

C:\mol\noter\Statistik\Statistiske grundbegreber-v11\s1v11-forside.wpd
C:\mol\noter\Statistik\Statistiske grundbegreber-v11\s1v11-forside.wpd
C:\mol\noter\Statistik\Statistiske grundbegreber-v11\s1v11-forside.wpd

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
MOGENS ODDERSHEDE LARSEN<br />
18<br />
15<br />
12<br />
9<br />
6<br />
3<br />
0<br />
STATISTISKE<br />
GRUNDBEGREBER<br />
med anvendelse af TI 89 og Excel<br />
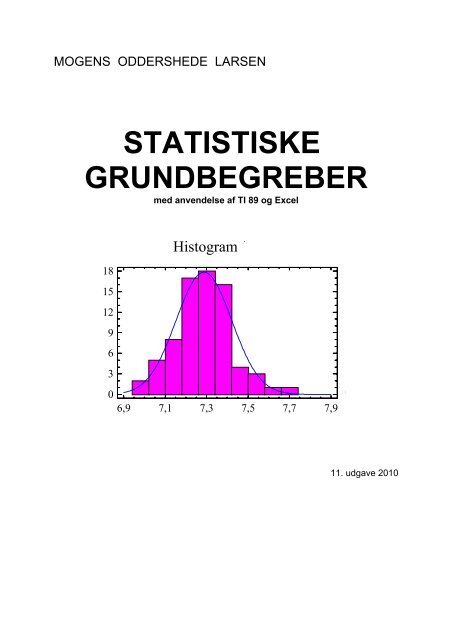
Histogram for pH<br />
6,9 7,1 7,3 7,5 7,7 7,9<br />
pH<br />
11. udgave 2010
FORORD<br />
Der er i denne bog søgt at give letlæst og anskuelig fremstilling af de statistiske <strong>grundbegreber</strong> til<br />
brug ved en indledende undervisning i statistik. De væsentligste definitioner og sætninger forklares<br />
derfor fortrinsvist ved hjælp af figurer og gennemregnede praktiske eksempler. Ønskes en mere<br />
matematisk uddybende forklaring, bevis for sætninger osv. kan dette ofte findes i et særskilt tillæg<br />
til bogen, som findes på nettet under titlen “Supplement til statistiske <strong>grundbegreber</strong>”.<br />
Læsning: Bogen er bygget således op, at der hurtigt nås frem til normalfordelingen og de vigtige<br />
normalfordelingstest. Disse vigtige begreber kan derfor blive grundigt indarbejdet, selv om der kun<br />
er kort tid til rådighed. Er det af tidsmæssige grunde svært at nå hele notatet kan man uden skade for<br />
helheden overspringe kapitlerne 10 og 11, ligesom man eventuelt kan tage kapitlerne 1 og 9 mere<br />
oversigtsagtigt.<br />
Sidst i hver kapitel findes en række opgaver, der yderligere kan fremme forståelsen.<br />
Bagerst i bogen findes en facitliste til alle opgaverne.<br />
I et længere kursusforløb er denne bog tænkt at skulle efterfølges af M. Oddershede Larsen:<br />
Videregående Statistik”, som kan hentes gratis på e-mailadressen www.larsen-net.dk<br />
Regnemidler. Det er hensigtsmæssigt, at man har adgang til en lommeregner eller en PC med<br />
normalfordeling, t - fordeling, binomialfordeling og Poissonfordeling indbygget.<br />
I eksemplerne angives således, hvorledes beregningerne kan foretages med den i øjeblikket mest<br />
populære lommeregner TI-89, samt med det meget udbredte regneark Excel.<br />
Endvidere er der i et afsnit sidst i bogen også angivet hvorledes beregningerne kan udføres med<br />
lommeregneren TI-83 og matematikprogrammerne Maple og Mathcad.<br />
I 8- udgave findes tabeller over de sædvanlige statistiske funktioner, samt forklaret hvordan<br />
tabellerne anvendes<br />
I denne 11. udgave er der ingen statistiske tabeller, men alle eksempler regnes med anvendelse af<br />
lommeregneren TI89 og regnearkprogrammet Excel.<br />
Endvidere er der indsat et kapitel om deskriptiv statistik, som viser hvordan man kan anvende Excel<br />
til tegning af histogrammer m.m.<br />
Denne udgave, samt 8 udgave kan sammen med en række andre noter findes på adressen:<br />
www.larsen-net.dk<br />
Jeg vil gerne takke ingeniørdocent L. Brøndum og J. D. Monrad for de mange gode råd gennem<br />
årene.<br />
En særlig tak til lektor Bjarne Hellesen, som dels har skrevet afsnit 11 , dels er kommet med mange<br />
værdifulde kommentarer og bidrag til forbedringer.<br />
august 2010 Mogens Oddershede Larsen<br />
i
INDHOLD<br />
1 INTRODUKTION TIL STATISTIK .......................................... 1<br />
2 DESKRIPTIV STATISTIK<br />
2.1 Kvalitative data ......................................................... 2<br />
2.2 Kvantitative data ........................................................ 4<br />
2.3 Karakteristiske tal....................................................... 7<br />
Opgaver ................................................................. 12<br />
3 KONTINUERT STOKASTISK VARIABEL<br />
3.1 Sandsynlighed......................................................... 15<br />
3.2 Stokastisk variabel ..................................................... 16<br />
3.3 Tæthedsfunktion, middelværdi og spredning for kontinuert stokastisk variabel ...... 17<br />
3.4 Linearkombination af stokastiske variable................................... 21<br />
3.5 Usikkerhedsberegning .................................................. 23<br />
Opgaver ................................................................. 26<br />
4 NORMALFORDELINGEN<br />
4.1 Indledning ........................................................... 28<br />
4.2 Definition og sætninger om normalfordeling ................................. 29<br />
4.3 Beregning af sandsynligheder ............................................ 32<br />
Opgaver ................................................................. 36<br />
5 STIKPRØVER<br />
5.1 Udtagning af stikprøver ................................................... 38<br />
5.2 Fordeling og spredning ag gennemsnit ..................................... 39<br />
5.3 Konfidensinterval for middelværdi .......................................... 40<br />
5.3.1 Definition af konfidensinterval ........................................ 40<br />
5.3.2 Populationens spredning kendt eksakt .................................. 41<br />
5.3.3 Populationens spredning ikke kendt eksakt .............................. 43<br />
5.4 Konfidensinterval for spredning ............................................ 48<br />
5.5 Oversigt over centrale formler i kapitel 5 ..................................... 50<br />
Opgaver ................................................................. 51<br />
6 HYPOTESETESTNING (1 NORMALFORDELT VARIABEL)<br />
6.1 Grundlæggende begreber ................................................ 53<br />
6.2 Eksempler på hypotesetest regnet med TI89 og Excel ......................... 56<br />
6.3 Fejl af type I og typr II .................................................. 59<br />
6.4 Oversigt over centrale formler i kapitel 6 ..................................... 63<br />
Opgaver ................................................................. 66<br />
7 HYPOTESETESTNING (2 NORMALFORDELTE VARIABLE)<br />
7.1 Indledning ........................................................... 70<br />
7.2 Sammenligning af 2 normalfordelte variable ................................. 71<br />
7.3 Oversigt over centrale formler i kapitel 7 ..................................... 76<br />
Opgaver ................................................................. 77<br />
ii
Indhold<br />
8 REGNEREGLER FOR SANDSYNLIGHED, KOMBINATORIK<br />
8.1 Regneregler for sandsynlighed ............................................ 80<br />
8.2 Betinget sandsynlighed ................................................. 82<br />
8.3 Kombinatorik ......................................................... 84<br />
8.3.1 Indledning ........................................................ 84<br />
8.3.2 Multiplikationsprincippet ............................................ 84<br />
8.3.3 Ordnet stikprøveudtagelse ............................................ 85<br />
8.3.4 Uordnet stikprøveudtagelse ........................................... 86<br />
Opgaver ................................................................. 88<br />
9 VIGTIGE DISKRETE FORDELINGER<br />
9.1 Indledning ........................................................... 91<br />
9.2 Hypergeometrisk fordeling .............................................. 91<br />
9.3 Binomialfordeling ..................................................... 94<br />
9.4 Poissonfordeling ...................................................... 100<br />
9.5 Den generaliserede hypergeometriske fordeling ............................. 103<br />
9.6 Polynomialfordeling ................................................... 104<br />
9.7 Approksimationer ..................................................... 104<br />
9.8 Oversigt over centrale formler i kapitel 9 ................................... 105<br />
Opgaver ................................................................ 107<br />
10 ANDRE KONTINUERTE FORDELINGER<br />
10.1 Indledning .......................................................... 113<br />
10.2 Den rektangulære fordeling ............................................. 113<br />
10.3 Eksponentialfordelingen .............................................. 115<br />
10.4 Weibullfordelingen ................................................. 117<br />
10.5 Den logaritmiske fordeling ............................................. 118<br />
10.6 Den todimensionale normalfordeling ...................................... 118<br />
Opgaver ................................................................ 119<br />
11 FLERDIMENSIONAL STATISTISK VARIABEL<br />
11.1 Essens ............................................................. 120<br />
11.2 Indledning ......................................................... 121<br />
11.2 Kovarians og korrelationskoefficient ..................................... 123<br />
11.3 Linearkombination ................................................... 126<br />
Opgaver ................................................................ 128<br />
STATISTISKE BEREGNINGER UDFØRT PÅ LOMMEREGNER OG PC<br />
TI-89................................................................... 131<br />
Excel................................................................... 133<br />
TI-83................................................................... 136<br />
Maple .................................................................. 138<br />
Mathcad ................................................................ 139<br />
APPENDIX. OVERSIGT OVER APPROKSIMATIONER ....................... 141<br />
iii
TABEL OVER FRAKTILER I NORMERET NORMALFORDELING ............. 143<br />
FACITLISTE .............................................................. 144<br />
STIKORD ................................................................. 148<br />
iv
1<br />
1 Introduktion til statistik<br />
1 INTRODUKTION TIL STATISTIK<br />
Ved næsten alle ingeniørmæssige problemer vil de indsamlede data udvise variation. Måler man<br />
således gentagne gange indholdet (i %) af et bestemt stof i et levnedsmiddel, vil det procentvise<br />
indhold ikke blive præcis samme tal for hver gang man foretager en måling. Dette kunne naturligvis<br />
være en usikkerhed ved målemetoden, men det vil sjældent være den væsentligste årsag.<br />
Ved mange industrielle processer vil en række ukontrollable forhold indvirke på det endelige<br />
resultat. Eksempelvis vil udbyttet af en kemisk proces variere fra dag til dag, fordi man ikke har<br />
fuldstændig kontrol over forsøgsbetingelser som temperatur, omrøringstid, tidspunkt for<br />
tilsætning af råmaterialer, fugtighed osv. Endvidere er forsøgsmaterialerne muligvis ikke<br />
homogene nok. Råmaterialerne kan f.eks. være af varierende kvalitet, der må bruges forskelligt<br />
apparatur under produktionsprocessen, forskelligt personale deltager i arbejdet osv.<br />
Statistik drejer sig om at samle, præsentere og analysere data med henblik på at foretage<br />
beslutninger og løse problemer.<br />
I den deskriptive statistik beskrives data ved tabeller, grafisk (lagkagediagrammer, søjlediagrammer)<br />
og ved beregning af karakteristiske tal såsom gennemsnit og spredning.<br />
Man kan eksempelvis i “Danmarks Statistik” (findes på nettet under adressen www.statistikbanken.dk<br />
) finde, hvor mange personbiler der er i Danmark i 2009 opdelt efter alder.<br />
Man kender her populationen (biler i Danmark), kan grafisk vise deres fordeling i et søjlediagram<br />
og beregne deres gennemsnitlige alder.<br />
I den mere analyserende statistik (kaldet inferentiel statistik) søger man ved mere avancerede<br />
statistiske metoder ud fra en repræsentativ stikprøve at konkludere noget om hele populationen.<br />
Eksempelvis udtages ved en meningsmåling en forhåbentlig repræsentativ stikprøve på 1000<br />
vælgere, som man spørger om hvilket politisk parti de ville stemme på, hvis der var valg i<br />
morgen.<br />
Man vil så ud fra stikprøven konkludere, at hvis man spurgte hele populationen (alle vælgere i<br />
Danmark) , så ville man med en vis usikkerhed få samme resultat.<br />
Viser stikprøven, at partiet “Venstre” vil gå 2.5% tilbage, så vil det samme ske, hvis der var valg<br />
i morgen.<br />
Et sådant tal er naturligvis usikkert. Man må derfor anvende passende statistiske metoder til<br />
eksempelvis at beregne, at usikkerheden er på 2%.
