Vergleich von künstlichen Neuronalen Netzen und multivariaten ...
Vergleich von künstlichen Neuronalen Netzen und multivariaten ...
Vergleich von künstlichen Neuronalen Netzen und multivariaten ...

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Holger Schulze<br />
<strong>Vergleich</strong> <strong>von</strong> künstlichen <strong>Neuronalen</strong> <strong>Netzen</strong> <strong>und</strong><br />
<strong>multivariaten</strong> statistischen Verfahren in der<br />
Primärforschung: Ein empirischer <strong>Vergleich</strong><br />
Masterarbeit im wissenschaftlichen Studiengang Agrarwissenschaften<br />
an der Georg-August-Universität Göttingen,<br />
Fakultät für Agrarwissenschaften<br />
Studienrichtung: Wirtschafts- <strong>und</strong> Sozialwissenschaften des Landbaus<br />
1. Prüfer: Prof. Dr. Achim Spiller<br />
2. Prüfer: Prof. Dr. Stephan <strong>von</strong> Cramon-Taubadel<br />
Abgabetermin: 04.04.2005<br />
angefertigt im: Institut für Agrarökonomie
Inhaltsverzeichnis<br />
Inhaltsverzeichnis:<br />
Abbildungsverzeichnis............................................................................................... III<br />
Tabellenverzeichnis..................................................................................................... V<br />
Symbolverzeichnis ....................................................................................................VII<br />
Abkürzungsverzeichnis..............................................................................................IX<br />
1 Einleitung ............................................................................................................. 1<br />
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung ...................... 3<br />
2.1 Der Ablauf des Marktforschungsprozesses.................................................. 3<br />
2.2 Analyseverfahren in der Primärforschung ................................................... 6<br />
3 Methodische Gr<strong>und</strong>legung................................................................................. 11<br />
3.1 Multivariate statistische Verfahren ............................................................ 11<br />
3.1.1 Überblick über multivariate statistische Verfahren................................ 11<br />
3.1.2 Regressionsanalyse ................................................................................ 12<br />
3.1.3 Clusteranalyse ........................................................................................ 22<br />
3.2 Künstliche Neuronale Netze ...................................................................... 34<br />
3.2.1 Überblick über Neuronale Netze............................................................ 34<br />
3.2.2 Gr<strong>und</strong>struktur <strong>und</strong> Funktionsweise Neuronaler Netze........................... 35<br />
3.2.3 Multi-Layer-Perceptrons........................................................................ 42<br />
3.2.4 Self-Organizing-Maps............................................................................ 48<br />
3.3 Eigenschaften Neuronaler Netze im <strong>Vergleich</strong> zu den <strong>multivariaten</strong><br />
Verfahren ................................................................................................... 52<br />
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren...................................... 58<br />
4.1 Zum Stand der Forschung .......................................................................... 58<br />
4.2 Bewertungskriterien für die Güte der Verfahren ....................................... 62<br />
4.3 Auswahl der Fallstudien <strong>und</strong> Vorgehensweise .......................................... 65<br />
4.4 Fallstudie 1: Meinungsforschung zum Stallbau in Diemarden.................. 68<br />
4.4.1 Empirische Basis <strong>und</strong> Problemstellung der Untersuchung .................... 68<br />
4.4.2 Ergebnisse der <strong>multivariaten</strong> Analyseverfahren .................................... 70<br />
I
Inhaltsverzeichnis<br />
4.4.3 Ergebnisse der künstlichen <strong>Neuronalen</strong> Netze....................................... 81<br />
4.4.4 Ergebnisse der Fallstudie <strong>und</strong> Verfahrensvergleich............................... 85<br />
4.5 Fallstudie 2: Markenpräferenz bei chinesischen Konsumenten................. 88<br />
4.5.1 Empirische Basis <strong>und</strong> Problemstellung der Untersuchung .................... 88<br />
4.5.2 Ergebnisse der <strong>multivariaten</strong> Analyseverfahren .................................... 90<br />
4.5.3 Ergebnisse der künstlichen <strong>Neuronalen</strong> Netze....................................... 99<br />
4.5.4 Ergebnisse der Fallstudie <strong>und</strong> Verfahrensvergleich............................. 104<br />
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich .......................... 108<br />
6 Schlussbemerkungen........................................................................................ 118<br />
Literaturverzeichnis.................................................................................................. 120<br />
Anhang ..................................................................................................................... 131<br />
A. Methoden der Datenanalyse........................................................................ 131<br />
B. Berechnungen der Fallstudie 1 .................................................................... 131<br />
C. Berechnungen der Fallstudie 2 .................................................................... 139<br />
D. <strong>Vergleich</strong> der Verfahren.............................................................................. 145<br />
E. Fragebogen der Fallstudie 1 ........................................................................ 148<br />
F. Fragebogen der Fallstudie 2......................................................................... 157<br />
II
Abbildungsverzeichnis<br />
Abbildungsverzeichnis:<br />
Abbildung 1: Die Ablaufschritte des Marktforschungsprozesses.............................. 3<br />
Abbildung 2: Gr<strong>und</strong>methoden der Datengewinnung ................................................. 4<br />
Abbildung 3: Methoden der Primärdatenerhebung.................................................... 5<br />
Abbildung 4: Analyseverfahren in der Primärforschung........................................... 7<br />
Abbildung 5: Verwendung <strong>von</strong> KNN im Data Mining-Prozess ................................ 9<br />
Abbildung 6: <strong>Vergleich</strong> <strong>von</strong> KNN <strong>und</strong> <strong>multivariaten</strong> Verfahren............................. 10<br />
Abbildung 7: Gr<strong>und</strong>legende strukturen-prüfende Verfahren................................... 11<br />
Abbildung 8: Die Ablaufschritte der Regressionsanalyse ....................................... 13<br />
Abbildung 9: Die Ablaufschritte der Clusteranalyse ............................................... 22<br />
Abbildung 10: Überblick über ausgewählte Clusteralgorithmen............................... 24<br />
Abbildung 11: Dendogramm für ein hierarchisches Clusterverfahren ...................... 25<br />
Abbildung 12: Scree-Test zur Bestimmung der Clusteranzahl.................................. 27<br />
Abbildung 13: Schematische Darstellung einer Nervenzelle .................................... 36<br />
Abbildung 14: Das menschliche Nervensystem als SOR-Modell ............................. 37<br />
Abbildung 15: Allgemeines Modell eines künstlichen Neurons................................ 37<br />
Abbildung 16: Kurvenverlauf ausgewählter Aktivierungsfunktionen....................... 38<br />
Abbildung 17: Darstellung der Schichten eines <strong>Neuronalen</strong> Netzes ......................... 39<br />
Abbildung 18: Einige schematische Netzwerktopologien ......................................... 40<br />
Abbildung 19: Ausgewählte künstliche neuronale Netzwerktypen........................... 41<br />
Abbildung 20: Ablaufschritte der Multi-Layer-Perceptrons...................................... 43<br />
Abbildung 21: Test- <strong>und</strong> Validationsfehler im Lernverlauf ...................................... 45<br />
Abbildung 22: Topologie einer Self-Organizing-Map............................................... 49<br />
Abbildung 23: Ablaufschritte bei den Self-Organizing-Maps................................... 50<br />
Abbildung 24: Eigenschaften Neuronaler Netze <strong>und</strong> statistische<br />
Problemsituationen............................................................................. 52<br />
Abbildung 25: Dimension der Komplexität............................................................... 54<br />
Abbildung 26: Blackbox-Ansatz................................................................................ 56<br />
Abbildung 27: Kriterien zur Beurteilung der Leistungsfähigkeit der Verfahren....... 63<br />
Abbildung 28: Clementine Oberfläche mit Daten-Stream......................................... 67<br />
Abbildung 29: Regressionsmodell auf Gr<strong>und</strong>lage der Faktorenanalyse<br />
(In-Sample) ........................................................................................ 74<br />
Abbildung 30: Modifiziertes Regressionsmodell (In-Sample) .................................. 75<br />
III
Abbildungsverzeichnis<br />
Abbildung 31: Regressionsmodell auf Basis der Rückwärts-Methode...................... 79<br />
Abbildung 32: MLP-Modell auf Gr<strong>und</strong>lage der Faktorenanalyse<br />
(Validationsdaten).............................................................................. 82<br />
Abbildung 33: Modifiziertes MLP Model (Validationsdaten) .................................. 83<br />
Abbildung 34: Elbow-Kriterium zur Bestimmung der Clusteranzahl ....................... 93<br />
Abbildung 35: Beschreibung der Cluster durch die Statements der Faktoren........... 96<br />
Abbildung 36: Entwicklung der Fehlerquadratsumme bei den SOM...................... 100<br />
Abbildung 37: Beschreibung der Cluster durch die Statements der<br />
Faktoren (SOM) ............................................................................... 103<br />
Abbildung 38: SOM, K-Means <strong>und</strong> Ward im <strong>Vergleich</strong> ......................................... 104<br />
Abbildung 39: Validität der Clusterlösungen im Verfahrensvergleich.................... 105<br />
Abbildung 40: Einordnung der Analyseverfahren nach anwender-, daten- <strong>und</strong><br />
methodenorientierten Anforderungen .............................................. 116<br />
Abbildung 41: Methoden der Datenanalyse............................................................. 131<br />
Abbildung 42: Häufigkeitsverteilung der Residualwerte......................................... 133<br />
Abbildung 43: P-P-Normalverteilungsdiagramm der standardisierten<br />
Residualwerte................................................................................... 133<br />
Abbildung 44: Streudiagramm - Residualwerte gegen Vorhersagewerte................ 134<br />
Abbildung 45: Häufigkeitsverteilung der Residualwerte (Modell 2) ...................... 137<br />
Abbildung 46: P-P-Normalverteilungsdiagramm der standardisierten<br />
Residualwerte (Modell 2)................................................................. 137<br />
Abbildung 47: Streudiagramm - Residualwerte gegen Vorhersagewerte<br />
(Modell 2) ........................................................................................ 138<br />
Abbildung 48: Screeplot der Faktorenanalyse ......................................................... 139<br />
Abbildung 49: Komponentendiagramm im rotierten Raum .................................... 139<br />
Abbildung 50: 3D-Streudiagramm der Clusterlösung (K-Means)........................... 145<br />
Abbildung 51: 3D-Streudiagramm der Clusterlösung (SOM)................................. 146<br />
Abbildung 52: Häufigkeit der eingesetzten Verfahren in der betrieblichen Praxis . 146<br />
Abbildung 53: Bedeutung der Auswahlkriterien geeigneter Verfahren .................. 147<br />
IV
Tabellenverzeichnis<br />
Tabellenverzeichnis:<br />
Tabelle 1: Annahmeverletzungen des linearen Regressionsmodells ....................... 15<br />
Tabelle 2: Terminologie der KNN im <strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren.. 35<br />
Tabelle 3: Ausgewählte Literatur zum Verfahrensvergleich in der<br />
Sek<strong>und</strong>ärforschung (Teil 1)..................................................................... 59<br />
Tabelle 4: Ausgewählte Literatur zum Verfahrensvergleich in der<br />
Sek<strong>und</strong>ärforschung (Teil 2)..................................................................... 60<br />
Tabelle 5: Ausgewählte Literatur zum Verfahrensvergleich in der<br />
Primärforschung...................................................................................... 61<br />
Tabelle 6: Übersicht über die Fallstudien <strong>und</strong> die verwendeten Modelle................ 66<br />
Tabelle 7: Faktorladungen der einzelnen Statements............................................... 72<br />
Tabelle 8: Prognosegüte des multiplen Regressionsmodells ................................... 78<br />
Tabelle 9: Prognosegüte des multiplen Regressionsmodells auf Basis der<br />
Rückwärts-Methode ................................................................................ 81<br />
Tabelle 10: Prognosequalität des <strong>Neuronalen</strong> Netzwerkes (MLP)............................ 84<br />
Tabelle 11: Prognosequalität im Verfahrensvergleich............................................... 85<br />
Tabelle 12: Faktorladungen der einzelnen Statements............................................... 91<br />
Tabelle 13: Kreuztabelle - K-Means versus Ward-Methode ..................................... 94<br />
Tabelle 14: Homogenität der Cluster (F-Werte der extrahierten Faktoren)............... 94<br />
Tabelle 15: Charakterisierung der Cluster durch die T-Werte der aktiven Faktoren. 95<br />
Tabelle 16: Homogenität der Cluster (F-Werte der extrahierten Faktoren)............. 101<br />
Tabelle 17: Charakterisierung der Cluster durch die T-Werte der Faktoren ........... 102<br />
Tabelle 18: Kreuztabelle - SOM versus K-Means ................................................... 106<br />
Tabelle 19: Bewertung <strong>von</strong> <strong>multivariaten</strong> Verfahren <strong>und</strong> KNN.............................. 115<br />
Tabelle 20: ANOVA der Regressionsanalyse.......................................................... 131<br />
Tabelle 21: Regressionskoeffizienten <strong>und</strong> Multikollinearitätsdiagnose .................. 132<br />
Tabelle 22: ANOVA der Regressionsanalyse (Modell 2)........................................ 134<br />
Tabelle 23: Regressionskoeffizienten <strong>und</strong> Multikollinearitätsdiagnose (Modell 2) 135<br />
Tabelle 24: Korrelationsmatrix der exogenen Variablen aus der<br />
Regressionsanalyse (Modell 2) ............................................................. 136<br />
Tabelle 25: Korrelationsmatrix der exogenen Variablen der Regressionsanalyse... 138<br />
Tabelle 26: Datenbasis zum Elbow-Kriterium......................................................... 140<br />
Tabelle 27: Mittelwertvergleich bei der Ward Methode.......................................... 140<br />
V
Tabellenverzeichnis<br />
Tabelle 28: Mittelwertvergleich bei der K-Means Methode.................................... 141<br />
Tabelle 29: ANOVA-Tabelle bei der K-Means Clusterung .................................... 141<br />
Tabelle 30: Kreuztabelle der Ergebnisse der replizierten <strong>und</strong> der anfänglichen ..... 141<br />
Tabelle 31: Ergebnisse der Clusteranalyse (Ausgangslösung) ................................ 142<br />
Tabelle 32: Ergebnisse der replizierten Clusteranalyse ........................................... 142<br />
Tabelle 33: <strong>Vergleich</strong> der Dimensionen der SOM................................................... 143<br />
Tabelle 34: Mittelwertvergleich bei den SOM......................................................... 143<br />
Tabelle 35: ANOVA der aktiven Faktoren .............................................................. 143<br />
Tabelle 36: ANOVA-Tabelle bei den SOM............................................................. 144<br />
Tabelle 37: Kreuztabelle der Ergebnisse der replizierten <strong>und</strong> der<br />
anfänglichen SOM ................................................................................ 144<br />
Tabelle 38: Ergebnisse der SOM (Ausgangslösung) ............................................... 144<br />
Tabelle 39: Ergebnisse der replizierten SOM .......................................................... 145<br />
VI
Symbolverzeichnis<br />
Symbolverzeichnis:<br />
a<br />
b<br />
0<br />
b<br />
j<br />
Anzahl der Neuronen in der Ausgabeschicht<br />
Konstante der Regressionsfunktion<br />
Regressionskoeffizient (j= 1,2,…,J)<br />
2<br />
D quadrierte Euklidische Distanz<br />
E<br />
durchschnittlicher Gesamtfehler<br />
e<br />
k<br />
Abweichung des Schätzwertes vom Beobachtungswert<br />
e(x)<br />
Eingangsfunktion<br />
J Zahl der unabhängigen Variablen<br />
K Zahl der Beobachtungen<br />
k Zahl der Ausprägungen<br />
M Zahl der Übereinstimmungen<br />
N<br />
p<br />
i<br />
Gesamtzahl der berechneten Beobachtungen (i = 1,…,N).<br />
relativer Anteil der einzelnen Ausprägungen an der<br />
Gesamtzahl der Fälle<br />
R<br />
Korrelationskoeffizient<br />
S(J) Standardabweichung der Variablen J in der<br />
Erhebungsgesamtheit<br />
s<br />
bj<br />
Standardfehler <strong>von</strong> b<br />
j<br />
s<br />
t<br />
Streuung der empirischen (beobachteten) Ausgabewerte<br />
s<br />
y<br />
Streuung der berechneten (vorhergesagte) Ausgabewerte<br />
t<br />
i<br />
empirische (beobachtete) Ausgabewerte<br />
t<br />
emp<br />
Empirischer t-Wert für den j-ten Regressor<br />
t<br />
u<br />
Ü<br />
Mittelwert der empirischen (beobachteten) Ausgabewerte<br />
Störgröße<br />
Anteil der tatsächlich beobachteten Übereinstimmungen<br />
VII
Symbolverzeichnis<br />
Ü<br />
E<br />
Anteil der erwarteten Übereinstimmung<br />
V Zahl der <strong>Vergleich</strong>e<br />
V (J) Varianz der Variablen J in der Erhebungsgesamtheit<br />
V(J,G) Varianz der Variablen J in Gruppe G<br />
w<br />
j<br />
Verbindungsgewichte<br />
X<br />
j<br />
Wert der unabhängigen Variablen (j= 1,2,…,J)<br />
x<br />
j<br />
Eingangsinformationen<br />
x<br />
ij<br />
(x<br />
i´j) Merkmalsausprägung des Objektes ei<br />
i´<br />
(x ) auf dem Merkmal j<br />
X(J,G) Mittelwert der Variablen J über die Objekte in Gruppe G<br />
X(J)<br />
Y<br />
y<br />
i<br />
y<br />
k<br />
Gesamtmittelwert der Variablen J in der Erhebungsgesamtheit<br />
Wert der j-ten Beobachtung für die abhängige Variable<br />
berechnete (vorhergesagte) Ausgabewerte<br />
Wert der abhängigen Variablen (k=1,2,…,K)<br />
$ y<br />
k<br />
ermittelter Schätzwert <strong>von</strong> Y für x<br />
k<br />
y<br />
Mittelwert der berechneten (vorhergesagte) Ausgabewerte<br />
β<br />
0<br />
Konstantes Glied der Regressionsfunktion<br />
β<br />
j<br />
Regressionskoeffizient (j= 1,2,…,J)<br />
VIII
Abkürzungsverzeichnis<br />
Abkürzungsverzeichnis:<br />
ANN<br />
ANOVA<br />
BLUE<br />
CLU<br />
DA<br />
DW<br />
EB<br />
KDD<br />
KI<br />
KNN<br />
KQ<br />
LOGR<br />
MAE<br />
MAPE<br />
MLP<br />
MRA<br />
MS<br />
MSE<br />
NDA<br />
OLS<br />
RCLU<br />
RBF<br />
RMSE<br />
SEA<br />
SNNS<br />
SOM<br />
SOR<br />
SPSS<br />
SS<br />
VIF<br />
Artificial Neural Networks<br />
Analysis of Variance<br />
Best Linear Unbiased Estimator<br />
Clusteranalyse<br />
Diskriminanzanalyse<br />
Durbin-Watson-Statistik<br />
Entscheidungsbaum<br />
Knowledge Discovery in Database<br />
Künstliche Intelligenz<br />
Künstliche Neuronale Netze<br />
Kleinstquadrat<br />
Logistische Regressionsanalyse<br />
Mean Absolute Error<br />
Mean Absolute Percent Error<br />
Multi-Layer-Perceptrons<br />
Multiple Regressionsanalyse<br />
Mean Squares<br />
Mean Square Error<br />
Neuronale Diskriminanzanalyse<br />
Ordinary Least Squares<br />
Replizierte Clusteranalyse<br />
Radiale Basisfunktionen<br />
Root Mean Square Error<br />
Sensitivitätsanalyse<br />
Stuttgarter Neuronale Netze Simulator<br />
Self-Organizing-Maps<br />
Stimulus-Organismus-Response<br />
Statistical Package for the Social Sciences<br />
Sum of Squares<br />
Variance Inflation Factors<br />
IX
1 Einleitung<br />
1 Einleitung<br />
Die heutige Unternehmensführung benötigt für die Entwicklung eines erfolgreichen<br />
Marketingkonzeptes umfassende <strong>und</strong> aktuelle Informationen. Das Ziel der<br />
Primärforschung ist, diese Informationen zu erheben <strong>und</strong> anschließend die<br />
Komplexität <strong>und</strong> Dynamik auf die relevanten Daten zu verdichten. Nur so kann den<br />
Entscheidungsträgern, die einem immer stärkeren Wettbewerbsdruck unterliegen,<br />
eine schnellere individuelle Anpassung an die Marktbedingungen ermöglicht werden.<br />
Dem Marktforscher obliegt somit die Aufgabe, eine möglichst effiziente Ausnutzung<br />
der zur Verfügung stehenden Daten zu erreichen. Dafür steht ihm ein breites<br />
Spektrum an Analyseverfahren zur Auswahl. Während es sich bei den klassischen<br />
uni-, bi- <strong>und</strong> <strong>multivariaten</strong> Verfahren um bereits erprobte Verfahren handelt, weisen<br />
die künstlichen <strong>Neuronalen</strong> Netze, im Einsatz für die Primärforschung, einen<br />
innovativen Charakter auf. Sie sind ursprünglich als mathematisches Abbild<br />
neurobiologischen Lernens (künstliche Intelligenz) entstanden <strong>und</strong> haben sich nach<br />
vielen Weiterentwicklungen in verschiedenartigen Wissenschaftsdisziplinen<br />
etabliert. Im Gegensatz zu den meisten herkömmlichen <strong>multivariaten</strong> Verfahren<br />
ermöglichen sie es unter anderem, nicht lineare Zusammenhänge darzustellen <strong>und</strong><br />
eine sehr hohe Anzahl an Variablen zu verarbeiten.<br />
Folglich ist es Ziel der Arbeit, zu untersuchen, ob durch den Einsatz <strong>von</strong> künstlichen<br />
<strong>Neuronalen</strong> <strong>Netzen</strong> in der Primärforschung eine Verbesserung der Informationsgewinnung<br />
im <strong>Vergleich</strong> zu den bisher eingesetzten <strong>multivariaten</strong> Verfahren<br />
möglich ist.<br />
Zur Beantwortung dieser Frage gliedert sich die vorliegende Masterarbeit in fünf<br />
Teile. Nach der Einleitung stellt Kapitel 2 die Einordnung der Primärforschung in<br />
den Marktforschungsprozess dar. Anschließend erfolgt ein Überblick über die in der<br />
Primärforschung einsetzbaren Analyseverfahren. Im dritten Abschnitt werden die<br />
methodischen Gr<strong>und</strong>lagen der zu vergleichenden Datenanalyseverfahren aufgezeigt.<br />
Da die Literatur zum Teil, außer bei der Regressionsanalyse, keine genauen <strong>und</strong><br />
einheitlichen Ablaufschritte sowie Gütekriterien zur Verwendung dieser Verfahren<br />
(Clusteranalyse, Multi-Layer-Perceptrons <strong>und</strong> Self-Organizing-Maps) aufweisen,<br />
1
1 Einleitung<br />
liegt der Schwerpunkt dieses Kapitels darin, diese anwenderbezogenen Abläufe<br />
darzulegen. Abgeschlossen wird dieser Abschnitt mit einem theoretischen Überblick<br />
über die Eigenschaften Neuronaler Netze im <strong>Vergleich</strong> zu den <strong>multivariaten</strong><br />
Verfahren. Zu Beginn des empirischen Teils wird durch eine Vorstellung<br />
ausgewählter Studien ein Überblick zum Stand der Forschung gegeben. Auf Basis<br />
der in Kapitel 4.2 vorgestellten Bewertungskriterien wird anschließend exemplarisch<br />
durch zwei Fallstudien der <strong>Vergleich</strong> zwischen den <strong>multivariaten</strong> Verfahren <strong>und</strong> den<br />
künstlichen <strong>Neuronalen</strong> <strong>Netzen</strong> durchgeführt. In den abschließenden Kapiteln 5 <strong>und</strong><br />
6 <strong>und</strong> werden die wesentlichen Ergebnisse der Arbeit zusammengefasst, ein Ausblick<br />
auf weitere, auf diese Arbeit aufbauende wissenschaftliche Untersuchungsmöglichkeiten<br />
gegeben <strong>und</strong> Handlungsempfehlungen ausgesprochen.<br />
2
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
2 Verwendung <strong>von</strong> statistischen Verfahren in der<br />
Primärforschung<br />
2.1 Der Ablauf des Marktforschungsprozesses<br />
Für die Festlegung der Marketingstrategien sowie die Entwicklung eines<br />
Marketingplans benötigt die Unternehmensführung vielfältige Informationen aus der<br />
Umfeld-, Markt-, <strong>und</strong> Unternehmensanalyse. Die methodische F<strong>und</strong>ierung für diesen<br />
Marketing-Entscheidungsprozess liefert die Marktforschung. Sie umfasst die<br />
Erhebung, Auswertung <strong>und</strong> Interpretation <strong>von</strong> entscheidungsrelevanten<br />
Informationen im Rahmen der Marketingsituationsanalyse (BODENSTEIN/SPILLER<br />
1998: 75; BRUHN 1999: 89-92). Die Durchführung einer Marktforschungsuntersuchung<br />
verläuft anhand des in Abbildung 1 dargestellten Prozesses. 1<br />
Abbildung 1: Die Ablaufschritte des Marktforschungsprozesses<br />
Schritt 1<br />
Problemdefinition<br />
Schritt 2<br />
Marktforschungsdesign<br />
Schritt 3<br />
Datengewinnung<br />
Schritt 4<br />
Datenanalyse<br />
Schritt 5<br />
Kommunikation der Ergebnisse<br />
Quelle: Eigene Darstellung in Anlehnung an HÜTTNER 1999: 17; BEREKOVEN et al. 1999: 49<br />
1 Einen detaillierten Überblick über den Marktforschungsprozess zeigen unter anderem<br />
BEREKOVEN et al. (1999), Bodenstein/Spiller (1998), BRUHN (1999), HERRMANN et al. (1999) <strong>und</strong><br />
HÜTTNER (1999).<br />
3
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
Demnach erfolgt zunächst die Strukturierung des Forschungsproblems<br />
(Modellbildung) mit anschließender Definition eines Forschungsziels. Zur<br />
Konkretisierung dieses Zieles werden im zweiten Schritt Hypothesen aufgestellt, die<br />
mögliche theoretische Lösungen des Forschungsproblems darstellen (Modellspezifikation).<br />
Darauf aufbauend wird ein detaillierter Forschungsplan (Arbeits-,<br />
Zeit-, Kostenplan) erstellt (Marktforschungsdesign) (HERRMANN et al. 1999: 18ff.).<br />
Im Rahmen der anschließenden Datengewinnung können die Sek<strong>und</strong>ärforschung<br />
(Desk Research) <strong>und</strong> die Primärforschung unterschieden werden (Abbildung 2).<br />
Abbildung 2: Gr<strong>und</strong>methoden der Datengewinnung<br />
Quelle: Eigene Darstellung in Anlehnung an HÜTTNER 1999: 23; BEREKOVEN et al. 1999: 49<br />
Die Sek<strong>und</strong>ärforschung verwendet für die Auswertung <strong>und</strong> Analyse bereits<br />
vorhandenes Datenmaterial. Zum einen können diese Daten aus<br />
unternehmensexternen Quellen (z. B. Panel, Statistisches B<strong>und</strong>esamt, öffentliche<br />
Institutionen, Fachbücher) <strong>und</strong> zum anderen aus unternehmensinternen Quellen<br />
(z. B. Buchhaltungsunterlagen, K<strong>und</strong>enstatistik, Controlling, Meldungen des<br />
Außendienstes) stammen (BODENSTEIN/SPILLER 1998: 75-77; BEREKOVEN et al.<br />
1999: 42-48). Diese Art der Informationsgewinnung verursacht einen relativ<br />
geringen finanziellen <strong>und</strong> zeitlichen Aufwand. Jedoch sind die ermittelten Daten<br />
häufig nicht speziell auf ein vorliegendes Informationsproblem ausgerichtet <strong>und</strong><br />
weisen einen zu geringen Grad an Aktualität, Detailliertheit, Objektivität <strong>und</strong><br />
Relevanz auf (ebd.).<br />
Ziel der Primärforschung ist es somit für die Entscheidungsfindung konkrete<br />
originäre Daten selbst zu erheben (BODENSTEIN/SPILLER 1998: 77). Abbildung 3<br />
verdeutlicht, dass im Rahmen der Primärdatenerhebung die Möglichkeit besteht<br />
Befragungen <strong>und</strong> Beobachtungen durchzuführen. Erstere können weiterhin in<br />
4
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
quantitative <strong>und</strong> qualitative Methoden differenziert werden. Während quantitative<br />
Befragungen standardisiert erfolgen <strong>und</strong> dadurch ein breites Spektrum an Verhaltens<strong>und</strong><br />
Denkmusterinformationen (z. B. K<strong>und</strong>enzufriedenheit, Einstellungen,<br />
Kaufabsichten usw.) über die Gr<strong>und</strong>gesamtheit liefern können, bieten qualitative<br />
Befragungen die Möglichkeit einen vertieften Einblick in Bestimmungsfaktoren<br />
einzelner Handlungen zu erhalten (ebd.: 77-78). Beobachtungen haben im Gegensatz<br />
zu den Befragungen den Vorteil, dass sie unabhängig <strong>von</strong> der Auskunftswilligkeit<br />
<strong>und</strong> Auskunftsfähigkeit der Probanten sind. Es können apparative <strong>und</strong> persönliche<br />
Beobachtungen unterschieden werden (BRUHN 1999: 104f.).<br />
Abbildung 3: Methoden der Primärdatenerhebung<br />
Quelle: Eigene Darstellung<br />
Bevor im nächsten Schritt die Analyse der gewonnenen Daten vorgenommen werden<br />
kann, müssen diese zunächst aufbereitet werden. Das heißt, die Datenquellen, z. B.<br />
Fragebögen, werden bezüglich der Vollständigkeit <strong>und</strong> Plausibilität <strong>und</strong> ggf. auch<br />
auf unsachgemäße Erhebung (Interviewereinfluss) hin überprüft. Nach Feststellung<br />
5
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
der Responsequote muss unter Umständen auch über eine Nachbefragung<br />
entschieden werden. Für die eigentliche Auswertung der Daten liegt eine Vielzahl<br />
<strong>von</strong> statistischen Methoden vor. Dieses breite Methodenspektrum wird in der<br />
vorliegenden Arbeit dadurch eingeschränkt, dass nur der Einsatz <strong>von</strong> <strong>multivariaten</strong><br />
Verfahren <strong>und</strong> künstlichen <strong>Neuronalen</strong> <strong>Netzen</strong> (KNN) bei der Analyse <strong>von</strong> Daten,<br />
die durch die Primärforschung erhoben wurden, betrachtet werden. Die<br />
unterschiedlichen Analyseverfahren der Primärforschung werden im anschließenden<br />
Kapitel noch einmal ausführlicher dargestellt.<br />
Der abschließende Schritt des Marktforschungsprozesses umfasst die Dokumentation<br />
<strong>und</strong> Interpretation der Analyseergebnisse. Die gewonnenen Informationen sind mit<br />
der in Schritt 1 (vgl. Abbildung 1) definierten Problemstellung zu vergleichen<br />
(Rückkopplung). Gegebenenfalls sind weitere Untersuchungen notwendig<br />
(BEREKOVEN et al. 1999: 36; HÜTTNER 1999: 26). Nur Marktforschungsergebnisse,<br />
die einen hohen Grad an Validität, Reliabilität <strong>und</strong> Objektivität aufweisen, können<br />
den Ansprüchen der Entscheidungsträger des Unternehmens gerecht werden <strong>und</strong><br />
somit die Gr<strong>und</strong>lage für zukünftige Marketingstrategien bilden. 2 Für eine schnelle<br />
Entscheidungsfindung ist darüber hinaus wichtig, dass die relevanten Informationen<br />
auf ein überschaubares Maß verdichtet werden. Die Datenauswertung <strong>und</strong> somit auch<br />
die Auswahl eines geeigneten Analyseverfahrens spielen dabei eine große Rolle.<br />
2.2 Analyseverfahren in der Primärforschung<br />
Die Analyseverfahren in der Primärforschung lassen sich hinsichtlich der Anzahl der<br />
untersuchten Variablen in uni-, bi- <strong>und</strong> multivariate Verfahren unterscheiden (vgl.<br />
Abbildung 4). Kennzeichnend für die einfachste Form der Datenanalyse (univariate<br />
Methoden) ist, dass sich diese nur auf die Auswertung einer Variablen <strong>und</strong> deren<br />
Ausprägung konzentrieren. Während es bei nominal- <strong>und</strong> ordinalskalierten Daten nur<br />
möglich ist Häufigkeiten zu analysieren, können bei metrischem Skalenniveau<br />
Häufigkeitsverteilungen durch die Berechnung <strong>von</strong> Mittelwerten <strong>und</strong><br />
Streuungsmaßen komprimiert charakterisiert werden. Das Ziel der univariaten<br />
2<br />
Reliabilität = Zuverlässigkeit der Ergebnisse; Reproduzierbarkeit der Daten; Validität =<br />
inhaltliche Gültigkeit des Gemessenen; Objektivität = Unabhängigkeit der Messergebnisse vom<br />
Untersuchungsleiter<br />
6
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
Datenanalyse ist somit insbesondere eine Datenverdichtung. Bei den bivariaten<br />
Verfahren wird durch die Verknüpfung <strong>von</strong> zwei Variablen versucht,<br />
Zusammenhänge zwischen den Merkmalen in Form <strong>von</strong> Korrelationen oder<br />
Abhängigkeiten aufzudecken oder zu überprüfen. Als Analysemethoden bieten sich<br />
hier unter anderem die Korrelationsanalyse, die Kreuztabellierung sowie die einfache<br />
Regressionsanalyse an.<br />
Abbildung 4: Analyseverfahren in der Primärforschung 3<br />
Quelle: Eigene Darstellung<br />
In der Marktforschung lassen sich jedoch häufig komplexe Zusammenhänge nicht<br />
nur durch die Herauslösung <strong>von</strong> einer bzw. zwei Variablen darstellen. Dieses würde<br />
leicht zu Fehlschlüssen bzw. -interpretationen führen. Aus diesem Gr<strong>und</strong>e besitzt die<br />
multivariate Datenanalyse innerhalb der Primärforschung einen hohen Stellenwert.<br />
Sie ermöglicht entweder die wechselseitigen Beziehungen (Interdependenzanalyse,<br />
Strukturentdeckung) oder die Abhängigkeiten (Dependenzanalyse, Strukturabbildung)<br />
zwischen mehreren Variablen zu analysieren. Das heißt während bei der<br />
3 Die wichtigsten Anwendungsfelder im Marketing sowie die Vorgehensweise der in Abbildung 1<br />
dargestellten Analyseverfahren werden im Anhang durch Abbildung 41 kurz vorgestellt.<br />
7
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
Dependenzanalyse (z. B. Regressionsanalyse) ein kausaler Zusammenhang<br />
unterstellt wird, indem eine Unterteilung in abhängige <strong>und</strong> unabhängige Variablen<br />
geschieht, erfolgt bei der Interdependenzanalyse (z. B. Clusteranalyse) keine<br />
Unterscheidung (BEREKOVEN et al. 1999: 191-204; HERRMANN et al. 1999: 29f.).<br />
Die KNN werden in der Literatur (BACKHAUS 2003: 742; PODDIG et al. 2001: 364),<br />
obwohl sie mehr als zwei Variablen analysieren nicht als spezielles multivariates<br />
Verfahren bezeichnet, sondern können neben den uni-, bi- <strong>und</strong> <strong>multivariaten</strong><br />
Verfahren als eine eigenständige Verfahrensklasse eingeordnet werden. 4<br />
Analysemethoden, die in diese Verfahrensklasse fallen, sind durch Lernfähigkeit, die<br />
Möglichkeit nichtlineare Zusammenhänge darzustellen <strong>und</strong> durch die Fähigkeit, eine<br />
sehr hohe Anzahl an Variablen verarbeiten zu können, charakterisiert (vgl. Kapitel<br />
3.3).<br />
KNN wurden bisher hauptsächlich im Rahmen des Data Mining eingesetzt (vgl.<br />
Kapitel 4.1). Der Terminus Data Mining bezeichnet eine relativ neue Forschungs<strong>und</strong><br />
Anwendungsrichtung. Auf Gr<strong>und</strong> dessen erfolgt auch die Definition dieses<br />
Begriffes in der Literatur auf unterschiedlichste Art <strong>und</strong> Weise. Übergreifend kann<br />
jedoch gesagt werden, dass beim Data Mining anspruchsvolle automatisierte<br />
Methoden (Verfahren der klassischen statistischen Datenanalyse, Anwendungen aus<br />
der künstlichen Intelligenz, der Mustererkennung <strong>und</strong> des maschinellen Lernens) auf<br />
relativ große <strong>und</strong> komplexe Datenvolumina angewendet werden. Das Ziel ist dabei<br />
die entscheidungsrelevanten Informationen aus den Daten zu extrahieren <strong>und</strong> zu<br />
interpretieren (BERRY et al. 2004: 7f.; KÜPPERS 1999: 17-22). 5<br />
Die erforderlichen Daten für den Data Mining-Prozess werden aus dem Data<br />
Warehouse bezogen. Diese Daten wiederum entstammen größtenteils<br />
unternehmensinternen Quellen (z.B. K<strong>und</strong>endaten). Der Data Mining-Prozess<br />
umfasst nach Abbildung 5 sechs Phasen. Erst nach der Aufgabendefinition<br />
(Bestimmung der analytischen Ziele, Modellbildung), Auswahl <strong>und</strong> Aufbereitung der<br />
4 Ein kurzer Überblick über die historische Entwicklung sowie dem Terminus der KNN findet sich<br />
in Kapitel 3.2.1.<br />
5 Die Begriffe „Knowledge Discovery in Database“ (KDD) <strong>und</strong> Data Mining werden <strong>von</strong> den<br />
meisten Autoren synonym verwendet (KÜPPERS 1999: 19; WILDE 2001: 13).<br />
8
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
relevanten Daten (z. B. Transformation <strong>und</strong> Entfernung <strong>von</strong> Ausreißern) erfolgt die<br />
eigentliche Anwendung der Data Mining-Methoden. Dabei stehen dem Anwender<br />
Methoden aus den verschiedensten Gebieten zur Verfügung (Data Mining als<br />
interdisziplinäre Wissenschaft). So können die künstlichen neuronalen Netze der<br />
künstlichen Intelligenz (KI), die Entscheidungsbäume als Element des maschinellen<br />
Lernens <strong>und</strong> die Assoziationsanalysen als eher heuristischer Ansatz betrachtet<br />
werden. Nach der Anwendung der Data Mining-Methoden <strong>und</strong> anschließender<br />
erfolgreicher Evaluation <strong>und</strong> Interpretation der Ergebnisse erfolgt letztlich die<br />
Anpassung des Marketings an die Data Mining-Ergebnisse (WILDE 2001: 14f.). 6<br />
Abbildung 5: Verwendung <strong>von</strong> KNN im Data Mining-Prozess<br />
Quelle: Eigene Darstellung<br />
6 Einen umfassenderen Überblick zum Data Mining zeigen die Autoren BERRY et al. (2004),<br />
KÜPPERS (1999), SÄUBERLICH (2000) <strong>und</strong> WILDE (2001).<br />
9
2 Verwendung <strong>von</strong> statistischen Verfahren in der Primärforschung<br />
Abbildung 5 verdeutlicht den Ansatz dieser Arbeit, KNN, die bislang im Rahmen des<br />
Data Mining-Prozesses Einsatz fanden, direkt auf die in der Primärforschung<br />
erhobenen Daten anzuwenden (gestrichelter Pfeil). 7 Dabei wird jeweils ein<br />
multivariates Verfahren aus der Interdependenz- <strong>und</strong> Dependenzanalyse mit einem<br />
dem Verwendungszweck nach analogen künstlichen <strong>Neuronalen</strong> Netzwerk<br />
verglichen. Entsprechend der Abbildung 6 wird die Regressionsanalyse den Multi-<br />
Layer-Perceptrons (MLP) <strong>und</strong> die Clusteranalyse den Self-Organizing-Maps (SOM)<br />
gegenübergestellt. 8<br />
Abbildung 6: <strong>Vergleich</strong> <strong>von</strong> KNN <strong>und</strong> <strong>multivariaten</strong> Verfahren<br />
Quelle: Eigene Darstellung<br />
Nachdem in den folgenden Kapiteln die methodischen Gr<strong>und</strong>lagen der eben<br />
genannten Verfahren aufgezeigt werden, wird im empirischen Teil untersucht, ob<br />
<strong>und</strong> in wie weit die KNN für die analytische Informationsgewinnung, im Rahmen<br />
des betrieblichen Informationsmanagements, potenzielle Vorteile erbringen können. 9<br />
Die Gr<strong>und</strong>lage für diese Bewertung erfolgt durch die in Kapitel 4.2 aufgezeigten<br />
Gütekriterien.<br />
7 Die Daten unterscheiden sich dabei in der Hinsicht, dass die Primärforschung im Gegensatz zur<br />
Sek<strong>und</strong>ärforschung mehr psychographische Variablen mit einem beschränkten Skalenniveau erhebt.<br />
8 Der praktische Verwendungszweck für die Regressionsanalyse <strong>und</strong> die MLP ist z. B. die<br />
Käuferanalyse, in der die Bestimmungsgründe <strong>von</strong> Kaufentscheidungen analysiert werden (Wirkungs<strong>und</strong><br />
Ursachenanalysen). Das Einsatzgebiet der Clusteranalyse <strong>und</strong> der SOM erfolgt z. B. im Rahmen<br />
des zielgruppenspezifischen Marketings durch Marktsegmentierungen (Clusterung).<br />
9 Das betriebliche Informationsmanagement beinhaltet unter anderem das Management <strong>von</strong><br />
Informationen, Informationssystemen <strong>und</strong> der Informations- <strong>und</strong> Kommunikationstechnologie<br />
(BEREKOVEN et al.1999: 19-48).<br />
10
3 Methodische Gr<strong>und</strong>legung<br />
3 Methodische Gr<strong>und</strong>legung<br />
3.1 Multivariate statistische Verfahren<br />
3.1.1 Überblick über multivariate statistische Verfahren<br />
In der Marktforschung liegen häufig sehr komplexe Zusammenhänge zwischen den<br />
erhobenen Daten vor. Um diese vieldimensionalen Beziehungen zwischen den<br />
Variablen aufzudecken, ist es notwendig, mehr als zwei Variablen gleichzeitig in die<br />
Datenanalysen mit einzubeziehen. Dafür stehen dem Marktforscher verschiedene<br />
multivariate Analyseverfahren zur Verfügung. Diese lassen sich, wie schon in<br />
Kapitel 2.2 aufgezeigt, in struktur-prüfende <strong>und</strong> struktur-entdeckende Verfahren<br />
unterteilen (BEREKOVEN et al. 1999: 202). Bei den struktur-prüfenden Verfahren<br />
unterstellt der Anwender aufgr<strong>und</strong> <strong>von</strong> sachlogischen oder theoretischen<br />
Überlegungen einen kausalen Zusammenhang zwischen den Variablen. Zur<br />
Überprüfung des theoretischen Modells werden die relevanten Variablen in<br />
unabhängige <strong>und</strong> abhängige Variablen eingeteilt <strong>und</strong> mit Hilfe <strong>von</strong> <strong>multivariaten</strong><br />
statistischen Verfahren geprüft. Das Ziel der Analyse besteht darin, den Einfluss der<br />
unabhängigen Variablen auf die abhängigen Variablen zu beschreiben (BACKHAUS et<br />
al. 2003: 7f.). Die gr<strong>und</strong>legenden struktur-prüfenden Verfahren lassen sich nach<br />
ihrem Skalenniveau gemäß Abbildung 7 zuordnen.<br />
Abbildung 7: Gr<strong>und</strong>legende strukturen-prüfende Verfahren<br />
Quelle: BACKHAUS et al. 2003: 8<br />
11
3 Methodische Gr<strong>und</strong>legung<br />
Bei den struktur-entdeckenden Verfahren erfolgt keine Unterteilung in abhängige<br />
<strong>und</strong> unabhängige Variablen. Der Anwender besitzt vor der Analyse keine<br />
Vorstellungen über die wechselseitigen Beziehungen zwischen den Daten. Ziel der<br />
Interdependenzanalyse ist somit unbekannte Zusammenhänge zwischen den<br />
Variablen oder Datenobjekten aufzudecken (BEREKOVEN et al. 1999: 203).<br />
Gr<strong>und</strong>legende struktur-entdeckende Verfahren sind unter anderem die<br />
Faktorenanalyse, die Clusteranalyse, die Multidimensionale Skalierung <strong>und</strong> die<br />
Korrespondenzanalyse. 10<br />
Um in der Marktforschung eine Problemstellung zu lösen, ist es vorteilhaft nicht nur<br />
ein einzelnes multivariates Verfahren zu verwenden, sondern mehrere Methoden<br />
miteinander zu kombinieren. Dieser Methodenmix ermöglicht eine Aggregation der<br />
Stärken jedes einzelnen Verfahrens. Beispielsweise wird die Faktorenanalyse häufig<br />
dafür eingesetzt, eine Vielzahl <strong>von</strong> Variablen auf einige wenige zu reduzieren, damit<br />
anschließend auf Gr<strong>und</strong>lage dieser Dimensionsreduktion eine Clusteranalyse oder<br />
Regressionsanalyse durchgeführt werden kann. 11 Eine ausführliche Betrachtung aller<br />
<strong>multivariaten</strong> Verfahren würde sicherlich den Rahmen dieser Arbeit sprengen,<br />
deshalb wird in den folgenden Kapiteln jeweils nur ein Verfahren aus der<br />
Dependenzanalyse (Regressionsanalyse) <strong>und</strong> Interdependenzanalyse (Clusteranalyse)<br />
näher vorgestellt. 12<br />
3.1.2 Regressionsanalyse<br />
Die Regressionsanalyse ist eines der vielseitigsten <strong>und</strong> am häufigsten eingesetzten<br />
