2.10 Speicherorganisation
2.10 Speicherorganisation
2.10 Speicherorganisation

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Informatik V-Teil 2,Kap. 10, SS 99<br />
10. Speicher-Organisation<br />
10.1 Einführung<br />
Wir haben bereits bei der Betrachtung von Befehlssätzen beobachtet, daß dort eine 90/10-Regel gilt.<br />
Bei einem komplexen Befehlssatz werden 90% der Operationen auf 10% des Befehlssatzes<br />
ausgeführt. Diese 90/10-Regel kann man allgemeiner auch als das "Prinzip der Lokalität" angeben.<br />
Sie gilt in ganz ähnlicher Weise auch für Speicher und zwar in zwei Beziehungen:<br />
− Zeitliche Lokalität:<br />
Wenn ein Speichereintrag erfolgt ist oder auf einen Eintrag zugegriffen wurde, so besteht eine hohe<br />
Wahrscheinlichkeit, daß in einem der nächsten Befehle ein erneuter Zugriff auf diesen Speichereintrag<br />
erfolgt..<br />
− Räumliche Lokalität:<br />
Wenn auf einen Eintrag zugegriffen wurde, so erfolgt mit hoher Wahrscheinlichkeit bald ein Zugriff<br />
auf einen benachbarten Eintrag.<br />
Auf der anderen Seite kann man zwar heute Speicher fast beliebig groß bauen und auch fast beliebig<br />
schnell, aber die Kombination beliebig groß und beliebig schnell stößt an harte wirtschaftliche<br />
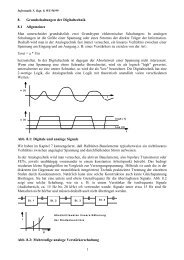
Grenzen. Es macht deshalb Sinn, ein Konzept der Speicher-Hierarchie einzuführen nach dem Prinzip<br />
"je kleiner um so schneller und je größer um so langsamer". Die oberste Ebene der Hierarchie enthält<br />
deshalb den kleinsten und schnellsten Speicher, die niedrigste Ebene den größten und langsamsten.<br />
Blöcke<br />
Prozessor<br />
Abb. 10.1a: Speicher-Hierarchie<br />
oberste Ebene<br />
1<br />
niedrigste Ebene
Informatik V-Teil 2,Kap. 10, SS 99<br />
Kapazität (Bytes)<br />
Zugriffszeit<br />
256 - 1024 Register<br />
10 ns<br />
16 - 23 K Primär-Cache 10 ns<br />
64 K - 1 M Sekundär-Cache 20 ns<br />
(SRAM)<br />
16 M - 500 M Hauptspeicher<br />
(DRAM)<br />
2<br />
35 - 100 ns<br />
100 M - 5000 M Sekundärspeicher<br />
(Platten)<br />
16 - 50 ms<br />
1 G - 100 G<br />
Archivspeicher<br />
(Magnetbänder, CDs)<br />
500 ms<br />
Abb. 10.1b: Ebenen der Speicherhierarchie: Speichergrößen und Zugriffszeiten<br />
Im Idealfall beinhalten die Ebenen der Hierarchie einander, d. h. alle Daten, die auf einer höheren<br />
Ebene gespeichert sind, findet man auch auf allen niedrigeren Ebenen in konsistenter Form wieder.<br />
Informationen zwischen den Ebenen werden nicht in beliebiger Größe ausgetauscht, sondern als<br />
sogenannte Blöcke. Die minimale Größe einer Informationseinheit, die auf zwei verschiedenen<br />
Ebenen vorhanden ist, nennt man einen Block. Blöcke können je nach Architektur des Rechners<br />
gleiche oder unterschiedliche Größe aufweisen.<br />
Die eigentliche oberste und schnellste Stufe der Speicher-Hierarchie bilden die Register im Prozessor<br />
selbst. Hier gilt aber das Block-Prinzip nicht und auch nicht die Konsistenz zwischen den Ebenen, so<br />
daß man als oberste Hierarchiestufe meistens die Ebene betrachtet, in die man einen ganzen Block<br />
einlagern kann. Das wird z. B. beim PC ein On-Chip-Cache-Speicher sein können.<br />
Wichtig für die Funktion und die Leistungsfähigkeit eines Rechners ist die Frage, ob beim Zugriff des<br />
Prozessors auf die oberste Hierarchiestufe ein Treffer (hit) erfolgt oder ein Fehlzugriff (miss)<br />
passiert. Letzteres bedeutet, daß der Block auf der höchsten Hierarchieebene nicht gefunden wurde<br />
und erst aus einer tieferen Ebene umgelagert werden muß. Die Treffer-Rate (hit rate) bezeichnet,<br />
meistens in Prozent angegeben, den Anteil der erfolgreichen Speicherzugriffe. Die Fehlzugriffsrate<br />
(miss rate) gibt den relativen Anteil der erfolglosen Zugriffe an. Der mehr- oder weniger erfolgreiche<br />
Speicherzugriff wirkt sich natürlich auf die Zeit aus, die der Rechner braucht, um ein Datum oder<br />
eine Adresse in ein Register der CPU zu laden oder es von dort in den Speicher zu schreiben.<br />
Die Trefferzeit (hit time) ist die Zeit, die für den Zugriff zur obersten Hierarchiestufe benötigt wird,<br />
einschließlich des Aufwandes für die Entscheidung, ob ein Hit oder ein Miss stattgefunden hat.<br />
Dagegen ist die Fehlzugriffszeit (miss penalty) die Zeit, die vergeht, bis ein nicht vorhandener Block<br />
der obersten Ebene durch eine Block der nächst niedrigeren Ebene ersetzt ist.<br />
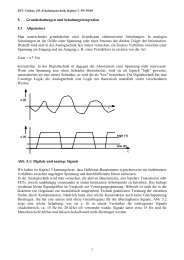
32- Bit-Adresse<br />
01001001010011010110101 110101001<br />
Block-Adresse (23 Bit) Block-Offset-Adresse (9 Bit)<br />
Abb. 10.2: Block-Adressierung<br />
Die Fehlzugriffszeit hat wiederum zwei Anteile: Die Zugriffszeit (access time) auf das erste Wort des<br />
Block auf der niedrigeren Ebene und die Transferzeit (transfer-time), das ist die zur Übetragung der<br />
Worte im Block zusätzlich notwendige Zeit.
Informatik V-Teil 2,Kap. 10, SS 99<br />
Die Speicheradresse für ein Datum wird aufgeteilt in die Block-Adresse (block frame address) und<br />
die Block-Offset-Adresse (block offset address).<br />
10.2 Leistung einer Speicher-Hierarchie<br />
In die benötigte Zeit zur Ausführung eines Programms geht neben der Leistung der CPU natürlich<br />
auch die Zugriffszeit auf Daten im Speicher direkt ein. Ein in der Praxis brauchbares Maß für die<br />
Zugriffszeit auf den Speicher ist die sogenannte "mittlere Speicher-Zugriffszeit". Sie errechnet sich<br />
als:<br />
Mittlere Sp.-Zugriffszeit = Trefferzeit + Fehlzugriffsrate * Fehlzugriffszeit.<br />
Dieser Parameter kann entweder absolut (in ns) oder in Taktzyklen der CPU gemessen werden,<br />
welche diese auf den Speicher wartet.<br />
Indirekt geht in diese Rechnung auch die Block-Größe ein.<br />
zeit<br />
Zugriffszeit<br />
Blockgröße<br />
Transferzeit<br />
Fehlzugriffs-<br />
rate<br />
3<br />
Blockgröße<br />
Abb. 10.3: Fehlzugriffszeit und Fehlzugriffsrate als Funktion der Block-Größe<br />
Mit wachsender Blockgröße steigt bei der Fehlzugriffszeit der Anteil der Transferzeit. Mit steigender<br />
Blockgröße in der obersten Hierarchieebene fällt zunächst die Rate der Fehlzugriffe. Wird der Block<br />
aber so groß, daß er vorwiegend nicht-lokale und damit wenig nützliche Information enthält und<br />
andererseits wegen Block-Grenzen nützliche Information blockiert, so steigt die Fehlzugriffsrate<br />
wieder an.<br />
Das Ziel der Optimierung der Speicherverwaltung ist vorrangig nicht die Verringerung der<br />
Fehlzugriffe, sondern der mittleren Zugriffszeit insgesamt.<br />
Im praktischen Entwurf wird deshalb die Blockgröße mit der geringsten mittleren Zugriffszeit<br />
bevorzugt, weniger die Blockgröße mit der geringsten Fehler-Zugfriffsrate.<br />
Es deutet sich hier schon an, daß der Aufbau einer Speicher-Hierarchie auch für den Entwurf der<br />
CPU zusätzlichen Aufwand erfordert. Ohne Speicherhierarchie entworfene Prozessoren sind<br />
natürlich wesentlich einfacher, weil im anderen Fall ein durchaus komplexes Optimierungsproblem zu<br />
lösen ist. Eine CPU muß nämlich durchaus sehr unterschiedliche Speicher-Zugriffszeiten verwalten<br />
und organisieren können.<br />
Dauert der Speicherzugriff einige bis einige zehn Taktzyklen, dann wird der Prozessor warten, bis<br />
der Zugriff erfolgt ist.<br />
Beim Zugriff auf Platten oder gar auf Magnetbänder kann ein Zugriff aber auch einige tausend<br />
Taktzyklen dauern. Zunächst muß damit die CPU bei jedem Speicherzugriff feststellen, welche<br />
Wartezeit absehbar ist.<br />
Da eine Wartezeit von tausenden von Taktzyklen nicht sinnvoll ist, wird man dann den laufenden<br />
Prozeß mit einem Interrupt abbrechen und der CPU einen anderen Prozeß zuteilen. Damit verbunden<br />
ist ein Prozeß der Interrupt-Bearbeitung und der Sicherung einer Rücksprungadresse.<br />
Auch die Prüfung auf die absehbare Zugriffszeit erfordert CPU-Leistung. Da sie bei jedem<br />
Sopeicherzugriff auftritt, wird spezielle Hardware notwendig sein, um die Leistungsverluste in<br />
Grenzen zu halten. Blocktransfers, die einige bis einige zehn Taktzyklen benötigen, werden mittels<br />
Hardware gesteuert. Bei sehr langen Zugriffszeiten setzt man spezielle I / O -Routinen in Software<br />
ein (z. B. Holen und Einlegen eines Magnetbandes).