2 Deskriptiv statistik<br />
2. DESKRIPTIV STATISTIK<br />
I den deskriptive statistik (eller beskrivende statistik) beskrives de indsamlede data i form af<br />
tabeller, søjlediagrammer, lagkagediagrammer, kurver samt ved udregning af centrale tal som<br />
gennemsnit, typetal, spredning osv.<br />
Kurver og diagrammer forstås lettere og mere umiddelbart end kolonner af tal i en tabel. Øjet er<br />
uovertruffet til mønstergenkendelse (“en tegning siger mere end 1000 ord”).<br />
2.1 KVALITATIVE DATA<br />
Hvis der er en naturlig opdeling af talmaterialet i klasser eller kategorier siges, at man har<br />
kategorisk eller kvalitative data .<br />
Alle spørgeskemaundersøgelser, hvor man eksempelvis bliver bedt om at sætte kryds i nogle<br />
rubrikker “meget god” , god, acceptabel osv. er af denne type.<br />
De følgende 2 eksempler viser anvendelse af henholdsvis lagkagediagram og søjlediagram<br />
Eksempel 2.1 Lagkagediagram<br />
Nedenfor er angivet hvordan en kommunes udgifter fordeler sig på de forskellige områder.<br />
Udligning 23,1<br />
øvrige 8,4<br />
Socialområdet,øvrige 9,4<br />
Ældre 18,6<br />
Børnepasning 10,4<br />
Bibliotek 1,9<br />
fritid 3,8<br />
Skoler 10,5<br />
Administration 7,3<br />
Teknik,anlæg 6,6<br />
Dan et lagkagediagram til anskueliggørelse heraf.<br />
Løsning:<br />
Data opskrives i Excel og der gives følgende “ordrer”<br />
2003: Marker udskriftsområde Vælg på værktøjslinien “Guiden diagram” Cirkel Marker ønsket figur Næste Navn<br />
på kategori Udfør<br />
2007: Marker udskriftsområde Vælg på værktøjslinien “Indsæt” Cirkel Marker ønsket figur<br />
Ønskes tekst placeret som på figur<br />
Cursor på figur Formater dataetiketter Vælg “kategorinavn” og “udenfor”.<br />
Skoler<br />
Fritid<br />
kultur<br />
Børnepasning<br />
Administr.<br />
Teknik<br />
Udgifter<br />
Ældre<br />
2<br />
Æ<br />
udligning<br />
Øvrige<br />
socialområdetøvrige
3<br />
2.1 Kvalitative data<br />
Eksempel 2.2 (kvalitative data)<br />
Følgende tabel angiver mandattallet ved de to sidste folketingsvalg.<br />
Partier A B C F K O V Ø<br />
Mandater 2001 52 9 16 12 4 22 56 4<br />
2005 47 17 18 11 0 24 52 6<br />
A = Socialdemokraterne, B =Radikale venstre, C = Konservative folkeparti , F =Socialistisk<br />
folkeparti, K = Kristendemokraterne,<br />
O = Dansk Folkeparti, V = Venstre, Ø = Enhedslisten<br />
Anskueliggør disse mandattal ved i Excel at tegne et søjlediagram<br />
Løsning:<br />
Et søjlediagram fås i Excel ved at opskrive<br />
A B C F K O V Ø<br />
52 9 16 12 4 22 56 4<br />
47 17 18 11 0 24 52 6<br />
2003: Vælg på værktøjslinien “Guiden diagram” Søjle Marker ønsket figur Næste marker udskriftsområde<br />
Næste Næste Udfør<br />
2007: Marker udskriftområde Vælg på værktøjslinien “Indsæt” Søjle Marker ønsket figur<br />
Cursor på vandret akse, højre musetast data Under “rediger kategoriakse” marker bogstavrækken<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
0<br />
A B C F K O V Ø<br />
Fordelen ved en grafisk fremstilling er, at de væsentligste egenskaber ved data opnås hurtigt og<br />
sikkert. Men netop det, at figurer appellerer umiddelbart til os, gør at vi kan komme til at lægge<br />
mere i dem, end det som tallene egentlig kan bære. Eksempelvis viser forsøg, at i lagkagediagrammer,<br />
hvor man skal sammenligne vinkler (eller arealer), da vil denne sammenligning<br />
afhænge noget af i hvilken retning vinklens ben peger.<br />
Nedenstående eksempel viser hvordan en figur kan være misvisende uden direkte at være forkert.<br />
Serie1<br />
Serie2
2 Deskriptiv statistik<br />
Eksempel 2.3. Misvisende figur<br />
Tønderne i figuren nedenfor skal illustrere hvordan osteeksporten fordeler sig på de forskellige<br />
verdensdele. Den giver imidlertid et helt forkert indtryk. Det er højderne på tønderne der angiver<br />
de korrekte forhold, men af tegningen vil man tro, at det er rumfangene af tønderne. De 3 små<br />
tønder kan umiddelbart være flere gange indeni den store tønde, men det svarer jo ikke til<br />
talforholdene.<br />
De mest almindelige figurer til at give et visuelt overblik over større talmaterialer er histogrammer<br />
(søjlediagrammer) og kurver i et koordinatsystem.<br />
2.2. KVANTITATIVE DATA (VARIABLE)<br />
Kvantitative data er data, hvor registreringen i sig selv er tal, der angiver en bestemt rækkefølge,<br />
f. eks. som i eksempel 1.4 hvor data registreres efter det tidspunkt hvor registreringen foregår<br />
eller som i eksempel 1.5, hvor det er størrelsen af registrerede værdi der er af interesse.<br />
Eksempel 2.4. Kvantitativ variabel: tid<br />
Fra “statistikbanken (adresse http://www.statistikbanken.dk/) er hentet følgende data ind i Excel,<br />
der beskriver hvorledes indvandringer og udvandringer er sket gennem tiden.<br />
Excel: Vælg “Befolkning og valg” Ind- og udvandring Ind- og udvandring på måned under “bevægelse” vælges<br />
alle og under “måned” vælges år og derefter alle Tryk på tabel Drej tabel med uret Gem som Excel fil<br />
Indvandringer og udvandringer efter tid og bevægelseIndvandrede<br />
Udvandrede<br />
1983 27718 25999<br />
1984 29035 25053<br />
1985 36214 26715<br />
1986 38932 27928<br />
1987 36296 30123<br />
1988 35051 34544<br />
1989 38391 34949<br />
1990 40715 32383<br />
1991 43567 32629<br />
1992 43377 31915<br />
1993 43400 32344<br />
1994 44961 34710<br />
1995 63187 34630<br />
1996 54445 37312<br />
1997 50105 38393<br />
1998 51372 40340<br />
1999 50236 41340<br />
2000 52915 43417<br />
2001 55984 43980<br />
2002 52778 43481<br />
2003 49754 43466<br />
2004 49860 45017<br />
2005 52458 45869<br />
2006 56750 46786<br />
2007 64656 41566<br />
2008 72749 43490<br />
2009 67161 44874<br />
Giv en grafisk beskrivelse af disse data.<br />
4
5<br />
2.2 Kvantitative data<br />
Løsning:<br />
Da dataene er registreret efter tid (år) (den kvantitative variabel “tid”) tegnes to kurver i samme<br />
koordinatsystem:<br />
Excel:2003: Marker udskriftsområde Vælg på værktøjslinien “Guiden diagram” Kurve Marker ønsket figur<br />
Næste Næste Næste Udfør<br />
Excel 2007:Marker udskriftsområde Vælg på værktøjslinien “ Indsæt” Streg Marker ønsket figur<br />
Der er foretaget enkelte andre justeringer inden følgende figur fremkom.<br />
80000<br />
70000<br />
60000<br />
50000<br />
40000<br />
30000<br />
20000<br />
10000<br />
0<br />
1983198519871989 1991199319951997199920012003200520072009<br />
Indvandrede<br />
Udvandrede<br />
Eksempel 2.5. Kvantitativ variabel , størrelse af brintionkoncentrationen pH<br />
I menneskers led udskiller den inderste hinde en "ledvæske" som "smører" leddet. For visse<br />
ledsygdomme kan brintionkoncentrationen (pH) i denne væske tænkes at have betydning. Som<br />
led i en nordisk medicinsk undersøgelse af en bestemt ledsygdom udtog man blandt samtlige<br />
patienter der led af denne sygdom en repræsentativ stikprøve ved simpel udvælgelse 75 patienter<br />
og målte pH i ledvæsken i knæet.<br />
Resultaterne (som kan findes som excel-fil på adressen www.larsen-net.dk ) var følgende:<br />
7.02 7.26 7.31 7.16 7.45 7.32 7.21 7.35 7.25 7.24 7.20 7.21 7.27 7.28 7.19<br />
7.39 7.40 7.33 7.32 7.35 7.34 7.41 7.28 7.27 7.28 7.33 7.20 7.15 7.42 7.35<br />
7.38 7.32 7.71 7.34 7.10 7.35 7.15 7.19 7.44 7.12 7.22 7.12 7.37 7.51 7.19<br />
7.30 7.24 7.36 7.09 7.32 6.95 7.35 7.36 7.52 7.29 7.31 7.35 7.40 7.23 7.16<br />
7.26 7.47 7.61 7.23 7.26 7.37 7.16 7.43 7.08 7.56 7.07 7.08 7.17 7.29 7.20<br />
Giv en grafisk beskrivelse af disse data.<br />
Løsning:<br />
I dette tilfælde, hvor vi er interesseret i at få et overblik over tallenes indbyrdes størrelse er det<br />
fordelagtigt at tegne et histogram.<br />
Et histogram ligner et søjlediagram, men her gælder, at antallet af enheder i hver søjle repræsenteres<br />
ved søjlens areal (histo er græsk for areal). Man bør så vidt muligt sørge for at grupperne<br />
er lige brede, da antallet af enheder så svarer til højden af søjlen.<br />
Excel kan umiddelbart tegne er histogram, men af hensyn til det følgende forklares hvordan man<br />
bestemmer intervalopdeling m.m.<br />
Først findes det største tal x max og det mindste tal x min i materialet og derefter beregne variationsbredden<br />
x max - x min. Vi ser, at største tal er 7.71 og mindste tal er 6.95 og variationsbredden<br />
derfor 7.71 - 6.95 = 0.76.
2 Deskriptiv statistik<br />
Dernæst deles tallene op i et passende antal intervaller (klasser). Som det første bud vælges ofte<br />
et antal nær n . Da<br />
076 .<br />
75 ≈ 9 vælges ca. 9 klasser. Da ≈ 008 . deler vi op i de klasser, der<br />
9<br />
ses af tabellen. Dette giver 10 intervaller. Vi tæller op hvor mange tal der ligger i hvert interval<br />
(gøres nemmest ved at starte forfra og sæt en streg i det interval som tallet tilhører).<br />
Klasser Antal n<br />
]6.94 - 7.02] // 2<br />
]7.02 - 7.10] ///// 5<br />
]7.10 - 7.18] //////// 8<br />
]7.18 - 7.26] ///////////////// 17<br />
]7.26 - 7.34] ////////////////// 18<br />
]7.34 - 7.42] //////////////// 16<br />
]7.42 - 7.50] //// 4<br />
]7.50 - 7.58] /// 3<br />
]7.58 - 7.66] / 1<br />
]7.66 - 7.74] / 1<br />
Allerede her kan man se, at antallet er størst omkring 7.30, og så falder hyppigheden nogenlunde<br />
symmetrisk til begge sider.<br />
I Excel sker det på følgende måde:<br />
Data indtastes i eksempelvis søjle A1 til A75 ( data findes på adressen www.larsen-net.dk )<br />
2003: Vælg “Funktioner” Dataanalyse Histogram<br />
2007: Vælg “Data” Dataanalyse Histogram<br />
I den fremkomne tabel udfyldes “inputområdet” med A1:A75 og man vælger “diagramoutput”..<br />
1) Trykkes på OK fås en tabel med hyppigheder, og en figur, hvor intervalgrænserne er fastlagt af Excel.<br />
2) Ønsker man selv at bestemme grænserne, skal man også udfylde intervalområdet. Dette gøres ved at skrive de<br />
øvre grænser i en søjle (f.eks. i B1 6.94, i B2 7.02 osv. til B10: 7.66) og så skrive B1:B10 i inputområdet<br />
Nedenstående figurer er blevet gjort lidt “pænere” ved<br />
cursor på en søjle tryk højre musetast formater dataserie indstilling mellemrumsbredde = 0 ok<br />
I tilfælde 1 fremkommer så følgende udskrift og tegning:<br />
Interval Hyppighed<br />
6,95 1<br />
7,045 1<br />
7,14 7<br />
7,235 17<br />
7,33 22<br />
7,425 18<br />
7,52 6<br />
7,615 2<br />
Mere 1<br />
25<br />
20<br />
15<br />
10<br />
5<br />
0<br />
6<br />
Hyppighed<br />
6,95 7,045 7,14 7,235 7,33 7,425 7,52 7,615 Mere<br />
Hyppighed
I tilfælde 2 følgende<br />
Interval Hyppighed<br />
6,94 0<br />
7,02 2<br />
7,1 5<br />
7,18 8<br />
7,26 17<br />
7,34 18<br />
7,42 16<br />
7,5 4<br />
7,58 3<br />
7,66 1<br />
Mere 1<br />
7<br />
2.3 Karakteristiske tal<br />
Histogrammet er et "klokkeformet histogram", hvor der er flest tal fra 7.19 til 7.42, og derefter<br />
falder antallet til begge sider.<br />
Man regner normalt med, at resultaterne af forsøg, hvor man har foretaget målinger (hvis man<br />
lavede nok af dem) har et sådant klokkeformet histogram og siger, at resultaterne er normalfordelt<br />
(beskrives nærmere i næste kapitel)<br />
2.3 KARAKTERISTISKE TAL<br />
20<br />
18<br />
16<br />
14<br />
12<br />
10<br />
8<br />
6<br />
4<br />
2<br />
