

Psychologische Diagnostik II - Universität Regensburg
Psychologische Diagnostik II - Universität Regensburg
Psychologische Diagnostik II - Universität Regensburg

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
<strong>Psychologische</strong> <strong>Diagnostik</strong> , latent trait Theorie<br />
WS 2010/11<br />
Prof. Dr. Jan Drösler<br />
Universität <strong>Regensburg</strong><br />
Das diagnostische Gespräch<br />
Hell u. a. (2007) haben knapp 4000 Validitätsuntersuchungen,<br />
die seit 1980 berichtet worden<br />
sind, ausgewertet. Es ergab sich (nach rechnerischer<br />
Schönung der Daten wegen mangelnder<br />
Reliabilität des jeweiligen Kriteriums) eine<br />
mittlere Validität von rho = 0.12<br />
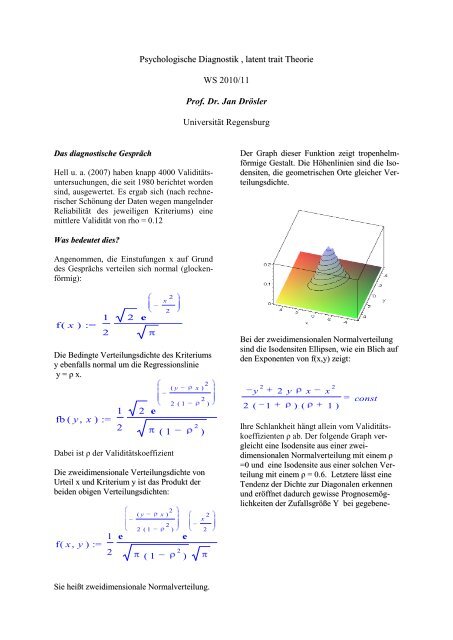
Der Graph dieser Funktion zeigt tropenhelmförmige<br />
Gestalt. Die Höhenlinien sind die Isodensiten,<br />
die geometrischen Orte gleicher Verteilungsdichte.<br />
Was bedeutet dies?<br />
Angenommen, die Einstufungen x auf Grund<br />
des Gesprächs verteilen sich normal (glockenförmig):<br />
x 2<br />
f( x )<br />
Die Bedingte Verteilungsdichte des Kriteriums<br />
y ebenfalls normal um die Regressionslinie<br />
y = ρ x.<br />
Dabei ist ρ der Validitätskoeffizient<br />
Die zweidimensionale Verteilungsdichte von<br />
Urteil x und Kriterium y ist das Produkt der<br />
beiden obigen Verteilungsdichten:<br />
f ( x,<br />
y )<br />
:=<br />
fb ( y,<br />
x )<br />
:=<br />
1<br />
2<br />
:=<br />
1<br />
2<br />
1<br />
2<br />
e<br />
2 e<br />
2 e<br />
2<br />
( y x )<br />
2<br />
2<br />
2 ( 1 )<br />
e<br />
2<br />
( 1 )<br />
( y x )<br />
2<br />
2<br />
2 ( 1 )<br />
2<br />
( 1 )<br />
x 2<br />
2<br />
Bei der zweidimensionalen Normalverteilung<br />
sind die Isodensiten Ellipsen, wie ein Blich auf<br />
den Exponenten von f(x,y) zeigt:<br />
Ihre Schlankheit hängt allein vom Validitätskoeffizienten<br />
ρ ab. Der folgende Graph vergleicht<br />
eine Isodensite aus einer zweidimensionalen<br />
Normalverteilung mit einem ρ<br />
=0 und eine Isodensite aus einer solchen Verteilung<br />
mit einem ρ = 0.6. Letztere lässt eine<br />
Tendenz der Dichte zur Diagonalen erkennen<br />
und eröffnet dadurch gewisse Prognosemöglichkeiten<br />
der Zufallsgröße Y bei gegebeney<br />
2 2 y x x 2<br />
2 ( 1 ) ( 1 )<br />
const<br />
Sie heißt zweidimensionale Normalverteilung.
nem Y = x.<br />
Ein entsprechender Vergleich mit Validitäten ρ<br />
= 0 und ρ = 0.1 (der Validität des freien Untersuchungsgesprächs)<br />
lässt jede Prognosemöglichkeit<br />
praktisch verschwinden:<br />
Daraus ergibt sich für die Psychologie das<br />
Gebot, freie Untersuchungsgespräche zu unterlassen<br />
und statt dessen jede <strong>Diagnostik</strong> zu objektivieren.<br />
Das kann beispielsweise durch die<br />
Verwendung von Tests geschehen, in denen<br />
der zu untersuchende Proband Punktwerte<br />
erzielen kann. Das Grundproblem jeder auf<br />
diese Weise objektivierten <strong>Diagnostik</strong> lautet:<br />
Was bedeutet es, Punktwerte zu addieren?<br />
Die Theorie der <strong>Diagnostik</strong><br />
stellt, Objektivität und Reproduzierbarkeit<br />
der Befunde sicher. Definition eines Entscheidungsraums.(Befund<br />
„wofür“). Sie<br />
definiert Validität der Befunde im Hinblick<br />
auf ein Kriterium (Punktwert bedeutet das<br />
und das). Wenn also eine Universität vom<br />
Bertelsmann-Intitut CHE einen höheren<br />
Rangplatz auf Grund einer höheren Punktzahl<br />
bekommt, so müßte damit irgendeine<br />
Bedeutung verbunden sein, die eine Universität<br />
auszeichen könnte. Infrage käme,<br />
daß etwa ihre Absolventen mehr verdienen,<br />
seltener arbeitslos sind oder umfangreichere<br />
Fachkenntnisse besitzen als die<br />
Absolventen anderer Universitäten. Das ist<br />
aber ebenso wenig der Fall wie der Nachweis<br />
irgend einer anderen nennenswerten<br />
Bedeutung. Die von der Illustrierten Stern<br />
verbreiteten Punkwerte sind bedeutungslos.<br />
Ihre Sinnlosigkeit läuft auf eine Desinformation<br />
der öffentlichkeit hinaus.<br />
Grundsätzlich stehen drei Wege offen, die<br />
Äquivalenz von Versuchspersonen mit<br />
gleicher Punktzahl zu untersuchen. Der<br />
