

Belegarbeit (.pdf - 2.3 MB) - Technische Universität Dresden
Belegarbeit (.pdf - 2.3 MB) - Technische Universität Dresden
Belegarbeit (.pdf - 2.3 MB) - Technische Universität Dresden

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
6. TESTS 44<br />
fig zu Verwechslungen. In einer Umgebung in der nur das wirklich benötigte Vokabular genutzt wird,<br />
kann dem nach eine bedeutend höhere Worterkennungsrate erreicht werden. Ein weiteres Problem für<br />
den Vergleich besteht darin, dass die SAPI sprecherabhängig arbeitet. In diesem Fall war der Erkenner<br />
durch eine vorab Trainingszeit von insgesamt etwa 60 Minuten besonders auf meine Stimme trainiert<br />
und um einen neuen Vokabulareintrag hinzuzufügen musst dieser ebenfalls noch einmal eingesprochen<br />
werden. Das sollte dem Erkenner normalerweise einen Vorteil verschaffen. Eine interessante Frage besteht<br />
darin, welchen Einfluss die Sprecherabhängigkeit auf die Erkennungsrate hat. Im Folgenden wird<br />
der gesamte Test noch einmal mit einem Sprecher wiederholt, auf den Erkenner vorher nicht trainiert<br />
wurde. Erschwerend kommt hinzu, dass es sich nun um eine Sprecherin handelt, der Erkenner ist jedoch<br />
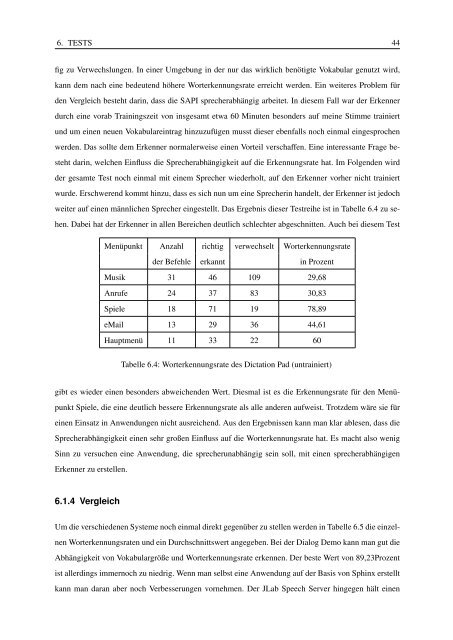
weiter auf einen männlichen Sprecher eingestellt. Das Ergebnis dieser Testreihe ist in Tabelle 6.4 zu sehen.<br />
Dabei hat der Erkenner in allen Bereichen deutlich schlechter abgeschnitten. Auch bei diesem Test<br />
Menüpunkt Anzahl richtig verwechselt Worterkennungsrate<br />
der Befehle erkannt in Prozent<br />
Musik 31 46 109 29,68<br />
Anrufe 24 37 83 30,83<br />
Spiele 18 71 19 78,89<br />
eMail 13 29 36 44,61<br />
Hauptmenü 11 33 22 60<br />
Tabelle 6.4: Worterkennungsrate des Dictation Pad (untrainiert)<br />
gibt es wieder einen besonders abweichenden Wert. Diesmal ist es die Erkennungsrate für den Menüpunkt<br />
Spiele, die eine deutlich bessere Erkennungsrate als alle anderen aufweist. Trotzdem wäre sie für<br />
einen Einsatz in Anwendungen nicht ausreichend. Aus den Ergebnissen kann man klar ablesen, dass die<br />
Sprecherabhängigkeit einen sehr großen Einfluss auf die Worterkennungsrate hat. Es macht also wenig<br />
Sinn zu versuchen eine Anwendung, die sprecherunabhängig sein soll, mit einen sprecherabhängigen<br />
Erkenner zu erstellen.<br />
6.1.4 Vergleich<br />
Um die verschiedenen Systeme noch einmal direkt gegenüber zu stellen werden in Tabelle 6.5 die einzelnen<br />
Worterkennungsraten und ein Durchschnittswert angegeben. Bei der Dialog Demo kann man gut die<br />
Abhängigkeit von Vokabulargröße und Worterkennungsrate erkennen. Der beste Wert von 89,23Prozent<br />
ist allerdings immernoch zu niedrig. Wenn man selbst eine Anwendung auf der Basis von Sphinx erstellt<br />
kann man daran aber noch Verbesserungen vornehmen. Der JLab Speech Server hingegen hält einen