<strong>multivariaten</strong> Analyseverfahren (BACKHAUS et al. 2003: 46). Sie wird verwendet, um<br />
die Beziehungen zwischen einer abhängigen (endogenen, Regressand) <strong>und</strong> einer oder<br />
mehreren unabhängigen (exogenen, Regressoren) Variablen zu analysieren (z. B. der<br />
10 Die wichtigsten Anwendungsfelder im Marketing sowie die Vorgehensweise der aufgezeigten<br />
struktur-entdecken <strong>und</strong> –prüfenden Analyseverfahren werden im Anhang durch Abbildung 41 kurz<br />
vorgestellt.<br />
11 Diese Vorgehensweise erfolgt auch im empirischen Teil dieser Arbeit.<br />
12 Die Varianz-, Diskriminanz- <strong>und</strong> Faktorenanalyse werden zusätzlich als Hilfsverfahren (der<br />
Regressions- <strong>und</strong> Clusteranalyse vor- oder nachgeschoben) im empirischen Teil dieser Arbeit<br />
verwendet. Eine ausführliche Darstellung dieser Verfahren würde jedoch den Rahmen des<br />
methodischen Kapitels sprengen.<br />
12
3 Methodische Gr<strong>und</strong>legung<br />
Einfluss des Preises auf die Nachfrage eines Produktes). Ist eine abhängige Variable<br />
nur <strong>von</strong> einer unabhängigen Variablen beeinflusst, so wird die Beziehung in einer<br />
Einfachregression analysiert. Wird hingegen eine abhängige Variable <strong>von</strong> mehreren<br />
unabhängigen Variablen bestimmt, kann <strong>von</strong> einer Mehrfach- oder auch multiplen<br />
Regression gesprochen werden. Im Folgenden wird die Vorgehensweise bei einer<br />
multiplen linearen Regression in Anlehnung an Abbildung 8 dargestellt (VON AUER<br />
2003: 8; BACKHAUS et al. 2003: 52).<br />
Abbildung 8: Die Ablaufschritte der Regressionsanalyse<br />
Schritt 1<br />
Spezifikation des Modells<br />
• funktional<br />
• Störgröße<br />
• Variablen<br />
A- Annahmen<br />
B- Annahmen<br />
C- Annahmen<br />
Schritt 2<br />
Schätzung des Modells<br />
Schritt 3<br />
Prüfung des geschätzten Modells<br />
Prüfung der<br />
Regressionsfunktion<br />
Prüfung der<br />
Regressionskoeffizienten<br />
Quelle: Eigene Darstellung in Anlehnung an VON AUER 2003: 8; BACKHAUS et al. 2003: 52<br />
Demnach erfolgt zuerst die Spezifikation des Regressionsmodells, welches die<br />
vermutete Ursache-Wirkungs-Beziehung möglichst vollständig enthalten sollte<br />
(BACKHAUS et al. 2003: 52). Prinzipiell geht die multiple lineare Regressionsanalyse<br />
<strong>von</strong> folgendem Gr<strong>und</strong>modell aus: 13<br />
13 Die Notation orientiert sich in diesem Kapitel an BACKHAUS et. al. (2003).<br />
13
3 Methodische Gr<strong>und</strong>legung<br />
Y = b0 + b1X1+ b2X2 + ... + b X + ... + b X<br />
mit<br />
j j J J<br />
Y = Wert der j-ten Beobachtung für die abhängige Variable<br />
b<br />
0<br />
= Konstante der Regressionsfunktion<br />
b<br />
j<br />
= Regressionskoeffizient (j= 1,2,…,J)<br />
X<br />
j<br />
= Wert der unabhängigen Variablen (j= 1,2,…,J)<br />
(1)<br />
Das lineare Regressionsmodell unterliegt dabei wichtigen gr<strong>und</strong>legenden Annahmen<br />
bzw. Prämissen, die erforderlich sind, um im zweiten Schritt, der Schätzung des<br />
Modells, die wahren unbekannten Parameter zu ermitteln (VON AUER 2003: 15).<br />
Tabelle 1 fasst die wichtigsten Prämissen, die Konsequenzen der Verletzung <strong>und</strong> die<br />
Überprüfung der Annahmen zusammen. Die A-Annahmen beziehen sich auf die<br />
funktionelle Spezifikation des Regressionsmodells. Dieses beinhaltet vor allem, dass<br />
alle relevanten <strong>und</strong> keine irrelevanten unabhängigen Variablen in die Gleichung (1)<br />
aufgenommen werden. Ebenfalls verdeutlicht Formel (1), dass der wahre<br />
Zusammenhang zwischen Y <strong>und</strong> den unabhängigen Variablen X j linear sein soll. Es<br />
ist jedoch auch möglich, nicht-lineare Zusammenhänge in lineare zu transformieren,<br />
z. B. im Falle einer multiplikativen Verknüpfung durch Logarithmieren (RUDOLPH<br />
1998: 43; VON AUER 2003: 277-299). Die B-Annahmen beziehen sich auf die<br />
Residuen bzw. die Störgröße. Die Residuen entsprechen nach Formel (2) der<br />
Abweichung der tatsächlich beobachteten Werte <strong>von</strong> den Schätzwerten (BACKHAUS<br />
et al. 2003: 56).<br />
e = y − $ y<br />
k = 1,2,..., K<br />
k k k<br />
mit<br />
e<br />
k<br />
= Abweichung des Schätzwertes vom Beobachtungswert<br />
(2)<br />
y<br />
k<br />
= Beobachtungswert der abhängigen Variablen Y für x k<br />
$ y<br />
k<br />
= ermittelter Schätzwert <strong>von</strong> Y für x k<br />
K = Zahl der Beobachtungen<br />
Eine Verletzung der B-Annahmen kann unter anderem zu Heteroskedastizität oder zu<br />
Autokorrelation führen. Heteroskedastizität liegt vor, wenn die Streuung der<br />
Residuen keine gleich bleibende Varianz aufweist. Autokorrelation ist gegeben,<br />
14
3 Methodische Gr<strong>und</strong>legung<br />
wenn die Residuen in der Gr<strong>und</strong>gesamtheit untereinander korrelieren (VON AUER<br />
2003: 353-404).<br />
A2: Linearität in den<br />
Parametern<br />
A3: Die Parameter sind<br />
für alle Beobach–<br />
tungen konstant<br />
B1: Erwartungswert<br />
der Störgröße<br />
gleich null<br />
B2: Homoskedastizität<br />
der Störgröße<br />
B3: Freiheit <strong>von</strong><br />
Autokorrelation<br />
B4: Normalverteilung<br />
der Störgröße<br />
C1: Keine lineare<br />
Abhängigkeit<br />
zwischen den<br />
unabhängigen<br />
Variablen<br />
Nichtlinearität<br />
verzerrte oder<br />
falsche Schätzer<br />
Überprüfung<br />
t-Test<br />
F-Test<br />
(korrigiertes R²)<br />
(graphische<br />
Analyse)<br />
Box-Cox-Test<br />
Strukturbruch falsches Modell F-Test<br />
Chow-Test<br />
Autokorrelation<br />
Störgröße nicht<br />
normalverteilt<br />
Perfekte<br />
Multikollinearität<br />
verzerrte<br />
Schätzer<br />
ineffiziente<br />
Schätzer<br />
ineffiziente<br />
Schätzer<br />
Ungültige<br />
Signifikanztests<br />
(F-Test, t-Test)<br />
bei N < 40<br />
Verminderte<br />
Präzision der<br />
Schätzwerte<br />
während der<br />
Datenerhebung<br />
Tabelle 1: Annahmeverletzungen des linearen Regressionsmodells<br />
Annahme Annnahmeverletzung<br />
Konsequenzen<br />
A1: Vollständigkeit Unvollständigkeit<br />
verzerrte oder<br />
des Modells<br />
ineffiziente<br />
(Berücksichtigung<br />
Schätzer<br />
aller relevanten<br />
Variablen)<br />
Erwartungswert<br />
der Störgröße <strong>von</strong><br />
null verschieden<br />
Heteroskedastizität<br />
Goldfeld-Quandt-<br />
Test<br />
White-Test<br />
Durbin-Watson-<br />
Test<br />
Graphische<br />
Analyse<br />
Jarque-Bera-Test<br />
Korrelationsmatrix<br />
Regression<br />
zwischen den<br />
erklärenden<br />
Variablen<br />
Variance Inflation<br />
Factor<br />
Quelle: Eigene Darstellung in Anlehnung an BACKHAUS et al. 2003: 92;VON AUER 2003: 237- 486<br />
Die C-Annahmen beziehen sich auf die Eigenschaften der unabhängigen Variablen.<br />
Wenn diese z. B. untereinander lineare Abhängigkeiten aufweisen, also korrelieren,<br />
liegt das Problem der Multikollinearität vor (ebd.: 461-487). In diesem Fall ist der<br />
Einfluss der exogenen Variablen auf die endogene Variable nicht mehr eindeutig<br />
zurechenbar (ebd.). Als Konsequenz der Prämissenverletzungen kann es zu<br />
15
3 Methodische Gr<strong>und</strong>legung<br />
verzerrten oder ineffizienten Schätzern kommen (vgl. Tabelle 1). Ein Schätzer ist<br />
unverzerrt (erwartungstreu), wenn die aus wiederholten Stichproben ermittelten<br />
Regressionskoeffizienten im Mittel den wahren Wert aus der Gr<strong>und</strong>gesamtheit<br />
treffen (BACKHAUS et al. 2003: 79). Wenn ein unverzerrter Schätzer innerhalb der<br />
Gruppe der unverzerrten Schätzer die kleinste Streuung aufweist, ist er effizient<br />
(ebd.). Die unter dem zweiten Schritt erklärte Kleinstquadratmethode (KQ-Methode,<br />
englisch: Ordinary Least Squares, OLS) liefert unter den getroffenen A-, B- <strong>und</strong> C-<br />
Annahmen (ohne B4-Annahme) Regressionskoeffizienten, die innerhalb der Klasse<br />
der unverzerrten linearen Schätzern effizient sind. Dieser Zusammenhang wird als<br />
das Gauss-Markov-Theorem bezeichnet (BLEYMÜLLER et al. 2002: 150). 14 In der<br />
Praxis werden die Prämissen des Modells häufig erst nach der Prüfung des<br />
geschätzten Modells kontrolliert. Ohne vorherige Prüfung der Prämissen dürften<br />
jedoch streng genommen, nach dem Gauss-Markov-Theorem, der F- <strong>und</strong> t-Test nicht<br />
angewandt werden (HOFFMANN 2004: 40). 15<br />
Nach der Spezifikation des Regressionsmodells wird im zweiten Schritt (vgl.<br />
Abbildung 8) mit Hilfe der KQ-Methode die Ermittlung der Schätzwerte für die<br />
Regressionskoeffizienten vorgenommen. Dabei werden die Parameter so gewählt,<br />
dass die Summe der quadrierten Residuen minimiert wird (FAHRMEIR et al. 2003:<br />
478; BACKHAUS et al. 2003: 60):<br />
( ) 2<br />
⎤<br />
0 1 1 2 2<br />
K K<br />
2<br />
∑ek ∑ ⎡<br />
⎣<br />
yk b bx<br />
k<br />
b x<br />
k<br />
bjxj bJxJ<br />
k= 1 k=<br />
1<br />
mit<br />
= − + + + ... + + ... +<br />
⎦<br />
→ min<br />
e<br />
k<br />
= Wert der Residualgröße (k=1,2,…,K)<br />
y<br />
k<br />
= Wert der abhängigen Variablen (k=1,2,…,K)<br />
b<br />
0<br />
= Konstante der Regressionsfunktion<br />
b<br />
j<br />
= Regressionskoeffizient (j= 1,2,…,J)<br />
x<br />
jk<br />
= Wert der unabhängigen Variablen (j= 1,2,…,J; k=1,2,…,K)<br />
J = Zahl der unabhängigen Variablen<br />
K = Zahl der Beobachtungen<br />
(3)<br />
14 Im Englischen auch als BLUE (Best Linear Unbiased Estimator) ausgedrückt (ebd.).<br />
15 Für tiefer greifende Betrachtungen in die Regressionsanalyse, besonders in Bezug auf die Überprüfung<br />
der Annahmen, sei auf die Literatur <strong>von</strong> BACKHAUS et al. (2003: 77-104), BROSIUS et al.<br />
(1996: 488-497), BLEYMÜLLER et al. (2002: 139-179) <strong>und</strong> VON AUER (2003: 237-486) verwiesen.<br />
16
3 Methodische Gr<strong>und</strong>legung<br />
Im letzten Schritt (vgl. Abbildung 8) wird die Qualität bzw. die Güte des geschätzten<br />
Modells überprüft. Neben der globalen Prüfung des Regressionsmodells erfolgt auch<br />
eine Kontrolle der einzelnen Regressionskoeffizienten. (BACKHAUS et al. 2003: 63).<br />
Bei der globalen Prüfung wird untersucht, wie gut die unabhängigen Variablen die<br />
abhängige Variable erklären können. Die Kontrolle der einzelnen<br />
Regressionskoeffizienten hingegen überprüft, wie gut jede einzelne exogene Variable<br />
zur Erklärung der endogenen Variablen beiträgt (ebd.). Am häufigsten wird zur<br />
Prüfung der Erklärungskraft der Regressionsfunktion das Bestimmtheitsmaß<br />
verwendet. Dieses Maß berechnet, wieviel der Gesamtvarianz durch die<br />
Regressionsgleichung erklärt werden kann (ebd.: 66):<br />
R<br />
K<br />
2<br />
$<br />
∑( yk<br />
− y)<br />
k =<br />
= =<br />
K<br />
2<br />
y − y<br />
2 1<br />
∑<br />
k = 1<br />
( k )<br />
erklärte Streuung<br />
Gesamtstreuung<br />
(4)<br />
Das Bestimmtheitsmaß R² ist jedoch kritisch zu sehen, denn mit jeder hinzugefügten<br />
exogenen Variablen wird der Erklärungsanteil, der möglicherweise nur zufällig<br />
bedingt ist, <strong>und</strong> somit der Wert des Bestimmtheitsmaßes, zunehmen (VON AUER<br />
2003: 252). Damit der Wert des Maßes nicht auch bei der Aufnahme einer<br />
irrelevanten Variablen (vgl. Annahme-A1) steigt, sollte das korrigierte<br />
Bestimmtheitsmaß, (englisch: adjusted R-squared) welches diesen Zusammenhang<br />
berücksichtigt, verwendet werden (BACKHAUS et al. 2003: 67):<br />
R<br />
2 2<br />
korr<br />
mit<br />
2<br />
( 1−<br />
R )<br />
J<br />
= R −<br />
K −J<br />
−1<br />
J = Zahl der Regressoren<br />
K −J −1 = Zahl der Freiheitsgrade<br />
K = Zahl der Beobachtungswerte<br />
(5)<br />
Um die Gültigkeit des Regressionsmodells auch in der Gr<strong>und</strong>gesamtheit zu<br />
gewähren, wird als weiteres Gütemaß zur globalen Prüfung der Regressionsfunktion<br />
17
3 Methodische Gr<strong>und</strong>legung<br />
der F-Test verwendet (ebd.: 68). Besonders wenn das Regressionsmodell nur<br />
aufgr<strong>und</strong> einer geringen Stichprobengröße geschätzt wird, erweist sich dieser Test als<br />
Gewähr für die Gültigkeit des Modells in der Gr<strong>und</strong>gesamtheit (ebd.). Um diesen<br />
Test jedoch anwenden zu können, wird die geschätzte Regressionsfunktion (vgl.<br />
Formel (1)) zunächst als eine stochastische Funktion mit dem Term der Störgröße<br />
dargestellt (vgl. Formel (6)). Es handelt sich dabei um eine stochastische Funktion,<br />
da sowohl β 0 , β j , u <strong>und</strong> Y Zufallsvariablen sind (BACKHAUS et al. 2003: 69, VON<br />
AUER 2003: 68).<br />
Y = β0 + β1X1+ β2X2 + ... + β<br />
jX j<br />
+ ... + βJXJ<br />
+ u<br />
mit<br />
Y = Abhängige Variable<br />
β<br />
0<br />
= Konstantes Glied der Regressionsfunktion<br />
β<br />
j<br />
= Regressionskoeffizient (j= 1,2,…,J)<br />
X<br />
j<br />
= Unabhängige Variable (j= 1,2,…,J)<br />
u = Störgröße<br />
(6)<br />
Die Nullhypothese des F-Tests besagt, dass keiner der Regressionskoeffizienten zur<br />
Erklärung der abhängigen Variablen beiträgt (FAHRMEIER et al. 2003: 498):<br />
H0 β1 β2<br />
β J<br />
: = = ... = = 0<br />
Der empirische F-Wert F emp berechnet sich aus dem Verhältnis der erklärten zu der<br />
nicht erklärten Streuung jeweils dividiert durch die Zahl der Freiheitsgrade<br />
(BACKHAUS et al. 2003: 70):<br />
F<br />
emp<br />
K<br />
2<br />
$<br />
∑( yk<br />
− y)<br />
J<br />
k = 1<br />
erklärte Streuung J<br />
= =<br />
K<br />
2<br />
$<br />
nicht erklärte Streuung K − J −1<br />
y − y K −J<br />
−1<br />
∑<br />
k = 1<br />
( k k )<br />
(7)<br />
Wenn der empirische F-Wert größer ist als der theoretische F-Wert, kann die<br />
Nullhypothese abgelehnt werden. In diesem Fall liegt zumindest ein signifikanter<br />
kausaler Zusammenhang zwischen einer exogenen <strong>und</strong> der endogenen Variablen in<br />
18
3 Methodische Gr<strong>und</strong>legung<br />
der Gr<strong>und</strong>gesamtheit vor (HOFFMANN 2004: 38). Der theoretische F-Wert ergibt sich<br />
mit dem gewählten Signifikanzniveau aus der F-Verteilung <strong>und</strong> kann aus der F-<br />
Tabelle 16 entnommen werden. Das als letztes für die Prüfung der<br />
Regressionsfunktion vorgestellte Gütemaß ist der Standardfehler der Schätzung.<br />
Dieses Maß gibt an, welcher mittlere Fehler aus der Anwendung der<br />
Regressionsfunktion zur Schätzung der endogenen Variablen resultiert (BACKHAUS<br />
et al. 2003: 73):<br />
s =<br />
∑ K<br />
k = 1<br />
e<br />
2<br />
k<br />
( K −J<br />
−1)<br />
(8)<br />
Nach der globalen Prüfung der Regressionsfunktion erfolgt die Überprüfung der<br />
einzelnen Regressionskoeffizienten. Während der F-Test in der Nullhypothese<br />
überprüft, dass alle Regressionskoeffizienten gleich null sind, wird analog mit dem<br />
t-Test jeder einzelne Koeffizient geprüft (ebd.):<br />
H : 0<br />
0<br />
β<br />
j<br />
=<br />
Der empirische t-Wert einer exogenen Variablen wird durch die Division des<br />
betreffenden Regressionskoeffizienten durch dessen Standardfehler ermittelt (ebd.:<br />
74):<br />
t<br />
emp<br />
bj<br />
− β<br />
j<br />
=<br />
s<br />
bj<br />
(9)<br />
mit<br />
t<br />
emp<br />
= Empirischer t-Wert für den j-ten Regresssor<br />
β<br />
j<br />
= Wahrer Regressionskoeffizient (unbekannt)<br />
b<br />
j<br />
= Regressionskoeffizient des j-ten Regressors<br />
s<br />
bj<br />
= Standardfehler <strong>von</strong> b<br />
j<br />
16 F- sowie eine t-Tabelle sind unter anderem in den meisten statistischen Lehrbüchern auffindbar.<br />
19
3 Methodische Gr<strong>und</strong>legung<br />
Ist der empirische t-Wert größer als der theoretische t-Wert, kann die Nullhypothese<br />
abgelehnt werden. Demnach existiert dann ein signifikanter Zusammenhang<br />
zwischen der unabhängigen Variablen <strong>und</strong> der abhängigen Variablen in der<br />
Gr<strong>und</strong>gesamtheit (FAHRMEIR et al. 2003: 497). Der theoretische t-Wert ergibt sich<br />
mit dem gewählten Signifikanzniveau aus der Student-t-Verteilung <strong>und</strong> kann aus der<br />
t-Tabelle 16 entnommen werden. Zusätzlich zum t-test gibt das Konfidenzintervall den<br />
Bereich an, in dem sich der wahre Wert des Regressionskoeffizienten in der<br />
Gr<strong>und</strong>gesamtheit befinden könnte (BACKHAUS et al. 2003: 76):<br />
b −t s ≤ β ≤ b + t s<br />
mit<br />
j bj j j bj<br />
t<br />
emp<br />
= t-Wert aus der Student-Verteilung<br />
β<br />
j<br />
= Wahrer Regressionskoeffizient (unbekannt)<br />
b<br />
j<br />
= Regressionskoeffizient der Stichprobe<br />
s<br />
bj<br />
= Standardfehler <strong>von</strong> Regressionskoeffizienten<br />
(10)<br />
Je größer das Konfidenzintervall ist, desto unsicherer ist die Schätzung des<br />
betreffenden Regressionskoeffizienten auf die Gr<strong>und</strong>gesamtheit übertragbar (ebd.:<br />
77). Anhand der Regressionskoeffizienten ist es möglich, den marginalen<br />
Zusammenhang zwischen den exogenen Variablen <strong>und</strong> der endogenen Variablen<br />
inhaltlich zu interpretieren (ebd.: 61). Ein <strong>Vergleich</strong> zwischen den Regressoren in<br />
Bezug auf die Einflussstärke auf den Regressanden ist allerdings nur dann möglich,<br />
wenn die unabhängigen Variablen ein gleiches Messniveau aufweisen (ebd.:). Sollte<br />
dieses jedoch nicht vorliegen, so können die Regressionskoeffizienten nach einer<br />
Standardisierung verglichen werden (BACKHAUS et al. 2003: 76; HOFFMANN 2004:<br />
40) 17 :<br />
b$<br />
j<br />
= b<br />
j<br />
Standardabweichung <strong>von</strong> X<br />
Standardabweichung <strong>von</strong> Y<br />
j<br />
(11)<br />
17 Die Standardabweichung berechnet sich wie folgt (BACKHAUS et al. 2003: 62):<br />
s<br />
x<br />
=<br />
K<br />
∑<br />
k = 1<br />
( x ) 2<br />
k<br />
− x<br />
K − 1<br />
20
3 Methodische Gr<strong>und</strong>legung<br />
Diese standardisierten Regressionskoeffizienten werden auch als Beta-Werte<br />
bezeichnet (BACKHAUS et al. 2003: 61). Im nachstehenden letzten Abschnitt über das<br />
multivariate Verfahren der Regressionsanalyse werden kurz deren Schwächen <strong>und</strong><br />
Stärken diskutiert.<br />
Ein optimales Einsetzen der Regressionsanalyse erfordert bereits im Vorfeld, dass<br />
die Art der Beziehungen zwischen der abhängigen Variablen <strong>und</strong> den Unabhängigen<br />
klar ist. Diese Zusammenhänge erweisen sich aber oft als sehr komplex <strong>und</strong> sind<br />
dementsprechend nur schlecht als lineares Model darzustellen. Es ergibt sich zwar,<br />
wie schon oben angesprochen, die Möglichkeit der Linearisierung, jedoch reicht<br />
auch diese oft nicht aus. Denn bei vielen Fragestellungen, insbesondere im<br />
Marketing, ist die endogene Variable binär (dichotom oder zweiwertig) ausgeprägt.<br />
Als Beispiel dafür sei der Kauf bzw. Nichtkauf eines Produktes genannt. Die<br />
Regressionsanalyse kann in diesem Fall nicht verwendet werden, da die Residuen<br />
nicht normalverteilt sind <strong>und</strong> somit die Annahme-B4 verletzt ist (MEYER 2002: 198).<br />
Als Analyseverfahren bieten sich daher im Fall einer binären abhängigen Variablen<br />
die logistische Regressionsanalyse <strong>und</strong> die Diskriminanzanalyse an (BACKHAUS et al.<br />
2003: 418). Praktische <strong>und</strong> wissenschaftliche Fragestellungen, die komplexere<br />
kausale Abhängigkeiten zwischen bestimmten Variablen aufweisen, können<br />
konfirmatorisch, mit Hilfe <strong>von</strong> Strukturgleichungen im Rahmen <strong>von</strong> Kausalanalysen,<br />
untersucht werden (ebd.: 334). 18 Die statistische Stärke des Regressionsmodells ist<br />
eine umfassende theoretische F<strong>und</strong>ierung mit zahlreichen Erweiterungen <strong>und</strong><br />
Spezialfällen. Deshalb setzt sie ein umfangreiches anwenderbasiertes Wissen voraus.<br />
So werden z. B. Ausreißer bei der Gewichtung der einzelnen Regressionskoeffizienten<br />
durch die quadratische Minimierung der Abweichungen (KQ-Methode)<br />
zu stark bewertet. Demnach ist gegebenenfalls eine Voranalyse der Datenbasis<br />
erforderlich. Letztendlich ist die Regressionsanalyse jedoch mathematisch <strong>und</strong><br />
sachlogisch einfach nachzuvollziehen <strong>und</strong> die Ergebnisse sind leicht zu<br />
interpretieren.<br />
18 Weiterführende Betrachtungen über die eben genannten <strong>multivariaten</strong> Verfahren enthalten z. B.<br />
BACKHAUS et al. (2003) <strong>und</strong> JANSEN et al. (2003).<br />
21
3 Methodische Gr<strong>und</strong>legung<br />
3.1.3 Clusteranalyse<br />
Während die Regressionsanalyse als struktur-prüfendes Verfahren die Beziehungen<br />
zwischen den Variablen aufzeigt, betrachtet die Clusteranalyse als strukturentdeckendes<br />
Verfahren die Beziehungsstrukturen zwischen den Objekten. Das Ziel<br />
der Clusteranalyse besteht darin, Gruppen (bzw. Cluster, Klassen, Typen) zu bilden,<br />
in denen die durch eine Anzahl <strong>von</strong> Variablen beschriebenen Objekte möglichst<br />
homogen sind. Objekte aus unterschiedlichen Gruppen sollten hingegen möglichst<br />
heterogen sein (BACHER 1996: 1-3). Der Einsatz der Clusteranalyse in der<br />
Primärforschung erfolgt z. B. zur Marktstrukturierung, Marktsegmentierung <strong>und</strong><br />
Konsumententypologisierung.<br />
Abbildung 9: Die Ablaufschritte der Clusteranalyse<br />
Schritt 1<br />
Auswahl <strong>von</strong> Variablen<br />
Schritt 2<br />
Wahl des Proximitätsmaßes<br />
Schritt 3<br />
Wahl des Clusteralgorithmus<br />
Schritt 4<br />
Bestimmung der Clusteranzahl<br />
Schritt 5<br />
Clusterzentrenanalyse<br />
Schritt 6<br />
Prüfung der Clusteranalyse<br />
externe<br />
Prüfung<br />
interne<br />
Prüfung<br />
relative<br />
Prüfung<br />
Schritt 7<br />
Interpretation der Cluster<br />
Quelle: Eigene Darstellung<br />
22
3 Methodische Gr<strong>und</strong>legung<br />
Die Literatur (unter anderem BACHER 1996; BACKHAUS et al. 2003; BORTZ 2005;<br />
GIERL et al. 2001; JANSEN et al. 2003) beschreibt die Vorgehensweise bei der<br />
Clusteranalyse besonders in Bezug auf die Gütekriterien zum Teil sehr<br />
unterschiedlich. In Anlehnung an Abbildung 9 wird deshalb im Folgenden die<br />
Vorgehensweise der Clusteranalyse, wie sie im Rahmen dieser Arbeit durchgeführt<br />
wird, vorgestellt.<br />
Der erste Schritt, die Auswahl der clusterbildenden Variablen (Inputvariablen, aktive<br />
Variablen), anhand derer die Zuordnung der Objekte zu den Clustern resultiert, ist als<br />
das ausschlaggebende Kriterium für den Erfolg der Analyse anzusehen. 19 Es sollten<br />
demnach nur die theoretisch relevanten Variablen für die Analyse ausgewählt<br />
werden (BACKHAUS et al. 2003: 537). 20 Bei Datensätzen mit sehr vielen Variablen<br />
bietet eine vorgeschobene Faktorenanalyse häufig die Möglichkeit eine größere<br />
Anzahl <strong>von</strong> miteinander korrelierten Variablen auf einige wenige Faktoren zu<br />
reduzieren. Diese Faktoren können dann anschließend als Inputvariablen verwendet<br />
werden (BACHER 1996: 126; BACKHAUS et al. 2003: 538; JANSEN et al. 2003: 437f.). 21<br />
Nach GIERL et al. (2001: 130) wird die Anzahl der clusterbildenden Variablen in der<br />
Literatur meistens auf vier bis acht beschränkt.<br />
Durch die Festlegung eines Proximitätsmaßes werden im zweiten Schritt der<br />
Clusteranalyse die Distanzen (Unterschiede) bzw. die Ähnlichkeiten<br />
(Übereinstimmungen) zwischen den zu gruppierenden Objekten numerisch<br />
ausgedrückt. Das allgemein gebräuchlichste, wie auch für die meisten<br />
Clusteralgorithmen am besten geeignete Proximitätsmaß, ist die „quadrierte<br />
Euklidische Distanz“ (BORTZ 2005: 569; GIERL et al. 2001: 865):<br />
K<br />
∑ ( ij i´j )<br />
2<br />
D = x −x<br />
j1 =<br />
2<br />
(12)<br />
19 Variablen, die nicht in der Clusterbildung Verwendung fanden, werden als passive Variablen<br />
bezeichnet.<br />
20 BACHER (1996: 410-412) <strong>und</strong> BERGS (1980: 51-62) zeigen eine umfassendere Beschreibung zur<br />
Auswahl der clusterbildenden Variablen auf.<br />
21 Eine Übersicht über die Faktorenanalyse zeigen z. B. BACKHAUS et al. (2003); BORTZ (2005);<br />
BROSIUS et al. (1996) <strong>und</strong> JANSEN et al. (2003).<br />
23
3 Methodische Gr<strong>und</strong>legung<br />
mit:<br />
2<br />
D = quadrierte Euklidische Distanz<br />
x<br />
ij<br />
(x<br />
i´j) = Merkmalsausprägung des Objektes ei<br />
i´<br />
(x ) auf dem Merkmal j<br />
Diese Quantifizierung dient als Ausgangspunkt für den sich anschließenden Clusterbzw.<br />
Fusionierungsalgorithmus (Clusterverfahren) (BROSIUS et al. 1996: 865). In der<br />
Literatur (BACHER 1996; BACKHAUS et al. 2003: 480-542; BERGS 1980;<br />
VAZIRGIANNIS et al. 2003; WEDEL et al. 2003) finden sich eine Vielzahl <strong>von</strong><br />
unterschiedlichen Algorithmen. Abbildung 10 gibt deshalb nur einen Überblick über<br />
die in dieser Arbeit verwendeten Clusteralgorithmen. Neben den <strong>multivariaten</strong><br />
Verfahren bieten auch die KNN (Self-Organizing-Maps) die Möglichkeit eine<br />
Clusterung durchzuführen (vgl. Kapitel 3.2.4). Bei den <strong>multivariaten</strong> statistischen<br />
Verfahren unterscheidet man die Gruppierungsalgorithmen in hierarchische <strong>und</strong><br />
partitionierende Verfahren.<br />
Abbildung 10: Überblick über ausgewählte Clusteralgorithmen<br />
Clusterverfahren<br />
Multivariate Verfahren<br />
Künstliche Neuronale<br />
Netze<br />
Partitionierende<br />
Verfahren<br />
Hierarchische<br />
Verfahren<br />
Self Organzing<br />
Maps<br />
K-Means<br />
Single-<br />
Linkage<br />
Ward<br />
Quelle: Eigene Darstellung in Anlehnung an PETERSOHN 1999: 553<br />
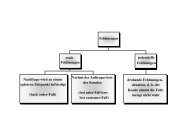
Die hierarchischen agglomerativen Verfahren beginnen mit der feinsten<br />
Objektgruppierung, d.h. jedes Objekt bzw. Fall bildet ein eigenes Cluster,<br />
24
3 Methodische Gr<strong>und</strong>legung<br />
schrittweise werden diese dann zu immer umfangreicheren Clustern<br />
zusammengefasst (WEDEL et al. 2003: 48-50). 22 Während das Single-Linkage<br />
Verfahren (oder auch Nearest-Neighbour-Verfahren) die Objekte (Gruppen)<br />
vereinigt, die die kleinste Distanz zueinander aufweisen, werden beim Ward-<br />
Verfahren diejenigen Gruppen fusioniert, die ein vorgegebenes Heterogenitätsmaß,<br />
die Fehlerquadratsumme (Varianzkriterium), am geringsten erhöhen (BORTZ 2005:<br />
575). 23 In Abbildung 11 werden die Fusionierungsschritte, bei der Ward-Methode,<br />
bezogen auf die Fehlerquadratsumme (standardisiert <strong>von</strong> 0 bis 25), graphisch für<br />
jedes Objekt (1-8) in Form eines Dendogramms dargestellt.<br />
Abbildung 11: Dendogramm für ein hierarchisches Clusterverfahren 24<br />
Quelle: Eigene Darstellung<br />
Unter die partitionierenden Verfahren fällt der K-Means-Algorithmus<br />
(Clusterzentrenanalyse). Dieser unterscheidet sich <strong>von</strong> den hierarchischen Verfahren<br />
dadurch, dass zunächst eine vorgegebene oder zufällige Startpartition durch iteratives<br />
Verschieben <strong>von</strong> Objekten zwischen den Clustern solange verbessert wird, bis sich<br />
jedes Objekt in einer Gruppe befindet, zu dessen Schwerpunkt (Mittelpunkt) es, im<br />
22<br />
Man unterscheidet zwischen hierarchisch-divisiven Verfahren <strong>und</strong> hierarchischenagglomerativen<br />
Verfahren. Die hierarchisch-divisiven Clusteralgorithmen beginnen mit der gröbsten<br />
Partition, bei der alle Objekte in einem Cluster zusammengefasst sind (WEDEL et al. 2003: 50).<br />
23<br />
Bei der Fusionierung zweier Gruppen im Ward-Algorithmus, entspricht die quadrierte<br />
Euklidische Distanz genau dem doppelten der Fehlerquadratsumme (BACKHAUS et al. 2003: 512).<br />
24 Einen Überblick über den Ablauf der Fusionierungsschritte innerhalb eines Dendogramms zeigt<br />
unter anderem BACKHAUS et al. (2004: 506-524), BROSIUS et al. (1996: 875-877) <strong>und</strong> PETERSOHN<br />
(1997: 118-120).<br />
25
3 Methodische Gr<strong>und</strong>legung<br />
<strong>Vergleich</strong> zu den übrigen Gruppen, die geringste Distanz aufweist (BORTZ 2005: 578;<br />
VAZIRGIANNIS et al. 2003: 25). Dieses Verfahren hat gegenüber den hierarchischen<br />
Methoden den Vorteil, dass eine Neuzuordnung der Objekte (Fälle) jederzeit möglich<br />
ist (GIERL et al. 2001: 131; GRABMEIER 2001: 329-332). Der Nachteil dieses<br />
Verfahrens liegt jedoch darin, dass man vor der Analyse die Struktur des Datensatzes<br />
<strong>und</strong> somit die Startpartitionen <strong>und</strong> die Clusteranzahl nicht kennt. Deshalb ist es nach<br />
BORTZ (2005: 575), JANSEN et al. (2003: 433) <strong>und</strong> WIEDENBECK et al. (2001: 14)<br />
vorteilhaft, zunächst mit dem Ward-Algorithmus die Anfangspartitionen zu<br />
berechnen <strong>und</strong> dann mit der K-Means-Methode das Ergebnis zu optimieren. Um die<br />
Anfälligkeit des Ward-Verfahrens bei der Gruppierung der Objektmenge gegenüber<br />
Ausreißern, welche den Fusionierungsprozess negativ beeinflussen, zu mindern,<br />
empfiehlt es sich, diese zunächst mit dem Single-Linkage-Algorithmus zu<br />
identifizieren <strong>und</strong> dann anschließend zu entfernen (BACKHAUS et al. 2003: 537;<br />
KÖNIG 2001: 110). 25 Demnach ergibt sich, in Bezug auf die Wahl der<br />
Fusionierungsalgorithmen, nachstehender Ablauf der Clusteranalyse: 26<br />
1. Single-Linkage-Methode (zur Eliminierung der Ausreißer)<br />
2. Ward-Methode (zur Bestimmung <strong>von</strong> Startpartitionen)<br />
3. K-Means (zur Bestimmung der optimalen Endpartitionen)<br />
Die Bestimmung der optimalen Clusteranzahl (vgl. Abbildung 9) ist innerhalb der<br />
hierarchischen <strong>und</strong> partitionierenden Verfahren nicht automatisiert. Die<br />
Entscheidung sollte deshalb aufgr<strong>und</strong> <strong>von</strong> mathematisch-statistischen <strong>und</strong><br />
interpretationsbezogenen Kriterien erfolgen (KÖNIG 2001: 112). Als mathematischstatistische<br />
Verfahren können das Dendogramm sowie das Scree-Test-Diagramm<br />
verwendet werden (ebd.: 522- 524). 27 Der Scree-Test (vgl. Abbildung 12) basiert<br />
gegenüber dem Dendogramm auf einem Koordinatensystem, auf dem die<br />
25 „Ausreißer sind Objekte, die im <strong>Vergleich</strong> zu den übrigen Objekten eine vollkommen anders<br />
gelagerte Kombination der Merkmalsausprägungen aufweisen <strong>und</strong> dadurch <strong>von</strong> allen andern Objekten<br />
weit entfernt liegen“ (BACKHAUS et al. 2003: 537).<br />
26 Einen umfassenderen Überblick über die Proximitätsmaße <strong>und</strong> Algorithmen der Clusteranalyse<br />
zeigen unter anderem BACHER (1996); BACKHAUS et al. (2003); BERGS (1980); VAZIRGIANNIS et al.<br />
(2003); <strong>und</strong> WEDEL et al. (2003).<br />
27 Einen Überblick über weitere statistisch-mathematische Kriterien, die jedoch nicht in dieser<br />
Arbeit verwendet werden, zeigen unter anderem BORTZ (2005: 576-578); GIERL et al. (2001: 134f.);<br />
WEDEL et al. (2003: 91-93) <strong>und</strong> TIBSHIRANI (2000).<br />
26
3 Methodische Gr<strong>und</strong>legung<br />
Clusteranzahl gegen die Entwicklung der Fehlerquadratsumme abgetragen wird<br />
(BORTZ 2005: 576 f.).<br />
Abbildung 12: Scree-Test zur Bestimmung der Clusteranzahl<br />
450<br />
400<br />
Fehlerquadratsumme<br />
350<br />
300<br />
250<br />
200<br />
150<br />
100<br />
„Elbow“<br />
50<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15<br />
Anzahl der Cluster<br />
Quelle: Eigene Darstellung in Anlehnung an BACKHAUS et al. 2003: 524; BERGS 1980: 102<br />
Die Heterogenitätszuwächse (Fehlerquadratsummen) nehmen mit sinkender<br />
Clusteranzahl <strong>und</strong> durch die Fusion immer heterogenerer Cluster überproportional<br />
zu. Dort, wo der Graph vor dem überproportionalen Anstieg einen deutlichen Knick<br />
(Elbow) aufweist, liegt bei der gegebenen Objektmenge die optimale Clusteranzahl<br />
vor (ebd.). BERGS (1980: 97) zeigte, dass der Scree-Test (oder auch das Elbow-<br />
Kriterium) bei den hierarchischen Algorithmen vor allem beim Ward-Verfahren die<br />
richtige Clusteranzahl signalisiert. Da jedoch dieser Knick nicht immer graphisch zu<br />
identifizieren ist, kann eine Tabelle mit den Koeffizienten (Fehlerquadratsummen)<br />
bei den einzelnen Fusionierungsschritten weiteren Aufschluss über die optimale<br />
27
3 Methodische Gr<strong>und</strong>legung<br />
Gruppenanzahl geben. 28 Das Dendogramm kann parallel zum Scree-Test bei der<br />
Bestimmung der optimalen Gruppenanzahl verwendet werden. Es wird allerdings mit<br />
zunehmender Stichprobengröße immer unübersichtlicher. Die Entscheidung für die<br />
Anzahl der Cluster sollte jedoch nicht nur auf statistisch-mathematische Kriterien<br />
(„Homogenitätsanforderungen“) beruhen, sondern vor allem aus der<br />
„Handhabbarkeit“ bzw. der sachlogischen Interpretation der Clusterlösung<br />
resultieren (BACKHAUS et al. 2003: 521). 29<br />
Nachdem die beste Clusteranzahl ermittelt wurde, wird dieses Ergebnis, wie oben<br />
dargestellt, mit einer Clusterzentrenanalyse (K-Means) optimiert (vgl. Abbildung 9).<br />
Im Anschluss erfolgt die Überprüfung der Clusterlösung. Dabei unterteilt man drei<br />
Bereiche zur Clustervalidierung (VAZIRGIANNIS et al. 2003: 95-123; WEDEL et al.<br />
2003: 59f.):<br />
- externe<br />
- interne<br />
- relative Kriterien<br />
Die externen Kriterien vergleichen die ermittelte Clusterstruktur mit der<br />
tatsächlichen (VAZIRGIANNIS et al. 2003: 98-101). In vielen Untersuchungen, sowie<br />
auch im empirischen Teil dieser Arbeit, sind jedoch die wahren Gruppen nicht<br />
bekannt. Deshalb wird dieses Kriterium hier nicht weiter betrachtet.<br />
Anhand der internen Kriterien wird das Ausmaß der Homogenität (Varianz)<br />
innerhalb der Cluster gemessen. Als Gütemaß stehen hier der F-Wert <strong>und</strong> eta zur<br />
Verfügung. Der F-Wert kann, sowohl für jede Variable über alle Gruppen, als auch<br />
für jede Variable innerhalb eines Cluster berechnet werden. Bei der Ermittlung des<br />
F-Wertes für eine Variable innerhalb einer Gruppe gilt (BACKHAUS et al. 2003: 533):<br />
28 Die meisten statistischen Programme (z. B. SPSS, ClustanGraphics) geben bei der Clusterlösung<br />
ein Dendogramm <strong>und</strong> eine Tabelle mit den Fehlerquadratsummen (Koeffizienten) an. Ein Scree-Test-<br />
Diagramm kann jedoch nur mit Hilfe dieser Tabelle in z. B. Excel erstellt werden.<br />
29 Dieser Konflikt bezieht sich z. B. auf Marktsegmentierungen. Denn eine zu große Anzahl an<br />
Gruppen würde die Gefahr der „Oversegmentation“ <strong>und</strong> den damit im Marketing verb<strong>und</strong>enen<br />
zusätzlichen Kosten mit sich bringen (KÖNIG 2001: 113).<br />
28
3 Methodische Gr<strong>und</strong>legung<br />
V(J,G)<br />
F =<br />
V(J)<br />
(13)<br />
mit<br />
V(J,G) = Varianz der Variablen J in Gruppe G<br />
V (J) = Varianz der Variablen J in der Erhebungsgesamtheit<br />
Je kleiner der Quotient aus der Streuung einer Variablen in einem Cluster <strong>und</strong> der<br />
Streuung dieser Variablen in der Gr<strong>und</strong>gesamtheit ist, desto homogener ist die<br />
Gruppe in Bezug auf die betrachtete Variable. Wenn alle Variablen einen F-Wert <strong>von</strong><br />
kleiner als eins aufweisen, gilt dieses Cluster als vollkommen homogen (BACHER<br />
1996: 334). Der F-Wert einer Variablen über alle Gruppen berechnet sich<br />
entsprechend der Formel (7). Die Nullhypothese lautet dabei: Die Mittelwerte der<br />
Variablen sind in allen Gruppen gleich. Kann diese Hypothese nicht abgelehnt<br />
werden, dann liegt kein signifikanter Unterschied zwischen den Mittelwerten der<br />
Variablen in den Clustern vor. 30 Analog zu R² in der Regressionsanalyse bietet sich<br />
als weiteres Gütekriterium innerhalb der Varianzanalyse das Assoziationsmaß eta²<br />
an. 31<br />
Es handelt sich dabei um ein spezielles Gütemaß für den Fall, dass die<br />
unabhängige Variable (Cluster) nominalskaliert <strong>und</strong> die Abhängige (aktive oder<br />
passive Variable) mindestens intervallskalierte ist (JANSEN et al. 2003: 321-326;<br />
BACHER 1996: 334). 32<br />
2 erklärte Varianz<br />
eta =<br />
Gesamtvarianz<br />
(14)<br />
Nach Formel (14) gibt eta² darüber Auskunft, wie viel Prozent der Streuung einer<br />
Variablen auf die Unterschiede zwischen den Clustern zurückzuführen sind. Oder<br />
anders gesagt, eta² zeigt den Anteil der Varianz der abhängigen Variablen an, der<br />
durch die unabhängigen Variablen erklärt wird (BACHER 1996: 335; JANSEN et al.<br />
30 Das Ergebnis der Standardisierung der Quadratsummen (SS = Sum of Squares), also der Division<br />
der SS durch die Freiheitsgrade entspricht dem Mittel der Quadrate (MS = Mean Squares).<br />
31 Hinweise zur Terminologie: Fehlerquadratsumme = nicht erklärte Varianz (Streuung) = Varianz<br />
innerhalb der Gruppen = Innengruppenvarianz = Fehlervarianz = Residual Sum of Squares; Erklärte<br />
Varianz = Varianz zwischen den Gruppen = Explained Sum of Squares; Gesamte Streuung = Total<br />
Sum of Squares<br />
32 Die unhabhängige Variable kann jedes Skalenniveau annehmen.<br />
29
3 Methodische Gr<strong>und</strong>legung<br />
2003: 325). Der Mittelwert <strong>von</strong> eta² (Gesamt eta²) aus mehreren Variablen gibt an,<br />
wie viel Prozent der Varianz der Variablen durch die Unterschiede zwischen den<br />
Gruppen erklärt wird (KAMINSKI et al. 2004: 24). Mit dem Eta-Koeffizienten lässt<br />
sich die Beziehung zwischen den Variablen beschreiben. Er zeigt an, wie sehr sich<br />
die Mittelwerte der clusterbildenden Variablen zwischen den verschiedenen Gruppen<br />
unterscheiden. Unterscheiden sie sich stark <strong>und</strong> ist außerdem die Varianz der<br />
einzelnen Gruppen gering, tendiert eta gegen 1. Unterscheiden sie sich gar nicht,<br />
tendiert er gegen 0. Eta entspricht der Wurzel aus eta² <strong>und</strong> kann wie der<br />
Korrelationskoeffizient r interpretiert werden (JANSEN et al. 2003: 245ff.). 33<br />
Variablen, die nach dem F-Test oder eta keinen signifikanten Beitrag zur Trennung<br />
der Gruppen leisten, sollten nicht als clusterbildene Variablen verwendet werden, da<br />
diese ansonsten das Ergebnis einer Clusteranalyse verzerren würden (BACHER 1996:<br />
335). Zur näheren Überprüfung des Einflusses (Wirkungsanalyse) der aktiven <strong>und</strong><br />
passiven Variablen auf die gebildeten Cluster, kann eine multinomial-logistische-<br />
Regressionsanalyse verwendet werden. 34<br />
Als letztes werden im Rahmen der Validitätsprüfung die relativen Kriterien<br />
aufgezeigt. Diese dienen für die Überprüfung der Stabilität bzw. Generalisierbarkeit<br />
(Stichprobenabhängigkeit) der Clusterlösung (BORTZ 2005: 580; König 2001: 115).<br />
Die Objektmenge wird dabei zufällig in zwei oder mehrere gleich große<br />
Teilstichproben getrennt. Anschließend werden auf diese Teilmengen verschiedene<br />
oder gleiche Clusteralgorithmen angewendet (replizierte Clusteranalysen). Die<br />
Gruppenlösungen werden dann auf Übereinstimmungen hin überprüft (BORTZ 2005:<br />
581). Diese Vorgehensweise soll die Vielfalt <strong>von</strong> unterschiedlichen Clusteralgorithmen<br />
berücksichtigen. Zur Beurteilung der Übereinstimmungen kommen<br />
dabei verschiedene Gütemaße in Betracht (ebd.: 581-583; KÖNIG 2001: 115): 35<br />
33 Die Zuordnung <strong>von</strong> eta² in die internen Kriterien erfolgt aufgr<strong>und</strong> seiner varianzanalytischen<br />
Betrachtung.<br />
34 Die multinomial-logistische-Regressionsanalyse wird jedoch nicht im empirischen Teil dieser<br />
Arbeit eingesetzt. Einen Überblick über dieser Verfahren zeigen unter anderem BACKHAUS et al.<br />
(2003: 417-477) <strong>und</strong> SPSS (2003e).<br />
35 Weitere hier nicht betrachtete Gütemaße sind der Rand- <strong>und</strong> der Jaccard-Index (BORTZ 2005:<br />
582; KÖNIG 2001: 115; GIERL et al. 2001: 129).<br />
30
3 Methodische Gr<strong>und</strong>legung<br />
- Prozentsatz übereinstimmender Zuordnungen<br />
- Kappa-Maß<br />
- Diskriminanzanalyse<br />
Das einfachste Gütemaß betrachtet den prozentualen Anteil der übereinstimmenden<br />
Zuordnungen (JANSEN et al. 2003: 248):<br />
M<br />
Ü = V<br />
mit:<br />
M = Zahl der Übereinstimmungen<br />
V = Zahl der <strong>Vergleich</strong>e<br />
(15)<br />
Bei diesem Maß wird jedoch nicht der mögliche Anteil an zufällig richtig<br />
zugeordneten Übereinstimmungen berücksichtigt. Dieser komplexere<br />
Zusammenhang wird mit dem Kappa-Maß einkalkuliert (BORTZ 2005: 581f.; JANSEN<br />
et al. 2003: 249):<br />
Ü−<br />
Ü<br />
κ=<br />
1 − Ü<br />
E<br />
E<br />
mit:<br />
Ü = Anteil der tatsächlich beobachteten Übereinstimmungen<br />
Ü = Anteil der erwarteten Übereinstimmung<br />
E<br />
(16)<br />
Der Anteil der erwarteten Übereinstimmungen berechnet sich durch (ebd.):<br />
Ü<br />
E<br />
k<br />
= ∑<br />
i=<br />
1<br />
( p )<br />
i<br />
2<br />
(17)<br />
mit:<br />
p<br />
i<br />
= relativer Anteil der einzelnen Ausprägungen an der Gesamtzahl der<br />
Fälle<br />
k = Zahl der Ausprägungen<br />
31
3 Methodische Gr<strong>und</strong>legung<br />
Das Kappa-Maß kann maximal den Wert <strong>von</strong> 1 erreichen. Nur, wenn der Anteil an<br />
Übereinstimmungen größer ist als der Anteil an zufälligen Übereinstimmungen,<br />
nimmt Kappa positive Werte an. Im umgedrehten Fall weist Kappa negative Werte<br />
auf. (KÖNIG 2001: 116).<br />
Die Diskriminanzanalyse ist ein eigenständiges multivariates Verfahren <strong>und</strong> bietet<br />
die Möglichkeit die Clusterlösung sowie die clusterbildenden Variablen zu<br />
überprüfen (BORTZ 2005: 583; WIEDENBECK et al. 2001: 17). Auf Gr<strong>und</strong>lage der<br />
Clusterlösung wird eine Diskriminanzfunktion geschätzt, die eine maximale<br />
Trennung der Cluster ermöglicht. Anschließend werden die Objekte nach der<br />
Bedingung der Diskriminanzfunktion den Gruppen neu zugeordnet. Die<br />
Diskriminanzkoeffizienten werden dabei ähnlich der Regressions- oder<br />
Varianzanalyse, durch die Optimierung des Verhältnisses zwischen der erklärten<br />
Streuung (Varianz zwischen den Clustern) <strong>und</strong> der nicht erklärten Streuung (Varianz<br />
innerhalb der Cluster) berechnet. Die letztendliche Übereinstimmung zwischen dem<br />
Gruppierungsergebnis der Diskriminanz- <strong>und</strong> der Clusteranalyse, kann als relatives<br />
Validitätskriterium verwendet werden (BACKHAUS et al. 2003: 155-227, BROSIUS et<br />
al. 1996: 771-813; JANSEN et al. 2003: 439-456) 36 .<br />
Die abschließenden Schritte der Clusteranalyse sind die Interpretation bzw. die<br />
Charakterisierung <strong>und</strong> die Beschreibung der einzelnen Gruppen (vgl. Abbildung 9).<br />
Dafür eigenen sich vornehmlich die t-Werte, welche einzeln für jede Variable<br />
innerhalb einer Gruppe berechnet werden (BACHER 1996: 330; BACKHAUS et al.<br />
2003: 534):<br />
X(J,G) − X(J)<br />
t =<br />
S(J)<br />
(18)<br />
mit<br />
X(J,G) = Mittelwert der Variablen J über die Objekte in Gruppe G<br />
X(J) = Gesamtmittelwert der Variablen J in der Erhebungsgesamtheit<br />
36 Weitere Ausführungen zur Diskriminanzanalyse finden sich bei BACKHAUS et al. (2003: 155-<br />
227), BROSIUS et al. (1996: 771-813) <strong>und</strong> JANSEN et al. (2003: 439-456).<br />
32
3 Methodische Gr<strong>und</strong>legung<br />
S(J) = Standardabweichung der Variablen J in der<br />
Erhebungsgesamtheit<br />
Positive bzw. negative t-Werte zeigen an, dass der Mittelwert einer Variablen<br />