0<br />
Hyppighed<br />
6,94 7,02 7,1 7,18 7,26 7,34 7,42 7,5 7,58 7,66 Mere<br />
Skal man sammenligne to talmaterialer, eksempelvis sammenligne de 75 pH-værdier i eksempel<br />
1.4 med 200 dårlige knæ fra Tyskland, har det ingen mening at sammenligne hyppighederne<br />
Man må i sådanne tilfælde angive nogle tal, som gør det muligt at foretage en sammenligning.<br />
Dette kunne blandt andet ske ved at man udregnede de relative hyppigheder<br />
2.3.1 Relativ hyppighed<br />
Ved den relative hyppighed forstås hyppigheden divideret med det totale antal.<br />
I eksempel 2.5 er den relative hyppighed for pH - værdier i intervallet ]7.18 - 7.26]:<br />
17<br />
= 02267 . = 2257% .<br />
75<br />
Man kunne sige, at “sandsynligheden” er 22.57% for at pH ligger i dette interval.<br />
Hyppighed<br />
2.3.2 Middelværdi<br />
Kendes hele “populationen” (målt højden på alle danske mænd) kan beregnes en “korrekt midterværdi”<br />
kaldet middelværdi µ (græsk my)<br />
Ud fra stikprøven vil en tilnærmet værdi (kaldet et estimat) for µ være gennemsnittet x (kaldt<br />
x streg).<br />
x1 + x2 + ... + xn<br />
Kaldes observationerne i en stikprøve x1, x2,..., xner x =<br />
n
2 Deskriptiv statistik<br />
Eksempel 2.6: Gennemsnit<br />
Find gennemsnittet af tallene 6, 17, 7, 13, 5, 3<br />
Løsning: x = + + + + + 6 17 7 13 5 3<br />
= 85 .<br />
6<br />
TI 89: Catalog mean ({6, 17, 7, 13, 5, 3}) .<br />
Excel: Tast tallene i en kolonne eksempelvis A1 til A6 Vælg på værktøjslinien fx Middel( A1..A6)<br />
2.3.3 Median:<br />
Medianen beregnes på følgende måde:<br />
1) Observationerne ordnes i rækkefølge efter størrelse.<br />
2a) Ved et ulige antal observationer er medianen det midterste tal<br />
2b) Ved et lige antal er medianen gennemsnittet af de to midterste tal.<br />
Eksempel 2.7: Median<br />
Find medianen af tallene 6, 17, 7, 13, 5, 3.<br />
Løsning: Ordnet i rækkefølge: 3, 5, 6, 7 13, 17. Median 6,5<br />
TI 89: Catalog median ({ 6, 17, 7, 13, 5, 2}) .<br />
Excel: Tast tallene i en kolonne eksempelvis A1 til A6 Vælg fx Median( A1..A6)<br />
Medianen kaldes også for 50% fraktilen, fordi den brøkdel (fraktil) der ligger under medianen<br />
er ca. 50% .<br />
Er median og gennemsnit nogenlunde lige store fordeler tallene sig nogenlunde symmetrisk<br />
omkring middelværdien.<br />
Er medianen mindre end gennemsnittet er der muligvis tale om<br />
en “højreskæv” fordeling som har den “lange” hale til højre.(se<br />
figuren)<br />
Er medianen større end gennemsnittet, er der muligvis tale om en<br />
venstreskæv fordeling<br />
At man eksempelvis i lønstatistikker 1 angives medianen og ikke<br />
gennemsnittet fremgår af følgende lille eksempel.<br />
Lad os antage at en virksomhed har 10 ansatte, med månedslønninger ordnet efter størrelse på<br />
20000, 21000, 22000, 23000, 24000, 25000, 26000, 27000, 28000, 100000<br />
Gennemsnittet er her 31600, mens medianen er 24500.<br />
Medianen ændrer sig ikke selv om den højeste løn vokser fra 100000 til 1 million, mens gennemsnittet<br />
naturligvis vokser. Medianen giver derfor en mere rimelig beskrivelse af middellønnen i<br />
firmaet.<br />
I nævnte lønstatistik er også angivet “nedre og øvre Kvartil” som er det tal som henholdsvis 25%<br />
og 75% af tallene ligger under.<br />
Nedre og øvre kvartil kaldes også 25% fraktil og 75% fraktil.<br />
1<br />
jævnfør statistisk årbog 2005 tabel 144 eller se www.statistikbanken.dk Og vælg løn\lønstatistik for den statslige<br />
sektor\løn32\klik for at vælge\alle værdier\hovedgrupper\ledelse på højt niveau+kontorarbejde<br />
8
Ved at angive dem får man et indtryk af, hvor stor lønspredningen er.<br />
9<br />
2.3 Karakteristiske tal<br />
2.3.4 Spredningsmål<br />
Egentlige målefejl, såsom at nogle af observationerne ikke bliver korrekt registreret, uklarheder<br />
i spørgeskemaet osv. skal naturligvis fjernes.<br />
Derudover er der den “naturlige” variation som også kunne kaldes “ren støj” (pure error), som<br />
skyldes, at man ikke kan forvente, at to personer der på alle områder er stillet fuldstændigt ens<br />
også vil svare ens på et spørgsmål. Tilsvarende hvis man måler udbyttet ved en kemisk proces,<br />
så vil udfaldet af to forsøg ikke være ens, da der altid er en række ukontrollable støjkilder<br />
(urenheder i råmaterialer, lidt forskel på personer og apparatur osv.)<br />
Denne naturlige variation skal naturligvis inddrages i den statistiske behandling af problemet,<br />
og dertil spiller et mål for, hvor meget tallene spreder sig naturligvis en væsentlig rolle..<br />
2.3.4.1 Spredning (engelsk: standard deviation)<br />
Hvis spredningen baserer sig på hele populationen benævnes den σ (sigma) .<br />
Baserer spredningen sig kun på en stikprøve benævnes den s.<br />
Man siger, at s er et estimat (skøn) for σ .<br />
n<br />
∑<br />
( )2<br />
s beregnes af formlen s =<br />
i=<br />
1<br />
xi−x n −1<br />
hvor observationerne i en stikprøve er<br />
Varians er s .<br />
2<br />
Eksempel 2.8: Spredning<br />
Find varians og spredning af tallene 6, 17, 7, 13, 5, 3<br />
Løsning:<br />
I eksempel 2.6 findes gennemsnittet x = 85 .<br />
Variansen s 2 ( 6− 85 . ) + ( 17− 85 . ) + ( 7− 85 . ) + ( 13− 85 . ) + ( 5− 85 . ) + ( 3−85 . )<br />
=<br />
6−1 Spredningen s = =<br />
28 7 5357<br />
. .<br />
TI 89: Catalog Variance ({6, 17, 7, 13, 5, 3}),<br />
Catalog stdDev ({6, 17, 7, 13, 5, 3})<br />
Excel: Tast tallene i en kolonne eksempelvis A1 til A6,<br />
vælg fx Varians( A1..A6)<br />
vælg fx STDDEV( A1..A6)<br />
2 2 2 2 2 2<br />
x1, x2,..., xn = 28. 7
2 Deskriptiv statistik<br />
Anskuelig forklaring på formlen for s.<br />
At formlen for s skulle være særlig velegnet til at angive, hvor meget resultaterne “spreder sig” (hvor megen støj der<br />
er ) er ikke umiddelbart indlysende. I det følgende gives en anskuelig forklaring.<br />
Lad os betragte 2 forsøgsvariable X og Y, hvorpå der for hver er udført en stikprøve på 4 forsøg.<br />
Resultaterne var: X: 35.9, 33.3, 34.7, 34.1 med gennemsnittet x = 34.5 , og<br />
Y: 34.3, 34.6, 34.7, 34.4 med gennemsnittet y = 34.5.<br />
De to forsøgsvariable har samme gennemsnit, men det er klart, at Y-resultaterne grupperer sig meget tættere om<br />
gennemsnittet end X-resultaterne, dvs. Y-stikprøven har mindre spredning (der er mindre støj på Y - forsøget) end Xstikprøven.<br />
For at få et mål for stikprøvens spredning beregnes resultaternes afvigelser fra gennemsnittet.<br />
xi−x y y<br />
10<br />
i −<br />
35.9 - 34.5 = 1.4 34.3 - 34.5 = - 0.2<br />
33.3 -34.5 = - 1.2 34.6 - 34.5 = 0.1<br />
34.7 - 34.5 = 0.2 34.7 - 34.5 = 0.2<br />
34.1 - 34.5 = - 0.4 34.4 - 34.5 = -0.1<br />
Summen af disse afvigelser er naturligvis altid 0 og kan derfor ikke bruges som et mål for stikprøvens spredning.<br />
I stedet betragtes summen af kvadraterne på afvigelserne (forkortet SS: Sum of Squares eller SAK: Sum af afvigelsernes<br />
Kvadrat).<br />
n<br />
∑<br />
2 2 2 2 2<br />
SAK = ( x − x)<br />
= 14 . + ( − 12 . ) + 02 . + ( − 04 . ) = 360 .<br />
x i<br />
i=<br />
1<br />
n<br />
∑<br />
2 2 2 2 2<br />
SAK = ( y − y)<br />
= ( − 02 . ) + 01 . + 02 . + ( − 01 . ) = 010 .<br />
y i<br />
i=<br />
1<br />
Da et mål for variansen ikke må være afhængig af antallet af forsøg, divideres med n - 1.<br />
Umiddelbart ville det være mere rimeligt at dividere med n. Imidlertid kan det vises, at i middel bliver et skøn for<br />
variansen for lille, hvis man dividerer med n, mens den “rammer” præcist, hvis man dividerer med n - 1. Det kan<br />
forklares ved, at tallene xi har en tendens til at ligge tættere ved deres gennemsnit x end ved middelværdien µ .<br />
2 360<br />
sx . og<br />
4 1 12 = − =<br />
.<br />
2 01 .<br />
. sy = = 0. 0333 sx = 12 . = 1095 . sy = 0. 0333 = 0183 .<br />
4− 1<br />
Som vi forudså, er stikprøvens spredning betydelig større for X-resultaterne end for Y-resultaterne.<br />
Frihedsgrader. Man siger, at stikprøvens varians er baseret på f = n - 1 frihedsgrader. Navnet<br />
skyldes, at kun n -1 af de n led xix kan vælges frit, idet summen af de n led er nul. Eksempel-<br />
−<br />
vis ser vi af ovenstående eksempel, at der er 3 frihedsgrader, da kendskab til de første 3 led på<br />
1.4, -1.2 og 0.2 er nok til at bestemme det fjerde led, da summen er nul.<br />
Vurdering af størrelsen af stikprøvens spredning.<br />
Man kan vise, at for tæthedsfunktioner med kun et maksimumspunkt gælder, at mellem x − 2⋅<br />
s<br />
og x + 2⋅s<br />
ligger ca. 89% af resultaterne, og mellem<br />
x −3⋅s og x + 3⋅sligger<br />
ca. 95% af resultaterne.<br />
For såkaldte normalfordelte resultater, er de tilsvarende tal ca. 95% og 99.7 %
1<br />
jævnfør statistisk årbog 2005 tabel 144 eller se www.statistikbanken.dk<br />
under løn\lønstatistik for den offentlige sektor \løn 32<br />
11<br />
2.3 Karakteristiske tal<br />
2.3.4.2 Kvartilafstand:<br />
Hvis fordelingen ikke er rimelig symmetrisk, er medianen det bedste skøn for en midterværdi, og<br />
kvartilafstanden kan være et mål for spredningen.<br />
I den tidligere omtalte lønstatistik 1 findes bl.a. følgende tal, idet de to sidste kolonner er vor<br />
bearbejdning af tallene.<br />
Løn pr. præsteret time<br />
nr gennemsnit x nedre kvartil<br />
k1<br />
median m øvre kvartil<br />
k3<br />
1 Ledelse på højt<br />
niveau<br />
353.41 231.63 313.38 433.78 1.13 0.64<br />
2 Kontorarbejde 196.82 158.86 186.99 222.78 1.05 0.34<br />
x<br />
m<br />
k3−k1 m<br />
x<br />
Af kolonnen ses, at for begge rækker er gennemsnittet større end medianen dvs. begge<br />
m<br />
fordelinger er højreskæv, men det gælder mest for række nr. 1. Her gælder åbenbart, at nogle få<br />
forholdsvis høje lønninger trækker gennemsnittet op.<br />
Skal man sammenligne lønspredningen i de to tilfælde, må man tage hensyn til, at medianen er<br />
meget forskellig. Man vil derfor som der er sket i sidste kolonne beregne den relative kvartilafstand.<br />
Den viser også, at lønspredningen er væsentlig mindre for række 2 end for række 1 .<br />
Eksempel 2.9 Kvartil<br />
Find kvartiler og median af de 12 tal 7 , 9 , 11, 3 , 16, 12, 15, 8, 2, 18, 22, 10<br />
Løsning:<br />
TI89:APPS Stat/List Indtast tal i en liste F4 1-Var Stats Angiv listens navn Enter<br />
Blandt mange tal fås 1 kvartil 7.5 og 3 kvartil 15.5<br />
Excel: 2003 og 2007: Data indtastes i eksempelvis søjle A1 til A12 På værktøjslinien foroven:<br />
f x<br />
Der fremkommer en tabel med anvisning på, hvordan den skal udfyldes<br />
Resultat : 1. kvartil 7.75 3 kvartil 15.25<br />
Tryk på = På rullemenu vælges “Kvartil” (evt. først vælg kategorien “statistik”)<br />
Ligesom man på TI 89 kan få mange karakteristiske tal på en gang ved at vælge “1-Var Stats” har<br />
Excel en tilsvarende menu.<br />
Excel: 2003: Funktioner Dataanalyse Beskrivende statistik udfyld inputområde Resumestatistik<br />
2007: Data Dataanalyse Beskrivende statistik udfyld inputområde Resumestatistik
2 Deskriptiv statistik<br />
OPGAVER<br />
Opgave 2.1.<br />
I www.statistikbanken.dk/luft4 er følgende oplysninger for året 2003 hentet ind i Excel.<br />
Udslip til luft af drivhusgasser efter enhed, type, kilde og tid<br />
2003<br />
Mia. C02-ækvivalenter I alt Energisektoren 32<br />