einfachste Weg ist die Korrelation der<br />
Punktwerte mit einem nahe liegenden Außenkriterium.<br />
Diesen Weg geht die klassische<br />
Testtheorie. Ein zweiter Weg besteht<br />
in der Untersuchung der empirischen<br />
Struktur und deren Vergleich mit den Bestimmungsstücken<br />
einer Zahlenstruktur.<br />
Diesen Weg geht die repräsentative Meßtheorie.<br />
Ein dritter Weg ist der statistische.<br />
Es wird untersucht, ob beispielsweise die<br />
Punktsummen erschöpfend über einen dahinterliegenden<br />
latent trait Auskunft geben.<br />
Dieser Weg wird din dieser Vorlesung<br />
im Einzelnen beschritten.<br />
Optimalität<br />
Den Befunden soll die Bedeutung nicht<br />
beliebig sondern in optimaler Weise zugeordnet<br />
werden. Das setzt einen Bewertungsmaßstab<br />
sowie außerdem ein Optimalitätskriterium<br />
voraus. Voraus-setzung für<br />
deren Erstellung ist die Objektivität der<br />
Befunde. Sie ist wie folgt definiert: Die<br />
Wahrscheinlichkeit des Auftretens eines<br />
Befundes hängt nicht vom Untersucher ab.<br />
Für die Erhebung jedes Befundes muß<br />
schon aus diesem Grunde ein Wahrscheinlichkeitsraum<br />
definiert sein:<br />
< , , ><br />
Dabei ist die Ergebnismenge, z. B.<br />
{Aufgabe gelöst, nicht gelöst}.die Ereignismenge,<br />
z. B.{ Aufgabe gelöst oder<br />
nicht gelöst, Aufgabe gelöst, nicht gelöst,
Aufgabe gelöst und nicht gelöst}, das<br />
Wahrscheinlichkeitsmaß (nicht-negativ,<br />
normiert, additiv) auf der Ereignismenge.<br />
Der Entscheidungsraum<br />
Nach diesen Vorüberlegungen lässt sich<br />
die Validitätsfrage systematisch untersuchen.<br />
Befunde x werden, wie gesagt, nicht<br />
isoliert betrachtet. Sie sollen Indikatoren<br />
für etwas anderes sein, das Kriterium . In<br />
einem wissenschaftlichen Kontext ist diese<br />
Beziehung empirisch nachzuweisen: Die<br />
Frage lautet:<br />
P( x | ) = P( x ) ?<br />
Erst wenn diese Frage verneint werden<br />
kann, geht es um die Findung einer Diagnose<br />
(als einer optimalen Entscheidung).<br />
Optimalität der Entscheidung<br />
Optimalität verlangt zweierlei: einen Kostenmaßstab<br />
und ein Optimalitätskriterium.<br />
Im vorliegenden Zusammenhang wird der<br />
Erwartungswert der quadrierten Größe der<br />
Abweichungen vom Kriterium als Maßstab<br />
benutzt. Als Optimalitätskriterium<br />
dient die maximale Likelihood.<br />
Likelihood<br />
Folgen die Daten X einer diskreten Zufallsverteilung,<br />
dann ist pk die Wahrscheinlichkeit<br />
für das Eintreffen von<br />
X = xk, k = 1,2,3 ..., n, und , unbekannte<br />
Parameter. Hier ist<br />
L = p1( , ) p2( , ) p3( , )... pn( , )<br />
die Likelihood. Diese Produktbildung setzt<br />
voraus, daß die einzelnen diagnostischen<br />
Ereignisse pk voneinander stochastisch<br />
unabhängig sind. Andernfalls wäre die<br />
Likelihood viel komplizierter zu formulieren.<br />
Für die psychologische <strong>Diagnostik</strong><br />
bedeutet dies beispielsweise, daß die Versuchsperson<br />
aus den früheren diagnostischen<br />
Zugriffen nicht in der Weise lernen<br />
darf, daß es ihr späteres Verhalten in der<br />
gleichen Untersuchung verändern würde.<br />
Für kontinuierlich zufallsverteilte Daten ist<br />
die Likelihood entsprechend als das Produkt<br />
der Dichten für die einzelnen Ergebnisse<br />
definiert und deshalb keine Wahrscheinlichkeit.<br />
Maximum Likelihood<br />
Funktionen kann man, wie in der 11.<br />
Gymnasialklasse unterrichtet wird, durch<br />
Ableiten und Nullsetzen der Ableitung<br />
optimieren. Das setzt voraus, daß man die<br />
Wahrscheinlichkeit für das Auftreten der<br />
Daten explizit formuliert hat, also eine<br />
Theorie für die Entstehung der Daten besitzt.<br />
Ein Beispiel für eine solche diagnostische<br />
Theorie ist das Rasch-Modell.<br />
Das Rasch-Modell<br />
Sei U = 0,1 eine Zufallgröße, und , <br />
Parameter, i der Personenindex, j der Aufgabenindex,<br />
dann ist die Lösungswahrscheinlichkeit<br />
PU ( 1 | , )<br />
i.<br />
j i j<br />
exp( )<br />
1 exp( )<br />
Die Lösungswahrscheinlichkeit einer Aufgabe<br />
hangt entsprechend der logistischen<br />
Funktion von der Differenz von Personenfähigkeit<br />
