Gliederung
Gliederung
Gliederung

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
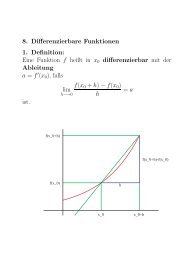
Rechnersysteme,<br />
Vorlesung 14: Cache & Co<br />
<strong>Gliederung</strong><br />
Meike Klettke<br />
Universität Greifswald<br />
meike.klettke@uni-greifswald.de<br />
� Heute verschiedene Themenkomplexe<br />
� Übersetzung von Javaprogrammen in Assemblercode<br />
� RISC, CISC<br />
� Pipelining von Maschinenbefehlen<br />
� Speicherzugriffszeiten,<br />
� Cache<br />
� Verwendung<br />
� Realisierungen<br />
� Zugriffszeiten<br />
� .. im Mehrprozessorbetrieb<br />
1<br />
2<br />
1
Merkmale von CISC-<br />
Prozessoren<br />
CISC = Complex Instruction Set Computer<br />
• mehrere (auch komplexere) Funktionen werden direkt<br />
durch den Prozessor durchgeführt<br />
• Merkmale:<br />
• große Anzahl von Maschinenbefehlen (meist mehr als 100)<br />
• komplexe Operationen (z.B. Gleitpunkt-Operationen in<br />
Hardware)<br />
• unterschiedliche Ausführungszeiten für einzelne Befehle<br />
• kleine Zahl von Registern (die meisten für feste Aufgaben)<br />
• mehrere Datentypen werden direkt von HW unterstützt<br />
• Interpretation einzelner Befehle durch Mikroprogramm<br />
Merkmale von RISC-<br />
Prozessoren<br />
RISC = Reduced Instruction Set Computer<br />
Gegensatz von CISC<br />
• Prozessor vereinfachen, indem Befehlssatz nur wenige, aber dafür<br />
sehr schnelle und einfach auszuführende Befehle beinhaltet<br />
• Merkmale:<br />
• wenige, schnell ausführbare Befehle (meist < 100)<br />
• einfache Operationen, die in einem Verarbeitungsschritt<br />
ausführbar sind<br />
• große Anzahl von Registern (meisten frei verwendbar)<br />
• Interpretation der einzelnen Befehle direkt durch HW<br />
3<br />
4<br />
2
Vor- und Nachteile von<br />
CISC bzw. RISC<br />
CISC erleichtert den Bau von Übersetzern<br />
RISC ermöglicht schnellere Ausführung von<br />
Maschinenprogrammen<br />
1. RISC-Befehle sind einfach, besitzen einheitlichen Befehlsaufbau,<br />
so dass sie in einem Zyklus ausführbar sind<br />
2. Feste Verdrahtung (kein Mikroprogramm) beim Steuerwerk<br />
bei RISC bringt schnellere Befehlsausführung mit sich<br />
3. Entwurf von RISC-Prozessoren ist einfacher<br />
4. RISC-Befehle ermöglichen wegen Einfachheit, einheitlichen<br />
Aufbau und Ausführbarkeit in einem Zyklus ein Pipelining<br />
Pipelining<br />
� Motivation:<br />
� Wäsche waschen nach dem Urlaub<br />
5<br />
6<br />
3
Phasen beim Pipelining<br />
Fließbandverarbeitung: Z.B. Befehl in 5 Phasen abarbeiten:<br />
• Phase 1: IF = Instruction Fetch<br />
nächsten Befehl aus dem Programmspeicher holen<br />
• Phase 2: ID = Instruction Decode<br />
dekodieren des Befehls, Operanden aus Registern holen<br />
• Phase 3: Ex = Execute/address calculation<br />
Ausführen der Operation und Berechnen der Adresse<br />
• Phase 4: MEM = Memory access<br />
Abspeichern des Ergebnisses<br />
• Phase 5: WB = Write back<br />
Evtl. Schreiben des Ergebnisses in Register<br />
Manche Befehle benötigen weniger als 5 Phasen:<br />
Erzeugt Befehl z.B. kein Ergebnis, entfallen die letzten<br />
beiden Phasen.<br />
RISC-Prozessor mit 5stufigem<br />
Pipelining<br />
Moderne Prozessoren haben nicht 5, sondern bis zu 20<br />