innerhalb eines Clusters über- bzw. unter dem Mittelwert der Erhebungsgesamtheit<br />
dieser Variablen liegt (ebd.). 37 Nur eine Clusterlösung, die durch eine Interpretation<br />
logisch nachvollziehbar ist, erweist sich als sinnvoll. Für die Beschreibung der<br />
einzelnen Gruppen sollten neben den clusterbildenden bzw. aktiven Variablen auch<br />
die nicht in die Clusterbildung eingeschlossenen Variablen (passive Variablen), die<br />
signifikante Unterschiede zwischen den Clustern aufweisen, herangezogen werden<br />
(KÖNIG 2001: 117).<br />
Insgesamt bietet die Clusteranalyse dem Nutzer durch die Vielzahl <strong>von</strong><br />
Proximitätsmaßen <strong>und</strong> Algorithmen ein breites Anwendungsfeld. Dieses bedeutet<br />
aber auch gleichzeitig eine starke subjektive Beeinflussung. Die besonders durch die<br />
Auswahl der clusterbildenden Variablen <strong>und</strong> die Entscheidung für die Anzahl der<br />
Gruppen erhöht wird. Deshalb sollte gegenüber Dritten eine umfassende<br />
Offenlegung, in Bezug auf die Ablaufschritte (vgl. Abbildung 9) <strong>und</strong> die damit<br />
verb<strong>und</strong>enen Entscheidungen des Anwenders, innerhalb der Clusteranalyse erfolgen.<br />
37 Die t-Werte stellen eine normierte Größe dar.<br />
33
3 Methodische Gr<strong>und</strong>legung<br />
3.2 Künstliche Neuronale Netze<br />
3.2.1 Überblick über Neuronale Netze<br />
Ursprünglich wurden künstliche Neuronale Netze (KNN, artificial neural networks,<br />
ANN) entwickelt, um die neurobiologischen Prozesse innerhalb des Nervensystems<br />
bei Tieren <strong>und</strong> Menschen besser begreifbar zu machen. Dieser Ansatz wird unter der<br />
Terminologie des Konnektionismus zusammengefasst (Hoffmann 2004: 48). „Das<br />
Paradigma des Konnektionismus besagt, dass Informationsverarbeitung als<br />
Interaktion einer großen Zahl einfacher Einheiten (Zellen, Neuronen) angesehen<br />
wird, die anregende oder hemmende Signale an andere Zellen senden“ (Zell 2003:<br />
26). 38 Seit dem Ende der 80er Jahre des zwanzigsten Jahrh<strong>und</strong>erts entwickelte sich<br />
neben diesem neurobiologisch orientierten Forschungszweig ein eigener nur auf<br />
statistische Problemstellungen bezogener anwendungsorientierter Zweig (PODDIG et<br />
al. 2001: 363). 39 In dieser Arbeit wird der Terminus der KNN nur im Zusammenhang<br />
mit der statistischen Forschungsrichtung weiter verwendet.<br />
Neuronale Netze können wie die <strong>multivariaten</strong> Verfahren als eine eigenständige<br />
Verfahrensklasse mit vielen verschiedenen Typen (Verfahren) <strong>von</strong> KNN angesehen<br />
werden (BACKHAUS 2003: 742; PODDIG et al. 2001: 364). Diese Typen der<br />
<strong>Neuronalen</strong> Netze ermöglichen es aber, ähnliche statistische Problemsituationen wie<br />
in der <strong>multivariaten</strong> Statistik zu analysieren (Strukturentdeckung <strong>und</strong><br />
Strukturabbildung). Die Literatur verwendet jedoch bei der Anwendung dieser<br />
beiden Verfahrensklassen (multivariate Statistik <strong>und</strong> KNN) unterschiedliche<br />
Fachtermini (vgl. Tabelle 2).<br />
38 Einen ausführlichen Überblick über die Historie KNN zeigen STRECKER et al. (1997: 9-12) <strong>und</strong><br />
ZELL (2003: 28-33). LENZ et al (1995) stellt die Begriffsdefinitionen der <strong>Neuronalen</strong> Netze <strong>und</strong> der<br />
künstlichen Intelligenz näher dar.<br />
39 Beide Forschungsrichtungen fallen unter dem Begriff der Künstlichen Intelligenz (KI)<br />
34
3 Methodische Gr<strong>und</strong>legung<br />
Tabelle 2: Terminologie der KNN im <strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren<br />
Quelle: Eigene Darstellung in Anlehnung an ANDERS 1996: 164<br />
In den folgenden Kapiteln wird zunächst ein Überblick über die Gr<strong>und</strong>struktur <strong>und</strong><br />
die Funktionsweise Neuronaler Netze gegeben. Anschließend werden zwei Typen<br />
<strong>von</strong> <strong>Neuronalen</strong> <strong>Netzen</strong> näher betrachtet, die Multi-Layer-Perceptrons <strong>und</strong> die Self-<br />
Organizing-Maps. Danach werden die spezifischen Eigenschaften der KNN im<br />
<strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren dargestellt.<br />
Im <strong>Vergleich</strong> zu der <strong>multivariaten</strong> Statistik wurde in der Literatur nur wenig zu der<br />
praktischen Vorgehensweise <strong>und</strong> Anwendung <strong>von</strong> KNN verfasst. Dementsprechend<br />
beruhen die hier dargestellten Verfahrensabläufe zum Teil auf einer eigenen<br />
methodischen Erforschung im Rahmen dieser Arbeit. 40<br />
3.2.2 Gr<strong>und</strong>struktur <strong>und</strong> Funktionsweise Neuronaler Netze<br />
Da die KNN ursprünglich dazu entwickelt wurden, biologische Lernprozesse besser<br />
darzustellen, bietet es sich zunächst an, die Informationsverarbeitung einer<br />
natürlichen Nervenzelle (Neuron) näher zu erläutern <strong>und</strong> diese dann der<br />
40 Anwenderbezogene Literatur für multivariate Verfahren finden sich z.B. bei BACKHAUS et al.<br />
(2004); BORTZ (2005); BROSIUS (2004); RUDOLF et al. (2004) <strong>und</strong> JANSEN et al. (2004).<br />
Anwenderbezogene Literatur für MLP Verfahren findet sich z.B. bei ALEX (1998); BACKHAUS et al.<br />
(2003) <strong>und</strong> WIEDMANN (2003).<br />
35
3 Methodische Gr<strong>und</strong>legung<br />
Funktionsweise eines künstlichen Neurons gegenüberzustellen. Nach Schätzungen<br />
besteht das menschliche Gehirn aus ca. 100 Milliarden Nervenzellen (ZELL 2003:<br />
35). Jede einzelne Nervenzelle (vgl. Abbildung 13) setzt sich aus dem Zellkörper<br />
(Soma) mit Zellkern (Nucleus), einer Nervenfaser (Axon) <strong>und</strong> vielen Dendriten<br />
zusammen. Die Verbindung zwischen Axon <strong>und</strong> Dendriten wird durch die Synapsen,<br />
die mit vielen verschiedenen Nervenzellen miteinander verb<strong>und</strong>en sind, realisiert<br />
(ebd. 37).<br />
Abbildung 13: Schematische Darstellung einer Nervenzelle<br />
Quelle: Eigene Darstellung in Anlehnung an ANDERSON et al. 1992; ZELL 2003: 36<br />
Über die Dendriten empfangene hemmende oder erregenden Signale werden an den<br />
Zellkörper weitergeleitet <strong>und</strong> aufaddiert. Haben die Signale einen bestimmten<br />
Schwellenwert überschritten wird der Zellkern aktiviert, die Signale analysiert,<br />
ausgewertet <strong>und</strong> schließlich über das Axon durch einen kurzfristigen elektrischen<br />
Impuls weitergeleitet. Dieser Impuls wird dann durch die Synapsen an die Dendriten<br />
der nachgeschalteten Neuronen übertragen. Durch die Anpassung der Verbindungen<br />
(Synapsen) zwischen den Nervenzellen erfolgt der biologische Lernprozess. Das<br />
heißt, mit zu-, bzw. abnehmenden Nutzungsgrad der Synapsen wachsen oder<br />
36
3 Methodische Gr<strong>und</strong>legung<br />
degenerieren diese (ebd.: 35-38). 41 Neben der Eigenschaft der Lernfähigkeit besitzt<br />
das Nervensystem sowie das KNN die Fähigkeit auf Signale der Umgebung<br />
(Stimulus) zu reagieren (Response) (BACKHAUS et al. 2003: 740). Abbildung 14<br />
verdeutlicht diesen Zusammenhang mit dem Stimulus-Organismus-Response-Modell<br />
(SOR-Modell).<br />
Abbildung 14: Das menschliche Nervensystem als SOR-Modell<br />
Quelle: BACKHAUS et al. 2003: 740<br />
Ein künstliches Neuron (Unit) lässt sich analog zu der biologischen Nervenzelle<br />
vereinfacht durch drei mathematische Rechenoperationen (Bildung des Inputs,<br />
Bildung des Aktivitätsniveaus, Bildung des Outputs) abbilden (vgl. Abbildung 15).<br />
Abbildung 15: Allgemeines Modell eines künstlichen Neurons<br />
Quelle: Eigene Darstellung in Anlehnung an PODDIG et al. 2001: 370; SCHÜLER 2002: 15<br />
41 Einen umfassenden Überblick über die Neurobiologischen Gr<strong>und</strong>lagen <strong>und</strong> Konnektionistische<br />
Modelle zeigt insbesondere Zell (2003).<br />
37
3 Methodische Gr<strong>und</strong>legung<br />
Dabei entspricht die Summe der unterschiedlich gewichteten Eingangswerte e(x)<br />
dem konnektionistischen Gegenstück der neurobiologischen Synapsen (SCHÜLER<br />
2002: 15):<br />
e(x) = ∑ w<br />
jx<br />
n<br />
j1 =<br />
j<br />
(19)<br />
mit:<br />
e(x) = Eingangsfunktion<br />
x<br />
j<br />
= Eingangsinformationen<br />
w<br />
j<br />
= Verbindungsgewichte<br />
Erreicht der summierte Eingabewert ein bestimmtes Niveau (Schwellenwert), wird<br />
die Aktivierungsfunktion aktiviert <strong>und</strong> dadurch bestimmt, inwieweit <strong>und</strong> in welcher<br />
Höhe das Signal durch das Neuron an andere Neuronen weitergeleitet wird (ALEX<br />
1997: 87). Die Aktivierungsfunktion kann dabei recht komplexe Formen annehmen<br />
(vgl. Abbildung 16). Besonders den sigmoiden Funktionen kommt eine große<br />
Bedeutung zu, wenn KNN für Problemstellungen verwendet werden sollen, bei<br />
denen der Zusammenhang zwischen Input- <strong>und</strong> Outputvariablen nicht-linear ist<br />
(ZELL 2003: 89). 42<br />
Abbildung 16: Kurvenverlauf ausgewählter Aktivierungsfunktionen<br />
Quelle: Eigene Darstellung in Anlehnung an ALEX 1997: 88; BACKHAUS et al. 2003: 740<br />
Im letzten Schritt erfolgt die Bildung der Ausgabe als Ergebnis auf die Anwendung<br />
einer Outputfunktion auf das Aktivitätsniveau. Diese Outputfunktion hat bei den<br />
42 Sigmoide Funktionen weisen einen S-förmigen Verlauf auf. Z. B. logistische <strong>und</strong> Tangens<br />
Hyperbolicus-Funktionen (BACKHAUS et al. 2003: 760).<br />
38
3 Methodische Gr<strong>und</strong>legung<br />
meisten neuronalen <strong>Netzen</strong> einen nichtlinearen Charakter <strong>und</strong> ist oftmals auch<br />
Bestandteil der Aktivierungsfunktion (Zell 2003: 76). Das Ausgangssignal wird<br />
anschließend an nachfolgende Neuronen weitergeleitet (PODDIG ET AL. 2001: 372).<br />
Der Ablauf dieser drei Rechenschritte lässt sich in der Literatur meistens wieder<br />
finden. Häufig wird er jedoch unterschiedlich zusammengefasst <strong>und</strong> anders<br />
angeordnet, was leicht zu Irritationen führen kann. Deshalb wird hier für einen<br />
umfassenderen Überblick über die Arbeitsweise der künstlichen <strong>Neuronalen</strong> Netze<br />
auf ANDERSON/MCNEILL 1992, FREEMAN/SKAPURA 1991, PERETTO 1992, PODDIG et<br />
al. 2001, WHITE 1992 <strong>und</strong> ZELL 2003 verwiesen.<br />
Durch die Verbindung <strong>von</strong> mehreren künstlichen Neuronen ergibt sich ebenfalls<br />
analog zum biologischen Nervensystem ein leistungs- <strong>und</strong> anpassungsfähiges<br />
Netzwerk, in dem die einzelnen Neuronen Berechnungs- <strong>und</strong> Informationsergebnisse<br />
austauschen (MEYER 2002: 1999). Die Neuronen werden dabei wie in Abbildung 17<br />
nach Aufgabe <strong>und</strong> Positionierung im Netzwerk in drei Schichten (Layer) unterteilt.<br />
Abbildung 17: Darstellung der Schichten eines <strong>Neuronalen</strong> Netzes<br />
Quelle: Eigene Darstellung in Anlehnung an HOFFMANN 2004: 50; BERRY et al. 2004: 221<br />
In der Eingabeschicht (Input-Layer) werden externe Informationen, die Werte der<br />
unabhängigen Variablen aufgenommen <strong>und</strong> unverändert an die verdeckte Schicht<br />
oder Zwischenschicht (Hidden-Layer) weitergeben. Diese verdeckte Schicht hat<br />
keine Verbindungen zur Netzwerkaußenwelt, ist für den außenstehenden Beobachter<br />
39
3 Methodische Gr<strong>und</strong>legung<br />
nicht sichtbar <strong>und</strong> dient der internen Informationsverteilung <strong>und</strong> -weiterverarbeitung.<br />
Die Ausgabenschicht (Output-Layer) verarbeitet die Informationen der vorgelagerten<br />
Neuronen weiter <strong>und</strong> ist der Austrittspunkt der analysierten Informationen. Die<br />
Anzahl der Output-Neuronen hängt <strong>von</strong> der Anzahl der zu analysierenden Zielgrößen<br />
ab (ZIMMERER 1997: 16). Besonders durch die nichtlinearen Aktivierungsfunktionen<br />
in der verdeckten Schicht sind KNN in der Lage, komplexe nichtlineare<br />
Zusammenhänge innerhalb der Datenbasis zu approximieren (HEIMEL 1994: 25).<br />
Würden nur lineare Aktivierungsfunktionen eingesetzt, könnte das Netz auf die Ein<strong>und</strong><br />
Ausgabeschicht reduziert werden (ZELL 2003: 89). 43<br />
Abbildung 18: Einige schematische Netzwerktopologien<br />
Quelle: Eigene Darstellung in Anlehnung an ALEX 1998: 83; PODDIG et al. 2001: 374; ZELL 2003: 79<br />
Die verschiedenen Typen <strong>von</strong> KNN sind gekennzeichnet durch differenzierte<br />
Verbindungsstrukturen der Neuronen (Topologie bzw. Architektur eines<br />
Netzwerkes), eine unterschiedliche Anzahl an verdeckten Schichten sowie eine<br />
unterschiedliche Anzahl an Neuronen pro Schicht (MEYER 2002: 200). Zusätzlich<br />
kann die Netzwerktopologie auch durch die Richtung des Informationsflusses<br />
charakterisiert werden. Verläuft der Informationsstrom nur <strong>von</strong> der Eingabe- zur<br />
Ausgabeschicht, so wird <strong>von</strong> vorwärtsgerichteten (feedforward) <strong>Netzen</strong> gesprochen.<br />
Bei rückwärtsgerichteten (feedback) KNN ist hingegen ein Informationsrückfluss<br />
(Rückkopplung) möglich. Das heißt, die Informationsverteilung verläuft nicht nur<br />
<strong>von</strong> der der Eingabe- zur Ausgabeschicht, sondern auch zwischen den Neuronen<br />
einer Schicht <strong>und</strong> <strong>von</strong> den eigentlich nachgelagerten Neuronen zu den<br />
43 Da die Inputschicht über keine Informationsverarbeitung verfügt, wird diese in der Literatur<br />
(BACKHAUS et al. 2003: 740; PODDIG et al. 2001: 373; ZIMMERER 1997: 16) nicht einheitlich den<br />
Schichten des Netzwerkes zugeordnet. In dieser Arbeit wird sie jedoch mitgezählt.<br />
40
3 Methodische Gr<strong>und</strong>legung<br />
Vorgängerneuronen (ANDERSON et al. 1992: 9). Dadurch ist häufig keine eindeutige<br />
Zuordnung der Schichten mehr möglich (ALEX 1998: 84). Abbildung 18 vermittelt<br />
einen schematischen Überblick über einige ausgewählte Netzwerkarchitekturen.<br />
Neben der Topologie stellt der Lernprozess eine weitere wichtige Eigenschaft der<br />
KNN dar. Dieser vollzieht sich durch die Anwendung eines Lernalgorithmus<br />
(Lernregel) bei dem die Höhe der Gewichte bzw. die Stärke der Verbindungen<br />
zwischen den Neuronen auf das Lernziel hin angepasst wird. Der gesamte<br />
Lernprozess wird auch als Training des Netzwerkes bezeichnet (ebd.: 89). Es kann<br />
zwischen unüberwachtem (Strukturentdeckung) <strong>und</strong> überwachtem (Strukturabbildung)<br />
Lernen unterschieden werden. Beim überwachten Lernen wird einem<br />
Eingabemuster (Input) ein bestimmtes Ausgabemuster (Output) zugeordnet. Die<br />
Verbindungsgewichte werden dann so lange angepasst, bis die Differenz (der Fehler)<br />
zwischen ermitteltem <strong>und</strong> tatsächlichem Output minimiert ist. Beim unüberwachten<br />
Lernen liegt dem KNN nur das Eingabemuster vor. Hier ist das Ziel des Netzwerkes<br />
diese Inputdaten entsprechend ihrer Homogenitäten hin zu ordnen (Clusterung) <strong>und</strong><br />
als Gruppen auszugeben (ANDERSON et al. 1992: 10-12).<br />
Abbildung 19: Ausgewählte künstliche neuronale Netzwerktypen 44<br />
Quelle: Eigene Darstellung in Anlehnung an BACKHAUS et al. 2003: 743; SCHÜLER 2002: 24<br />
44 In dieser Arbeit werden nur die MLP <strong>und</strong> SOM vorgestellt. Die anderen Verfahren der KNN<br />
werden unter anderem <strong>von</strong> ANDERSON/MCNEILL (1992), FREEMAN/SKAPURA (1991), PERETTO<br />
(1992), PODDIG et al. (2001), WHITE (1992) <strong>und</strong> ZELL (2003) aufgezeigt.<br />
41
3 Methodische Gr<strong>und</strong>legung<br />
Abbildung 19 zeigt Beispiele für verschiedene Netzwerktypen <strong>und</strong> klassifiziert diese<br />
in Bezug auf die angewandten Lernregeln <strong>und</strong> die Richtung des Informationsflusses.<br />
Die unterschiedlichen <strong>Neuronalen</strong> Netze haben die Gemeinsamkeit, dass sie einen<br />
iterativen Lernprozess zur Erschließung <strong>von</strong> Zusammenhängen in den Daten<br />
durchlaufen. Daraus folgend wird noch einmal deutlich (vgl. Kapitel 2.2 <strong>und</strong> 3.2.1),<br />
dass die KNN wie die <strong>multivariaten</strong> Verfahren für unterschiedliche statistische<br />
Problemstellungen eingesetzt werden können <strong>und</strong> deshalb neben den uni-, bi-, <strong>und</strong><br />
<strong>multivariaten</strong> Methoden eine eigene Verfahrensklasse bilden (BACKHAUS 2003: 742;<br />
PODDIG et al. 2001: 364).<br />
Im Folgenden werden zwei Typen <strong>von</strong> KNN (MLP <strong>und</strong> SOM) näher vorgestellt.<br />
Diese können in Bezug auf die Datenanalyse in der Primärforschung, wie die im<br />
Kapitel 3.1 aufgezeigten <strong>multivariaten</strong> Verfahren (Regressionsanalyse, Clusteranalyse)<br />
eingesetzt werden.<br />
3.2.3 Multi-Layer-Perceptrons<br />
Das Multi-Layer-Perceptron (MLP) ist das bekannteste struktur-abbildende<br />
künstliche Neuronale Netzwerk (SÄUBERLICH 2000: 54; WIEDMANN et al. 2003: 58).<br />
Es ist eine Weiterentwicklung der Perceptrons, einem zweischichtigen, trainierbaren<br />
neuronalen Netz, dass <strong>von</strong> dem Psychologen Rosenblatt 1958 entwickelt wurde <strong>und</strong><br />
somit eines der ersten KNN darstellt (HEIMEL 1994: 33). Bei dem MLP handelt es<br />
sich um ein Neuronales Netz wie es in Abbildung 17 aufgezeigt wurde. Dabei<br />
variiert jedoch die Anzahl der verdeckten Schichten <strong>und</strong> Neuronen pro Schicht je<br />
nach Problemfall. Der Informationsfluss ist vorwärtsgerichtet (feedforward) <strong>und</strong><br />
verläuft dementsprechend <strong>von</strong> den Input-Layern zu den Output-Layern (ANDERS<br />
1997: 3). Innerhalb der Neuronen entspricht die Informationsverarbeitung den<br />
Ausführungen zu Abbildung 15. Der Aktivierungszustand wird durch eine<br />
logistische Funktion festgelegt (SPPS 2003a: 4).<br />
Als überwachtes Lernverfahren bieten MLP die Möglichkeit, funktionale<br />
Zusammenhänge zwischen einer oder mehreren abhängigen <strong>und</strong> unabhängigen<br />
Variablen aufzuzeigen. Dem Verwendungszeck nach entsprechen sie deshalb der<br />
42
3 Methodische Gr<strong>und</strong>legung<br />
Regressionsanalyse aus den <strong>multivariaten</strong> Verfahren. (PODDIG et al. 2001: 367). Die<br />
folgenden Ausführungen zu den MLP beziehen sich auf die in Abbildung 20<br />
dargestellte Vorgehensweise.<br />
Abbildung 20: Ablaufschritte der Multi-Layer-Perceptrons<br />
Schritt 1<br />
Problemstrukturierung<br />
Schritt 2<br />
Festlegung der Netztopologie<br />
Schritt 3<br />
Trainieren des Netzes<br />
Schritt 4<br />
Anwendung des Netzes<br />
Schritt 5<br />
Prüfung des Netzes<br />
Quelle: Eigene Darstellung in Anlehnung an ALEX 1998: 108; BACKHAUS et al. 2003: 752;<br />
WIEDMANN 2003: 70<br />
Im ersten Schritt, der Problemstrukturierung, müssen die abhängigen <strong>und</strong><br />
unabhängigen Variablen festgelegt werden (überwachtes Lernverfahren). Dabei ist es<br />
sogar möglich, mehrere endogene Variablen zu bestimmen. Diese Eingangs- <strong>und</strong><br />
Zielvariablen können numerisch, ordinal oder metrisch skaliert sein (SPSS 2003c).<br />
Die Auswahl der exogenen Variablen sollte, trotz der Fähigkeit der MLP, Variablen<br />
zu identifizieren, die keinen relevanten Einfluss auf die Outputvariable ausüben,<br />
aufgr<strong>und</strong> <strong>von</strong> sachlogischen Überlegungen erfolgen. Andernfalls würde nach<br />
BACKHAUS et al. (2003: 754) die Komplexität des Netzes überdimensioniert <strong>und</strong><br />
somit die Rechenzeit erheblich steigen.<br />
Die Festlegung der Netztopologie wird durch die Bestimmung der Anzahl der<br />
verdeckten Schichten <strong>und</strong> Neuronen pro Schicht definiert. Je höher die Anzahl der<br />
43
3 Methodische Gr<strong>und</strong>legung<br />
Schichten <strong>und</strong> Neuronen ist, desto komplexer wird das Netzwerk <strong>und</strong> umso besser<br />
wird der Zusammenhang zwischen den Inputdaten <strong>und</strong> den Outputdaten approximiert<br />
(HEIMEL 1994: 25; PODDIG et al. 2001: 380f.). Jedoch hat ein sehr komplexes<br />
Netzwerk auch gleichzeitig sehr hohe Rechenzeitansprüche (SARLE 2002: 123-130).<br />
Die Literatur gibt aufgr<strong>und</strong> dieses Zusammenhanges keine genauen Empfehlungen<br />
zur Festlegung der Netzwerktopologie ab. Der Anwender muss somit nach dem<br />
Trial-and-Error Prinzip ein Netzwerk konstruieren, dass sowohl der Komplexität der<br />
Datenstruktur sowie dem Rechenaufwand gerecht wird.<br />
Nach der Festlegung der Netztopologie erfolgt der eigentliche überwachte<br />
vorwärtsgerichtete (feedforward) Lernprozess (Trainieren des Netzes) unter<br />
Verwendung des Backpropagation-Algorithmus. 45 Dieser versucht den<br />
durchschnittlichen Gesamtfehler durch die Veränderung der Verbindungsgewichte zu<br />
minimieren. Der durchschnittliche Gesamtfehler E ergibt sich dabei nach Formel<br />
(20) aus der Differenz zwischen dem empirischen <strong>und</strong> dem berechneten<br />
Ausgabewert (BACKHAUS et al. 2003: 766; WIEDMANN et al. 2003: 62):<br />
a<br />
∑<br />
E = (t −y )<br />
mit:<br />
i=<br />
1<br />
i<br />
i<br />
2<br />
a = Anzahl der Neuronen in der Ausgabeschicht<br />
t<br />
i<br />
= empirische (beobachtete) Ausgabewerte<br />
y<br />
i<br />
= berechnete (vorhergesagte) Ausgabewerte<br />
(20)<br />
Durch die Quadrierung wird einer gegenseitigen Aufhebung der Vorzeichen<br />
vorgebeugt. Der Lernprozess wird durch die Schrittweite (Lernrate), also die<br />
Änderung der Gewichte, beeinflusst. Eine sehr kleine Lernrate bedeutet, dass auch<br />
viele Lernschritte <strong>und</strong> somit auch ein erhöhter Rechenaufwand notwendig ist, bis der<br />
Algorithmus das Minimum der Fehlerfunktion erreicht hat (BACKHAUS et al. 2003:<br />
767). In Bezug auf die optimale Lernrate empfiehlt die Literatur diese in<br />
Abhängigkeit <strong>von</strong> der Problemstellung, der Stichprobengröße <strong>und</strong> der Netztopologie<br />
45<br />
Einen umfassenden Überblick über den Backpropagation-Algorithmus zeigen<br />
ANDERSON/MCNEILL (1992); FREEMAN/SKAPURA (1991); WHITE (1992) <strong>und</strong> ZELL (2000).<br />
44
3 Methodische Gr<strong>und</strong>legung<br />
zu wählen (ALEX 1998: 126; BACKHAUS et al. 2003: 767; Zell 2003: 114). Der<br />
Anwender unterliegt aber im Prinzip wieder einem Trial-and-Error Prozess. Das Ziel<br />
des Lernalgorithmus ist es nicht, den durchschnittlichen Gesamtfehler innerhalb des<br />
Trainingsdatensatzes zu verringern, sondern diesen auf einen separaten<br />
Validationsdatensatz <strong>und</strong> somit auf allgemeine Zusammenhänge<br />
(Generalisierungsfähigkeit) zwischen den Inputdaten <strong>und</strong> Outputdaten zu minimieren<br />
(vgl. Abbildung 21) (HOFFMANN 2004: 65).<br />
Abbildung 21: Test- <strong>und</strong> Validationsfehler im Lernverlauf<br />
Quelle: Eigene Darstellung in Anlehnung an BACKHAUS et al. 2003: 770; HOFFMANN 2004: 66<br />
Dieses birgt auch die Gefahr des „Overfitting“, dem Auswendiglernen der Daten<br />
durch das Neuronale Netz vor (BACKHAUS et al. 2003: 769; WILBERT 1996: 76). Der<br />
empirische Datensatz wird deshalb in Trainings-, Validierungs- <strong>und</strong> in Testdaten<br />
aufgeteilt. Die zusätzliche Unterteilung in einen Testdatensatz erfolgt, weil die<br />
Validationsdaten schon zur Auswahl des Modells herangezogen wurden <strong>und</strong> somit<br />
nicht mehr für die Berechnung der Güte des gewählten Modells verwendet werden<br />
können (ebd.: 770).<br />
Im vierten Schritt (vgl. Abbildung 20) wird nach Abschluss des Lernprozesses die<br />
Anwendung des trainierten Netzes durchgeführt. Die Verbindungsgewichte der<br />
Neuronen innerhalb der Schichten sind fest bestimmt <strong>und</strong> werden auf die<br />
45
3 Methodische Gr<strong>und</strong>legung<br />
Eingabedaten angewandt (ebd. 772). Das Ergebnis, die berechneten Ausgabedaten<br />
(Testdaten), können im abschließenden Ablaufschritt der „Anwendung des Netzes“<br />
geprüft werden. Dafür bieten sich nachstehende Fehlermaße an, die im Wesentlichen<br />
auf die Residuen (Formel (2)) basieren (ANDERS 1997: 80-81; FAHRMEIER et al. 364-<br />
374; RUDOLPH 1998: 7f.):<br />
1<br />
MAE = t − y<br />
N<br />
∑ N i i<br />
i=<br />
1<br />
Mean Absolute Error<br />
(21)<br />
1<br />
MSE = t − y<br />
N<br />
∑ N i i<br />
i=<br />
1<br />
( ) 2<br />
1<br />
RMSE = t − y<br />
N<br />
∑ N i i<br />
i=<br />
1<br />
( ) 2<br />
Mean Square Error<br />
Root Mean Square Error<br />
(22)<br />
(23)<br />
1 −<br />
= ∑ N ti yi<br />
MAPE i 100% Mean Absolute Percent Error<br />
N t<br />
i=<br />
1 i<br />
(24)<br />
( t t) ( y y)<br />
∑ N i i<br />
i 1<br />
− i −<br />
1<br />
R = =<br />
N s i s<br />
t<br />
y<br />
Korrelationskoeffizient<br />
(25)<br />
mit:<br />
N = Gesamtzahl der berechneten Beobachtungen (i = 1,…,N).<br />
t = Mittelwert der empirischen (beobachteten) Ausgabewerte<br />
y = Mittelwert der berechneten (vorhergesagte) Ausgabewerte<br />
s<br />
t<br />
= Streuung der empirischen (beobachteten) Ausgabewerte<br />
s<br />
y<br />
= Streuung der berechneten (vorhergesagte) Ausgabewerte<br />
Der Mean Absolute Error (MAE) gibt an, inwieweit der vorhergesagte Ausgabewert<br />
im Durchschnitt dem empirischen Wert entspricht. Durch das Quadrieren der<br />
Residuen im Mean Square Error (MSE), werden große Abweichungen stärker<br />
gewichtet als kleinere, woraus eine hohe Sensibilität gegenüber Ausreißern in den<br />
berechneten Ausgabewerten folgt. Der Root Mean Square Error (RMSE) berechnet<br />
die Wurzel aus dem MSE. Dieser häufig verwendete Wert ist mit dem Standardfehler<br />
der Regression (Standardfehler der Residuen) unmittelbar vergleichbar <strong>und</strong><br />
46
3 Methodische Gr<strong>und</strong>legung<br />
ermöglicht eine leichte inhaltliche Interpretation, da er auf der gleichen Maßeinheit<br />
wie die beobachteten Werte beruht (ANDERS 1997: 8). 46 Der Vorteil des Mean<br />
Absolute Percent Error (MAPE) ist seine Unabhängigkeit <strong>von</strong> der Größe der<br />
Ausgabewerte, da er die betragsmäßige, mittlere prozentuale Abweichung der<br />
empirischen Ausgabewerte <strong>von</strong> den berechneten Ausgabewerten bestimmt. Dabei<br />
muss jedoch beachtet werden, dass dasselbe Ausmaß einer Fehlberechnung bei<br />
einem hohen Beobachtungswert weniger wichtig bewertet wird, als bei einem<br />
niedrigen Beobachtungswert (ebd.: 9). Der hier aufgezeigte Korrelationskoeffizient<br />
R ist vor allem in regressionsanalytischen Verfahren gebräuchlich. Er quantifiziert<br />
die lineare Korrelation zwischen den empirischen <strong>und</strong> den berechneten<br />
Ausgabewerten. Durch Quadrieren dieses Koeffizienten ergibt sich das schon in<br />
Kapitel 3.1.2 aufgezeigte Bestimmtheitsmaß R².<br />
Das Ergebnis der MLP liefert nicht, wie bei der <strong>multivariaten</strong> Regressionsanalyse,<br />
Koeffizienten, mit deren Hilfe eine einfache inhaltliche Interpretation der<br />
einfließenden Variablen erfolgen kann (HOFFMANN 2004: 68). Es ist jedoch möglich<br />
unter Anwendung <strong>von</strong> verschiedenen Verfahren eine Aussage über die globale <strong>und</strong><br />
lokale Relevanz der Inputvariablen zu treffen. Die globale Relevanz soll eine<br />
Aussage darüber treffen, inwieweit eine Inputvariable einen Beitrag zu Varianz der<br />
Outputvariablen leistet (WIEDMANN et al. 2003: 74). Dafür können im Rahmen des<br />
Trainingsprozesses der MLP Pruning-Verfahren Informationen darüber geben,<br />
welche Variablen keinen Beitrag zur Varianz der Outputvariablen leisten (ebd.). 47<br />
Ein anderer Ansatz zur Bestimmung der globalen Relevanz erfolgt durch die<br />
Beobachtung der Veränderung der Fehlermaße bei der iterativen Auswahl der<br />
Inputvariablen (ebd.). Die lokale Relevanz betrachtet durch die Anwendung <strong>von</strong><br />
linearen Sensitivitätsanalysen wie stark sich der Output bei Variation einer<br />
Inputvariablen unter Verwendung <strong>von</strong> Durchschnittswerten bei den restlichen<br />
Variablen ändert (SPSS 2003a: 16; WIEDMANN et al. 2003: 74). Diese<br />
Durchschnittsbetrachtung ist daher nur anzuwenden, wenn die Nicht-Lineraritäten<br />
46 Dies setzt jedoch voraus, dass die Größenordnung der abhängigen Variablen bekannt ist<br />
(ANDERS 1997: 8).<br />
47 Diese Verfahren beginnen mit sehr vielen Inputvariablen (Neuronen) <strong>und</strong> löschen dann iterativ<br />
die Variablen, die keinen hilfreichen Einfluss auf den Output haben (SPSS 2003a: 12-13).<br />
47
3 Methodische Gr<strong>und</strong>legung<br />
innerhalb des <strong>Neuronalen</strong> Netzwerkes gering ausgeprägt sind (BACKHAUS et al.<br />
2003: 773).<br />
Insgesamt wurde aufgezeigt, dass die Literatur (Z.B. ALEX 1998; BACKHAUS et al.<br />
2003; WIEDMANN 2003) oft keine genauen Angaben zur spezifischen Anwendung<br />
<strong>von</strong> MLP geben kann. Der Anwender unterliegt, wie oben aufgezeigt, häufig einem<br />
Trial-and-Error Prozess. Er muss deshalb besonders sorgfältig einen systematischen<br />
Mittelweg zwischen dem zeitlichen Rechenaufwand <strong>und</strong> der Fähigkeit des Netzes,<br />
komplexe Zusammenhänge darzustellen, finden. 48 Dabei beeinflusst er die<br />
Rechenzeit des Netzes durch die Anzahl der Variablen, Schichten, Neuronen <strong>und</strong> die<br />
Höhe der Lernrate. In Bezug auf die notwendige Stichprobengröße gibt die Literatur<br />
keine Hinweise. Es scheint aber offensichtlich, dass umso komplexer der<br />
Zusammenhang der Datenstruktur ist, desto größer sollte auch der Datensatz sein.<br />
Trotz dieser anwendungsbezogenen Probleme bieten MLP auf Gr<strong>und</strong> ihrer<br />
spezifischen Eigenschaften (Nichtlinearität, Lernfähigkeit usw.) viele Potenziale <strong>und</strong><br />
ein breites Einsatzgebiet (vgl. Kapitel 3.3).<br />
3.2.4 Self-Organizing-Maps<br />
Die Self-Organzing-Maps (SOM, Selbstorganisierende Karten) oder auch Kohonen-<br />
Netze sind neben den MLP ein ebenfalls weit verbreiteter Netzwerktyp (MEYER<br />
2002: 202). Sie wurden 1981 <strong>von</strong> Kohonen entwickelt <strong>und</strong> gehören zu den<br />
unüberwachten Lernverfahren (KOHONEN 1995: 2001). Die Architektur eines SOM<br />
wird in Abbildung 22 aufgezeigt. Es ist demnach ein einfach konstruiertes<br />
zweischichtiges, vorwärtsgerichtetes (feedforward) KNN, mit einer Inputschicht zur<br />
externen Informationsaufnahme <strong>und</strong> einer zweidimensionalen Outputschicht. Jedes<br />
Neuron der Eingabeschicht ist mit jedem Neuron der Ausgabeschicht durch<br />
Verbindungsgewichte verb<strong>und</strong>en. Auch die Neuronen der Ausgabeschicht<br />
48 Die Berechnung eines <strong>Neuronalen</strong> Netzes kann im extremsten Fall einige St<strong>und</strong>en bis Tage<br />
dauern.<br />
48
3 Methodische Gr<strong>und</strong>legung<br />
(Kartenschicht) sind miteinander verknüpft, was Rückkopplungen der Karte auf sich<br />
selbst ermöglicht (PETERSOHN 1997: 94). 49<br />
Abbildung 22: Topologie einer Self-Organizing-Map<br />
Quelle: Eigene Darstellung in Anlehnung an MEYER 2002: 202; SCHÜLER 2002: 282<br />
Als struktur-entdeckendes Verfahren bieten die SOM die Möglichkeit, eine beliebige<br />
Menge <strong>von</strong> Objekten (z. B. K<strong>und</strong>en) nach ihren Ähnlichkeiten, eine bestimmte<br />
Anzahl <strong>von</strong> Merkmalen (oder auch Variablen z.B. Umsatz, Haushaltsgröße), zu<br />
ordnen. Die Objekte werden dabei solange auf der Karte (Fläche) verschoben, bis die<br />
ähnlichsten Objekte nebeneinander liegen (PODDIG et al. 2001: 383). Diese Objekte<br />
werden dann in Gruppen zusammengefasst. Das Ziel des Lernprozesses der SOM ist<br />
es, dass die Objekte innerhalb der Gruppen möglichst homogen <strong>und</strong> die Gruppen<br />
zueinander möglichst heterogen sind (SPSS 2003d: 324). Demnach haben die SOM<br />
<strong>und</strong> das multivariate Verfahren der Clusteranalyse das gleiche Ziel (vgl. Kapitel<br />
3.1.3). 50 Es ist deshalb nicht verw<strong>und</strong>erlich, dass sich die Ablaufschritte (vgl.<br />
Abbildung 9 <strong>und</strong> Abbildung 23) der beiden Verfahren ähneln. Dementsprechend<br />
werden im Folgenden nur die Schritte 1 bis 3 aus Abbildung 23 näher dargestellt.<br />
Insgesamt beruht der hier dargestellte Verfahrensablauf auf einer eigenen<br />
49<br />
Die Verbindungslinien zwischen den Outputneuronen in Abbildung 22 stellen keine<br />
Verbindungsgewichte, sondern symbolisieren nur deren Ordnungsrelation in der Ausgabeschicht.<br />
50 Obwohl man die SOM, wie in Abbildung 10 den Clusterverfahren zuordnen kann, wird dieses<br />
hier terminologisch getrennt. D. h. die Verwendung des Terminus der Clusteranalyse bezieht sich nur<br />
auf die <strong>multivariaten</strong> Clusterverfahren.<br />
49
3 Methodische Gr<strong>und</strong>legung<br />
methodischen Erforschung im Rahmen dieser Arbeit, da die Literatur bisher kaum<br />
anwenderorientierte Ausführungen aufweist.<br />
Abbildung 23: Ablaufschritte bei den Self-Organizing-Maps<br />
Schritt 1<br />
Auswahl <strong>von</strong> Variablen<br />
Schritt 2<br />
Festlegung des Outputgitters<br />
Schritt 3<br />
Trainieren der SOM<br />
Schritt 4<br />
Prüfung des Netzergebnisses<br />
externe<br />
Prüfung<br />
interne<br />
Prüfung<br />
relative<br />
Prüfung<br />
Schritt 5<br />
Interpretation der Cluster<br />
Quelle: Eigene Darstellung<br />
Zunächst erfolgt die Auswahl der Inputvariablen, welche gleichzeitig den<br />
Inputneuronen entsprechen. Die Eingangsvariablen können nominal, ordinal oder<br />
metrisch skaliert sein. Wie bei der Clusteranalyse hat die Auswahl der aktiven<br />
Variablen den größten Einfluss auf das Gruppierungsergebnis. Nach GIERL et al.<br />
(2001: 130) wird die Anzahl der Eingabeneuronen in der Literatur meist auf vier bis<br />
acht beschränkt. Es ist ebenfalls möglich bei einer hohen Anzahl an Variablen eine<br />
Faktorenanalyse vorzuschieben (ebd.).<br />
50
3 Methodische Gr<strong>und</strong>legung<br />
Die optimale Clusteranzahl des Datensatzes wird automatisch durch den<br />
Trainingsprozess der SOM bestimmt (SPSS 2003d: 325). Jedoch kann durch die<br />
Festlegung der Dimension (Breite <strong>und</strong> Länge) des Outputgitters (Karte) auf die<br />
Anzahl der Ausgabeneuronen <strong>und</strong> somit auch auf die Anzahl der Cluster Einfluss<br />
genommen werden. Um möglichst brauchbare Ergebnisse zu erzielen, sollte die<br />
Karte jedoch nicht zu groß spezifiziert werden.<br />
Während des Trainings (Schritt 3) der SOM konkurrieren die Outputneuronen<br />
untereinander um jedes Objekt. Hat ein Neuron ein Objekt gewonnen, so werden die<br />
Verbindungsgewichte dieses Siegerneurons <strong>und</strong> seiner Nachbarneuronen der Art<br />
angepasst, dass die Werte des Objektes, bestimmt durch die Inputvariablen, besser<br />
vorausgesagt werden. Im Laufe des Trainingsprozesses werden die Gewichte der<br />
Outputgitterneuronen so angenähert, dass sie eine zweidimensionale Karte erzeugen<br />
(deshalb Self-Organizing-Maps), in der benachbarte Cluster durch benachbarte<br />
Neuronen repräsentiert werden (SPSS 2003d: 324f.). 51 Die Genauigkeit der<br />
Anpassung der Verbindungsgewichte kann der Anwender, wie bei den MLP, durch<br />
die Höhe der Lernraten vorgeben. Das Training wird abgebrochen bzw. beendet,<br />
wenn die Gewichtsanpassungen nur noch sehr klein sind oder eine bestimme Anzahl<br />
an Durchläufen stattgef<strong>und</strong>en hat. 52<br />
Die Überprüfung sowie die Interpretation des Ergebnisses der SOM (Schritt 4 <strong>und</strong> 5)<br />
erfolgt analog zur Clusteranalyse (vgl. Kapitel 3.1.3).<br />
Wie bei den MLP wurde auch bei den SOM aufgezeigt, dass der Anwender<br />
Kenntnisse <strong>und</strong> Erfahrungen mitbringen muss, um die KNN effizient einsetzen zu<br />
können. Dem Trial-and-Error Prozess sollte er durch ein systematisches <strong>und</strong><br />
sachlogisches Vorgehen vorbeugen.<br />
51 Als Ähnlichkeitsmaß verwenden die SOM das Euklidische Distanzmaß (SPSS 2003a: 50).<br />
52 Einen ausführlicheren Überblick über den Lernprozess der SOM gibt KOHONEN (2001).<br />
51
3 Methodische Gr<strong>und</strong>legung<br />
3.3 Eigenschaften Neuronaler Netze im <strong>Vergleich</strong> zu den<br />
<strong>multivariaten</strong> Verfahren<br />
Nachdem in den vorhergehenden Kapiteln die Verfahren der <strong>multivariaten</strong> Statistik<br />
<strong>und</strong> der künstlichen <strong>Neuronalen</strong> Netze vorgestellt wurden, werden im Rahmen dieses<br />
Abschnittes zunächst, in Anlehnung an Abbildung 24, blockweise die speziellen<br />
Eigenschaften der <strong>Neuronalen</strong> Netze den <strong>multivariaten</strong> Verfahren in Bezug auf die<br />
statistischen Problemsituationen gegenübergestellt. Anschließend werden der Trialand-Error<br />
Prozess sowie das Black-Box Prinzip in Hinblick auf die vorgestellten<br />
statistischen Verfahren näher untersucht.<br />
Abbildung 24: Eigenschaften Neuronaler Netze <strong>und</strong> statistische Problemsituationen<br />
in der Primärforschung 53<br />
Quelle: Eigene Darstellung in Anlehnung an WIEDMANN et al. 2003: 49<br />
53 Die aufgezeigte Dynamik eines Systems berücksichtigt insbesondere die zeitliche Entwicklung<br />
eines Merkmals (Variable), welche in vielen ökonomischen Vorgängen eine wichtige Rolle spielt.<br />
Diese Dynamik wird vor allem durch Lernen unter Verwendung <strong>von</strong> Beispieldaten innerhalb des<br />
KNN berücksichtigt (WIEDMANN et al. 2003: 50). Da im Rahmen der Primärforschung selten<br />
Zeitreihen mit einbezogen werden, wird dieser Punkt hier nicht näher betrachtet.<br />
52
3 Methodische Gr<strong>und</strong>legung<br />
Nichtlinearität<br />
Neuronale Netze können jeden nichtlinearen funktionellen Zusammenhang, wie z. B.<br />
die Interaktionen zwischen den Eingabevariablen darstellen <strong>und</strong> sind deshalb nicht<br />
auf die gewichtete Addition (Linearität) der Inputvariablen wie bei vielen<br />
<strong>multivariaten</strong> Verfahren (z. B. lineare Regressionsanalyse <strong>und</strong> Diskriminanzanalyse)<br />
beschränkt (STRECKER 1997: 28). Sie vermögen deshalb die Komplexität <strong>und</strong><br />
Intransparenz einer statistischen Problemsituation besser aufzudecken (WIEDMANN et<br />
al. 2003: 49).<br />
Lernfähigkeit<br />
KNN werden durch Lernverfahren auf Basis <strong>von</strong> Beispieldaten trainiert. Der<br />
Anwender benötigt im Gegensatz zu den <strong>multivariaten</strong> Verfahren keine expliziten<br />
problembezogenen Annahmen (Wissen) über die Zusammenhänge (HEIMEL 1994:<br />
30; STRECKER 1997: 28). Oder anders gesagt, neuronale Netze benötigen keine<br />
Regeln um ein Problem detailliert zu beschreiben, sondern Beispiele (Erfahrungen)<br />
(PETERSOHN 1997: 78). Durch diese Lernfähigkeit können sich KNN dynamisch an<br />
die Bedingungen der Problemsituation anpassen (Flexibilität des KNN), sofern sich<br />
die Datengr<strong>und</strong>lage nicht verändert oder der Anwender durch die Beeinflussung des<br />
Lernverhaltens (Einstellungen der Lernrate, Lernschritte) einen Algorithmus für ein<br />
Problem vorschreibt (ANDERS 1996: 164; PETERSOHN 1997: 78; WIEDMANN et al.<br />
2003: 49).<br />
Variablenanzahl<br />
Die beiden erstgenannten Eigenschaften (Lernfähigkeit <strong>und</strong> Nichtlinearität) werden<br />
bei einer geringen Anzahl <strong>von</strong> Variablen zum Teil auch <strong>von</strong> <strong>multivariaten</strong> Verfahren<br />
ermöglicht. Jedoch können KNN eine besonders große Anzahl <strong>von</strong> erklärenden<br />
Variablen in den Lernprozess mit einbeziehen. Dieses ermöglicht dem <strong>Neuronalen</strong><br />
Netzwerk, die Komplexität einer Datenstruktur besser zu durchdringen bzw. offen zu<br />
legen (WIEDMANN et al. 2003: 49). Die Dimensionalität des Begriffes der<br />
Komplexität umfasst dabei im mathematischen Sinn zum einen den Grad der<br />
Nichtlinearität <strong>und</strong> zum anderen die Anzahl der Variablen (vgl. Abbildung 25)<br />
(REHKUGEL et al. 1994: 13-20). Während es mit den <strong>multivariaten</strong> Verfahren nur<br />
möglich ist, entweder mit wenigen Variablen einen hohen Grad an Nichtlinearität<br />
53
3 Methodische Gr<strong>und</strong>legung<br />
(Analysis) oder umgekehrt mit vielen Variablen einen geringen Grad an<br />
Nichtlinearität (Lineare Algebra) zu erreichen, können KNN beide Dimensionen<br />
verwirklichen. Es ist jedoch darauf hinzuweisen, dass eine höhere Anzahl an<br />
Inputvariablen zwar eine Verbesserung der Anpassung an die beobachteten<br />
Ausgabedaten bedeutet, was aber nicht notwendigerweise mit einer besseren<br />
Approximation der gesuchten Funktion einhergeht (ANDERS 1996: 164).<br />
Abbildung 25: Dimension der Komplexität<br />
Quelle: Eigene Darstellung in Anlehnung an REHKUGEL et al. 1994: 13<br />
Parallelität <strong>und</strong> Fehlertoleranz<br />
Die Parallelität der Informationsverarbeitung innerhalb der Netzwerkarchitektur<br />
verteilt den Input über viele Neuronen. Dadurch bleibt das KNN auch funktionsfähig<br />
beim Ausfall einiger Bausteine (z. B. Entfernung oder Fehlfunktion <strong>von</strong><br />
Verbindungen <strong>und</strong> Verarbeitungseinheiten) oder bei der Aufnahme unsicherer oder<br />
fehlerhafter Inputsignale. Daraus ergibt sich auch die Robustheit bzw. Fehlertoleranz<br />
gegenüber Datenmängeln (STRECKER 1997: 28; ZELL 2003: 27). Dieses bedeutet aber<br />
nicht, dass die Genauigkeit der Ergebnisse (des Outputs) erhalten bleibt. Sondern es<br />
besteht sogar die Gefahr, dass sich das Neuronale Netz aufgr<strong>und</strong> seiner Flexibilität<br />
den fehlerhaften Daten anpasst (ANDERS 1996: 164). Somit sollten Datensätze vor<br />
der Analyse mit KNN ebenso wie vor der Anwendung <strong>von</strong> <strong>multivariaten</strong> Verfahren<br />
auf Ausreißer hin untersucht werden.<br />
54
3 Methodische Gr<strong>und</strong>legung<br />
„Trial-and-Error“ Entwicklungsprozess<br />
Bei der Darstellung der MLP <strong>und</strong> der SOM (vgl. Kapitel 3.2.3 <strong>und</strong> 3.2.4) wurde<br />
schon deutlich, dass der Entwicklungsprozess eines KNN experimentell-explorativ<br />
verläuft. Denn im Gegensatz zu den <strong>multivariaten</strong> Verfahren liegen in der Literatur<br />
keine allgemeingültigen Handlungsanweisungen für den Aufbau des <strong>Neuronalen</strong><br />
Netzwerkes vor (STRECKER 1997: 29f.). Der Anwender unterliegt deshalb einem<br />
Trial-and-Error Prozess in dem er die Netzwerktopologie <strong>und</strong> die Lernregeln so<br />
lange variiert bis er ein akzeptables Ergebnis erreicht. Dadurch erhöht sich<br />
letztendlich in erheblichem Maße die Entwicklungs- bzw. Vorbreitungszeit zur<br />
Lösung eines statistischen Problems (ebd.). Diesem Prozess kann der Praktiker nur<br />
durch ein systematisches Vorgehen bei der Netzwerkentwicklung begegnen. Auch<br />
benötigt er Kenntnisse <strong>und</strong> Erfahrungen im Umgang mit KNN (PODDIG et al. 2001:<br />
369). Es soll jedoch nicht suggeriert werden, dass künstliche Neuronale Netze einem<br />
größeren subjektiven Einfluss in der Ergebnisentwicklung unterliegen <strong>und</strong> mehr<br />
Anwenderwissen benötigen als multivariate Verfahren. Denn auch diese unterliegen<br />
