PDF 4:1
PDF 4:1
PDF 4:1

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
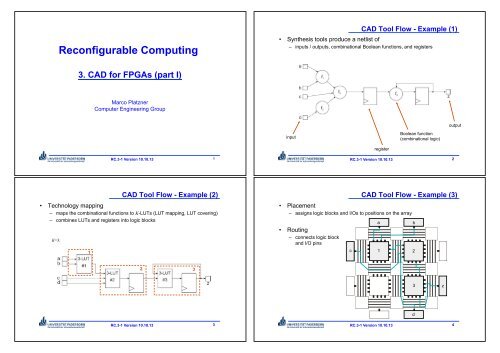
Reconfigurable Computing<br />
CAD Tool Flow - Example (1)<br />
• Synthesis tools produce a netlist of<br />
– inputs / outputs, combinational Boolean functions, and registers<br />
3. CAD for FPGAs (part I)<br />
Marco Platzner<br />
Computer Engineering Group<br />
output<br />
input<br />
Boolean function<br />
(combinational logic)<br />
register<br />
RC.3-1 Version 10.10.13 1<br />
RC.3-1 Version 10.10.13 2<br />
CAD Tool Flow - Example (2)<br />
• Technology mapping<br />
– maps the combinational functions to K-LUTs (LUT mapping, LUT covering)<br />
– combines LUTs and registers into logic blocks<br />
K=3:<br />
1<br />
CAD Tool Flow - Example (3)<br />
• Placement<br />
– assigns logic blocks and I/Os to positions on the array<br />
• Routing<br />
– connects logic block<br />
and I/O pins<br />
c<br />
a<br />
b<br />
1 2<br />
2 3<br />
3<br />
z<br />
d<br />
RC.3-1 Version 10.10.13 3<br />
RC.3-1 Version 10.10.13 4
design entry<br />
optimization<br />
& synthesis<br />
technology<br />
mapping<br />
placement<br />
CAD for FPGAs - Contents<br />
– Technology mapping<br />
! network decomposition<br />
! LUT mapping<br />
! sequential mapping<br />
! logic block packing (VPack)<br />
– Placement<br />
! simulated annealing (VPR)<br />
Optimization Problems<br />
• Objectives<br />
– area: minimize the required chip area<br />
– delay: minimize the delay on the critical path<br />
– power: minimize the dynamic power dissipation<br />
– routability: facilitate successful routing<br />
! these goals are often conflicting, eg. area and delay<br />
routing<br />
simulation<br />
generation<br />
of bitfile<br />
– Routing<br />
! Pathfinder (VPR)<br />
– Timing analysis & delay modeling<br />
• Cost models (estimates)<br />
– area models: number of LUTs (logic blocks), routing area<br />
– delay models: logic block delay, routing delay<br />
– power models: the power can be estimated by the output load<br />
capacitances and transition frequencies<br />
RC.3-1 Version 10.10.13 5<br />
RC.3-1 Version 10.10.13 6<br />
optimization<br />
& synthesis<br />
technology<br />
mapping<br />
node decomposition<br />
LUT mapping<br />
Technology Mapping<br />
sometimes called<br />
FPGA logic synthesis<br />
Boolean Network – Definitions (1)<br />
• A Boolean network is a directed acyclic graph (DAG) G=(V,E), where<br />
the nodes v !V represent logic functions, primary inputs (PIs), or<br />
primary outputs (POs). A directed edge (v,w) ! E denotes that the<br />
output of v is an input of w.<br />
1 2 3 4 5 6 7 8<br />
placement<br />
logic block packing<br />
p q t<br />
o<br />
routing<br />
s<br />
w<br />
x<br />
– node decomposition<br />
! split combinational functions into nodes with at most K inputs<br />
! is done during synthesis or during technology mapping<br />
r u y<br />
v<br />
z<br />
9 10 11<br />
RC.3-1 Version 10.10.13 7<br />
RC.3-1 Version 10.10.13 8
Boolean Network – Definitions (2)<br />
• Given a directed edge (v,w) ! E, v is a fanin of w, and w is a fanout of v.<br />
A PI has no fanin; a PO has no fanout. If there is a path from a node r<br />
to a node s, r is a predecessor of s, and s is a successor of r.<br />
• The level of a node v is the maximum number of edges on any path<br />
from a PI to v. The depth of a network is the largest level of any node.<br />
• The set of fanins of node v is called input(v). A node is K-feasible, if<br />
|input(v)| ! K. If every node in a network is K-feasible, the network is<br />
K-bounded.<br />
Boolean Network – Definitions (3)<br />
• The set of fanouts of a node v is called output(v). A node v is fanoutfree,<br />
if |output(v)| ! 1.<br />
• The network is called a<br />
– tree if every node (including PIs) is fanout-free and there is only one PO<br />
– leaf-DAG if every non-PI node is fanout-free<br />