Phasen, die durch eigene Funktionseinheiten realisiert sind<br />
7<br />
8<br />
4
RISC-Prozessor mit 5stufigem<br />
Pipelining<br />
• einzelne Funktionseinheiten/Phasen sind unabhängig voneinander<br />
• benötigen gleich lange Ausführungszeit<br />
� können also parallel bearbeitet werden<br />
Geschwindigkeitsgewinn<br />
beim Pipelining<br />
b Befehle benötigen zu ihrer Abarbeitung folgende Zeiten:<br />
• ohne Pipelining: b*t<br />
• mit Pipelining: (b*t)/n +((b-1)*t)/n<br />
9<br />
10<br />
5
Daten-Hazards –<br />
Datenabhängigkeiten<br />
Datenabhängigkeit zwischen zwei Befehlen, wenn zum<br />
Beispiel der 2. Befehl ein Ergebnis des 1. Befehls<br />
benötigt, dieses aber noch nicht vorliegt:<br />
Daten-Hazards beim<br />
Pipelining<br />
1. Möglichkeit Daten-Hazards zu lösen: leere<br />
Operationen (NOP)<br />
10 statt 7 Takte � negativ für Geschwindigkeit des<br />
Programms<br />
11<br />
12<br />
6
Daten-Hazards beim<br />
Pipelining<br />
2. Möglichkeit: Umsortieren der Befehle durch den Compiler<br />
Umsortierung, die Daten-Hazard beseitigt:<br />
Daten-Hazards beim<br />
Pipelining<br />
2. Möglichkeit: Umsortieren der Befehle durch den Compiler<br />
13<br />
14<br />
7
Control-Hazards beim<br />
Pipelining<br />
Control-Hazards bei bedingten Sprüngen:<br />
Nachdem der Sprungbefehl JC die Phase IF verlassen hat,<br />
kann nicht SUB geladen werden, es ist zu diesem Zeitpunkt<br />
noch nicht bekannt, ob ein Sprung auf den Befehl an Position<br />
50 stattfindet.<br />
Control-Hazards beim<br />
Pipelining<br />
1. Möglichkeit Control-Hazards zu lösen: leere Operation<br />
(NOP)<br />
� negativ für Geschwindigkeit des Programms<br />
15<br />
16<br />
8
Control-Hazards beim<br />
Pipelining<br />
2. Möglichkeit Control-Hazards zu lösen:<br />
Branch Prediction<br />
• Prozessoren versuchen (mit bestimmten Techniken) den<br />
wahrscheinlichsten nächsten Befehl zu erraten<br />
• z.B. Statistik, nach der festgelegt, wie oft ein bedingter Sprung zu<br />
einem Sprung führte und wie oft nicht<br />
• � Das am wahrscheinlichsten eintretende Ereignis wird genommen,<br />
entsprechender Befehl in die Pipeline geladen.<br />
• Richtige Vorhersage � viel Zeit gespart, da keine NOP’s.<br />
• Falsche Vorhersage � ganze Pipeline leeren und evtl.<br />
falsch gesetzte Werte müssen zurückgesetzt werden.<br />
Cache<br />
� stammt vom französischen cacher – verbergen = „geheimes<br />
Lager“<br />
� bezeichnet einen schnellen Speicher<br />
� enthält Kopien von Inhalten eines anderen (Hintergrund-)<br />
Speichers<br />
� beschleunigt den Zugriff darauf<br />
� zum Zugriff werden Lokalitätseigenschaften ausgenutzt.<br />
� Zeitliche Lokalität<br />
� Räumliche Lokalität<br />
� für den Programmierer ist ein Cache weitgehend transparent<br />
� Darin gespeicherte Daten nicht direkt adressierbar<br />
� Nicht sichtbar, ob Daten aus dem Cache oder vom<br />
Hintergrundspeicher geholt werden<br />
17<br />
18<br />
9
Cache<br />
• Direkt in CPU (on-chip-cache oder first-level-cache)<br />
• Außerhalb der CPU (second-level-cache)<br />
• Cache-Speicher im Vergleich zum Hauptspeicher sehr kleine,<br />
aber wesentlich schnellere Speicher<br />
• Cache, um Geschwindigkeitslücke zwischen Register und<br />
Hauptspeicher zu schließen:<br />