Informatik V-Teil 2,Kap. 10, SS 99<br />
10.3 Speicher-Organisation bei 80X86- PCs<br />
10.3.1 Ursache<br />
Eine ganz besondere Art von Speicherverwaltung macht die Architektur der Intel 80X86-Familie in<br />
Verbindung mit dem MS-DOS Betriebssystem notwendig. Die Beschränkungen kommen prinzipiell<br />
von der Geschichte der Intel-Prozessoren und des MS-DOS Betriebsystems her.<br />
Ursprünglich gab es unter DOS nur einen16-Bit-Adressraum (vom 8086 / 80186-Prozessor), der<br />
einer Speichergröße von 1024 KByte entspricht. Davon war aber per Definition die obere Hälfte für<br />
das Betriebssystem reserviert. Die ab dem 80286-Prozessor erfolgte Erweiterung des Adreßraums<br />
auf 20 Bit wird nicht linear für einen größeren Adreßraum genutzt, sondern der Speicher wird in<br />
"Segmente" gegliedert.<br />
Viele unter DOS und Windows 3.1 gebräuchliche Programme, zum Beispiel das Betriebssystem<br />
selbst und die Treiber für periphere Geräte, die im Hauptspeicher "resident" sind, nutzen als Default<br />
vorrangig das unterste Segment.<br />
Um überhaupt einen größeren Speicherumfang als 1 MByte nutzen zu können, benötigt ein PC unter<br />
DOS oder Windows 3.X auch Memory-Management-Programme (HIMEM, EMMS386), die als<br />
default selbst wieder im unteren Speicherbereich stehen. Damit ist der tatsächlich verfügbare<br />
Arbeitsspeicher im untersten Segment für Anwendungen schon erheblich beschränkt.<br />
Für viele Anwendungen (insbesondere unter Windows) wird das zunächst nicht auffallen, da die<br />
Speicher-Management-Programme den Mangel verwalten.<br />
Es gibt aber durchaus Programme, und das sind insbesondere Spiele und komplexere<br />
Installationsprogramme, welche nur auf das unterste Speichersegment explizit zugreifen. Dann gibt<br />
es die bei DOS berüchtigte Fehlermeldung von "zu wenig Arbeitsspeicher", obwohl der PC mit 8<br />
oder 16 MB ausgestattet sein kann. Abhilfe schaffen zum Teil intelligente Programme zur<br />
Verwaltung des Speicherplatzes, aber vorrangig erst mal eine Verlagerung der speicherresidenten<br />
Programme aus der niedrigsten Partition in einen höheren Bereich. Diese Einstellungen sind in den<br />
Dateien CONFIG.SYS und AUTOEXEC.BAT vorzunehmen.<br />
10.3.2 Expanded Memory<br />
Wie die Erweiterung der Speicheradressierung tatsächlich stattfindet, ist in Abb. 10.4 dargestellt.<br />
Physikalische<br />
Seiten im<br />
Adaptersegment<br />
640 kByte<br />
Adaptersegment<br />
Page 3<br />
Page 2<br />
Page 1<br />
Page 0<br />
Hauptspeicher<br />
Abb. 10.4: Expanded Memory-Management bei DOS<br />
4<br />
Page 2<br />
Page 3<br />
Page 0<br />
Page 1<br />
Logische Seiten<br />
im<br />
Expanded Memory
Informatik V-Teil 2,Kap. 10, SS 99<br />
Der Trick besteht darin, daß man eine physikalische und eine logische Adresse definiert. Im Bereich<br />
des sogenannten Adapter-Segments (zwischen 832 und 896 kByte) wird ein zusammenhängendes<br />
"Durchreichefenster" eingerichtet, das eine Größe von 64 kByte hat. Dieses ist in vier sogenannte<br />
"page frames" von je 16 kByte aufgeteilt. Der gesamte Expansionsspeicher oberhalb von 1 Mbyte ist<br />
ebenfalls in Sektoren von je 16 KByte aufgeteilt. Diese Sektoren im Expansionsspeicher werden<br />
"logical pages" (logische Seiten) genannt.<br />
Wird eine Information aus dem Expanded Memory benötigt, so wird diese durch das "Fenster"<br />
durchgereicht, wobei aus den logischen Seiten physikalische Seiten werden.<br />
Der Zugriff auf den Expansionsspeicher war bei kleinen Speicherbausteinen gleich mit dem Zugriff<br />
auf eine zusätzliche Speicherplatine, was natürlich auch Zeitverluste mit sich brachte. Für Rechner ab<br />
dem 80386 kann man mit einem physikalisch einheitlichen Hauptspeicher auskommen. Eine spezielle<br />
Software, der sogenannte Expanded Memory Manager, bildet im erweiterten Speicher das Expanded<br />
Memory nach. Der gebräuchlichste Speichermanager ist das Programm EMM386.EXE.<br />
10.3.3 Extended Memory<br />
Der Bereich oberhalb von 640 kByte wird auch als "Extended Memory" bezeichnet. Dieser<br />
Speicherbereich ist direkt nur durch eine Erweiterung auf mehr als 16 Adressleitungen adressierbar,<br />
z. B. 24 Bit beim 80286 und 32 Leitungen beim 80386 und 80486.<br />
Hier gab es bei DOS spezielle Probleme damit, daß kein "protected mode" möglich war. DOS<br />
speicherte also keine Information darüber, ob ein hoher Speicherbereich belegt ist oder nicht.<br />
Es ergab sich also die Situation, daß ab dem 286er Prozessor Speicher oberhalb von 1 MByte<br />
adressierbar war, wenn auch nicht linear, sondern auf dem Umweg über Segmente, DOS war die<br />
Bremse. 1988 hat Microsoft zusammen mit anderen Firmen dann den XMS (Extended Memory<br />
Specification) Standard definiert. Ein spezieller Treiber, unter DOS "HIMEM.SYS" genannt,<br />
verwaltet das Extended Memory.<br />
Trotzdem nutzen längst nicht alle Programme die mit HIMEM verbundenen Möglichkeiten.<br />
Wenn z. B. ein Computer-"Experte" der größten PC-Vertriebsfirma in Deutschland seinen Kunden<br />
erklärt, dies oder das Spiel laufe nicht, weil der PC "falsch konfigurierte sei", meint er wahrscheinlich<br />
diesen Effekt. Man kann dann nur versuchen, den unteren Speicherbereich leerzuräumen. Oder ganz<br />
auf ein Betriebssystem jenseits von DOS umsteigen. Mittels HIMEM.SYS sind folgende<br />
Speicherbereiche zusätzlich nutzbar:<br />
− der obere Speicherbereich zwischen 640 kBytes und 1 Mbyte<br />
− der hohe Speicherbereich, der 64 kByte oberhalb der 1 MB-Grenze bietet<br />
− erweiterter Speicher oberhalb von 1 Mbyte plus 64 Kbyte (nur für Prozessoren ab 80386 aufwärts.<br />
Dami lassen sich dann auch Adressen oberhalb von 1 Mbyte plus 64 kByte adressieren. In diesem<br />
Modus findet aber keine virtuelle Speicherverwaltung statt, weshalb man ihn beim Betrieb mit<br />
Windows ggf. abschalten sollte.<br />
Zu erwähnen bleibt hier noch, daß DOS im Adaptersegment zwischen 640 kB und 1 MB<br />
typischerweise ungenutzte "Löcher" läßt.<br />
Spzielle Programme wie 386MAX oder QEMM stellen nicht nur Extented Memory bereit, sondern<br />
verlagern auch Speicher-residente Programme (und sich selbst) in solche Nischen. Ab MS-DOS 5.0<br />
kann auch das Programm EMM386.EXE solche Nischen öffnen (optional).<br />
Erwähnt werden sollte noch, daß man mit den Befehlen DEVICEHIGH in CONFIG.SYS bzw.<br />
LOADHIGH in AUTOEXEC.BAT speicherresidente Programme in den oberen Memory-Bereich<br />
auslagern kann und sich dadurch Raum für Anwenderprogramme im konventionellen Speicher<br />
schafft.<br />
5
Informatik V-Teil 2,Kap. 10, SS 99<br />
Das Programm SMARTDRV.EXE legt im extended-Teil des Hauptspeichers einen Cache als<br />
schnellen Zwischenspeicher für den Plattenzugriff an.<br />
10.4 Caches<br />
"Cache" stammt aus der französischen Sprache und ist im Englischen eine Art sicheres Versteck für<br />
Gegenstände. Man bezeichnet damit heute eine (oder mehrere) Speicherebenen zwischen der CPU<br />
und dem Hauptspeicher oder Arbeitsspeicher. Caches kommen heute fast in jedem Rechner vor. Der<br />
Grund ist darin zu suchen, daß sich bei explodierender Größe der dynamischen RAM-Bausteine<br />
deren Zugriffszeit kaum verändert hat und heute bei 60 bis 70 ns liegt. Wer schnellere RAMs haben<br />
will, muß zu statischen RAMs greifen, die zwar fast um einen Faktor 10 schneller sein können, aber<br />
längst nicht die Komplexität dynamischer RAMs aufweisen (mindestens Faktor 4).<br />
Deshalb ist es üblich geworden, auch bei PCs und erst recht bei Workstations die Speicherhierarchie<br />
um den Cache als Puffer-Speicher zwischen Arbeitsspeicher und den Registern der CPU zu<br />
erweitern. Man unterscheidet auch zwischen Caches für Befehle (instruction cache) und für Daten<br />
(data cache). Z. B. besitzt der 80486-Prozessor nur einen kleinen on-chip Cache für Befehle.<br />
Block-Größe 4 - 128 Byte<br />
Trefferzeit 1 - 4 Taktzyklen (normal 1)<br />
Fehlzugriffszeit 8 - 32 Taktzyklen<br />
Zugriffszeit 6 - 10 Taktzyklen<br />
Transferzeit 2 - 22 Taktzyklen<br />
Fehlzugriffsrate 1% bis 20%<br />
Cache-Größe 1 KB - 256 kB<br />
Abb. 10.5: Typische Daten für Caches in Workstations und PCs<br />
Ein nicht triviales Problem ist die Organisation von Caches. Dazu gehört z. B. die Frage, wo ein<br />
Block im Cache plaziert werden kann oder soll und welche Blöcke aus dem Hauptspeicher wann und<br />
wie lange im Cache gehalten werden.<br />
Man unterscheidet drei Varianten der Cache-Organisation:<br />
− Hat jeder Block nur einen bestimmten Platz, an dem er im Cache abgelegt werden kann. Dann<br />
existierte eine direkte Abbildung des Arbeitsspeichers auf den Cache. Man spricht in diesem Fall<br />
von einem einfach assoziativen Cache (direct mapped cache). Die Abbildung geschieht<br />
gewöhnlich nach dem Rezept Blockadresse modulo Anzahl der Blöcke im Cache.<br />
Kann ein Block an jeder Stelle des Cache abgelegt werden, so spricht man von einem vollassoziativen<br />
(fully associative) Cache.<br />
Kann ein Block wahlweise einer eingeschränkten Menge von Plätzen zugeordnet werden, so spricht<br />
man von einem "set associative cache".<br />
Ein Set ist dann eine Gruppe von zwei oder mehr Blöcken im Cache. Ein Block wird zunächst einem<br />
Set zugeordnet und kann dann irgendwo innerhalb des Set plaziert werden. Ein Set wird gewöhnlich<br />
nach der Formel: Blockadresse modulo Zahl der Sets in Cache festgelegt. Gibt es gleichzeitig n<br />
Blöcke im Cache, so nennt man die Cache-Plazierung n-fach assoziativ.<br />
6
Informatik V-Teil 2,Kap. 10, SS 99<br />
Block Nr.<br />
Block Nr.<br />
Voll assoziativ<br />
Einfach assoziativ Mehrfach assoziativ<br />
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7<br />
Blockadresse<br />
1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3<br />
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2<br />
Abb. 10.6: Typen von Caches<br />
7<br />
Set 0 1 2 3<br />
Im Cache zu plazieren sei der Block Nr. 12. Im voll assoziativen Cache kann er in jedem der hier<br />
angenommenen Slots plaziert werden, im einfach assoziativen Cache dagegen nur im Slot Nr. 4 (12<br />
modulo 8) Im mehrfach assoziativen Cache ist z. B. das Set Nr. 0 zuständig (12 modulo 4), von dem<br />
beide Slots benutzt werden können.<br />
Ein bestimmter Block muß natürlich auch im Cache wiedergefunden werden können. Dazu haben<br />
Caches für jeden Block einen sogenannten Adreß-Tag, der die Blockadresse enthält (Abb. 10.6).<br />
Suche<br />
Tag<br />
Voll assoziativ<br />
Einfach assoziativ Mehrfach assoziativ<br />
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7<br />
1<br />
2<br />
Abb. 10.7: Cache mit Adress-Tag und Suchvorgang<br />
1<br />
2<br />
Set 0 1 2 3<br />
Das Tag jedes Cache-Blocks, der den benötigten Block enthalten könnte, wird geprüft. Da der<br />
Cache-Zugriff sehr schnell erfolgen soll, werden in der Regel alle Tags gleichzeitig geprüft. Beim<br />
voll-assoziativen Cache kann der Block an jeder Stelle der 8 "Slots" sein, beim einfach-assoziativen<br />