häufig einem Trial-and-Error Prozess, z. B. die Faktor- <strong>und</strong> Clusteranalyse. Der<br />
entscheidende Unterschied zwischen den beiden Verfahrensklassen liegt bei diesem<br />
Problem vor allem darin, dass bisher im <strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren<br />
nur wenige wissenschaftliche Erkenntnisse über den praktischen Gebrauch der<br />
neuronalen Netze vorhanden sind.<br />
„Black-Box“ Modelle<br />
Neuronale Netze unterliegen häufig dem Vorwurf, sie seien „Black-Box“ Modelle,<br />
denn es sei nicht nachvollziehbar, welche Prozesse zwischen der Eingabe- <strong>und</strong><br />
Ausgabeschicht durchgeführt werden (Abbildung 26) (STRECKER 1997: 29f.;<br />
WILBERT 1996: 257-264). Diese Prozesse verlaufen aufgr<strong>und</strong> der konfigurierten<br />
Lernverfahren automatisch in der internen Zwischenschicht des Netzwerkes <strong>und</strong><br />
führen so zu einer komplizierten Analysierbarkeit <strong>und</strong> damit einhergehenden<br />
eingeschränkten Nachvollziehbarkeit der Verarbeitungsentscheidungen des KNN.<br />
Während STRECKER (1997: 29f.) <strong>und</strong> WILBERT (1996: 257-264) die Ergebnisse bzw.<br />
Entscheidungen der Netzausgabe aufgr<strong>und</strong> des fehlenden Lösungsweges für schwer<br />
interpretierbar halten, sehen WIEDMANN et al. (2003: 74), dass Problem darin, dass<br />
Neuronale Netze „lediglich komplexe Zusammenhänge der Realität abbilden“, <strong>und</strong><br />
55
3 Methodische Gr<strong>und</strong>legung<br />
somit nicht sie, „sondern die Realität für uns Menschen eine „Black Box“<br />
darstellt“. 54<br />
Abbildung 26: Blackbox-Ansatz<br />
Quelle: Eigene Darstellung in Anlehnung an WILBERT 1996: 257<br />
Nach STRECKER (1997: 29) kann jedoch die eben genannte Problematik letztendlich<br />
zu einer geringeren Ergebnisakzeptanz in der praktischen Anwendung <strong>von</strong><br />
<strong>Neuronalen</strong> <strong>Netzen</strong> führen. Es stellt sich jedoch darüber hinaus die Frage, ob für den<br />
Marktforschungspraktiker mit geringen Methodenwissen die komplizierten<br />
<strong>multivariaten</strong> Verfahren, z. B. die Cluster-, Faktor <strong>und</strong> Diskriminanzanalyse, bedingt<br />
durch einfache Anwendersoftware, nicht ebenfalls als Black Box-Prinzip erscheinen.<br />
Demnach sollten zunächst empirische Untersuchungen über das Wissen <strong>und</strong> den<br />
Gebrauch <strong>von</strong> statistischen Methoden in der Praxis erfolgen, bevor man einer ganzen<br />
Verfahrenklasse (den <strong>Neuronalen</strong> <strong>Netzen</strong>) das Black-Box Prinzip unterstellt.<br />
Die in diesem Kapitel aufgezeigten Eigenschaften der <strong>Neuronalen</strong> Netze machen<br />
deutlich, dass unter gewissen Einschränkungen mit ihrer Hilfe neuartige Modelle<br />
statistischer Problemsituationen gebildet werden können.<br />
In dem nun folgenden empirischen Teil dieser Arbeit soll aufgezeigt werden,<br />
inwieweit die KNN die hier aufgezeigten Eigenschaften <strong>und</strong> Potenziale in der<br />
54 WIEDMANN et al. (2003: 74) beschreibt als Analogie dazu, dass ein PC Anwender ja auch nicht<br />
weiß wie dieser funktioniert <strong>und</strong> trotzdem dessen Ergebnissen vertraut.<br />
56
3 Methodische Gr<strong>und</strong>legung<br />
Primärforschung verwirklichen können. Um diese Frage zu beantworten, zeigt das<br />
anschießende Kapitel zunächst ein Überblick zum Stand der Forschung. Erst darauf<br />
hin erfolgt auf Basis <strong>von</strong> Bewertungskriterien <strong>und</strong> anhand <strong>von</strong> zwei Fallstudien der<br />
<strong>Vergleich</strong> zwischen den <strong>multivariaten</strong> Verfahren <strong>und</strong> den KNN.<br />
57
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
4.1 Zum Stand der Forschung<br />
Über die Einsatzmöglichkeiten <strong>von</strong> <strong>Neuronalen</strong> <strong>Netzen</strong> existiert eine Vielzahl <strong>von</strong><br />
Untersuchungen. Nach GYAN et al. (2004) wurden in der Periode <strong>von</strong> 1999 bis 2003<br />
schätzungsweise 22.500 Zeitschriftenartikel <strong>und</strong> 13.800 Konferenzpapiere in den<br />
verschiedensten Forschungsfeldern (<strong>von</strong> der Biologie bis zur Ökonomie) über KNN<br />
veröffentlicht. 55 Angesichts dieser hohen Anzahl <strong>von</strong> Publikationen ist es nicht<br />
verw<strong>und</strong>erlich, dass neben GYAN et al. (2004) auch andere Autoren (KRYCHA et al.<br />
1999, SHARDA et al. 1998, VELLIDO et al. 1999) den Schwerpunkt ihrer Studien nur<br />
auf die Auswertung <strong>von</strong> schon publizierten Artikeln zur Verwendung <strong>von</strong> KNN im<br />
Marketing beziehen.<br />
Im Rahmen dieses Kapitels werden unter anderem die Ergebnisse der oben<br />
genannten Autoren mit denen der eigenen Bestandsaufnahme verglichen. Primäres<br />
Ziel ist es jedoch zu überprüfen, inwieweit die bestehende Literatur einen Beitrag zur<br />
Forschungsfrage (vgl. Abschnitt 2.2) leisten kann. 56 Aufgr<strong>und</strong> dieser Fragestellung<br />
wurden nur Publikationen aus der Marktforschung untersucht, die einen<br />
Methodenvergleich zwischen den in Kapitel 3 aufgeführten Verfahren aufweisen.<br />
Tabelle 3, 4 <strong>und</strong> 5 geben einen Überblick über ausgewählte Forschungsergebnisse<br />
auf diesem Gebiet. Neben dem Autor, dem Jahr der Veröffentlichung <strong>und</strong> einer<br />
kurzen Beschreibung des Untersuchungsschwerpunktes, werden jeweils die<br />
wesentlichen Forschungsergebnisse in komprimierter Form dargestellt.<br />
55 Über die Anzahl der Veröffentlichungen, die in die Forschungsrichtung des betriebswirtschaftlichen<br />
Marketings fallen, liegen jedoch keine Zahlen vor.<br />
56 Ziel der Arbeit ist es, zu untersuchen, ob durch den Einsatz <strong>von</strong> künstlichen <strong>Neuronalen</strong> <strong>Netzen</strong><br />
in der Primärforschung, eine Verbesserung der Informationsgewinnung im <strong>Vergleich</strong> zu den bisher<br />
eingesetzten <strong>multivariaten</strong> Verfahren möglich ist (vgl. Kapitel 1).<br />
58
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Tabelle 3: Ausgewählte Literatur zum Verfahrensvergleich in der Sek<strong>und</strong>ärforschung<br />
Autor<br />
(Jahr)<br />
ALON et al.<br />
(2001)<br />
BARTHELE-<br />
MY et al.<br />
(2003)<br />
CHAN et al.<br />
(2000)<br />
ERXLEBEN<br />
et al. (1992)<br />
HEIMEL<br />
(1994)<br />
HIPPNER et<br />
al. (2001a)<br />
HOFFMANN<br />
(2004)<br />
HRUSCHKA<br />
et al.<br />
(2001b,<br />
2004) <strong>und</strong><br />
PROBST<br />
(2002)<br />
(Teil 1)<br />
Typologisierung <strong>von</strong><br />
sehr kleinen<br />
Unternehmen<br />
Vorhersage <strong>von</strong><br />
Finanzzeitreihen im<br />
Aktienmarkt<br />
Klassifikation <strong>von</strong><br />
Unternehmen in der<br />
Krisenfrüherkennung<br />
Kaufverhalten bei<br />
kurzlebigen Konsumgütern<br />
(Universalwaschmittelmarkt)<br />
Kreditwürdigkeitsprüfung<br />
im Versandhandel<br />
Werbewirkungsforschung<br />
in<br />
verschiedenen<br />
Branchen<br />
Analyse der Markenwahlentscheidungen<br />
bei Ketchup <strong>und</strong><br />
Erdnussbutter<br />
(Scannerdaten)<br />
Untersuchungsschwerpunkt/<br />
Anwendungsgebiet<br />
Vorhersage <strong>von</strong><br />
Einzelhandelsumsätzen<br />
Stichprobengröße<br />
DW<br />
Verfahrensvergleich<br />
MLP vs.<br />
MRA<br />
459 SOM vs.<br />
CLU (Ward,<br />
K-Means)<br />
650 MLP vs.<br />
MRA<br />
3539 NDA vs.<br />
DA<br />
2198 MLP vs.<br />
LOGR<br />
159165 MLP vs. DA<br />
vs. LOGR<br />
vs. EB<br />
2713 MLP vs.<br />
MRA<br />
811<br />
Ketchup<br />
960<br />
Erdnuss<br />
butter<br />
MLP vs.<br />
MNR<br />
Ergebnisse<br />
Überlegenheit der MLP. Diese<br />
benötigen aber Expertenwissen<br />
<strong>und</strong> einen höheren Softwareaufwand.<br />
Die Ergebnisse sind<br />
schwer zu interpretieren.<br />
SOM, Ward <strong>und</strong> K-Means CLU<br />
Algorithmus erbringen im<br />
Wesentlichen die gleichen<br />
Ergebnisse. Die SOM sind<br />
jedoch weniger anfällig für<br />
Datenfehler.<br />
<strong>Vergleich</strong>bare Ergebnisse.<br />
Eignung der KNN für die<br />
Krisenfrüherkennung, aber<br />
keine abschließende<br />
Beurteilung, ob die KNN der<br />
DA überliegen.<br />
Überlegenheit der MLP.<br />
Problematisch erwies sich<br />
jedoch die Interpretation der<br />
Netzwerkarchitektur bei den<br />
MLP.<br />
Überlegenheit der MLP.<br />
Problematisch erwies sich<br />
jedoch die Interpretation der<br />
Ergebnisse.<br />
<strong>Vergleich</strong>bare Ergebnisse.<br />
Jedoch weisen die Ergebnisse<br />
der MRA zum Teil erhebliche<br />
Prämissenverletzungen auf.<br />
Überlegenheit der MLP. Zur<br />
Erzielung robuster Ergebnisse<br />
sind jedoch relativ große<br />
Schätzsamples notwendig. Dies<br />
führt wiederum zu langen<br />
Rechenzeiten. Die Ergebnisse<br />
sind schwer zu interpretieren.<br />
Überlegenheit der SOM.<br />
KIANG et al.<br />
(2005a,b)<br />
Marktsegmentierung<br />
<strong>von</strong> Telefonk<strong>und</strong>en<br />
3602 SOM vs. K-<br />
Means<br />
QI et al. Vorhersage für die 1804 MLP vs.<br />
(2003) Entscheidung eines<br />
LOGR<br />
Kreditkarteneinsatzes<br />
DA = Diskriminanzanalyse EB = Entscheidungsbaum<br />
LOGR= Logistische Regressionsanalyse MLP = Multi-Layer-Perceptrons<br />
MRA = Multiple Regressionsanalyse NDA = Neuronale Diskriminanzanalyse<br />
SOM = Self-Organizing-Maps CLU = Clusteranalyse<br />
DW = Data Warehouse MNR = Multinomiale-logistische-Regression<br />
Quelle: Eigene Darstellung<br />
Erheblich bessere Ergebnisse<br />
der MLP.<br />
59
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Tabelle 4: Ausgewählte Literatur zum Verfahrensvergleich in der Sek<strong>und</strong>ärforschung<br />
Autor<br />
(Jahr)<br />
SÄUBERLICH<br />
(2003)<br />
SHIN et al.<br />
(2004)<br />
SMITH et al.<br />
(2000)<br />
THIEME et<br />
al. (2000)<br />
TIETZ et al.<br />
(2001)<br />
URBAN<br />
(1998)<br />
WEBER<br />
(2003b)<br />
WEBER<br />
(2001)<br />
WEINGÄRT-<br />
NER (2001)<br />
(Teil 2)<br />
Segmentierung <strong>von</strong><br />
Aktienhandelsk<strong>und</strong>en<br />
Verfahrensvergleich<br />
K<strong>und</strong>enbindungsanalyse<br />
in der Versicherungsbranche<br />
Entscheidungsunterstützung<br />
bei der<br />
Neuentwicklung <strong>von</strong><br />
Produkten<br />
Cross-Selling-<br />
Optimierung <strong>von</strong><br />
Finanzprodukten<br />
Werbemitteleinsatzplanung<br />
im Versandhandel<br />
Medienforschung zur<br />
Vorhersage des<br />
Fernsehverhaltens<br />
Medienforschung<br />
zum Publikumserfolg<br />
<strong>von</strong> Spielfilmen<br />
Web Mining für<br />
Online Shops<br />
Untersuchungsschwerpunkt/<br />
Anwendungsgebiet<br />
Web Mining für<br />
Online Shops<br />
Stichprobengröße<br />
22000 MLP vs.<br />
MRA vs. EB<br />
3000 SOM vs. K-<br />
Means vs.<br />
Fuzzy K-<br />
Means<br />
20914 MLP vs.<br />
LOGR vs.<br />
EB<br />
612 MLP vs. K-<br />
Means vs.<br />
MNR vs.<br />
MRA vs.<br />
DA<br />
160716 MLP vs.<br />
LOGR vs.<br />
EB<br />
22000 MLP vs. DA<br />
vs. LOGR<br />
5200 MLP vs.<br />
MRA<br />
209 MLP vs.<br />
MRA<br />
300000 MLP vs.<br />
LOGR vs.<br />
EB<br />
Ergebnisse<br />
Überlegenheit der MLP. Die<br />
MLP sind aber im Gegensatz zu<br />
den anderen Verfahren eine<br />
Black Box.<br />
Überlegenheit der Fuzzy K-<br />
Means. Die SOM überliegen<br />
aber der K-Means Clusterung.<br />
Überlegenheit <strong>und</strong> bessere<br />
Generalisierung der MLP.<br />
Überlegenheit der MLP.<br />
Problematisch erwies sich<br />
jedoch die Interpretation der<br />
Parameter des neuronalen<br />
Netzes.<br />
Überlegenheit der EB. Die MLP<br />
überliegen jedoch den LOGR.<br />
Problematisch erwies sich die<br />
Interpretation der MLP<br />
Ergebnisse.<br />
Bessere Ergebnisse der MLP.<br />
Jedoch weisen diese eine<br />
geringe Transparenz <strong>und</strong><br />
wissenschaftliche F<strong>und</strong>ierung<br />
auf.<br />
Geringfügige Überlegenheit der<br />
MLP.<br />
Erheblich bessere Ergebnisse<br />
der MLP. Jedoch benötigen<br />
diese ein hohes Maß an<br />
Erfahrungen, Experimentierfreude<br />
<strong>und</strong> Rechenzeit.<br />
Überlegenheit der MLP. Jedoch<br />
konnte der Weg zur Lösung<br />
nicht erklärt werden (Black-<br />
Box-Effekt).<br />
Überlegenheit der neuronalen<br />
WIEDMANN Marktsegmentierung 12582 NDA vs.<br />
et al. (1995) <strong>von</strong> PKW-Nutzern<br />
DA Diskriminanzanalyse.<br />
WIEDMANN Käuferverhalten bzw. DW MLP vs. DA Überlegenheit der MLP<br />
et al. Kaufgründe für PKW<br />
gegenüber der konventionellen<br />
(2003a) Marken<br />
Methode.<br />
DA = Diskriminanzanalyse EB = Entscheidungsbaum<br />
LOGR= Logistische Regressionsanalyse MLP = Multi-Layer-Perceptrons<br />
MRA = Multiple Regressionsanalyse NDA = Neuronale Diskriminanzanalyse<br />
SOM = Self-Organizing-Maps CLU = Clusteranalyse<br />
DW = Data Warehouse MNR = Multinomiale-logistische-Regression<br />
Quelle: Eigene Darstellung<br />
60
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Bei den Auswertungen der Tabellen 3 <strong>und</strong> 4 wird deutlich, dass der größte Teil der<br />
Forschungsarbeiten aus dem Data-Mining bzw. der Sek<strong>und</strong>ärforschung stammt.<br />
Dieses wird neben dem Untersuchungsschwerpunkt vor allem auch durch die sehr<br />
großen Stichproben der jeweiligen Studien ersichtlich. GYAN et al. (2004: 3) <strong>und</strong><br />
SHARDA et al. (1998: 3f.) bestätigen diese Beobachtung. In Bezug auf die<br />
Verwendung <strong>von</strong> KNN in der Primärforschung konnten nur drei Studien gef<strong>und</strong>en<br />
werden. Dadurch wird der Ansatz dieser Arbeit, die KNN, die bislang im Rahmen<br />
des Data-Mining-Prozesses Einsatz fanden, direkt auf die in der Primärforschung<br />
erhobenen Daten anzuwenden bestätigt (vgl. Kapitel 2.2). Es muss jedoch darauf<br />
hingewiesen werden, dass die Ergebnisse der Tabelle 5 sicherlich nicht repräsentativ<br />
sind. Insbesondere deswegen, weil dort nur Studien über die SOM vorliegen.<br />
Tabelle 5: Ausgewählte Literatur zum Verfahrensvergleich in der Primärforschung<br />
Autor<br />
(Jahr)<br />
Anwendungsgebiet<br />
Untersuchungs-<br />
Stichproben-<br />
Verfahrensvergleich<br />
Ergebnisse<br />
DOLNICAR<br />
(1997)<br />
HRUSCHKA<br />
et al. (1999)<br />
LÖBLER et<br />
al. (2001)<br />
schwerpunkt<br />
Marktsegmentierung<br />
in der Tourismusbranche<br />
Marktsegmentierung<br />
<strong>von</strong> Haushaltsreinigermarken<br />
K<strong>und</strong>ensegmentierung<br />
im Automobilhandel<br />
KNN = künstliches Neuronales Netzwerk<br />
Quelle: Eigene Darstellung<br />
größe<br />
7864 SOM vs. K-<br />
Means<br />
n= 854 spezielles<br />
KNN vs. K-<br />
Means<br />
? SOM vs. K-<br />
Means<br />
Annährend gleiche Ergebnisse.<br />
Jedoch erwiesen sich die SOM<br />
als nicht benutzerfre<strong>und</strong>lich.<br />
Überlegenheit des KNN.<br />
Die SOM weisen bessere<br />
Klassifizierungsergebnisse auf.<br />
Die Interpretation der<br />
gebildeten Segmente (SOM)<br />
erwies sich als schlüssig.<br />
SOM = Self-Organizing-Maps<br />
In fast allen Untersuchungen aus der Sek<strong>und</strong>ärforschung wurden die MLP<br />
verwendet. Dabei erzielten diese im <strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren außer<br />
bei der Studie <strong>von</strong> TIETZ et al. (2001) gleich gute oder bessere Ergebnisse. VELLIDO<br />
et al. (1999) bestätigt dieses Resultat nach einer Untersuchung <strong>von</strong> 93 Publikationen.<br />
Die MLP offenbarten in den Forschungsstudien jedoch zum Teil erhebliche<br />
anwenderbezogene Probleme. So zeigte sich unter anderem bei HIPPNER et al.<br />
(2001a) <strong>und</strong> THIEME et al. (2000) die Interpretation der Netzwerkarchitektur <strong>und</strong> der<br />
Ergebnisse als sehr problematisch. URBAN (1998) schreibt den MLP deshalb eine<br />
geringe wissenschaftliche F<strong>und</strong>ierung <strong>und</strong> Transparenz zu. Aufgr<strong>und</strong> dieser<br />
Schwierigkeiten sehen SÄUBERLICH (2003) <strong>und</strong> WEINGÄRTNER (2001) den<br />
61
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Verfahrensablauf des MLP als Black-Box an. Um diese Black-Box zu öffnen,<br />
benötigt der Anwender nach WEBER (2003) ein hohes Maß an Erfahrungen <strong>und</strong><br />
Experimentierfreude.<br />
Die Untersuchungsergebnisse zu den SOM entsprechen im Wesentlichen denen der<br />
MLP. So erbrachten bei BARTHELEMY et al. (2003) die SOM die gleichen Ergebnisse<br />
wie die Ward <strong>und</strong> K-Means Clusterung. Jedoch erwiesen sich die KNN als weniger<br />
anfällig gegenüber Datenfehlern. Die Berechnungen <strong>von</strong> HRUSCHKA et al. (1999) <strong>und</strong><br />
SHIN et al. (2004) wiesen den SOM ein besseres Klassifizierungsergebnis zu als den<br />
<strong>multivariaten</strong> Clusterverfahren. Während sich bei LÖBLER et al. (2001) die<br />
Interpretation der SOM als schlüssig erwies, bezeichnet DOLNICAR (1997) die SOM<br />
als nicht benutzerfre<strong>und</strong>lich.<br />
Im Hinblick auf die Bewertung der Einsatzmöglichkeiten <strong>von</strong> <strong>Neuronalen</strong> <strong>Netzen</strong> zur<br />
Lösung <strong>von</strong> statistischen Problemen in der Primärforschung, liegt als Ergebnis der<br />
Auswertungen der oben aufgeführten Forschungsergebnisse die Vermutung nahe,<br />
dass die KNN, unter der Einschränkung der aufgezeigten Anwendungsprobleme,<br />
bessere Ergebnisse erbringen als die <strong>multivariaten</strong> Verfahren. Jedoch genügen die in<br />
den Tabellen 3, 4 <strong>und</strong> 5 aufgezeigten Ergebnisse nicht, um diese Annahme in Bezug<br />
auf die Primärforschung verifizieren zu können. Auf der Gr<strong>und</strong>lage der im<br />
anschließenden Kapitel aufgezeigten Bewertungskriterien, werden daher im<br />
Folgenden weitere empirische Untersuchungen durchgeführt.<br />
4.2 Bewertungskriterien für die Güte der Verfahren<br />
Für die Bewertung der Leistungsfähigkeit (Informationsgewinnung) <strong>von</strong><br />
<strong>multivariaten</strong> Verfahren <strong>und</strong> künstlichen <strong>Neuronalen</strong> <strong>Netzen</strong> in der Primärforschung<br />
sowie den <strong>Vergleich</strong> dieser Methoden sind geeignete Kriterien festzulegen. In diesem<br />
Kontext können nach Abbildung 27 direkte <strong>und</strong> indirekte Kriterien differenziert<br />
werden (ALEX 1998: 176f).<br />
62
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Abbildung 27: Kriterien zur Beurteilung der Leistungsfähigkeit der Verfahren<br />
Quelle: Eigene Darstellung in Anlehnung an ALEX 1998: 178; BERRY et al. 1997: 422f.; KÜPPERS<br />
1999: 87f.<br />
Die direkten Kriterien (direkt messbar) beziehen sich auf die Lösung einer konkreten<br />
Problemstellung <strong>und</strong> können objektiv z. B. durch statistische Kennzahlen<br />
quantifiziert werden. Sie können weiter in daten- <strong>und</strong> methodenorientierte Kriterien<br />
unterteilt werden. Die datenorientierten Kriterien (Datendeformation, Datenqualität<br />
<strong>und</strong> Datenmengen) beziehen sich darauf, dass bei der Anwendung eines statischen<br />
Verfahrens mitunter Anforderungen bzw. Einschränkungen bezüglich der Daten<br />
bestehen (KÜPPERS 1999: 96). Während das Kriterium „Datendeformation“<br />
untersucht, inwieweit eine Methode Einschränkungen hinsichtlich der<br />
Vorverarbeitung der Daten hat (z. B. Anforderungen an das Skalenniveau), wird bei<br />
der „Datenqualität“ geprüft, ob ein Verfahren gegenüber Fehlern bzw.<br />
unvollständigen Daten anfällig ist. In Bezug auf die „Datenmengen“ wird analysiert,<br />
wie akzeptabel die Laufzeiten (Rechenzeiten) der Verfahren bei großen oder kleinen<br />
Datenbeständen sind (ebd.). Bei den methodenorientierten Kriterien<br />
(Ergebnissicherheit, Generalisierung, Modellprämissen) wird neben den<br />
Analyseergebnissen direkt die angewendete Verfahrensmethodik betrachtet. Dabei<br />
bewertet das Kriterium „Ergebnissicherheit“ durch statistische Kennzahlen, die Güte<br />
63
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
mit der ein Verfahren eine Lösung für eine Problemsituation ermitteln kann (ALEX<br />
1998: 176). Zusätzlich wird durch das Kriterium „Generalisierung“, die Fähigkeit<br />
des trainierten (MLP) oder geschätzten (Regression) Modells, auf neue Daten<br />
sinnvolle Outputdaten zu erzeugen, beurteilt (Allgemeingültigkeit der Ergebnisse)<br />
(BERRY et al. 1997: 423). Die Bewertung der „Modellprämissen“ eines Verfahrens<br />
erfolgt an Hand der Relevanz der Annahmebeschränkungen für die Modellbildung<br />
(KÜPPERS 1999: 94). Eine Methode, für die keine oder weniger Annahmen bezüglich<br />
der zu verarbeitenden Daten vorliegen, gilt dabei als vorteilhafter, als eine für die<br />
viele Prämissen notwendig sind.<br />
Neben den direkten Kriterien können die indirekten oder auch anwenderorientierten<br />
Kriterien formuliert werden. Diese lassen sich schwerer objektiv ermitteln <strong>und</strong> leiten<br />
sich aus dem jeweiligen Einsatzgebiet des Verfahrens sowie der subjektiven<br />
Einschätzung des Anwenders ab. Bezogen auf das betriebswirtschaftliche<br />
Informationsmanagement, spielen diese Kriterien eine besonders wichtige Rolle,<br />
denn die Methoden sollten dem Marktforscher möglichst schnell interessante <strong>und</strong><br />
leicht verständliche Ergebnisse liefern, damit darauf aufbauend die<br />
Entscheidungsträger des Unternehmens flexibel auf neue Marktsituationen reagieren<br />
können. Aufgr<strong>und</strong> dessen werden diese anwenderorientierten Bewertungen<br />
(Interessantheit, Verständlichkeit, Interpretierbarkeit, Bedienbarkeit, Flexibilität,<br />
Verfügbarkeit) im Folgenden detailliert aufgezeigt (vgl. Abbildung 27).<br />
Das Kriterium „Interessantheit“ bezieht sich auf die Einschätzung, welche<br />
Informationen interessant sind <strong>und</strong> welche nicht <strong>und</strong> hängt im Wesentlichen vom<br />
individuellen Anwender ab (ebd. 88). Der Fokus in dieser Arbeit liegt deshalb vor<br />
allem auf der Entdeckung <strong>von</strong> neuen interessanten Mustern in den Datenbeständen. 57<br />
In Bezug auf die Ergebnisse der Verfahren stellt der Anwender die Anforderung,<br />
dass diese einfach nachvollziehbar <strong>und</strong> leicht interpretierbar sind. Dabei bezieht sich<br />
die „Verständlichkeit“ vor allem auf die Nachvollziehbarkeit der hinter der Lösung<br />
stehenden Rechenschritte bzw. Algorithmen. Letztendlich ist eine Methode<br />
verständlich, wenn sie dem Anwender transparent <strong>und</strong> nicht als Black-Box erscheint<br />
57 Einen umfassenden Überblick über die „Interessantheit“ in Datenbeständen gibt KÜPPERS (1999:<br />
88).<br />
64
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
(BERRY et al. 1997: 422). Eine weitere wichtige Voraussetzung für den Einsatz <strong>von</strong><br />
<strong>multivariaten</strong> Verfahren <strong>und</strong> KNN im betrieblichen Informationsmanagement ist,<br />
dass deren „Bedienbarkeit“ (<strong>von</strong> der Eingabe der Daten bis zur Ausgabe der<br />
Ergebnisse) möglichst einfach ist. Dieses beinhaltet darüber hinaus die Robustheit<br />
gegenüber Fehleinstellungen oder Fehlbedienungen (ALEX 1998: 177). Dieses<br />
Kriterium ist neben dem spezifischen Verfahrensablauf vor allem auch <strong>von</strong> der zur<br />
Verfügung stehenden Software abhängig (Kriterium „Verfügbarkeit“). Das letzte<br />
anwenderorientierte Kriterium ist die Forderung nach einer weitgehenden<br />
„Flexibilität“ des Verfahrens. Dieses bezieht sich zum einen auf die<br />
unterschiedlichen Einsatzgebiete einer Methode <strong>und</strong> betrachtet zum anderen den<br />
zeitlichen Aspekt (ebd.). Ein Analyseverfahren ist dann flexibel einsetzbar, wenn es<br />
schnell auf eine neue Problemsituation hin konfiguriert werden kann <strong>und</strong> nur kurze<br />
Rechenzeiten bis zur Projektion der Ergebnisse benötigt.<br />
In dem letzten Abschnitt wurde deutlich, dass es schwierig ist, geeignete Kennzahlen<br />
zur Bewertung der indirekten Kriterien zu definieren, da diese zum Teil der<br />
subjektiven Wahrnehmung unterliegen. In den folgenden Fallstudien zur Lösung<br />
konkreter statistischer Problemstellungen in der Primärforschung liegt daher der<br />
Schwerpunkt auf den ergebnisorientierten Kriterien (Ergebnissicherheit <strong>und</strong><br />
Generalisierung). Erst in Kapitel 5 werden dann die Analyseverfahren anhand der<br />
weiteren Kriterien, gestützt auf die Ergebnisse der Fallstudien, die literarischen<br />
Bestandsaufnahme <strong>und</strong> die methodische Gr<strong>und</strong>legung, bewertet.<br />
4.3 Auswahl der Fallstudien <strong>und</strong> Vorgehensweise<br />
Die Gr<strong>und</strong>lage der sich anschließenden empirischen Untersuchungen für den Einsatz<br />
<strong>von</strong> KNN in der Primärforschung <strong>und</strong> den <strong>Vergleich</strong> mit den <strong>multivariaten</strong> Verfahren<br />
bilden jeweils die Daten zweier Studien des Lehrstuhles für Marketing für<br />
Lebensmittel <strong>und</strong> Agrarprodukte am Institut für Agrarökonomie der Universität<br />
Göttingen. Die Erhebung dieser Primärdaten erfolgte durch standardisierte<br />
Fragebögen bei einem face-to-face Interview. Tabelle 6 gibt einen komprimierten<br />
Überblick über die beiden Fallstudien.<br />
65
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Tabelle 6: Übersicht über die Fallstudien <strong>und</strong> die verwendeten Modelle 58<br />
Fallstudie 2:<br />
Markenpräferenz bei<br />
Chinesischen<br />
Konsumenten/<br />
Typlogisierung<br />
(Strukturentdeckung)<br />
164<br />
Anwohner<br />
800<br />
Konsumenten<br />
MLP = Multi-Layer-Perceptrons<br />
SOM = Self-Organizing-Maps<br />
Quelle: Eigene Darstellung<br />
Fallstudie/<br />
Anwendungsschwerpunkt<br />
Fallstudie 1:<br />
Meinungsforschung<br />
zum Stallbau in<br />
Diemarden/<br />
Ursachenanalyse<br />
(Strukturabbildung)<br />
Stichprobengröße<br />
Verfahrensvergleich<br />
MLP vs.<br />
MRA<br />
SOM vs.<br />
CLU<br />
(Ward,<br />
K-<br />
Means)<br />
Modelle<br />
Modell 1:<br />
explorative Faktorenanalyse mit<br />
anschließender Ursachenanalyse<br />
Modell 2:<br />
Aufnahme aller unabhängigen<br />
Variablen in das Modell mit<br />
anschließendem sequentiellen<br />
Ausschluss nichtsignifikanter<br />
Variablen<br />
Modell 1:<br />
explorative Faktorenanalyse mit<br />
anschließender Clusterung auf Basis<br />
<strong>von</strong> 3 clusterbildenden Variablen<br />
Modell 2:<br />
Clusterung auf Basis <strong>von</strong> 11<br />
clusterbildenden Variablen<br />
MRA = Multiple Regressionsanalyse<br />
CLU = Clusteranalyse<br />
Aufgr<strong>und</strong> der Stichprobengröße, der Erhebungsart (Datengewinnung) sowie des<br />
Anwendungsschwerpunktes (Strukturentdeckung, Strukturabbildung) der Fallstudien<br />
wird deutlich, dass die Datenbestände dieser Untersuchungen als statistische<br />
Problemstellungen in der Primärforschung angesehen werden können <strong>und</strong> somit<br />
deren Verwendung als Ausgangsbasis für den Methodenvergleich im Rahmen dieser<br />
Arbeit gerechtfertigt ist. 59<br />
Die Vorgehensweise beider Fallstudien vollzieht sich gleichermaßen. Zunächst wird<br />
die empirische Basis <strong>und</strong> die Problemstellung der Untersuchung vorgestellt. Darauf<br />
aufbauend werden jeweils zwei Modelle für die <strong>multivariaten</strong> Methoden <strong>und</strong> die<br />
KNN entwickelt, um die Vielfältigkeit anwenderbezogener Fragestellungen<br />
58 Das erste Modell beinhaltet jeweils durch die explorative Faktoranalyse auch ein strukturentdeckendes<br />
Verfahren. Deshalb kann in der zweiten Studie das erste Modell nur eingeschränkt als<br />
struktur-abbildendes Modell betrachtet werden.<br />
59 Für einen umfassenderen Methodenvergleich müssten jedoch in Zukunft noch mehr Fallstudien<br />
mit eingeschlossen werden.<br />
66
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
bezüglich der Verfahren besser abzudecken. 60 Anschließend werden die Ergebnisse<br />
der <strong>multivariaten</strong> Verfahren <strong>und</strong> der KNN präsentiert. 61 Erst daraufhin werden die<br />
Resultate der beiden Verfahrensklassen miteinander verglichen. Dabei muss auf eine<br />
tiefergehende inhaltliche Analyse der Fallstudien verzichtet werden, da dieses den<br />
Rahmen der vorliegenden Arbeit sprengen würde. Der Schwerpunkt liegt deshalb vor<br />
allem auf dem methodischen ergebnisorientierten <strong>Vergleich</strong>.<br />
Für die Berechnungen der Fallstudien wurde zum einem das klassische<br />
Datenanalyse-Tool SPSS 12 (Statistical Package for the Social Sciences) <strong>und</strong> zum<br />
anderen das Data Mining-Tool Clementine 8.5 verwendet. 62<br />
Abbildung 28: Clementine Oberfläche mit Daten-Stream<br />
Quelle: Eigene Darstellung<br />
Das zentrale Softwarekonzept <strong>von</strong> Clementine ist eine prozessorientierte<br />
Benutzeroberfläche, bei der einzelne Datenoperationen durch Knoten dargestellt<br />
werden (Abbildung 28). Die Verbindung mehrerer Knoten untereinander ergibt einen<br />
60 Die anwenderbezogenen Fragestellungen werden in den betreffenden Kapiteln näher dargestellt.<br />
61 Dabei können nicht alle Berechnungen der Analysen aufgezeigt werden. Diese nichtaufgezeigten<br />
Kalkulationen werden jeweils im Anhang dargelegt.<br />
62 Darüber hinaus wurde besonders für die Berechnungen der Gütekriterien (R², MSE usw.) das<br />
Microsoft Office XP-Tool EXCEL verwendet.<br />
67
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Datenstrom (Stream). Durch diese Darstellungsweise wird es dem Benutzer unter<br />
anderem ermöglicht, Datenzugriff, -veränderung <strong>und</strong> -analyse sichtbar zu machen.<br />
Clementine bietet neben anderen Verfahren auch die Möglichkeit, die in dieser<br />
Arbeit verwendeten KNN (MLP, SOM), einzusetzen. 63<br />
4.4 Fallstudie 1: Meinungsforschung zum Stallbau in Diemarden<br />
4.4.1 Empirische Basis <strong>und</strong> Problemstellung der Untersuchung<br />
Die erste Fallstudie zum Verfahrensvergleich zwischen KNN <strong>und</strong> <strong>multivariaten</strong><br />
Verfahren beruht auf einer face-to-face Befragung zu den Einstellungen <strong>von</strong> 164<br />
Anwohnern in Diemarden über den geplanten Bau eines Schweinestalles zweier<br />
Landwirte. Das Dorf Diemarden mit 1358 Einwohnern gehört zur Gemeinde<br />
Gleichen im Landkreis Göttingen (Niedersachsen/Deutschland). 64<br />
Von den 164 durchgeführten Befragungen waren 155 für weitere Analysen<br />
verwertbar. Das entspricht 11,41 % der Gesamtbevölkerung Diemardens. Aufgr<strong>und</strong><br />
dieses hohen Anteils <strong>und</strong> der Zusammensetzung der Stichprobe kann die Studie als<br />
repräsentativ angesehen werden. Der Fragebogen (siehe Anhang E) setzt sich aus<br />
verschiedenen inhaltlichen <strong>und</strong> methodischen Elementen zusammen. Überwiegend<br />
wurden geschlossene Fragen sowie Statementbatterien mit siebenstufigen Likert-<br />
Skalen eingesetzt. In der Regel dauerte die Beantwortung des Fragebogens ca. 15<br />
Minuten. Durchgeführt wurde die Erhebung im November <strong>und</strong> Dezember 2003. Die<br />
Probanden wurden per Random-Verfahren ausgewählt <strong>und</strong> durch geschulte,<br />
studentische Interviewer zur Beantwortung des Fragebogens zu Hause aufgesucht.<br />
Die Stichprobe setzt sich aus 55,5 % männlichen <strong>und</strong> 44,5 % weiblichen Probanten<br />
zusammen. Der größte Anteil der Befragten (81 %) hat eine eigene Wohnung oder<br />
ein eigenes Haus, 15 % sind Mieter. Über die Hälfte der Befragten (56,8 %) leben in<br />
einem 2 bis 3 Personenhaushalt, knapp 32 % wohnen in größeren Haushalten. Die<br />
63 Nach ANGUS (2004: 29) unterstützt Clementine, als eine führende Datenplattform, eine schnelle<br />
<strong>und</strong> gute Marketingentscheidungsfindung in den praktischen Unternehmen.<br />
64 1358 Einwohner mit Hauptwohnsitz (EINWOHNERSTATISTIK GEMEINDE GLEICHEN 2004)<br />
68
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Zahl der Single-Haushalte beträgt 11,1 %. R<strong>und</strong> 26 % der Probanten sind gebürtige<br />
Diemardener, ca. 63 % sind zugezogen. Als höchster Bildungsabschluss dominiert in<br />
der Stichprobe ein abgeschlossenes Hochschulstudium (33,1 %), ca. 10,6 % der<br />
Probanden absolvierten das Gymnasium, 23,2 % die Realschule <strong>und</strong> r<strong>und</strong> 27 % die<br />
Hauptschule. Demnach ist das Bildungsniveau in Diemarden im <strong>Vergleich</strong> zum<br />
b<strong>und</strong>esdeutschen Durchschnitt sehr hoch (STATISTISCHES BUNDESAMT 2004: 121f.).<br />
In Bezug auf die Beschäftigung gaben r<strong>und</strong> 46,4 % an, in einem<br />
Angestelltenverhältnis bei einem staatlichen (12,4 %) oder privat geführten (34 %)<br />
Unternehmen zu stehen sowie ca. 11,1 %, dass sie selbstständig sind. R<strong>und</strong> 22 % der<br />
Befragten sind Rentner oder Pensionäre. Die Arbeitslosenquote lag in der erhobenen<br />
Stichprobe bei nur 1,3 %.<br />
Das Ziel der folgenden Untersuchungen ist, zu analysieren, welche Gründe bzw.<br />
Ursachen bei den Probanten für oder gegen den Stallbau sprechen. Zur Lösung dieser<br />
struktur-beschreibenden Problemstellung bieten sich die Regressionsanalyse aus der<br />
<strong>multivariaten</strong> Statistik sowie die MLP aus den KNN an. Um einen umfassenderen<br />
<strong>Vergleich</strong> der Leistungsfähigkeit der beiden Verfahrensklassen zur Lösung der<br />
Problemsituation zu ermöglichen, wurden zwei Modelle aufgestellt:<br />
Modell 1:<br />
Um die Vielzahl <strong>von</strong> Einflussfaktoren zu berücksichtigen erfolgt im ersten Modell<br />
zunächst eine explorative Faktorenanalyse zur Komplexitätsreduktion. Die dadurch<br />
aufgedeckten <strong>von</strong>einander unabhängigen Einflussgrößen werden dann als exogene<br />
Variablen in der anschließenden Ursachenanalyse verwendet.<br />
Modell 2:<br />
Im zweiten Modell werden zunächst direkt 29 unabhängige Variablen aus der<br />
Faktorenanalyse in die Wirkungsanalyse aufgenommen. Anschließend werden<br />
sequentiell nichtsignifikante exogene Variablen ausgeschlossen.<br />
Mit Hilfe dieser Modelle sollen unter anderem folgende anwenderbezogene<br />
Fragestellungen beantwortet werden:<br />
69
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
• Welche Verfahrensklasse ermittelt die Gründe für oder gegen den Stallbau<br />
besser?<br />
• Werden bei der Regressionsanalyse <strong>und</strong> bei den MLP die gleichen Beziehungen<br />
zwischen den unabhängigen <strong>und</strong> der abhängigen Variablen aufgedeckt?<br />
• Welche Verfahrensklasse weist eine bessere Generalisierungsfähigkeit auf?<br />
• Erbringt eine vorgeschobene Faktorenanalyse ein besseres Ergebnis der<br />
Wirkungsanalyse?<br />
In den nächsten zwei Kapiteln werden die Analyseergebnisse der einzelnen Modelle<br />
pro Verfahrensklasse vorgestellt.<br />
4.4.2 Ergebnisse der <strong>multivariaten</strong> Analyseverfahren<br />
Für die Berechnungen der MLP war es zunächst erforderlich, die Daten der<br />
abhängigen Variablen auf das kontinuierliche Intervall [0;1] zu transformieren (vgl.<br />
Formel (26)). 65 Um die gleichen Aussagen bei den Prognosegütemaßen zu erhalten,<br />
wurde diese Normierung auch für die regressionsanalytischen Berechnungen<br />
verwendet.<br />
x<br />
x´<br />
i<br />
=<br />
x<br />
i<br />
max<br />
− x<br />
− x<br />
min<br />
min<br />
mit:<br />
x<br />
max<br />
= Maximalwert der i-ten Beobachtungsvariablen<br />
x<br />
min<br />
= Minimalwert der i-ten Beobachtungsvariablen<br />
(26)<br />
Für die Schätzung der Parameter des multiplen Regressionsmodells bzw. zum<br />
Training der MLP wurden aus der bereinigten Stichprobe 103 Datensätze als Schätzbzw.<br />
Trainings-/Validationsdaten entnommen. Die verbliebenen 52 Daten wurden als<br />
Testdaten verwendet. Das Aufteilungsverhältnis der Daten beträgt demnach zwei zu<br />
eins (HIPPNER ET AL. 2001: 74).<br />
65 Obwohl diese Transformation in Clementine automatisch verläuft, zeigte sich, dass die vorweg<br />
durchgeführte Normierung eine Verbesserung der Prognoseleistung erbrachte, da die geschätzten<br />
Skalierungsdaten nicht ger<strong>und</strong>et, sondern in Dezimal-Dezimal Zahlen vorlagen. Eine Prüfung dieser<br />
Problematik sollte in Zukunft vorgenommen werden.<br />
70
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Modell 1:<br />
Faktorenanalyse zur Dimensionsreduktion<br />
Zur Erklärung welche Gründe bzw. Ursachen der Anwohner in Diemarden für oder<br />
gegen einen Stallbau sprechen, sind eine Vielzahl <strong>von</strong> Einflussfaktoren zu<br />
berücksichtigen. Um diese Variablenvielfalt zu reduzieren, wird im Folgenden eine<br />
explorative Faktorenanalyse durchgeführt. Neben der Komplexitätsreduktion soll sie<br />
vor allem zur Aufdeckung <strong>von</strong>einander unabhängiger Einflussgrößen dienen <strong>und</strong><br />
beugt somit a priori dem Problem der Multikollinearität in der sich anschließenden<br />
Regressionsanalyse vor. Für die nachstehende Untersuchung wurde die<br />
Hauptkomponentenanalyse als Faktorextraktionsverfahren gewählt. 66 Die Güte der<br />
Daten für die Faktorenanalyse wurde zusammen mit dem Bartlett-Test durch das<br />
Kaiser–Meyer–Olkin–Kriterium getestet. Der ermittelte Wert <strong>von</strong> 0,863 belegt eine<br />
gute Tauglichkeit der Datengr<strong>und</strong>lage. 67 Insgesamt konnten 5 Faktoren (mit<br />
Eigenwerten > 1), die kumuliert eine Gesamtvarianz <strong>von</strong> 65,89 % erklären, extrahiert<br />
<strong>und</strong> folgendermaßen charakterisiert werden: 68<br />
• Faktor 1: emotionale/persönliche Belastung durch den Stallbau<br />
• Faktor 2: gesellschaftliche Bedeutung der Landwirtschaft<br />
• Faktor 3: Wissen über die Landwirtschaft<br />
• Faktor 4: Informationsnachfrage<br />
• Faktor 5: nicht in meiner Nachbarschaft<br />
Die folgende Tabelle gibt die hinter den jeweiligen Faktoren stehenden Statements<br />
<strong>und</strong> die zugehörigen Faktorladungen wieder:<br />
66 Für die Rotation wurde die Varimax-Methode gewählt <strong>und</strong> die Faktorwerte wurden mit der<br />
Bartlett-Methode abgespeichert.<br />
67 Bei Werten unter 0,5 wird <strong>von</strong> einer Durchführung der Faktorenanalyse abgeraten. Werte <strong>von</strong><br />
größer als 0,8 sind wünschenswert (BACKHAUS et al. 2003: 276).<br />
68 Der Eigenwert eines Faktors gibt an, welcher Betrag der Gesamtstreuung aller Variablen eines<br />
Faktorenmodells durch diesen einen Faktor erklärt wird (BROSIUS 1996: 825).<br />
71
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Tabelle 7: Faktorladungen der einzelnen Statements<br />
Faktor 1: Cronbachs Alpha = 0,955; 28,98% der Varianz:<br />
Faktorladung<br />
Wenn ich an den Stallbau denke, ärgere ich mich sehr. 0,835<br />
Durch den Schweinestall würde ganz Diemarden stinken. 0,835<br />
Ich fühle mich <strong>von</strong> den Landwirten unfair behandelt. 0,823<br />
Die Gründung eines Vereins gegen den Schweinestall finde ich übertrieben. -0,816<br />
Die Belastung durch den Schweinestall wird man kaum bemerken. -0,735<br />
Durch den Stall wird die ges<strong>und</strong>heitliche Belastung stark steigen. 0,734<br />
Der Verein "Natürlich Diemarden" hat dafür gesorgt, dass wir endlich informiert 0,728<br />
werden.<br />
Die Landwirte in Diemarden haben sich ungeschickt verhalten. 0,719<br />
Der Güllegeruch beim Ausbringen wird unerträglich sein. 0,673<br />
Wenn ein Stall ordentlich begrünt ist, stört er optisch nicht weiter. -0,667<br />
Die Freizeitmöglichkeiten in Diemarden werden durch den Stall nicht beeinträchtigt. -0,629<br />
Dass die Landwirte einfach einen Stall bauen können, finde ich nicht akzeptabel. 0,588<br />
Die Gülle belastet die Umwelt in unserer Umgebung. 0,564<br />
Ich rechne nicht mit einer persönlichen Belastung durch den Stall. -0,557<br />
Faktor 2: Cronbachs Alpha = 0,786; 14,271% der Varianz:<br />
Ohne die Bauern wäre Diemarden nur halb so lebenswert. 0,683<br />
Die Bedeutung der Landwirtschaft in der Gesellschaft wird überbewertet. -0,655<br />
Ohne Landwirtschaft hätten wir in Deutschland noch viel mehr Arbeitslose. 0,651<br />
Polaritätenprofil: bescheiden-gierig 0,636<br />
Polaritätenprofil: sympathisch-unsympathisch 0,611<br />
Polaritätenprofil: Landschaftspfleger-Landschaftszerstörer 0,592<br />
Die Subventionen für die Landwirtschaft sind generell zu hoch. -0,568<br />
Faktor 3 : Cronbachs Alpha = 0,665; 7,60% der Varianz:<br />
Von Landwirtschaft habe ich eigentlich keine Ahnung. 0,887<br />
Ich kenne mich in landwirtschaftlichen Themen aus. -0,867<br />
Die Diskussion um den Stallbau interessiert mich überhaupt nicht. 0,558<br />
Faktor 4 : Cronbachs Alpha = 0,492; 7,45% der Varianz:<br />
Hätten die Landwirte uns Bürger <strong>von</strong> Anfang an informiert, wäre die Akzeptanz<br />
größer.<br />
Eigentlich müssten die Bürger immer vor Beginn eines größeren Bauvorhabens<br />
informiert werden.<br />
Ich informiere mich sehr ausführlich über alles, was mit dem Stallbau zusammen<br />
hängt.<br />
Faktor 5 : Cronbachs Alpha = 0,620; 7,26% der Varianz:<br />
0,756<br />
0,631<br />
0,590<br />
Eigentlich habe ich nichts gegen solch einen Stall, nur sollte er nicht direkt vor unserer 0,772<br />
Haustür gebaut werden.<br />
Würde der Stall in Diemarden an anderer Stelle stehen, wäre mir das Ganze egal. 0,718<br />
Quelle: Eigene Berechnungen<br />
Zur Überprüfung der Zuverlässigkeit der extrahierten Faktoren wurde die<br />
Reliabilitätsanalyse (Cronbachs Alpha) eingesetzt. Sie ermittelt, wie zuverlässig ein<br />
latentes Merkmal durch ein Set <strong>von</strong> Variablen bzw. Statements abgebildet wird <strong>und</strong><br />
welchen Beitrag die einzelne Variable zur Zuverlässigkeit des Konstruktes leistet<br />
(JANSEN/LAATZ 2003: 521). Die extrahierten Faktoren „emotionale/persönliche<br />
72
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Belastung durch den Stallbau“ (0,955) <strong>und</strong> „gesellschaftliche Bedeutung der<br />
Landwirtschaft“ (0,786) verfügen über Werte, die größer als 0,7 sind <strong>und</strong> weisen<br />
somit einen reliablen Charakter auf. 69 Die Komponenten „Wissen über die<br />
Landwirtschaft“ (0,665), „nicht in meiner Nachbarschaft“ (0,620) <strong>und</strong><br />
„Informationsnachfrage“ (0,492) können als nur bedingt bzw. gering reliabel<br />
angesehen werden. Aufgr<strong>und</strong> dieser Reliabilitätsproblematik sowie des hohen<br />
Anteils an Missing Values, die zu einem Ausschluss <strong>von</strong> 81 Fällen bei der<br />
Faktorenanalyse führten, werden im Folgenden für die weiteren Analysen nur die<br />
Leitvariablen verwendet. 70 In diesem Kontext wird der explorative Charakter der<br />
durchgeführten Faktorenanalyse noch einmal verstärkt deutlich. Dieser muss jedoch<br />
auch sehr kritisch betrachtet werden. 71<br />
Regressionsanalyse auf Basis der extrahierten Faktoren<br />
Für den Aufbau des Regressionsmodells wurden die Leitvariablen der extrahierten<br />
Faktoren als unabhängige Variablen <strong>und</strong> das Statement „Stellen Sie sich vor, es gäbe<br />
eine Dorfabstimmung über den Stallbau in Diemarden, wie würden Sie<br />