Industri og produktion 8<br />
Transport 13<br />
Affaldsbehandling 2<br />
Landbrug 10<br />
Andet 9<br />
a) Hent selv disse data ind i Excel, og opstil et lagkagediagram til belysning af tallene.<br />
b) Find de tilsvarende tal for 1996, og vælg en passende grafisk fremstilling til sammenligning<br />
af tallene fra 1996 og 2003.<br />
c) Beregn i Excel for årene 1990 til 2003 energisektorens udslip i forhold til det samlede udslip<br />
af drivhusgasser (i %), og tegn dette grafisk.<br />
Opgave 2.2<br />
Følgende tabel angiver for et udvalgt antal lande oplysning om middellevetid for befolkningen<br />
og indbyggerantal.<br />
Land Middellevetid Indbyggertal i millioner<br />
Australien 80.3 19.9<br />
Canada 80.0 32.5<br />
Danmark 77,5 5.5<br />
Frankrig 79.4 60.4<br />
Marokko 70.4 32.2<br />
Polen 74.2 38.6<br />
Sri Lanka 72.9 19.9<br />
USA 77.4 293.0<br />
1) Indskriv ovenstående tabel i Excel, hvor landene er opskrevet alfabetisk.<br />
Benyt Excel til<br />
1) at ordne landene efter middellevetid (længst levetid først), og afbild dem grafisk.<br />
2) tegn i et koordinatsystem to kurver, som angiver såvel landenes størrelse som middellevetid<br />
Opgave 2.3<br />
I http://www.statistikbanken.dk/statbank5a/default.asp?w=1600 findes nogle oplysninger om<br />
Danmarks forbrug af energi efter type og mængde.<br />
1) Hent produktion af naturgas og råolie ind målt i tons for de sidste 2 år (i måneder) ind i Excel<br />
2) Tegn i Excel i samme koordinatsystem to kurver for henholdsvis produktionen af naturgas og<br />
råolie.<br />
12
13<br />
Opgaver til kapitel 2<br />
Opgave 2.4<br />
Færdselspolitiet overvejede, om der burde indføres en fartgrænse på 70 km/h på en bestemt<br />
landevejsstrækning, hvor der hidtil havde været en fartgrænse på 80 km/h.<br />
Som et led i analysen af hensigtmæssigheden af den overvejede ændring observeredes inden for<br />
et bestemt tidsrum ved hjælp af radarkontrol de forbipasserende bilers fart.<br />
Resultatet af målingerne (som kan findes som excel-fil på adressen www.larsen-net.dk ) var:<br />
50 observationer<br />
64<br />
50<br />
59<br />
75<br />
98<br />
72<br />
63<br />
49<br />
74<br />
55<br />
82<br />
35<br />
55<br />
64<br />
85<br />
52<br />
60<br />
99<br />
74<br />
80<br />
60<br />
77<br />
65<br />
62<br />
78<br />
1) Foretag en vurdering af, om fordelingen er nogenlunde symmetrisk (normalfordelt) ved<br />
a) at tegne et histogram<br />
b) at beregne karakteristiske værdier<br />
2) Angiv hvor stor en procent af bilisterne, der “approksimativt” overstiger hastighedsgrænsen<br />
på 80 km/h. (Vink: Anvend histogram og kumulativ frekvens samt hensigtsmæssige intervalgrænser).<br />
Opgave 2.5<br />
Til fabrikation af herreskjorter benyttes et råmateriale, som indeholder en vis procentdel uld. For<br />
nærmere at undersøge uldprocenten, måles denne i 64 tilfældigt udvalgte batch.<br />
Resultatet (som kan findes som excel-fil på adressen www.larsen-net.dk ) var (i %):<br />
34.2 33.1 34.5 35.6 36.3 35.1 34.7 33.6 33.6 34.7 35.0 35.4 36.2 36.8 35.1 35.3<br />
95<br />
41<br />
76<br />
70<br />
53<br />
33.8 34.2 33.4 34.7 34.6 35.2 35.0 34.9 34.7 33.6 32.5 34.1 35.1 36.8 37.9 36.4<br />
37.8 36.6 35.4 34.6 33.8 37.1 34.0 34.1 32.6 33.1 34.6 35.9 34.7 33.6 32.9 33.5<br />
35.8 37.6 37.3 34.6 35.5 32.8 32.1 34.5 34.6 33.6 24.1 34.7 35.7 36.8 34.3 32.7<br />
1) Foretag en vurdering af, om fordelingen er nogenlunde symmetrisk (normalfordelt) ved<br />
a) at tegne et histogram<br />
b) at beregne karakteristiske værdier<br />
Der er i datamaterialet en såkaldte outliers (en mulig fejlmåling). En sådan kan ødelægge<br />
enhver analyse. Det er i dette tilfælde tilladeligt at fjerne den, da vi går ud fra det er en fejlmåling.<br />
2) Beregn stikprøvens relative kvartilafstand<br />
86<br />
47<br />
76<br />
85<br />
96<br />
70<br />
88<br />
68<br />
73<br />
71<br />
63<br />
62<br />
51<br />
93<br />
84<br />
48<br />
66<br />
80<br />
65<br />
103
2 Deskriptiv statistik<br />
Opgave 2.6<br />
Den følgende tabel (som kan findes som excel-fil på adressen www.larsen-net.dk ) viser vægtene<br />
(i kg) af 80 kaniner.<br />
2.90<br />
2.60<br />
2.45<br />
2.75<br />
2.60<br />
2.55<br />
2.45<br />
2.70<br />
2.75<br />
2.80<br />
2.95<br />
2.65<br />
2.65<br />
2.85<br />
2.45<br />
2,70<br />
3.15<br />
2.95<br />
2.70<br />
2.95<br />
3.20<br />
3.40<br />
2.80<br />
2.95<br />
2.65<br />
2.75<br />
2.90<br />
2.85<br />
2.75<br />
2.90<br />
3.20<br />
3.00<br />
2.70<br />
2.70<br />
2.95<br />
2.85<br />
2.50<br />
2.95<br />
2.65<br />
2.90<br />
2.60<br />
2.95<br />
3.05<br />
3.05<br />
2.95<br />
14<br />
2.90<br />
3.00<br />
2.65<br />
2.90<br />
2.75<br />
2.85<br />
3.25<br />
2.70<br />
3.00<br />
2.75<br />
2.70<br />
2.80<br />
2.70<br />
2.75<br />
2.80<br />
2.80<br />
2.70<br />
3.00<br />
2.60<br />
3.00<br />
2.55<br />
2.60<br />
2.80<br />
3.00<br />
2.50<br />
3.10<br />
2.80<br />
2.70<br />
3.15<br />
3.00<br />
1) Foretag en vurdering af, om fordelingen er nogenlunde symmetrisk (normalfordelt) ved<br />
a) at tegne et histogram<br />
b) at beregne karakteristiske værdier<br />
2) Angiv hvor stor en procent af kaninerne, der “approksimativt” overstiger en vægt på 3 kg<br />
(Vink: Anvend histogram og kumulativ frekvens).<br />
2.90<br />
2.70<br />
3.00<br />
2.60<br />
3.15<br />
Opgave 2.7<br />
I “statistikbanken” finder man under punktet “Uddannelse og kultur”,”Fuldførte kompetancegivende<br />
uddannelser ved bacheloruddannelserne” en statistik over antal elever i “Maskinteknik”<br />
og “Design og Innovation” i 2008 fordelt efter alder fra 20 til 36 år for hele landet.<br />
1) Indsæt data i Excel for de to uddannelser.<br />
2) Lav et søjlediagram over aldersfordelingen for de to uddannelser<br />
3) Beregn på basis af ovennævnte tal den gennemsnitlige alder af de studerende for de to uddannelser<br />
i.<br />
Opgave 2.8<br />
I “statistikbanken” find under Løn ,fortjeneste for privatansatte efteruddannelse osv., Højere<br />
uddannelse, Teknisk, ledere i 2008<br />
“Gennemsnit, median, øvre og nedre kvartil for såvel mænd som kvinder “<br />
1) Overfør data til Excel på egen harddisk<br />
2) Angiv om de to fordelinger er symmetrisk, højre eller venstreskæv<br />
3) Er der forskel på lønspredningen for mænd og kvinder<br />
(Vink: Beregn den relative kvartilafstand)
15<br />
3.1 Sandsynlighed<br />
3 KONTINUERT STOKASTISK VARIABEL<br />
3.1 SANDSYNLIGHED<br />
Statistik bygger på sandsynlighedsteorien, som giver metoder til at finde, hvor stor chancen<br />
(sandsynligheden) er for at et bestemt resultat af et eksperiment forekommer.<br />
DEFINITION af tilfældigt eksperiment. Et eksperiment som kan resultere i forskellige<br />
udfald, selv om eksperimentet gentages på samme måde hver gang, kaldes et tilfældigt<br />
eksperiment (engelsk : random experiment).<br />
Det er karakteristisk for tilfældige eksperimenter, at man kan afgrænse en mængde kaldet<br />
eksperimentets udfaldsrum U, der indeholder de mulige udfald. Derimod kan man ikke forudsige,<br />
hvilket udfald der vil indtræffe ved udførelsen af eksperimentet.<br />
Består eksperimentet eksempelvis i kast med en terning er udfaldsrummet U = {1, 2, 3, 4 ,5, 6},<br />
men man kan ikke forudsige udfaldet af næste kast (eksperiment). Selv om man 4 gange i træk<br />
har fået udfaldet “øjental 1", kan man ikke forudsige, hvilket udfald der indtræffer næste gang.<br />
Resultatet af 5. kast afhænger ikke af resultaterne af de foregående 4 spil. Man siger, at eksperimenterne<br />
er "statistisk uafhængige" (en præcis definition ses i kapitel 9).<br />
Som eksempler på tilfældige eksperimenter kan nævnes:<br />
a) Ét kast med en mønt. Udfaldsrum U = Plat, Krone .<br />
{ }<br />
b) Fremstilling af et parti levnedsmiddel og måling af det procentvise indhold af protein.<br />
U = mængden af reelle tal fra 0 til 100.<br />
c) Udtage en stikprøve på 400 elektroniske komponenter af en dagsproduktion og optælling af<br />
0, 1, 2, 3, 4, 5,..., 400<br />
antallet af defekte komponenter. U = { }<br />
d) Udtagning af et tilfældigt TV-apparat fra en dagsproduktion af TV-apparater og optælling af<br />
antallet af loddefejl. U = mængden af positive hele tal.<br />
En hændelse er en delmængde af et eksperiments udfaldsrum.<br />
Eksempelvis er A: “At få et lige øjental” en hændelse ved kast med en terning.<br />
Hændelsen A siges at indtræffe, hvis et udfald fra A forekommer.<br />
Sandsynlighedsbegrebet tager udgangspunkt i det i kapitel 1 omtalte begreb “relativ hyppighed”.<br />
DEFINITION af relativ hyppighed for hændelse A. Gentages et eksperiment n gange,<br />
og forekommer hændelsen A netop n A gange af de n gange, er A’s relative<br />
n<br />
hyppighed hA ( )=<br />
n<br />
A
3. Kontinuert stokastisk variabel<br />
Lad eksempelvis eksperimentet være kast med en terning og hændelsen A være at få et lige<br />
øjental. Kastes terningen 100 gange og bliver resultatet et lige øjental 45 af de 100 gange er h(A)<br />
= 0.45.<br />
Det er en erfaring, at øges antallet af gentagelser af eksperimentet, vil den relative hyppighed af<br />
hændelsen A stabilisere sig. Når n går mod ∞ ,vil den relative hyppighed erfaringsmæssigt<br />
nærme sig til en grænseværdi ("de store tals lov").<br />
Ved sandsynligheden for A som benævnes P(A) forstås denne grænseværdi. (P = probability)<br />
Da definitionen af sandsynlighed bygger på relativ hyppighed, er det naturligt, at det for ethvert<br />
par af hændelser A og B i udfaldsrummet U skal gælde :<br />
0≤ P( A)<br />
≤1,<br />
PU ( )= 1 og<br />
P(enten A eller B) = P(A) + P(B) forudsat A og B ingen elementer har fælles (er disjunkte).<br />
Den sidste regel skrives kort P( A∪ B) = P( A) + P( B)<br />
Eksempel 3.1 Anvendelse af regel P( A∪ B) = P( A) + P( B)<br />
Lad A = at få et lige øjental ved kast med en terning<br />
B = at få en sekser ved et kast mad en terning<br />
Find sandsynligheden for enten at få et lige øjental eller en sekser ved kast med en terning.<br />
Løsning:<br />
1 1<br />
1 1 2<br />
P(A) = . P(B) =<br />
P( A∪ B) = P( A) + P( B)<br />
= + =<br />
2 6<br />
2 6 3<br />
De 3 regler kaldes sandsynlighedsregningens aksiomer.<br />
I kapitel 8 udledes på dette grundlag en række regler for regning med sandsynligheder.<br />
3.2 STOKASTISK VARIABEL<br />
Ethvert statistisk problem må det på en eller anden måde være muligt at behandle talmæssigt.<br />
Betragtes et eksempel med kast med en mønt, kunne man til udfaldet plat tilordne tallet 0 og til<br />
udfaldet krone tilordne tallet 1 og på den måde få problemet overført til noget, hvor man kan<br />
foretage beregninger. Man siger, man har indført en stokastisk (eller statistisk) variabel X, som<br />
er 0, når udfaldet er plat, og 1 når udfaldet er krone.<br />
Generelt gælder følgende definition:<br />
DEFINITION af stokastisk variabel (engelsk: random variable). En stokastisk variabel<br />
(også kaldet statistisk variabel) er en funktion, som tilordner et reelt tal til hvert udfald i<br />
udfaldsrummet for et tilfældigt eksperiment.<br />
En stokastisk variabel betegnes med et stort bogstav såsom X, mens det tilsvarende lille bogstav<br />