entsprechend seiner Adresse nur im Slot 6. Beim einfach assoziativen kommen die Slots 1 und 2 in<br />
Betracht.<br />
Darüber hinaus muß die CPU wissen, ob ein bestimmter Block gültige Information enthält. Deshalb<br />
wird zum Tag meistens noch ein "Gültigkeitsbit" (valid bit) hinzugefügt. Ist dieses Bit nicht gesetzt,<br />
so kann auf den entsprechenden Block nicht zugegriffen werden.<br />
1<br />
2
Informatik V-Teil 2,Kap. 10, SS 99<br />
Tag Index<br />
Abb. 10.7: Cache-Adresse<br />
8<br />
Block-<br />
Offset<br />
Die Struktur der Adresse eines mehrfach assoziativen Cache ist in Abb. 10.7 dargestellt. Das Block-<br />
Offset.Feld dient der Auswahl der Daten aus dem Block, das Index-Feld bezeichnet das Set, und das<br />
Tag-Feld zeigt den Block an.<br />
Ein nicht triviales Problem ist das Management des Cache. Wesentliche Aufgabe ist es, möglichst<br />
genau die Datenblöcke im Cache verfügbar zu haben, welche den Speicherzugriff insgesamt am<br />
wirksamsten gestalten.<br />
Hat man einen Block mit ungünstigen Raten, also einer Trefferquote von 0%, so ist dieser Block<br />
sicher ein Kandidat, aus dem Cache ausgelagert zu werden. Schwieriger gestaltet sich das Problem,<br />
wenn eine Auswahl zwischen verschiedenen Blöcken stattfinden muß, die alle gültige und benötigte<br />
Daten beinhalten.<br />
Bei den einfach assoziativen Caches ist die Auswahl am einfachsten. Man wählt für den<br />
Speicherzugriff einen Block im Cache aus. Wenn dieser keine Trefferquote aufweist, wird er<br />
ausgetauscht. Bei einem voll-oder mehrfach assoziativen Cache ist die Auswahl komplizierter.<br />
Man unterscheidet zwei Haupt-Strategien zur Auswahl des zu ersetzenden Blocks.<br />
Im ersten Fall benutzt man Zufallszahlen oder Pseudo- Zufallszahlen zur Steuerung der Auswahl.<br />
Der andere Ansatz lagert nach dem "LRU"-Prinzip (least recently used) jeweils den Block aus, der<br />
am längsten ungenutzt geblieben ist.<br />
Dazu muß die Anzahl der Zugriffe blockweise registriert werden. Man nutzt hier Prinzipien der<br />
räumlichen und zeitlichen Lokalität aus. Allerdings wird bei einer hohen Zahl der zu<br />
berücksichtigenden Blöcke der zum "Monitoring" der Zugriffe notwendige Aufwand sehr hoch. Man<br />
wird deshalb dieses Prinzip oft nicht komplett implementieren.<br />
Blockadresse<br />
LRU-Blocknummer<br />
- vier Blöcke (Nummer 0 bis 3)<br />
- zu Beginn ist 0 die LRU-Blocknummer<br />
FIFO<br />
Block-Nummer<br />
Auslagern / ersetzen<br />
3 2 1 0 0 2 3 1 3 0<br />
0 0 0 0 3 3 3 1 0 0 2<br />
3 2<br />
Abb. 10.8: LRU- und FIFO-Prinzip<br />
3<br />
1<br />
2<br />
3<br />
0<br />
1<br />
2<br />
3<br />
0<br />
1<br />
2<br />
3<br />
Noch einfacher als das LRU-Prinzip ist der FIFO: Man lagert einfach den Block aus, den man die<br />
größte Spanne von Takten zuvor benutzt hat, ohne die Cache-Misses explizit zu registrieren.<br />
Der Cache wurde vorrangig eingeführt, um die benötigten Informationen (Daten und Befehle)<br />
möglichst schnell lesen zu können. Alle Befehle werden nur gelesen, Daten können aber auch<br />
geschrieben werden.<br />
2<br />
0<br />
1<br />
3<br />
3<br />
2<br />
0<br />
1<br />
1<br />
3<br />
2<br />
0<br />
3<br />
1<br />
2<br />
0<br />
0<br />
3<br />
1<br />
2
Informatik V-Teil 2,Kap. 10, SS 99<br />
Die Rolle des Cache beim Schreiben von Daten ist also noch zu klären. Insgesamt macht das<br />
Schreiben im Mittel nur ca. 10% des Speicherverkehrs aus, stellt also keinen vorrangigen Engpaß<br />
dar. Trotzdem ist dieser Aspekt nicht zu vernachlässigen.<br />
Ein Block kann in derselben Zeit, in der das Tag gelesen und verglichen wird, bereits gelesen<br />
werden. Das Lesen eines Blocks beginnt also, sobald seine Adresse verfügbar ist. Ist das Lesen ein<br />
Treffer, so wird der Block gleich zur CPU übertragen, tritt ein Fehlgriff auf, so wird das Lesen<br />
abgebrochen. Ein Zeitverlust entsteht nicht.<br />
Beim Schreiben sind die Verhältnisse anders. Der Prozessor stellt zunächst die Größe des<br />
Schreibzugriffs fest, meistens 1 bis 8 Byte (Byte bis Langwort), und nur der entsprechende Teil eines<br />
Blocks kann geändert werden.<br />
Man kann den Vorgang auch wie folgt als mehrstufige Operation darstellen:<br />
1. Lesen des Originalblocks<br />
2. Modifizieren des Blocks bzw. eines Teils<br />
3. Schreiben des neuen Blocks<br />
Die Modifikation kann erst beginnen, nachdem mittels des Tag geprüft wurde, ob der betreffende<br />
Speicherzugriff ein Treffer war. Da man mit dem Schreiben, ganz im Gegensatz zum Lesen, nicht<br />
überlappend parallel zur Tag-Prüfung beginnen kann, dauert notwendigerweise das Schreiben länger<br />
als das Lesen.<br />
Für das Schreiben gibt es zwei unterschiedliche Strategien:<br />
− Write-through: Die Information wird sowohl in den Cache als auch in die nächste Ebene der<br />
Speicher-Hierarchie "durchgeschrieben".<br />
− Write-back: Die Information wird nur in den Block im Cache geschrieben. Der modifizierte<br />
Cache-Block wird erst dann in den Hauptspeicher zurückgeschrieben, wenn er durch einen<br />
anderen Block ersetzt werden muß.<br />
Im zweiten Fall kann es dazu kommen, daß im Cache eine andere Information steht als im<br />
Hauptspeicher. Man unterscheidet dann auch zwischen "clean" und "dirty" Blöcken im Cache, wobei<br />
die ersteren die sind, welche unmodifiziert im Hauptspeicher stehen, im zweiten Fall gibt es<br />
Unterschiede.<br />
Zur Kennzeichnung der einzelnen Blöcke wird denen oft noch ein spezielles Dirty-Bit beigegeben,<br />
um ein mehrfaches Rückschreiben auszuschließen. Bei nicht modifizierten Blöcken wird das<br />
Rückschreiben also ausgeschlossen.<br />
Beim Write-Back erfolgt das Rückschreiben von Daten von Registern in den Cache mit der relativ<br />
hohen Geschwindigkeit des Cache. Mehrfaches Schreiben innerhalb eines Blocks erfordert zur<br />
Wiederherstellung der Konsistenz nur einen Schreibvorgang vom Cache zum Hauptspeicher. Der<br />
Datenverkehr vom Cache zum Hauptspeicher wird also vergleichsweise niedriger als beim "Write<br />
Through" sein.<br />
Damit ist diese Methode speziell für Multi-Prozessor-Systeme interessant.<br />
Dagegen ist beim "Write Through" stets automatisch eine Konsistenz zwischen Cache und<br />
Hauptspeicher hergestellt, auch ist der Aufwand für die Implementierung geringer. Der<br />
Hauptspeicher enthält automatisch immer die aktuellste Kopie der Daten. Das ist für Multi-<br />
Prozessor-Systeme und für Ein- /Ausgabe-Prozeduren wichtig.<br />
Multiprozessoren würden also ein Write-back zur Verringerung des Speicher-Verkehrs und ein<br />
Write-through zur Konsistenzerhaltung benötigen.<br />
Beim Write-through kann durchaus der Fall auftreten, daß die CPU auf die Fertigstellung des<br />
Schreibens warten muß. Man spricht dann von einem Write-Stall.<br />
9
Informatik V-Teil 2,Kap. 10, SS 99<br />
Dieser kann durch den Einsatz eines Schreibpuffers (write buffer) zumindest teilweise vermieden<br />
werden. Daten werden im write buffer gespeichert, solange das Rückschreiben nicht beendet ist, der<br />
Prozessor kann sich derweil anders beschäfigen. Auch dann können allerdings noch Wartezyklen<br />
auftreten, z. B. wenn der Block auch nicht im Hauptspeicher vorhanden ist, sondern auf die<br />
Festplatte zurückgeschrieben werden muß.<br />
Auch beim Schreiben kann es Cache-Misses geben.<br />
Dann kann auf zwei Arten reagiert werden:<br />
Write-allocate oder "fetch on write": Der entsprechende Block wird in den Cache geladen und dann<br />
eine normale Write-Operation durchgeführt.<br />
No-write-allocate oder "write around": Der Block wird gar nicht mehr im Cache behandelt, sondern<br />
gleich auf die nächste Ebene zurückgeschrieben.<br />
Beide Strategien können sowohl mit dem write-through als auch mit dem write-back verknüpft<br />
werden. Praktisch hat es sich aber durchgesetzt, daß die "Write-back-Caches" die "write-allocate"-<br />
Methode benutzen, während Write-through-Caches meistens "no-write-allocate" benutzen.<br />
Imm ersten Fall hofft man, daß ein späteres Schreiben in den Block vom Cache abgefanden wird, im<br />
zweiten Fall müßte ja späteres Schreiben in jedem Fall auch noch zum Hauptspeicher gehen.<br />
10.4.1 Die Cache-Leistung<br />
Die CPU-Zeit einer Maschine kann aufgespalten werden in einen Anteil, in dem das Programm<br />
ausgeführt wird, und einen anderen Teil, in dem die CPU auf das Speichersystem wartet.<br />
Damit kann man für die CPU-Zeit eines Programms schreiben:<br />
CPU-Zeit = (CPU-Taktzyklen zur Ausführung + Speicher-Wartezyklen) * Taktzyklus-Zeit<br />
Für die relative Bewertung verschiedener Cache-Implementierungen zueinander kann man in erster<br />
Näherung den Einfluß von Wartezyklen anderer Art (z. B. durch den Zugriff vom Hauptspeicher zur<br />
Platte) vernachlässigen.<br />
Die Speicher-Wartezyklen sind außerdem beschreibbar durch:<br />
Speicher-Wartezyklen = Speicherzugriffe / Programm * Fehlzugriffsrate * Fehlzugriffstakte.<br />
Die Befehlszahl (IC) kann man noch aus Ausführungszeit und Speicher-Wartezyklen ausklammern<br />
und erhält:<br />
CPU-Zeit = IC * (CPIAusführung + Speicherzugriffe / Befehl * Fehlzugriffsrate * Fehlzugriffs-takte)<br />
* Taktzykluszeit<br />
Den Einfluß der Cache-Organisation soll ein Beispiel zeigen:<br />
Bei der VAX 11/ 780 verursacht ein Cache-Fehlzugriff 6 zusätzliche Taktzyklen. Die "normalen"<br />
Befehle benötigen zur Ausführung etwa 8,5 Taktzyklen.<br />
Bei einer Fehlzugriffsrate von 11% und einer mittleren Anzahl von 3 Speicherzugriffen pro Befehl<br />
erhöht sich die CPU-Zeit von 8,5 auf 10,5.<br />
Der Einfluß der Speicherhierarchie dehnt die CPU-Zeit im 24 % aus.<br />
Nehmen wir nun für eine modernere Maschine an, daß pro Befehl im Mittel nur noch 1,5 Taktzyklen<br />
notwendig sind, aber ein Cache-Fehler im Mittel 11 Taktzyklen erfordert. Die Fehlzugriffsrate<br />
betrage wieder 11%, nun aber bei nur noch 1,4 Speicherzugriffen pro Befehl.<br />
10
Informatik V-Teil 2,Kap. 10, SS 99<br />
Jetzt erhöht sich unter Einschluß der Cache-Fehler die mitteler CPU-Zeit von 1,5 auf 3, wird also nur<br />
durch Cache-Misses verdoppelt.<br />
Man kann deshalb feststellen:<br />
− Je geringer der CPI-Wert ist, umso größer sind die Cache-Misses für die Leistung des<br />
Gesamtsystems.<br />
− Hauptspeicher haben, unabhängig von der Leistung der CPU, im Mittel dieselbe Zugriffszeit, da<br />
die DRAMs weitgehend statndardisiert sind.<br />
Deshalb wirken sich Cache-Misses umso mehr aus, je höher die Taktrate der CPU relativ zur<br />
maximalen Frequenz der Speicherzugriffe ist.<br />
Jetzt können wir auch verstehen, weshalb leistungsfähigere Prozessoren sowohl größere Caches als<br />
auch unter Umständen die Einführung mehrerer Cache-Stufen notwendig machen. Die Auswirkungen<br />
erstrecken sich darüber hinaus auch auf die mehr oder weniger gut funktionierende<br />
Füllung von Pipelines.<br />
10.4.2 Quellen von Cache-Fehlzugriffen<br />