– general network otherwise<br />
RC.3-1 Version 10.10.13 9<br />
RC.3-1 Version 10.10.13 10<br />
Boolean Network – Definitions (4)<br />
• A cone of node v is denoted as C v and consists of v and some non-PI<br />
predecessors such that for any node w in C v there exists a path from w<br />
to v that is entirely in C v . The node v is the root of C v . The maximum<br />
cone of v is denoted as MC v and consists of all non-PI predecessors<br />
of v.<br />
N v<br />
Boolean Network - Example<br />
1 2 3 4 5 6 7 8<br />
p q t o<br />
• The fanin network of v is denoted as N v and extends MC v by including<br />
all PI predecessors of v.<br />
MC v<br />
s<br />
w<br />
x<br />
• A fanout-free cone (FFC) is a cone in which the fanouts of every node<br />
(except the root node) are in the cone. For each node v, there exists a<br />
unique maximum fanout-free cone MFFC v .<br />
• For each node v, there exists also a maximum tree MT v of non-PI nodes.<br />
MT " MFFC " MC ! N<br />
v<br />
v<br />
v<br />
v<br />
MFFC v<br />
MT v<br />
r u y<br />
v<br />
z<br />
9 10 11<br />
RC.3-1 Version 10.10.13 11<br />
RC.3-1 Version 10.10.13 12
Network Decomposition<br />
• Some nodes in the network might not be K-feasible<br />
! decompose such nodes into smaller ones that are K-feasible<br />
– a decomposed (ie. a K-bounded) network is already a trivial LUT mapping<br />
• Classification of decomposition methods<br />
– structural decomposition methods<br />
! for node functions that are basic gates<br />
! some methods: balanced tree decomposition, minimum tree decomposition,<br />
Huffman tree decomposition, bin-packing decomposition<br />
– symbolic decomposition methods<br />
! for more complex node functions<br />
! some methods: AND/OR decomposition, algebraic division based extraction,<br />
OBDD based extraction<br />
– Boolean decomposition methods<br />
! for more complex node functions<br />
! some methods: cofactoring, function-based decomposition<br />
RC.3-1 Version 10.10.13 13<br />
Structural Decomposition<br />
• For simple node functions (AND, OR, XOR, !.)<br />
– associative and commutative properties allow arbitrary groupings<br />
of the inputs<br />
a + (b + c) = (a + b) + c a + b = b + a<br />
– structural decomposition is used in classical logic synthesis systems<br />
that target simple gates (eg. 2-NAND)<br />
– early FPGA logic synthesis systems used the same approach<br />
1. decompose the network into simple gates<br />
2. map the simple gate network to LUTs<br />
• Problem statement: Decompose a simple gate node v,<br />
input(v) = {w 1 , …w m }, (m > K), into a<br />
tree of nodes of input size K or less.<br />
RC.3-1 Version 10.10.13 14<br />
Balanced Tree Decomposition<br />
• Algorithm<br />
1. divide input(v) into K groups of (nearly) equal size (balancing constraint)<br />
2. introduce K new gates, each combining the inputs from one group;<br />
these K new gates form the input of the root gate v that replaces v<br />
3. apply recursively for all nodes with input size larger than K<br />
• Properties<br />
– gives minimum-depth decomposition of v<br />
– the size (number of gates) might not be minimum (for K>2)<br />
Minimum Tree Decomposition<br />
• Replaces the balancing constraint by a FIFO (first-in, first-out) list<br />
• Algorithm<br />
1. construct a list L of nodes in input(v) in FIFO order<br />
2. iterate: a. remove the first K nodes from L and create a new node with these<br />
nodes as inputs<br />
b. put the new node back to L in FIFO order<br />
c. stop when |L| ! K; |L| is the number of entries in the FIFO<br />
9-OR, K=2<br />
5 4<br />
3<br />
RC.3-1 Version 10.10.13 15<br />
• Properties<br />
– gives minimum-depth and minimum-size decomposition of v<br />
$ m % 1"<br />
(for |input(v)| = m, the minimum number of gates is D = )<br />
# K % 1!<br />
– runtime complexity O(m)<br />
RC.3-1 Version 10.10.13 16