und Aufgabenschwierigkeit ab.<br />
Sind beide gleich, so ist das Argument der<br />
Funktion gleich null und der Funktionswert<br />
gleic ½. Der Fähigkeitswert, bei dem dieser<br />
Funktionswert auftritt, ist der Zahlenwert<br />
der Aufgabenschwierigkeit.<br />
i<br />
i<br />
j<br />
j
Die Aufgebencharakteristik<br />
Die Likelihood-Funktion<br />
Sei U = 0,1 eine Zufallgröße, und , <br />
Parameter, i der Personenindex, j der Aufgabenindex,<br />
dann ist die Wahrscheinlichkeit<br />
als Likelihood-Funktion für eine Aufgabe<br />
und eine Person zum Rasch-Modell<br />
gegeben.<br />
P ( U u | , )<br />
i. j i , j i j<br />
exp[ u ( )]<br />
i , j i j<br />
1 exp( )<br />
Die Versuchsperson als Zufallgenerator<br />
i<br />
j<br />
Die Aufgaben-Charakteristik verläuft als<br />
logistische Funktion von (θ- ) ogivenförmig.<br />
Andere Ogiven<br />
Die Formel des Rasch-Modells legt in Abhängigkeit<br />
von Personenfähigkeit und<br />
Aufgabenschwierigkeit eine Wahrscheinlichkeit<br />
fest, mit der richtige bzw.<br />
falsche Lösungen produziert werden. Diese<br />
werden als Einsen bzw. Nullen kodiert.<br />
Bei gegebener Aufgabe wird die Wahrscheinlichkeit,<br />
bei einer Vp. mit großer<br />
Fähigkeit hoch sein, aber nicht den Wert<br />
Eins annehmen.<br />
Aufgabe des <strong>Diagnostik</strong>ers<br />
Die Aufgabe des <strong>Diagnostik</strong>ers besteht<br />
darin, aus den zufälligen Nullen und Einsen,<br />
dem Antwortmuster, die Werte von <br />
und zu erschließen und Angaben über<br />
die Genauigkeit dieses Verfahrens zu liefern.<br />
Dazu stehen ihm die Hilfsmittel der<br />
Statistik zur Verfügung.<br />
Die Summenstatistik<br />
Andere Beschreibungen der Itemcharakteristikmittels<br />
arctan(θ-ε), tanh(θ-ε) oder die<br />
kumul. Normalverteilung sind graphisch<br />
nicht von der (in der Abszisse mit Faktor<br />
1.43 gedehnten)logistischen Funktion zu<br />
unterscheiden. Sie besitzen aber nicht die<br />
noch zu beschreibenden Eigenschaften, die<br />
die logistische Funktion als Theorie für die<br />
psychologische <strong>Diagnostik</strong> so interessant<br />
machen.<br />
Funktionen von Daten heißen Statistiken.<br />
Eine besonders in der Psychologie beliebte<br />
Statistik ist die Summe richtiger Antworten.<br />
Ihr gegenüber besitzt das Fach eine<br />
merkwürdige Ambivalenz. Einerseits sind<br />
Psychologen oft skeptisch, ob ein eindimensionales<br />
Symptom sinnvoll sei. Andererseits<br />
summieren auch sie, wie eingangs<br />
erörtert, nicht selten bedenkenlos Unvergleichliches.<br />
Deshalb müssen die Eigenschaften<br />
von Statistiken, auch der Summenstatistik<br />
analysiert werden.
Bedingte Wahrscheinlichkeit<br />
Für jede bedingte Wahrscheinlichkeit gilt:<br />
P ( u | s)<br />
i,<br />
j<br />
P ( u , s)<br />
i,<br />
j<br />
P( s)<br />
und deshalb auch unter der zusätzlichen<br />
Bedingung<br />
P ( u | s, )<br />
i,<br />
j<br />
P ( u , s | )<br />
i,<br />
j<br />
P( s | )<br />
Erschöpfungseigenschaft<br />
der Statistik beschreibt faktorisieren, dann<br />
ist bei gegebener Statistik die Auftretenswahrscheinlichkeit<br />
der Daten ebenso durch<br />
die Statistik allein bestimmt, wie in Abwesenheit<br />
der Erschöpfungseigenschaft nur<br />
durch die Daten.<br />
Erschöpfungseigenschaft der Summenstatistik<br />
im Rasch-Modell als Lehrsatz formuliert<br />
Wegen der hervorragenden Bedeutung der<br />
Erschöpfungseigenschaft für jede Skalierung<br />
überhaupt wird sie hier noch einmal nach dem<br />
Euklidschen Schema von Voraussetzung, Behauptung,<br />
Beweis formuliert:<br />
Voraussetzungen:<br />
Dieses Attribut von Parameterschätzungen<br />
ist definiert als<br />
P ( u | s, ) P ( u | s )<br />
i , j<br />
i , j<br />
Es verlangt, daß bei gegebener Statistik die<br />
Daten stochastisch unabhängig von sind.<br />
1. das Rasch-Modell<br />
P 0 u i, j<br />
= 1, q i<br />
, 3 j 1 =<br />
2. Die Summenstatistik:<br />
n<br />
s i<br />
=<br />
j<br />
> u i,<br />
= 1<br />
e 0 q i K 3 j1<br />
1 C e 0 q i K 3 j1<br />
Faktorisierungsbedingung<br />
Manchmal ordnet man die sich unter der<br />
Erschöpfungseigenschaft ergebende Formel<br />
anders:<br />
P ( u | ) P ( s | ) P ( u | s )<br />