Als Quellen von Cache-Misses kann man mehrere Effekte unterscheiden:<br />
1. Erstbelegung (compulsory)<br />
Beim ersten Zugriff auf einen Speicher-Block ist dieser nicht im Cache, sondern muß erst aus dem<br />
Hauptspeicher geholt werden.<br />
2. Kapazität (capacity)<br />
Wenn ein Cache nicht alle während der Ausführung eines Programms benötigten Blöcke beinhalten<br />
kann, dann ergeben sich Fehlzugriffe durch zwischenzeitlich notwendigerweise ausgelagerte<br />
(verworfene) und ein- oder mehrfach wiederhergestellte Blöcke.<br />
3. Konflikt (conflict)<br />
Ist die Block-Plazierung ein- oder mehrfach assoziativ, so können sich zusätzliche Zugriffskonflikte<br />
ergeben, weil ein Block verworfen und später wiederhergestellt wird. Dies ist dann aber nicht auf<br />
einen absoluten Kapazitätsengpaß zurückzuführen, sondern weil zu viele Blöcke einem ausgelagerten<br />
Set zugeordnet sind. Nur bei voll assoziativen Caches würde man solche Probleme vermeiden.<br />
Die Modellierung des Verhaltens eines Caches mit den oben dargestellten Konflikt-Typen wird auch<br />
als "3 C-Modell" bezeichnet.<br />
Die Auswertung experimenteller Ergebnisse zeigt, daß zunächst die Zugriffe durch<br />
Kapazitätsengpässe bei kleinen Caches überwiegen (bis ca. 32 kB). Dagegen steigen die Konflikte<br />
durch ungünstige Erstbelegung anteilsmäßig sowohl mit der Größe des Caches als auch mit dem<br />
Grad der Assoziativität an. Dagegen gewinnen Misses des "conflict" - Typs eher bei niedrigen<br />
Graden der Assoziativität und größeren Speichern Bedeutung.<br />
Eine resultierende Faustregel besagt, daß ein einfach assoziativer Cache der Größe N ungefähr die<br />
gleiche Fehl-Zugriffsrate hat wie ein 2-fach assoziativer Cache der Größe N / 2.<br />
Natürlich hat auch die Auswahl der Block-Größen absolut und im Verhältnis zur Cache.Größe<br />
Bedeutung. Größere Blöcke reduzieren die Zahl der Misses bei Erstzugriffen, sie bewirken aber auch<br />
eine Verringerung der Zahl der Blöcke im Cache und erzeugen damit mehr Konflikte. Üblich sind<br />
Block-Größen zwischen 1 KByte und etwa 256 KB.<br />
11
Informatik V-Teil 2,Kap. 10, SS 99<br />
In modernen Prozessoren werden oft Daten- und Befehlscaches getrennt. Man kann diese dann<br />
separat bezüglich der Block-Größen und der Assoziativität optimieren. Beispielsweise haben<br />
Befehls-Caches typischerweise geringere Miss-Raten als Daten-Caches. Die Prozessoren der Intel<br />
80X86-Familie sind ab dem 80486 (on-chip-Befehlcache) mit Caches versehen, und zwar getrennt<br />
nach Daten und Befehlen (nicht mehr im Second-Level-Cache auf dem Mutterbrettern).<br />
10.5 Hauptspeicher<br />
10.5.1 Einführung<br />
Im einfachsten Fall, das heißt ohne einen "second level cache", ist der Hauptspeicher die nächste<br />
Hierarchie-Ebene unter dem Cache. Der Hauptspeicher hat Kommunikation sowohl mit dem Cache<br />
als auch mit Eingabe- und Ausgabe-Einheiten, denen er als Ziel bzw. als Quelle dient.<br />
Von Bedeutung für andere Funktionseinheiten sind sowohl die Latenzzeit des Hauptspeichers, d. h.<br />
die Zeit, die ein Speicherzugriff durch den Prozessor benötigt, als auch die Speicher-Bandbreite, das<br />
ist die Anzahl der pro Zeiteinheit maximal möglichen Speicherzugriffe.<br />
Für die Speicher-Latenzzeit werden oft zwei Maße angegeben, Zugriffszeit und Zykluszeit. Die<br />
Zugriffszeit ist die Zeit zwischen der Anforderung eines Speicherzugriffs (Lesezugriff) und dem<br />
Eintreffen des entsprechenden Wortes. Die Zykluszeit (cycle time) ist der minimale Zeitabstand<br />
zwischen zwei Speicheranforderungen.<br />
Zeilenadressierung<br />
Abb. 10.9: Speichermatrix<br />
Spalten-Adressierung<br />
In den 70er Jahren hat es sich eingebürgert, daß Halbleiter-Speicher zur Reduzierung der Anzahl der<br />
Anschlußpins die Adresse multiplexend in zwei Schritten übertragen, und zwar zunächst die Zeilen-<br />
Adresse (Row Access-Strobe, RAS), danach die Spaltenadresse (Column-Address-Strobe, CAS).<br />
Dies kostet natürlich Zugriffszeit. Zusätzlich müssen dynamische RAMs (DRAMs) regelmäßig einen<br />
Refresh erhalten, ca. alle 2 ms. Deshalb ist das Speichersystem gelegentlich nicht verfügbar. Ein<br />
Refresh-Zyklus benötigt einen vollen Speicherzugriffs-Zyklus (RAS und CAS) für jede Zeile des<br />
DRAMs. Damit ist die Zahl der Refresh-Schritte meistens gegeben (bei quadratischer<br />
Speichermatrix) durch die Quadratwurzel aus der DRAM-Kapazität.<br />
Bei statischen Speicher-Bausteinen (SRAMs) ist die Speicherzelle nicht, wie bei den DRAMs, nur<br />
aus jeweils einem Transistor (plus Speicher-Kondensator als Kapazität) aufgebaut, sondern ist aus<br />
vier Transistoren aufgebaut. Damit spart man auf Kosten der Speichergröße bzw. der Speicherdichte<br />
(etwa Faktor 4) das bei dynamischen RAMs nötige Rückschreiben einer gelesenen Information.<br />
Entsprechend verkürzen sich Zugriffs- und die Zykluszeit etwa um den Faktor 16. Da man bei<br />
SRAMs auf Geschwindigkeit optimiert, werden generell die Adressleitungen auch nicht im<br />
Multiplex-Betrieb genutzt.<br />
12
Informatik V-Teil 2,Kap. 10, SS 99<br />
Zeilenzugriff Spaltenzugriff Zykluszeit<br />
(RAS)<br />
langs. schnell<br />
Einführung Chip-Grösse DRAM DRAM (CAS)<br />
1980 64 kBit 180 ns 150 ns 75 ns 250 ns<br />
1983 256 KBit 150 ns 120 ns 50 ns 220 ns<br />
1986 1 MBit 120 ns 100 ns 25 ns 190 ns<br />
1989 4 MBit 100 ns 80 ns 20 ns 165 ns<br />
1992 16 MBit 85 ns 60 ns 15 ns 140 ns<br />
1996 64 MBit 70 ns 50 ns 12ns 120 ns<br />
Abb. 10.10: Größen und Zugriffszeiten bei dynamischen RAM-Bausteinen<br />
Wen man sich vergleichsweise die Entwicklung bei schnellen CPUs ansieht, so ist seit 1980 bis 1992<br />
deren Leistung um den Faktor 1000 gewachsen. Während also die Entwicklung der Speichergrößen<br />
mit der Entwicklung der CPU-Leistung noch in etwa schrittgehalten hat, ist das nur unwesentlich<br />
verbesserte Zeitverhalten dynamischer RAMs ein besonderer Bremsklotz bei der Systementwicklung<br />
geworden und muß durch vielfältige Tricks, von denen der Cache nur einer ist, überwunden werden.<br />
10.5.2 Organisationsformen zur Steigerung der Hauptspeicher-Leistung<br />
Allgemein ist es technologisch leichter, durch neue Organisationsformen die Speicher-Bandbreite zu<br />
erhöhen, als die Latenzzeit des Speichers zu reduzieren. Man wird z. B. die Cache-Blockgröße<br />
erhöhen können, ohne einen Anstieg der Fehlzugriffsraten befürchten zu müssen.<br />
Für ein Beispiel sei angenommen, daß der Speicherzugriff wie folgt organisiert ist:<br />
− 1 Taktzyklus zum Senden der Adresse<br />
− 6 Taktzyklen als Zugriffszeit zum Wort<br />
− 1 Taktzyklus zum Senden des Datenwortes<br />
Gegeben sei außerdem ein Cache-Block mit vier Worten, eine Fehlzugriffszeit von 32 Taktzyklen<br />
und eine Speicher-Bandbreite von 0,5 Byte pro Taktzyklus.<br />
Wesentliche Möglichkeiten zur Leistungssteigerung sind eine breite <strong>Speicherorganisation</strong> oder eine<br />
verschränkte <strong>Speicherorganisation</strong>.<br />
1-Wort-breite<br />
<strong>Speicherorganisation</strong><br />
CPU CPU CPU<br />
Cache<br />
Speicher<br />
Bus<br />
breite<br />
<strong>Speicherorganisation</strong><br />
Multiplexer<br />
Cache<br />
Bus<br />
Speicher<br />
Abb. 10.11: Arten der <strong>Speicherorganisation</strong><br />
13<br />
verschränkte<br />
<strong>Speicherorganisation</strong><br />
Bus<br />
Cache<br />
Speicher Speicher Speicher Speicher<br />
Bank 0 Bank 1 Bank 2 Bank 3
Informatik V-Teil 2,Kap. 10, SS 99<br />
Caches sind fast immer für eine Bit-Breite von einem Datenwort (also meistens 32 Bit) organisiert,<br />
weil auch die meisten CPU-Zugriffe diese Breite haben. Entsprechend ist auch der Hauptspeicher<br />
generell für eine Breite von einem Wort organisiert, um wiederum mit Cache und CPU<br />
zusammenzupassen. Es ist nun aber auch möglich, den Speicher so zu organisieren, daß nicht nur ein<br />
Wort, sondern mit größerer Breite parallel zugegriffen werden kann. Damit erhöht sich auch die<br />
Speicher-Bandbreite.<br />
Bei einer Hauptspeicherbreite von 2 Worten würde in unserem Beispiel die Fehlzugriffszeit von 4<br />
mal 8 oder 32 Taktzyklen auf 2 mal 8 oder 16 Taktzyklen sinken. Bei vier Worten Breite beträgt die<br />
Fehlzugriffszeit nur noch 1 mal 8 Taktzyklen.<br />
Leider verursacht der dann notwendige breitere Bus zwischen Speicher und Cache erhebliche<br />
Zusatzkosten. Die CPU greift auf den Cache immer noch wortweise zu. Deshalb werden Multiplexer<br />
zwischen Cache und CPU benötigt. Diese Multiplexer befinden sich dann gerade im zeitkritischen<br />
Pfad. Ist der Cache schneller als der Bus, so kann man die Multiplexer auch zwischen Cache und Bus<br />
anordnen.<br />
In einer solchen Konfiguration kann man auch den Hauptspeicher nicht mehr beliebig erweitern.<br />
Erweiterung bedeutet dann Verdopplung, Vervielfachung etc.<br />
Speicher sind auch in der Regel fehlerkorrigierend, und zwar ist diese Korrektur Byte-weise<br />
organisiert. Bei den Lese- und Schreibverfahren muß man also die modifizierte Speicher-organisation<br />
berücksichtigen. Viele Entwürfe breiterer Speicher haben eine spezielle Fehler-erkennung und -<br />
Korrektur für 32 Bit-Worte.<br />
Die andere Möglichkeit zur Verbesserung der <strong>Speicherorganisation</strong> ist der verschränkte Speicher.<br />
Speicherchips können in sogenannten "Bänken" organisiert sein, um damit mehrere Worte<br />
gleichzeitig zu lesen oder zu schreiben. Die einzelnen Bänke sind jeweils 1 Wort breit, womit die<br />
Organisation von Bus und Cache nicht geändert werden muß. Adressen können nun zu<br />
verschiedenen Bänken gesendet werden.<br />
Sendet man beispielsweise eine Adresse an vier Bänke, so gibt das eine Zugriffszeit (siehe Beispiel)<br />
von 1+6+4*1 oder 11 Taktzyklen, was wiederum einer Bandbreite von 1,5 Byte pro Taktzyklus<br />
entspricht.<br />
Bänke sind auch für Schreiboperationen nützlich. Während normalerweise bei jedem Schreibzugriff<br />
gewartet werden muß, bis ein vorhergehender Schreibvorgang beendet ist, benötigt man jetzt nur<br />
noch einen Taktzyklus für den Schreibvorgang, vorausgesetzt daß der vorhergehende<br />
Schreibvorgang nicht auf dieselbe Bank erfolgte.<br />
Natürlich ist es notwendig, die Adressierung der Speicherbänke speziell zu organisieren. Die<br />
Adressen sind auf der Wortebene miteinander verschränkt. Als Beispiel wird ein Speicher mit vier<br />
Bänken betrachtet. Bank 0 beinhaltet dann alle Worte, deren Adresse modulo vier gleich 0 ist (also<br />
0, 4 , 8 usw), Bank 1 alle Adressen, die modulo 4 gleich 1 sind (1, 5, usw.) Man bezeichet dies als<br />
Verschränkungsfaktor mit verschränktem Speicher.<br />
Bei der generellen Speicher-Organisation spielt natürlich auch die Wechselwirkung mit dem Cache<br />
und dabei das Verhalten bei Cache-Fehlzugriffen eine Rolle.<br />
Ein Write-Back-Cache führt Lese- und Schreiboperationen sequentiell aus, was recht gut zur<br />