entscheiden?“ als abhängige Variable verwendet. 72 Aufgr<strong>und</strong> dessen, dass die<br />
endogene Variable ein siebenstufiges metrisches Skalenniveau <strong>von</strong> „Ja, ich stimme<br />
auf jeden Fall dafür“ bis „Nein, ich stimme auf jeden Fall dagegen“ hat <strong>und</strong> die<br />
durch die Voranalyse berechnete Korrelationsmatrix einen linearen Zusammenhang<br />
zeigt, wurde eine Multiple-Lineare-Regressionsanalyse durchgeführt. 73 Für die<br />
Berechnung der Regressionsfunktion bietet das Statistikprogramm Clementine<br />
verschiedene Möglichkeiten. Bei dem hier verwendeten Einschluss-Verfahren<br />
werden alle erklärenden Variablen in einem Schritt in die Gleichung einbezogen<br />
69 In der Literatur existieren keine Konventionen für die Höhe der Reliabilitätskoeffizienten (Werte<br />
des Koeffizienten Cronbachs Alpha liegen zwischen 0 <strong>und</strong> 1), ab dem eine Skala als hinreichend<br />
zuverlässig angesehen wird. Mindestwerte <strong>von</strong> 0,7 oder 0,8 werden häufig empfohlen (JANSEN/LAATZ<br />
2003: 525). Darüber hinaus ist Cronbachs Alpha umso größer, je stärker die Korrelation zwischen den<br />
Variablen <strong>und</strong> je größer die Anzahl der Variablen ist (BROSIUS 1996: 911-913).<br />
70 Die Leitvariable ist die Variable auf die der Faktor am höchsten lädt (JANSEN/LAATZ 2003: 472).<br />
71 Auf eine tiefergehende Interpretation der Faktoren wird verzichtet, da dieses keinen wesentlichen<br />
Beitrag zum Verfahrensvergleich erbringen, sondern nur zusätzlich den Umfang der Arbeit erhöhen<br />
würde.<br />
72 Die nicht in der Faktorenanalyse verwendeten Variablen wurden auch nicht in das Regressionsmodell<br />
eingeschlossen, da sie keine Korrelationen zu der abhängigen Variablen aufwiesen.<br />
73 In Bezug auf die endogene Variable wäre auch eine logistische Regressionsanalyse möglich. Da<br />
die Daten der Abstimmungsentscheidung aber im metrischem Skalenniveau vorliegen, würde diese<br />
Form der Regressionsanalyse zu einem Informationsverlust führen.<br />
73
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
(JANSEN/LAATZ 2003: 472). Abbildung 29 zeigt das Ergebnis der Regressionsanalyse<br />
<strong>und</strong> verdeutlicht, dass nur die Variablen „Wenn ich an den Stallbau denke, ärgere ich<br />
mich sehr“, „Hätten die Landwirte uns Bürger <strong>von</strong> Anfang an informiert, wäre die<br />
Akzeptanz größer“ <strong>und</strong> „Ohne die Bauern wäre Diemarden nur halb so lebenswert“<br />
einen signifikanten Einfluss auf die Abstimmungsentscheidung der Anwohner haben.<br />
Abbildung 29: Regressionsmodell auf Gr<strong>und</strong>lage der Faktorenanalyse (In-Sample) 74<br />
Quelle: Eigene Berechnungen<br />
Da die Variablen „Von Landwirtschaft habe ich eigentlich keine Ahnung“ <strong>und</strong><br />
„Eigentlich habe ich nichts gegen solch einen Stall, nur sollte er nicht direkt vor<br />
unserer Haustür gebaut werden“ keinen signifikanten Einfluss aufweisen, wurden<br />
diese iterativ aus dem Modell entfernt. Abbildung 30 zeigt folglich das modifizierte<br />
Regressionsmodell auf.<br />
74 Terminologie: Signifikanz: *** = p < 0,001, ** = p < 0,01, * = p < 0,05; s = Standardfehler der<br />
Schätzung; DW = Durbin-Watson-Statistik<br />
74
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Abbildung 30: Modifiziertes Regressionsmodell (In-Sample)<br />
Quelle: Eigene Berechnungen<br />
Demnach können die drei verbliebenen exogenen Variablen 71,8 % der Varianz der<br />
endogenen Variablen erklären. Die ANOVA in Tabelle 20 im Anhang zeigt, dass die<br />
Prüfgröße F hochsignifikant ist, wonach ein Einfluss bei einer oder mehreren<br />
unabhängigen Variablen auf die Abstimmungsentscheidung gegeben ist. Nach der t-<br />
Teststatistik sind die Regressionskoeffizienten signifikant <strong>von</strong> Null verschieden (vgl.<br />
Tabelle 23 im Anhang). Die Interpretation der standardisierten<br />
Regressionskoeffizienten verdeutlicht, dass die Variable „Wenn ich an den Stallbau<br />
denke, ärgere ich mich sehr“ die Hauptursache für die Abstimmungsentscheidung der<br />
Diemardener ist. Bevor jedoch eine detaillierte Interpretation des<br />
Regressionsergebnisses erfolgt, wird zunächst die Einhaltung der Prämissen des<br />
geschätzten multiplen Regressionsmodells untersucht.<br />
Im ersten Schritt wird die Multikollinearität der aufgenommenen exogenen Variablen<br />
geprüft. Tabelle 23 im Anhang stellt die Multikollinearitätsdiagnose dar. Für die<br />
Toleranz gilt, dass kleine Werte (
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Im zweiten Schritt erfolgt die Analyse der Residuen, wobei die Prämissen der<br />
Normalverteilung der Residuen, Autokorrelation <strong>und</strong> Heteroskedastizität untersucht<br />
werden. Im Histogramm der Abbildung 42 im Anhang entsprechen die Säulen den<br />
empirischen Häufigkeiten der Residuen. Die glockenförmige Kurve gibt die Linie<br />
der entsprechenden Normalverteilung wieder. Es zeigt sich, dass die Abweichungen<br />
der empirischen Werte <strong>von</strong> der Normalverteilung nicht sehr gravierend sind.<br />
Demnach kann <strong>von</strong> einer Normalverteilung der Residuen ausgegangen werden.<br />
Womit letztendlich auch die Voraussetzung zur Durchführung <strong>von</strong> Signifikanztests<br />
gewährt ist (JANSEN/LAATZ 2003: 403). Diese Aussage wird auch durch das<br />
Diagramm der Abbildung 43 gestützt, in dem die kumulierte Häufigkeitsverteilung<br />
der standardisierten Residuen (Punkte) der kumulierten Normalverteilung<br />
(durchgezogene Gerade) gegenübergestellt ist. Würde keine Normalverteilung<br />
vorliegen, müssten die Residuen weiter entfernt <strong>von</strong> der Geraden liegen (ebd.).<br />
Das Problem der Autokorrelation spielt vorwiegend bei Regressionsanalysen <strong>von</strong><br />
Zeitreihen eine Rolle. Nach JANSEN/LAATZ (2003: 398) sollte aber auch dann auf<br />
Autokorrelation hin geprüft werden, wenn die Untersuchungsobjekte eine räumliche<br />
Nähe (spatial correlation), wie sie in diesem Fall gegeben ist, zueinander aufweisen.<br />
Über das Vorliegen <strong>von</strong> Autokorrelation gibt der Durbin-Watson-Test Auskunft.<br />
Nach Abbildung 30 entspricht der Durbin-Watson-Koeffizient 2,400. Für 98<br />
Beobachtungen, 3 exogenen Variablen <strong>und</strong> einer Irrtumswahrscheinlichkeit <strong>von</strong> 5 %<br />
ergibt sich aus der Durbin-Watson-Tabelle (vgl. VON AUER 2003: 553) d u = 2,387<br />
<strong>und</strong> d 0 = 2,264. Damit fällt die Prüfgröße in den Ablehnungsbereich für die Null-<br />
Hypothese. Es liegt demnach eine negative Autokorrelation der Residualwerte vor.<br />
Das Vorhandensein der Autokorrelation führt zwar zu unverzerrten Schätzwerten für<br />
die Regressionskoeffizienten, nicht aber für deren Standardabweichungen. Die Folge<br />
ist, dass die Signifikanztests fehlerbehaftet <strong>und</strong> somit nicht mehr aussagekräftig sind<br />
(JANSEN/LAATZ 2003: 398). Die Ursache für die Autokorrelation kann neben einer<br />
falschen Gleichungsform folge des Fehlens wichtiger exogener Variablen in der<br />
Regressionsgleichung sein (ebd.). Da in diesem Fall mittlere bis starke lineare<br />
Beziehungen (Korrelationen) zwischen der abhängigen <strong>und</strong> den unabhängigen<br />
Variablen vorliegen, wird da<strong>von</strong> ausgegangen, dass eine oder mehrere wichtige<br />
Variablen fehlen.<br />
76
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Die Prämisse der Homoskedastizität verlangt, dass die Varianz der Fehlervariablen<br />
über alle empirischen Werte homogen ist. Eine Überprüfung der homoskedastischen<br />
Struktur der Residuen erfolgt über den Zusammenhang zwischen den<br />
standardisierten geschätzten Werten der Untersuchungsvariablen <strong>und</strong> den<br />
standardisierten Residuen der Beobachtungswerte (BACKHAUS et al. 2003: 104).<br />
Abbildung 44 im Anhang stellt eine systematische lineare Beziehung zwischen den<br />
Residuen <strong>und</strong> den geschätzten Werten der Untersuchungsvariablen dar. Es muss<br />
demnach da<strong>von</strong> ausgegangen werden, dass Homoskedastizität vorliegt, wodurch die<br />
bei der Autokorrelation aufgetretenen Zweifel über die Unvollständigkeit des<br />
Regressionsmodells gestärkt werden (JANSEN/LAATZ 2003: 402).<br />
Zusammenfassend lässt sich bisher festhalten, dass die Abstimmungsentscheidung<br />
der Diemardener im Wesentlichen durch die Variable „Wenn ich an den Stallbau<br />
denke, ärgere ich mich sehr“ erklärt wird. Unter der Berücksichtigung, dass diese<br />
Variable die Leitvariable des ersten Komponenten aus der Faktorenanalyse ist <strong>und</strong><br />
somit auch mit den anderen in diesen Faktor fallenden Variablen korreliert, kann mit<br />
Vorbehalt die Aussage getroffen werden, dass die Entscheidung für oder gegen den<br />
Stallbau vor allem auf die emotionale/persönliche Belastung der Anwohner durch<br />
den Stallbau zurückzuführen ist. Dieses Resultat muss jedoch aufgr<strong>und</strong> der<br />
vorhandenen Prämissenverletzungen mit Einschränkungen beurteilt werden, da das<br />
Vorliegen <strong>von</strong> Autokorrelation <strong>und</strong> Homoskedastizität zu nicht vertrauenswürdigen<br />
Ergebnissen führt. 75<br />
Im Folgenden wird daher anhand der Testdaten geprüft, inwieweit die geschätzte<br />
Regressionsfunktion die Abstimmungsentscheidung der Anwohner prognostizieren<br />
kann. Der <strong>Vergleich</strong> zwischen den geschätzten <strong>und</strong> den tatsächlichen Werten beruht<br />
auf dem mittleren quadratischen Fehler (MSE) <strong>und</strong> der Wurzel aus dem mittleren<br />
quadratischen Fehler (RMSE). 76 Dabei wurde der RMSE hauptsächlich wegen seiner<br />
75<br />
Ob durch die Aufnahme weiterer exogener Variablen eine Vorbeugung der Annahmeverletzungen<br />
möglich ist, wird im anschließenden zweiten Modell überprüft.<br />
76 Nach MCGUIRK (1995), WIDMANN (2001: 103) <strong>und</strong> VON AUER (2003: 291) sollte das<br />
Bestimmtheitsmaß R² nur bei Modellen verwendet werden, bei denen die endogene Variable identisch<br />
ist, die Anzahl der exogenen Variablen identisch ist <strong>und</strong> die Modelle einen Niveauparameter<br />
verwenden. Da aber KNN über keinen Niveauparameter verfügen, eignet sich R² nicht als<br />
Prognosegütemaß.<br />
77
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
quadratischen Fehlergewichtung, seiner einfachen Interpretation <strong>und</strong> seinem hohen<br />
Bekanntheitsgrad als Gütemaß für die Prognosequalität ausgewählt (vgl. Kapitel<br />
3.2.3). Tabelle 8 enthält die Prognosegütemaße, die sich aus den Berechnungen mit<br />
dem geschätzten Regressionsmodell ergeben haben.<br />
Tabelle 8: Prognosegüte des multiplen Regressionsmodells<br />
In-Sample Out-of-Sample<br />
MSE: 0,038 0,070<br />
RMSE: 0,196 0,266<br />
Quelle: Eigene Berechnungen<br />
Demnach liegt ein mittlerer Fehler <strong>von</strong> 0,266 (RMSE) aus der Anwendung der<br />
Regressionsfunktion zur Schätzung der endogenen Variablen vor. 77 Nach dem MSE<br />
verschlechterte sich die Schätzung auf die Out-of-Sample Menge im Gegensatz zu<br />
der In-Sample Menge um 83,75%. 78 Unter der Beachtung der Skalierung (<strong>von</strong> 0 bis<br />
1) der abhängigen Variablen kann trotz der Prämissenverletzungen ein mittel gutes<br />
Prognoseergebnis erzielt werden.<br />
Modell 2:<br />
Im Rahmen des zweiten Modells wurden direkt die 29 exogenen Variablen aus der<br />
Faktorenanalyse in die Regressionsanalyse aufgenommen. Anschließend wurden die<br />
nicht signifikanten Variablen sequentiell ausgeschlossen. Für diese<br />
Variablenselektion wurde die Rückwärts-Methode aus SPSS angewendet. Bei diesem<br />
Verfahren wird die exogene Variable mit der kleinsten Teilkorrelation zur endogenen<br />
Variablen als erste für den Ausschluss in Betracht gezogen. Als Kriterien für den<br />
Ausschluss einer unabhängigen Variablen dient, neben der Toleranz<br />
(Multikollinearität), das Signifikanzniveau des partiellen Korrelationskoeffizienten,<br />
wobei der Schwellenwert für die Signifikanz bei 0,05 liegt. Nach dem Ausschluss<br />
der ersten Variablen wird die nächste Variable mit der kleinsten Teilkorrelation in<br />
Betracht gezogen. Das Verfahren wird beendet, wenn keine Variablen mehr zur<br />
77 Die Interpretation des RMSE entspricht dem Standardfehler aus der Regressionsanalyse.<br />
78 Für die Berechnung der relativen Verschlechterung der Prognoseleistung wurde der MSE der In-<br />
Sample-Menge auf 100 festgelegt.<br />
78
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Verfügung stehen, die die Ausschlusskriterien erfüllen (JANSEN/LAATZ 2003: 410).<br />
Der Nachteil der Rückwärtsregression besteht darin, dass die weiteren relevanten<br />
Prüfkriterien hinsichtlich der Prämissenverletzungen in den einzelnen Schritten nicht<br />
berücksichtigt werden.<br />
Die Variablenselektion der Rückwärtsregression war nach 21 Schritten<br />
abgeschlossen. Von den ursprünglich 29 Regressoren haben entsprechend der<br />
Abbildung 31 neun Variablen einen signifikanten Einfluss auf die<br />
Abstimmungsentscheidung der Diemardener.<br />
Abbildung 31: Regressionsmodell auf Basis der Rückwärts-Methode<br />
Quelle: Eigene Berechnungen<br />
79
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
88,8 % der Varianz der endogenen Variablen können durch diese neun unabhängigen<br />
Variablen erklärt werden. Die ANOVA in Tabelle 22 im Anhang zeigt, dass die<br />
Prüfgröße F hochsignifikant ist, wonach ein Einfluss bei einer oder mehreren<br />
unabhängigen Variablen auf die Abstimmungsentscheidung gegeben ist. Nach der t-<br />
Teststatistik sind die Regressionskoeffizienten signifikant <strong>von</strong> Null verschieden (vgl.<br />
Tabelle 23 im Anhang). Die Interpretation der standardisierten Regressionskoeffizienten<br />
verdeutlicht wie schon im ersten Modell, dass die Variable „Wenn ich<br />
an den Stallbau denke, ärgere ich mich sehr“, eine der Hauptursachen für die<br />
Abstimmungsentscheidung der Diemardener ist.<br />
Die Multikollinearitätsdiagnose in Tabelle 23 im Anhang zeigt, dass keine<br />
Multikollinearität vorliegt. Dieses wird auch durch die Korrelationsmatrix (vgl.<br />
Tabelle 24) der exogenen Variablen bestätigt. Demnach kann die ursprünglich vor<br />
der Durchführung der Faktorenanalyse begründete Multikollinearitätsproblematik in<br />
Bezug auf diesen Datensatz nicht bestätigt werden. Abbildung 45 <strong>und</strong> Abbildung 46<br />
im Anhang zeigen, dass die Abweichungen der empirischen Residualwerte <strong>von</strong> der<br />
Normalverteilung nicht sehr gravierend sind. Folglich kann <strong>von</strong> einer<br />
Normalverteilung der Residuen ausgegangen werden. Mit 1,961 liegt der Durbin-<br />
Watson-Koeffizient nahe bei zwei, wonach keine Autokorrelation existiert<br />
(JANSEN/LAATZ 2003: 398). Durch die Abbildung 47 im Anhang wird ersichtlich,<br />
dass eine systematische lineare Beziehung zwischen den standardisierten Residuen<br />
der Beobachtungswerte <strong>und</strong> den standardisierten geschätzten Werten der<br />
Untersuchungsvariablen besteht. Es muss demnach da<strong>von</strong> ausgegangen werden, dass<br />
Homoskedastizität vorliegt.<br />
Zusammenfassend lässt sich festhalten, dass im <strong>Vergleich</strong> zu dem ersten Modell im<br />
Zweiten eine größere Varianzerklärung (vgl. adjusted R²) <strong>und</strong> keine Autokorrelation<br />
gegeben sind. Im Folgenden wird anhand der Testdaten geprüft, ob durch diese<br />
Verbesserungen des Modells die Prognosequalität erhöht wird. Tabelle 9 enthält die<br />
dafür notwendigen Prognosegütemaße, die sich aus den Berechnungen mit dem<br />
geschätzten Regressionsmodell ergeben haben.<br />
80
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Tabelle 9: Prognosegüte des multiplen Regressionsmodells auf Basis der Rückwärts-<br />
Methode<br />
In-Sample Out-of-Sample<br />
MSE: 0,0237 0,0469<br />
RMSE: 0,1542 0,2165<br />
Quelle: Eigene Berechnungen<br />
Dementsprechend liegt ein mittlerer Fehler <strong>von</strong> 0,2165 (RMSE) aus der Anwendung<br />
der Regressionsfunktion zur Schätzung der endogenen Variablen vor. Nach dem<br />
MSE verschlechterte sich die Schätzung auf die Out-of-Sample Menge im Gegensatz<br />
zu der In-Sample Menge um 97,16 %. Trotz dieser schlechten Anpassung an die Outof-Sample<br />
Daten, ist das Ergebnis des zweiten Regressionsmodells nach dem MSE<br />
um 50,70 % besser als das des ersten Modells. Ein darüber hinausgehender <strong>Vergleich</strong><br />
mit den RMSE macht deutlich, dass der mittlere Fehler beim zweiten Modell nur um<br />
0,0493 kleiner ist als beim ersten Modell. Dieses lässt sich wahrscheinlich vor allem<br />
darauf zurückführen, dass alleine die Variable „Wenn ich an den Stallbau denke,<br />
ärgere ich mich sehr“ bei einer Einfachregression 66,7 % der Varianz (adjusted R²)<br />
der abhängigen Variablen erklärt. Somit steht der Anwender vor der Entscheidung,<br />
entweder ein sehr umfassendes Ergebnis mit vielen signifikanten exogenen Variablen<br />
<strong>und</strong> einer guten Güte (Modell 2) oder andererseits, ein sehr komprimiertes Ergebnis<br />
mit einer etwas minderen Güte (Modell 1) für die weiteren Analysen zu verwenden.<br />
4.4.3 Ergebnisse der künstlichen <strong>Neuronalen</strong> Netze<br />
Analog zu der Ergebnispräsentation bei der multiplen linearen Regressionsanalyse,<br />
werden im Folgenden die Ergebnisse der künstlichen <strong>Neuronalen</strong> Netze (MLP)<br />
vorgestellt.<br />
Modell 1:<br />
Für den Aufbau des <strong>Neuronalen</strong> Netzwerkes wurden die Leitvariablen der<br />
extrahierten Komponenten aus der <strong>multivariaten</strong> Faktorenanalyse als Inputneuronen<br />
in der Eingangsschicht <strong>und</strong> das Statement „Stellen Sie sich vor, es gäbe eine<br />
Dorfabstimmung über den Stallbau in Diemarden, wie würden Sie entscheiden?“, als<br />
81
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Outputneuron in der Ausgabeschicht verwendet. Das Statistikprogramm<br />
„Clementine“ bietet für das Training verschiedene Verfahren. Um einen schnellen<br />
<strong>und</strong> guten Netzaufbau zu gewähren, wurde die Quick-Methode verwendet, die alle<br />
erklärenden Variablen in einem Schritt in die Gleichung einbezieht. Für die<br />
Trainingsdaten wurden 60% der 103 Datensätze verwendet, 40 % der Daten wurden<br />
als Validationsdaten eingesetzt. Die systematische Änderung der Lernraten <strong>und</strong> der<br />
Netzwerktopologie erbrachte keine besseren Ergebnisse, als es schon bei den<br />
Standardeinstellungen der Fall war. 79 Abbildung 32 zeigt das Ergebnis des trainierten<br />
<strong>und</strong> validierten Netzes, welches 20 Neuronen in der verdeckten Schicht aufweist.<br />
Abbildung 32: MLP-Modell auf Gr<strong>und</strong>lage der Faktorenanalyse (Validationsdaten) 80<br />
Quelle: Eigene Berechnungen<br />
Für die Interpretation des erstellten Netzwerkes wurde eine lineare<br />
Sensitivitätsanalyse (SEA) durchgeführt (lokale Relevanz) (vgl. Kapitel 3.2.3). Die<br />
SEA-Werte (<strong>von</strong> 0 bis 1) werden für jede Inputvariable einzeln gemessen <strong>und</strong> zeigen<br />
79 Die Standardeinstellungen lauten: Alpha = 0,9; Initial Eta = 0,3; High Eta = 0,1; Eta decay = 30;<br />
Low Eta = 0,01.Als Aktivierungsfunktion wurde eine sigmoide, logistische Funktion gewählt.<br />
Overtraining wurde automatisch verhindert. Das Abbruchkriterium wurde zeitlich festgelegt (nach 3<br />
Minuten).<br />
80 Terminologie: SEA = Sensitivitätsanalyse; Die Abbildung zeigt nicht die Netztopologie sondern<br />
nur die Input- <strong>und</strong> Outputneuronen.<br />
82
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
die relative Wichtigkeit dieser Variablen auf das Output an. Während eine Variable<br />
mit dem SEA-Wert <strong>von</strong> null keinen Einfluss auf die Outputvariable hat, bedeutet ein<br />
Wert <strong>von</strong> 1, dass die Eingabevariable vollständig durch die Ausgabevariable erklärt<br />
wird (SPSS 2003a: 16). Demnach kann die Abstimmungsentscheidung der<br />
Diemardener zu 61% durch das Eingabeneuron „Wenn ich an den Stallbau denke,<br />
ärgere ich mich sehr“ erklärt werden. Das Ergebnis der MLP in Abbildung 32 zeigt<br />
die gleiche Rangfolge in Bezug auf die Wichtigkeiten der erklärenden Variablen wie<br />
das Regressionsmodell in Abbildung 29. Einschränkend muss jedoch darauf<br />
hingewiesen werden, dass der Aufbau unterschiedlicher Netzwerke zeigte, dass die<br />
Hierarchie der Variablen zum Teil um einen Platz variierte. Ausgenommen da<strong>von</strong><br />
war die Eingabevariable „Wenn ich an den Stallbau denke, ärgere ich mich sehr“.<br />
Hauptursache für die Veränderungen der Rangfolgen war die Festlegung<br />
unterschiedler Startgewichte (Verbindungsgewichte) bei den Neuronen.<br />
Abbildung 33: Modifiziertes MLP Model (Validationsdaten)<br />
Quelle: Eigene Berechnungen<br />
Um die Ergebnisse der KNN mit denen der Regressionsanalyse besser vergleichen zu<br />
können, wurden entsprechend des modifizierten Regressionsmodells (vgl. Abbildung<br />
30) die zwei unwichtigsten (nicht signifikanten) Variablen aus dem MLP-Modell<br />
ausgeschlossen (vgl. Abbildung 33). Auch hier zeigte der Aufbau unterschiedlicher<br />
Netzwerke, dass die Hierarchie der Eingabevariablen „Hätten die Landwirte uns<br />
Bürger <strong>von</strong> Anfang an informiert, wäre die Akzeptanz größer“ <strong>und</strong> „Ohne die Bauern<br />
wäre Diemarden nur halb so lebenswert“ untereinander variierte. Da die Werte der<br />
SEA dieser beiden Neuronen nicht sehr unterschiedlich sind, wurde letztendlich ein<br />
83
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
dem Regressionsmodell vergleichendes Netzwerk ausgewählt. Demnach können die<br />
drei verbleibenden Inputvariablen 73,2 % der Varianz der Outputvariablen erklären.<br />
Zur Überprüfung der Prognosequalität des trainierten Netzes, wurde anhand der<br />
Testdaten eine Prognose zur Abstimmungsentscheidung der Anwohner<br />
vorgenommen. 81<br />
Tabelle 10: Prognosequalität des <strong>Neuronalen</strong> Netzwerkes (MLP)<br />
Validationsdaten Testdaten<br />
MSE: 0,044 0,073<br />
RMSE: 0,210 0,270<br />
Quelle: Eigene Berechnungen<br />
Nach Tabelle 10 liegt ein mittlerer Fehler <strong>von</strong> 0,266 (RMSE) aus der Anwendung<br />
des MLP-Modelles zur Prognose der endogenen Variablen vor. 82 Nach dem MSE<br />
verschlechterte sich die Schätzung auf die Out-of-Sample Menge im Gegensatz zu<br />
der In-Sample Menge um 64,70%. Unter der Beachtung der Skalierung (<strong>von</strong> 0 bis 1)<br />
der Outputvariablen wird demnach ein mittelgutes Prognoseergebnis erzielt.<br />
Modell 2:<br />
Im Rahmen des zweiten Modells wurden entsprechend der <strong>multivariaten</strong><br />
Regressionsanalyse direkt die 29 exogenen Variablen aus der Faktorenanalyse in das<br />
Netzwerk aufgenommen. Analog zu der Rückwärts-Methode wurde für das Training<br />
der MLP (im Software-Tool Clementine) die Pruning-Methode verwendet. Dieses<br />
Verfahren beginnt mit sehr vielen Inputvariablen (Neuronen) <strong>und</strong> löschen dann<br />
iterativ die Variablen, die keinen wichtigen Einfluss auf den Output haben. Die<br />
Pruning-Methode verringert somit die Komplexität des <strong>Neuronalen</strong> Netzwerks,<br />
wodurch auch gleichzeitig die Netzwerktopologie optimiert wird (SPSS 2003a: 12-<br />
13). Das Training der MLP konnte jedoch keine stabilen Ergebnisse erbringen. Die<br />
Anzahl der verbliebenen Neuronen sowie deren relativen Wichtigkeiten auf den<br />
Output waren bei jedem Netzwerk unterschiedlich, obwohl die Prognosequalitäten<br />
nicht groß schwankten. Auch erhöhte Rechenzeitaufwendungen erbrachten keine<br />
81 Diese Überprüfung dient auch als Test für die Generalisierbarkeit des Netzes.<br />
82 Die Interpretation des RMSE entspricht dem Standardfehler aus der Regressionsanalyse.<br />
84
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
besseren Ergebnisse. Es ließen sich keine Tendenzen sowie wiederkehrende Muster<br />
in den trainierten <strong>Netzen</strong> erkennen. Hauptursache für die unterschiedlichen<br />
Trainingsergebnisse waren die differenzierten Festlegungen der Startgewichte<br />
(Verbindungsgewichte) bei den Neuronen. Aufgr<strong>und</strong> dieser Problematik wurde kein<br />
endgültiges Netzwerk trainiert.<br />
4.4.4 Ergebnisse der Fallstudie <strong>und</strong> Verfahrensvergleich<br />
Die empirischen Untersuchungen haben gezeigt, dass die Abstimmungsentscheidungen<br />
der Diemardener Anwohner mittels multipler linearer<br />
Regressionsanalyse <strong>und</strong> künstlicher Neuronaler Netze (MLP) analysiert werden<br />
konnte. Ohne vorherige Festlegung der unabhängigen Variablen (Modell 2), war es<br />
aber nur mit Hilfe der Rückwärts-Methode bei der Regressionsanalyse möglich ein<br />
Ergebnis zu erhalten, da durch die Verwendung der Pruning-Methode bei den MLP<br />
kein stabiles Netzwerk aufgebaut werden konnte. Der sich anschließende<br />
Verfahrensvergleich stützt sich deshalb, unter Einbeziehung der erzielten<br />
Prognosequalitäten <strong>und</strong> der Interpretationen der Ergebnisse, hauptsächlich auf das<br />
erste Modell.<br />
Tabelle 11: Prognosequalität im Verfahrensvergleich<br />
Verfahren Modelle<br />
In-Sample<br />
Qualität<br />
Out-of-Sample<br />
Qualität<br />
MSE RMSE MSE RMSE<br />
Multiple<br />
Modell 1 0,039 0,196 0,070 0,266<br />
Regressionsanalyse Modell 2 0,024 0,154 0,046 0,216<br />
Multi-Layer-Perceptrons Modell 1 0,044 0,210 0,073 0,270<br />
Quelle: Eigene Berechnungen<br />
Tabelle 11 verdeutlicht, dass die Regressionsanalyse in Bezug auf die In-Sample-<br />
Qualität im ersten Modell nach dem MSE um 12,81 % bessere Ergebnisse aufweist<br />
als die MLP. Diese bessere Schätzung der Regression verringert sich jedoch bei der<br />
Out-of-Sample Qualität auf nur 2,72 %. Demnach weisen die KNN eine bessere<br />
Generalisierbarkeit auf als die multivariate Regressionsanalyse. Letztendlich sind die<br />
85
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Ergebnisse beider Verfahren aber nahezu identisch. Die Ursache für die schlechten<br />
Ergebnisse der KNN, im <strong>Vergleich</strong> zu den positiven Aussagen in der Literatur (vgl.<br />
Kapitel 4.1), könnten unter anderem damit begründet sein, dass in den<br />
Datenstrukturen nur wenige nichtlineare Anteile nachweisbar sind (vgl. die<br />
Korrelationsmatrix in Tabelle 25 im Anhang). Auf der anderen Seite könnte aber<br />
auch die Regressionsanalyse bei einer Verringerung der Prämissenverletzungen<br />
effizientere <strong>und</strong> unverzerrtere Schätzer aufweisen. Das zweite Regressionsmodell<br />
bestätigt, mit weniger Annahmeverletzungen <strong>und</strong> einer höheren Prognosequalität,<br />
diesen Zusammenhang. Zukünftige Studien sollten daher diese Probleme<br />
(Nichtlinearität <strong>und</strong> Prämissenverletzungen) berücksichtigen <strong>und</strong> darüber hinaus<br />
variierende Stichprobengrößen <strong>und</strong> wechselnde Anzahlen an Variablen in die<br />
Analysen einbeziehen, um so die mögliche Leistungsfähigkeit der KNN in der<br />
Primärforschung umfangreicher <strong>und</strong> besser aufzudecken.<br />
Die Ursachenanalyse (Interpretation der Regressionskoeffizienten <strong>und</strong> der<br />
Sensitivitätsanalyse) beider Verfahren erbrachte jeweils im ersten Modell, in Bezug<br />
auf die Wichtigkeit der unabhängigen Variablen auf die Abstimmungsentscheidung,<br />
die gleichen Ergebnisse. Demzufolge hat die Variable „Wenn ich an den Stallbau<br />
denke, ärgere ich mich sehr“ den größten Einfluss auf die exogene Variable. Danach<br />
folgen die Variablen „Hätten die Landwirte uns Bürger <strong>von</strong> Anfang an informiert,<br />
wäre die Akzeptanz größer“ <strong>und</strong> „Ohne die Bauern wäre Diemarden nur halb so<br />
lebenswert“. Während die Regressionskoeffizienten die Richtung des Einflusses<br />
(negatives oder positives Vorzeichen) der exogenen Variablen auf die Endogene<br />
anzeigen, fehlt diese Wirkungsanalyse bei den MLP. Demnach kann das Neuronale<br />
Netzwerk auch nicht erklären, dass die Variable „Ohne die Bauern wäre Diemarden<br />
nur halb so lebenswert“ einen positiven Einfluss auf die Abstimmungsentscheidung<br />
hat, während die anderen Variablen negativ wirken. Aufgr<strong>und</strong> dieser<br />
Einschränkungen der Sensitivitätsanalyse des <strong>Neuronalen</strong> Netzes, ist die<br />
Interpretation der Ergebnisse der MLP im <strong>Vergleich</strong> zu denen der<br />
Regressionsanalyse nur bedingt möglich.<br />
Durch das zweite Modell sollte insbesondere untersucht werden, ob die Verfahren<br />
auch ohne eine vorherige Dimensionsreduktion (Faktorenanalyse) die Komplexität<br />
86
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
der statistischen Problemsituation (vgl. Kapitel 3.3) erfassen <strong>und</strong> auf die<br />
wesentlichen exogenen Variablen reduzieren können. Es zeigte sich, wie schon oben<br />
dargestellt, dass nur die Regressionsanalyse ein verwertbares Ergebnis erzeugte,<br />
welches eine bessere Güte als das erste Modell aufwies. Die Vielzahl der<br />
Einflussfaktoren bzw. der unabhängigen Variablen erschwert jedoch die<br />
Interpretation der Ergebnisse. Somit steht der Anwender vor der Entscheidung,<br />
entweder ein sehr umfassendes Ergebnis mit vielen exogenen Variablen <strong>und</strong> einer<br />
guten Güte (Modell 2) oder andererseits ein sehr komprimiertes Ergebnis mit einer<br />
etwas minderen Güte (Modell 1) für die weiteren Analysen zu verwenden.<br />
Die Interpretation beider Modelle macht deutlich, dass die Abstimmungsentscheidung<br />
der Anwohner vor allem <strong>von</strong> der emotionalen/persönlichen Belastung<br />
(vgl. Faktor 1, Kapitel 4.4.2) durch den Stallbau abhängt. Da dieses Ergebnis eine<br />
hohe Komplexität in Hinsicht der Vielzahl der Einflussvariablen <strong>und</strong> der<br />
Beziehungen dieser untereinander aufweist, sollten weitergehende Analysen<br />
spezifische Problemstellungen betrachten, z. B. die Möglichkeiten der Landwirte, die<br />
Abstimmungsentscheidung der Diemardener zu beeinflussen oder die Hauptgründe<br />
der stärksten Ablehner des Stallbaus.<br />
Die Schlussfolgerung dieser Fallstudie in Bezug auf den Verfahrensvergleich ist,<br />
dass sich die MLP zwar einerseits nach der Güte (MSE) <strong>und</strong> der Generalisierbarkeit<br />
der Ergebnisse für den Einsatz in der Primärforschung eignen aber andererseits durch<br />
die mangelnde Interpretierbarkeit der Ergebnisse im <strong>Vergleich</strong> zu der<br />
Regressionsanalyse nur bedingt einsetzbar sind.<br />
87
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
4.5 Fallstudie 2: Markenpräferenz bei chinesischen Konsumenten<br />
4.5.1 Empirische Basis <strong>und</strong> Problemstellung der Untersuchung<br />
Die nachfolgend vorgestellte Fallstudie beruht auf einer face-to-face Befragung über<br />
das Konsumentenverhalten <strong>von</strong> 1600 Chinesen in den beiden Städten Peking <strong>und</strong><br />
Wuhan. 83 Peking ist die Hauptstadt der Volksrepublik China mit einer registrierten<br />
Bevölkerung <strong>von</strong> 11,5 Mio. Einwohnern. Die Stadt verfügt über eine der höchsten<br />
Konzentrationen <strong>von</strong> Einwohnern mit hohen Einkommen in China <strong>und</strong> repräsentiert<br />
als solche die boomenden Metropolen der weltmarktorientierten Ostküste. Die Stadt<br />
Wuhan ist mit 7,8 Mio. Einwohnern die Hauptstadt der zentralchinesischen Provinz<br />
Hubei. Mit ihrer schwerindustriellen Ausrichtung ist die Stadt ökonomisch am<br />
Binnenmarkt ausgerichtet <strong>und</strong> partizipiert nur marginal an den vom Weltmarkt<br />
ausgehenden Wachstumsimpulsen. Wuhan steht somit für die große Gruppe der<br />
chinesischen Städte mit mittleren Einkommen (NATIONAL BUREAU OF STATISTICS<br />
2004: 404).<br />
In den zwei Befragungsregionen Peking <strong>und</strong> Wuhan wurden jeweils 800 Probanden<br />
interviewt. Folglich kann die Studie als bedingt repräsentativ angesehen werden.<br />
Dennoch können aufgr<strong>und</strong> der Zusammensetzung der Stichprobe aussagekräftige<br />
Ergebnisse über das chinesische Konsumentenverhalten erwartet werden. Der<br />
Fragebogen (siehe Anhang F) setzt sich aus verschiedenen inhaltlichen <strong>und</strong><br />
methodischen Elementen zusammen. Überwiegend wurden geschlossene Fragen<br />
sowie Statementbatterien mit Likert-Skalen eingesetzt. In der Regel dauerte die<br />
Beantwortung des Fragebogens ca. 30 Minuten. Durchgeführt wurde die Erhebung<br />
im September 2004 (KW 38 <strong>und</strong> KW 39). Die Probanden wurden per Random-<br />
Verfahren ausgewählt <strong>und</strong> durch geschulte, chinesische Interviewer zur<br />
Beantwortung des Fragebogens zu Hause aufgesucht.<br />
Die Stichprobe setzt sich aus 44,8 % männlichen <strong>und</strong> 55,2 % weiblichen Probanten<br />
zusammen. Die Hälfte der Befragten (52,3 %) leben mit Kind <strong>und</strong>/ oder Ehepartner<br />
83 Die Datenerhebung erfolgte in Kooperation mit dem China Economic Monitoring Center des<br />
National Bureau of Statistics der VR China.<br />
88
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
in einem Haushalt, knapp 16 % leben zusammen mit ihren Eltern. Die Zahl der<br />
Single-Haushalte (7,6 %) sowie derer, die kinderlos mit Partner (10,6 %) leben, ist<br />
im <strong>Vergleich</strong> zu europäischen Verhältnissen auffallend gering (STATISTISCHES<br />
BUNDESAMT 2004: 63). 42 % der Probanden sind haushaltsführend, bzw. kaufen für<br />
den eigenen Haushalt Lebensmittel ein. Als höchster Bildungsabschluss dominiert in<br />
der Stichprobe die High School (ca. 32 %), r<strong>und</strong> 26 % der Probanden absolvierten<br />
das Junior College <strong>und</strong> r<strong>und</strong> 19 % die Senior Secondary School. In Bezug auf die<br />
Beschäftigung gaben r<strong>und</strong> 41 % an, in einem Angestelltenverhältnis bei einem<br />
staatlichen (25,5 %) oder privat geführten (15,6 %) Unternehmen zu stehen sowie ca.<br />
14,4 %, dass sie selbstständig sind. Die Arbeitslosenquote lag in der erhobenen<br />
Stichprobe bei 12,9 %. Hinsichtlich des monatlich verfügbaren<br />
Haushaltseinkommens können r<strong>und</strong> 48 % der Befragten in eine der<br />
Einkommensklassen zwischen 500 <strong>und</strong> 2000 RMB ein (12,9 % gaben diesbezüglich<br />
keine Antwort) eingeordnet werden.<br />
Das Ziel der folgenden Untersuchungen ist, die Probanden aus Wuhan hinsichtlich<br />
ihres Kaufverhaltens in Bezug auf internationale <strong>und</strong> chinesische Marken zu<br />
typologisieren. Zur Lösung dieser struktur-entdeckenden Problemstellung bieten sich<br />
die Clusteranalyse (Single-Linkage, Ward <strong>und</strong> K-Means Algorithmus) aus der<br />
<strong>multivariaten</strong> Statistik sowie die SOM aus den KNN an. Um einen umfassenderen<br />
<strong>Vergleich</strong> der Leistungsfähigkeit der beiden Verfahrensklassen zur Lösung der<br />
Problemsituation zu ermöglichen, werden zwei Modelle aufgestellt:<br />
Modell 1<br />
Im ersten Modell erfolgt zunächst durch eine explorative Faktorenanalyse eine<br />
Dimensionsreduktion <strong>von</strong> mehreren korrelierten Variablen auf einige wenige<br />
Faktoren. 84 Anschließend werden diese Faktoren als clusterbildende Variablen bei<br />
der <strong>multivariaten</strong> Clusteranalyse <strong>und</strong> den SOM verwendet.<br />
84 Es kann entweder eine explorative (ohne vorangestellte Hypothese) oder eine konfirmatorische<br />
(Überprüfung einer vorangestellten Hypothese) Faktorenanalyse durchgeführt werden (JANSEN/LAATZ<br />
2003: 457).<br />
89
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Modell 2:<br />
Im zweiten Modell erfolgt die Typologisierung direkt auf Basis <strong>von</strong> 11<br />
clusterbildenden Variablen.<br />
Mit Hilfe dieser Modelle sollen unter anderem folgende anwenderbezogene<br />
Fragestellungen beantwortet werden:<br />
• Welche Verfahrensklasse weist eine bessere Klassifizierungsgüte auf?<br />
• Werden die Probanten bei der <strong>multivariaten</strong> Clusteranalyse <strong>und</strong> bei den SOM den<br />
gleichen Clustern zugeordnet?<br />
• Erbringt eine vorgeschobene Faktorenanalyse ein besseres Gruppierungsergebnis?<br />
• Wie verändert sich die Homogenität der Cluster mit zunehmender Clusteranzahl?<br />
In den nächsten zwei Kapiteln werden die Ergebnisse der einzelnen Modelle pro<br />
Verfahrensklasse vorgestellt. Daran anschließend werden die Resultate der KNN <strong>und</strong><br />
der <strong>multivariaten</strong> Methoden verglichen.<br />
4.5.2 Ergebnisse der <strong>multivariaten</strong> Analyseverfahren<br />
Bevor in den folgenden Modellen eine Analyse der Daten vorgenommen wird,<br />
wurden zunächst 3 Fragebögen, die Ausreißer enthielten, entfernt. Damit verblieben<br />
für weitere Berechnungen 797 Datensätze aus Wuhan.<br />
Model 1:<br />
Faktorenanalyse zur Dimensionsreduktion<br />
Zur Erklärung der Markenpräferenzen chinesischer Konsumenten ist es erforderlich,<br />
eine Vielzahl <strong>von</strong> Einflussfaktoren zu berücksichtigen. Gegenstand der zunächst<br />
durchgeführten Faktorenanalyse ist deshalb die Reduktion dieser Variablenvielfalt<br />
auf Gruppen <strong>von</strong> Variablen, die ähnliche Erklärungsfaktoren thematisieren<br />
(BACKHAUS et al. 2003: 292). Die Faktorenanalyse dient neben der<br />
Komplexitätsreduktion der Aufdeckung <strong>von</strong>einander unabhängiger Einflussgrößen<br />
90
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
<strong>und</strong> wird in diesem Fall explorativ eingesetzt. Für die folgende Untersuchung wurde<br />
die Hauptkomponentenanalyse als Faktorextraktionsverfahren gewählt. 85 Die Güte<br />
der Daten für die Faktorenanalyse wurde zusammen mit dem Bartlett-Test durch das<br />
Kaiser–Meyer–Olkin–Kriterium getestet. Mit diesem Kriterium wird geprüft, ob sich<br />
die Datengr<strong>und</strong>lage zur Durchführung einer Faktorenanalyse eignet (ebd.). Der<br />
ermittelte Wert <strong>von</strong> 0,796 belegt eine gute Tauglichkeit der Datengr<strong>und</strong>lage. 86<br />
Insgesamt konnten drei Faktoren (mit Eigenwerten > 1), die kumuliert eine<br />
Gesamtvarianz <strong>von</strong> 61,04 % erklären, extrahiert <strong>und</strong> folgendermaßen charakterisiert<br />
werden: 87<br />
• Faktor 1: Patriotismus<br />
• Faktor 2: Prestige-Effekt <strong>von</strong> internationalen Marken<br />
• Faktor 3: Vertrauens-/Performance-Effekt <strong>von</strong> chinesischen Marken<br />
Tabelle 12: Faktorladungen der einzelnen Statements<br />
Faktor 1: Cronbachs Alpha = 0,877; 22,53% der Varianz:<br />
Faktorladung<br />
…to support the national industry. 0,900<br />
…because I love my home country. 0,873<br />
…because this will generate jobs in China. 0,834<br />
Faktor 2: Cronbachs Alpha = 0,753; 21,96% der Varianz:<br />
…when I invite friends, I try to offer foreign brands. 0,811<br />
…I prefer to buy foreign brands if I want to give the product away as<br />
a gift.<br />
0,745<br />
…I will shop first at retail stores that make a special effort to sell<br />
foreign brands.<br />
0,728<br />
…I choose foreign brands because they are cool and have really funny<br />
and crazy ads.<br />
0,669<br />
Faktor 3 : Cronbachs Alpha = 0,616; 16,55% der Varianz:<br />
…it is more important to know whether the product I buy was made in<br />
China than what brand it is.<br />
0,718<br />
…even though certain products are available in a number of different<br />
brands, I always tend to buy the Chinese brand.<br />
0,621<br />
…because I trust Chinese brands more than foreign brands. 0,601<br />
…Chinese products have a higher level of quality than products from<br />
abroad.<br />
0,593<br />
85 Für die Rotation wurde die Varimax-Methode gewählt <strong>und</strong> die Faktorwerte wurden mit der<br />
Bartlett-Methode abgespeichert.<br />
86 Bei Werten unter 0,5 wird <strong>von</strong> einer Durchführung der Faktorenanalyse abgeraten (BACKHAUS et<br />
al. 2003: 276).<br />
87 Abbildung 48 zeigt den Screeplot der Faktorlösung <strong>und</strong> Abbildung 49 das Komponentendiagramm<br />
im rotierten Raum. Der Eigenwert eines Faktors gibt an, welcher Betrag der Gesamtstreuung<br />
aller Variablen eines Faktorenmodells durch diesen einen Faktor erklärt wird (BROSIUS 1996: 825).<br />
91
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Quelle: Eigene Berechnungen<br />
Tabelle 12 gibt die hinter den jeweiligen Faktoren stehenden Statements <strong>und</strong> die<br />
zugehörigen Faktorladungen wieder. Als Gütekriterium zur Überprüfung der<br />
Zuverlässigkeit der extrahierten Faktoren wurde die Reliabilitätsanalyse (Cronbachs<br />
Alpha) eingesetzt. Die extrahierten Faktoren „Patriotismus“ (0,877) <strong>und</strong> „Prestige-<br />
Effekt <strong>von</strong> internationalen Marken“ (0,753) verfügen über Werte die größer als 0,7<br />
sind <strong>und</strong> weisen somit einen reliablen Charakter auf. 88 Der Faktor „Vertrauens-<br />
/Performance-Effekt <strong>von</strong> chinesischen Marken“ (0,616) kann nur als bedingt reliabel<br />
angesehen werden. Aufgr<strong>und</strong> der inhaltlichen Relevanz sowie der Faktorladungen<br />
wird diese Komponente trotzdem in die weiteren Analysen einbezogen. 89<br />
Clusteranalyse zur Identifikation <strong>von</strong> Gruppen unterschiedlicher<br />
Markenpräferenz<br />
Aufgr<strong>und</strong> fehlender Einzelwerte (missing values) wurde die Stichprobe bei der<br />
Faktorenanalyse um 10 Datensätze reduziert. Mit Hilfe des Single-Linkage-<br />
Algorithmus unter Verwendung der drei bei der Faktoranalyse extrahierten<br />
Komponenten, „Patriotismus“, „Prestige-Effekt <strong>von</strong> internationalen Marken“ <strong>und</strong><br />
„Vertrauens-/Performance-Effekt <strong>von</strong> chinesischen Marken“, als clusterbildende<br />
Variablen wurden noch einmal 4 Ausreißer lokalisiert <strong>und</strong> ebenfalls aus der Menge<br />
der zu gruppierenden Objekte entfernt. 90 Es verblieben demnach 783 Datensätze für<br />
die Bestimmung der optimalen Clusteranzahl durch die Ward-Methode. 91 Obwohl<br />
das Ellbow-Kriterium auf eine Vierclusterlösung hinwies, wurde infolge der<br />
inhaltlichen Interpretation ein Ergebnis mit fünf Clustern zur weiteren Analyse<br />
ausgewählt (vgl. Abbildung 34). 92<br />
88 In der Literatur existieren keine Konventionen für die Höhe der Reliabilitätskoeffizienten (Werte<br />
des Koeffizienten Cronbachs Alpha liegen zwischen 0 <strong>und</strong> 1), ab dem eine Skala als hinreichend<br />
zuverlässig angesehen wird. Mindestwerte <strong>von</strong> 0,7 oder 0,8 werden häufig empfohlen (JANSEN/LAATZ<br />
2003: 525).<br />
89 Auf eine tiefergehende Interpretation der Faktoren wird verzichtet, da dieses keinen wesentlichen<br />
Beitrag zum Verfahrensvergleich erbringen sondern nur zusätzlich den Umfang der Arbeit erhöhen<br />
würde.<br />
90<br />
Die Methodik, die hinter den verwendeten Analyseverfahren steht, wurde in Kapitel 3<br />
vorgestellt.<br />
91 Es ist jedoch kritisch zu sehen, inwieweit die optimale Clusteranzahl bestimmt werden kann.<br />