• Idee: In Cache-Speicher möglichst immer Daten aus<br />
Hauptspeicher kopieren, die vom Prozessor als<br />
Nächstes benötigt werden<br />
• Damit keine zeitaufwändigen Zugriffe auf den<br />
Hauptspeicher, stattdessen auf den schnellen Cache<br />
Speicherarchitektur<br />
� mehrstufigen Speicherarchitektur<br />
� Level-1-Cache ist direkt im Prozessorkern untergebracht<br />
� wird mit derselben Taktrate betrieben wie der Prozessor<br />
selbst.<br />
� sehr klein (z. B. 16 Kilobyte oder 128 Kilobyte).<br />
� Level-2-Cache ist<br />
� entweder außerhalb des Prozessors auf dem Mainboard<br />
untergebracht oder<br />
� im Prozessor, aber nicht im Prozessorkern.<br />
� schneller als der normale Arbeitsspeicher, jedoch langsamer<br />
als der Level-1-Cache,<br />
� dafür mit z. B. 512 oder 1024 Kilobyte erheblich größer als<br />
Level-1-Cache<br />
19<br />
20<br />
10
Überblick: Speicherhierarchie<br />
1-10ns<br />
Register<br />
10-100ns<br />
Cache<br />
100-1000ns<br />
Hauptspeicher<br />
10 ms<br />
Plattenspeicher<br />
sec<br />
Archivspeicher<br />
Die Peripherie<br />
Massenspeicher<br />
1 – 8 Byte<br />
Compiler<br />
8 – 128 Byte<br />
Cache-Controller<br />
4 – 64 KB<br />
Betriebssystem<br />
Benutzer<br />
21<br />
22<br />
11
Lokalitäts-Prinzip<br />
Bei Programmausführung wird mit großer<br />
Wahrscheinlichkeit nur auf kleinen Adressbereich<br />
wiederholt zugegriffen.<br />
Räumliches Lokalitätsprinzip:<br />
�Mit großer Wahrscheinlichkeit wird als Nächstes auf eine Adresse<br />
zugegriffen, die nahe an Adresse liegt, auf die zuletzt<br />
zugegriffen wurde (Schleifen und Arrays).<br />
� In einen Cache wird nicht nur ein gerade benötigtes Datum aus<br />
dem Hauptspeicher kopiert sondern ganze Blöcke,<br />
(benachbarte Werte)<br />
Zeitliches Lokalitätsprinzip:<br />
� auf gleiches Datum wird in kurzer Zeit mehrfach<br />
zugegriffen � beim 2. Zugriff befindet es sich im Cache<br />
Ersetzung von Cache-Einträgen<br />
� Cache ist nicht sehr groß<br />
� Wenn der Cache voll besetzt ist, müssen Einträge entfernt<br />
werden<br />
� Auswahl der Einträge, die aus dem Cache entfernt werden,<br />
verschiedene Strategien (Verdrängungsstrategien) dazu:<br />
� Der Eintrag, auf den am längsten nicht zugegriffen wurde, wird<br />
verdrängt<br />
� Der am wenigsten verwendete Eintrag wird verdrängt<br />
� FIFO (First In First Out): Der älteste Eintrag wird verdrängt<br />
� Climb: eine neue Seite wird unten im Speicher eingesetzt, steigt bei<br />
jedem Zugriff eine Ebene nach oben, bei Verdrängungsstrategien<br />
wird die unterste Seite ersetzt<br />
� Optimal: Vorausschau, der Speicherbereich, auf den zukünftig am<br />
längsten nicht zugegriffen werden wird, wird verdrängt, nur<br />
anwendbar, wenn der Programmablauf im Voraus bekannt ist<br />
23<br />
24<br />
12
Verfahren: write-through<br />
� Cache Hit (Eintrag im Cache vorhanden)<br />
CPU<br />
Cache<br />
� Wert wird im Cache geändert<br />
Hauptspeicher<br />
� Aktualisierung des Wertes erfolgt gleichzeitig im<br />
Hauptspeicher<br />
Verfahren: write-through<br />
� Cache Miss (Eintrag ist im Cache nicht vorhanden)<br />
CPU<br />
Cache<br />
� Wert wird im Cache geändert<br />
Hauptspeicher<br />
� Aktualisierung des Wertes erfolgt gleichzeitig im<br />