verschränkten Organisation des in Bänke organisierten Speichers paßt, da dort ebenfalls ein<br />
sequentieller Zugriff erfolgt.<br />
Der Speicher kann nun auch so organisiert sein, daß mehrere Controller vorhanden sind und auch<br />
eine unabhängige Funktion der einzelnen Speicherbänke ermöglichen. Damit können z. B. mehrere<br />
periphere Baugruppen über einen jeweils eigenen Controller parallel und unabhängig auf<br />
verschiedene Speicherbänke zugreifen. Eine solche Möglichkeit erhöht die Gesamtleistung eines<br />
Rechners unter Umständen beträchtlich.<br />
Die Aufteilung eines Speichers auf mehrere Bänke funktioniert so lange recht gut, wie man eine<br />
größere Anzahl wahlweise zuordbarer RAM-Chips hat. Bei Verwendung nur weniger Speicher-ICs<br />
mit hoher Kapazität laßt sich diese Verschränkung nicht mehr organisieren.<br />
14
Informatik V-Teil 2,Kap. 10, SS 99<br />
Deshalb spielt die verschränkte Organisation mit mehreren Bänken heute bei PCs keine wesentliche<br />
Rolle mehr.<br />
Speziell für DRAMs gibt es angepaßte Verschränkungsmethoden zur Verbesserung der<br />
Hauptspeicherleistung. Die Zugriffszeit bei DRAMs wird in Zeilenzugriff und Spaltenzugriff<br />
unterteilt. Dabei puffern die DRAMs intern eine Bit-Zeile für den Spaltenzugriff. Diese Spalte hat<br />
eine Größe, welche durch die Quadratwurzel aus der Speichergröße bestimmt ist, also z. B. 1024 Bit<br />
für 1 MBit-Speicher und 2048 Bit für 4 MBit-Bausteine beträgt.<br />
Die üblichen DRAMs sind nun so aufgebaut, daß sie einen wiederholten Zugriff zu diesem<br />
Zwischenpuffer ohne die jeweilige zusätzliche Zeilen-Zugriffszeit ermöglichen. Dazu gibt es<br />
verschiedene "Modi".<br />
− Nibble-Modus: Für jeden Zeilenzugriff können bis zu 3 Bits auf nacheinander folgenden<br />
Speicherplätzen mit einer Zeilen-Adressierung gelesen und transferiert werden.<br />
− Seiten-Modus: Der Puffer bewirkt, daß sich der DRAM-Baustein nach außen wie ein SRAM<br />
verhält. Nur durch Änderung der Spaltenadresse kann auf den Puffer bis zum nächsten<br />
Zeilenzugriff oder Refresh zugegriffen werden.<br />
− Statische Spalte (static column): Entspricht dem Seiten-Modus bis auf den Unterschied, daß nicht<br />
jeweils die CAS-Leitung des DRAMs bei einer Änderung der Spaltenadresse angeprochen werden<br />
muß.<br />
Weiterhin können DRAMs heute teilweise im BURST-Modus betrieben werden. Ein in 1-Bit-Breite<br />
organisiertes DRAM liest dabei nacheinander die Inhalte mehrerer (z. B. 4) aufeinanderfolgender<br />
Speicheradressen in vier optimierten Zyklen ein oder aus, ohne jeweils eine explizite Speicher-<br />
Adressierung durchzuführen. Damit ist die Zugriffszeit wesentlich verringerbar. EDO-RAMs<br />
erlauben durch Zwischenspeicherung teilweise überlappende Lese- und Schreibphasen. Natürlich<br />
erfordern solche Methoden eine optimierte Zeitsteuerung<br />
Meistens sind die reinen Speicherchips so gefertigt, daß sie je nach Anschluß der vorhandenen Pads<br />
an die Außenwelt (über das Gehäuse) die eine oder andere Option unterstützen.<br />
10.6 Virtueller Speicher<br />
10.6.1 Einführung<br />
In der Steinzeit der Rechner-Technologie war es eine wesentliche Aufgabe des Programmierers,<br />
dafür zu sorgen, daß sein Programm nie mehr als den physikalisch vorhandenen Speicher eines<br />
Rechners benutzte. Dies ging soweit, daß vom Nutzerprogramm aus das Laden von Programmteilen<br />
in den Hauptspeicher und Ersetzen gegen andere Programmteile zu organisieren war. Damit war ein<br />
Programmierer schon fast damit ausgelastet, an den Grenzen der jeweiligen Maschine entlang zu<br />
programmieren, entsprechend war die Produktivität niedrig.<br />
Erst die Einführung des virtuellen Speichers änderte diesen Zustand:<br />
Mit der Einführung virtuellen Speichers ist diese Begrenzung aufgelöst.<br />
Der verfügbare Adreßraum ist von physischen Speicherausbau entkoppelt.<br />
Dazu wird die nächste Ebene der Speicherhierarchie, der sekundäre Speicher, in die Speicherverwaltung<br />
insgesamt einbezogen. Ein im Hauptspeicher ablaufendes Programm kann also auch<br />
Daten adressieren, die auf dem Plattenspeicher eines Rechners vorhanden sind und zur Bearbeitung<br />
in den Hauptspeicher geladen werden müssen.<br />
15
Informatik V-Teil 2,Kap. 10, SS 99<br />
Ganz im Unterschied zum Programmablauf in Maschinen ohne virtuelle Speicherverwaltung kann auf<br />
der virtuellen Maschine auch ein Programm an beliebiger Stelle im Arbeitsspeicher stehen, es ist nicht<br />
mehr festen Speicheradressen zugewiesen.<br />
Eine weitere wichtige Aufgabe der virtuellen Speicherverwaltung ist die Organisation des Ablaufs<br />
mehrere Prozesse (also z. B. mehrerer Programme) nebenläufig auf demselben Rechner. Dazu wird<br />
der Speicher in Blöcke aufgeteilt, die jeweils verschiedenen Prozessen zugeordnet sind. Dazu muß es<br />
einen Schutzmechanismus geben, der dafür sorgt, daß ein Prozeß nur auf die ihm zugeordneten<br />
Blöcke zugreift.<br />
(Ein Problem von DOS-Rechnern war lange Zeit, daß sie nur den Adreßraum des physischen<br />
Speichers kannten, bis zu 2**16 Adressen, und keine Schutzmechanismen implementiert hatten).<br />
Verschiedene Begriffe aus der Speichertechnik, die wir vorstehend schon verwendet haben, tauchen<br />
bei den virtuellen Speichern in ähnlicher Form wieder auf:<br />
Man benutzt Seite (page) oder Segment anstelle von Block,<br />
Seitenfehler (page faults) und Adreßfehler (address faults) spielen bei Fehlzugriffen (misses) eine<br />
Rolle.<br />
Bei einem virtuellen Speicher erzeugt die CPU entsprechend virtuelle Adressen, die durch Hardware<br />
und Software in physische Adressen übersetzt werden müssen und die dem Zugriff auf den<br />
Hauptspeicher dienen. Dieser Vorgang wird als Speicherzuordnung (memory mapping) oder<br />
Adressumsetzung (address translation) bezeichnet. Heute sind die beiden Ebenen der<br />
Speicherhierarchie, die durch den virtuellen Speicher gesteuert werden, DRAMs und Magnetplatten.<br />
Block (Seiten-) Größe 512 - 8192 Byte<br />
Trefferzeit 110 Taktzyklen<br />
Fehlzugriffszeit 100.000 - 600.000 Taktzyklen<br />
(Zugriffszeit) 100.000 - 500.000 Taktzyklen<br />
(Transferzeit) 10.000 - 100.000 Taktzyklen<br />
Fehlzugriffsrate 0,00001% - 0,001%<br />
Hauptspeichergröße 4 MB - 2048 MB<br />
Abb. 10.12: Typische Dimensionen bei virtuellen Speichern<br />
Die typischen Dimensionen des virtuellen Speichers liegen also, im Vergleich zum Cache, ca.<br />
10 000 bis 100 000 mal darüber.<br />
Es gibt aber noch einige weitere signifikante Unterschiede zwischen dieser und der höheren Ebene<br />
der Speicher-Hierarchie:<br />
− Die Ersetzung von Blöcken im Cache nach einem Fehlzugriff wird vorrangig durch Hardware<br />
gesteuert. Dagegen erfolgt die Verwaltung des virtuellen Speichers durch das Betriebssystem. Die<br />
wesentlich längere Fehlzugriffszeit bedeutet auch, daß das Betriebssystem einen relativ hohen<br />
Aufwand treibt um zu entscheiden, welche Blöcke zu ersetzen sind.<br />
− Die Größe des Adreßraums des Prozessors bestimmt die maximale Größe des virtuellen<br />
Speichers. Dagegen ist die Cache-Größe davon weitgehend unabhängig (so große Caches gibts<br />
nicht).<br />
− Zusätzlich zur Funktion als "virtueller Hauptspeicher" wird die Platte auch für das File-System<br />
genutzt (und zwar vor allem). Dieses File-System ist natürlich nicht auf den Adreßraum<br />
abgebildet, sondern ist davon völlig unabhängig.<br />
16
Informatik V-Teil 2,Kap. 10, SS 99<br />
Die Organisation des virtuellen Speichers kann mittels Blöcken fester Größe, die auch als Seiten<br />
(pages) bezeichnet werden, oder mit Blöcken variabler Größe, die als Segmente bezeichnet werden,<br />
organisiert.<br />
Seiten-Größen liegen typisch zwischen 512 und 8192 Bytes. Das kleinste Segment ist 1 Byte, die<br />
größten unterstützten Segmente liegen zwischen 2**16 und 2 ** 32 Byte.<br />
Ob in Seiten aufgeteilter oder ein segmentierter Hauptspeicher benutzt wird, hängt vom Typ der<br />
verwendeten Rechner-CPU ab.<br />
Die Seiten-Adressierung kommt mit einfachen Adressen fester Größe aus, die wie beim Cache in<br />
Seitennummer und Offset aufgeteilt ist.<br />
Bei der Verwendung variabler Segmente ist ein Wort Adreßbreite für die Segmentnummer und ein<br />
zweites Wort für den Offset innerhalb des Segmentes notwendig.<br />
Worte pro Adresse<br />
sichtbar für<br />
Programmierer ?<br />
Blockersetzung<br />
Ineffizienz der<br />
Speichernutzung<br />
Effizienter<br />
Plattenverkehr<br />
unsichtbar für<br />
Seite Segment<br />
eins zwei (Segment u. Offset)<br />
Anwendungsprogramm.<br />
einfach (gleiche Blockgröße)<br />
interne Fragmentierung:<br />
(ungenutzte Teile der Seite)<br />
ja: Seitengröße wird ausgewogenem<br />
Verhälnis von Zugriffs- und Transferzeit<br />
angepaßt<br />
17<br />
kann für Anwender<br />
sichtbar sein<br />
schwierig: benötigt werden freie<br />
zusammanhängnde Hauptspeichersegmente<br />
variabler Größe<br />
externe Fragmentierung:<br />
ungenutzte Teile desHauptspeichers<br />
nicht immer: kleine Segmente<br />
übertragen nur einige Byte<br />
Abb. 10.13: Seiten-orientierte und Segment-orientierte <strong>Speicherorganisation</strong> im Vergleich<br />
Nach einer längeren Nutzungsdauer eines Rechners stellt sich automatisch eine gewisse Speicher-<br />
Fragmentierung ein. Es ergeben sich immer weniger größere zusammenhängende Speicherbereiche<br />
auf einer Platte. Damit wird es für einen nach dem Prinzip der Segementierung arbeitenden Rechner<br />
immer schwieriger, größere zusammenhängende Speicherbereiche zu finden. Die wenigsten<br />
Maschinen nutzen heute einen reinen Segmentierungs-Ansatz. Einige Maschinen verwenden eine<br />
Mischung aus beiden Ansätzen, sogenannte seiteneingeteilte Segmente (paged segnments). Dabei<br />
enthält ein Segment stets eine ganzzahlige Anzahl von Seiten.<br />
Dann muß der benötigte Speicherbereich nicht mehr unbedingt zusammenhängend sein, man muß<br />
auch nicht ein ganzes Segment im Hauptspeicher ablegen, sondern kann auch nur einen Teil der darin<br />
enthaltenen Seiten abspeichern.<br />
10.6.2 Organisation des virtuellen Speichers<br />
Wo ein Block im Hauptspeicher plaziert werden kann, ist eine Aufgabe, die das Betriebssystems zu<br />
organisieren hat. Ein Fehlzugriff auf den Hauptspeicher bewirkt die Notwendigkeit, auf die Platte<br />
zuzugreifen und dort die Bewegung der Lese- / Schreibköpfe zu organisieren. Damit ist ein<br />
Fehlzugriff von der benötigten Zeit her extrem teuer. Der Entwerfer des Betriebssystems hat einen<br />
Trade-off zwischen geringeren Fehlzugriffsraten und einfacheren Plazierungsalgorithmen.<br />
Praktischerweise wird man sich für die geringste zu erwartende Zahl der Fehlzugriffe entscheiden.<br />
Das Betriebssystem wird es also erlauben, Blöcke fast beliebig irgendwo im Hauptspeicher zu<br />
plazieren. Man könnte das, in Anlehnung an die Cache-Organisation, als eine voll assoziative<br />
Methode kennzeichnen.