i , j<br />
i , j<br />
und spricht von einer Faktorisierungsbedingung<br />
der Likelihood. Dabei ist für die<br />
Verbundwahrscheinlichkeit von uij und s<br />
die Wahrscheinlichkeit von uij allein eingesetzt,<br />
weil mit der Kenntnis von uij und<br />
der Berechnungsvorschrift für die Statistik,<br />
die Summenbildung, s gegeben ist.<br />
Bedeutung dieser Bedingung<br />
Läßt sich die Likelihood der Daten in einen<br />
Faktor, der die Wahrscheinlichkeit des<br />
Auftretens des Wertes der Statistik und<br />
einen Faktor, der die Wahrscheinlichkeit<br />
der Daten in alleiniger Abhängigkeit von<br />
3. Die Erschöpfungseigenschaft:<br />
L ( U, s, q ) = L ( U, s )<br />
Behauptung<br />
Satz: Die Summenstatistik im Raschmodell<br />
besitzt die Erschöpfungseigenschaft.<br />
Beweis<br />
Die Likelihood-Funktion für eine Aufgabe und<br />
eine Versuchsperson lautet:<br />
q1 := L ( u, q, 3 ) = e 0 u i, j 0 q i K 3 j1 1<br />
Die Likelihood für eine Person und n Aufgaben<br />
(Das ? bedeutet ε) :<br />
n<br />
e 0 u i, j 0 q i K 3 j1 1<br />
q2 := L ( U, q, ? ) = ?<br />
j = 1<br />
Wegen der Rechenregeln für Exponenten läßt<br />
sich q2 schreiben als:<br />
æ<br />
ç<br />
ç<br />
è<br />
1 C e 0 q i K 3 j1<br />
1 C e 0 q i K 3 j1<br />
ö<br />
÷<br />
ø
q3 := L ( U , q, ? ) = e æ<br />
Summierung ist ein linearer Operator und läßt<br />
sich deshalb in die Klammer „hineinmultiplizieren"<br />
q4 := L ( U , q,<br />
æ æ<br />
ç<br />
ç q ç<br />
i ç<br />
? ) = e è è<br />
n<br />
><br />
j = 1<br />
Die Summe von Einsen und Nullen ist gleich<br />
der Summe der vorgekommenen Einsen, also<br />
der Summe richtig gelöster Aufgaben der<br />
Person i :<br />
q5 := L ( U , q, ? ) =<br />
u i, j ö<br />
÷<br />
÷<br />
ø<br />
Man sieht, daß diese Likelihood faktorisierbar<br />
ist in einen Ausdruck, der nur von der Statistik<br />
aber nicht mehr von den Daten abhängt, und<br />
einen der von den Daten aber nicht mehr von<br />
abhängt. Die Erschöpfungseigenschaft der<br />
Statistik ist damit bewiesen.<br />
ç<br />
ç<br />
è<br />
n ö<br />
K > u 3 ÷<br />
i, j j ÷<br />
j = 1 ø<br />
n<br />
?<br />
0 0 q i K 3 j1 1 C e 1<br />
j = 1<br />
æ<br />
ç<br />
ç<br />
e è<br />
n<br />
> u i, j 0 q i K 3 j1<br />
j = 1<br />
n<br />
q s K i i ><br />
j = 1<br />
ö<br />
÷<br />
÷<br />
ø<br />
n<br />
?<br />
0 0 q i K 3 j1 1 C e 1<br />
j = 1<br />
u i, j 3 j ö<br />
÷<br />
÷<br />
ø<br />
n<br />
?<br />
0 0 q i K 3 j1 1 C e 1<br />
j = 1<br />
relative Häufigkeiten von null oder eins auftreten,<br />
für die keine logits existieren, und dann in<br />
logits log (p/(1-p)) umgewandelt. Da logits die<br />
Umkehrfunktion des Modells darstellen, bedeuten<br />
die Eintragungen nun θ – ε :<br />
0.405 -0.847 -1.73 -2.20 -3.66<br />
1.39 0.100 -1.39 -2.51 -2.20<br />
2.51 1.10 -0.100 -1.24 -2.94<br />
2.94 1.95 1.24 0.405 -0.969<br />
3.66 3.66 1.73 1.55 0.511<br />
Wegen der fehlenden Eindeutigkeit der Skalierung<br />
kann man nun den<br />
Ursprung für beide willkürlich ansetzen und<br />
die Größe der Niveaus in beiden Variablen aus<br />
den mittleren Differenzen bestimmen.<br />
Kleinere Stichproben<br />
Hat man z. B. nur 15 Vpn. untersucht, dann<br />
ergeben sich Häufigkeiten wie<br />
diese:<br />
1 0 0 0 0<br />
2 2 2 0 0<br />
2 2 1 0 0<br />
3 3 3 0 1<br />
3 3 3 3 2<br />
Da die Randsummen ebenfalls die Erschöpfungseigenschaft<br />
besitzen, kann man sie in<br />
relative Häufigkeiten, umrechnen und auswerten:<br />
Auswertungsbeispiel<br />
Auf Grund der Erschöpfungseigenschaft der<br />
Summenstatistik lassen sich beispielsweise<br />
200 Vpn. in fünf gleichgroße Gruppen nach<br />
der erreichten Gesamtpunktzahl zusammenfassen.<br />
Entsprechendes geschieht für die Aufgaben<br />
(Spalten):<br />
24 12 6 4 1<br />
32 21 8 3 4<br />
37 30 19 9 2<br />
38 35 31 24 11<br />
39 39 34 33 25<br />
Diese Lösungshäufigkeiten werden zunächst in<br />
relative Häufigkeiten. Dies ist nur bei größen<br />
Versuchspersonenzahlen möglich, da sonst<br />
Randsummenauswertung<br />
1<br />
6<br />
5<br />
10<br />
14<br />
Die logits der Randsummen existieren, solange<br />
keine Nullen oder Einsen als relative Häufigkeiten<br />
auftreten.