92 Das Dendogramm konnte zur Bestimmung der optimalen Clusteranzahl nicht verwendet werden,<br />
da der Datensatz zu groß <strong>und</strong> damit auch das Dendogramm zu unübersichtlich ist. Die<br />
Fünfclusterlösung wird durch die Datenbasis des Scree-Tests besser bestätigt (vgl. Tabelle 26).<br />
Ebenfalls spricht für die Fünfclusterlösung, dass mit zunehmender Clusteranzahl auch die<br />
Fehlerquadratsumme sinkt.<br />
92
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Abbildung 34: Elbow-Kriterium zur Bestimmung der Clusteranzahl<br />
Fehlerquadratsumme<br />
2000<br />
1800<br />
1600<br />
1400<br />
1200<br />
1000<br />
800<br />
600<br />
400<br />
200<br />
0<br />
2 3 4 5 6 7 8 9 10 11 12 13 14 15<br />
Anzahl der Cluster<br />
Quelle: Eigene Berechnungen<br />
Durch das K-Means Verfahren wurde abschließend die ermittelte Näherungslösung<br />
des Ward-Algorithmus in sieben Iterationen optimiert. 93 Tabelle 13 zeigt, dass bei<br />
dieser Optimierung 24 % der Objekte zwischen den Clustern verschoben wurden.<br />
76 % der Fälle wurden durch die K-Means <strong>und</strong> Ward Methode gleich klassifiziert. 94<br />
Der auf Basis der Übereinstimmungsquoten berechnete Kappa-Koeffizient erreicht<br />
mit 0,694 einen positiven Wert, der signalisiert, dass die Übereinstimmungsquote<br />
wesentlich höher ausfällt, als dies bei einer zufälligen Zuordnung der Objekte zu den<br />
Clustern zu erwarten wäre. 95 Damit liegt eine recht gute Übereinstimmung zwischen<br />
den beiden Clusteralgorithmen vor.<br />
93 Die K-Means Methode kann nur angewendet werden, wenn die Startpartitionen sowie die Anzahl<br />
der Cluster a priori vorliegen. Eine direkte Berechnung, ohne das vorherige Ward-Verfahren, würde<br />
aufgr<strong>und</strong> zufälliger Startwerte zu unterschiedlichen Clusterlösungen führen (vgl. Kapitel 3.1.3).<br />
94 Neben der guten numerischen Übereinstimmung der K-Means <strong>und</strong> Ward Methode, ergab auch<br />
die inhaltliche Interpretation der Cluster ein annährend gleiches Ergebnis (vgl. Tabelle 27 <strong>und</strong> Tabelle<br />
28 im Anhang).<br />
95 Nach BORTZ (1999: 204) <strong>und</strong> JANSEN/LAATZ (2003: 249) kann der Kappa-Koeffizient ähnlich<br />
dem Korrelationskoeffizienten interpretiert werden. Schwache Korrelation = |r| < 0,5; mittlere<br />
Korrelation = 0,5 ≤ |r| < 0,8; starke Korrelation 0,8 ≤ |r| (FAHRMEIER ET AL. 2003: 136).<br />
93
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Tabelle 13: Kreuztabelle - K-Means versus Ward-Methode<br />
Ward<br />
K-Means<br />
Gesamt<br />
Cluster 1 2 3 4 5<br />
1 142 0 4 1 3 150<br />
2 64 138 17 13 27 259<br />
3 13 5 140 0 8 166<br />
4 8 1 0 62 0 71<br />
5 1 0 10 15 111 137<br />
Gesamt<br />
228 144 171 91 149 783<br />
Quelle: Eigene Berechnungen<br />
Zur Prüfung der internen Validität sind in Tabelle 14 die F-Werte der erhaltenen<br />
Clusterlösung dargestellt. Diese bilden ein Gütemaß für die Homogenität innerhalb<br />
der ermittelten Cluster (vgl. Abschnitt 3.1.3). Insgesamt unterschreiten alle aktiven<br />
Variablen die kritische Prüfgröße <strong>von</strong> 1. Damit kann <strong>von</strong> einer sehr guten<br />
Homogenität der Clusterlösung ausgegangen werden. Nach der Analysis of Variance<br />
(ANOVA) unterscheiden sich die Mittelwerte der clusterbildenden Variablen<br />
signifikant in den Gruppen (vgl. Tabelle 29 im Anhang). 96 Durch diese Unterschiede<br />
in den Clustern können 55 % der Varianz der aktiven Variablen erklärt werden (K-<br />
Means, eta² = 0,55; Ward, eta² = 0,50). Der eta Koeffizient zeigt an, wie sehr sich die<br />
Mittelwerte der clusterbildenden Variablen zwischen den verschiedenen Gruppen<br />
unterscheiden. Mit 0,74 (Ward eta = 0,70) weist er einen mittelstarken<br />
Zusammenhang auf (vgl. Abschnitt 3.1.3).<br />
Tabelle 14: Homogenität der Cluster (F-Werte der extrahierten Faktoren)<br />
Cluster<br />
1 2 3 4 5<br />
n = 228 n = 144 n = 171 n = 91 n = 149<br />
Faktoren<br />
29,1 % 18,4 % 21,8 % 11,6 % 19,0 %<br />
Faktor 1: patriotism 0,27 0,53 0,33 0,47 0,32<br />
Faktor 2: prestige effect of foreign<br />
brands 0,30 0,61 0,66 0,50 0,70<br />
Faktor 3: trust/performance effect of<br />
Chinese brands 0,50 0,45 0,39 0,45 0,44<br />
Quelle: Eigene Berechnungen<br />
96 Die Homogenitätsüberprüfung der passiven Variablen steht noch offen.<br />
94
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Zur Überprüfung der relativen Validität der Clusterlösung wurden die<br />
Übereinstimmungsquoten herangezogen, die auf Gr<strong>und</strong>lage der Diskriminanzanalyse<br />
sowie der replizierten Clusteranalysen ermittelt wurden. Anhand der<br />
Diskriminanzfunktion konnten 96,3 % der ursprünglich durch die K-Means Methode<br />
gruppierten Fälle korrekt klassifiziert werden (Ward Methode 81,9%). Wilks`<br />
Lambda liegt mit einem Wert <strong>von</strong> 0,084 nahe bei Null, was auf eine hohe Güte der<br />
Ergebnisse schließen lässt, da nur 8,4 % der Streuung der aktiven Variablen nicht<br />
durch die Gruppenunterschiede erklärt werden können (JANSEN/LAATZ 2003: 445). 97<br />
Zur Berechnung der Übereinstimmungsquote mit der replizierten Clusteranalyse<br />
wurde der gesamte Datensatz durch eine Zufallsauswahl in zwei gleich große Hälften<br />
geteilt. 98 Für jeden der Teildatensätze wurde eine Clusteranalyse mittels des Ward<strong>und</strong><br />
des K-Means Algorithmus durchgeführt. Die Ausgangsanalysen sowie die<br />
Teilanalysen ergaben mit einer Übereinstimmungsquote <strong>von</strong> 78,2 % (Kappa-Wert<br />
<strong>von</strong> 0,726) sehr ähnliche Clusterstrukturen (vgl. Tabelle 30 im Anhang). Darüber<br />
hinaus zeigte jedoch ein inhaltlicher <strong>Vergleich</strong> der Cluster, dass zum Teil starke<br />
Mittelwertabweichungen zwischen den Ergebnissen der replizierten Clusteranalyse<br />
<strong>und</strong> der Ausgangslösung vorliegen (vgl. Tabelle 31 <strong>und</strong> Tabelle 32). Somit kann<br />
letztendlich <strong>von</strong> einer nur sehr eingeschränkten Generalisierbarkeit der<br />
Gruppierungsergebnisse gesprochen werden.<br />
Tabelle 15: Charakterisierung der Cluster durch die T-Werte der aktiven Faktoren<br />
1 2 3 4 5<br />
Cluster<br />
n = 228 n = 144 n = 171 n = 91 n = 149<br />
Faktoren<br />
29,1 % 18,4 % 21,8 % 11,6 % 19,0 %<br />
Faktor 1: patriotism 0,48 0,39 0,69 -1,38 -1,07<br />
Faktor 2: prestige effect of foreign<br />
brands -0,83 1,07 0,18 -0,51 0,34<br />
Faktor 3: trust/performance effect of<br />
Chinese brands 0,38 0,87 -1,01 0,70 -0,69<br />
Quelle: Eigene Berechnungen<br />
97 nicht erklärte Streuung<br />
W ilk´s Lambda =λ=<br />
gesamte Streuung<br />
Wilk`s Lambda <strong>und</strong> eta² (kanonischen Korrelationskoeffizienten) sind zueinander komplementär,<br />
da sie sich zu eins ergänzen (JANSEN/LAATZ 2003: 445).<br />
98 Die Ausreißer wurden bereits vorher eliminiert.<br />
95
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Einen ersten Anhaltspunkt zur Beurteilung der Interpretationsfähigkeit der<br />
Clusterlösung liefert die Struktur des Gruppierungsergebnisses, welche durch die<br />
Anzahl der Cluster <strong>und</strong> den relativen Anteil der Objekte pro Gruppe charakterisiert<br />
wird (vgl. Tabelle 15). Weiterhin werden die t-Werte der Variablen zur Interpretation<br />
herangezogen (vgl. Kapitel 3.1.3).<br />
Abbildung 35: Beschreibung der Cluster durch die Statements der Faktoren<br />
Quelle: Eigene Berechnungen<br />
96
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Da im Rahmen dieser Arbeit der Verfahrensvergleich im Vordergr<strong>und</strong> steht, werden<br />
zur Bewertung der Interpretierbarkeit nur die t-Werte der aktiven Faktoren (vgl.<br />
Tabelle 15) <strong>und</strong> die dahinter stehenden Statements herangezogen (Abbildung 35).<br />
Denn nur diese haben im Gegensatz zu den passiven Variablen einen Einfluss auf die<br />
Homogenität einer Gruppe. Im Folgenden werden die Gruppen kurz beschrieben.<br />
Cluster 1: „Patriotic Brand Supporters“ (29,1 %)<br />
Mit 29,1 % der Befragten sind die „Patriotic Brand Supporters“ die größte Gruppe.<br />
Das deutlichste Merkmal dieses Clusters ist die pro-patriotische Gr<strong>und</strong>einstellung.<br />
Darüber hinaus sind eine starke Präferenz <strong>und</strong> ein großes Vertrauen für chinesische<br />
Marken vorhanden. Die „Patriotic Brand Supporters“ schätzen die Performance ihrer<br />
chinesischen Marken <strong>und</strong> lehnen den Kauf <strong>von</strong> internationalen Marken aus<br />
Prestigegründen ab. Aus diesem Gr<strong>und</strong> kommt dem Patriotismus bei der<br />
Kaufentscheidung eine gleichwertige Bedeutung wie der Präferenz für chinesische<br />
Marken zu.<br />
Cluster 2: „Brand Lovers“ (18,4 %)<br />
Das Cluster der „Brand Lovers“ wird durch ein konsistentes Bekenntnis zur Marke<br />
geprägt. Mit 18,4 % der Befragten weist es eine ähnliche Größe wie die Cluster 3<br />
<strong>und</strong> 4 auf. Eine differenzierte Betrachtung der Gruppe in Hinblick auf die<br />
Markenpräferenz verdeutlicht, dass sowohl internationale als auch chinesische<br />
Marken präferiert werden, allerdings bestimmt der Kaufanlass die<br />
Wahlentscheidung. Der Fokus auf internationale Marken lässt sich<br />
schwerpunktmässig anhand <strong>von</strong> Prestige-Gründen erklären. Patriotismus-Motive<br />
spielen bei der Kaufentscheidung im Gegensatz dazu eine untergeordnete Rolle.<br />
Cluster 3: „Foreign Brand Accepters“ (21,8%)<br />
In der Gruppe der „Foreign Brand Lovers“, die 21,8 % der Stichprobe umfasst,<br />
finden sich Probanden mit einer deutlichen Markenpräferenz, die sowohl auf<br />
internationale als auch auf nationale Marken fokussiert sind. Im Widerspruch zur<br />
Präferenz für internationale Marken scheint das äußerst hohe Maß an Patriotismus zu<br />
stehen. Daher ist anzunehmen, dass die Foreign Brands vor allem aus Prestige-<br />
Gründen nachgefragt werden, etwa als Geschenk oder für besondere Anlässe.<br />
97
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Cluster 4: „Chinese Brand Supporters“ (11,6 %)<br />
Ähnlich wie beim Cluster 1 ist das deutlichste Merkmal der kleinsten Gruppe die<br />
Präferenz für chinesische Marken. Die „Chinese Brand Supporters“ schätzen die<br />
Performance „ihrer“ chinesischen Marken ebenso wie die „Patriotic Brand<br />
Supporters“. Internationale Marken werden im Gegensatz dazu abgelehnt. Vor allem<br />
die in den Clustern 2 bis 3 zitierten Prestige-Gründe wirken an dieser Stelle negativ.<br />
Der Patriotismus-Faktor ist im <strong>Vergleich</strong> zu den anderen Clustern am schwächsten<br />
ausgeprägt.<br />
Cluster 5: „Foreign Brand Lovers“ (19,0 %)<br />
Die Gruppe der „Foreign Brand Lovers“ verfügt mit 19,0 % der befragten<br />
Konsumenten über eine ähnliche Größe wie das Cluster der „Foreign Brand<br />
Accepters“. Weitere Parallelen werden bei der Betrachtung des Faktors 2 „Prestige-<br />
Effekt <strong>von</strong> internationalen Marken“ <strong>und</strong> des Faktors 3 „Vertrauens-/Performance-<br />
Effekt <strong>von</strong> chinesischen Marken“ deutlich. Der Fokus auf internationale Marken ist<br />
allerdings etwas stärker ausgeprägt als bei Cluster 3. Im Gegensatz zu den<br />
aufgezählten Gemeinsamkeiten fällt das äußerst niedrige Maß an Patriotismus in<br />
diesem Cluster auf.<br />
Insgesamt konnten somit durch die multivariate Clusteranalyse fünf verschiedene<br />
Gruppen aufgedeckt werden, die alle außer den „Brand Lovers“ (18,4 %), in Form<br />
einer allgemeinen Markenpräferenz für internationale als auch für chinesische<br />
Marken zu spezifizieren sind.<br />
Modell 2:<br />
Im zweiten Modell wurden die 11 Variablen aus der Faktorenanalyse direkt als<br />
aktive Variablen in der Clusteranalyse verwendet. Die Ergebnisse verschiedener<br />
Gruppenlösungen zeigten insgesamt, im <strong>Vergleich</strong> zu dem ersten Modell, eine<br />
wesentlich höhere Fehlerquadratsumme <strong>und</strong> daraus folgend eine sehr geringe<br />
Homogenität der Cluster in Bezug auf die gruppenbildenden Variablen. Nach<br />
BACKHAUS et al. (2003: 537f.) ist die Ursache für diese mindere Güte der Ergebnisse<br />
darin zu sehen, dass eine ungleiche Korrelation unter den aktiven Variablen zu<br />
unterschiedlichen Gewichtungen führt, die bei der Fusionierung der Objekte eine<br />
98
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Überbetonung bestimmter Merkmale bedeutet <strong>und</strong> somit zu Verzerrungen der<br />
Ergebnisse führen kann. Die im ersten Modell vorgeschaltete Faktorenanalyse beugte<br />
dieser Ungleichgewichtung vor, wodurch anschließend auch bessere Ergebnisse<br />
erzeugt wurden. Aufgr<strong>und</strong> dessen, dass das zweite Modell im Gegensatz zum ersten<br />
keinen zusätzlichen Informationsgewinn in Bezug auf den Verfahrensvergleich<br />
erbringt, wurde im Folgenden darauf verzichtet dieses näher zu beschreiben.<br />
4.5.3 Ergebnisse der künstlichen <strong>Neuronalen</strong> Netze<br />
Analog zu der Ergebnispräsentation bei der <strong>multivariaten</strong> Clusteranalyse werden in<br />
diesem Abschnitt die Ergebnisse der künstlichen <strong>Neuronalen</strong> Netze (SOM)<br />
dargestellt.<br />
Modell 1:<br />
Zur Bildung der SOM <strong>und</strong> somit zur Typlogisierung der chinesischen Konsumenten<br />
bezüglich deren Markenpräferenzen wurden die aus der Faktorenanalyse (aus Kapitel<br />
4.5.2) extrahierten Komponenten, „Patriotismus“, „Prestige-Effekt <strong>von</strong> internationalen<br />
Marken“ <strong>und</strong> „Vertrauens-/Performance-Effekt <strong>von</strong> chinesischen<br />
Marken“, als Inputneuronen verwendet.<br />
Bei der Festlegung des Outputgitters der SOM zeigte sich, dass die besten<br />
Ergebnisse, in Hinsicht auf eine hohe Homogenität der Cluster, erzeugt werden<br />
konnten, wenn eine Dimension der Outputkarte auf 2 Neuronen beschränkt wurde<br />
(Tabelle 33). 99 Darüber hinaus erwies es sich als vorteilhaft, zunächst die Dimension<br />
des Outputgitters zu bestimmen <strong>und</strong> erst daran anschließend das Netz durch<br />
systematisches Verändern der Lernraten zu optimieren. 100 Die Veränderung der<br />
Startgewichte hatte im Gegensatz zu den MLP nicht sehr starke Auswirkungen auf<br />
das Ergebnis der Clusterlösung. 101 Abbildung 36 verdeutlicht die Entwicklung der<br />
99 Dieser Sachverhalt wurde aber nur bis zu einer Clusteranzahl <strong>von</strong> fünfzehn überprüft.<br />
100 Letztendlich erweisen sich bei diesem Datensatz folgende Einstellungen als optimal: Learning<br />
rate decay = linear; Phase 1: Neighborhood = 2, Initial Eta = 0,6, Cycles 60; Phase 2: Neighborhood =<br />
1, Initial Eta = 0,2, Cycles 450<br />
101 In Zukunft sollten jedoch in Bezug auf die Veränderungen der Startgewichte weitere Untersuchungen<br />
erfolgen.<br />
99
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Fehlerquadratsumme mit zunehmender Clusteranzahl. 102 Obwohl demzufolge nach<br />
dem Scree-Test eine Sieben- oder Achtclusterlösung statistisch optimal wäre, wird<br />
im Folgenden die Fünferlösung weiter betrachtet um den <strong>Vergleich</strong> der Ergebnisse<br />
mit der <strong>multivariaten</strong> Clusteranalyse zu gewähren.<br />
Abbildung 36: Entwicklung der Fehlerquadratsumme bei den SOM 103<br />
1800<br />
1600<br />
Fehlerquadratsumme<br />
1400<br />
1200<br />
1000<br />
800<br />
600<br />
400<br />
200<br />
0<br />
2 3 4 5 6 7 8 9 10 11 12 13 14 15<br />
Anzahl der Cluster<br />
Quelle: Eigene Berechnungen<br />
Die Prüfung der internen Validität mit Hilfe der Tabelle 16 zeigt, dass die F-Werte<br />
des Faktors „prestige effect of foreign brands“ im Durchschnitt der kritischen<br />
Prüfgröße <strong>von</strong> 1 entsprechen. Somit kann, obwohl sich nach der ANOVA die<br />
Mittelwerte der clusterbildenden Variablen signifikant in den Gruppen unterscheiden<br />
(vgl. Tabelle 36 im Anhang), die Gruppenlösung als lediglich mäßig homogen<br />
beurteilt werden. 104 Tabelle 35 im Anhang bestätigt diese Aussage durch die hohe<br />
Fehlervarianz <strong>und</strong> den geringen Eta-Wert des zweiten aktiven Faktors. 105 Durch die<br />
Unterschiede in den Clustern können trotzdem 46 % der Varianz der aktiven<br />
102 Beim Training der SOM wurde ersichtlich, dass mit zunehmender Clusteranzahl auch die<br />
Rechenzeit steigt.<br />
103 Es konnte aufgr<strong>und</strong> der Dimensionen der SOM keine Zweiclusterlösung gebildet werden.<br />
104 Die Homogenitätsüberprüfung der passiven Variablen steht noch offen.<br />
105 Die weiteren Analysen bezüglich der Homogenitäten der Clusterlösungen offenbarten, dass ab<br />
der Sechserclusterlösung eine gute Homogenität der Gruppen vorliegt.<br />
100
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Variablen erklärt werden (eta² = 0,46). Der eta Koeffizient mit 0,60 weist einen<br />
mittelmäßigen Zusammenhang auf.<br />
Tabelle 16: Homogenität der Cluster (F-Werte der extrahierten Faktoren)<br />
Cluster<br />
1 2 3 4 5<br />
n = 138 n = 198 n = 162 n = 181 n = 104<br />
Faktoren<br />
17,4 % 25 % 20,4 % 22,8 % 14,4 %<br />
Faktor 1: patriotism 0,30 0,32 0,25 0,39 0,11<br />
Faktor 2: prestige effect of foreign<br />
brands 0,99 1,01 1,00 1,00 0,87<br />
Faktor 3: trust/performance effect of<br />
Chinese brands 0,08 0,32 0,33 0,61 0,45<br />
Quelle: Eigene Berechnungen<br />
Zur Überprüfung der relativen Validität der Clusterlösung wurden die<br />
Übereinstimmungsquoten herangezogen, die auf Gr<strong>und</strong>lage der Diskriminanzanalyse<br />
sowie der replizierten Clusteranalysen ermittelt wurden. Anhand der<br />
Diskriminanzfunktion konnten 88 % der ursprünglich durch die K-Means Methode<br />
gruppierten Fälle korrekt klassifiziert werden. Wilks`Lambda liegt mit einem Wert<br />
<strong>von</strong> 0,097 nahe bei Null, was auf eine hohe Güte der Ergebnisse schließen lässt, da<br />
nur 9,7 % der Streuung der aktiven Variablen nicht durch die Gruppenunterschiede<br />
erklärt werden können. Es muss jedoch beachtet werden, dass die<br />
Diskriminanzfunktion linear ist <strong>und</strong> somit für die Prüfung der relativen Validität der<br />
nichtlinearen SOM nur bedingt geeignet ist. Zur Berechnung der<br />
Übereinstimmungsquote mit der replizierten SOM wurde der gesamte Datensatz<br />
durch eine Zufallsauswahl in zwei gleich große Hälften geteilt. 106 Die<br />
Ausgangsanalysen sowie die Teilanalysen ergaben mit einer Übereinstimmungsquote<br />
<strong>von</strong> 52,82% (Kappa-Wert <strong>von</strong> 0,401 Kappa) eine nur sehr schwache Ähnlichkeit der<br />
Clusterstrukturen (vgl. Tabelle 37 im Anhang). Darüber hinaus zeigte der<br />
Mittelwertvergleich zwischen den Ergebnissen der replizierten <strong>und</strong> der<br />
Ausgangslösung der SOM kaum Übereinstimmungen (Tabelle 38 <strong>und</strong> Tabelle 39).<br />
106<br />
Die Ausreißer wurden bereits vorher eliminiert. Die Zufallsauswahl der <strong>multivariaten</strong><br />
Clusteranalyse ist identisch.<br />
101
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Somit kann <strong>von</strong> einer sehr schlechten Generalisierbarkeit der<br />
Gruppierungsergebnisse gesprochen werden.<br />
Tabelle 17: Charakterisierung der Cluster durch die T-Werte der Faktoren<br />
Cluster<br />
1 2 3 4 5<br />
n = 138 n = 198 n = 162 n = 181 n = 104<br />
Faktoren<br />
17,4 % 25 % 20,4 % 22,8 % 14,4 %<br />
Faktor 1: patriotism 0,78 0,55 0,55 -1,34 -0,60<br />
Faktor 2: prestige effect of foreign<br />
brands -0,13 -0,15 0,01 0,22 0,06<br />
Faktor 3: trust/performance effect of<br />
Chinese brands -0,05 1,10 -1,09 0,24 -0,73<br />
Quelle: Eigene Berechnungen<br />
Für die Beurteilung der Interpretationsfähigkeit der Clusterlösung der SOM wurde<br />
zum einen die Struktur des Gruppierungsergebnisses <strong>und</strong> zum anderen die t-Werte<br />
der aktiven Variablen herangezogen (vgl. Tabelle 17). Es zeigt sich, dass die oben<br />
beschriebene geringe Homogenität der Cluster in Bezug auf den Faktor „prestige<br />
effect of foreign brands“ auch mit einer verminderten Interpretierbarkeit einhergeht.<br />
Die Abbildung 37 enthält daher nur die Mittelwerte der Faktoren „patriotism“ <strong>und</strong><br />
„trust/performance effect of Chinese brands“. Ein <strong>Vergleich</strong> der Mittelwerte mit<br />
denen der <strong>multivariaten</strong> Clusteranalyse (vgl. Tabelle 15) lässt ähnliche<br />
Ausprägungen bzw. Werte erkennen. Aufgr<strong>und</strong> dessen wird auf eine detaillierte<br />
Beschreibung der Cluster verzichtet.<br />
Die mittelmäßige Homogenität der Gruppen sowie die geringe Generalisierbarkeit<br />
der Clusterlösung weist insgesamt ein mittelgutes Ergebnis der SOM auf. Die<br />
weiteren Analysen zeigten, dass erst ab einer Sechsclusterlösung eine bessere<br />
Homogenität sowie Interpretation der Gruppen gegeben ist. Demnach sollten<br />
zukünftige Forschungsarbeiten untersuchen, inwieweit die Anzahl der Inputvariablen<br />
sowie die Anzahl der Gruppen einen Einfluss auf das Ergebnis der SOM haben.<br />
102
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Abbildung 37: Beschreibung der Cluster durch die Statements der Faktoren (SOM)<br />
Quelle: Eigene Berechnungen<br />
Modell 2:<br />
Im zweiten Modell wurden die 11 Variablen aus der Faktorenanalyse direkt als<br />
aktive Variablen für den Netzwerkaufbau verwendet. Die Ergebnisse verschiedener<br />
Gruppenlösungen zeigten insgesamt, im <strong>Vergleich</strong> zu dem ersten Modell, eine<br />
wesentlich höhere Fehlerquadratsumme <strong>und</strong> daraus folgend eine sehr geringe<br />
Homogenität der Cluster in Bezug auf die gruppenbildenden Variablen. Dieses<br />
Ergebnis entspricht somit auch den Resultaten aus der <strong>multivariaten</strong> Clusteranalyse<br />
(vgl. 4.5.2, Modell 2). Demnach wird auch im Folgenden auf weitere Analysen<br />
verzichtet.<br />
103
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
4.5.4 Ergebnisse der Fallstudie <strong>und</strong> Verfahrensvergleich<br />
Die empirischen Untersuchungen im ersten Modell haben gezeigt, dass sowohl mit<br />
der <strong>multivariaten</strong> Clusteranalyse als auch mit den SOM die Probanden aus Wuhan<br />
hinsichtlich ihres Kaufverhaltens in Bezug auf internationale <strong>und</strong> chinesische<br />
Marken typologisiert werden können. Im zweiten Modell wurde dagegen ersichtlich,<br />
dass ohne eine vorherige Dimensionsreduktion (vgl. Modell 2) beide<br />
Verfahrensklassen im <strong>Vergleich</strong> zum ersten Modell schlechtere Ergebnisse hatten.<br />
Demnach konzentriert sich der folgende Verfahrensvergleich auf das erste Modell.<br />
Abbildung 38 macht deutlich, dass der K-Means Algorithmus im <strong>Vergleich</strong> zu den<br />
anderen Methoden auch bei zunehmender Clusteranzahl die kleinste<br />
Fehlerquadratsumme aufweist <strong>und</strong> somit auch die homogensten Gruppen bildet. Die<br />
SOM <strong>und</strong> die Ward-Methode zeigen einen annährend gleichen Verlauf der<br />
Fehlerquadratsumme. Aufgr<strong>und</strong> dieser Ergebnisse können die positiven Aussagen<br />
aus der Literatur in Bezug auf die Überlegenheit der KNN bei der Klassifizierung<br />
<strong>von</strong> Objekten im <strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren nicht bestätigt werden<br />
(vgl. Kapitel 4.1).<br />
Abbildung 38: SOM, K-Means <strong>und</strong> Ward im <strong>Vergleich</strong><br />
Fehlerquadratsumme<br />
2000<br />
1800<br />
1600<br />
1400<br />
1200<br />
1000<br />
800<br />
600<br />
400<br />
200<br />
0<br />
2 3 4 5 6 7 8 9 10 11 12 13 14 15<br />
Anzahl der Cluster<br />
Ward<br />
K-Means<br />
SOM<br />
Quelle: Eigene Berechnungen<br />
104
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Die Berechnung des Scree-Test-Diagramms (vgl. Abbildung 38) gestaltet sich bei<br />
der K-Means Methode <strong>und</strong> den SOM als sehr aufwendig, da für jede Gruppenlösung<br />
(<strong>von</strong> 2 bis 15) eine Clusteranalyse berechnet bzw. ein Netz trainiert werden muss, um<br />
anschließend durch die ANOVA die Fehlerquadratsumme pro Input bzw.<br />
clusterbildende Variable zu kalkulieren. Erst daran anschließend können in Excel die<br />
Gesamtfehlerquadratsummen berechnet <strong>und</strong> die Scree-Plots erstellt werden. Aus<br />
dieser umfangreichen Vorgehensweise wird ersichtlich, dass es für den praktischen<br />
Anwender bei der K-Means <strong>und</strong> SOM Clusterung nur schwer möglich ist, die<br />
optimale Clusteranzahl zu definieren, wenn er nicht vorweg eine Hypothese über die<br />
Gruppenanzahl hat. Bei einer vorherigen Festlegung der Clusteranzahl würde aber<br />
wiederum zum Teil der explorative Charakter der Clusteranalyse bzw. der SOM als<br />
struktur-entdeckendes Verfahren verloren gehen. Somit ist der Anwender auf ein<br />
Hilfsverfahren, z. B. die Ward-Methode angewiesen, um die optimale<br />
Gruppenanzahl für die betreffende Problemsituation festzulegen. In diesem<br />
Zusammenhang liegen jedoch keine Literaturhinweise über die Verwendung eines<br />
Hilfsverfahrens bei den SOM vor. 107 Zukünftige Studien sollten diese Problematik<br />
mit einbeziehen.<br />
Abbildung 39: Validität der Clusterlösungen im Verfahrensvergleich<br />
Cluster<br />
Validierung<br />
interne<br />
Gütekriterium K-Means SOM<br />
eta² 0,55 0,46<br />
Validität eta 0,74 0,60<br />
Übereinstimmungsquote der DA 96,30 88,00<br />
relative<br />
Validität<br />
Wilks` Lambda 0,084 0,097<br />
Übereinstimmungsquote der RCLU 78,20 52,82<br />
Kappa-Wert der RCLU 0,726 0,401<br />
DA = Diskriminanzanalyse<br />
Quelle: Eigene Berechnungen<br />
RCLU = replizierte Clusteranalyse<br />
107 In diesem Kontext müssten die SOM auch die Endpartitionen des Ward-Algorithmus verwenden<br />
können (Kapitel 3.1.3). Das heißt aber letztendlich zusätzliche Softwareimplikationen.<br />
105
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
Die Validitätskriterien der Fünfclusterlösungen der Verfahren in Abbildung 39<br />
zeigen, dass die K-Means-Methode bei der internen <strong>und</strong> relativen Prüfung bessere<br />
Ergebnisse hat als die SOM. In Hinsicht auf die relative Validität wurde jedoch bei<br />
dem inhaltlichem <strong>Vergleich</strong> der Gruppen (Mittelwertvergleich) der replizierten <strong>und</strong><br />
der Ausgangslösung beider Verfahren ersichtlich, dass nur wenige<br />
Übereinstimmungen zwischen den Ergebnissen vorliegen. Die multivariate<br />
Clusteranalyse <strong>und</strong> die SOM weisen somit insgesamt eine schlechte<br />
Generalisierungsleistung auf. Darüber hinaus wird ersichtlich, dass der Einsatz der<br />
Diskriminanz- <strong>und</strong> der replizierten Clusteranalyse zur Prüfung der Generalisierbarkeit<br />
der Gruppenlösungen, wie er in der Literatur empfohlen wird, nur dann<br />
zweckmäßig ist, wenn die Ergebnisse der replizierten Analysen auch auf inhaltliche<br />
Übereinstimmungen hin überprüft werden.<br />
Tabelle 18: Kreuztabelle – SOM versus K-Means<br />
SOM<br />
Gesamt<br />
Cluster 1 2 3 4 5<br />
1 81 111 23 0 13 228<br />
2 25 80 5 24 10 144<br />
3 32 0 134 0 5 171<br />
4 0 7 0 82 2 91<br />
K-Means<br />
5 0 0 0 75 74 149<br />
Gesamt<br />
138 198 162 181 104 783<br />
Quelle: Eigene Berechnungen<br />
Tabelle 18 zeigt, dass nur 58 % der Objekte durch die SOM <strong>und</strong> K-Means Methode<br />
gleich klassifiziert wurden. Der auf Basis der Übereinstimmungsquoten berechnete<br />
Kappa-Koeffizient erreicht mit 0,473 einen positiven Wert, der signalisiert, dass die<br />
Übereinstimmungsquote nur geringfügig höher ausfällt, als dies bei einer zufälligen<br />
Zuordnung der Objekte zu den Clustern zu erwarten wäre. Neben dieser schlechten<br />
Übereinstimmung zwischen den Gruppierungsergebnissen der Verfahrensklassen,<br />
zeigt auch die inhaltliche Interpretation der Cluster (durch die Mittelwerte) zum Teil<br />
sehr unterschiedliche Ergebnisse auf (vgl. Tabelle 15 <strong>und</strong> Tabelle 17). Ein <strong>Vergleich</strong><br />
der 3D-Streudiagramme der Abbildung 50 <strong>und</strong> Abbildung 51 im Anhang<br />
verdeutlicht diesen Zusammenhang noch einmal visuell. Die Ursache für die geringe<br />
Übereinstimmungsquote zwischen den Verfahren ist vor allem darauf<br />
zurückzuführen, dass der zweite aktive Faktor bei den SOM kaum zur Clusterbildung<br />
106
4 Empirische Anwendung <strong>und</strong> <strong>Vergleich</strong> der Verfahren<br />
verwendet wurde. Die weitergehenden Analysen zeigten erst ab einer<br />
Sechsclusterlösung, dass eine Einbeziehung des zweiten Faktors in die<br />
Gruppenbildung erfolgt. Inwieweit sich die SOM deshalb nur für umfangreichere<br />
Gruppierungslösungen eignen, sollte in weitergehenden Studien überprüft werden.<br />
Dies spielt insbesondere für die praktische Marktforschung eine wichtige Rolle da<br />
jede weitere ermittelte Gruppe auch zusätzliche Marketingkosten bedeutet. Ein<br />
Analyseverfahren sollte dementsprechend auch bei einer geringen Gruppenanzahl<br />
gute Ergebnisse erbringen.<br />
Die Interpretationen der Gruppenlösungen der <strong>multivariaten</strong> Clusteranalyse <strong>und</strong> den<br />
SOM zeigen, dass insgesamt fünf verschiedene Gruppen spezifiziert werden können,<br />
<strong>von</strong> denen alle einen deutlich ausgeprägten Markenfokus aufweisen. Dieser Fokus ist<br />
allerdings differenziert zu betrachten. Denn auf der einen Seite finden sich die<br />
Cluster, die eine deutliche Präferenz für internationale Marken haben, während auf<br />
der anderen Seite die Gruppen deren deutlichstes Merkmal die Präferenz für<br />
chinesische Marken ist einen Gegenpol bilden. Lediglich bei einem Cluster, den<br />
„Brand Lovers“, ist der Markenfokus in Form einer allgemeinen Markenpräferenz zu<br />
spezifizieren.<br />
Die Schlussfolgerung dieser Fallstudie in Bezug auf den Verfahrensvergleich ist,<br />
dass die SOM, nach der internen Prüfung, wie die Ward-Methode in der<br />
Primärforschung eingesetzt werden können. Aufgr<strong>und</strong> der mangelnden<br />
Generalisierbarkeit der Ergebnisse sowie den fehlenden Optionen (Voranalysen) für<br />
eine optimale Clusteranzahl sind die SOM jedoch im <strong>Vergleich</strong> zu der K-Means<br />
Methode nur bedingt einsetzbar.<br />
107
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
Im Rahmen dieses Kapitels werden die in Abschnitt 4.2 aufgezeigten Gütekriterien<br />
(vgl. Abbildung 27) verwendet, um die Leistungsfähigkeit der <strong>multivariaten</strong><br />
Verfahren <strong>und</strong> der künstlichen <strong>Neuronalen</strong> Netze in der Primärforschung zu<br />
vergleichen. Die Basis für diesen <strong>Vergleich</strong> bilden, neben den methodischen<br />
Gr<strong>und</strong>lagen der Verfahren, die Ergebnisse der zuvor vorgestellten Fallstudien. 108<br />
Darüber hinaus wird überprüft, ob die KNN durch ihre spezifischen Eigenschaften<br />
(vgl. Abschnitt 3.3) im Stande sind, die statistischen Problemstellungen in der<br />
Primärforschung besser zu lösen als die <strong>multivariaten</strong> Verfahren. Die Ergebnisse der<br />
literarischen Bestandsaufnahme werden ebenfalls mit in den <strong>Vergleich</strong><br />
eingeschlossen.<br />
Datenorientierte Kriterien<br />
In Bezug auf die „Datendeformation“ haben die KNN den Vorteil, keine Ansprüche<br />
an das Skalenniveau zu stellen. Das heißt, die MLP <strong>und</strong> SOM können sowohl mit<br />
metrisch-/ordinal- als auch mit nominalskalierten Daten ein Netzwerk aufbauen. Um<br />
die <strong>multivariaten</strong> Verfahren anwenden zu können müssen die Daten hingegen ein<br />
bestimmtes Skalenniveau aufweisen (vgl. Abbildung 7). Demgemäß liegt unter<br />
anderem bei der multiplen linearen Regressionsanalyse die Prämisse vor, dass die<br />
abhängige Variable metrisch skaliert sein muss. Ist diese stattdessen z. B.<br />
nominalskaliert, müssen andere Verfahren, die logistische oder multinomiallogistische<br />
Regressionsanalyse, verwendet werden (vgl. Kapitel 3.1.2). Auch für die<br />
Durchführung der <strong>multivariaten</strong> Clusteranalyse ist es notwenig, dass die Daten der<br />
clusterbildenden Variablen im metrischem Skalenniveau vorliegen (BACKHAUS et al.<br />
2003: 517).<br />
Die Ansprüche der KNN (MLP) an die „Datenqualität“ (Missing Values) sind<br />
geringer als die der <strong>multivariaten</strong> Verfahren. Dementsprechend kann z. B. im<br />
108 Aufgr<strong>und</strong> der geringen Ergebnisunterschiede zwischen den SOM <strong>und</strong> den MLP werden diese<br />
nicht getrennt durch die Kriterien bewertet.<br />
108
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
Rahmen der Regressionsanalyse keine Schätzung für die endogene Variable eines<br />
Datenobjektes vorgenommen werden, wenn nur ein Wert einer exogenen Variablen<br />
fehlt. Diese Problematik ist besonders dann schwerwiegend, wenn viele Regressoren<br />
zur Schätzung einbezogen werden <strong>und</strong> gleichzeitig eine hohe Anzahl an Missing<br />
Values vorliegt. Daraus folgt, dass nur für sehr wenige Datenobjekte eine Schätzung<br />
vorgenommen werden kann <strong>und</strong> daran anschließend auch nur eine geringere<br />
Generalisierung der Ergebnisse möglich ist. Die KNN, in diesem Fall die MLP, sind<br />
durch ihre parallele Informationsverarbeitung (vgl. Kapitel 3.3) tolerant gegenüber<br />
diesem Missing Values Problem. Inwieweit diese Toleranz jedoch mit einer geringen<br />
Approximation an das tatsächliche Output einhergeht, konnte im Rahmen dieser<br />
Arbeit nicht überprüft werden (vgl. Abschnitt 3.3). Bei der <strong>multivariaten</strong><br />
Clusteranalyse sowie den SOM konnten keine unterschiedlichen Einflüsse der<br />
Datenqualität auf das Ergebnis identifiziert werden. Wie gut KNN <strong>und</strong> multivariate<br />
Verfahren mit Datenfehlern (falsche oder fehlerhafte Daten) umgehen können, steht<br />
ebenfalls noch offen.<br />
Hinsichtlich der Verarbeitungsfähigkeit <strong>von</strong> großen „Datenmengen“ zeigen die<br />
KNN im <strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren ein besseres Laufzeitverhalten.<br />
Der Gr<strong>und</strong> dafür ist, dass die statistischen KNN ursprünglich für das Data Mining<br />
entwickelt wurden <strong>und</strong> somit auch das originäre Ziel haben, sehr große Datenmengen<br />
automatisch verarbeiten zu können (vgl. Kapitel 2.2). In der Primärforschung liegen<br />
jedoch im Gegensatz zum Data Mining häufig kleinere Stichproben mit einer relativ<br />
großen Anzahl an (psychographischen) Variablen vor. Das Ziel der statistischen<br />
Analysen ist dann, anhand <strong>von</strong> wenigen Variablen aussagekräftige Ergebnisse zu<br />
erhalten (Dimensionsreduktion). Im Rahmen der ersten Fallstudie (Modell 2) wurde<br />
deutlich, dass die multivariate Rückwärtsregression im <strong>Vergleich</strong> zur Pruning-<br />
Methode (MLP) stabilere <strong>und</strong> validere Ergebnisse erzeugt <strong>und</strong> demzufolge besser die<br />
relevanten bzw. signifikanten Variablen selektieren kann. Die zweite Fallstudie<br />
zeigte hingegen, dass weder die SOM noch die multivariate Clusteranalyse bei vielen<br />
Input- bzw. clusterbildenden Variablen valide Ergebnisse erbringen konnten.<br />
Demnach können die KNN die Komplexität einer statistischen Problemsituation (vgl.<br />
Kapitel 3.3) nicht besser aufdecken als die <strong>multivariaten</strong> Verfahren. Diese Aussage<br />
muss jedoch eingeschränkt betrachtet werden, denn ob die <strong>Neuronalen</strong> Netze die<br />
109
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
„Nichtlinearität der Daten“ als Teil der Dimension der Komplexität (vgl. Abschnitt<br />
3.3 besser erklären können als die <strong>multivariaten</strong> Methoden konnte nicht überprüft<br />
werden, da die verwendeten Fallstudien nur geringe nachweisbare nichtlineare<br />
Datenstrukturen aufwiesen. 109<br />
Methodenorientierte Kriterien<br />
Die methodenorientierten Kriterien beziehen sich neben den Analyseergebnissen<br />
(Ergebnissicherheit, Generalisierung,) auch auf die angewendete Verfahrensmethodik<br />
(Modellprämissen). Das Kriterium „Ergebnissicherheit“ wurde umfassend<br />
durch statistische Kennzahlen in den Kapiteln 4.4 <strong>und</strong> 4.5 überprüft. In dem ersten<br />
Fallbeispiel (Modell 1) wurde dargestellt, dass die Gütekriterien (adjusted R², MSE)<br />
der In-Sample-Mengen bei der Regressionsanalyse geringfügig besser waren als bei<br />
den MLP. Die zweite Fallstudie machte deutlich, dass die K-Means Methode nach<br />
der Fehlervarianz bzw. dem F-Test homogenere Cluster bildete als die SOM.<br />
Lediglich das Ward-Verfahren wies eine ähnliche Homogenität in den Gruppen auf<br />
wie die SOM. Aufgr<strong>und</strong> dieser Resultate können die in der Literatur überwiegend<br />
positiven Aussagen hinsichtlich der Ergebnissicherheit der KNN im Data Mining<br />
(vgl. Kapitel 4.1) nicht auf die Primärforschung übertragen werden. Um diese These<br />
zu festigen, sollten aber in Zukunft weitere Studien über den Einsatz <strong>von</strong> <strong>Neuronalen</strong><br />
<strong>Netzen</strong> in der Primärforschung folgen. Denn die Ursache für die geringere<br />
Ergebnissicherheit der KNN in den Fallbeispielen dieser Arbeit könnte unter<br />
anderem damit begründet werden, dass in den Datenstrukturen nur wenige<br />
nichtlineare Anteile nachweisbar waren. Zukünftige Arbeiten sollten diese<br />
Problematik berücksichtigen <strong>und</strong> darüber hinaus variierende Stichprobengrößen <strong>und</strong><br />
wechselnde Anzahlen an Variablen in die Analysen einbeziehen, um so die mögliche<br />
Leistungsfähigkeit der KNN in der Primärforschung umfangreicher <strong>und</strong> besser<br />
aufzudecken.<br />
Durch das Kriterium „Generalisierbarkeit“ wird die Allgemeingültigkeit der<br />
Ergebnisse überprüft. Bei der Anwendung der erzeugten Modelle in der ersten<br />
Fallstudie auf die Out-of-Sample Menge zeigte sich, dass die MLP eine bessere<br />
109 Die nichtlinearen Datenstrukturen spielen insbesondere im <strong>Vergleich</strong> zwischen den MLP <strong>und</strong><br />
der multiplen linearen Regressionsanalyse eine wichtige Rolle (vgl. Kapitel 4.4).<br />
110
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
Generalisierbarkeit aufwiesen als die geschätzte Regressionsfunktion. Diese Leistung<br />
der MLP kann möglicherweise durch deren Lernfähigkeit begründet werden (vgl.<br />
Abschnitt 3.3), während die schlechte Leistung der Regressionsanalyse<br />
wahrscheinlich auf Verletzungen der Modellprämissen zurückzuführen ist.<br />
Letztendlich war jedoch die Güte der Prognosen beider Verfahren ähnlich (vgl.<br />
Kapitel 4.4.4). Zur Überprüfung der relativen Validität bzw.<br />
Generalisierungsleistung der Clusterlösung wurden die Übereinstimmungsquoten<br />
herangezogen, die auf Gr<strong>und</strong>lage der Diskriminanzanalyse sowie der replizierten<br />
Clusteranalysen ermittelt wurden (vgl. Abschnitt 3.1.3). Anhand der<br />
Diskriminanzfunktion zeigte die multivariate Clusteranalyse eine höhere<br />
Übereinstimmungsquote auf als die SOM. Die replizierten Analysen der Verfahren<br />
offenbarten jedoch, dass kaum inhaltliche Übereinstimmungen zwischen den<br />
Ergebnissen vorlagen (vgl. Kapitel 4.5.4. Demnach ist der Einsatz der<br />
Diskriminanzanalyse zur alleinigen Überprüfung der Generalisierbarkeit der<br />
Gruppenlösungen kritisch zu sehen. Somit weisen die multivariate Clusteranalyse<br />
<strong>und</strong> die SOM insgesamt eine schlechte Generalisierungsleistung auf.<br />
Die Bewertung des Kriteriums „Modellprämissen“ erfolgte an Hand der Relevanz<br />
der Annahmebeschränkungen eines Verfahrens für die Modellbildung. Da die KNN<br />
im <strong>Vergleich</strong> zu den <strong>multivariaten</strong> Verfahren keine bzw. weniger Annahmen<br />
bezüglich der zu verarbeitenden Daten erfordern, gelten sie als vorteilhafter. So muss<br />
für ein neuronales Netz lediglich die Netzwerktopologie festgelegt werden, während<br />
z. B bei der Spezifikation des Regressionsmodells Annahmen im Hinblick auf die<br />
Funktion, die Störgröße <strong>und</strong> die Variablen einzuhalten sind (vgl. Abschnitt 3.1.2).<br />
Die Fallstudie 1 zeigte aber auch, dass selbst bei Prämissenverletzungen der<br />
Regressionsfunktion gute Ergebnisse erzeugt werden können (vgl. Kapitel 4.4.2).<br />
Anwenderorientierte Kriterien<br />
Neben den bisher aufgezeigten direkten Kriterien werden im Folgenden die<br />
indirekten oder auch anwenderorientierten Kriterien pro Verfahren bewertet, die<br />
besonders im betriebswirtschaftlichen Informationsmanagement eine wichtige Rolle<br />
spielen (vgl. Abschnitt 4.2). Die Beurteilung der „Interessantheit“ der<br />
Verfahrensergebnisse bezieht sich vor allem auf die struktur-entdeckenden<br />
111
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
Verfahren. Denn bei den struktur-beschreibenden Verfahren ist vor der Berechnung<br />
ein Modell aufzubauen, so dass keine neuen interessanten Informationen gewonnen,<br />
sondern nur vorhandene in ihrer Wechselwirkung bestätigt werden können (vgl.<br />
Kapitel 2.2). Die Pruning-Methode der MLP kann, obwohl dieser Netzwerktyp den<br />
struktur-beschreibenden Verfahren zugeordnet ist, zur Entdeckung neuer reduzierter<br />
nichtlinearer Datenmuster eingesetzt werden (vgl. Abschnitt 4.4.3). Im Rahmen der<br />
ersten Fallstudie konnte jedoch kein stabiles Netzwerk aufgebaut <strong>und</strong> somit auch<br />
keine neuen Datenmuster identifiziert werden. Bei den struktur-entdeckenden<br />
Verfahren zeigten die Gruppenlösungen der SOM <strong>und</strong> der <strong>multivariaten</strong><br />
Clusteranalyse vom methodischen Ansatz her keine wesentlichen Unterschiede in<br />
Bezug auf die Entdeckung <strong>von</strong> interessanten Mustern in den Daten. Folglich können<br />
die KNN auch nicht durch ihre Lernfähigkeit die Unwissenheit (Intransparenz) über<br />
die Strukturen in den Datenbeständen besser aufdecken (vgl. Kapitel 3.3). Insgesamt<br />
erwies sich die Bewertung der „Interessantheit“ als sehr schwierig <strong>und</strong> sollte daher<br />
dem jeweiligen Anwender überlassen werden.<br />
Das Kriterium „Verständlichkeit“ bezieht sich vor allem auf die methodische<br />
Transparenz der Verfahren. Während die Regressions- <strong>und</strong> Clusteranalyse<br />
mathematisch <strong>und</strong> sachlogisch einfach nachzuvollziehen sind, ist es schwierig die<br />
internen Gewichtungen <strong>und</strong> Verknüpfungen der Netzwerkstrukturen der <strong>Neuronalen</strong><br />
Netze zu durchschauen. Andere Programme für Datenanalysen mit KNN, z. B. der<br />
SNNS (Stuttgarter Neuronale Netze Simulator), bieten hier zwar mehr Transparenz<br />
als SPSS Clementine, haben dafür aber auch höhere methodische Anforderungen an<br />
den Anwender. 110 In Zukunft sollten weitergehende Studien über den Einsatz <strong>von</strong><br />
KNN in der Primärforschung eine Befragung über die Transparenz der Verfahren bei<br />
wissenschaftlichen <strong>und</strong> praktischen Anwendern einschließen. Dadurch wäre eine<br />
bessere Bewertung des Kriteriums „Verständlichkeit“ geben <strong>und</strong> darauf aufbauend,<br />
könnten anwenderorientierte Softwareanpassungen für KNN vorgenommen werden.<br />
Die „Interpretierbarkeit“ der Ergebnisse ist bei den MLP nicht so einfach möglich<br />