Informatik V-Teil 2,Kap. 10, SS 99<br />
Ein weiteres Problem ist das effiziente Auffinden eines Datenblocks im Hauptspeicher. Einem<br />
Segment oder Block ist zunächst eine virtuelle Adresse zugeordnet, welche eine Block-oder<br />
Seitennummer plus einen Offset enthält.<br />
Zum Auffinden der physischen Adresse eines Blocks oder Segments im Hauptspeicher muß die<br />
physische Adresse erst gebildet werden.<br />
Beim Paging wird der Offset an die physische Adresse angehängt, bei der Segmentierung wird der<br />
Offset zur physischen Segmentadresse addiert, und man erhält so die virtuelle Adresse.<br />
virtuelle Adresse<br />
virtuelle<br />
Seitennummer<br />
Seitentabelle<br />
Seiten-<br />
Offset<br />
physische<br />
Adresse<br />
18<br />
Haupt-<br />
speicher<br />
Abb. 10.14: Zuordnung zwischen virtueller und physischer Adresse über eine Seitentabelle<br />
Die Datenstruktur, welche die physische Adresse enthält, ist oft eine sogenannte "Seitentabelle"<br />
(page table). Sie ordnet also einer virtuellen Seitennummer eine physische Adresse zu. Diese<br />
Seitentabelle kann eine erhebliche Größe annehmen. Hat man zum Beispiel eine virtuelle Adresse mit<br />
28 Bit Länge, eine Anzahl von 4 KB Seiten und vier Byte pro Eintrag in die Seitentabelle, so erhält<br />
die Seitentabelle eine Größe von 256 KB. Das Durchsuchen einer solchen Tabelle zur Adressbildung<br />
ist natürlich aufwendig. Da in der Regel die Anzahl der physischen Seiten im Hauptspeicher<br />
wesentlich kleiner ist als die im Adreßraum mögliche, wird man versuchen, mit einer solchen<br />
verkleinerten Tabelle auszukommen. Eine solche Struktur heißt invertierte Seitentabelle (inverted<br />
page table). Bei einem physischen Speicher von 64 MB würde man nur 64 KB für die Tabelle<br />
benötigen.<br />
In vielen Rechnern, die sowohl eine Segmentierung als auch eine Seiten-Organisation des Speichers<br />
verwenden, ist eine zweistufige Übersetzung einer logischen in eine physikalische Adresse mittels<br />
einer Segment-Tabelle (oder eines Segment-Registers) und einer Seitentabelle (page table)<br />
notwendig.<br />
32 Bit logische Adresse<br />
Hash-Fakt.<br />
4 28<br />
16 Segmentregister<br />
52 Bit virtuelle Adresse<br />
VSID 24 VPN 16 12<br />
Seitentabelle<br />
19 16<br />
32 Bitn physikalische Adresse<br />
RPN 20 12<br />
Abb. 10. 15: Adressbildung über Segmentregister und Seitentabellen
Informatik V-Teil 2,Kap. 10, SS 99<br />
In Abb. 10.15 ist dieser Prozeß für den IBM Power Prozessor dargestellt Typ 601, 603, 604). Hier<br />
werden zunächst vier Bit der logischen Tabelle zur Auswahl eines von 16 Segment-Registern<br />
verwendet. Hier überwachen Steuerbits in den Registern den Zugriffsschutz, die Auswahl des<br />
Adressraumes, der physikalischen Adressen, der virtuellen Adressen oder der Ein-/Ausgabeadressen.<br />
Ein 24 Bit großer Teil der Inhalte der Segmentregister, gewöhnlich als VSID (virtual<br />
segment identifier) bezeichnet, wird zur Bildung der physikalischen Adresse verwendet.<br />
Das Resultat ist eine 52 Bit breite virtuelle Adresse, die sich aus dem VSID und den niederwertigen<br />
28 Bit der logischen Adresse zusammensetzen.<br />
Diese wird dann der Seiten- oder Blockübersetzung unterworfen. Beim Power PC hat eine Seite eine<br />
feste Größe von 4 kByte. Ein Teil der virtuellen 52 Bit-Adresse, der aus 19 Bits der VSID und 16<br />
Bits der logischen Adresse, welche virtual page number (VPN) genannt werden, besteht, adressiert<br />
über eine Hash-Funktion einen Eintrag in der Seitentabelle. Dieser Eintrag wird daraufhin überprüft,<br />
ob die virtuelle Seitennummer des Eintrages mit der angelegten virtuellen Adresse übereinstimmt. Ist<br />
dies erfüllt, so wird eine physikalische Seitennummer erzeugt (real page number, PRN), die<br />
tatsächlich für den Speicherzugriff verwendet wird.<br />
Das Durchsuchen einer solchen Tabelle zur Adressbildung ist natürlich aufwendig. Da in der Regel<br />
die Anzahl der physischen Seiten im Hauptspeicher wesentlich kleiner ist als die im Adreßraum<br />
mögliche, wird man versuchen, mit einer solchen verkleinerten Tabelle auszukommen. Eine solche<br />
Struktur heißt invertierte Seitentabelle (inverted page table). Bei einem physischen Speicher von 64<br />
MB würde man nur 64 KB für die Tabelle benötigen.<br />
Die Leistung des Speichersystems ist natürlich stark vom Zeitaufwand für die Adreßbildung<br />
abhängig. Um die Zeit für die Adreßumsetzung zu minimieren, verwenden manche Rechner einen<br />
speziellen Cache, den Adreß-Umsetzungspuffer (translation lookaside-buffer, TLB).<br />
Im TLB werden die aktuellen Übersetzungen von logischen oder virtuellen Adressen auf<br />
physikalische Seitenadressen gehalten. Der TLB wird oft als Assoziativspeicher realisiert, der die<br />
angeforderten mit den gespeicherten Adressen assoziativ vergleicht. Er enthält meistens nur 32, 64<br />
oder 128 Abbildungspaare und ist bei High-End-Prozesoren auf dem Prozessorchip integriert.<br />
Der TLB ist, mit zusätzlicher Logik, Teil der Memory Management Unit (MMU). In Prozessoren,<br />
die getrennte Caches für Befehle und Daten verwenden, werden gleich 2 getrennte MMUs benötigt.<br />
Wie beim Cache stellt sich auch beim Hauptspeicher das Problem der Ersetzung des richtigen Blocks<br />
im Fall eines Fehlzugriffs auf den Hauptspeicher. Es ist vor allem notwendig, geschickt zu<br />
entscheiden, welche Blöcke ausgelagert werden können.<br />
Das Betriebssystem des Rechners hat die vorrangige Aufgabe, durch richtige Entscheidungen die<br />
Anzahl der Seitenfehler zu minimieren. Fast alle Betriebssysteme stellen fest, welcher Block am<br />
längsten nicht genutzt wurde und lagern diesen Block aus (least recently used - LRU - Methode).<br />
Dazu muß das Betriebssystem eine Statistik über die Zugriffsgeschichte der im Hauptspeicher<br />
vorhandenen Blöcke führen. Viele Maschinen setzen deshalb ein Use- oder Referenz-Bit für eine<br />
bestimmte Seite, wenn auf diese zugegriffen wurde. Das Betriebssystem liest diese Use-Bits<br />
periodisch, speichert sie und setzt sie für den Block zurück. Mittels der permanent geführten Statistik<br />
ist es dann möglich, den LRU-Block zu identifizieren.<br />
Wenn Blöcke oder Seiten nicht nur gelesen, sondern auch durch Schreiben verändert werden, so<br />
ergibt sich ein Konsistenzproblem. Eine Seite, die im Hauptspeicher geändert wurde, ist nicht mehr<br />
mit ihrer Kopie auf der Platte identisch.<br />
Die einfachste Strategie wäre ein direktes Zurückschreiben der jeweiligen Seite auf die Platte nach<br />
jeder Änderung, aber die Zugriffszeiten von hunderttausenden von Taktzyklen der CPU für einen<br />
Plattenzugriff lassen diese Strategie nicht zu.<br />
Die Zugriffsstrategie kann also nur ein "write-back" in größeren Zeitabständen beinhalten. Dazu muß<br />
jede modifizierte Seite ein "dirty"-Bit enthalten, das erst nach dem write-back gelöscht wird. Es<br />
werden dann beim write-back nur die Blöcke zurückgeschrieben, die durch das Dirty-Bit als geändert<br />
gelten können.<br />
19
Informatik V-Teil 2,Kap. 10, SS 99<br />
10.6.3 Auswahl der Seitengrößen<br />
Die Auswahl einer geeigneten Seitengröße ist ein kritischer Parameter für die Optimierung des<br />
Speichersystems insgesamt. Einige Aspekte sprechen für große Seiten:<br />
Die Seitentabelle für die Adreßbildung ist bezüglich ihrer Größe umgekehrt proportional zur<br />
Seitengröße. Mit kleineren Tabellen und größeren Seiten kann man also Speichergröße sparen.<br />
Die Übertragung weniger großer Seiten ist insgesamt effektiver als die getrennte Übertragung vieler<br />
kleiner Seiten. Größere Seiten sind auch günstiger für die Adreßumsetzung der Cache-Adressen.<br />
Für kleine Seitengrößen spricht dagegen die potentielle Einsparung an Speicherplatz. Kleine Seiten<br />
verschwenden weniger Speicherplatz, wenn ein zusammenhängender Bereich des virtuellen Speichers<br />
kleiner ist als ein Vielfaches der Seitengröße. Bei Speichergrößen des Hauptspeichers von mehreren<br />
bis vielen MByte und Seitengrößen von 2KB bis 8 KB spielt dieser Effekt nock keine Rolle, wohl<br />
aber bei Seitengrößen von 32BK und mehr.<br />
10.6.4 Techniken für schnelle Adreßumsetzung<br />
Seitentabellen sind oft so groß, daß sie im Hauptspeicher untergebracht werden müssen (nicht im<br />
Cache) und selbst einige Seiten lang sind. Man würde damit zwei Speicherzugriffe für eine<br />
Adressierung benötigen: Einen, um mittels der Page-Tabelle die physikalische Adresse zu ermitteln,<br />
und einen zweiten, um die Daten tatsächlich aus dem Speicher zu holen. Da der Speicherzugriff<br />
grundsätzlich einen Engpaß bezüglich der erreichbaren Rechenleistung darstellt, ist eine solche<br />
Kombination nicht vertretbar.<br />
Bei Speicherzugriffen ist es wahrscheinlich, daß eine aktuelle Adresse auf dieselbe Seite zugreift wie<br />
die vorherige. Dann kann man eine volle Adreßumsetzung umgehen. Eine andere Lösung ist durch<br />
das Prinzip der Lokalität vorgezeichnet:<br />
Weisen die Zugriffe eine prinzipielle Lokalität auf, dann kann die Adreßumsetzung auch ein lokales<br />
Verhalten zeigen. Es bietet sich also an, "aktuelle" Adressumsetzungen in einem speziellen Cache zu<br />
halten. Dann erfordert der Speicherzugriff selbst nur noch den direkten Zugriff auf die Daten, wenn<br />
die Adreßübersetzung aus dem Cache übernommen werden kann. Dieser spezielle Cache wird als<br />
Adreß-Umsetzungspuffer oder translation lookaside buffer (TLB) bezeichnet. Ein TLB-Eintrag<br />
entspricht einem Cache-Eintrag, bei dem das Tag (die Kennung) Teile der virtuellen Adresse enthält,<br />
außerdem den Datenteil der physikalischen Seitennummer (page frame number). Darin stehen das<br />
Schutzfeld, das Use-Bit und das Dirty-Bit.<br />
Wie üblich bei doppelter Datenhaltung gibt es hier wieder ein Konsistenzproblem:<br />
Wenn eine physikalische Seitennummer geändert werden soll (also eine Seite auf eine andere<br />
physikalische Adresse verschoben wird), dann muß das Betriebssystem sichern, daß der alte Eintrag<br />
nicht im TLB stehen bleibt.<br />
Das Dirty-Bit zeigt übrigens nur an, daß eine Seite modifiziert ist und damit keine Konsistenz<br />
zwischen Hauptspeicher und Cache mehr besteht. Das Dirty-Bit zeigt nicht an, daß die<br />
Adreßumsetzung oder ein bestimmter Block im Cache modifiziert sind.<br />
Tabelle 10.1: Typische Parameter eines TLB<br />
Blockgröße 4 - 8 Byte (ein Seitentabellen-Eintrag)<br />
Trefferzeit 1 Taktzyklus<br />
Fehlzugriffszeit 10 - 30 Taktzyklen<br />
Fehlzugriffsrate 0,1% bis 2%<br />
TLB-Größe 32 - 8192 Byte<br />
20
Informatik V-Teil 2,Kap. 10, SS 99<br />
Einige nicht triviale Probleme ergeben sich aus der Kombination von Cache mit virtuellem Speicher.<br />
Die virtuelle Adresse muß erst in die physische Adresse umgewandelt werden, bevor ein Cache-<br />
Zugriff möglich ist. Damit erhöht sich die Trefferzeit des Cache, also die minimale Zeit für einen<br />
erfolgreichen Zugriff. Dies kann wiederum Einfluß auf die Dauer der Phasen in der Pipeline haben<br />
oder gar eine Ausdehnung der Pipeline erfordern.<br />
Eine Lösung besteht darin, auf den Cache mittels des Seiten-Offsets zuzugreifen.<br />