-2.64<br />
-0.405<br />
-0.693<br />
0.693<br />
2.64<br />
Sie werden als Differenzen der verschiedenen<br />
θ zu einem mittleren ε aufgefaßt und unter<br />
Benutzung der freien Ursprungswahl zahlenmäßig<br />
bestimmt. Entsprechendes wiederholt<br />
man für die Spaltensummen und die Ausprägungen<br />
der ε.<br />
Was bedeutet ?<br />
Die Bedeutung von wird durch Bildung<br />
der Umkehrfunktion der Rasch-Modells<br />
deutlich:<br />
Die logarithmierte Wettchance ist gleich<br />
der Parameterdifferenz. Alle weitergehende<br />
Bedeutung liegt in den Aufgaben selbst.<br />
Spezifische Objektivität<br />
Aus den Ausdrücken für die Wahrscheinlichkeiten<br />
der Lösung einer Aufgabe durch<br />
eine und eine andere Person läßt sich durch<br />
Abziehen der beiden Umkehrfunktionen<br />
voneinander der Aufgabenparameter eliminieren:<br />
Pi,<br />
j<br />
log( )<br />
1 P<br />
i,<br />
j<br />
Pk,<br />
j<br />
log( )<br />
1 P<br />
k,<br />
j<br />
Pi,<br />
j<br />
log( )<br />
1 P<br />
i<br />
k<br />
j<br />
i,<br />
j<br />
j<br />
Die Differenz der logarithmierten Wettchancen<br />
zweier Personen hängt nicht von<br />
der betrachteten Aufgabe ab (ist für alle<br />
Aufgaben gleich).<br />
P<br />
P<br />
i , j k , j<br />
log( ) log( )<br />
1 P 1 P<br />
i , j k , j<br />
i<br />
i<br />
j<br />
k<br />
Diese Aussage setzt voraus, daß das<br />
Rasch-Modell in gerade betrachteten Fall<br />
empirisch gilt, weil nur dann sämtliche<br />
aufgaben gleichartig sind. Wie die empirische<br />
Geltung festgestellt wird, kommt später<br />
zur Sprache.<br />
Spezifische Objektivität<br />
Aus den Ausdrücken für die Wahrscheinlichkeiten<br />
der Lösung einer Aufgabe durch<br />
eine und eine andere Person läßt sich durch<br />
Abziehen der beiden Umkehrfunktionen<br />
voneinander der Aufgabenparameter eliminieren:<br />
Pi,<br />
j<br />
log( )<br />
1 P<br />
i,<br />
j<br />
Pk,<br />
j<br />
log( )<br />
1 P<br />
k,<br />
j<br />
i<br />
k<br />
j<br />
j<br />
Die Differenz der logarithmierten Wettchancen<br />
zweier Personen hängt nicht von<br />
der betrachteten Aufgabe ab (ist für alle<br />
Aufgaben gleich).<br />
P<br />
P<br />
i , j k , j<br />
log( ) log( )<br />
1 P 1 P<br />
i , j k , j<br />
Diese Aussage setzt voraus, daß das<br />
Rasch-Modell in gerade betrachteten Fall<br />
empirisch gilt, weil nur dann sämtliche<br />
aufgaben gleichartig sind. Wie die empirische<br />
Geltung festgestellt wird, kommt später<br />
zur Sprache.<br />
Hinreichende und notwendige empirische<br />
Bedingungen<br />
Man definiert die einer Person i äquivalente<br />
Aufgabe j durch Gleichheit von i und<br />
j. Eine Aufgabe j ist demnach einer Person<br />
i äquivalent, wenn Pij = ½. Nun lassen<br />
sich Personen bzw. Aufgaben untereinander<br />
vergleichen. Ein praktisches Beispiel<br />
i<br />
k
ist etwa das Tennisspiel, bei dem der Spieler<br />
mit einem Gegner als „Aufgabe“ konfrontiert<br />
ist.<br />
Aus den drei Vergleichswahrscheinlichkeiten<br />
für drei Aufgaben (oder drei Personen),<br />
lassen sich deren Parameter sämtlich eliminieren.<br />
Es ergibt sich so die Multiplikationsbedingung.<br />
Multiplikationsbedingung (Luce,1959).<br />
P P<br />
i , j j , k<br />
Pik<br />
,<br />
log( ) log( ) log( )<br />
1 P 1 P 1 P<br />
oder:<br />
i , j j , k i , k<br />
Betrachtet man die P als Beobachtungen<br />
von relativen Häufigkeiten (richtiger Lösungen),<br />
dann ist die Multiplikationsbedingung<br />
eine empirische Formulierung von<br />
Raschs Latent Trait Theorie, weil sie parameterfrei<br />
ist. Grundsätzlich ließe sich<br />
diese Form zur empirischen Modellprüfung<br />
benutzen, sofern man alle aus den<br />
Aufgaben zu bildenden Tripel untersucht.<br />
Praktisch ergeben sich dabei allerdings<br />
Schwierigkeiten in der Beobachtung von<br />
hinreichend großen absoluten Häufigkeiten,<br />
sowie bei der Formulierung einer geeigneten<br />
statistischen Nullhypothese. Man<br />
benutzt deshalb später zu besprechende<br />
andere Modelltests.<br />
Eigenschaften von Abständen D<br />
(x, x) = 0. (1)<br />
(x, y) > 0 für x ¹ y. (2)<br />
(x, y) = D (y, x). (3)<br />
(x, y) + D (y, z) ³ D (x, z). (4)<br />
Beispiel:<br />
P P P<br />
i , j j , k ik ,<br />
1 P 1 P 1 P<br />
i , j j , k i , k<br />
--O---------------------------O---------------O-<br />
x y z<br />
Würzburg Nürnberg <strong>Regensburg</strong><br />
Lineare Abhängigkeit<br />
Bei Geltung der Multiplikationsbedingung<br />
wird die Dreiecksungleichung zur Gleichung.<br />
Die beiden Summanden links ergeben<br />
dann stets den rechten Term. Man sagt,<br />
die drei Abstände sind linear abhängig.<br />
Geometrisch wird lineare Abhängigkeit<br />
von je drei Elementen als Eindimensionalität<br />
gedeutet. Diese Eigenschaft der Abstände<br />