x betegner en mulig værdi af X.<br />
Er eksempelvis eksperimentet “udtagning af en kasse med 100 møtrikker, ud af en løbende<br />
produktion af kasser”, kunne den stokastiske variabel X være defineret som “ antal defekte<br />
møtrikker i kassen”.<br />
16
17<br />
3.3 Tæthedsfunktion<br />
Et andet eksempel kunne være eksperimentet “anvendelse af en ny metode til fremstilling af et<br />
produkt”. Her kunne den stokastiske variabel Y være det målte procentvise udbytte ved forsøget.<br />
Ved en diskret variabel (eller tællevariabel) forstås en variabel, hvis mulige værdier udgør en<br />
endelig eller tællelig mængde.<br />
I eksemplet hvor X er antal defekte møtrikker, er X en diskret variabel, da den kun kan antage<br />
heltallige værdier fra 0 til 100.<br />
Vi vil i senere afsnit behandle diskrete variable.<br />
Ved en kontinuert stokastisk variabel forstås en stokastisk variabel, hvis mulige værdier er alle<br />
reelle tal i et vist interval.<br />
I eksemplet, hvor Y er det målte procentiske udbytte, er Y en kontinuert variabel, da den kan<br />
antage alle værdier fra 0% til 100%.<br />
3.3 TÆTHEDSFUNKTION<br />
Vi vil benytte eksempel 1.5 til illustration.<br />
Eksempel 3.2. Kontinuert stokastisk variabel<br />
I menneskers led udskiller den inderste hinde en "ledvæske" som "smører" leddet. For visse<br />
ledsygdomme kan koncentrationen af brintioner (pH) i denne væske tænkes at have betydning.<br />
Som led i en nordisk medicinsk undersøgelse af en bestemt ledsygdom udtog man blandt samtlige<br />
patienter der led af denne sygdom tilfældigt 75 patienter og målte pH i ledvæsken i knæet.<br />
Resultaterne findes i eksempel 1.5<br />
Population og stikprøve. Samtlige indbyggere i Norden med denne sygdom udgør populationen.<br />
Da det er ganske uoverkommeligt at undersøge alle, udtages en stikprøve på 75 patienter.<br />
Det er målet ved hjælp af statistiske metoder på basis af en stikprøve at sige noget generelt om<br />
populationen.<br />
Histogram. For at få et overblik over et større datamateriale, vil man sædvanligvis starte med<br />
at tegne et histogram. Hvorledes dette gøres fremgår af eksempel 1.5.<br />
I skemaet ses resultatet af en opdeling i 10 klasser med en bredde på 0.08.<br />
Endvidere er der beregnet en søjle ved at dividere den relative hyppighed med intervallængden.<br />
Klasser Antal n Relativ hyppighed<br />
n<br />
75<br />
Skalering<br />
]6.94 - 7.02] 2 0.0267 0.3333<br />
]7.02 - 7.10] 5 0.0667 0.8333<br />
]7.10 - 7.18] 8 0.1067 1.3333<br />
]7.18 - 7.26] 17 0.2267 2.8333<br />
]7.26 - 7.34] 18 0.2400 3.0000<br />
]7.34 - 7.42] 16 0.2133 2.6667<br />
]7.42 - 7.50] 4 0.0533 0.6667<br />
]7.50 - 7.58] 3 0.0400 0.5000<br />
]7.58 - 7.66] 1 0.0133 0.1667<br />
]7.66 - 7.74] 1 0.0133 0.1667<br />
n<br />
75⋅ 0. 08
3. Kontinuert stokastisk variabel<br />
Vi får det nedenfor tegnede histogram (kan ses beregnet i eksempel 1.5)<br />
Dette viser et "klokkeformet histogram", hvor der er flest tal fra 7.19 til 7.42, og derefter falder<br />
antallet til begge sider.<br />
18<br />
15<br />
12<br />
9<br />
6<br />
3<br />
Histogram for pH<br />
0<br />
6,9 7,1 7,3 7,5 7,7 7,9<br />
pH<br />
Man regner normalt med, at resultaterne af forsøg hvor man har foretaget målinger (hvis man<br />
lavede nok af dem) har et sådant klokkeformet histogram. Hvis man tænker sig antallet af forsøg<br />
stiger (for eksempel undersøger hele populationen på måske 1 million nordiske knæ), samtidig<br />
6<br />
med at man øger antallet af klasser tilsvarende (til for eksempel 10 ≈ 1000 ) , vil histogrammet<br />
blive mere og mere fintakket, og til sidst nærme sig til en kontinuert klokkeformet kurve (indtegnet<br />
på grafen).<br />
Hvis man benytter den skalerede skala fra skemaet, som også er afsat på højre side af tegningen,<br />
vil arealet af hver søjle være den relative hyppighed, og for den idealiserede kontinuerte kurve,<br />
vil arealet under kurven i et bestemt interval fra a til b være sandsynligheden for at få en værdi<br />
mellem a og b.<br />
Det samlede areal under kurven er naturligvis 1.<br />
Man siger, at den kontinuerte stokastiske variabel X (pH værdien) har en tæthedsfunktion f(x)<br />
hvis graf er den ovenfor nævnte kontinuerte kurve.<br />
Da arealet under en kontinuert kurve beregnes ved et bestemt integral, følger heraf følgende<br />
definition:<br />
DEFINITION af tæthedsfunktion f(x) for kontinuert variabel X.<br />
Pa ( ≤ X≤ b) = f( xdx ) for ethvert interval af reelle tal<br />
∫ [ a; b]<br />
∞<br />
a<br />
b<br />
∫ f ( x) dx = 1, f ( x)≥0for<br />
alle x<br />
−∞<br />
Bemærk, at for kontinuerte variable er<br />
Pa ( ≤ X≤ b) = Pa ( < X≤ b) = Pa ( ≤ X< b) = Pa ( < X< b).<br />
18
19<br />
3.3 Tæthedsfunktion<br />
Et eksempel på en tæthedsfunktion for en kontinuert variabel er den i næste kapitel beskrevne<br />
normalfordeling.<br />
Måleresultater vil sædvanligvis være værdier af normalfordelte variable, så en rimelig hypotese<br />
for den i eksempel 3.2 angivne kontinuerte stokastiske variabel X = pH er således, at den er<br />
normalfordelt. Dette bestyrkes af at grafen for sådanne netop er klokkeformede .<br />
Det er væsentlig at finde en central værdi i populationen, samt angive et spredningsmål<br />
Disse angives i de følgende kapitler for de konkrete funktioner, der behandles.<br />
Generelt gælder følgende definitioner<br />
DEFINITION af middelværdi for kontinuert variabel. Middelværdi for en kontinuert variabel X med tætheds-<br />
∞<br />
funktion f ( x ) benævnes µ eller E ( X ) og er defineret som µ = E( X) = x⋅ f ( x) dx<br />
DEFINITION af varians og spredning for kontinuert variabel. Variansen for en kontinuert variabel X med<br />
tæthedsfunktion f ( x ) benævnes σ eller V( X ) og er defineret som<br />
2 2<br />
σ = V( X) =<br />
∞<br />
2<br />
( x−µ ) ⋅ f ( x) dx<br />
Spredningen (engelsk: standard deviation) for en diskret variabel X med tæthedsfunktion f(x) benævnes σ og er<br />
defineret som σ = V( X)<br />
Eksempel 3.3 Kontinuert stokastisk variabel.<br />
3 2<br />
⎧⎪<br />
⋅x for 0≤ x<<br />
2<br />
8<br />
Lad der være givet følgende funktion: f ( x)=<br />
⎨<br />
.<br />
⎩⎪ 0 ellers<br />
∫<br />
a) Vis, at f ( x) dx = 1<br />
∞<br />
−∞<br />
I det følgende antages, at f ( x ) er tæthedsfunktion for en kontinuert stokastisk variabel X.<br />
b) Skitser grafen for f.<br />
c) Beregn middelværdi og spredning for X.<br />
Løsning:<br />
x<br />
a) f ( x) dx = x dx = .<br />
⎡ ⎤<br />
⎢ ⎥<br />
⎣ ⎦<br />
=<br />
∞<br />
2<br />
3<br />
3 2<br />
∫−∞ ∫<br />
1<br />
0<br />
8<br />
8<br />
b) Grafen, som er en del af en parabel, ses på Fig 3.1.<br />
c) µ = = ⋅ = ⋅ = .<br />
⎡ ⎤<br />
⎢ ⎥<br />
⎣ ⎦<br />
=<br />
∞<br />
2<br />
4<br />
2<br />
3 2 x 3<br />
E( X) ∫ x f ( x) dx<br />
−∞ ∫ x x dx 3<br />
0 8 32 2<br />
2<br />
0<br />
0<br />
2 5<br />
∫<br />
−∞<br />
∫<br />
−∞<br />
Fig.3.1 Tæthedsfunktion<br />
x<br />
V( X) = x ⋅ f ( x) dx − = x ⋅ x dx − . . . .<br />
⎛ ⎞<br />
⎜ ⎟ =<br />
⎝ ⎠<br />
⎡<br />
∞<br />
2<br />
2 2 2 3 2 3 ⎤<br />
∫ µ ⎢ ⎥ − =<br />
−∞<br />
∫<br />
3 225 015 σ ( X ) = 015 . = 0. 387<br />
0 8 2 ⎣ 40⎦<br />
2<br />
0
3. Kontinuert stokastisk variabel<br />
Fordelingsfunktion. I visse situationer er det en fordel at betragte den kontinuerte variabels fordelingsfunktion F(x)<br />
DEFINITION af fordelingsfunktion F(x) for kontinuert variabel.<br />
x<br />
Fordelingsfunktionen for en kontinuert variabel X er defineret ved F( x) = P( X ≤ x) = ∫ f ( x) dx<br />
−∞<br />
DEFINITION af p-fraktil . Lad p være et vilkårligt tal mellem 0 og 1.<br />
Ved p-fraktilen eller 100 p % fraktilen forstås det tal , for hvilket det gælder, at<br />
F( x ) = P( X ≤ x ) = p ( ( ) )<br />
p p<br />
x p<br />
= ∫ f x dx<br />
0<br />
x p<br />
Særlig ofte benyttede fraktiler er 50% fraktilen, som kaldes medianen (eller 2. kvartil), 25 % fraktilen, som kaldes<br />
nedre kvartil (eller 1. kvartil) og 75% fraktilen, som kaldes øvre kvartil (eller 3. kvartil).<br />
Eksempel 3.4. Fordelingsfunktion for kontinuert variabel.<br />
For den i eksempel 3.3 angivne kontinuerte variabel X med tæthedsfunktion f (x) ønskes fundet:<br />
1) Fordelingsfunktionen F (x).<br />
x<br />
2) Medianen .<br />
dx x<br />
Løsning:<br />
x<br />
x<br />
x x x<br />
1) F( x) = f ( x) dx = + xdx=<br />
x<br />
.<br />
x<br />
+ dx=<br />
⎡<br />
⎧<br />
⎪∫<br />
0<br />
−∞<br />
⎪<br />
⎪<br />
⎤<br />
∫<br />
⎨0<br />
⎢ ⎥ = ≤ ≤<br />
−∞ ∫<br />
0 2<br />
⎪<br />
⎣ 8 ⎦ 8<br />
⎪<br />
⎪0<br />
+<br />
⎩⎪<br />
∫<br />
2<br />
= 0 for < 0<br />
3<br />
3<br />
3 2<br />
for<br />
0<br />
8<br />
0<br />
3<br />
0 1 for x > 2<br />
8 2<br />
3<br />
x<br />
3<br />
2) Medianen er bestemt ved F( x)<br />
= 05 . ⇔ = 05 . ⇔ x = 4⇔ x = 159 . .<br />
8<br />
20
3.4 Linearkombination af stokastiske variable<br />
3.4 LINEARKOMBINATION AF STOKASTISKE VARIABLE<br />
Vi betragter i dette afsnit flere stokastiske variable.<br />
Eksempel 3.5 vil blive benyttet som gennemgående eksempel<br />
Eksempel 3.5. To variable.<br />
Insektpulver sælges i papkartoner. Lad den stokastiske variable X 1 være vægten af pulveret, mens<br />
X 2 er vægten af papkartonen. I middel fyldes der 500 gram insektpulver i hver karton med en<br />
spredning på 5 gram. Kartonen vejer i middel 10 gram med en spredning på 1.0 gram.<br />
Y = X 1 + X 2 er da bruttovægten.<br />
1) Find middelværdien af Y<br />
2) Find spredning af Y.<br />
Mere generelt haves:<br />
Lad X1, X2,..., Xnvære n stokastiske variable.<br />
Ved en linearkombination af disse forstås<br />
Y = a0 + a1 ⋅ X1 + a2 ⋅ X2 + ... + an ⋅ Xn<br />
, hvor a0, a1, a2,..., aner konstanter.<br />
Man kan vise (se eventuelt kapitel 9) at der gælder følgende<br />
Linearitetsregel: E( Y) = a + a ⋅ E( X ) + a ⋅ E( X ) + ... + a ⋅E(<br />
X ) .<br />
0 1 1 2 2<br />
21<br />
n n<br />
I eksempel 3.5 synes det rimeligt at antage, at vægten af pulveret og vægten af papkartonen er<br />
uafhængige ( påfyldningen kan tænkes at ske maskinelt, uden at den er afhængig på nogen måde<br />
af hvilken vægt, kartonen tilfældigvis har).<br />
Man kan vise (se eventuelt kapitel 11, for en mere udførlig behandling af uafhængighed m.m.),<br />
at hvis X1, X2,..., Xner statistisk uafhængige, gælder<br />
Kvadratregel for statistisk uafhængige variable:<br />
2<br />
VY ( ) = a ⋅ V( X<br />
2<br />
) + a ⋅ V( X<br />
2<br />
) + ... + a ⋅V(<br />
X )<br />
1<br />
1 2<br />
2<br />
n n<br />
Eksempel 3.5. (fortsat) To variable.<br />
Spørgsmål 1: E(Y) = E(X1) + E(X2) = 500 + 10 = 510 gram.<br />
Spørgsmål 2: V(Y) = V(X1) + V(X2) = 5 2 + 1 2 = 26. σ ( Y ) = 26 = 51 . gram.<br />
Ensfordelte uafhængige variable.<br />
Lad os antage, at vi uafhængigt af hinanden og under de samme betingelser udtager n elementer<br />
fra en population med middelværdi og spredning . Lad være den stokastiske variabel,<br />
µ σ X 1<br />
der er resultatet af første udtagning af et element i stikprøven, være den stokastiske variabel,<br />
X 2<br />
der er resultatet af anden udtagning, osv.<br />
X1, X2,..., Xnvil da være ensfordelte uafhængige stokastiske variable, dvs. have samme<br />
fordeling med middelværdi µ og spredning σ<br />
.<br />
.