Während dann der Cache-Tag bereits gelesen wird, sendet man den virtuellen Teil der Adresse, also<br />
die Seitenadresse, zum TLB. Dann erfolgt der Adressenvergleich zwischen den Cache-Tag und der<br />
inzwischen gebildeten physischen Adresse.<br />
Ein Nachteil ist hier, daß dann ein einfach assoziativer Cache nicht größer als eine Seite sein kann.<br />
Eine weitere Möglichkeit ist der virtuell adressierte Cache,<br />
10.7 Zugriffsschutz<br />
Die Fähigkeit des Multi-Tasking eines Rechners, also die Fähigkeit, mehrere Aufgaben parallel zu<br />
bearbeiten, hat zum Konzept des Prozesses geführt.<br />
Der Prozeß ist die organisatorische "Blase", in der ein Programm abläuft. Neben dem Programm<br />
selbst gehört dazu die notwendige Status-Information. Die Prozessor-Ressourchen werden im Time-<br />
Sharing genutzt, wobei jeder Nutzer vorgespielt bekommt, er besitze den Prozessor allein. Um<br />
mehrere überlappend ablaufende Prozesse ablaufen zu lassen muß es jederzeit möglich sein, von<br />
einem Prozeß zu einem anderen umzuschalten (process switching).<br />
Dieses Umschalten muß vom Betriebssystem organisiert werden. Der Auslöser für ein Umschalten<br />
kann ein Interrupt von außen sein oder eine Aktion der Timer-Funktion im Betriebssystem, die den<br />
abzuarbeitenden Prozessen je nach Bedarf und Priorität CPU-Zeit zuweist.<br />
Die Organisation eines Umschaltprozesses ist eine Aufgabe sowohl des Rechnerarchitekten als auch<br />
des Betriebssystem-Entwicklers.<br />
Der Rechnerentwickler muß dafür sorgen, daß sich der Rechner jederzeit in einem definierten<br />
Zustand befindet, der verlassen und wieder eingerichtet werden kann.<br />
Das Betriebssystem hat dagegen dafür zu sorgen, daß mehrere ablaufende Prozesse sich nicht<br />
gegenseitig stören, wohl aber im Bedarfsfall miteinander kommunizieren können.<br />
10.8 Speicher-Organisation bei PCs<br />
10.8.1 Segmentierung<br />
Die grundsätzlichen Probleme der Speicher-Organisation bei PCs wurden bereits am Anfang dieses<br />
Kapitels angesprochen.<br />
Die PCs der Intel-Serie haben ab dem 8086 eine segmentierte Adressierung, die zunächst dem Zweck<br />
dient, Schutzfunktionen für einzelne Prozesse bereitzustellen.<br />
Die Adressenbildung geschieht nicht linear, sondern mittels spezieller Segment-Register. Ab dem<br />
80286 war ein erweiterter Segmentschutz verfügbar. Eine volle 32-Bit-Adressierung mit dem<br />
zugehörigen großen Adressraum bot allerdings erst der 80386-Prozessor. Hier war auch eine<br />
Seitenaufteilung (Paging) und eine virtuelle Adressierung verfügbar. Natürlich verkomplizierte dies<br />
die Bildung physikalischer Adressen aus logischen Adressen. Deshalb ist die entsprechende Adreß-<br />
Umsetzung auf dem Chip integriert.<br />
21
Informatik V-Teil 2,Kap. 10, SS 99<br />
Prozessor<br />
Direkt<br />
adressierbarer<br />
8086 1 MByte<br />
Speicher<br />
80286 16 MByte<br />
80386 4 GByte<br />
80486 4 GByte<br />
Pentium 4 GByte<br />
Virtuelle<br />
Speicher-<br />
größe<br />
keine<br />
22<br />
Segmentgröße<br />
64 KByte<br />
1 GByte 1 Byte - 4 GByte<br />
Seitengröße<br />
keine<br />
keine<br />
64 TByte 1 Byte - 4 GByte 4 KByte<br />
64 TByte<br />
64 TByte<br />
1 Byte - 4 GByte<br />
1 Byte - 4 GByte<br />
Abb. 10.16: Speicheradressierung bei Intel 80x86-Prozessoren<br />
4 KByte<br />
4 KByte und<br />
4 MByte<br />
Wie vorstehend erwähnt, organisiert die Segmentierung den Speicher in mehrere unabhängige und<br />
gegeneinander geschützte Adressräume.<br />
Bezüglich der Speicher-Organisation erlauben die Intel-Prozessoren ab dem 80386 verschiedene<br />
Alternativen. Im primitivsten Fall können, wie bei 8-Bit-Mikroprozessoren üblich, alle Segmente in<br />
denselben Adreßraum abgebildet werden, eine Seiteneinteilung fehlt. Die Seiteneinteilung (paging)<br />
wird bei virtuellen Adressierungen benötigt. Sie sorgt dafür, daß die Nutzung des RAM-Speichers<br />
auf ein Minimum reduziert wird. Auf PCs kann man wahlweise entweder die Segmentierung oder das<br />
Paging einzeln oder auch beide in Kombination verwenden. Schutzfunktionen bezüglich der<br />
Abschottung mehrerer Prozesse gegeneinander sind sowohl bei der Segmentierung als auch beim<br />
Paging vorhanden. UNIX kennt nur Paging ohne Segmentierung.<br />
Im einfachsten Fall der Speicher-Organisation besteht die Möglichkeit, ein unstrukturiertes Modell<br />
zu verwenden. Alle Segmente sind dem gesamten physikalischen Adressraum zugeordnet. Im<br />
Extremfall ist es möglich, die Segmentierung völlig auszuschalten. Die logische Adresse wird dann<br />
gleich der physikalischen Adresse, wenn nicht ein Paging-Mechanismus (wie für virtuelle<br />
Betriebssysteme notwendig) benötigt wird. In einem solchen Modus läuft UNIX, das keine<br />
Segmentierung kennt, auf Intel-Prozessoren.<br />
Trotzdem existieren für Speichersegmente sogenannte Segmentdeskriptoren. Für das unsegmentierte<br />
Modell werden zwei Deskriptoren erzeugt, einer für Code-Referenzen und einer für Daten-<br />
Referenzen.<br />
Segmentregister<br />
CS<br />
SS<br />
DS<br />
Segmentdeskriptoren<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Abb. 10.17: Speichermodell ohne Segmente<br />
Physikalischer<br />
Speicher<br />
EPROM<br />
DRAM<br />
4 GByte<br />
Der Segmentdeskriptor liefert neben der Basisadresse eines Segmentes auch dessen Grenze und eine<br />
Zugriffs-Steuerinformation.<br />
0
Informatik V-Teil 2,Kap. 10, SS 99<br />
Das ROM wird normalerweise ganz oben im physikalischen Adreßraum plaziert, das RAM ganz<br />
unten, da die ursprüngliche Basis-Adresse für den Rechner nach einer Reset-Initialisierung 0 ist.<br />
Bei einem völlig unsegmentierten Modell hat jeder Deskriptor die Basisadresse 0 und eine<br />
Segmentgrenze von 4 GByte.<br />
Neben dem unsegmentierten Modell existiert auch ein geschütztes unsegmentiertes Modell. Dabei<br />
sind die Segmentgrenzen so gesetzt, daß die nur den Teil der Speicheradressen abdecken, die<br />
tatsächlich vorhanden sind. Wenn also auf eine Adresse zugegriffen werden soll, die zu einer<br />
physikalisch nicht vorhandenen Speicherzelle gehört, so erfolgt eine Fehlermeldung.<br />
Diese Sicherung ist insbesondere dann sinnvoll, wenn kein Paging, also keine virtuelle<br />
Speicherverwaltung aktiviert ist.<br />
Segmentregister<br />
CS<br />
ES<br />
SS<br />
DS<br />
Segmentdeskriptoren<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Physikalischer<br />
Speicher<br />
23<br />
EPROM<br />
DRAM<br />
Abb. 10.18: Geschütztes Speichermodell ohne Segmente<br />
4 GByte<br />
0<br />
Logischer<br />
Speicher<br />
EPROM<br />
DRAM<br />
Beim Modell mit mehreren Segmenten erhält jedes Programm seine eigene Tabelle mit Segment-<br />
Deskriptoren und seinen Segmenten. Grundsätzlich können die Segmente nur vom jeweiligen<br />
Programm genutzt oder gemeinsam mit anderen Segmenten genutzt werden. Die 80X86-Architektur<br />
erlaubt die gleichzeitige Nutzung von bis zu 6 Segmenten. Deren Segmentselektoren sind in die<br />
Segmentregister des Prozessors geladen. Soll auf andere Segmente zugegriffen werden, so sind<br />
davor ihre Segmentselektoren in die Segmentregister zu laden.<br />
Jedes Segment bildet einen zusammenghängenden Adressraum. Nur der Zugriff auf diesen<br />
Adressraum ist zulässig. Der Versuch, Speicherzellen jenseits des Endes des zuständigen Segments<br />
zu adressieren, erzeugt eine Schutzverletzung und einen Interrupt. Natürlich müssen Segmente nicht<br />
zusammenhängend im physikalischen Speicher stehen, insbesondere bei Nachschalten eines Paging<br />
für die virtuelle Adressierung wird dies normalerweise nicht der Fall sein.<br />
Segmentregister Segm.-Deskriptoren Physik. Speicher<br />
CS<br />
Zugriff Grenze<br />
Basisadresse<br />
4 GByte<br />
SS<br />
DS<br />
ES<br />
FS<br />
GS<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Zugriff Grenze<br />
Basisadresse<br />
Abb. 10.18: Speichermodell mit mehreren Segmenten<br />
0
Informatik V-Teil 2,Kap. 10, SS 99<br />
10.8.2 Virtuelle Adressierung beim 80X86-PC<br />
Die vituelle Speicherverwaltung (paging) ist der Segmentierung optional nachgeschaltet. Der lineare<br />
Adressraum wird in 4 kByte große Seiten aufgeteilt.<br />
Wenn ein Programm versucht, auf eine im Arbeitsspeicher (oder im Cache) nicht vorhandene Seite<br />
zuzugreifen, so wird das abzuarbeitende Programm zunächst unterbrochen.<br />
Dies ist ein "gutartiger" Interrupt, der im Gegensatz zu anderen Interrupts nach dem Holen der<br />
benötigten Seite den Ausgangszustand und die Registerinhalte wiederherstellt. Ist das Paging nicht<br />
aktiviert, so wird die lineare Adresse als physikalische Adresse verwendet.<br />
Der Zusammenhang zwischen der Größe des Segmente und der Seiten ist nicht trivial und hat sogar<br />
Auswirkungen auf die verwendeten Schutzmechanismen:<br />
1. Es werden wenige, aber große Segmente verwendet.<br />
Man kann dann die Segmente aus ganzen Seiten zusammensetzen. Jedes Segment beginnt an einer<br />
Seitengrenze und ist mindestens eine Seite lang. Die Seite ist die Einheit der Speicher-Allokation,<br />
und auch die Schutzmaßnahmen werden über die Seitenverzeichnisse, welche die Zuordnung von<br />
Seiten zu Prozessen regeln, implementiert.<br />
2. Es gibt viele, aber relativ kleine Segmente.<br />
Hier können nun die Segmente kleiner als die 4 kByte-Einheitsgröße der Seiten sein. Man wird jetzt<br />
die Segmente einzelnen Seiten zuordnen. Die Allokation von Daten und die Schutzmaßnahmen<br />
stützen sich auf die Segmente, die Seiten dienen nur der virtuellen Speicherverwaltung.<br />
Die Verwaltung der Speicher-Seiten wird durch sogenannte Seiten-Tabellen organisiert. Eine<br />
Prozessor-Seitentabelle definiert zum Beispiel eine Gruppe von 4-KByte-Seiten. Bei Verwendung<br />
einer Segmentierung sind das dann genau so viele Segmente variabler Größe, wie eine<br />
Deskriptorentabelle umfaßt. Eine Seitentabelle ist eine Seite lang und besteht aus einem Feld von<br />
Tabellen-Einträgen (PTEs- page table entries). Bei 4 KByte lienaren Adressen sind in einer Tabelle<br />
1024 Einträge vorhanden, von denen jeder eine 4 KByte-Seite definiert. Damit kann eine<br />
Seitentabelle einen linearen oder physikalischen Speicherraum von 4 Mbyte abdecken.<br />
Ein Seitentabellen-Eintrag enthält die Adressierung, Schutz-Information (z. B. Schreibschutz) und<br />
virtuelle Speicherfelder.<br />
Probleme ergeben sich nun, wenn ein Prozeß einen Schreibprozeß in den Speicher ausführen muß<br />
und deshalb eine neue Adresse erzeugen muß.<br />
Im schlimmsten Fall müßte der Prozeß dann den ganzen 4-GByte-Adressraum durchsuchen, um eine<br />
"freie" physikalische Adresse zu finden, das sind 1024 Seitentabellen. Damit nun nicht jede Task<br />
einen Wasserkopf aus einer vollständigen Seitentabelle (mit meistens leeren Einträgen) mitführen<br />
muß, bietet der Prozessor ein sogenanntes Seitenverzeichnis, dessen Einträge als page data entries<br />
(PDEs) bezeichnet werden.<br />
Das Seitenverzeichnis ähnelt einer Seitentabelle, ist eine Seite lang und nach Seiten ausgerichtet.<br />
Dieses Seitenverzeichnis ist in einem geschützten Teil des Speichers abgelegt.<br />