Huffman Tree Decomposition<br />
• Balanced tree decomposition<br />
– does not give the minimum number of levels for the overall network when<br />
the inputs of v have different levels<br />
! the Huffman tree decomposition uses a different sorting rule for the list L<br />
• Algorithm<br />
1. construct a list L of nodes in input(v) sorted according to non-decreasing<br />
levels<br />
2. iterate a. remove the first K nodes from L and create a new node with these<br />
nodes as inputs<br />
b. put the new node back to L (the list must remain sorted)<br />
c. stop when |L| ! K<br />
• Properties<br />
– when done for all not K-feasible nodes of the network in topological order<br />
(from the PIs to the POs), the decomposed network is delay-optimal<br />
– runtime complexity O(m.log(m))<br />
RC.3-1 Version 10.10.13 17<br />
Symbolic Decomposition<br />
• For more complex node functions<br />
– the node function is specified in some symbolic representation, eg. as<br />
Boolean expression, sum-of-products (SOP), ordered binary decision<br />
diagram (OBDD), !<br />
– symbolic decomposition techniques try to extract K-feasible subfunctions<br />
from these representations<br />
• Some methods<br />
– AND/OR decomposition<br />
! when the node function is given as SOP, split it into a disjunction of conjunctions<br />
! if the resulting subfunctions are not K-feasible, apply structural decomposition<br />
– algebraic division based extraction<br />
! when the node function is given as Boolean expression, view it as an algebraic<br />
expression and apply transformations of polynomial algebra (instead of Boolean<br />
algebra)<br />
! although weaker, the polynomial algebra allows to perform polynomial division to<br />
extract kernels and co-kernels as subfunctions<br />
RC.3-1 Version 10.10.13 18<br />
Boolean Decomposition<br />
• For more complex node functions<br />
– symbolic decomposition works on the symbolic representation of the node<br />
function, but the specific representation might not be the best one<br />
– Boolean decomposition works on the Boolean function itself, which is<br />
independent of the representation<br />
• Some methods<br />
– co-factoring<br />
! uses Shannon expansion to extract cofactors; a cofactor has one fewer variable<br />
! limited to cofactors as subfunctions f x!<br />
f + x f<br />
a b c d<br />
z<br />
f z<br />
= abc( de + de)<br />
= d(<br />
abce)<br />
+ d(<br />
abce)<br />
e<br />
=<br />
x= 1<br />
!<br />
x=0<br />
a b<br />
z<br />
c e<br />
z<br />
a b<br />
z<br />
c e<br />
RC.3-1 Version 10.10.13 19<br />
d<br />
• Some methods (contd)<br />
– functional decomposition<br />
! exploits arbitrary subfunctions<br />
i,<br />
j,<br />
m # r<br />
Boolean Decomposition<br />
( y ( x … x ),…<br />
y ( x … x ), x ,…<br />
x )<br />
f ( x1,<br />
… xr<br />
) = g<br />
1 1 i m 1<br />
i " j ! 1 > 0<br />
! the first j-1 variables of the function are encoded by m new variables<br />
! y 1 …y m are the econding functions, g is the base function<br />
! if i=j-1 the decomposition is disjunctive, x 1 …x i is the bound set and x j …x r the free<br />
set<br />
! there are several methods for partitioning the variables into bound and free sets<br />
and finding encoding and base functions, eg. Ashenhurst decomposition, Roth-<br />
Karp decomposition, !<br />
– functional decomposition techniques are very important for LUT-based logic<br />
synthesis, because LUTs can implement any function that is K-feasible (the<br />
specific structure or symbolic representation is irrelevant)<br />
RC.3-1 Version 10.10.13 20<br />
i<br />
j<br />
r
optimization<br />
& synthesis<br />
technology<br />
mapping<br />
placement<br />
routing<br />
node decomposition<br />
LUT mapping<br />
logic block packing<br />
Technology Mapping<br />
sometimes called<br />
FPGA logic synthesis<br />
• Given is<br />
– a K-bounded tree T r with root node r<br />