führt dazu, daß man aus je zwei<br />
Abstanden den dritten berechnen kann.<br />
Aus zwei Vergleichen dreier Personen ist<br />
das Resultat des ausstehenden dritten Vergleichs<br />
vorherzusagen. Aus zwei Vergleichen<br />
dreier Personen ist das Resultat des<br />
ausstehenden dritten Vergleichs in Wahrscheinlichkeit<br />
berechenbar<br />
Beispiel:<br />
Wenn Person i von Person j den Abstand<br />
0,5 besitzt und Person j von Person k den<br />
Abstand 1,5 , dann besitzt Person i von<br />
Person k den Abstand 2. Wegen 2 = log<br />
(pik/(1 - pik)) ist die Wahrscheinlichkeit<br />
pik, daß Person i das Niveau von Person k<br />
übertrifft gleich 0,88.<br />
Multiplikationsbedingung als Modelltest<br />
Man kann alle Tripel von logits daraufhin<br />
untersuchen, ob ihre Summe Null ist. Es<br />
ergibt sich eine Verteilung um Null. Deren<br />
Streuung kann man beurteilen, wenn man<br />
die gleiche Verteilung aus vorgegebenen<br />
Skalenwerten simuliert und dann verschiedene<br />
„Verrauschungen“ einführt und vergleicht.<br />
Auch hier ist das logit gleich der<br />
Differenz zweier Skalenwerte.<br />
Beispiel<br />
Seien drei Tennisspieler i, j, k gegeben,<br />
deren Spielstärken i =1, j = 2 und k = 4
etragen. Dann sind die drei Differenzen ij<br />
= 1, jk = 2 und ik = 3. Daraus lassen sich<br />
die paarweisen Gewinnwahrscheinlichkeiten<br />
berechnen. Die Differenzen addieren<br />
sich zu Null. Überlagert man die Differenzen<br />
mit einer (normalverteilten) Fehlerkomponente<br />
, dann bilden sie eine Verteilung<br />
um Null, deren Streubreite von der<br />
Größe der Fehlerkomponente abhängt.<br />
Ableitung des Rasch-Modells<br />
Unter der Voraussetzung einer erschöpfenden<br />
Statistik s, der Eindimensionalität und<br />
der lokalen stochastischen Unabhängigkeit<br />
läßt sich das Rasch-Modell ableiten. Zunächst<br />
wird die Faktorisierungsbedingung<br />
für eine Statistik von s = 1 formuliert.<br />
PU ( [1, 0] |<br />
oder<br />
h<br />
P( s 1 | )<br />
PU ( [0,1] |<br />
h<br />
h<br />
P( s 1 | )<br />
h<br />
h)<br />
h)<br />
Zwei Aufgaben g und f.<br />
P ( U [1, 0] | s 1)<br />
h<br />
P ( U [0,1] | s 1)<br />
Bei h = k = läßt sich wegen der lokalen<br />
stochastischen Unabhängigkeit schreiben<br />
P ( U [1, 0] | P (1 P )<br />
und<br />
h ) h , g h , f<br />
P ( U [0,1] | P (1 P )<br />
k ) k , f k , g<br />
Wahrscheinlichkeit für s = 1<br />
Weil logisch „oder“ disjunkter Ereignisse<br />
der Addition von Wahrscheinlichkeiten<br />
entspricht, gilt<br />
P ( s 1 | ) P (1 P ) P (1 P )<br />
h , g hf h , f h , g<br />
h<br />
Kombinieren der beiden Gleichungen<br />
durch Division<br />
PU ( [1, 0] | )<br />
(1 P )<br />
h , g h , f<br />
P ( s 1 | ) P (1 P ) P (1 P )<br />
P<br />
h , g h , f h , f h , g<br />
unabhängig von . Vereinfacht<br />
PU ( [1, 0] | ) 1<br />
P( s 1 | )<br />
1<br />
P<br />
P<br />
Spezifische Objektivität<br />
(1 P )<br />
h , f h , g<br />
(1 P )<br />
h , g h , f<br />
Das Verhältnis der Wettchancen zweier<br />
Aufgaben f,g ist für eine Person h<br />
1<br />
P<br />
1<br />
P<br />
h , f<br />
h , g<br />
P<br />
P<br />
h , f h , g<br />
k<br />
f , g<br />
unabhängig von . Aus Symmetriegründen<br />
gilt dies auch für den Vergleich zweier<br />
Personen mittels einer beliebigen Aufgabe.<br />
<strong>Psychologische</strong> Bedeutung von k<br />
Andersen hat gezeigt, daß die Interpretation<br />
dieser Konstanten k als Verhältnis εf /<br />
εg der betreffenden Aufgabenschwierigkeiten<br />
die Entwicklung mit einem psychologischen<br />
Sachsinn versieht und gleichzeitig<br />
die Ableitung vollendet.<br />
Multiplikationsbedingung<br />
Die Wahl der Konstanten k = εf / εg führt<br />
dazu, daß Sich bei einer multiplikativen<br />
Kombination von drei Wettchanchen sämtliche<br />
Parameter herauskürzen:<br />
P<br />
1<br />
P<br />
P<br />
i , j ik , j , k i k j<br />
1 P P 1 P<br />
i , j i , k j , k j i k<br />
Das ist die Multiplikationsbedingung von-<br />
Luce(1959. Sie ist hinreichend und notwendig<br />
für das Rasch-Modell. Deshalb ist<br />
damit die Ableitung vollzogen.)<br />
0<br />
1
Eindimensionalität<br />
Logarithmiert man die Multiplikationsbedingung,<br />
dann werden aus den Quotienten<br />
der Parameter Differenzen und die entstehenden<br />
logarithmierten Wettschancen weisen<br />
als „Logits“ eine lineare Abhängigkeit<br />
auf.<br />
Pi , j<br />
1 P P<br />
ik ,<br />
j , k<br />
log log log<br />
1 P P 1 P<br />
.<br />
i , j i , k j , k<br />
i<br />
k<br />
log log log 0<br />
j i k<br />
Beweis für n Aufgaben<br />
Dieser Beweis einer Ableitbarkeit eines<br />
Rasch-Tests bestehend aus zwei Aufgaben<br />
aus der Erschöpfungseigenschaft einer<br />
Summenstatistik von 1, der lokalen stochastischen<br />
Unabhängigkeit und der Eindimensionalität<br />