wie bei der Regressionsanalyse (vgl. Kapitel 4.4.4). Während bei der multiplen<br />
110<br />
Die SNNS sind ein leistungsfähiger universeller Simulator neuronaler Netze für Unix<br />
Workstations <strong>und</strong> Unix-PCs <strong>und</strong> wurden <strong>von</strong> einem Team an der Universität Stuttgart entwickelt.<br />
112
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
linearen Regression die Richtung (positiv, negativ) <strong>und</strong> die Stärke des Einflusses auf<br />
die abhängige Variable durch die Regressionskoeffizienten der unabhängigen<br />
Variablen genau dargelegt werden, bietet die Sensitivitätsanalyse der MLP nur eine<br />
sehr einfache Gr<strong>und</strong>lage (relative Wichtigkeit der Eingabevariable auf die<br />
Ausgabevariable) zur Interpretation der Inputneuronen. Die Interpretation der<br />
Ergebnisse der <strong>multivariaten</strong> Clusteranalyse <strong>und</strong> der SOM vollzieht sich<br />
gleichermaßen (vgl. Abschnitt 4.5.4). Ein inhaltlicher <strong>Vergleich</strong> der<br />
Verfahrenslösungen untereinander ist jedoch nur schwierig durchzuführen, da die<br />
Methoden keine analogen Ergebnisse hervorbringen. Da die KNN eine geringere<br />
methodische Transparenz aufweisen <strong>und</strong> deren Analyseergebnisse im <strong>Vergleich</strong> zu<br />
den <strong>multivariaten</strong> Verfahren nur beschränkt zu interpretieren sind, kann die in der<br />
Literatur häufig erwähnte Black-Box-Problematik der neuronalen Netze bestätigt<br />
werden (vgl. Kapitel 3.3 <strong>und</strong> 4.1). Inwieweit diese Problematik letztendlich zu einer<br />
geringeren Akzeptanz der Ergebnisse der KNN in der praktischen Anwendung führt,<br />
sollte in weitergehenden Studien erforscht werden.<br />
Eine weitere wichtige Voraussetzung für den Einsatz <strong>von</strong> <strong>multivariaten</strong> Verfahren<br />
<strong>und</strong> KNN in der betrieblichen Primärforschung ist, dass deren „Bedienbarkeit“ bzw.<br />
Anwendung möglichst einfach ist. Die Regressionsanalyse weist in diesem<br />
Zusammenhang <strong>von</strong> der Dateneingabe bis zur Ergebnisausgabe im <strong>Vergleich</strong> zu den<br />
anderen Verfahren eine relativ anwenderfre<strong>und</strong>liche Bedienung auf (vgl. Abschnitt<br />
4.4.2). Bei den KNN müssen hingegen sehr viele Einstellungen im Hinblick auf die<br />
Netzwerktopologien, Lernraten <strong>und</strong> Laufzyklen usw. vorgenommen werden, um ein<br />
brauchbares Ergebnis zu erhalten. Durch diese Vielfalt an Einstellungsmöglichkeiten<br />
kann der praktisch orientierte Anwender der Versuchung unterliegen, <strong>von</strong> einem<br />
systematischen Vorgehen zu einem Trial-and-Error Prozess bei der Bedienung zu<br />
wechseln. Dieses würde aber die Verständlichkeit <strong>und</strong> Transparenz der Ergebnisse<br />
verringern. Um dem vorzubeugen, sollten in Zukunft differenzierte Einstellungen für<br />
Experten <strong>und</strong> Anfänger sowie Standardfunktionen für spezifische Problemsituationen<br />
in die statistischen Softwares für KNN implementiert werden. In Bezug auf die<br />
Komplexität des Verfahrensablaufes zeigt insbesondere die multivariate<br />
Clusteranalyse Schwächen (vgl. Kapitel 4.5.2). Denn um verwertbare<br />
Gruppenergebnisse zu erhalten, müssen neben den nacheinander folgenden<br />
113
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
Berechnungen verschiedener Clusteralgorithmen (Single-Linkage, Ward, K-Means)<br />
auch zusätzliche Analysen für die Güte der Clusterlösungen durchgeführt werden.<br />
Dieser methodisch anspruchsvolle Verfahrensablauf sollte in Zukunft bei der<br />
Neuentwicklung <strong>von</strong> statischen Programmen für die praktische Datenanalyse besser<br />
automatisiert werden. 111 Letztendlich muss jedoch beachtet werden, dass die<br />
Bewertung der Bedienbarkeit eines Verfahrens <strong>von</strong> den subjektiven<br />
Methodenkenntnissen <strong>und</strong> den Erfahrungen des Anwenders abhängt.<br />
Im Zusammenhang mit der Forderung nach einer weitgehenden „Flexibilität“ der<br />
Verfahren haben die KNN zwar einerseits den Vorteil, dass diese auch bei<br />
unterschiedlichen Skalenniveaus der Variablen eingesetzt werden können, anderseits<br />
wird jedoch viel Zeit für den Netzwerkaufbau <strong>und</strong> das Training (inklusive der<br />
Anpassung der Lernrate) benötigt (vgl. Abschnitt 3.2). Dadurch können die<br />
<strong>Neuronalen</strong> Netze insgesamt nicht flexibel auf unterschiedliche Problemsituationen<br />
hin angewendet werden. Bei den <strong>multivariaten</strong> Verfahren kann demgegenüber die<br />
Regressionsanalyse nach einem erfolgten Modellaufbau sehr schnell durchgeführt<br />
werden. Die Clusteranalyse benötigt wiederum durch ihre methodisch<br />
anspruchsvollen Ablaufschritte einen wesentlich höheren Rechenzeitanspruch (vgl.<br />
Kapitel 4.5.2).<br />
In Bezug auf die „Verfügbarkeit“ der Verfahren zeigen WILDE et al. (2002: 157),<br />
dass fast alle Softwareanbieter (z. B. SPSS GmbH, SAS Institut, StatSoft GmbH<br />
usw.) auch die in dieser Arbeit verwendeten <strong>multivariaten</strong> Verfahren in ihre<br />
Statistikprogramme implementiert haben. Die KNN sind stattdessen bei den meisten<br />
Softwareanbietern nur als Einzelprodukt oder eigenständiges Tool zu erwerben. Die<br />
frei zur Verfügung stehenden Statistikprogramme (z. B. R, SNNS) bieten zwar auch<br />
die Möglichkeit mit KNN zu arbeiten, jedoch erweist sich die Benutzeroberfläche für<br />
die praktische Primärforschung als nicht anwenderfre<strong>und</strong>lich genug <strong>und</strong> wird deshalb<br />
vornehmlich im wissenschaftlichen Bereich eingesetzt. Für die praktische<br />
Marktforschung bedeutet deshalb der Einsatz <strong>von</strong> <strong>Neuronalen</strong> <strong>Netzen</strong> zur<br />
Datenanalyse auch zusätzliche Kosten.<br />
111 Untersuchungen bezüglich der Robustheit gegenüber Fehleinstellungen oder Fehlbedienungen<br />
der Verfahren wurden nicht durchgeführt.<br />
114
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
Tabelle 19 stellt noch einmal zusammenfassend die Ergebnisse der oben<br />
aufgeführten Bewertungskriterien für jedes Verfahren dar. Es soll jedoch abermals<br />
darauf hingewiesen werden, dass die in diesem Kapitel aufgeführten Bewertungen,<br />
insbesondere bei den indirekten Kriterien, schwierig objektiv zu ermitteln sind <strong>und</strong><br />
sich zum Teil aus dem jeweiligen Einsatzgebiet des Verfahrens sowie der<br />
subjektiven Einschätzung des Anwenders ableiten lassen. Ziel zukünftiger Studien<br />
sollte es daher sein, diese Kriterien detaillierter anhand <strong>von</strong> unterschiedlichen<br />
Fallstudien in der Primärforschung zu analysieren.<br />
Tabelle 19: Bewertung <strong>von</strong> <strong>multivariaten</strong> Verfahren <strong>und</strong> KNN<br />
Strukturabbildung Strukturentdeckung<br />
Kriterium<br />
Regressions-<br />
Clusteranalyse<br />
MLP<br />
analyse<br />
SOM<br />
datenorientierte<br />
Kriterien<br />
Datendeformation - ++ - ++<br />
Datenqualität - ++ + +<br />
Datenmengen + - - -<br />
methodenorientierte<br />
Kriterien<br />
Ergebnissicherheit ++ ++ ++ +<br />
Generalisierung + ++ - -<br />
Modellprämissen - ++ - ++<br />
anwenderorientierte<br />
Kriterien<br />
Interessantheit - - + +<br />
Verständlichkeit ++ - + -<br />
Interpretierbarkeit ++ + + +<br />
Bedienbarkeit + - - -<br />
Flexibilität + - - -<br />
Verfügbarkeit ++ - ++ -<br />
Mit „++“, „+“, oder „-“ wird ein Kriterium „sehr gut erfüllt“, gut erfüllt“ oder „nicht erfüllt“.<br />
Quelle: Eigene Darstellung<br />
115
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
Die aufgezeigten Kriterien können auch als Anforderungen der Marktforscher/innen<br />
an die Analysemethoden angesehen werden. Das heißt, nur wenn ein Verfahren<br />
sowohl die Anforderungen an die Daten, die Methodik <strong>und</strong> die Anwendbarkeit<br />
ausreichend erfüllt, eignet es sich für den Einsatz in der Primärforschung.<br />
Abbildung 40: Einordnung der Analyseverfahren nach anwender-, daten- <strong>und</strong><br />
methodenorientierten Anforderungen<br />
Quelle: Eigene Darstellung<br />
Aus der Abbildung 40 wird ersichtlich, dass die KNN im <strong>Vergleich</strong> zu den<br />
<strong>multivariaten</strong> Verfahren zwar kaum Anforderungen an die Daten <strong>und</strong> die Methodik<br />
stellen, stattdessen aber weniger anwenderfre<strong>und</strong>lich sind. Daraus folgt, dass diese<br />
sich auch nur bedingt für das betriebswirtschaftliche Informationsmanagement<br />
eignen. Denn ein erfolgreicher, praktischer Einsatz eines Analyseverfahrens ist nur<br />
dann gewährleistet, wenn dieses möglichst schnell aufschlussreiche <strong>und</strong> leicht<br />
verständliche Ergebnisse für die Entscheidungsträger des Unternehmens liefern kann.<br />
Andernfalls könnte die Unternehmensleitung nicht flexibel <strong>und</strong> spezifisch auf neue<br />
Marktsituationen reagieren (vgl. Kapitel 2.1). Die <strong>multivariaten</strong> Verfahren werden<br />
demnach diesen Ansprüchen besser gerecht. Der Einsatz der <strong>Neuronalen</strong> Netze in der<br />
Primärforschung fällt somit eher der Wissenschaft <strong>und</strong> den Marktforschungsunternehmen<br />
zu, die weniger anwenderorientierte Anforderungen stellen. HIPPNER et<br />
al. (2002) zeigten diesbezüglich in einer Studie über die Anwendungspraxis <strong>von</strong> Data<br />
Mining Methoden in 44 deutschen Unternehmen, dass die <strong>multivariaten</strong> Verfahren<br />
116
5 Zusammenfassung der Ergebnisse <strong>und</strong> Verfahrensvergleich<br />
aufgr<strong>und</strong> ihrer einfachen Nachvollziehbarkeit <strong>und</strong> guten Verständlichkeit häufiger<br />
für Datenanalysen eingesetzt werden als die künstlichen <strong>Neuronalen</strong> Netze (vgl.<br />
Abbildung 52 <strong>und</strong> Abbildung 53). Weitergehende Studien sollten daher unter<br />
anderem überprüfen, inwieweit diese Anwendungspraxis im Data Mining auf die<br />
Primärforschung übertragbar ist.<br />
117
6 Schlussbemerkungen<br />
6 Schlussbemerkungen<br />
Neuronale Netze wurden bislang überwiegend <strong>und</strong> mit sehr guten Ergebnissen im<br />
Rahmen des Data Mining eingesetzt. Der erfolgreiche Einsatz der KNN begründet<br />
sich dabei durch deren Eigenschaften, z. B. nichtlineare Datenstrukturen<br />
aufzudecken <strong>und</strong> eine hohe Anzahl <strong>von</strong> Variablen mit in die Analysen einbeziehen<br />
zu können. Das Ziel dieser Arbeit bestand deshalb darin, anhand <strong>von</strong> Gütekriterien<br />
zu untersuchen, ob durch den Einsatz <strong>von</strong> künstlichen <strong>Neuronalen</strong> <strong>Netzen</strong> in der<br />
Primärforschung eine Verbesserung der Informationsgewinnung im <strong>Vergleich</strong> zu den<br />
bisher verwendeten <strong>multivariaten</strong> Verfahren möglich ist. Zur Beantwortung dieser<br />
zugr<strong>und</strong>e liegenden Zielsetzung wurde, neben einer umfassenden Bestandsaufnahme<br />
der bestehenden Erkenntnisbeiträge aus der Literatur, eine eigene empirische<br />
Untersuchung durchgeführt.<br />
Die Ergebnisse der Fallstudien dieser Arbeit zeigen, dass der Einsatz <strong>von</strong> KNN zur<br />
Datenanalyse in der Primärforschung prinzipiell möglich ist. Folglich stellen die<br />
<strong>Neuronalen</strong> Netze ein alternatives Verfahren zu den konventionellen <strong>multivariaten</strong><br />
Verfahren innerhalb der Primärforschung dar <strong>und</strong> ergänzen somit den bisherigen<br />
Methodenvorrat.<br />
Darüber hinaus konnten jedoch bei den tiefergehenden Analysen in den empirischen<br />
Untersuchungen, im Gegensatz zu den in der Literatur befindlichen Resultaten, keine<br />
besseren Güteergebnisse <strong>und</strong> Informationsgewinne durch die KNN im <strong>Vergleich</strong> zu<br />
den <strong>multivariaten</strong> Verfahren erzeugt werden. Zurückzuführen ist dieses Resultat<br />
wahrscheinlich auf die linearen Zusammenhänge zwischen den Variablen innerhalb<br />
der Daten der Fallbeispiele. Zukünftige Studien über den Einsatz <strong>von</strong> <strong>Neuronalen</strong><br />
<strong>Netzen</strong> in der Primärforschung sollten daher untersuchen, ob bei Vorliegen <strong>von</strong><br />
komplexeren, nichtlinearen Zusammenhängen in den Datenstrukturen die KNN den<br />
<strong>multivariaten</strong> Verfahren überlegen sind.<br />
Der abschließende Verfahrensvergleich durch die daten-, methoden- <strong>und</strong><br />
anwenderorientierten Bewertungskriterien in dieser Arbeit macht deutlich, dass die<br />
<strong>Neuronalen</strong> Netze vor allem in Bezug auf deren Anwendbarkeit (Verständlichkeit,<br />
118
6 Schlussbemerkungen<br />
Interpretierbarkeit, Bedienbarkeit, Verfügbarkeit usw.) Schwächen zeigen, während<br />
die <strong>multivariaten</strong> Verfahren hier ihre Stärke haben. Der Vorwurf aus der Literatur,<br />
KNN wiesen einen Black-Box Charakter auf <strong>und</strong> durchliefen in der<br />
Netzwerkkonstruktion einen Trial-and-Error Prozess, kann daher nicht entkräftet<br />
werden. Aus dieser Anwendungsproblematik heraus resultiert die<br />
Handlungsempfehlung, den Einsatz der <strong>Neuronalen</strong> Netze zur Datenanalyse<br />
gegenwärtig auf die wissenschaftliche Forschung zu beschränken <strong>und</strong> in der<br />
Unternehmenspraxis vornehmlich die <strong>multivariaten</strong> Verfahren einzusetzen. Daran<br />
anknüpfend besteht aber durchaus weiterhin das Ziel für die Wissenschaft <strong>und</strong><br />
speziell für die angewandte Informatik, die <strong>Neuronalen</strong> Netze bezüglich eines<br />
zukünftigen praktischen Einsatzes in der Primärforschung weiterzuentwickeln. Der<br />
Schwerpunkt sollte dabei vor allem auf der Entwicklung einer anwenderorientierten<br />
Benutzeroberfläche liegen, die die Identifikation <strong>und</strong> Schätzung des <strong>Neuronalen</strong><br />
Netzwerkmodells vereinfacht bzw. standardisiert. Denn letztendlich bieten die KNN,<br />
insbesondere im Hinblick auf das Ziel der Primärforschung, im Rahmen der<br />
Datenanalyse schnell aufschlussreiche <strong>und</strong> leicht verständliche Ergebnisse zu liefern,<br />
ein enormes Verbesserungs- <strong>und</strong> Weiterentwicklungspotential, während viele<br />
konventionelle Verfahren der <strong>multivariaten</strong> Statistik schon ausgereift sind <strong>und</strong> kaum<br />
noch Verbesserungsmöglichkeiten aufweisen.<br />
119
Literaturverzeichnis<br />
Literaturverzeichnis:<br />
ALEX, B. (1998): Künstliche Neuronale Netze in Management-<br />
Informationssystemen – Gr<strong>und</strong>lagen <strong>und</strong> Einsatzmöglichkeiten, Wiesbaden.<br />
ALON, I.; QI, M.; SADOWSKI, R.J. (2001): Forecasting aggregate retail sales: a<br />
comparison of artificial neural networks and traditional methods, In: Journal<br />
of Retailing and Consumer Services, Heft 8 (2001), S. 147-156. URL: http://<br />
web.rollins.edu/~ialon/publications/Retail%20Forecasting.pdf,<br />
Abrufdatum: 13.01.2005<br />
ANDERS, U. (1996): Was neuronale Netze wirklich leisten, In: Die Bank, Heft 3<br />
(1996), S. 162–165.<br />
ANDERS, U. (1997): Statistische Neuronale Netze, München.<br />
ANDERSON, D.; MCNEIL, G. (1992): Artificial Neural Networks Technology, New<br />
York. URL: http://www.dacs.dtic.mil/techs/neural/, Abrufdatum: 13.01.2005<br />
ANGUS, J. (2004): Test Center – Clementine 8.1 – Melds Business Analytics With<br />
Business Intelligence, In: Infoworld, Heft 29 (2004), S. 28-29.<br />
ARNDT, D.; GESTEN, W.; WIRTH, R. (2001): K<strong>und</strong>enprofile zur Prognose der<br />
Markenaffinität im Automobilsektor. In: Hippner, H.; Küsters, U.; Meyer,<br />
M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data Mining im Marketing,<br />
Wiesbaden, S. 591-606.<br />
BACHER, J. (1996): Clusteranalyse, 2. Auflage, München.<br />
BACKHAUS, K.; ERICHSON, B.; PLINKE, W.; WEIBER, R. (2003): Multivariate<br />
Analyseverfahren: Eine anwenderorientierte Einführung, 10. Auflage, Berlin.<br />
BARTHELEMY, S., FILIPPI, J.-B (2003): A typology of very small companies using<br />
self organizing maps, Proceedings of the IEEE International Conference on<br />
Systems, Man & Cybernetics Conference, Washington, 2003, Heft 1, S.<br />
3518-3523. URL: http://spe.univ-corse.fr/filippiweb/publis/docs/som2.pdf,<br />
Abrufdatum: 22.02.05<br />
BERGS, S. (1980): Optimalität bei Clusteranalysen – Experimente zur Bewertung<br />
numerischer Klassifikationsverfahren, Münster.<br />
BERRY, M. J. A.; LINOFF, G. (1997): Data Mining Techniques – For marketing Sales<br />
and Costumer Support, New York.<br />
BERRY, M. J. A.; LINOFF, G. (2004): Data Mining Techniques: for Marketing,<br />
Sales and Customer Relationship Management, 2. Auflage, Indianapolis.<br />
120
Literaturverzeichnis<br />
BLEYMÜLLER, J.; GEHLERT, G.; GÜLICHER, H. (2002): Statistik für<br />
Wirtschaftswissenschaftler, 13. Auflage, München.<br />
BODENSTEIN, G.; SPILLER A. (1998): Marketing- Strategien, Instrumente <strong>und</strong><br />
Organisation, Landsberg/Lech.<br />
BONNE, T.; ARMINGER G. (2001): Diskriminanzanalyse, In: Hippner, H.; Küsters,<br />
U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data Mining im<br />
Marketing, Wiesbaden, S. 193-241.<br />
BOONE, D.S.; ROEHM, M. (2002): Evaluating the Appropriateness of Market<br />
Segmentation Solutions Using Artificial Neural Networks and the<br />
Membership Clustering Criterion, In: Marketing Letters, Heft 13 (2002), S.<br />
317-333. URL: http://springerlink.metapress.com/media/9H0B3Q31XH6YW<br />
J4DKGU/Contributions/X/V/4/2/XV427KJ70N8P7V65.pdf, Abrufdatum:<br />
20.02.2005<br />
BORTZ, J. (1999): Statistik Sozialwissenschaftler, 5. Auflage, Berlin.<br />
BORTZ, J. (2005): Statistik - für Human- <strong>und</strong> Sozialwissenschaftler, Berlin.<br />
BREKEOVEN, L.; ECKERT, W.; ELLENRIEDER, P. (1999): Marktforschung –<br />
Methodische Gr<strong>und</strong>lagen <strong>und</strong> praktische Anwendung, 8. Auflage, Wiesbaden.<br />
BREUNIG, M.-M. (2001): Quality Driven Database Mining, Aahen.<br />
BROSIUS, G.; BROSIUS F. (1996): SPSS – Base System <strong>und</strong> Professional Statistics,<br />
Heidelberg.<br />
BROSIUS, F. (2004): SPPS 12, Bonn.<br />
BRUHN, M. (1999): Marketing – Gr<strong>und</strong>lagen für Studium <strong>und</strong> Praxis, 4. Auflage,<br />
Wiesbaden.<br />
CHAN, M.-C.; WONG C.-C.; LAM, C.-C. (2000): Financial Time Series Forecasting<br />
by Neural Network Using Conjugate Gradient Learning Algorithm and<br />
Multiple Linear Regression Weight Initialization, In: Computing in<br />
Economics and Finance 2000 from Society for Computational Economics,<br />
Heft 61 (2000). URL: http://fmwww.bc.edu/cef00/papers/paper61.pdf,<br />
Abrufdatum: 20.02.2005<br />
COOPER, J.C.B. (1998): Artificial neural networks versus multivariate statistics: an<br />
application from economics, In: Working Paper Heft 15, Glasgow Caledonian<br />
University.<br />
COOPER, J.C.B. (1999): Artificial neural networks versus multivariate statistics: an<br />
application from economics, In: Journal of Applied Statistics, Heft 26, 8<br />
(1999) S. 909-921.<br />
121
Literaturverzeichnis<br />
CREEDY, J.; MARTIN, V. L. (1997): Nonlinear Economic – Cross-sectional, Time<br />
Series and Neural Network Applications, Cheltenham.<br />
DEBOECK, G. (1998a): Chapter 13 – Software Tools for Self- Organizing Maps, In:<br />
Deboeck, G. J.; Kohonen T. K. (1998) (Hrsg.): Visual Exploration in Finance<br />
with Self- Organizing Maps, London.<br />
DEBOECK, G. (1998b): Chapter 15 – Best practices in data mining using selforganizing<br />
maps, In: Deboeck, G. J.; Kohonen T. K. (1998) (Hrsg.): Visual<br />
Exploration in Finance with Self- Organizing Maps, London.<br />
DOLNICAR, S. (1997): The use of neural networks in marketing: market<br />
segmentation with self organising feature maps. Proceedings of the Workshop<br />
on Self-Organizing Maps (WSOM'97), Helsinki University of Technology,<br />
Espoo/Finland, June 4-6. URL: http://nucleus.hut.fi/wsom97/progabstracts<br />
/34.html, Abrufdatum: 18.02.2005<br />
ERXLEBEN, K.; BAETGE, J.; FEIDICKER, M.; KOCH, H.; KRAUSE, C.; MERTENS, P.<br />
(1992): Klassifikation <strong>von</strong> Unternehmen. Ein <strong>Vergleich</strong> <strong>von</strong> <strong>Neuronalen</strong><br />
<strong>Netzen</strong> <strong>und</strong> Diskriminanzanalyse, In: Zeitschrift für Betriebswirtschaft, Bd.<br />
62 (1992), S. 1237-1262.<br />
EINWOHNERSTATISTIK GEMEINDE GLEICHEN (2004): Homepage der Gemeinde<br />
Gleichen – Landkreis Göttingen – Einwohnerstatistik. URL: http://www.<br />
gleichen.de/gemeinde/Seiten/Einwohner.htm, Abrufdatum: 09.03.05<br />
FAHRMEIR, L.; KÜNSTLER, R.; PIGEOT, I.; TUTZ, G. (2003): Statistik – Der Weg<br />
zur Datenanalyse, Berlin/Heidelberg.<br />
FRANSES, P.-H.; PAAP, R. (2001): Quantitative models in marketing research,<br />
Cambridge.<br />
FREEMAN, J.A.; SKAPURA, D. M. (1991): Neural Networks Algorithms,<br />
Applications, and Programming Techniques, New York.<br />
GENTSCH, P. (2002): Personalisierung der K<strong>und</strong>enbeziehung im Internet – Methoden<br />
<strong>und</strong> Technologien, In: Hippner, H.; Merzenich, M.; Wilde, K. D. (Hrsg.)<br />
(2002): Handbuch Web Mining im Marketing: Konzepte, Systeme,<br />
Fallstudien, Braunschweig, S. 266-307.<br />
GIERL, H.; SCHWANENBERG, S. (2001): Clusteranalyse mittels SOFM. In:<br />
Marketing ZFP, Heft 2 (2001).<br />
GRABMEIER, J. (2001): Segmentierende <strong>und</strong> clusterbildende Methoden, In: Hippner,<br />
H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data<br />
Mining im Marketing, Wiesbaden, S. 299-362.<br />
122
Literaturverzeichnis<br />
GYAN, B.; VOGES, K. E.; POPE, N. K. L. (2004): Artificial Neural Networks in<br />
Marketing from 1999 to 2003: A Region of Origin and Topic Area Analysis,<br />
Proceedings of the ANZMAC 2005 Conference, Wellington (New Zealand),<br />
2004. URL: http://130.195.95.71:8081/WWW/ANZMAC2004/CDsite/papers<br />
/Gyan1.PDF, Abrufdatum: 20.02.2005<br />
HEIMEL, J. P. (1994): Konnektionistische Analyse des Kaufverhaltens: künstliche<br />
neuronale Netze im <strong>Vergleich</strong> zu stochastischen <strong>und</strong> ökonometrischen<br />
Modellen am Beispiel des deutschen Universalwaschmittelmarktes,<br />
Berlin.<br />
HERRMANN, A.; HOMBURG, C. (Hrsg.)(1999): Marktforschung- Methoden,<br />
Anwendungen, Praxisbeispiele, Wiesbaden.<br />
HIPPNER, H. (1998): Neuronale Netze zur langfristigen Prognose <strong>von</strong> PKW-<br />
Neuzulassungen, In: Hippner, H.; Meyer, M.; Wilde, K. D.(Hrsg.) (1999):<br />
Computer Based Marketing - Das Handbuch zur Marketinginformatik,<br />
Braunschweig/Wiesbaden, S. 453-461.<br />
HIPPNER, H.; RUPP, A. (2001a): Kreditwürdigkeitsprüfung im Versandhandel, In:<br />
Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch<br />
Data Mining im Marketing, Wiesbaden, S. 685- 706.<br />
HIPPNER, H.; MERZENICH, M.; WILDE, K.D. (2001b): Der Prozess des Data Mining<br />
im Marketing, In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.)<br />
(2001): Handbuch Data Mining im Marketing, Wiesbaden, S. 21-91.<br />
HIPPNER, H.; SCHMITZ, B. (2001c): Data Mining in Kreditinstituten – Die<br />
Clusteranalyse zur zielgruppengerechten K<strong>und</strong>enansprache, In: Hippner, H.;<br />
Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data Mining<br />
im Marketing, Wiesbaden, S. 607-622.<br />
HIPPNER, H.; MERZENICH, M.; STOLZ, C. (2002): Data Mining im Marketing -<br />
Anwendungspraxis in deutschen Unternehmen, In: Wilde, K. D.; Hippner, H.;<br />
Merzenich, M. (Hrsg.) (2002a): Aufsatzsammlung - Data Mining : mehr<br />
Gewinn aus Ihren K<strong>und</strong>endaten, Düsseldorf, S. 127- 143.<br />
HOFFMANN, M. (2004): Künstliche Neuronale Netze im empirischen <strong>Vergleich</strong> zu<br />
regressionsanalytischen Verfahren in der Werbewirkungsforschung, Aachen.<br />
HRUSCHKA, H.; NATTER, M. (1995): Clusterorientierte Marktsegmentierung mit<br />
Hilfe Künstlicher Neuronaler Netzwerke, in: Marketing-ZFP, Bd. 17<br />
(1995), S. 249–254.<br />
HRUSCHKA, H.; NATTER, M. (1999): Comparing Performance of Feedforward<br />
Neural Nets and K-Means for Cluster-Based Market Segmentation, Working<br />
Paper No. 2, Adaptive Information Systems and Modelling. In: Economics<br />
and Management Science, Vienna University of Economics and Business<br />
Administration, Vienna.<br />
123
Literaturverzeichnis<br />
HRUSCHKA, H.; PROBST, M. (2001a): Interpretation Aids for Multilayer Perceptron<br />
Neural Nets. Discussion Paper 364, Faculty of Economics, University of<br />
Regensburg 2001.<br />
HRUSCHKA, H., FETTES, W., PROBST (2001b): Analyzing Purchase Data by a<br />
Neural Net Extension of the Multinomial Logit Model, Proceedings of the<br />
International Conference Vienna, Artificial Neural Networks - ICANN 2001<br />
Austria, August 21-25, 2001, S. 790-795. URL: http://www.springerlink.com/<br />
media/253X5250DK5YNHEA6W7M/Contributions/M/6/K/N/M6KNVJLN5<br />
D6R6W0T.pdf, Abrufdatum: 22.02.05<br />
HRUSCHKA, H.; FETTES, W.; PROBST, M. (2004): An Empirical Comparison of the<br />
Validity of a Neural Net Based Multinomial Logit Choice Model to<br />
Alternative Model Specifications, in: European Journal of Operational<br />
Research Bd. 159, 2004, S. 166-180.<br />
HÜTTNER, M. (1999): Gr<strong>und</strong>züge der Marktforschung, 6. Auflage, München.<br />
JANSSEN, J.; LAATZ, W. (2003): Statistische Datenanalyse mit SPSS für Windows,<br />
4. Auflage, Heidelberg.<br />
KAMINSKI, C.; LIENIG, B.; MEISEGEIER, S. (2004): Präsentation - Die<br />
wirtschaftliche Situation der Krise <strong>und</strong> kreisfreien Städte in Deutschland –<br />
Eine Clusteranalyse im Rahmen der Lehrveranstaltung Multivariate Statistik,<br />
Sommersemester 2004, Berlin. URL: http://karlshorst.weltregierung.de/<br />
Freigegebene%20Dokumente/Multivariate%20Statistik%20-%20Strategy%<br />
20Dwight%20Lightning.ppt#1, Abrufdatum: 13.01.2005<br />
KIANG, Y.; KUMAR, A. (2001): An Evaluation of Self-Organizing Map Networks as<br />
a Robust Alternative to Factor Analysis in Data Mining Applications, In:<br />
Information Systems Research, Vol. 12, No. 2 (2001), S. 177-194.<br />
KIANG, M. Y.; HU, M. Y.; FISHER, D. M.; CHI, R. T. (2005a): The Effect of Sample<br />
Size on the Extended Self-Organizing Map Network for Market<br />
Segmentation, Proceedings of the 38th Hawaii International Conference on<br />
System Sciences 2005. URL: http://csdl.computer.org/comp/proceedings/<br />
hicss/2005/2268/03/22680073b.pdf, Abrufdatum: 18.02.2005<br />
KIANG, M. Y.; HU, M. Y.; FISHER, D. M. (2005b): An Extended Self-Organizing<br />
Map Network for Market Segmentation – A Telecommunication Example, In:<br />
Decision Support Systems, forthcoming.<br />
KOHONEN, T. (1995): Self- Organizing Maps, Berlin/Heidelberg/New York.<br />
KOHONEN, T. (2001): Self-Organizing Maps, New York.<br />
KÖNIG, T. (2001): Nutzensegmentierung <strong>und</strong> alternative Segmentierungsansätze –<br />
Eine vergleichende Gegenüberstellung im Handelsmarketing, Wiesbaden.<br />
124
Literaturverzeichnis<br />
KOPP, J. (1999): Neuronale Netze <strong>und</strong> qualitative Wissensbasen in der integrierten<br />
Umweltanalyse, Berlin.<br />
KRAFFT, M. (1998): Anwendungen der logistischen Regression, In: Hippner, H.;<br />
Meyer, M.; Wilde, K. D.(Hrsg.) (1998): Computer Based Marketing - Das<br />
Handbuch zur Marketinginformatik, Braunschweig/Wiesbaden, S. 535-543.<br />
KRÖSE, B.; VAN DER SMAGT, P. (1996): An introduction to Neural Network,<br />
Amsterdam. URL: http://www.avaye.com/files/articles/nnintro/nn_intro.pdf,<br />
Abrufdatum: 13.01.2005<br />
KRYCHA, K.; WAGNER, U. (1999): Applications of artifical neural networks in<br />
management science: a survey, In: Journal of Retailing and Consumer<br />
Services, Heft 6 (1999), S. 185-203.<br />
KÜPPERS, B. (1999): Data Mining in der Praxis: Ein Ansatz zur Nutzung der<br />
Potentiale <strong>von</strong> Data Mining im betrieblichen Umfeld, Frankfurt am Main.<br />
KÜSTERS, U. (2001): Data Mining Methoden - Einordnung <strong>und</strong> Überblick, In:<br />
Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch<br />
Data Mining im Marketing, Wiesbaden, S. 95-130.<br />
KÜSTERS, U. KALINOWSKI, C. (2001): Traditionelle Verfahren der <strong>multivariaten</strong><br />
Statistik, In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.)<br />
(2001): Handbuch Data Mining im Marketing, Wiesbaden, S. 131-192.<br />
LENZ, A.; MERETZ, S. (1995): Neuronale Netze <strong>und</strong> Subjektivität: Lernen,<br />
Bedeutung <strong>und</strong> die Grenzen der Neuro- Informatik, Braunschweig.<br />
LINK, J.; HILDEBRAND, V. G. (1998): Stand <strong>und</strong> Entwicklungstendenzen des<br />
Database Marketing <strong>und</strong> Computer Aided Selling in deutschen Unternehmen,<br />
In: Hippner, H.; Meyer, M.; Wilde, K. D.(Hrsg.) (1998): Computer Based<br />
Marketing - Das Handbuch zur Marketinginformatik, Braunschweig/<br />
Wiesbaden, S. 125-133.<br />
LÖBLER, H.; PETERSOHN, H. (2001): K<strong>und</strong>ensegmentierung im Automobilhandel<br />
zur Verbesserung der Marktbearbeitung. In: Hippner, H.; Küsters, U.; Meyer,<br />
M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data Mining im Marketing,<br />
Wiesbaden, S. 623-641.<br />
MCGUIRK, A. M.; DRISCOLL, P. (1995): The Hot Air in R² and Consistent Measures<br />
of Explained Variation, In: American Journal of Agricultural Economics,<br />
Heft 77 (1995), S. 319-328.<br />
MEYER, M. (2001): Data Mining im Marketing: Einordung <strong>und</strong> Überblick, In:<br />
Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch<br />
Data Mining im Marketing, Wiesbaden, S. 563-591.<br />
125
Literaturverzeichnis<br />
MEYER, M. (2002): Einsatz <strong>von</strong> Klassifikation <strong>und</strong> Prognose im Web Mining, In:<br />
Hippner, H.; Merzenich, M.; Wilde, K. D. (Hrsg.) (2002): Handbuch Web<br />
Mining im Marketing: Konzepte, Systeme, Fallstudien, Braunschweig, S.<br />
192-216.<br />
NATIONAL BUREAU OF STATISTICS (2004): China Statistical Yearbook 2004,<br />
Beijing.<br />
PERETTO, P. (1992): An Introduction to the Modelling of Neural Networks,<br />
Cambridge.<br />
PETERSOHN, H. (1997): <strong>Vergleich</strong> <strong>von</strong> <strong>multivariaten</strong> statistischen Analyseverfahren<br />
<strong>und</strong> künstlichen neuronalen <strong>Netzen</strong> zur Klassifikation bei<br />
Entscheidungsproblemen in der Wirtschaft, Frankfurt am Main.<br />
PETERSOHN, H. (1998): Beurteilung <strong>von</strong> Clusteranalysen <strong>und</strong> selbstorganisierenden<br />
Karten, In: Hippner, H.; Meyer, M.; Wilde, K. D.(Hrsg.) (1998): Computer<br />
Based Marketing - Das Handbuch zur Marketinginformatik,<br />
Braunschweig/Wiesbaden, S. 551-561.<br />
PODDING, T.; SIDOROVITCH, I. (2001) - Künstliche Neuronale Netze - Überblick,<br />
Einsatzmöglichkeiten <strong>und</strong> Anwendungsbeispiele, In: Hippner, H.; Küsters,<br />
U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data Mining im<br />
Marketing, Wiesbaden, S. 363-402.<br />
PROBST, M. (2002): Neuronale Netze zur Bestimmung nichtlinearer<br />
Nutzenfunktionen in Markenwahlmodellen, Frankfurt am Main.<br />
QI, M.; YANG, S. (2003): Forecasting consumer credit card adoption: what can we<br />
learn about utility function? In: International Journal of Forecasting, Heft 19<br />
(2003), S. 71–85. URL: http://socsci2.ucsd.edu/~aronatas/project/academic/<br />
Forecasting%20consumer%20credit%20card%20adoption.pdf, Abrufdatum:<br />
22.02.05<br />
REHKUGLER, H.; ZIMMERMANN, H.-G. (Hrsg.) (1994): Neuronale Netze in der<br />
Ökonomie: Gr<strong>und</strong>lagen <strong>und</strong> finanzwirtschaftliche Anwendungen, München.<br />
ROOSEN, J.; HANSEN, K.; THIELE S. (2004): Food Safety and Risk Perception in a<br />
Changing World, GeWiSoLa, Berlin.<br />
RUDOLF, M.; MÜLLER, J. (2004): Multivariate Verfahren: eine praxisorientierte<br />
Einführung mit Anwendungsbeispielen in SPSS, Göttingen.<br />
RUDOLPH, A. (1998): Prognoseverfahren in der Praxis, Heidelberg.<br />
SARLE, W. S. (2002): Neural Network FAQ. URL : http://wwwbruegge.in.tum.de/<br />
pub/Lehrstuhl/MachineLearningSoSe2003/NeuralNetworkFAQ.pdf,<br />
Abrufdatum: 26.01.2005<br />
126
Literaturverzeichnis<br />
SÄUBERLICH, F. (2000): KDD <strong>und</strong> Data Mining als Hilfsmittel zur<br />
Entscheidungsunterstützung, Frankfurt.<br />
SÄUBERLICH, F. (2003): Web Mining: Effektives Marketing im Internet, In:<br />
Wiedmann, K. P., Buckler, F. (Hrsg.) (2003): Neuronale Netze im Marketing-<br />
Management – Eine praxisorientierte Einführung in modernes Data-Mining,<br />
Wiesbaden, S. 129-146<br />
SCHEED, B- A. (2001): Softwarewerkzeuge für visuelles Data Mining im Marketing,<br />
In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001):<br />
Handbuch Data Mining im Marketing, Wiesbaden, S. 837-854.<br />
SCHMITT, B.; DEBOECK, G. (1998): Chapter 10 - Differential patterns in<br />
consumption preferences using self-organizing maps: case study of China, In:<br />
Deboeck, G. J.; Kohonen T. K. (1998) (Hrsg.) (1998): Visual Exploration in<br />
Finance with Self-Organizing Maps, London.<br />
SCHÜLER, F. (2002): Künstliche Neuronale Netze zur Datenanalyse in der<br />
Marktforschung, Berlin.<br />
SHARDA, R.; RAMPAL, R. (1998): Neural Networks and Management Science/<br />
Operations Research: A Bibliographic Essay, Encyclopedia of Library and<br />
Information Science, Vol. 61, Supp. 24 (1998), S. 247-259. URL: http://catt.<br />
bus.okstate.edu/itorms/guide/nnpaper.html, Abrufdatum: 18.02.2005<br />
SHIN, H.W.; SOHN, S.Y. (2004): Segmentation of stock trading customers according<br />
to potential value, In: Expert Systems with Applications, Heft 27 (2004), S.<br />
27-33.<br />
SMITH, K.A.; WILLIS, R.J.; BROOKS, M. (2000): An analysis of costumer retention<br />
and insurance claim patterns using data mining: a case study, In: Journal of<br />
the Operational Research Society, 2000, Heft51, S. 532-541. URL:<br />
http://www.palgrave-journals.com/cgi-taf/DynaPage.taf?file=/jors/journal/<br />
v51/ n5/full/2600941a.html&filetype=pdf, Abrufdatum: 18.02.2005<br />
SPILLER, A. (2001): Praxiskrise der Marketinglehre, In: Marketing ZFP, Heft 1<br />
(2001), S. 31-44.<br />
SPSS (Hrsg) (2003a): Clementine Algorithms Guide. URL: http://www.nbs.ntu.<br />
edu.sg/userguide/clementine/Clementine8.0/Clementine%20Algorithms%20<br />
Guide.pdf, Abrufdatum: 13.01.2005<br />
SPSS (Hrsg) (2003b): SPSS Advanced Models 12.0. URL: http://www.washington.<br />
edu/computing/software/sitelicenses/spss/docs/, Abrufdatum: 13.01.2005<br />
SPSS (Hrsg) (2003c): SPSS Base 12.0 User´s Guide. URL: http://www.washington.<br />
edu/computing/software/sitelicenses/spss/docs/, Abrufdatum: 13.01.2005<br />
SPSS (Hrsg) (2003d): Clementine® 8.0 Users`s Guide.<br />
127
Literaturverzeichnis<br />
SPSS (Hrsg) (2003e): SPSS Regression Models 12.0. URL: http://www.washington.<br />
edu/computing/software/sitelicenses/spss/docs/, Abrufdatum: 13.01.2005<br />
STATISTISCHES BUNDESAMT (2004): Statistisches Jahrbuch der B<strong>und</strong>esrepublik<br />
Deutschland, Wiesbaden.<br />
STRECKER, S. (1997): Künstliche Neuronale Netze – Aufbau <strong>und</strong> Funktionsweise,<br />
Arbeitspapiere WI, Nr. 10, 1997. URL: http://www.econbiz.de/archiv/gi/<br />
ugi/winformatik/kuenstliche_neuronale_netze.pdf, Abrufdatum: 13.01.2005<br />
STRECKER, S.; SCHWICKERT, A. C. (1997): Künstliche Neuronale Netze -<br />
Einordnung, Klassifikation aus betriebswirtschaftlicher Sicht,<br />
Arbeitspapiere WI, Nr. 4 (1997).URL:http://www.econbiz.de/archiv /gi/ugi/<br />
winformatik/kuenstliche_neuronale_netze_bwl.pdf, Abrufdatum: 13.01.2005<br />
THIEME, R. J.; SONG, M.; CALANTONE, R. J., (2000): Artificial Neural Network<br />
Decision Support Systems for New Product Development Project Selection.<br />
Journal of Marketing Research, Heft 37/4 (2000), S. 499-507. URL:<br />
http://fork.ltk.hut.fi/ehtf/Files/20ARTIFICIAL%20NEURAL%20NETWOR<br />
K%20DECISION%20SUPPORT%20SYSTEMS%20FOR%20NEW%20PR<br />
ODUCT%20DEVEL OPMENT%20PROJECT%20SELECTION.pdf,<br />
Abrufdatum: 20.02.2005<br />
TIBSHIRANI, R.; WALTHER, G.; HASTIE, T. (2000): Estimating the number of cluster<br />
in a data set via the gap statistic, In: Journal of the Royal Statistical Society:<br />
Series B (Statistical Methodology), Volume 63 (2001), Issue 2, S. 411–423.<br />
URL: http://www.blackwell-synergy.com/links/doi/10.1111/1467-9868.<br />
00293, Abrufdatum: 13.01.2005<br />
TIETZ, C.; POSCHARSKY, N.; ERICHSON, B.; MÜLLER, H. (2001): Ein <strong>Vergleich</strong><br />
führender Data Mining- Metoden zur Cross-Selling-Optimierung <strong>von</strong><br />
Finanzprodukten, In: Hippner, H.; Küsters, U.; Meyer, M.; Wilde, K.D.<br />
(Hrsg.) (2001): Handbuch Data Mining im Marketing, Wiesbaden, S.767-<br />
785.<br />
ULTSCH, A., VETTER C. (1994): Selforganizing Feature Maps versus Statistical<br />
Clustering: A Benchmark Research Report, No. 9 (1994), URL:<br />
http://www.informatik.uni- marburg.de/~databionics/papers/94cluster.pdf,<br />
Abrufdatum: 13.01.2005<br />
URBAN, A. (1998): Einsatz Künstlicher Neuronaler Netze bei der operativen<br />
Werbemittelplanung im Versandhandel im <strong>Vergleich</strong> zu ökonometrischen<br />
Verfahren, Berlin.<br />
VAZIRIGIANNIS, M.; HALKIDI, M., GUNOPULOS, D. (2003): Uncertainly Handling<br />
and Quality Assessment in Data Mining, London.<br />
VELLIDO, A.; LISBOAA, P.J.G; VAUGHANB, J. (1999): Neural networks in<br />
business: a survey of applications (1992–1998), In: Expert Systems with<br />
128
Literaturverzeichnis<br />
Applications, No. 17 (1999), S. 51–70. URL: http://www.lsi.upc.es/<br />
~avellido/publications_archivos/buss%20appls%20of%20NNs.pdf,<br />
Abrufdatum: 20.02.2005<br />
VENABLES, W. N.; RIPLEY, B. D. (2002): Modern Applied Statistics with S, Fourth<br />
edition, New York.<br />
VON AUER, L. (2003): Ökonometrie – Eine Einführung, 2.Auflage, Berlin.<br />
WEBER, R. (1998). Statische <strong>und</strong> dynamische Evaluation <strong>von</strong> Prognosen, In: ZA-<br />
Information, 43 (1998), S. 111-123.<br />
WEBER, R. (2000): Prognosemodelle zur Vorhersage der Fernsehnutzung. Neuronale<br />
Netze, Tree-Modelle <strong>und</strong> klassische Statistik im <strong>Vergleich</strong>, München.<br />
WEBER, R. (2001): Datenanalyse mittels neuronaler Netze am Beispiel des<br />
Publikumserfolgs <strong>von</strong> Spielfilmen. In: Zeitschrift für Medienpsychologie,<br />
Heft 13/4 (2001), S. 164–176.<br />
WEBER, R. (2003a): Neuronale Netze zur Beschreibung <strong>und</strong> Prognose <strong>von</strong><br />
Prozessen. URL: http://www.dr-rene-weber.de/files/weber.version1b.pdf,<br />
Abrufdatum: 13.01.2005<br />
WEBER, R. (2003b): Methods to Forecast Television Viewing Patterns for Target<br />
Audiences, In: Schorr, A.; Campbell, B.; Schenk, M. (2003): Communication<br />
Research in Europe and Abroad – Challenges of the First Decade, Berlin.<br />
URL: http://www.dr-rene-weber.de/files/article.europe.reneweber.pdf<br />
Abrufdatum: 13.01.2005<br />
WEDEL, M.; KAMAKURA, W. A. (2003): Market Segmentation – Conceptual and<br />
Methodological Fo<strong>und</strong>ations, Norwell.<br />
WEINGÄRTNER, S. (2001): Web-Mining- Ein Erfahrungsbericht, In: Hippner, H.;<br />
Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data<br />
Mining im Marketing, Wiesbaden, S. 889-903.<br />
WEINGESSEL, A.; DIMITRIADOU, E.; DOLNICAR, (1999): Working Paper - An<br />
Examination Of Indexes For Determining The Number Of Clusters in Binary<br />
Data Sets. URL: http://mpa.itc.it/biblio/papers/tibshirani00estimating.ps,<br />
Abrufdatum: 13.01.2005<br />
WHITE, H. (1992): Artifical Neural Networks – Approximation and Learning<br />
Theory, Cambridge.<br />
WIDMANN, G. (2001): Künstliche neuronale Netze <strong>und</strong> ihre Beziehungen zur<br />
Statistik, Frankfurt am Main.<br />
WIEDENBECK, M.; ZÜLL, C. (2001): Klassifikation mit Clusteranalyse –<br />
Gr<strong>und</strong>legende Techniken hierarchischer <strong>und</strong> K-means-Verfahren, ZUMA<br />
129
Literaturverzeichnis<br />
How-to-Reihe, Nr. 10, Mannheim. URL: http://www.gesis.org/Publikationen/<br />
Berichte/ZUMA_How_to/Dokumente/pdf/how-to10mwcz.pdf, Abrufdatum:<br />
13.01.2005<br />
WIEDMANN, (2003): Neuronale Netze als Basis eines effizienten<br />
Zielk<strong>und</strong>enmanagements in der Finanzdienstleistungsbranche, In: Wiedmann,<br />
K. P., Buckler, F. (Hrsg.) (2003): Neuronale Netze im Marketing-<br />
Management – Eine praxisorientierte Einführung in modernes Data-<br />
Mining, Wiesbaden, S.241-273.<br />
WIEDMANN, K.-P.; JUNG, H. H. (1995): Eignung neuronaler Netze als<br />
Klassifikationsansatz der Marketingforschung: Gr<strong>und</strong>lagen <strong>und</strong> erste<br />
Ergebnisse eines Methodenvergleichs am Beispiel der Klassifikation des<br />
Mobilitätsverhalten <strong>von</strong> Pkw- Nutzern, Hannover.<br />
WIEDMANN, K.-P.; JUNG, H.-H. (2003): Neuronale Netze zur Segmentierunganalyse<br />
in der Automobilindustrie, In: Wiedmann, K. P., Buckler, F. (Hrsg.) (2003):<br />
Neuronale Netze im Marketing-Management – Eine praxisorientierte<br />
Einführung in modernes Data-Mining, Wiesbaden, S.197- 214.<br />
WILBERT, R. (1996): Interpretation <strong>und</strong> Anwendung Neuronaler Netze in den<br />
Wirtschaftswissenschaften, Frankfurt am Main.<br />
WILDE, K. D. (2001): Data Warehouse, OLAP <strong>und</strong> Data Mining im Marketing –<br />
Moderne Informationstechnologien im Zusammenspiel, In: Hippner, H.;<br />
Küsters, U.; Meyer, M.; Wilde, K.D. (Hrsg.) (2001): Handbuch Data<br />
Mining im Marketing, Wiesbaden, S. 1-19.<br />
WILDE, K. D.; HIPPNER, H.; MERZENICH, M. (Hrsg.) (2002a): Aufsatzsammlung -<br />
Data Mining : mehr Gewinn aus Ihren K<strong>und</strong>endaten, Düsseldorf.<br />
WILDE, K. D.; HIPPNER, H.; MERZENICH, M. (Hrsg.) (2002b): Web Mining in der<br />
Praxis – eine empirische Untersuchung, In: Hippner, H.; Merzenich, M.;<br />
Wilde, K. D. (Hrsg.) (2002): Handbuch Web Mining im Marketing:<br />
Konzepte, Systeme, Fallstudien, Braunschweig, S.310-336.<br />
WU, SITAO (2004): Clustering of the self-organizing map using a clustering validity<br />
index based on inter-cluster and intra-cluster density, In: The journal of the<br />
Pattern Recognition Society, Bd. 37 (2004), Heft 2, S. 175-188.<br />
ZELL, A. (2003): Simulation neuronaler Netze, 4. unveränderter Nachdruck, Bonn.<br />
ZIMMERER, T. (1997): Künstliche neuronale Netze versus ökonometrische <strong>und</strong><br />
zeitreihenanalytische Verfahren zur Prognose ökonomischer Zeitreihen,<br />
Frankfurt am Main.<br />
130
Anhang<br />
Anhang<br />
A. Methoden der Datenanalyse<br />
Abbildung 41: Methoden der Datenanalyse<br />
Quelle: BODENSTEIN/SPILLER 1998: 81<br />
B. Berechnungen der Fallstudie 1<br />
Tabelle 20: ANOVA der Regressionsanalyse<br />
Quelle: Eigene Berechnungen<br />
131
Anhang<br />
Tabelle 21: Regressionskoeffizienten <strong>und</strong> Multikollinearitätsdiagnose<br />
Quelle: Eigene Berechnungen<br />
132
Anhang<br />
Abbildung 42: Häufigkeitsverteilung der Residualwerte<br />
Abhängige Variable: Abstimmung<br />
25<br />
20<br />
Häufigkeit<br />
15<br />
10<br />