Tree Mapping (1)<br />
– a mapping where LUT r implements r, which means that there is also a<br />
mapping for each subtree T w rooted at w ! input(LUT r )<br />
– the number of LUTs in is given by<br />
!<br />
area<br />
M Tw<br />
M Tr<br />
M Tr<br />
( M<br />
T<br />
) = 1+<br />
! area( M )<br />
r<br />
T w<br />
w"<br />
input ( LUTr<br />
)<br />
area( M Tr<br />
)<br />
– LUT mapping<br />
! maps K-bounded Boolean networks into K-LUTs<br />
r<br />
K=3<br />
RC.3-1 Version 10.10.13 21<br />
RC.3-1 Version 10.10.13 22<br />
• The area optimal mapping<br />
area<br />
%<br />
& = + '<br />
LUTr<br />
$ w input (<br />
*<br />
*<br />
( M ) min 1 area( M )<br />
Tr<br />
( LUTr<br />
)<br />
Tw<br />
#<br />
"<br />
!<br />
Tree Mapping (2)<br />
*<br />
M Tr<br />
– can be computed from the area-optimal mappings of the subtrees<br />
Tree Mapping (3)<br />
• How can the best LUT r be found?<br />
– by enumerating all K-feasible cones rooted at r (all possible LUT r )<br />
– by a greedy method TreeMap that has been shown to be optimal<br />
! with input(v) = {w 1 , …w m }, and<br />
the following ordering of LUT indices<br />
{ }<br />
input LUTw ) !!!<br />
input(<br />
LUT w<br />
)<br />
(<br />
1 m<br />
! set LUT<br />
where s is the largest index such that LUT<br />
v<br />
= v " LUTw<br />
v<br />
i<br />
remains K-feasible<br />
i!<br />
s<br />
r<br />
two possible LUT r<br />
K=3<br />
• Algorithm TreeMap<br />
– go through the tree in topological order<br />
1. at each node v, sort the input LUTs in increasing order of input size<br />
2. greedily expand the cone C v to cover as many input LUTs as possible in that order<br />
3. set LUT v =C v<br />
• Properties<br />
– gives the area-optimal mapping for trees<br />
– runtime complexity O(max{K,log(n)·n}); n is the number of nodes in the tree<br />
RC.3-1 Version 10.10.13 23<br />
RC.3-1 Version 10.10.13 24
Tree Mapping (4)<br />
• Remarks<br />
– to find a delay-optimal mapping with TreeMap, sort the LUTs by decreasing<br />
order of depths<br />
– TreeMap is optimal only for trees, general networks must be partitioned into<br />
a set of MT (maximum trees) which are mapped independently<br />
! which does not give an optimal mapping for the overall circuit<br />
MFFC Mapping<br />
• In MFFCs, internal nodes may have multiple fanouts<br />
– LUTs may overlap, ie. a node may be implemented in several LUTs<br />
– a mapping without such overlaps is called a duplication-free mapping<br />
– a mapping with such overlaps is called mapping with logic duplication and<br />
can lead to less delay and less area (!)<br />
– MMFC mapping with logic duplication is as difficult as general network<br />
mapping<br />
– for leaf-DAGs there exists also a delay-optimal version of TreeMap,<br />
but no area-optimal version<br />
K=4<br />
r<br />
RC.3-1 Version 10.10.13 25<br />
RC.3-1 Version 10.10.13 26<br />
General Network Mapping (1)<br />
• General networks<br />
– can be split into MTs or MFFCs that are mapped independently<br />
– however, direct mapping of general networks can produce better results<br />
• Delay minimization<br />
– we only have to look at the levels of the nodes, the number of LUTs is not<br />
important (ie. we can use logic duplication)<br />
! the delay-optimal mapping of a node v depends only on the mapping of<br />
nodes in N v ; the delay of node v is 1 plus the delay of N v -LUT v<br />
– we go through the network in topological order and, at each node v, select<br />
the LUT v that minimizes the delay of N v -LUT v<br />
! there are several algorithms to find the delay-optimal LUT v (eg. dag-map)<br />
General Network Mapping (2)<br />
• Algorithm dag-map<br />
– assign each PI node v of the network a label l(v)=0<br />
– go through the network in topological order, for each node v<br />
! let p be the largest label of the nodes in input(v)<br />