ergibt den Induktionsanfang<br />
für einen allgemeinen Beweis.<br />
Es läßt sich zeigen, daß unter Beibehaltung<br />
der Annahmen die schrittweise Vergrößerung<br />
der Summenstatistik von 1 auf 2, 3, ...<br />
, n zu einem Rasch-Test von n Aufgaben<br />
führt.<br />
Test-Information<br />
Die logarithmierte Likelihood-Funktion<br />
log( L) ist für stochatisch unabhängige<br />
Daten X und Y additiv.Wegen L( |<br />
X,Y)=L1( | X) L2( |Y) gilt<br />
log L( |X,Y) = log L1( | X) + log L2(<br />
|Y).<br />
Die Log-Likelihood-Funktion wird auch<br />
support genannt. Ihre Ableitung nach <br />
heißt score:<br />
Parameter des score V<br />
V = v( X | ) = log L( | X ) / = L´(<br />
) / L ( ).Der Erwartungswert des score<br />
ist gleich Null:<br />
(V) = ([v( X | )] = 0.<br />
j<br />
Die Varianz des score ist die Fishersche<br />
Information I Der Stichprobe X:<br />
IX( ) = var (V) = { [ log ( L ( X | )/ <br />
]² }<br />
Additivität der Information<br />
Satz: Für unabhängige Experimente X und<br />
Y ist Information additiv:<br />
I X,Y ( ) = I X ( ) + I Y ( ).<br />
Deshalb ergibt auch die Information einer<br />
Stichprobe n-fachen Umfangs Z = ( X1,X2,<br />
... ,Xn )die n-fache Information.<br />
I Z ( ) = n I X ( ).<br />
Information erschöpfender Statistik<br />
Satz: Die Information, die durch eine erschöpfende<br />
Statistik beigetragen wird, ist<br />
gleich der Information der Stichprobe.<br />
Das folgt aus der Faktorisierungsbedingung:<br />
F ( X | ) = g( t(X), ) h( X ).<br />
Satz: Bei der Reduktion einer Stichprobe<br />
auf eine Statistik kann Information verlorengehen,<br />
es sei denn die Statistik ist erschöpfend:<br />
Ist T = t( X ), dann gilt<br />
I T ( ) I X ( ).<br />
Parameterschätzung<br />
Sei U = 0,1 eine Zufallgröße, und , <br />
Parameter, i der Personenindex, j der Aufgabenindex,<br />
dann ist die Wahrscheinlichkeit<br />
exp( u ( ))<br />
i , j i j<br />
P ( U u | , )<br />
i , j i j<br />
1 exp( u ( ))<br />
i , j i j<br />
als Likelihood-Funktion für eine Aufgabe<br />
und eine Person zum Rasch-Modell gegeben.
Erweiterung auf mehrere Aufgaben<br />
Betrachtet man die Bearbeitung von n<br />
Aufgaben einer Person, so ergibt sich:<br />
n exp( u ( ))<br />
i , j i j<br />
P ( U | , , E )<br />
i i i j j 1<br />
1 exp( )<br />
exp( u ( ))<br />
n<br />
j 1<br />
n<br />
j 1<br />
i , j i j<br />
1 exp( )<br />
i<br />
Maximum Likelihood Schätzung<br />
j<br />
Im weiteren setzt man h = exp(h) und<br />
g= exp(g). Dabei ist h der Personen- und<br />
g der Aufgabenindex. Dann gilt<br />
P<br />
h,<br />
g<br />
h<br />
h<br />
1 1<br />
h g h g<br />
h<br />
mit = 1/ der Aufgabenleichtigkeit.<br />
Neue Schreibweise der Likelihood<br />
h,<br />
g<br />
g<br />
h<br />
h g uh , g<br />
h g 1 uh , g<br />
L( u | , ) ( ) (1 ( )<br />
h,<br />
g<br />
1 1<br />
L( u | , )<br />
( )<br />
1<br />
h<br />
g<br />
h g h g<br />
h<br />
u h,<br />
g<br />
Erweiterung der Likelihood auf mehrere<br />
Aufgaben<br />
sh<br />
h<br />
g , h g 1 k k<br />
L( u | , ,..., )<br />
g<br />
i 1<br />
u h1<br />
1<br />
g<br />
,...,<br />
(1 , )<br />
i<br />
h<br />
u hk<br />
k<br />
Ausmultiplizieren des Nenners rechts führt<br />
zur elementarsymmetrische Funktion k-ter<br />
Ordnung, die man mit γk abgekürzt.<br />
Elementarsymmetrische Funktionen<br />
sind Produktsummen aller Tupel der Parameter:<br />
i<br />
j<br />
0<br />
...<br />
1,<br />
1 1 2<br />
2 1 2 1 3 k 1<br />
3 1 2 3 1 2 4 k 2 k 1 k<br />
k<br />
k<br />
g<br />
1<br />
g<br />
.<br />
... ,<br />
k<br />
... ,<br />
k<br />
... ,<br />
Grundsätzlich gibt es zwei Möglichkeiten<br />
eine Maximum-Likelihood Schätzung der<br />
Parameter anzusetzen. Die erste besteht in<br />
der Formulierung der Likelihood für die<br />
gesamte Datenmatrix, deren Maximierung<br />
in Abhängigkeit von den gesuchten Parametern<br />
und Auflösung nach den gesuchten<br />
Parametern. Dieser Zugang führt zu einfacheren<br />
Formeln, wird aber dennoch nicht<br />
gern begangen. Die gemeinsame Schätzung<br />
von Person- und Aufgabenparametern<br />
ermöglicht keine konsistenten Parameterschätzungen,<br />
da eine Vergrößerung der<br />
Stichprobe stets mit einer Vermehrung der<br />
Parameteranzahl einhergeht.<br />
Der andere Ansatz geht von der Formulierung<br />
der bedingten Likelihood unter der<br />
Bedingung der beobachteten Zeilen- sowie<br />
Spaltensummen der Datenmatrix aus. Dazu<br />
muß entsprechend dem Satz von Bayes<br />
neben der Likelihood der Datenmatrix<br />
auch die Likelihood der Bedingung bestimmt<br />
werden. Der Quotient dieser beiden<br />
Größen ist die bedingte Likelihood, die<br />
maximiert und nach den Parametern ausgewertet<br />
werden kann. Die Formulierung<br />
dieses Ausdrucks ist nicht ganz einfach, da<br />
bei festen Randsummen einer Matrix mehrere<br />
