

XML-‐basierte Kommunikation im IHE - Institute of Health ...
XML-‐basierte Kommunikation im IHE - Institute of Health ...
XML-‐basierte Kommunikation im IHE - Institute of Health ...

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
4. Ergebnisse<br />
4.1.2 Schnittstellenkonzept des Document Consumers<br />
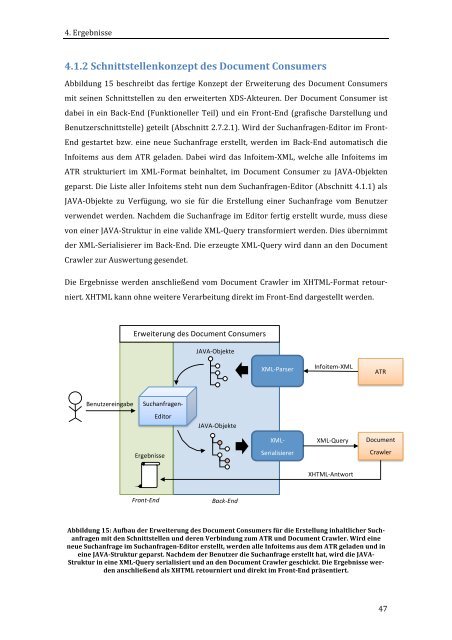
Abbildung 15 beschreibt das fertige Konzept der Erweiterung des Document Consumers<br />
mit seinen Schnittstellen zu den erweiterten XDS-‐Akteuren. Der Document Consumer ist<br />
dabei in ein Back-‐End (Funktioneller Teil) und ein Front-‐End (grafische Darstellung und<br />
Benutzerschnittstelle) geteilt (Abschnitt 2.7.2.1). Wird der Suchanfragen-‐Editor <strong>im</strong> Front-‐<br />
End gestartet bzw. eine neue Suchanfrage erstellt, werden <strong>im</strong> Back-‐End automatisch die<br />
Infoitems aus dem ATR geladen. Dabei wird das Infoitem-‐<strong>XML</strong>, welche alle Infoitems <strong>im</strong><br />
ATR strukturiert <strong>im</strong> <strong>XML</strong>-‐Format beinhaltet, <strong>im</strong> Document Consumer zu JAVA-‐Objekten<br />
geparst. Die Liste aller Infoitems steht nun dem Suchanfragen-‐Editor (Abschnitt 4.1.1) als<br />
JAVA-‐Objekte zu Verfügung, wo sie für die Erstellung einer Suchanfrage vom Benutzer<br />
verwendet werden. Nachdem die Suchanfrage <strong>im</strong> Editor fertig erstellt wurde, muss diese<br />
von einer JAVA-‐Struktur in eine valide <strong>XML</strong>-‐Query transformiert werden. Dies übern<strong>im</strong>mt<br />
der <strong>XML</strong>-‐Serialisierer <strong>im</strong> Back-‐End. Die erzeugte <strong>XML</strong>-‐Query wird dann an den Document<br />
Crawler zur Auswertung gesendet.<br />
Die Ergebnisse werden anschließend vom Document Crawler <strong>im</strong> XHTML-‐Format retour-‐<br />
niert. XHTML kann ohne weitere Verarbeitung direkt <strong>im</strong> Front-‐End dargestellt werden.<br />
Benutzereingabe<br />
Erweiterung des Document Consumers<br />
Suchanfragen-‐<br />
Front-‐End<br />
Editor<br />
Ergebnisse<br />
JAVA-‐Objekte<br />
JAVA-‐Objekte<br />
Back-‐End<br />
<strong>XML</strong>-‐Parser<br />
Infoitem-‐<strong>XML</strong><br />
<strong>XML</strong>-‐Query<br />
XHTML-‐Antwort<br />
Abbildung 15: Aufbau der Erweiterung des Document Consumers für die Erstellung inhaltlicher Such-‐<br />
anfragen mit den Schnittstellen und deren Verbindung zum ATR und Document Crawler. Wird eine<br />
neue Suchanfrage <strong>im</strong> Suchanfragen-‐Editor erstellt, werden alle Infoitems aus dem ATR geladen und in<br />
eine JAVA-‐Struktur geparst. Nachdem der Benutzer die Suchanfrage erstellt hat, wird die JAVA-‐<br />
Struktur in eine <strong>XML</strong>-‐Query serialisiert und an den Document Crawler geschickt. Die Ergebnisse wer-‐<br />
den anschließend als XHTML retourniert und direkt <strong>im</strong> Front-‐End präsentiert.<br />
<strong>XML</strong>-‐<br />
Serialisierer<br />
ATR<br />
Document<br />
Crawler<br />
47