3. Kontinuert stokastisk variabel<br />
Eksempel 3.6. Ensfordelte variable<br />
Bruttovægten af det i eksempel 3.4 nævnte karton insektpulver havde middelvægten 510 g med<br />
en spredning på 5.1 g.<br />
Vi udtager nu tilfældigt og uafhængigt af hinanden 10 pakker insektpulver.<br />
a) Hvad bliver i middel den samlede vægt af de 10 kartonner<br />
b) Hvad bliver i middel spredningen på den samlede vægt af de 10 kartoner<br />
Løsning:<br />
Lad X1 være vægten af karton 1, X2 være vægten af karton 2 osv. X10 være vægten af karton 10.<br />
Y= X1 + X2 + ... + X10 er da vægten af alle 10 kartonner.<br />
a) E(Y) = E(X1)+E(X2)+ . . . +E(X10) =10⋅ 510 = 5100 g<br />
b) V(Y) = V(X1)+V(X2)+ . . . +V(X10) =10⋅ 26 = 260 g<br />
σ ( Y ) = 260 = 1612 .<br />
Bemærk: En almindelig fejl er her, at man tror, at Y=10 X og dermed V(Y)=102 ⋅ ⋅ V(X)=2600<br />
Vi har her at gøre med 10 ensfordelte uafhængige variable, og ikke 10 ⋅ vægten af 1 karton.<br />
For ensfordelte uafhængige stokastiske variable gælder:<br />
SÆTNING 3.1 (middelværdi og spredning for stikprøves gennemsnit )<br />
σ<br />
X1 + X2 + ...<br />
+ Xn<br />
E( X)=<br />
µ og σ ( X ) = , hvor X =<br />
n<br />
n<br />
⎛ X + X + ... + X<br />
Bevis: Af linearitetsreglen fås n<br />
E( X) = E⎜<br />
1 2<br />
⎞ 1<br />
⎟<br />
⎜<br />
⎟ ( ( ) ( ) ... ( ) )<br />
n n E X E X E X = + + + = µ<br />
⎝<br />
⎠ 1 2 n<br />
X + X + ... X 2 2<br />
⎛ 1 1 n ⎞ 1<br />
n ⋅ σ ο<br />
Af kvadratreglen fås V( X) = V⎜<br />
⎟ = ( V( X ) + V( X ) + ... + V( Xn) ) = = .<br />
⎝ n ⎠ 2 1 2<br />
2<br />
n<br />
n n<br />
Eksempel 3.7. Spredning på gennemsnit (eksempel 3.5 fortsat)<br />
Hvis der udtages 5 kartoner insektpulver, hvad vil da være spredningen på gennemsnittet af<br />
vægten af insektpulveret .<br />
Løsning:<br />
Da spredningen på 1 karton er 5.1 gram, vil spredningen på gennemsnittet af 5 kartoner være<br />
σ 51 .<br />
σ ( X ) = = = 228 .<br />
n 5<br />
22
3.5 USIKKERHEDSBEREGNING<br />
23<br />
3.5 Usikkerhedsberegning<br />
Ved enhver måling kan den fysiske størrelse aldrig måles eksakt. Målingen behæftes altid med<br />
en vis usikkerhed. Det kan skyldes usikkerhed på objektet, måleinstrumentet, brugeren af<br />
instrumentet osv.<br />
Systematiske fejl er fejl, hvor man eksempelvis har glemt at korrigere for temperaturens indflydelse<br />
på måling af et stofs hårhed.<br />
Er målingen befriet for systematiske fejl, er der kun tilbage “tilfældige fejl”.<br />
Eksempelvis vil der ofte på et instrument være anført en “instrumentusikkerhed”, som viser hvor<br />
nøjagtigt instrumentet kan måle.<br />
En sådan usikkerhed kan eksempelvis findes ved at man foretager en måling flere gange eventuelt<br />
af forskellige personer.<br />
Lad der eksempelvis være foretaget 5 målinger og resultaterne er x1, x2, x3, x4, x5<br />
Lad gennemsnittet af de 5 målinger være x .<br />
“Maksimal” usikkerhed<br />
Den maksimale usikkerhed ∆x er så defineret som den numerisk største afvigelse mellem en målt<br />
værdi og gennemsnittet.<br />
Er eksempelvis en temperatur angivet som 30.45 0<br />
± 0.05 menes hermed, at i værst tænkelige<br />
tilfælde kunne målingen være 30.40 0 eller 30.50 0 .<br />
Eksempel 3.8. Maksimal usikkerhed<br />
Lad x = 153 ± 1m og y = 25 ± 2 m<br />
Den maksimale usikkerhed på x - y er da 3m , dvs. x-y = 128 ± 3 m<br />
Statistisk usikkerhed<br />
Ved den statistiske usikkerhed regner man populært sagt med at fejlene til en vis grad ophæver<br />
hinanden. Det er jo ret usandsynligt, hvis man har mange målinger, at de alle ligger i den samme<br />
høje ende af usikkerhedsintervallet<br />
Her siger man derfor at spredningen er et mål for usikkerheden.<br />
Eksempel 3.9 Statistisk usikkerhed<br />
Lad x = 153 med en spredning på 1m og y = 25 med en spredning på 2m<br />
X og Y antages at være uafhængige målinger,<br />
2 2<br />
Den statistiske usikkerhed på x-y vil ifølge kvadratsætningen være σ = 1 + 2 = 5 = 224 . m<br />
Relativ usikkerhed<br />
∆x<br />
Ved den relative usikkerhed på en størrelse x forstås størrelsen henholdsvis<br />
x<br />
1<br />
I eksemplerne 3.7 og 3.8 er den relative usikkerhed på x således = 0. 65%<br />
153<br />
Usikkerheden på to størrelser kan jo godt være den samme , f.eks. 1 cm, men hvis den ene<br />
størrelse er usikkerheden på diameteren af et rør på 10 cm og den anden er højden på en skyskraber,<br />
så er det klart, at det er den relative usikkerhed, der siger mest.<br />
s<br />
x
3. Kontinuert stokastisk variabel<br />
Eksempel 3.8 og 3.9 viser forskellen mellem de to definitioner af usikkerhed.<br />
Vi vil i det følgende koncentrere os om den statistiske usikkerhed σ , som vi i det følgende kort<br />
vil benævne usikkerheden.<br />
Vi vil dog også kort angive, hvorledes tilsvarende beregninger af maksimal usikkerhed vil<br />
forløbe.<br />
Som eksemplerne 3.8 og 3.9 viser, er det let at udregne usikkerheden på summer og differenser<br />
af to eller flere størrelser.<br />
De følgende formler viser hvorledes man beregner usikkerheden på mere komplicerede udtryk.<br />
Eksempel 3.10 Usikkerhed på sammensat udtryk<br />
Måles trykket P, volumenet V og temperaturen T af en ideal gas , optræder der tilfældige<br />
målefejl, som gør værdierne usikre. Beregnes molantallet n nu af ligningen<br />
PV ⋅<br />
PV ⋅ = n⋅RT ⋅ ⇔ n=<br />
, bliver værdien af n derfor også usikker. Vi ønsker at kunne<br />
RT ⋅<br />
beregne usikkerheden på n ud fra usikkerhederne på P, V og T.<br />
Sætning 3.2. (ophobningsloven for usikkerheder)<br />
Lad X1,X2, . . . , X være uafhængige stokastiske variable, som hidrører fra målinger.<br />
og lad X1 have usikkerheden σ 1 ,X2 have usikkerheden σ 2 osv.<br />
Beregnes en ny størrelse Y = f ( X1, X2 ,..., Xn) , i et punkt P = ( x1, x2, ,..., xn) får Y en usikker-<br />
hed σ ( Y)<br />
som kan beregnes på følgende måde:<br />
Lad ∂Y<br />
∂Y<br />
∂Y<br />
( P) = a1,<br />
( P) = a2,...,<br />
( P) = an<br />
∂X<br />
∂X<br />
∂X<br />
1<br />
Der gælder da<br />
2<br />
n<br />
Ved den praktiske brug af formlerne for relative fejl og den ophobede fejl kan man erstatte alle<br />
middelværdier med de faktisk målte værdier.<br />
Bevis for ophobningsloven, Funktionen Y = f ( X1, X2,..., Xn) tilnærmes ved sit 1. Taylorpolynomium med<br />
∂Y<br />
∂Y<br />
∂Y<br />
udviklingspunkt i punktet P: Y = f ( X1, X2,..., Xn) ≈ Y( P)<br />
+ ⋅( X1− x1)<br />
+ ⋅( X2 − x2)<br />
+ ... + ⋅( Xn −xn),<br />
∂X1<br />
∂X<br />
2<br />
∂X<br />
n<br />
hvor de partielle afledede er beregnet i punktet P. Vi finder derfor<br />
∂Y<br />
∂<br />
∂<br />
Y = f ( X1, X2,..., Xn) ≈ konstant + ⋅ + ⋅ + + ⋅<br />
∂X<br />
∂<br />
∂<br />
X<br />
Y<br />
Y<br />
⎛<br />
∂Y<br />
∂Y<br />
∂Y<br />
⎞<br />
1 X 2 ... X k , VY ( ) ≈ V⎜konstant<br />
+ ⋅ X 1 + ⋅ X 2 + ... + ⋅ X k ⎟<br />
1 X 2<br />
X k<br />
⎝ ∂X<br />
1 ∂X<br />
2<br />
∂X<br />
k ⎠<br />
Da X1, X2,..., Xk er forudsat statistisk uafhængige, får vi ifølge kvadratreglen<br />
Y<br />
Y<br />
Y<br />
VY ( ) ≈ V( X ) V( X ) ... V( Xk)<br />
X<br />
X<br />
X<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ +<br />
⎝ ⎠<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ + +<br />
⎝ ⎠<br />
⎛<br />
∂<br />
∂<br />
∂ ⎞<br />
1<br />
2 ⎜ ⎟ ⋅<br />
∂<br />
∂<br />
⎝ ∂ ⎠<br />
1<br />
2<br />
2<br />
2<br />
∂Y<br />
∂Y<br />
∂Y<br />
σ ( Y)<br />
≈ V( X ) V( X ) ... V( Xk)<br />
∂X<br />
∂X<br />
∂X<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ +<br />
⎝ ⎠<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ + +<br />
⎝ ⎠<br />
⎛ ⎞<br />
1<br />
2 ⎜ ⎟ ⋅<br />
⎝ ⎠<br />
1<br />
2<br />
2<br />
2<br />
σ( Y) ≈ a1⋅ σ1+ a2⋅ σ2+ ... + an ⋅σn<br />
2<br />
2<br />
2<br />
2 2 2<br />
For den maksimale usikkerhed gælder med de samme betegnelser som ved ophobningsloven:<br />
∆Y = a1 ∆x1 + a2 ∆x2 + ... + an ∆xn<br />
(svarer til differentialet for en funktion)<br />
k<br />
k<br />
2<br />
2<br />
24
25<br />
3.5 Usikkerhedsberegning<br />
Eksempel 3.11. Usikkerhedsberegning.(fortsættelse af eksempel 3.10)<br />
PV ⋅<br />
−1 −1<br />
En ideal gas opfylder ligningen n = , hvor R = 8314 . J⋅K⋅mol .<br />
RT ⋅<br />
Man har målt P = 123400 Pa , V = 567 . m ,<br />
3<br />
T = 678 K<br />
med usikkerheder σ ( P ) = 1000 Pa , σ ( V ) = 006 . m og .<br />
3 σ ( T ) = 3K<br />
Det kan antages, at måleresultaterne for P, V og T er statistisk uafhængige.<br />
a) Find molantallet n, usikkerheden σ ( n) , samt den relative usikkerhed rel( n)<br />
.<br />
Man skønner, at der for de maksimale absolutte fejl gælder<br />
P = 123400 3000 Pa V = 5.67 0.18 m3 ± ± og T = 678 ± 9 K<br />
b) Find den maksimale usikkerhed på n , og den relative maksimale usikkerhed på n.<br />
Løsning<br />
Håndregning:<br />
n mol<br />
PV ⋅ 123400 ⋅ 5. 67<br />
= =<br />
= 12412 .<br />
R ⋅ T 8314 . ⋅ 678<br />
Af ophobningsloven for usikkerheder fås usikkerheden på n:<br />
∂n<br />
V<br />
=<br />
∂P<br />
RT ⋅ =<br />
567 .<br />
∂n<br />
P<br />
= 0. 001006<br />
=<br />
8. 314⋅ 678<br />
∂V<br />
RT ⋅ =<br />
123400<br />
= 218915 .<br />
8. 314⋅ 678<br />
∂n<br />
PV<br />
=<br />
∂T<br />
RT<br />
− ⋅<br />
=<br />
⋅<br />
− ⋅ 123400 567 .<br />
= 0183075 .<br />
2 2<br />
8. 314 ⋅678<br />
a) σ<br />
2<br />
∂n<br />
∂n<br />
∂n<br />
( n)<br />
= σ ( P)<br />
σ ( V ) σ ( T)<br />
∂P<br />
∂V<br />