! l(v)=p if the set of nodes w ! N v with label l(w)=p form a K-feasible cone C v ;<br />
otherwise, l(v)=p+1<br />
! LUT v = {w | w ! N v , l(w)=l(v)} (plus duplicated logic, if required)<br />
• Properties<br />
– runtime complexity O(n 2 ) for a network with n nodes<br />
– delay-optimal only if the network is monotonic under LUT mapping<br />
! if a cone C w is not K-feasible, then any larger cone C v containing C w cannot<br />
be K-feasible<br />
! general networks are not always monotonic, they can have reconvergent<br />
fanout paths<br />
RC.3-1 Version 10.10.13 27<br />
RC.3-1 Version 10.10.13 28
General Network Mapping (3)<br />
• Delay minimization<br />
– there is also a delay-optimal algorithm for non-monotonic general<br />
networks: flowmap<br />
– flowmap has a runtime complexity of O(Kmn), with m as the number of<br />
edges and n as the number of nodes of the general network<br />
• Area minimization for general networks<br />
– is a more difficult problem than delay minimization because we have to<br />
consider overlapping sub-networks<br />
– there exist several algorithms<br />
! exact algorithms based on enumeration and Integer Linear Programs (ILP)<br />
! heuristic algorithms that use rules to select the nodes that will be covered<br />
by a LUT<br />
RC.3-1 Version 10.10.13 29<br />
Overview - Decomposition & LUT Mappers<br />
– Chortle family<br />
! Chortle [1990] partitions simple-gate networks into trees, node<br />
decomposition, area-optimal mapping by enumeration<br />
! Chortle-crf [1991] decomposition and mapping by FFD bin-packing,<br />
further heuristic improvements for leaf-DAGs<br />
! Chortle-d [1991] delay minimization for leaf-DAGs<br />
– MIS family<br />
! MIS-pga [1990], symbolic and Boolean decomposition,<br />
MIS-pga (new) [1991] area-minimization for general networks<br />
! MIS-pga (delay) [1991] delay minimization for general networks<br />
– TechMap family<br />
! TechMap [1992], TechMap-L [1992], TechMap-D [1993] for simple-gate<br />
networks<br />
– FlowMap family<br />
! DAG-Map [1992], FlowMap [1992] delay-optimal mapping for general networks<br />
! FlowMap-r [1993], FlowSYN [1993], diverse improvements<br />
FlowMap-d [1993], CutMap [1995]<br />
RC.3-1 Version 10.10.13 30<br />
Sequential Mapping<br />
Retiming - Example<br />
• Technology mapping algorithms usually<br />
1. split a sequential circuit into several combinational circuits<br />
2. map the combinational circuits to LUTs independently<br />
3. assemble LUTs and registers to the final technology-mapped netlist<br />
a<br />
b<br />
d<br />
e<br />
retiming<br />
a<br />
b<br />
d<br />
e<br />
c<br />
c<br />
• Direct sequential mapping techniques<br />
– do not split the sequential circuit into independent combinational<br />
circuits, but work on the overall netlist<br />
– common treatment of combinational functions and registers allows for<br />
! more combinational optimizations (area and delay)<br />
! register optimization (minimize number of registers)<br />
– most important transformation: retiming, ie. shifting registers to different<br />
positions in the netlist without changing the function of the circuit<br />
combinational<br />
LUT mapping<br />
K=4<br />
a<br />
b<br />
d<br />
e<br />
a<br />
b<br />
c<br />
combinational<br />
LUT mapping<br />
K=4<br />
d<br />
e<br />
example:<br />
c<br />
register<br />
optimization<br />
4-LUT<br />
RC.3-1 Version 10.10.13 31<br />
RC.3-1 Version 10.10.13 32
Technology Mapping<br />
Logic Block Packing (1)<br />
optimization<br />
& synthesis<br />
technology<br />
mapping<br />
node decomposition<br />
LUT mapping<br />
sometimes called<br />
FPGA logic synthesis<br />
• Combines LUTs and registers into logic blocks<br />
– simple logic block (basic logic element, BLE) consists of a single LUT<br />
and a register<br />
– cluster-based logic block consists of several BLEs<br />
placement<br />
logic block packing<br />