Datenmatrizen infrage kommen, die<br />
diese Randsummen hervorgebracht haben.<br />
Die Bestimmung dieser Anzahl ist ein<br />
kombinatorisches Problem, das schon<br />
Rasch (1960) bearbeitet hat. Man kann den<br />
kombinatorischen Koeffizienten mittels<br />
elementarsymmetrischer Funktionen der i<br />
bestimmen. Dieses Symbol bedeutet hier<br />
uij ist in der gerade betrachteten Zeile der<br />
Datenmatrix in der i-ten Spalte gleich eins.<br />
In der sich auf diese Weise ergebenden<br />
elementarsymmetrischen Funktion der i<br />
ergibt sich der gesuchte kombinatorische
Wert als Koeffizient desjenigen Produkts<br />
von Potenzen der 12 …k (k ist die Spaltenanzahl<br />
der Datenmatrix), dessen Potenzen<br />
bei den einzelnen i gleich den Spaltensummen<br />
sind. Diese Koeffizient kann<br />
rechnerisch durch Ableitung nach den i<br />
gefunden werden. Fischer (1974) beschreibt<br />
das Verfahren im einzelnen, erklärt<br />
aber auch, wie es iterativ in den eigentlichen<br />
Parameterschätzprozess eingegliedert<br />
werden kann.<br />
Diesem Verfahren wird, obwohl etwas<br />
komplizierter, der Vorzug gegeben, weil<br />
damit die Aufgabenparameter unabhängig<br />
von den Personparametern geschätzt werden<br />
können. Bei der Formulierung der bedingten<br />
Likelihood fällt jeweils eine Art<br />
der Parameter heraus.<br />
Das iterative Verfahren wird in folgenden<br />
Schritten vollzogen:<br />
Likelihood einer gesamten Datenmatrix<br />
G( , n )<br />
n*<br />
i<br />
v*<br />
n*<br />
i<br />
i<br />
nv*<br />
für 0 n n und<br />
n<br />
* i<br />
K<br />
i<br />
* i<br />
n<br />
v<br />
Die bedingte Likelihood ist dann der Quotient,<br />
bei dem die Personenparameter ξ<br />
herausgefallensind („Trennung der Parameter“,<br />
„Spezifische Objektivität“):<br />
n*<br />
I<br />
i<br />
L P ( n | n ) K<br />
* i v*<br />
G nv<br />
*<br />
( , )<br />
Maximierung der logarithmierten Likelihood<br />
Nun wird in diesen Ausdruck für K und G<br />
eingesetzt, logarithmiert, nach den gesuchten<br />
ω abgeleitet, und nullgesetzt. Es ergibt<br />
sich die (implizite) Schätzgleichung<br />
P{ n , n | , } K<br />
v* * i<br />
v<br />
v<br />
i<br />
n v *<br />
i<br />
* i<br />
(1 )<br />
Dabei ist K der kombinatorische Faktor,<br />
der angibt, wie viele binäre Datenmatrizen<br />
die eben gegebenen Ransummen erzeugt<br />
haben können. Die Likelihood der Bedingung<br />
ist<br />
P{ n | , }<br />
v*<br />
v<br />
v<br />
i<br />
i<br />
v<br />
v<br />
Dabei ist<br />
nv*<br />
(1 )<br />
nv*<br />
v<br />
nv*<br />
n*<br />
i<br />
v i<br />
v i<br />
i<br />
a*<br />
i<br />
G( , N )<br />
v*<br />
(1 )<br />
v<br />
i<br />
K<br />
v<br />
K<br />
i<br />
i<br />
* i<br />
v<br />
* i<br />
(1 )<br />
i<br />
Nullsetzen führt zu der (impliziten) Lösung:<br />
u<br />
k ( g )<br />
* g<br />
r 1<br />
n<br />
r<br />
g r 1 r<br />
Dabei bedeutet der Ausdruck im Zähler<br />
ganz rechts, daß in γr das g gleich Null<br />
gesetzt wird, nach dem eben partiell differenziert<br />
wird<br />
Dies ist eine Schätzung der Aufgabenparameter<br />
allein auf Grund der Randsummen<br />
u*g und nr.<br />
Mit Hilfe von auf dem Markt befindlichen<br />
kommerziellen Computerprogrammen läßt<br />
sich für die Aufgabenparameter iterativ<br />
eine Lösung finden. Man setzt sie zu Anfang<br />
alle mit gleichem Zahlenwert in die<br />
rechte Seite der Gleichung ein, so daß sie<br />
sich zu Eins aufsummieren. Dann errechnet<br />
man die links in der Gleichung vorkommenden<br />
ω. Diese benützt man dann
wieder rechts als Eingabe für den nächsten<br />
Iterationsschritt. Sobald sich die jeweils<br />
neuen nicht mehr wesentlich geändert<br />
haben, beendet man das Verfahren. Nun<br />
kann man mit den bekannte Aufgabenparametern<br />
und dem Rasch-Modell die Personenparameter<br />
berechen.<br />
(wird fortgesetzt).<br />
Literatur<br />
Fischer, G.H.(1974), Einführung in die<br />
Theorie psychologischer Tests. Bern, Huber.<br />
Fischer, G.H.(1995) Derivation of the<br />
Rasch Model, S.15 – 38 in Fischer, G. H,<br />
& Molenaar,I, W., (Herausgeber) Rasch<br />
Models, New York usw., Springer.<br />
Fischer, G. H. & Mlenaar I,.V.: (1995)<br />
Rasch Models, foundations, recent developments<br />
and applications. New York,<br />
Springer.<br />
Hell, B., Trapmann, S., Weigand, S. & Schuler,<br />
H: (2007) ,<br />
Die Validität von Auswahlgesprächen im<br />
Rahmen der Hochschulzulassung – eine Metaanalyse.<br />
<strong>Psychologische</strong> Rundschau, 58, 2, 93 – 102.<br />
Irtel, H.,(1996) Entscheidungs- und testtheoretische<br />
Grundlagen der <strong>Psychologische</strong>n<br />
<strong>Diagnostik</strong>, Frankfurt a. M., Lang,<br />
.<br />
Lindgren, B. W., (1968) Statistical Theory,<br />
second edition. London, McMillan.