∂T<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ +<br />
⎝ ⎠<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ +<br />
⎝ ⎠<br />
⎛<br />
2<br />
2 ⎞ 2<br />
⎜ ⎟ ⋅<br />
⎝ ⎠<br />
2<br />
= 0. 001006 ⋅ 1000 + 218915 . ⋅ 0. 06 + 0183075 . ⋅3<br />
2 2 2 2 2 2<br />
= 101178 . + 172526 . + 0. 30165 = 174318 . = 174 . mol<br />
2<br />
σ ( n)<br />
174318 .<br />
og dermed den relative usikkerhed rel( n)<br />
= = = 0. 0140443 ≈140%<br />
. .<br />
n 124. 12<br />
n<br />
b) d n = dn<br />
mol<br />
P dP<br />
n<br />
V dV<br />
n<br />
T dT<br />
∂ ∂ ∂<br />
= + + = 0. 00106⋅ 3000 + 218915 . ⋅ 018 . + 0183075 . ⋅ 9 = 8. 768<br />
∂ ∂ ∂<br />
dn ( ) 18. 768<br />
rel( n)<br />
= = = 706% .<br />
n 12412 .<br />
TI 89<br />
p*v/(8.314*t) STO n<br />
n v=5.67 and p=123400 and t=678 Resultat n = 124.12<br />
d(n,p) v=5.67 and p=123400 and t=678 STO a<br />
d(n,v) v=5.67 and p=123400 and t=678 STO b<br />
d(n,t) v=5.67 and p=123400 and t=678 STO c<br />
a) ((a*1000)^2+(b*0.06)^2+(c*3)^2) Resultat σ( n ) = 17432 .<br />
rel(n) =1.7432/124.12 = 0.0140 = 1.4%<br />
b) a*3000+b*0.18+c*9 = rel(n)=8.768//12412 )= 0.0706<br />
Excel Ikke muligt, da ikke kan differentiere.<br />
,
Statistiske <strong>grundbegreber</strong><br />
OPGAVER<br />
Opgave 3.1<br />
Givet følgende funktion:<br />
1<br />
⎧ 4 ( 3− x) for 0< x<<br />
2<br />
f ( x)<br />
= ⎨<br />
⎩0<br />
ellers<br />
∫<br />
1) Vis, at f (x) opfylder betingelsen f ( x) dx = 1 der indgår i kravet til en tæthedsfunktion.<br />
a<br />
b<br />
Idet følgende antages, at f ( x ) er tæthedsfunktion for en stokastisk variabel X .<br />
2) Skitser grafen for f (x ) , find den tilsvarende fordelingsfunktion F ( x ) og skitser også dennes graf.<br />
3) Beregn middelværdien E(X), variansen V (X ) og spredningen σ ( X ) .<br />
4) Bestem P(. 025≤ X < 05 .)<br />
Opgave 3.2<br />
Givet følgende funktion:<br />
⎧ 3<br />
⎪ for 1≤ x<br />
4<br />
f ( x) = ⎨ x<br />
⎪<br />
⎩0<br />
ellers<br />
b<br />
1) Vis, at f (x) opfylder betingelsen f ( x) dx = 1 der indgår i kravet til en tæthedsfunktion.<br />
∫<br />
a<br />
Idet følgende antages, at f ( x ) er tæthedsfunktion for en stokastisk variabel X .<br />
2) Skitser grafen for f (x ) , find den tilsvarende fordelingsfunktion F ( x ) og skitser dens graf.<br />
3) Beregn middelværdien E(X), variansen V (X ) og spredningen σ ( X ) .<br />
4) Bestem P( 2≤ X ≤3)<br />
.<br />
Opgave 3.3<br />
Vægten af en (tilfældigt udvalgt) tablet af en vis type imod hovedpine har middelværdien<br />
µ = 065 . g og spredningen σ = 004 . g<br />
Beregn middelværdi og spredning af den sammenlagte vægt af 100 (tilfældigt udvalgte) tabletter<br />
Opgave 3.4<br />
En mængde råmateriale til en produktion ligger i kegleformet bunke. En kegle med radius R og<br />
højde H har volumenet V = R H .<br />
π 2<br />
3<br />
Man har målt R = 12. 0 m , H = 110 . m ,<br />
med usikkerheder σ ( R ) = 02 . m , σ ( H ) = 01 . m .<br />
Det kan antages, at måleresultaterne for R og H er statistisk uafhængige.<br />
Find volumenet V, usikkerheden σ ( V ) , samt den relative usikkerhed rel( V ).<br />
Opgave 3.5<br />
For en rektangulær flade har man målt længden L og bredden B :<br />
L = 12. 3 m , B = 84 . m<br />
med usikkerheder<br />
σ ( L ) = 01 . m , σ ( B ) = 02 . m .<br />
Det kan antages, at måleresultaterne for L og B er statistisk uafhængige.<br />
Find fladens areal A, usikkerheden σ ( A) , samt den relative usikkerhed rel( A)<br />
.<br />
26
27<br />
Opgaver til kapitel 3<br />
Opgave 3.6<br />
For et bassin af form som en retvinklet kasse har man målt længden L , bredden B og højden H<br />
:<br />
L = 18. 0 m , B = 12. 3 m H = 45 . m<br />
med usikkerheder σ ( L ) = 02 . m , σ ( B ) = 01 . m , σ ( H ) = 02 . m.<br />
Det kan antages, at måleresultaterne for L, B og H er statistisk uafhængige.<br />
Find bassinets volumen V, usikkerheden σ ( V ) , samt den relative usikkerhed rel( V ).<br />
Opgave 3.7<br />
På den viste forsøgsopstilling kan man foretage målinger til bestemmelse af et stofs længdeudviddelseskoefficient.<br />
l1 er længden af stangen ved starttemeraturen t1. l2 er længden af stangen ved sluttemeraturen t2. Under forsøget er følgende størrelser bestemt.<br />
l1 = 500 ± 0.1 mm<br />
l2 = 500.48 ± 0.1 mm<br />
t2 - t1 = 78 0 0.1 0 ± C<br />
l2 − l1<br />
Længdeudvidelseseskoefficienten k kan bestemmes af udtrykket k =<br />
l2( t2 − t1)<br />
a) Find den maksimale usikkerhed på k<br />
b) Find den relative maksimale usikkerhed på k.<br />
Idet man nu antager, at man har den erfaring, at spredningen på størrelserne er 0.1, skal man<br />
c) Finde den statistiske usikkerhed på k<br />
d) Find den relative statistiske usikkerhed på k.
4.Normalfordelingen.<br />
4 NORMALFORDELINGEN<br />
4.1 INDLEDNING<br />
Lad os som eksempel tænke os et kemisk forsøg, hvor vi måler udbyttet af et stof A. Selv om vi<br />
gentager forsøget ved anvendelse af den samme metode og i øvrigt søger at gøre forsøgsbetingelserne<br />
så ensartet som muligt, varierer udbyttet dog fra forsøg til forsøg. Disse variationer fra den<br />
ene forsøg til det næste må skyldes forhold vi ikke kan styre. Det kan skyldes små ændringer i<br />
temperaturen, i luftens relative fugtighed, vibrationer under fremstillingen, små forskelle i de<br />
anvendte råmaterialer (kornstørrelse, renhed), forskelle i menneskelig reaktionsevne osv. Hvis<br />
ingen af disse variationsårsager er dominerende, der er et stort antal af dem, de er uafhængige og<br />
lige så godt kan have en positiv som en negativ indvirkning på resultatet, så vil den totale fejl<br />
sædvanligvis approksimativt være fordelt efter den såkaldte normalfordeling. (også kaldet<br />
Gauss-fordelingen)<br />
Som illustration af dette kan anvendes Galtons apparat.<br />
Eksempel 4.1. Eksperiment med et Galton-apparat.<br />
På den anførte figur er skitseret et Galton-apparat.<br />
A er en tragt; B er sømrækker, hvor sømmene i en<br />
underliggende række er anbragt midt ud for mellemrummene<br />
mellem sømmene i den overliggende række;<br />
C er opsamlingskanaler.<br />
Lader man mange kugler passere gennem tragten A<br />
ned gennem sømrækkerne B til opsamlingskanalerne<br />
C, vil man konstatere, at de enkelte kugler nok bliver<br />
tilfældigt fordelt i opsamlingskanalerne, men at kuglernes<br />
samlede fordeling giver et mønster, som gentages,<br />
hver gang man udfører eksperimentet. Fordelingen er hver gang med tilnærmelse en<br />
klokkeformet symmetrisk fordeling som skitseret på tegningen, noget som er karakteristisk<br />
for normalfordelingen.<br />
Galton-apparatet illustrerer, hvorfor man så ofte antager, at måleresultater er værdier af en<br />
normalfordelt variabel: Hver sømrække repræsenterer en faktor, hvis niveau det ikke er muligt<br />
at holde konstant fra måling til måling, og sømrækkernes påvirkning af kuglens bane symboliserer<br />
den samlede virkning, som de ukontrollerede faktorer har på størrelsen af den målte<br />
egenskab.<br />
28
4.2 Definition og sætning om normalfordeling<br />
En anden illustration af under hvilke omstændigheder en normalfordelt variabel kan forekomme<br />
i praksis så vi i kapitel 2 eksempel 2.5 hvor man på 75 mennesker med en bestemt ledsygdom<br />
målte pH i knæleddet.<br />
Histogrammet som er gentaget nedenfor har et klokkeformet udseende, som kraftigt antyder, at<br />
den kontinuerte stokastiske variabel X = pH er normalfordelt.<br />
I den teoretiske statistik giver den centrale grænseværdisætning en forklaring på, hvorfor<br />
normalfordelingen er en god model ved mange anvendelser.<br />
Den centrale grænseværdi 1 siger (løst sagt), at selvom man ikke kender fordelingen for de n<br />
ensfordelte stikprøvevariable X1, X2,..., Xn, så vil gennemsnittet X være approksimativt<br />
normalfordelt blot n er tilstrækkelig stor (i praksis over 30) . 2<br />
4.2 DEFINITION OG SÆTNINGER OM NORMALFORDELING<br />
Definition af normalfordeling n( µ , σ )<br />
Nornalfordelingen er sandsynlighedsfordelingen for en kontinuert stokastisk variabel X med<br />
tæthedsfunktionen f(x) bestemt ved f ( x)= Den har middelværdi µ og spredning σ<br />
2<br />
1 ⎛ x−<br />
µ ⎞<br />
− ⋅ 1<br />
⎜ ⎟<br />
2 ⎝ σ ⎠<br />
⋅ e<br />
2 ⋅π ⋅σ<br />
for ethvert x<br />
Grafen er klokkeformet og symmetrisk om linien x = µ .<br />
1<br />
Den centrale grænseværdi sætning. Lad som ovenfor X være gennemsnittet for en stikprøve af størrelsen n taget fra<br />
en population med middelværdi µ og spredning σ .<br />
StørrelsenU vil da for n gående mod være normeret normalfordelt.<br />
X − µ<br />
=<br />
∞<br />
σ<br />
n<br />
2 ⎛ ( X − µ ) n⎞<br />
P⎜ ⎟ →φ( u) for n→<br />
∞<br />
⎝ σ ⎠<br />
20<br />
18<br />
16<br />
14<br />
12<br />
10<br />
8<br />
6<br />
4<br />
2<br />
0<br />
Hyppighed<br />
6,94 7,02 7,1 7,18 7,26 7,34 7,42 7,5 7,58 7,66 Mere<br />
At f (x ) virkelig er en tæthedsfunktion med de angivne egenskaber vises i “Supplement til<br />
statistiske <strong>grundbegreber</strong> afsnit 2.A”<br />
29<br />
Hyppighed
4.Normalfordelingen.<br />
For at få et overblik over betydningen af µ og σ er der nedenfor afbildet tæthedsfunktionen for<br />
normalfordelingerne n(0 , 1), n(4.8 , 2.2), n(4.8 , 0.7) og n(10 , 1).<br />
0,6<br />
0,5<br />
0,4<br />
0,3<br />
0,2<br />
0,1<br />
0<br />
-7 -3 1 5 9 13 17<br />
Fig 4.1 Forskellige normalfordelinger<br />