Hauptspeicher<br />
25<br />
26<br />
13
Verfahren: write-through<br />
� Eintrag aus dem Cache entfernen<br />
Cache<br />
Hauptspeicher<br />
� Cache und Hauptspeicher sind abgeglichen<br />
� Entfernen von Einträgen aus dem Cache jederzeit<br />
ohne Rückschreiben auf den Hauptspeicher möglich<br />
Verfahren: write-back<br />
� Cache Hit (Eintrag im Cache vorhanden)<br />
CPU<br />
Cache<br />
Dirty bits<br />
Hauptspeicher<br />
� Wert wird im Cache geändert<br />
� Dirty-Bit-Kennzeichung wird gesetzt<br />
� Aktualisierung des Wertes im Hauptspeicher erfolgt<br />
vorläufig nicht<br />
27<br />
28<br />
14
Verfahren: write-back<br />
� Cache Miss (Eintrag ist im Cache nicht vorhanden)<br />
CPU<br />
Cache<br />
Dirty bits<br />
� Wert wird im Hauptspeicher geändert<br />
Verfahren: write-back<br />
� Eintrag aus dem Cache entfernen<br />
Cache<br />
Dirty bits<br />
Hauptspeicher<br />
Hauptspeicher<br />
Realisierung<br />
identisch zu<br />
write-through<br />
� Wenn der Wert im Cache aktualisiert wurde (dirty bit<br />
gesetzt), wird er in den Hauptspeicher<br />
zurückgeschrieben<br />
29<br />
30<br />
15
Verfahren: write-allocation<br />
� Cache Hit (Eintrag im Cache vorhanden)<br />
CPU<br />
Cache<br />
� Wert wird im Cache geändert<br />
Dirty bits<br />
� Dirty-Bit-Kennzeichung wird gesetzt<br />
� Aktualisierung des Wertes im<br />
Hauptspeicher erfolgt vorläufig nicht<br />
Hauptspeicher<br />
Verfahren: write-allocation<br />
Realisierung<br />
identisch zu<br />
write-through<br />
� Cache Miss (Eintrag ist im Cache nicht vorhanden)<br />
CPU<br />
Cache<br />
Dirty bits<br />
Hauptspeicher<br />
� Neuer Wert wird in den Cache geschrieben<br />
� Dirty-Bit-Kennzeichung wird gesetzt<br />
� Aktualisierung des Wertes im Hauptspeicher erfolgt<br />
später<br />
31<br />
32<br />
16
Verfahren: write-allocation<br />
� Eintrag aus dem Cache entfernen<br />
Cache<br />
Dirty bits<br />
Hauptspeicher<br />
� Wenn der Wert im Cache aktualisiert wurde (dirty bit<br />
gesetzt), wird er in den Hauptspeicher<br />
zurückgeschrieben<br />
Vergleich der Verfahren<br />
� Write-allocation:<br />
� Schnellste Realisierung<br />
� Geringste Busbelastung, weil Rückschreiben der Werte nicht<br />
nach jeder Veränderung sondern erst nach mehreren<br />
Schreibvorgängen notwendig ist<br />
� Cache-Kohärenz (Übereinstimmung: Cache -<br />
Hauptspeicher) dabei aber nicht zu jedem Zeitpunkt<br />
gegeben: wichtig beim Zugriff durch mehrere Prozessoren<br />
� Write-through<br />
� Einfach zu realisieren<br />
� Cache-Kohärenz ist jederzeit garantiert<br />
� Langsamer als write-allocation und write-back<br />
33<br />
34<br />
17
Zusammenfassung<br />
� Vorlesung sollte Eindruck vermitteln<br />
� Von schaltungstechnischen Realisierung von<br />
Basisfunktionen bis hin zu Prozessoren und Prinzipien von<br />
Computern<br />
� Ergänzend dazu:<br />
� Betriebssysteme<br />
� Weiterführende Literatur:<br />
� Helmut Herold / Bruno Lurz / Jürgen Wohlrab: Grundlagen der<br />
Informatik, Pearson Studium, 2006<br />
� Andrew S. Tanenbaum: Computerarchitektur, Strukturen - Konzepte –<br />
Grundlagen, Pearson Studium<br />
� Beides in der Greifswalder Bibliothek (mit jeweils einem Exemplar)<br />
35<br />
18