In einer Seite der Seitentabelle definiert jeder der 1024 Einträge (PTEs) die Attribute einer Seite.<br />
Jedes der 1024 PDEs des Seitenverzeichnisses beinhaltet die Attribute aller Seiten, die in einer<br />
Seitentabelle beschrieben sind.<br />
Eine Seite hat also zwei Attribute:<br />
− eins definiert durch den Eintrag in die Seitentabelle (PTE)<br />
− eins definiert durch den Eintrag ins Page-Date-Entry der Seitentabelle.<br />
24
Informatik V-Teil 2,Kap. 10, SS 99<br />
Die Attribute, die eine Seite charakterisieren, sind also verteilt: Einmal in solche, die sich<br />
gleichermaßen auf alle Seiten in einer speziellen Seitentabelle erstrecken, und dann solche, die<br />
speziell auf eine Seite zutreffen.<br />
Der Prozessor überprüft nacheinander zuerst den PDE und dann den PTE. Ergibt sich beim PDE-<br />
Check bereits ein Fehler, so erfolgt der PTE nicht mehr.<br />
Es kann also z. B. eine ganze page-table das Attribut "schreibgeschützt" haben. Dann ist es gar nicht<br />
mehr notwendig, darunter bei einzelnen Seiten nachzusehen.<br />
Als Gegenbeispiel seien zwei benachbarte Seiten in einem Segment so charakterisiert, daß die eine<br />
Seite les- und schreibbar sein soll, die andere aber nur lesbar. Dann bietet erst der Eintrag in die<br />
Seitentabelle die entsprechende Information.<br />
Bei den 80x86-Prozessoren enthält ein spezielles Register, das CR3-Systemregister, stets die<br />
Adresse des aktuellen Seitenverzeichnisses. Bereits bei der Initialisierung des Betriebssystems wird<br />
das CR3-Systemregister mit dem (priviligieten) Befehl MOV CR3 geladen. Entsprechen gibt es auch<br />
einen priviligierten Speicherbefehl für den Inhalt von CR3: MOV MEN, CR3. Sobald CR3 geladen<br />
ist, ignoriert der Prozessor die unteren 12 Bits eines Quelloperanden. Auch die unteren 12 Bits eines<br />
Zieloperanden sind dann nicht definiert.<br />
Für jede Task steht innerhalb des linearen Adressraumes eine 4 MByte große Zone zur Verfügung,<br />
mit dessen Inhalt die Seitentabellen und Seitenverzeichnisse einer Task im physikalischen<br />
Adressraum adressiert werden können. Dieser Bereich muß stets bei einer 4 MByte-Grenze<br />
beginnen, kann aber ansonsten beliebig innerhalb des 4 GByte großen Adressraumes liegen. Laufen<br />
mehrere Tasks ab, so müssen natürlich jeder einzelnen Task unterschiedliche Adreßräume<br />
zugewiesen werden.<br />
4 GByte<br />
4 MB<br />
PDE 1023<br />
Seitenverzeichnis<br />
PDE 1023<br />
PDE 0<br />
Frei für<br />
Seitentab.<br />
Seitentab. 1<br />
Seitentab. 0<br />
0<br />
Linearer Adressraum Physikalischer Adressraum<br />
25<br />
Seiten-<br />
Tabelle 1<br />
Seitenverzeichnis<br />
Seitentabelle<br />
0<br />
Abb. 10. 19: PDEs und PTEs im linearen und physikalischen Adressraum
Informatik V-Teil 2,Kap. 10, SS 99<br />
Seitenverzeichnis-<br />
Einträge<br />
Seitentabellen-<br />
Einträge<br />
Offset Zugriff<br />
1023 0 0 PT0, PTE0<br />
1023 0 4 PT0, PTE1<br />
1023 1 8 PT1, PTE2<br />
1023 1 12 PT1, PTE3<br />
1023 1023 4092 PD, PTE1023<br />
Abb. 10.20: Seitentabellen-Adressierung<br />
Nur der Vollständigkeit halber sei bemerkt, daß sich zwei oder mehrere Tasks auch dasselbe<br />
Seitenverzeichnis teilen können. Sie nutzen dann verschieden Seiten desselben Verzeichnisses. Das<br />
bedeutet aber noch nicht, daß sie auf dieselben Daten zugreifen. Diese sind dann noch in<br />
verschiedenen Seiten oder unterschiedlichen Segmenten angeordnet.<br />
10.9 Betriebsmoden der 80x86-Prozessoren<br />
10.9.1 Übersicht<br />
Wie bereits an anderer Stelle diskutiert wurde, hat Intel bei der Entwicklung der 80x86-<br />
Prozessorserie auf Kompatibilität mit den Vorgängertypen geachtet.<br />
Aus diesem Grund haben die neueren Prozessoren der Intel-Serie unterschiedliche Betriebsmodi, die<br />
als "real mode", "protected mode" und "virtual 8086-mode" bezeichnet werden.<br />
Prozessor<br />
8086<br />
80286<br />
80386<br />
80486<br />
Pentium<br />
Software-Mode<br />
Real Mode Protected Mode Virtual 8086 Mode<br />
ja nein nein<br />
ja ja nein<br />
ja ja ja<br />
ja ja ja<br />
ja ja ja<br />
Abb. 10.21: Betriebsmodi von 80x86-Prozessoren<br />
10.9.2 Real Mode<br />
Jeder Rechner mit einem 80x86-Prozessor wird zunächst im Real Mode gestartet. Selbst wenn die<br />
eigentlichen Programme für den Protected Mode geschrieben sind, laufen die Start-up-Programme<br />
im Real Mode. In diesem Mode werden Programme betrieben, die eigentlich für den 8086 / 8088-<br />
Prozessor geschrieben sind. Sie sind auf 80286, 80386, 80486 und Pentium-Prozessoren lauffähig,<br />
deren in diesem Modus verwendete Architektur dann nahezu der des Urprozessors entspricht. Für<br />
den Programmierer ist z. B. der Pentium dann ein superschneller 8086 mit erweitertem Befehlssatz<br />
und erweiterten Registern. Der Zugriff zu den 32-Bit-Registern der größeren Prozessoren ist in<br />
diesem Modus möglich.<br />
26
Informatik V-Teil 2,Kap. 10, SS 99<br />
Die Adressierungsmethoden, die Speicherverwaltung und die Interrupt-Behandlung entsprechen dem<br />
Real Mode des 80286-Prozessors. Dementsprechend ist die Standard-Größe der Operanden 16 Bit.<br />
Eine Adressbildung findet ganz analog zum 8086 statt.<br />
Basis<br />
+<br />
Offset<br />
=<br />
lineare<br />
Adresse<br />
19 0<br />
16-Bit-Segment Selektor 0 0 0 0<br />
19 0<br />
16 Bit effektive Adresse<br />
20 0<br />
x x x x x x x x x x x x x x x x x x x x<br />
Abb. 10. 22: Adreßumwandlung beim 80x86-Prozessor<br />
Zunächst wird die 16 Bit-Adresse für den Segment-Selektor in einem 20-Bit-Register um vier Bit<br />
nach links verschoben und bildet dann eine 20-Bit-Basisadresse. Die zweite Teiladresse, die effektive<br />
Adresse (Offset), wird im vier Bit bei den höherwertigen Stellen erweitert und dann zur Basisadresse<br />
addiert. Damit ergibt sich dann die für den Speicherzugriff notwendige lineare Adresse. Diese<br />
entspricht der physikalischen Adresse, da im Real-Mode ein virtueller Betrieb (Paging) nicht möglich<br />
ist. Bei der Adreßaddition ist ein Überlauf in das Bit Nr. 20 möglich. Damit steht ein Adreßraum von<br />
0 bis 10FFEFH entsprechend 1 MByte plus 64 kByte zur Verfügung.<br />
Der 80386, 80486 und Pentium können echte 32-Bit-Adressen bilden. Unter Verwendung eines<br />
sogenannten Adress-Überschreibpräfixes lassen sie im Ral-Modus Adressen bis zu 65535 zu, ohne<br />
eine Ausnahme hervorzurufen. Darüber treten sogenannte Pseudo-Fehler auf (Interrupts Nr. 12 oder<br />
13 ohne Fehlercode).<br />
Im Real Mode sind auch die Register, die 80386, 80486 und Pentium über den Umfang des 8086<br />
hinaus besitzen, zulässig. Auch Befehle, welche diese Register benutzen, sind nutzbar, z. B. zur<br />
Adreßberechnung. Die Befehle allerdings, die sich explizit auf den "Protected Mode" des Prozessors<br />
beziehen, erzeugen ungültigen Op-Code.<br />
Auch die Interrupt-Verarbeitung erfolgt analog zum 80386, allerdings steht eine größere Interrupt-<br />
Tabelle zur Verfügung.<br />
10.9.3 Protected Mode<br />
Die zweite wichtige Betriebsart ist der Protected Mode. Hier gibt es wiederum Unterschiede<br />
zwischen dem Protected Mode des 80286, des 80386 / 80486 und des Pentium. Der wesentliche<br />
Unterschied zum Real-Mode besteht im wesentlich vergrößerten Adreßraum und anderen<br />
Mechanismen zur Adreßbildung.<br />
Im protected Mode des 80286 können schon Programme mit bis zu einem GByte Adreßraum<br />
verwendet werden. Der physikalische Adre?raum umfaßt 16 MByte, virtuelle Adressen werden also<br />
in 24-Bit physikalische Adressen umgewandelt.<br />
Bis auf die unterschiedliche Speichergröße ist die Organisation des Speichers beim80286 für den<br />
Real Mode und für den Protected Mode gleich. Zusätzlich zu den "normalen" Speicheradressen hat<br />
der 80286 einen zusätzlichen Adreßraum für Ein- / Ausgabebefehle mit bis zu 65 538 8-Bit E / A -<br />
Ports und bis zu 32 768 32-Bit-E / A-Ports.<br />
Für den 80386 und den 80486 bietet der Protected Mode den Übergang zu Multi-Tasking-<br />
Betriebssystemen und zur Seiteneinteilung und zur Segmentierung des Speichers, also zur virtuellen<br />
Speicherverwaltung.<br />
27<br />
4<br />
3
Informatik V-Teil 2,Kap. 10, SS 99<br />
Auch hier wird die logische Adresse aus zwei Komponenten gebildet.<br />
Zunächst wird ein 16-Bit-Selektor verwendet, um die lineare Basisadresse eines Segments zu<br />
bestimmen. Die Basisadresse wird zur effektiven 32-Bit-Adresse hinzugefügt und bildet eine lineare<br />
32-Bit-Adresse.<br />
Diese lineare 32-Bit-Adresse wird entweder direkt in eine physikalische 24-Bit-Adresse umgesetzt<br />
(ohne Paging) oder bildet den Ausgang für die Adressberechnung im virtuellen Adressraum. Dabei<br />
hat man einen linearen Adressraum von vier GByte zur Verfügung. Auch im Protected Mode des<br />
80386 / 80486 ist das Ablaufen von allen Programmen, die für den 80386-DX, den 80286 und den<br />
8086 geschrieben wurden, möglich. Man hat nun aber die für einen Multi-Tasking-Betrieb<br />
notwendigen Schutzmechanismen verfügbar.<br />
Der Protected Mode des Pentium verhält sich ganz entsprechend, jedoch sich neue Flags im<br />
sogenannten EFLAG-Register verfügbar. Damit ist im Multi-Tasking-Betrieb ein effizienterer<br />
Übergang zwischen den Betriebsmodi möglich.<br />
Der Umstieg vom Real Mode zum Protected Mode erfordert eine Sequenz von Schritten, die<br />
zwischen dem Prozessor und dem Betriebssystem ablaufen.<br />
Folgende Prozeduren müssen gestartet werden, um in den Protected Mode zu gelangen:<br />
− Öffnen des Protected Mode<br />
− Öffnen der Seiten-Verwaltung (optional)<br />
− Umschalten zu den ursprünglichen Aufgaben.<br />
Oft schalten die Betriebssysteme automatisch nach einem RESET zum Protected Mode und von der<br />
16-Bit- zur 32-Bit-Registerverwaltung. Dazu werden bei der Initialisierung zunächst Daten-<br />
Zuweisungen nach dem RESET den ersten 64 KByte des linearen Adressraumes zugeordnet, die<br />
oberen 64 KByte sind für Codes reserviert.<br />
10.9.4 Virtueller Mode<br />
Der virtuelle Mode ist erst mit dem 80386 verfügbar. Er stellt die Möglichkeit dar, 8086-, 8088-,<br />
80186- und 80188-Programme in einer Protected-Mode-Umgebung ablaufen zu lassen. Dann läuft z.<br />
B. ein 8086-Programm als Teil einer virtuellen Task. Eine Task ist ein geladenes Programm, das mit<br />
Hilfe des Betriebssystems gesteuert wird und das seine eigene Umgebung aufweist. Damit kann man<br />
sogar mehrere 8086-Programme gleichzeitig innerhalb von virtuellen Tasks oder auch gemischt mit<br />
anderen Tasks ablaufen lassen (Multi-Tasking-Betrieb).<br />
Eine virtuelle 8086-Task besteht aus dem abzuarbeitenden 8086-Programm plus weiterem Code<br />
einer speziellen Software, der als virtueller Maschinen-Monitor dient. Die Task muß durch einen<br />
Task-Manager (TSS) für den 386, 486 oder Pentium bearbeitet werden. Das Programm wird aus<br />
dem Protected Mode heraus gestartet und bearbeitet und kehrt nach Beendigung auch in diesen<br />
zurück.<br />
Benötigt werden virtuelle 8086-Mode-Software und Betriebssystem-Dienste.<br />
Man muß also zum 8086-Programm Betriebssystem-Routinen bereitstellen, die entweder Teil des<br />
8086-er Programms sein können oder in die virtuelle 8086-er Software eingebunden sein können.<br />
28