• Basic logic element (BLE)<br />
– characterized by K<br />
routing<br />
– logic block packing<br />
! combines LUTs and registers into logic blocks and/or clusters of logic blocks<br />
RC.3-1 Version 10.10.13 33<br />
RC.3-1 Version 10.10.13 34<br />
• A cluster is characterized by<br />
– the BLE parameter K<br />
– the number of BLEs in the cluster N<br />
– the number of cluster inputs I, I < K.N<br />
Cluster-based Logic Blocks (1)<br />
• Example: K = 3, N = 3, I = 6<br />
! 9 multiplexors 9:1<br />
Cluster-based Logic Blocks (2)<br />
• Fully-connected clusters<br />
– any cluster input or cluster output can<br />
connect to any BLE input<br />
– the connections are realized with<br />
multiplexors<br />
– full connectivity is expensive but<br />
simplifies the packing problem<br />
– some commercial FPGAs are fully<br />
connected (eg. Altera 8K/10K),<br />
others are nearly fully connected<br />
(eg. Xilinx XC5200)<br />
RC.3-1 Version 10.10.13 35<br />
• Packing goals<br />
– pack connected BLEs (LUTs) into one cluster to minimize the number of<br />
signals to be routed between clusters<br />
– pack the clusters as full as possible to minimize the number of required<br />
clusters<br />
RC.3-1 Version 10.10.13 36
• Logic block packing is a clustering problem<br />
– for logic block packing, greedy heuristics are used<br />
(eg. algorithms VPack, T-VPack)<br />
Logic Block Packing (2)<br />
Algorithm VPack (1)<br />
• VPack – step 1<br />
– pack LUTs and registers to BLEs by following pattern matching rule<br />
• Algorithm VPack<br />
– input: netlist of LUTs and registers<br />
– output: netlist of clusters<br />
– parameters: N, I, K<br />
– runs in two steps:<br />
1. pack LUTs with registers into BLEs<br />
2. pack BLEs into clusters<br />
LUT followed by a register:<br />
pack into one BLE<br />
LUT with fanout followed by a register:<br />
pack LUT and register into two different BLEs<br />
RC.3-1 Version 10.10.13 37<br />
RC.3-1 Version 10.10.13 38<br />
Algorithm VPack (2)<br />
Algorithm VPack (3)<br />
• VPack – step 2<br />
– pack BLEs to clusters; runs in two phases<br />
phase I:<br />
1. start a new cluster with a seed BLE; the seed BLE is the BLE<br />
with the most inputs used<br />
2. greedily pack further BLEs to the cluster using the metric<br />
attraction(C, BLE)<br />
3. if the cluster is full, goto 1 and start a new cluster; if the cluster<br />
is not full, start phase II<br />
phase II: greedily pack further BLEs to the cluster using the metric<br />
" cluster inputs (C, BLE)<br />
UnClusteredBLEs = PatternMatchingToBLEs(netlist);<br />
Clusters = { };<br />
while (UnClusteredBLEs != { }) {<br />
C = GetBLEWithMostUsedInputs(UnClusteredBLEs);<br />
while (|C| < N) {<br />
BestBLE = MaxAttractionLegalBLE(C, UnClusteredBLEs);<br />
if (BestBLE) == { } ) break;<br />
}<br />
UnClusteredBLEs = UnClusteredBLEs \ BestBLE;<br />
C = C U BestBLE;<br />
}<br />
if (|C| < N) {<br />
while (|C| < N) {<br />
BestBLE = MinClusterInputIncreaseBLE(C, UnClusteredBLEs);<br />
}<br />
UnClusteredBLEs = UnClusteredBLEs \ BestBLE;<br />
C = C U BestBLE;<br />
}<br />
if (!ClusterIsLegaI(C))<br />
RestoreToLastLegalState(C, UnClusteredBLEs);<br />
Clusters = Clusters U C<br />
phase I<br />
phase II<br />
RC.3-1 Version 10.10.13 39<br />
RC.3-1 Version 10.10.13 40
Algorithm VPack (4)<br />
• MaxAttractionLegalBLE(C, UnClusteredBLEs)<br />
– attraction(C, BLE) = | nets(BLE) " nets(C) |<br />
nets(BLE) is the set of inputs and outputs of the BLE<br />
nets(C) is the set of inputs and outputs of the BLEs in cluster C<br />
– this metric tends to pack connected BLEs into one cluster<br />
– a BLE is not added to a cluster if the cluster size would be exceeded<br />
(ie. if the number of required inputs becomes larger than I)<br />
• MinClusterInputIncreaseBLE(C, UnClusteredBLEs)<br />
– " cluster inputs (C, BLE) = | fanin(BLE) | - | nets(BLE) " nets(C) |<br />