5<br />
0<br />
-3 -2 -1 0 1 2 3 4<br />
Regression Standardisiertes Residuum<br />
Mean = 6,64E-16<br />
Std. Dev. = 0,984<br />
N = 97<br />
Quelle: Eigene Berechungen<br />
Abbildung 43: P-P-Normalverteilungsdiagramm der standardisierten Residualwerte<br />
1,0<br />
Abhängige Variable: Abstimmung<br />
0,8<br />
Erwartete Kum. Wahrsch.<br />
0,6<br />
0,4<br />
0,2<br />
0,0<br />
0,0 0,2 0,4 0,6 0,8 1,0<br />
Beobachtete Kum. Wahrsch.<br />
Quelle: Eigene Berechungen<br />
133
Anhang<br />
Abbildung 44: Streudiagramm - Residualwerte gegen Vorhersagewerte<br />
Abhängige Variable: Abstimmung<br />
4<br />
Regression Standardisiertes Residuum<br />
3<br />
2<br />
1<br />
0<br />
-1<br />
-2<br />
-3<br />
-2 -1 0 1<br />
Regression Standardisierter geschätzter Wert<br />
Quelle: Eigene Berechungen<br />
Tabelle 22: ANOVA der Regressionsanalyse (Modell 2)<br />
Quelle: Eigene Berechnungen<br />
134
Anhang<br />
Tabelle 23: Regressionskoeffizienten <strong>und</strong> Multikollinearitätsdiagnose (Modell 2)<br />
Quelle: Eigene Berechnungen<br />
135
Anhang<br />
Tabelle 24: Korrelationsmatrix der exogenen Variablen aus der Regressionsanalyse (Modell 2)<br />
Ohne<br />
Landwirtschaf<br />
t hätten wir in<br />
Deutschland<br />
noch viel<br />
mehr<br />
Arbeitslose.<br />
Der Verein<br />
"Natürlich<br />
Diemarden"<br />
hat dafür<br />
gesorgt, dass<br />
wir endlich<br />
informiert<br />
werden.<br />
Dass die<br />
Landwirte<br />
einfach einen<br />
Stall bauen<br />
können, finde<br />
ich nicht<br />
akzeptabel.<br />
Die<br />
Diskussion<br />
um den<br />
Stallbau<br />
interessiert<br />
mich<br />
überhaupt<br />
nicht.<br />
Hätten die<br />
Landwirte<br />
uns Bürger<br />
<strong>von</strong> Anfang<br />
an informiert,<br />
wäre die<br />
Akzeptanz<br />
größer.<br />
Polaritäten<br />
profil<br />
Landschaf<br />
tspfleger-<br />
Landschaf<br />
tszerstörer<br />
Die<br />
Subventionen<br />
für die<br />
Landwirtschaf<br />
t sind generell<br />
zu hoch.<br />
Wenn ich an<br />
den Stallbau<br />
denke, ärgere<br />
ich mich sehr.<br />
Wenn ein<br />
Stall<br />
ordentlich<br />
begrünt ist,<br />
stört er<br />
optische<br />
nicht weiter.<br />
1 -,501 -,295 ,376 -,135 ,194 -,337 -,404 ,192<br />
,000 ,001 ,000 ,103 ,017 ,000 ,000 ,020<br />
151 150 120 148 147 151 141 147 146<br />
-,501 1 ,362 -,466 ,179 -,425 ,563 ,622 -,241<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
Wenn ein Stall ordentlich<br />
begrünt ist, stört er<br />
optische nicht weiter.<br />
,000 ,000 ,000 ,029 ,000 ,000 ,000 ,003<br />
150 152 120 150 148 152 143 148 147<br />
Wenn ich an den Stallbau<br />
denke, ärgere ich mich<br />
sehr.<br />
N<br />
-,295 ,362 1 -,438 ,070 -,069 ,367 ,308 -,297<br />
,001 ,000 ,000 ,449 ,454 ,000 ,001 ,001<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Die Subventionen für die<br />
Landwirtschaft sind<br />
generell zu hoch.<br />
120 120 121 119 118 121 112 120 119<br />
,376 -,466 -,438 1 -,165 ,300 -,490 -,402 ,398<br />
,000 ,000 ,000 ,044 ,000 ,000 ,000 ,000<br />
148 150 119 151 148 151 142 148 146<br />
-,135 ,179 ,070 -,165 1 ,030 ,148 ,330 -,103<br />
,103 ,029 ,449 ,044 ,720 ,080 ,000 ,216<br />
147 148 118 148 151 150 141 147 146<br />
,194 -,425 -,069 ,300 ,030 1 -,318 -,283 ,044<br />
,017 ,000 ,454 ,000 ,720 ,000 ,000 ,598<br />
151 152 121 151 150 154 144 150 148<br />
-,337 ,563 ,367 -,490 ,148 -,318 1 ,490 -,244<br />
,000 ,000 ,000 ,000 ,080 ,000 ,000 ,004<br />
141 143 112 142 141 144 145 142 138<br />
-,404 ,622 ,308 -,402 ,330 -,283 ,490 1 -,316<br />
,000 ,000 ,001 ,000 ,000 ,000 ,000 ,000<br />
147 148 120 148 147 150 142 150 145<br />
,192 -,241 -,297 ,398 -,103 ,044 -,244 -,316 1<br />
,020 ,003 ,001 ,000 ,216 ,598 ,004 ,000<br />
146 147 119 146 146 148 138 145 148<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Polaritätenprofil<br />
Landschaftspfleger-<br />
Landschaftszerstörer<br />
Hätten die Landwirte uns<br />
Bürger <strong>von</strong> Anfang an<br />
informiert, wäre die<br />
Akzeptanz größer<br />
Die Diskussion um den<br />
Stallbau interessiert mich<br />
überhaupt nicht.<br />
Dass die Landwirte<br />
einfach einen Stall bauen<br />
können, finde ich nicht<br />
akzeptabel<br />
Der Verein "Natürlich<br />
Diemarden" hat dafür<br />
gesorgt, dass wir endlich<br />
informiert werden<br />
Ohne Landwirtschaft<br />
hätten wir in Deutschland<br />
noch viel mehr<br />
Arbeitslose<br />
Quelle: Eigene Berechnungen<br />
136
Anhang<br />
Abbildung 45: Häufigkeitsverteilung der Residualwerte (Modell 2)<br />
Abhängige Variable: Abstimmung<br />
14<br />
12<br />
10<br />
Häufigkeit<br />
8<br />
6<br />
4<br />
2<br />
0<br />
-3 -2 -1 0 1 2<br />
Regression Standardisiertes Residuum<br />
Mean = 1,84E-16<br />
Std. Dev. = 0,931<br />
N = 69<br />
Quelle: Eigene Berechungen<br />
Abbildung 46: P-P-Normalverteilungsdiagramm der standardisierten Residualwerte<br />
(Modell 2)<br />
1,0<br />
Abhängige Variable: Abstimmung<br />
0,8<br />
Erwartete Kum. Wahrsch.<br />
0,6<br />
0,4<br />
0,2<br />
0,0<br />
0,0 0,2 0,4 0,6 0,8 1,0<br />
Beobachtete Kum. Wahrsch.<br />
Quelle: Eigene Berechungen<br />
137
Anhang<br />
Abbildung 47: Streudiagramm - Residualwerte gegen Vorhersagewerte<br />
(Modell 2)<br />
Abhängige Variable: Abstimmung<br />
2<br />
Regression Standardisiertes Residuum<br />
1<br />
0<br />
-1<br />
-2<br />
-3<br />
-2 -1 0 1 2<br />
Regression Standardisierter geschätzter Wert<br />
Quelle: Eigene Berechungen<br />
Tabelle 25: Korrelationsmatrix der exogenen Variablen der Regressionsanalyse<br />
(Modell 1)<br />
Stellen Sie sich vor, es<br />
gäbe eine<br />
Dorfabstimmung über<br />
den Stallbau in<br />
Diemarden, wie würden<br />
Sie entscheiden?<br />
Wenn ich an den<br />
Stallbau denke, ärgere<br />
ich mich sehr.<br />
Hätten die Landwirte<br />
uns Bürger <strong>von</strong> Anfang<br />
an informiert, wäre die<br />
Akzeptanz größer.<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
Stellen Sie<br />
sich vor, es<br />
gäbe eine<br />
Dorfabstimmu<br />
ng über den<br />
Stallbau in<br />
Diemarden,<br />
wie würden<br />
Sie<br />
entscheiden?<br />
Wenn ich an<br />
den Stallbau<br />
denke, ärgere<br />
ich mich sehr.<br />
Hätten die<br />
Landwirte<br />
uns Bürger<br />
<strong>von</strong> Anfang<br />
an informiert,<br />
wäre die<br />
Akzeptanz<br />
größer.<br />
Ohne die<br />
Bauern wäre<br />
Diemarden<br />
nur halb so<br />
lebenswert.<br />
1 -,781 -,305 ,443<br />
,000 ,000 ,000<br />
154 152 150 151<br />
-,781 1 ,179 -,374<br />
,000 ,029 ,000<br />
152 152 148 149<br />
-,305 ,179 1 -,177<br />
,000 ,029 ,032<br />
150 148 151 148<br />
Ohne die Bauern wäre<br />
Diemarden nur halb so<br />
lebenswert.<br />
Korrelation nach Pearson<br />
Signifikanz (2-seitig)<br />
N<br />
,443 -,374 -,177 1<br />
,000 ,000 ,032<br />
151 149 148 151<br />
Quelle: Eigene Berechungen<br />
138
Anhang<br />
C. Berechnungen der Fallstudie 2<br />
Abbildung 48: Screeplot der Faktorenanalyse<br />
4<br />
3<br />
Eigenwert<br />
2<br />
1<br />
0<br />
1 2 3 4 5 6 7 8 9 10 11<br />
Faktor<br />
Quelle: Eigene Berechnungen<br />
Abbildung 49: Komponentendiagramm im rotierten Raum<br />
Komponente 2<br />
1,0<br />
0,5<br />
0,0<br />
-0,5<br />
q11d_buy_chinese_brands<br />
q11e_buy_chinese_brands<br />
q6d<br />
q6c<br />
q6b<br />
q6f q6g<br />
q11b_buy_chinese_brands<br />
q11c_buy_chinese_brands<br />
-1,0<br />
-1,0<br />
-0,5<br />
0,0<br />
0,5<br />
Komponente 1<br />
1,0<br />
1,0<br />
0,5<br />
0,0<br />
-0,5<br />
Komponente 3<br />
-1,0<br />
Quelle: Eigene Berechnungen<br />
139
Anhang<br />
Tabelle 26: Datenbasis zum Elbow-Kriterium<br />
Anzahl Cluster Fehlerquadratsumme<br />
Differenz der<br />
Fehlerquadratsumme zum<br />
nächsten Cluster<br />
2 1890,69455<br />
3 1575,27089 315,42366<br />
4 1297,22636 278,044533<br />
5 1144,13912 153,087239<br />
6 1025,82845 118,310669<br />
7 921,994037 103,83441<br />
8 841,309577 80,6844599<br />
9 782,42096 58,8886169<br />
10 741,309266 41,1116947<br />
11 702,760502 38,548764<br />
12 665,498874 37,2616281<br />
13 635,10224 30,3966338<br />
14 606,919396 28,1828435<br />
15 580,62669 26,2927061<br />
Quelle: Eigene Berechungen<br />
Tabelle 27: Mittelwertvergleich bei der Ward Methode<br />
Ward Method<br />
1<br />
2<br />
3<br />
4<br />
5<br />
Insgesamt<br />
patriotism prestige effect of trust/performance<br />
effect of Chinese<br />
foreign brands<br />
brands<br />
Mittelwert 0,485089536 -1,040889003 0,255761214<br />
N 150 150 150<br />
Standardabweichung 0,54545942 0,474408474 0,664298277<br />
Mittelwert 0,19404448 0,626933001 0,682806419<br />
N 259 259 259<br />
Standardabweichung 0,744373864 0,841631622 0,655007801<br />
Mittelwert 0,722286779 0,02535323 -1,029679742<br />
N 166 166 166<br />
Standardabweichung 0,635039915 0,910712438 0,59213012<br />
Mittelwert -1,20979497 -0,778231198 0,740650149<br />
N 71 71 71<br />
Standardabweichung 0,697798512 0,509785955 0,730828435<br />
Mittelwert -1,14866843 0,332362548 -0,698377642<br />
N 137 137 137<br />
Standardabweichung 0,701999469 0,762087263 0,702972586<br />
Mittelwert -0,000437371 0,00093255 0,001523156<br />
N 783 783 783<br />
Standardabweichung 0,993111383 0,994146308 0,98012211<br />
Quelle: Eigene Berechungen<br />
140
Anhang<br />
Tabelle 28: Mittelwertvergleich bei der K-Means Methode<br />
K-Means<br />
1<br />
2<br />
3<br />
4<br />
5<br />
Insgesamt<br />
patriotism prestige effect of trust/performance<br />
effect of Chinese<br />
foreign brands<br />
brands<br />
Mittelwert 0,477164654 -0,821982953 0,370699723<br />
N 228 228 228<br />
Standardabweichung 0,512152186 0,546574307 0,693223059<br />
Mittelwert 0,387588696 1,061756269 0,856408261<br />
N 144 144 144<br />
Standardabweichung 0,722735146 0,778080014 0,655554161<br />
Mittelwert 0,690252272 0,178285803 -0,991779324<br />
N 171 171 171<br />
Standardabweichung 0,570790898 0,805526889 0,612143243<br />
Mittelwert -1,371448784 -0,50204805 0,691426087<br />
N 91 91 91<br />
Standardabweichung 0,679364756 0,700051615 0,656959275<br />
Mittelwert -1,061611238 0,338583207 -0,670974531<br />
N 149 149 149<br />
Standardabweichung 0,557496133 0,831114793 0,649341986<br />
Mittelwert -0,000437371 0,00093255 0,001523156<br />
N 783 783 783<br />
Standardabweichung 0,993111383 0,994146308 0,98012211<br />
Quelle: Eigene Berechungen<br />
Tabelle 29: ANOVA-Tabelle bei der K-Means Clusterung<br />
Faktoren<br />
Quadratsumme<br />
Quadrate<br />
df Mittel der F Signifikanz<br />
patriotism Zwischen den Gruppen 494,10 4 123,53 346,74 0,0000<br />
Innerhalb der Gruppen 277,16 778 0,36<br />
Insgesamt 771,26 782<br />
prestige effect of foreign Zwischen den Gruppen 361,84 4 90,46 171,22 0,0000<br />
brands<br />
Innerhalb der Gruppen 411,03 778 0,53<br />
Insgesamt 772,87 782<br />
trust/performance effect Zwischen den Gruppen 415,73 4 103,93 241,02 0,0000<br />
of Chinese brands<br />
Innerhalb der Gruppen 335,49 778 0,43<br />
Insgesamt 751,22 782<br />
Quelle: Eigene Berechungen<br />
Tabelle 30: Kreuztabelle der Ergebnisse der replizierten <strong>und</strong> der anfänglichen<br />
Clusteranalyse<br />
Ergebnisse der<br />
replizierten<br />
Clusteranalyse<br />
Ergebnisse der Clusteranalyse<br />
Gesamt<br />
Cluster 1 2 3 4 5<br />
1 91 0 0 2 0 93<br />
2 0 62 0 0 0 62<br />
3 3 3 84 0 5 95<br />
4 11 0 2 26 29 68<br />
5 0 11 0 19 42 72<br />
Gesamt<br />
105 76 86 47 76 390<br />
Quelle: Eigene Berechungen<br />
141
Anhang<br />
Tabelle 31: Ergebnisse der Clusteranalyse (Ausgangslösung)<br />
Ergebnisse der<br />
Clusteranalyse<br />
1<br />
2<br />
3<br />
4<br />
5<br />
Insgesamt<br />
patriotism prestige effect of trust/performance<br />
effect of Chinese<br />
foreign brands<br />
brands<br />
Mittelwert 0,450450928 -0,9033712 0,350757452<br />
N 105 105 105<br />
Standardabweichung 0,5251005 0,558512992 0,676608003<br />
Mittelwert 0,407041992 1,122831898 0,872218125<br />
N 76 76 76<br />
Standardabweichung 0,778298219 0,893741453 0,70854378<br />
Mittelwert 0,719099797 0,133796649 -0,936293308<br />
N 86 86 86<br />
Standardabweichung 0,559387015 0,79125893 0,607799913<br />
Mittelwert -1,315053111 -0,547837574 0,574744861<br />
N 47 47 47<br />
Standardabweichung 0,52175934 0,687123421 0,537404276<br />
Mittelwert -1,029884182 0,334213181 -0,602909138<br />
N 76 76 76<br />
Standardabweichung 0,531029243 0,759737837 0,660496505<br />
Mittelwert -9,1608E-06 0,004204092 0,009714871<br />
N 390 390 390<br />
Standardabweichung 0,981362736 1,034381658 0,951133873<br />
Quelle: Eigene Berechungen<br />
Tabelle 32: Ergebnisse der replizierten Clusteranalyse<br />
Ergebnisse der<br />
replizierten<br />
Clusteranalyse<br />
1<br />
2<br />
3<br />
4<br />
5<br />
Insgesamt<br />
Quelle: Eigene Berechungen<br />
patriotism<br />
prestige effect of<br />
trust/performance<br />
effect of Chinese<br />
foreign brands<br />
brands<br />
Mittelwert 0,525383651 -0,875819549 0,488266779<br />
N 93 93 93<br />
Standardabweichung 0,496163297 0,534581227 0,668893255<br />
Mittelwert 0,592923003 1,151307439 0,974498852<br />
N 62 62 62<br />
Standardabweichung 0,701525724 0,944788373 0,717925109<br />
Mittelwert 0,650887263 0,180461471 -0,921933241<br />
N 95 95 95<br />
Standardabweichung 0,600139981 0,769811405 0,633268083<br />
Mittelwert -0,993120188 -0,786116078 -0,313461643<br />
N 68 68 68<br />
Standardabweichung 0,579060454 0,58183527 0,838087449<br />
Mittelwert -1,110105495 0,666969531 0,095279302<br />
N 72 72 72<br />
Standardabweichung 0,558354262 0,610051206 0,598788347<br />
Mittelwert -9,1608E-06 0,004204092 0,009714871<br />
N 390 390 390<br />
Standardabweichung 0,981362736 1,034381658 0,951133873<br />
142
Anhang<br />
Tabelle 33: <strong>Vergleich</strong> der Dimensionen der SOM<br />
Breite/Länge eta² Breite/Länge eta²<br />
9 Cluster 9 -- 2 0,64 3 -- 3 0,60<br />
12 Cluster 12 -- 2 0,69 3 -- 4 0,66<br />
15 Cluster 15 --2 0,73 3 -- 5 0,72<br />
Quelle: Eigene Berechungen<br />
Tabelle 34: Mittelwertvergleich bei den SOM<br />
SOM<br />
1<br />
2<br />
3<br />
4<br />
5<br />
Insgesamt<br />
patriotism prestige effect of trust/performance<br />
effect of Chinese<br />
foreign brands<br />
brands<br />
Mittelwert -1,332948516 0,222361691 0,232634352<br />
N 181 181 181<br />
Standardabweichung 0,619883504 0,992017795 0,763704378<br />
Mittelwert -0,601085198 0,057891629 -0,716192663<br />
N 104 104 104<br />
Standardabweichung 0,336747396 0,92517282 0,653991938<br />
Mittelwert 0,547447945 0,014475906 -1,071211988<br />
N 162 162 162<br />
Standardabweichung 0,497170352 0,996585028 0,563073054<br />
Mittelwert 0,769731062 -0,133102497 -0,049682141<br />
N 138 138 138<br />
Standardabweichung 0,541989563 0,989505877 0,271588428<br />
Mittelwert 0,548104174 -0,149065458 1,080617816<br />
N 198 198 198<br />
Standardabweichung 0,558336874 1,000897224 0,553929085<br />
Mittelwert -0,000437371 0,00093255 0,001523156<br />
N 783 783 783<br />
Standardabweichung 0,993111383 0,994146308 0,98012211<br />
Quelle: Eigene Berechungen<br />
Tabelle 35: ANOVA der aktiven Faktoren<br />
Faktoren Eta Eta-Quadrat Fehlervarianz Gesamtvarianz<br />
F1: patriotism 0,84 0,71 222,30 771,26<br />
F2: prestige effect of foreign<br />
brands 0,14 0,02 756,70 772,87<br />
F3: trust/performance effect<br />
of Chinese brands 0,80 0,64 270,64 751,22<br />
Quelle: Eigene Berechnungen<br />
143
Anhang<br />
Tabelle 36: ANOVA-Tabelle bei den SOM<br />
Faktoren<br />
patriotism<br />
prestige effect of foreign<br />
brands<br />
trust/performance effect<br />
of Chinese brands<br />
Quelle: Eigene Berechungen<br />
Quadratsumme<br />
df Mittel der F Signifikanz<br />
Quadrate<br />
Zwischen den Gruppen 548,96 4 137,24 480,32 0,0000<br />
Innerhalb der Gruppen 222,30 778 0,29<br />
Insgesamt 771,26 782<br />
Zwischen den Gruppen 16,18 4 4,04 4,16 0,0024<br />
Innerhalb der Gruppen 756,70 778 0,97<br />
Insgesamt 772,87 782<br />
Zwischen den Gruppen 480,58 4 120,15 345,39 0,0000<br />
Innerhalb der Gruppen 270,64 778 0,35<br />
Insgesamt 751,22 782<br />
Tabelle 37: Kreuztabelle der Ergebnisse der replizierten <strong>und</strong> der anfänglichen SOM<br />
Ergebnisse der<br />
replizierten<br />
SOM<br />
Ergebnisse der anfänglichen SOM<br />
Gesamt<br />
Cluster 1 2 3 4 5<br />
1 17 24 14 0 0 55<br />
2 14 46 20 8 4 92<br />
3 35 24 37 0 0 96<br />
4 0 0 1 79 20 100<br />
5 1 1 6 12 27 47<br />
Gesamt<br />
67 95 78 99 51 390<br />
Quelle: Eigene Berechungen<br />
Tabelle 38: Ergebnisse der SOM (Ausgangslösung)<br />
Ergebnisse der<br />
SOM<br />
1<br />
2<br />
3<br />
4<br />
5<br />
Insgesamt<br />
patriotism prestige effect of trust/performance<br />
effect of Chinese<br />
foreign brands<br />
brands<br />
Mittelwert 0,784609062 -0,260595211 -0,116855804<br />
N 67 67 67<br />
Standardabweichung 0,574289244 1,01928367 0,280919898<br />
Mittelwert 0,598738493 -0,131191597 1,069579847<br />
N 95 95 95<br />
Standardabweichung 0,542041319 1,044077542 0,545001064<br />
Mittelwert 0,575104454 0,09208315 -1,032224981<br />
N 78 78 78<br />
Standardabweichung 0,493954855 1,032616004 0,572659225<br />
Mittelwert -1,236635985 0,259607134 0,254739409<br />
N 99 99 99<br />
Standardabweichung 0,541856085 1,082514771 0,69770431<br />
Mittelwert -0,625171012 -0,0259003 -0,680345099<br />
N 51 51 51<br />
Standardabweichung 0,324291605 0,832811235 0,680122836<br />
Mittelwert -9,1608E-06 0,004204092 0,009714871<br />
N 390 390 390<br />
Standardabweichung 0,981362736 1,034381658 0,951133873<br />
Quelle: Eigene Berechungen<br />
144
Anhang<br />
Tabelle 39: Ergebnisse der replizierten SOM<br />
Ergebnisse der<br />
replizierten<br />
SOM<br />
1<br />
2<br />
3<br />
4<br />
5<br />
Insgesamt<br />
patriotism prestige effect of trust/performance<br />
effect of Chinese<br />
foreign brands<br />
brands<br />
Mittelwert 0,78493719 -0,067490825 0,130889302<br />
N 55 55 55<br />
Standardabweichung 0,556038571 0,493346148 0,793132706<br />
Mittelwert 0,620188854 1,064785418 0,594905775<br />
N 92 92 92<br />
Standardabweichung 0,680472671 0,868429532 0,955905202<br />
Mittelwert 0,511126583 -0,967348212 -0,337209119<br />
N 96 96 96<br />
Standardabweichung 0,451972773 0,590351712 0,978534768<br />
Mittelwert -1,228199137 0,309452206 -0,070650001<br />
N 100 100 100<br />
Standardabweichung 0,554245555 0,772691126 0,83032973<br />
Mittelwert -0,563419808 -0,652945947 -0,397965275<br />
N 47 47 47<br />
Standardabweichung 0,357045999 0,629384051 0,710863618<br />
Mittelwert -9,1608E-06 0,004204092 0,009714871<br />
N 390 390 390<br />
Standardabweichung 0,981362736 1,034381658 0,951133873<br />
Quelle: Eigene Berechungen<br />
D. <strong>Vergleich</strong> der Verfahren<br />
Abbildung 50: 3D-Streudiagramm der Clusterlösung (K-Means)<br />
Quelle: Eigene Berechnungen<br />
145
Anhang<br />
Abbildung 51: 3D-Streudiagramm der Clusterlösung (SOM)<br />
Quelle: Eigene Berechnungen<br />
Abbildung 52: Häufigkeit der eingesetzten Verfahren in der betrieblichen Praxis 112<br />
(n=44; Mittelwerte, Skala <strong>von</strong> 1=„nie“ bis 5=“immer“)<br />
Quelle: Eigene Darstellung nach HIPPNER et al. 2002:138<br />
112 Um die Übersichtlichkeit zu wahren sind drei selten verwendete Verfahren (Multidimensionale<br />
Skalierung, Sequenzanalyse, Bayesianische Netze) nicht aufgelistet.<br />
146
Anhang<br />
Abbildung 53: Bedeutung der Auswahlkriterien geeigneter Verfahren<br />
(n=45; Mittelwert, Skala <strong>von</strong> 1=“geringe Bedeutung“ bis<br />
5=“hohe Bedeutung“)<br />
Quelle: Eigene Darstellung nach HIPPNER et al. 2002:138<br />
147
Anhang<br />
E. Fragebogen der Fallstudie 1<br />
Universität Göttingen<br />
Meinungsforschung zum Stallbau in Diemarden<br />
Guten Tag!<br />
Wir sind Studenten der Universität Göttingen. Im Rahmen einer Vorlesung führen<br />
wir eine Umfrage zum Thema „Stallbau in Diemarden“ durch. Ziel der Umfrage ist<br />
es, ein neutrales Meinungsbild über den Stallbau zu erhalten. Die Ergebnisse dieser<br />
Umfrage haben keinerlei Einfluss auf den Stallbau, sondern dienen rein<br />
wissenschaftlichen Zwecken.<br />
Wir würden uns sehr freuen, wenn Sie sich zu einer Teilnahme bereit erklären<br />
würden. Alle erhobenen Daten werden anonym <strong>und</strong> ohne Rückschlussmöglichkeit<br />
auf Ihre Person bearbeitet.<br />
Die Beantwortung dieses Fragebogens dauert ungefähr 15 Minuten.<br />
Interviewer<br />
Datum<br />
Uhrzeit bei Beginn<br />
1. Wie Sie sicherlich wissen, planen zwei Landwirte am Ortsrand <strong>von</strong><br />
Diemarden einen Schweinestall zu bauen. Was meinen Sie zu diesem<br />
Vorhaben? Bitte benutzen Sie dafür folgende Skala. (Interviewer bitte die<br />
Skala zeigen). Stimmen Sie dem Stallbau zu oder lehnen Sie ihn ab?<br />
Stimme<br />
voll <strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils, teils<br />
Lehne<br />
eher ab<br />
Lehne ab<br />
Lehne<br />
voll <strong>und</strong><br />
ganz ab<br />
2. Können Sie kurz sagen, warum Sie dafür oder dagegen sind?<br />
____________________________________________________________________<br />
____________________________________________________________________<br />
____________________________________________________________________<br />
148
Anhang<br />
3. Über den Stallbau in Diemarden kann man unterschiedlicher Meinung<br />
sein. Wir haben dazu einige Äußerungen aufgeführt <strong>und</strong> möchten Sie<br />
bitten, diese Äußerungen anhand dieser 7-stufigen Skala zu bewerten.<br />
Stimme<br />
voll <strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils,<br />
teils<br />
Lehne<br />
eher ab<br />
Lehne<br />
ab<br />
Lehne voll<br />
<strong>und</strong> ganz<br />
ab<br />
Durch den Stall wird<br />
die ges<strong>und</strong>heitliche<br />
Belastung stark<br />
steigen.<br />
Würde der Stall in<br />
Diemarden an anderer<br />
Stelle stehen, wäre mir<br />
das Ganze egal.<br />
Der Güllegeruch beim<br />
Ausbringen wird<br />
unerträglich sein.<br />
Ich glaube nicht, dass<br />
ein Stall die Gr<strong>und</strong>stückspreise<br />
in<br />
Diemarden verändert.<br />
Wenn ein Stall<br />
ordentlich begrünt ist,<br />
stört er optisch nicht<br />
weiter.<br />
Ich rechne nicht mit<br />
einer persönlichen Belastung<br />
durch den<br />
Stall.<br />
Die Freizeitmöglichkeiten<br />
in Diemarden<br />
werden durch den Stall<br />
nicht beeinträchtigt.<br />
Wenn der Stall erst<br />
mal steht, wird der<br />
Verkehr stark<br />
zunehmen.<br />
Die Belastung durch<br />
den Schweinestall<br />
wird man kaum<br />
bemerken.<br />
Durch<br />
den<br />
Schweinestall würde<br />
ganz Diemarden<br />
stinken.<br />
Eigentlich habe ich<br />
nichts gegen solch<br />
einen Stall, nur sollte<br />
er nicht direkt vor<br />
unserer Haustür<br />
gebaut werden.<br />
149
Anhang<br />
Wenn man alle Vor<strong>und</strong><br />
Nachteile des<br />
Schweinestalls<br />
vergleicht, überwiegen<br />
die Vorteile.<br />
Wenn ich an den<br />
Stallbau denke, ärgere<br />
ich mich sehr.<br />
Stimme<br />
voll <strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils,<br />
teils<br />
Lehne<br />
eher ab<br />
Lehne<br />
ab<br />
Lehne voll<br />
<strong>und</strong> ganz<br />
ab<br />
4. Es gibt unterschiedliche Bedenken oder Ängste im Zusammenhang mit<br />
dem Bau des geplanten Schweinestalls. Welche Bedenken sind für Sie die<br />
wichtigsten? Bilden Sie bitte eine Rangfolge Ihrer drei wichtigsten<br />
Bedenken. (Bitte den wichtigsten Einwand mit einer 1, den<br />
zweitwichtigsten mit einer 2 usf. kennzeichnen.)<br />
ڤ<br />
Erhöhung des Verkehrsaufkommens ڤ<br />
Keine artgerechte Tierhaltung ڤ<br />
Wertverlust <strong>von</strong> Häusern <strong>und</strong> Gr<strong>und</strong>stücken ڤ<br />
Starke Geruchsbelästigung ڤ<br />
Baldige Erweiterung der Stallanlagen ڤ<br />
Erhöhung der Umweltbelastung durch Gülleausbringung ڤ<br />
Minderung des Freizeit- <strong>und</strong> Erholungswertes ڤ<br />
Sonstige_______________________________________________________ ڤ<br />
Ich habe keine Bedenken. 5. Die folgenden Aussagen beziehen sich auf die Landwirtschaft im<br />
Allgemeinen, aber auch in Diemarden. Auch hierzu gibt es eine Vielzahl<br />
<strong>von</strong> Meinungen. Bitte bewerten Sie die folgenden Aussagen anhand der<br />
bereits verwendeten Skala.<br />
Die Bedeutung der<br />
Landwirtschaft in<br />
der Gesellschaft<br />
wird überbewertet.<br />
Der Stall ist für die<br />
Landwirte die<br />
einzige Möglichkeit,<br />
ihren Arbeitsplatz zu<br />
erhalten.<br />
Wenn man aufs Dorf<br />
zieht, muss man die<br />
Landwirtschaft<br />
akzeptieren.<br />
Stimme<br />
voll <strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils,<br />
teils<br />
Lehne<br />
eher ab<br />
Lehne<br />
ab<br />
Lehne<br />
voll <strong>und</strong><br />
ganz ab<br />
150
Anhang<br />
Ich kenne mich in<br />
landwirtschaftlichen<br />
Themen aus.<br />
Die Subventionen<br />
für<br />
die<br />
Landwirtschaft sind<br />
generell zu hoch.<br />
Ohne die Bauern<br />
wäre Diemarden nur<br />
halb so lebenswert.<br />
Ohne<br />
Landwirtschaft<br />
hätten wir in<br />
Deutschland noch<br />
viel mehr<br />
Arbeitslose.<br />
Landwirte müssen<br />
im Allgemeinen<br />
mehr Rücksicht auf<br />
andere Bürger<br />
nehmen.<br />
Die Landwirte in<br />
Diemarden haben<br />
sich ungeschickt<br />
verhalten.<br />
Eigentlich sollten<br />
alle Landwirte<br />
ökologisch<br />
wirtschaften.<br />
Von Landwirtschaft<br />
habe ich eigentlich<br />
keine Ahnung.<br />
Stimme<br />
voll <strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils,<br />
teils<br />
Lehne<br />
eher ab<br />
Lehne<br />
ab<br />
Lehne<br />
voll <strong>und</strong><br />
ganz ab<br />
151
Anhang<br />
6. Bitte vervollständigen Sie folgende Sätze, indem Sie Ihre Meinung an der<br />
zutreffenden Stelle ankreuzen:<br />
Landwirtschaft ist......<br />
wichtig<br />
altmodisch<br />
glaubwürdig<br />
familiär<br />
modern<br />
trifft<br />
voll<br />
<strong>und</strong><br />
ganz<br />
zu<br />
trifft<br />
zu<br />
trifft<br />
eher<br />
zu<br />
teils,<br />
teils<br />
trifft<br />
eher<br />
zu<br />
trifft<br />
zu<br />
trifft<br />
voll<br />
<strong>und</strong><br />
ganz<br />
zu<br />
3 2 1 0 1 2 3<br />
unwichtig<br />
innovativ<br />
unglaubwürdig<br />
industriell<br />
traditionell<br />
Landwirte sind ......<br />
kommunikativ<br />
gierig<br />
sympathisch<br />
trifft<br />
voll<br />
<strong>und</strong><br />
ganz<br />
zu<br />
trifft<br />
zu<br />
trifft<br />
eher<br />
zu<br />
teils,<br />
teils<br />
trifft<br />
eher<br />
zu<br />
trifft<br />
zu<br />
trifft<br />
voll<br />
<strong>und</strong><br />
ganz<br />
zu<br />
3 2 1 0 1 2 3<br />
faul<br />
reich<br />
unfre<strong>und</strong>lich<br />
clever<br />
skandalverursachend<br />
skandalunschuldig<br />
fleißig<br />
arm<br />
fre<strong>und</strong>lich<br />
dumm<br />
Landschaftspfleger<br />
Landschaftszerstörer<br />
verschlossen<br />
bescheiden<br />
unsympathisch<br />
152
Anhang<br />
7. Der Stallbau hat in Diemarden einige Wellen geschlagen <strong>und</strong><br />
wahrscheinlich haben Sie sich mit anderen Bürgern darüber<br />
ausgetauscht. Wie würden Sie die folgenden Aussagen bewerten?<br />
Hätten die Landwirte<br />
uns Bürger <strong>von</strong> Anfang<br />
an informiert, wäre die<br />
Akzeptanz größer.<br />
Ich fühle mich <strong>von</strong> den<br />
Landwirten unfair<br />
behandelt.<br />
Ich habe meine<br />
Einstellung zu diesem<br />
Thema bei vielen<br />
Gelegenheiten zum<br />
Ausdruck gebracht.<br />
Der Verein „Natürlich<br />
Diemarden“ hat dafür<br />
gesorgt, dass wir endlich<br />
informiert werden.<br />
Die Diskussion um den<br />
Stallbau interessiert<br />
mich überhaupt nicht.<br />
Ich informiere mich sehr<br />
ausführlich über alles,<br />
was mit dem Stallbau<br />
zusammen hängt.<br />
Ich stehe voll auf der<br />
Seite der Landwirte.<br />
Die Gründung eines<br />
Vereins gegen den<br />
Schweinestall finde ich<br />
übertrieben.<br />
Stimme<br />
voll<br />
<strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils,<br />
teils<br />
Lehne<br />
eher ab<br />
Lehne<br />
ab<br />
Lehne<br />
voll<br />
<strong>und</strong><br />
ganz ab<br />
8. Wenn Sie an die Argumente der Landwirte <strong>und</strong> des Vereins „Natürlich<br />
Diemarden“ denken, wen halten Sie für glaubwürdig? Verteilen Sie bitte<br />
100 Punkte <strong>und</strong> geben Sie der glaubwürdigsten Partei die höchste<br />
Punktzahl.<br />
100<br />
Landwirte<br />
Natürlich Diemarden<br />
Summe 100<br />
153
Anhang<br />
9. Im Göttinger Tageblatt wurde <strong>von</strong> Seiten der Ablehner z. B. die<br />
Tierhaltung bemängelt. Wir haben zu verschiedenen Themenbereichen<br />
Aussagen gesammelt, zu denen man wiederum unterschiedlicher<br />
Meinung sein kann. Bitte beurteilen Sie die Aussagen anhand dieser<br />
Skala:<br />
Die Gülle belastet die<br />
Umwelt in unserer<br />
Umgebung.<br />
Von Massentierhaltung<br />
kann bei 660 Schweinen<br />
nicht geredet werden.<br />
Die gesetzlichen<br />
Anforderungen an die<br />
Schweinehaltung sind<br />
insgesamt zu niedrig.<br />
Wenn die Tiere auf Stroh<br />
stehen würden, hätte ich<br />
gegen den Stall nichts<br />
einzuwenden.<br />
Stimme<br />
voll<br />
<strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils,<br />
teils<br />
Lehne<br />
eher ab<br />
Lehne<br />
ab<br />
Lehne<br />
voll<br />
<strong>und</strong><br />
ganz ab<br />
10. Wenn Sie jetzt mal weg <strong>von</strong> Diemarden gehen <strong>und</strong> die gesamte<br />
gesellschaftliche Entwicklung betrachten, wie bewerten Sie dann<br />
folgende Aussagen?<br />
Für das Allgemeinwohl<br />
ist niemand mehr bereit,<br />
auf etwas zu verzichten.<br />
Bei jedem größeren<br />
Bauvorhaben muss man<br />
in Deutschland<br />
inzwischen mit einer<br />
Bürgerinitiative rechnen.<br />
Dass die Landwirte<br />
einfach einen Stall bauen<br />
können, finde ich nicht<br />
akzeptabel.<br />
Als Bürger muss man<br />
sich schon einiges<br />
gefallen lassen.<br />
Eigentlich müssten die<br />
Bürger immer vor<br />
Beginn eines größeren<br />
Bauvorhabens informiert<br />
werden.<br />
Stimme<br />
voll<br />
<strong>und</strong><br />
ganz zu<br />
Stimme<br />
zu<br />
Stimme<br />
eher zu<br />
Teils,<br />
teils<br />
Lehne<br />
eher ab<br />
Lehne<br />
ab<br />
Lehne<br />
voll<br />
<strong>und</strong><br />
ganz ab<br />
154
Anhang<br />
11. Sind Sie in Vereinen in Diemarden aktiv?<br />
□ Nein<br />
□ Ja, ich bin Mitglied im<br />
□ Schützenverein<br />
□ Heimatverein<br />
□ Sportverein<br />
□ Schulförderverein<br />
□ „Natürlich Diemarden“<br />
□ Sonstigen_________________________________<br />
12. Können Sie sich in eine der drei Bewohnergruppen in Diemarden<br />
einordnen?<br />
□ Gebürtige/r DiemardenerIn<br />
□ Zugezogene/r DiemardenerIn<br />
□ Eingeheiratete/r DiemardenerIn<br />
□ Sonstige________________________________________<br />
13. Seit wann wohnen Sie in Diemarden?<br />
_______________________________________________<br />
14. Können Sie kurz sagen, warum Sie in Diemarden leben?<br />
(Mehrfachantworten möglich)<br />
□ Ich bin hier geboren<br />
□ Meine Frau / mein Mann lebt hier<br />
□ Zufall bzw. es hat sich so ergeben<br />
□ Günstiges Bauland<br />
□ Ruhige Lage<br />
□ Nähe zum Arbeitsplatz<br />
□ Weil ich mich hier wohlfühle<br />
□ Vielzahl <strong>von</strong> Freizeitmöglichkeiten<br />
□ Schönheit der Landschaft<br />
□ Anderes, nämlich_________________________________________<br />
15. Stellen Sie sich vor, es gäbe eine Dorfabstimmung über den Stallbau in<br />
Diemarden, wie würden Sie entscheiden?<br />
Ja, ich<br />
stimme<br />
auf<br />
jeden<br />
Fall<br />
dafür<br />
Ja, ich<br />
stimme<br />
dafür.<br />
Ja, ich<br />
würde<br />
eher<br />
dafür<br />
stimmen.<br />
Ich bin<br />
unentschlossen<br />
<strong>und</strong> würde<br />
mich<br />
enthalten.<br />
Nein, ich<br />
würde<br />
eher<br />
dagegen<br />
stimmen.<br />
Nein, ich<br />
würde<br />
dagegen<br />
stimmen.<br />
Nein, ich<br />
stimme<br />
auf jeden<br />
Fall<br />
dagegen<br />
155
Anhang<br />
Zum Ende des Fragebogens würde ich gerne noch ein paar allgemeine Angaben zu<br />
Ihrer Person notieren.<br />
16. In welchem Jahr sind Sie geboren?<br />
_________________________________<br />
17. Was ist Ihr höchster Bildungsabschluss?<br />
(noch) keinen Abschluss □ Fachhochschule □<br />
Hauptschule/Volksschule □ Universität □<br />
Realschule □ Promotion □<br />
Gymnasium □ Sonstige □<br />
18. Zu welcher Berufsgruppe gehören Sie?<br />
Schüler/in □ Arbeiter/in □<br />
Student/in □ z.Zt. ohne Beschäftigung □<br />
Angestellte/r □ Rentner/Pensionär/in □<br />
Selbständige/r □ Hausfrau/-mann □<br />
Beamtin/er □ B<strong>und</strong>eswehr/Zivildienst □<br />
Auszubildender/r □ Sonstiges □<br />
19. Wie ist Ihr Familienstand?<br />
Ledig □ Lebensgemeinschaft □<br />
Verheiratet □ Getrennt lebend □<br />
Geschieden □ Andere □<br />
□<br />
verwitwet<br />
20. Wie viele Personen leben in Ihrem Haushalt (Sie eingeschlossen)?<br />
1 □ 4 □<br />
2 □ 5 □<br />
3 □ 6 <strong>und</strong> mehr □<br />
21. Zählen Landwirte zu Ihrem engeren Familien- oder Fre<strong>und</strong>eskreis?<br />
Ja □ Nein □<br />
156
Anhang<br />
22. Sind Sie.....<br />
Mieter □ Eigentümer □<br />
□<br />
Sonstiges<br />
Vielen Dank für Ihre Teilnahme!<br />
Bitte vom Interviewer ausfüllen<br />
Geschlecht:<br />
□ Männlich<br />
□ Weiblich<br />
Uhrzeit beim Interviewende<br />
Straße<br />
F. Fragebogen der Fallstudie 2<br />
1. How often do you buy food product at the following locations?<br />
I buy food in<br />
Every<br />
day<br />
More<br />
than<br />
once a<br />
week<br />
Once a<br />
week<br />
1-3<br />
times a<br />
month<br />
Never<br />
Traditional markets/wet markets<br />
Chinese Supermarkets (Hualian etc.)<br />
Small retailers in the neighborhood<br />
Convenience stores (opened 24h)<br />
Foreign Supermarkets (Carrefour etc.)<br />
Chinese department stores<br />
Foreign department stores<br />
157
Anhang<br />
2.<br />
Approximately, how many percentages of your food expenditures do you<br />
spend in which store? Please note the respective percentages.<br />
Store type<br />
Percentage<br />
Traditional markets/wet markets<br />
Chinese Supermarkets (Hualian etc.)<br />
Small retailers in the neighborhood<br />
Convenience stores (opened 24h)<br />
Foreign Supermarkets (Carrefour etc.)<br />
Chinese department stores<br />
Foreign department stores<br />
Sum 100 %<br />
3. Do you sometimes buy milk?<br />
Every day<br />
More than once a<br />
week<br />
Once a week 1-3 times a month Never<br />
If „no“ proceed with question 5.<br />
4. a) Do you know any brands in the milk / dairy market?<br />
1.<br />
2.<br />
3.<br />
4. b)<br />
Which of these brands do you know? (Please mark the brands you know with<br />
“X”)<br />
1.<br />
2.<br />
3.<br />
5. Please take a look at the following pictures. Each showing a different product<br />
with different attributes. Please choose the product you prefer most and mark it<br />
with ”1” then go on and choose the next best in your opinion marking it with<br />
”2”. Please continue until you have arranged all products from the one you like<br />
best (”1”) to the one you like least (”10”).<br />
158
Anhang<br />
6.<br />
When buying products… (Please mark on the following scale whether you<br />
agree or disagree.)<br />
Statement<br />
…I am willing to pay a premium for my favorite<br />
brand.<br />
…I will shop first at retail stores that make a<br />
special effort to sell foreign brands.<br />
…I prefer to buy foreign brands if I want to<br />
give the product away as a gift.<br />
…even though certain products are available<br />
in a number of different brands, I always tend<br />
to buy the Chinese brand.<br />
…I am willing to take time to look on the labels<br />
so I know where the products I purchase are<br />
produced.<br />
…I choose foreign brands because they are<br />
cool and have really funny and crazy ads.<br />
…when I invite friends, I try to offer foreign<br />
brands.<br />
…it is more important to know whether the<br />
product I buy was made in China than what<br />
brand it is.<br />
…I always choose well known brands because<br />
they are of higher quality.<br />
…sometimes I get confused because there<br />
are so many different brands.<br />
Strongly<br />
agree<br />
agree<br />
neut<br />
ral<br />
disagree<br />
Strongly<br />
disagree<br />
…I am focused on buying low priced products.<br />
7. a)<br />
Separate from foodstuffs, please think about purchasing a refrigerator. Do you<br />
know any brands?<br />
1.<br />
2.<br />
3.<br />
7. b)<br />
Which of these brands do you know? (Please mark the brands you know)th<br />
“X”)<br />
1. Bosch-Siemens<br />
2. Whirlpool<br />
3. Haier<br />
4. Kelon<br />
5. TCL<br />
6. Samsung<br />
7. Toschiba<br />
8. LG<br />
9. Wanbao<br />
159
Anhang<br />
8. Please take a look at the following pictures. Each showing a different<br />
refrigerator with different attributes and prices. Please choose the product you<br />
prefer most and mark it with ”1” then go on and choose the next best in your<br />
opinion marking it with ”2”. Please continue until you have arranged all<br />
products from the one you like best (”1”) to the one you like least (”10”).<br />
9. During the last years, the first foreign retailers like Carrefour, Metro or Wal Mart<br />
have entered the Chinese Market. If you have the opportunity to buy your food<br />
in such a foreign supermarket, compared with a Chinese supermarket, which<br />
one would you prefer?<br />
Strongly prefer<br />
the foreign<br />
supermarket<br />
Prefer the<br />
foreign<br />
supermarket<br />
Neutral<br />
Prefer the<br />
Chinese<br />
supermarket<br />
Strongly prefer<br />
the Chinese<br />
supermarket<br />
10.<br />
Before purchasing a product it is important to know…<br />
(Please mark on the following scale whether you agree or disagree.)<br />
Statement<br />
Strongly<br />
agree<br />
agree neutral disagree<br />
Strongly<br />
disagree<br />
…whether any brands are available.<br />
…the name of the company that<br />
makes the product.<br />
…the country of origin different brands<br />
are produced in.<br />
…the level of quality of the different<br />
brands.<br />
11.<br />
It is important to buy Chinese brands …<br />
(Please mark on the following scale whether you agree or disagree.)<br />
Statement<br />
…because I trust Chinese brands more<br />
than foreign brands.<br />
…Chinese products have a higher level<br />
of quality than products from abroad.<br />
…because this will generate jobs in<br />
China.<br />
Strongly<br />
agree<br />
agree<br />
neutral<br />
disagre<br />
e<br />
Strongly<br />
disagre<br />
e<br />
…because I love my home country<br />
…to support the national industry.<br />
160
Anhang<br />
12.<br />
When thinking of Chinese brands, do you think they are …<br />
(Please mark your opinion on the following scale by placing an ”X” in the<br />
respective box)<br />
of high quality<br />
Cutting-edge<br />
frumpy<br />
of high prestige<br />
likable<br />
expensive<br />
innovative<br />
of low quality<br />
boring<br />
hip<br />
of low prestige<br />
dislikable<br />
cheap<br />
old fashioned<br />
13.<br />
When thinking of foreign brands, do you think they are...<br />
(Please mark your opinion on the following scale by placing an ”X” in the<br />
respective box)<br />
of high quality<br />
Cutting-edge<br />
frumpy<br />
of high prestige<br />
likable<br />
expensive<br />
innovative<br />
of low quality<br />
boring<br />
hip<br />
of low prestige<br />
dislikable<br />
cheap<br />
old fashioned<br />
14.<br />
When you think of buying food, which is your opinion?<br />
(Please mark on the following scale whether you agree or disagree.)<br />
Statement<br />
Strongly<br />
agree<br />
agree<br />
neutral<br />
disagre<br />
e<br />
Strongly<br />
disagre<br />
e<br />
Foreign retailers are too expensive<br />
Chinese supermarkets have more fresh<br />
products.<br />
My friends all prefer Chinese<br />
supermarkets<br />
I prefer food stores which are nearby<br />
Foreign stores do not really know what<br />
Chinese people like<br />
Foreign retailers have a broader<br />
assortment<br />
161
Anhang<br />
15.<br />
When thinking of Chinese Supermarkets, do you think they are …<br />
(Please mark your opinion on the following scale by placing an ”X” in the<br />
respective box)<br />
of high quality<br />
Cutting-edge<br />
frumpy<br />
of high prestige<br />
likable<br />
expensive<br />
clean<br />
kind<br />
often lots of articles<br />
on sale<br />
innovative<br />
of low quality<br />
boring<br />
hip<br />
of low prestige<br />
dislikable<br />
cheap<br />
dirty<br />
unkind<br />
never any articles<br />
on sale<br />
old fashioned<br />
16.<br />
When thinking of foreign Supermarkets, do you think they are...<br />
(Please mark your opinion on the following scale by placing an ”X” in the<br />
respective box)<br />
Of high quality<br />
Cutting-edge<br />
frumpy<br />
of high prestige<br />
likable<br />
expensive<br />
clean<br />
kind<br />
often lots of articles<br />
on sale<br />
innovative<br />
of low quality<br />
boring<br />
hip<br />
of low prestige<br />
dislikable<br />
cheap<br />
dirty<br />
unkind<br />
never any articles<br />
on sale<br />
old fashioned<br />
Lastly we would like to ask some personal questions, helping us to analyze the<br />
questionnaire.<br />
17.<br />
In my household, generally who is the one who buys the food?<br />
(Please choose only one and mark it with an ”X”)<br />
Regular, I buy food<br />
products<br />
Regularly, anyone else<br />
buy food products<br />
Sometimes I buy food,<br />
sometimes some else<br />
162
Anhang<br />
18.<br />
How many persons live in your household?<br />
(Please choose only one and mark it with an ”X”)<br />
I live alone.<br />
I live in a flat-sharing community<br />
I live with my parents.<br />
I live with my mate / no child<br />
I live with my mate / with child<br />
I live with my mate / child is living on his /<br />
her own now<br />
19.<br />
What is your year of birth?<br />
(Please just write down the year of birth.)<br />
Year of birth<br />
20. Gender<br />
Male<br />
Female<br />
21.<br />
Where are you occupied?<br />
(Please choose only one and mark with an ”X”)<br />
Stated owned enterprise<br />
Privately owned enterprise<br />
Self-employed<br />
Civil servant<br />
Military<br />
Student/pupil<br />
Unemployed<br />
163
Anhang<br />
22.<br />
What is your highest graduation?<br />
(Please choose only one and mark with an ”X”)<br />
Junior Secondary School<br />
Senior Secondary School<br />
High School<br />
Junior College<br />
BA<br />
MA<br />
Foreign University<br />
None<br />
23.<br />
What is the overall income of your household?<br />
(Please choose only one and mark with an ”X”)<br />
< 500<br />
501-1000<br />
1001-1500<br />
1501-2000<br />
2501-3000<br />
3001-3500<br />
3501-4000<br />
4001-4500<br />
4501-5000<br />
5001-5500<br />
5501-6000<br />
>6000<br />
No response<br />
164
Eidesstattliche Erklärung<br />
Eidesstattliche Erklärung<br />
Hiermit versichere ich, die vorliegende Arbeit selbständig verfasst zu haben <strong>und</strong> keine<br />
anderen als die angegebenen Quellen <strong>und</strong> Hilfsmittel benutzt zu haben.<br />
Datum: Göttingen, den 31.03.2005<br />
Unterschrift:<br />
165