329 and 330:
314 8. Tree-Based Methods Figure 8.
- Page 331 and 332:
316 8. Tree-Based Methods ▼ Unfor
- Page 333 and 334:
318 8. Tree-Based Methods Error 0.1
- Page 335 and 336:
320 8. Tree-Based Methods 8.2.2 Ran
- Page 337 and 338:
322 8. Tree-Based Methods of the ot
- Page 339 and 340:
324 8. Tree-Based Methods stumps wi
- Page 341 and 342:
326 8. Tree-Based Methods > tree.ca
- Page 343 and 344:
328 8. Tree-Based Methods Residual
- Page 345 and 346:
330 8. Tree-Based Methods The test
- Page 347 and 348:
332 8. Tree-Based Methods 8.4 Exerc
- Page 349 and 350:
334 8. Tree-Based Methods (e) Use r
- Page 352 and 353:
9 Support Vector Machines In this c
- Page 354 and 355:
9.1 Maximal Margin Classifier 339 X
- Page 356 and 357:
9.1 Maximal Margin Classifier 341 h
- Page 358 and 359:
9.1 Maximal Margin Classifier 343 m
- Page 360 and 361:
9.2 Support Vector Classifiers 345
- Page 362 and 363: 9.2 Support Vector Classifiers 347
- Page 364 and 365: 9.3 Support Vector Machines 349 X2
- Page 366 and 367: 9.3 Support Vector Machines 351 in
- Page 368 and 369: 9.3 Support Vector Machines 353 X2
- Page 370 and 371: 9.4 SVMs with More than Two Classes
- Page 372 and 373: 9.5 Relationship to Logistic Regres
- Page 374 and 375: 9.6 Lab: Support Vector Machines 35
- Page 376 and 377: 9.6 Lab: Support Vector Machines 36
- Page 378 and 379: 9.6 Lab: Support Vector Machines 36
- Page 380 and 381: 9.6.3 ROC Curves 9.6 Lab: Support V
- Page 382 and 383: 9.6 Lab: Support Vector Machines 36
- Page 384 and 385: Obs. X 1 X 2 Y 1 3 4 Red 2 2 2 Red
- Page 386 and 387: 9.7 Exercises 371 (b) Compute the c
- Page 388 and 389: 10 Unsupervised Learning Most of th
- Page 390 and 391: 10.2 Principal Components Analysis
- Page 392 and 393: 10.2 Principal Components Analysis
- Page 394 and 395: 10.2 Principal Components Analysis
- Page 396 and 397: 10.2 Principal Components Analysis
- Page 398 and 399: 10.2 Principal Components Analysis
- Page 400 and 401: 10.2.4 Other Uses for Principal Com
- Page 402 and 403: 10.3 Clustering Methods 387 K=2 K=3
- Page 404 and 405: 10.3 Clustering Methods 389 Data St
- Page 406 and 407: 10.3 Clustering Methods 391 X2 −2
- Page 408 and 409: 10.3 Clustering Methods 393 0.0 0.5
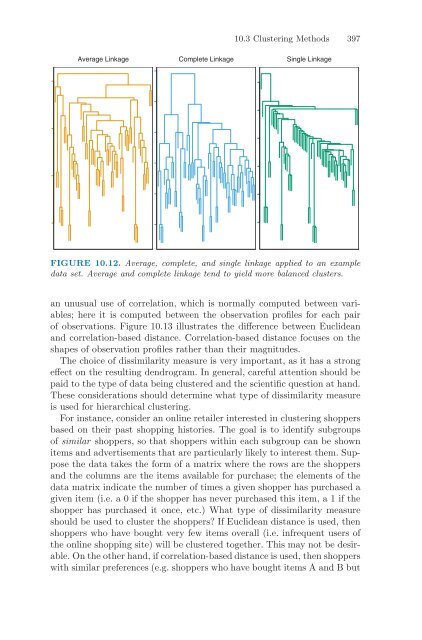
- Page 410 and 411: Algorithm 10.2 Hierarchical Cluster
- Page 414 and 415: 10.3 Clustering Methods 399 0 2 4 6
- Page 416 and 417: 10.4 Lab 1: Principal Components An
- Page 418 and 419: 10.4 Lab 1: Principal Components An
- Page 420 and 421: 10.5 Lab 2: Clustering 405 Cluster
- Page 422 and 423: 10.6 Lab 3: NCI60 Data Example 407
- Page 424 and 425: 10.6 Lab 3: NCI60 Data Example 409
- Page 426 and 427: 10.6 Lab 3: NCI60 Data Example 411
- Page 428 and 429: 10.7 Exercises 413 differ: for inst
- Page 430 and 431: 10.7 Exercises 415 (b) At a certain
- Page 432 and 433: 10.7 Exercises 417 10. In this prob
- Page 434 and 435: Index C p , 78, 205, 206, 210-213 R
- Page 436 and 437: Index 421 Wage, 1, 2, 9, 10, 14, 26
- Page 438 and 439: Index 423 noise, 22, 228 non-linear
- Page 440 and 441: Index 425 read.table(), 48, 49 regs