– the number of cluster inputs is allowed to exceeded I, because subsequent<br />
steps could reduce the number of required inputs<br />
– if the cluster is illegal at the end, the last legal state of phase II is restored<br />
Timing-driven VPack (1)<br />
• Algorithm T-VPack<br />
– VPack tries to pack clusters full; T-VPack additionally tries to minimize the<br />
number of intercluster-connections on the critical path<br />
– the seed and attraction functions of T-VPack depend on the criticality of<br />
BLEs<br />
– T-VPack performs timing analysis with three types of delays<br />
! LogicDelay: delay through a BLE<br />
! IntraClusterDelay: delay between BLEs in a cluster<br />
! InterClusterDelay: delay between different clusters, approximated<br />
by a constant<br />
• Runtime complexity is O(k max Kn)<br />
– k max is the maximum number of terminals on any net<br />
– n is the number of LUTs and registers (BLEs) in the netlist<br />
RC.3-1 Version 10.10.13 41<br />
RC.3-1 Version 10.10.13 42<br />
• Algorithm T-VPack (cont'd)<br />
Timing-driven VPack (2)<br />
• Algorithm T-VPack (contd)<br />
Timing-driven VPack (3)<br />
– the criticality of a connection i is:<br />
slack(<br />
i)<br />
Connection Criticality ( i)<br />
= 1!<br />
MaxSlack<br />
! MaxSlack is the maximum slack of any connection in the circuit<br />
– seed BLE: the BLE with the highest connection criticality for any of its<br />
connections<br />
– attraction function:<br />
nets(<br />
BLE)<br />
! nets(<br />
C)<br />
attraction ( C,<br />
BLE)<br />
= !"<br />
Criticalit y ( C,<br />
BLE)<br />
+ (1 # !)"<br />
MaxNets<br />
! ! is a weighting parameter (" = 0 corresponds to VPack; " = 1 minimizes<br />
the circuit delay)<br />
! MaxNets is the maximum nuber of nets that can connect to a BLE (normalization)<br />
– attracting a BLE to a cluster C: the criticality of the BLE, Criticality(C, BLE),<br />
is defined as the maximum connection criticality of any connection joining<br />
BLE to C; if there is no such connection, the criticality is zero<br />
• Runtime complexity<br />
– depends on how often timing analysis is done<br />
! recompute the delays after each packed BLE: O(n 2 ), where n is the no. of BLEs<br />
! recompute the delays after p packed BLEs: O(n 2 /p)<br />
! compute the delays only once at the beginning: O(k max Kn), the same as for VPack<br />
RC.3-1 Version 10.10.13 43<br />
RC.3-1 Version 10.10.13 44
Selected Literature (1)<br />
• Digital Design<br />
– John P. Hayes. Introduction to Digital Logic Design.<br />
Addison-Wesley, 1993<br />
– John F. Wakerly. Digital Design: Principles and Practices.<br />
Addison-Wesley, 4th. Edition, 2006<br />
– Randy H. Katz, Gaetano Borriello. Contemporary Logic Design.<br />
Addison-Wesley, 2. Edition, 2005<br />
– M. Morris Mano, Charles R. Kime, Logic and Computer Design<br />
Fundamentals. 4th. Edition, Prentice Hall, 2007<br />
• CAD General<br />
– G. De Micheli. Synthesis and Optimization of Digital Circuits.<br />
McGraw-Hill, 1994.<br />
Selected Literature (2)<br />
• CAD for FPGAs<br />
– V. Betz, J. Rose and A. Marquardt. Architecture and CAD for Deep-<br />
Submicron FPGAs. Kluwer Academic Publishers, 1999.<br />
– J. Cong and Y. Ding. Combinational Logic Synthesis for LUT Based<br />
Field Programmable Gate Arrays. ACM Transactions on Design<br />
Automation of Electronic Systems, 1(2):145–204, April 1996.<br />
• FPGA Architectures<br />
– S. Brown and J. Rose. FPGA and CPLD Architectures: A Tutorial.<br />
IEEE Design & Test of Computers, pages 42–57, Summer 1996.<br />
– S. Brown, R.J. Francis, J. Rose, and Z.G. Vranesic. Field-<br />
Programmable Gate Arrays. Kluwer Academic Publishers, 1992.<br />
– J. Rose, A. El Gamal, and A. Sangiovanni-Vincentelli. Architecture of<br />
Field-Programmable Gate Arrays. Proceedings of the IEEE, 81(7):<br />
1013–1029, July 1993.<br />
RC.3-1 Version 10.10.13 45<br />
RC.3-1 Version 10.10.13 46