30<br />
0,1<br />
4,8,2,2<br />
4,8,0,7<br />
10,1<br />
Det ses, at tæthedsfunktionerne er klokkeformede, og at et interval på [ µ −3⋅ σ ; µ + 3⋅σ]<br />
indeholder stort set hele sandsynlighedsmassen.<br />
Vi nævner uden bevis følgende sætning:<br />
SÆTNING 4.1 (Additionssætning for linearkombination af normalfordelte variable).<br />
Er Y en linearkombination af n stokastisk uafhængige , normalfordelte variable, vil Y også<br />
være normalfordelt.<br />
Kendes middelværdi og spredning for de n normalfordelte variable , kan man ved anvendelse af<br />
linearitetsregel og kvadratregel finde Y’s middelværdi og spredning.<br />
Endvidere følger det af additionssætningen, og sætning 3.1, at gennemsnittet x er normalfordelt<br />
σ<br />
med en spredning på .<br />
n
3<br />
Normeret normalfordeling<br />
Af særlig interesse er den såkaldte normerede normalfordeling.<br />
Den er bestemt ved at have middelværdien 0 og spredningen 1.<br />
Grafen for den er tegnet i figur 4.1<br />
1<br />
ϕ(<br />
u) = e<br />
2⋅<br />
π<br />
2<br />
u<br />
−<br />
2<br />
for ethvert u<br />
4 1 u −<br />
Φ ( u) = ⋅ e 2 dt<br />
2 ⋅ π ∫∞<br />
t<br />
2<br />
4.2 Definition og sætning om normalfordeling<br />
Den kaldes sædvanligvis U eller Z og dens fordeling U- eller Z-fordelingen . Dens tæthedsfunktion<br />
3 benævnes og dens fordelingsfunktion 4 .<br />
ϕ Φ<br />
Specielt vil dens p - fraktil u p indgå i adskillige formler i de næste afsnit.<br />
Den kan naturligvis beregnes ved anvendelse af eksempelvis TI89 eller Excel, (se afsnit 4.3) men<br />
da de så ofte indgår i beregningerne er der i tabel 1 angivet værdier af den for specielt ofte<br />
forekommende p -værdier.<br />
En vigtig sammenhæng mellem fraktiler for X og fraktiler for U er følgende<br />
xp = up<br />
⋅ σ + µ<br />
31<br />
(4.1)<br />
Beviset for denne relation indgår i beviset for den følgende sætning, som også viser, at man kan<br />
overføre en vilkårlig normalfordeling til den normerede normalfordeling.<br />
Det er derfor nok at lave en tabel over den normerede normalfordeling.<br />
Dette er det man udnytter, hvis man ikke har rådighed over et program, der som beskrevet i afsnit<br />
4.3 direkte kan beregne værdierne.<br />
Der gælder følgende
4.Normalfordelingen.<br />
SÆTNING 4.2. (normering af normalfordeling). Når X er normalfordelt<br />
er den variable U normalfordelt , og der gælder<br />
X − µ<br />
=<br />
n( 01 ,)<br />
σ<br />
⎛ b − µ ⎞<br />
P( X ≤ b)<br />
= Φ⎜<br />
⎟<br />
⎝ σ ⎠<br />
og<br />
⎛ b−µ ⎞ ⎛ a−µ<br />
⎞<br />
Pa ( < X≤ b)<br />
= Φ⎜⎟−Φ⎜⎟. ⎝ σ ⎠ ⎝ σ ⎠<br />
Endvidere gælder xp = up<br />
⋅ σ + µ<br />
Bemærk, at det for de to formler er ligegyldigt, om ulighederne er med eller uden lighedstegn.<br />
Bevis:<br />
At U også er normalfordelt vises ikke her.<br />
∞<br />
∞<br />
∞<br />
⎛ X − µ ⎞ x − µ 1 µ<br />
1 µ<br />
EU ( ) = E⎜ ⎟ = f( xdx ) = x⋅ f( xdx ) − f( xdx ) = E( X)<br />
− = 0<br />
⎝ σ ⎠ ∫−∞<br />
σ σ∫−∞<br />
σ∫−∞ σ σ<br />
∞ 2<br />
∞<br />
⎛ X − µ ⎞ ⎛ x − µ ⎞<br />
1<br />
2 V( X)<br />
VU ( ) = V⎜ ⎟ = ⎜ ⎟ f ( x) dx = ( x − µ ) ⋅ f ( x) dx = = 1<br />
⎝ σ ⎠ ∫−∞⎝<br />
σ ⎠<br />
2<br />
σ ∫<br />
2<br />
−∞<br />
σ<br />
U har derfor middelværdi 0 og spredning 1.<br />
X − b<br />
b b<br />
Endvidere fås P( X ≤ b) = P ≤ PU og<br />
−<br />
⎛<br />
⎞<br />
⎜<br />
⎟ = ≤<br />
⎝<br />
⎠<br />
− ⎛<br />
µ µ<br />
µ ⎞ ⎛ − µ ⎞<br />
⎜ ⎟ = Φ⎜<br />
⎟<br />
σ σ ⎝ σ ⎠ ⎝ σ ⎠<br />
Pa X b P a ⎛ − µ b−µ ⎞ ⎛ b−µ ⎞ ⎛ a−µ<br />
⎞<br />
( < ≤ ) = ⎜ < U≤ ⎟ = Φ⎜⎟−Φ⎜⎟ ⎝ σ σ ⎠ ⎝ σ ⎠ ⎝ σ ⎠<br />
⎛ x p − ⎞ x p<br />
Bevis for formel 2.1: P( X ≤ xp) = p⇔<br />
⎜ ⎟ = p ⇔ up xp up<br />
⎝ ⎠<br />
−<br />
µ<br />
µ<br />
Φ<br />
= ⇔ = ⋅ σ + µ<br />
σ<br />
σ<br />
4.3. BEREGNING AF SANDSYNLIGHEDER<br />
Stikprøves gennemsnit og spredning.<br />
Ofte er middelværdien µ og spredningen σ ukendt i en foreliggende normalfordeling. I så fald<br />
erstattes fordelingen n( µ , σ ) i praksis med en approksimerende fordeling nxs ( , ) , såfremt der<br />
foreligger et rimelig stort antal observationer fra den givne fordeling.<br />
På basis af den i eksempel 1.5 angivne stikprøve på 75 patienter beregnes et gennemsnit af pH<br />
værdierne på 546. 52<br />
SAK<br />
x = = 7. 2868 og en s værdi på s =<br />
.<br />
75<br />
n − = 0134355 .<br />
1<br />
Vi vil altså antage, at pH værdierne er approksimativt normalfordelt n (7.29, 0.134).<br />
32<br />
n( µ , σ )
Ønsker vi at benytte ovenstående normal<br />
fordeling n (7.29, 0.134) til at finde sandsynligheden<br />
for, at pH er mindre end 7.2, er<br />
denne sandsynlighed lig med arealet af det<br />
skraverede areal under tæthedsfunktionen.<br />
Ønsker vi tilsvarende at beregne sandsynligheden<br />
for, at pH ligger mellem 7.2 og 7.5 er sandsynligheden<br />
lig med det skraverede areal<br />
under kurven på omstående figur.<br />
Eksempel 4.1. Beregning med TI89 og Excel<br />
Lad X være normalfordelt n( µ , σ ) , hvor µ = 7.29 og σ = 0.134.<br />
1) Find P( X ≤ 72 . )<br />
2) Find P(. 72≤ X ≤75<br />
.)<br />
3) Find P( X ≥ 76 . )<br />
4) Find 90% fraktilen<br />
Løsning:<br />
x09 .<br />
33<br />
4.3. Beregn af sandsynligheder<br />
TI89: Man finder de benyttede sandsynlighedsfordelinger ved at trykke på CATALOG F3<br />
1) normCdf( , 7.2, 7.29, 0.134) = 0.2509<br />
P( X ≤ 72 . ) = −∞<br />
2) P(. 72≤ X ≤75<br />
.) = normCdf( 7.2,7,5, 7.29, 0.134) = 0.691<br />
3) P( X ≤ 76 . ) = normCdf( 7.6, ∞ 7.29, 0.134) = 0.2509<br />
4) Har man omvendt givet en sandsynlighed p = 0.9 og ønsker at finde den tilsvarende<br />
værdi x p for hvilken P( X ≤ xp) = 09 . betyder det, at man kender arealet 0.9 og skal<br />
finde x-værdien.<br />
Det svarer jo til at finde den inverse (omvendte) funktion af normalfordelingen.<br />
x09 . = invnorm(0.6, 7.29, 0.134) = 7.462<br />
Excel: Man finder de benyttede sandsynlighedsfordelinger ved på værktøjslinien foroven:<br />
Tryk f x Vælg kategorien “Statistisk”<br />
1) P( X ≤ 72 . ) = NORMFORDELING(7,2;7,29;0,134,1)=0.2509.<br />
2) Beregningen sker i Excel ved (se det skraverede areal på figuren ) at beregne arealet fra −∞til<br />
7.5 og<br />
derfra trække arealet fra til 7.2, dvs.<br />
−∞<br />
P( 72 . ≤ X ≤ 75 .) = P( X ≤72 .) − P( X ≤ 75 .) =<br />
NORMFORDELING(7,5;7,29;0,134;1)-NORMFORDELING(7,2;7,29;0,134;1)=0,691
4.Normalfordelingen.<br />
3) Da arealet under kurven er 1, fås<br />
P( X ≥ 76 . ) = 1− P( X < 76 . )<br />
4) x09 . = NORMINV(0.9, 7.29, 0.134) = 7.462 .<br />
=1-NORMFORDELING(7,6;7,29;0,134;1)= 0,01035<br />
Eksempel 4.2. Kvalitetskontrol.<br />
En fabrik støber plastikkasser. Fabrikken får en ordre på kasser, som blandt andet har den<br />
specifikation, at kasserne skal have en længde på 90 cm. Kasser, hvis længder ikke ligger mellem<br />
tolerancegrænserne 89.2 og 90.8 cm bliver kasseret.<br />
Det vides, at fabrikken producerer kasserne med en længde X, som er normalfordelt med en<br />
spredning på 0.5 cm.<br />
a) Hvis X har en middelværdi på 89.6, hvad er så sandsynligheden for, at en kasse har en længde,<br />
der ligger indenfor tolerancegrænserne.<br />
b) Hvor stor er sandsynligheden for at en kasse bliver kasseret, hvis man justerer støbningen, så<br />
middelværdien bliver den der giver den mindste procentdel kasserede (spredningen kan man<br />
ikke ændre).<br />
Fabrikanten finder, at selv efter den i spørgsmål 2 foretagne justering kasseres for stor en<br />
procentdel af kasserne. Der ønskes højst 5% af kasserne kasseret.<br />
c) Hvad skal spredningen σ formindskes til, for at dette er opfyldt?<br />
Hvis det er umuligt at ændre σ , kan man prøve at få ændret tolerancegrænserne.<br />
d) Find de nye tolerancegrænser (placeret symmetrisk omkring middelværdien 90,0) idet spredningen<br />
stadig er 0.5, og højst 5% må kasseres.<br />
En ny maskine indkøbes, og som et led i en undersøgelse af, om der dermed er sket ændringer<br />
i middelværdi og spredning produceres 12 kasser ved anvendelse af denne maskine.<br />
Man fandt følgende længder: 89.2 90.2 89.4 90.0 90.3 89.7 89.6 89.9 90.5 90.3 89.9 90.6.<br />
e) Angiv på dette grundlag et estimat for middelværdi og spredning.<br />
LØSNING:<br />
TI89: Man finder de benyttede sandsynlighedsfordelinger ved at trykke på CATALOG F3<br />
a) P( 89. 2 ≤ X ≤ 908 . ) = normCdf(89.2, 90.8, 89.6, 0.5)= 0.7799 = 77.99%<br />
b) Middelværdien justeres til midtpunktet 90.0<br />
P( X > 908 . ) + P( X < 89. 2) = normCdf(90.8 , ∞ , 90, 0.5)+normCdf(- ∞ ,89.2, 90, 0.5)= 10.96%<br />
c) Da der ligger 5% udenfor intervallet, så må af symmetrigrunde 2,5% ligge på hver sin side<br />
af intervallet. Vi har følgelig, at vi skal finde spredningenσ så P( X ≤ 89. 2) = 0. 025<br />
08 .<br />
Metode 1:Af relationen (4.1) fås 89. 2 = 0025 . ⋅ + 90 ⇔ = .<br />
−<br />
u σ σ<br />
u<br />
34<br />
0025 .<br />
Da =−196 . ( findes af tabel 2 eller ved invNorm(0.025,0,1)) fås σ = 0. 408<br />
u0. 025<br />
Metode 2: solve( normCdf( −∞ ,89.2, 90,x)=0.025,x) x > 0<br />
eller solve(invNorm(0.025,90,x)=89.2,x) x > 0 Resultat x = σ = 0. 408<br />
d) Kaldes den nedre tolerancegrænse for a fås med samme begrundelse som i punkt c :<br />
P( X ≤ a)<br />
= 0. 025.<br />
Vi kan her benytte den “inverse” normalfordeling
Nedre grænse a = invNorm(0.025, 90,0.05) = 89.02<br />
Øvre grænse b = 90 +(90 - 89.02) = 90.98<br />
e) APPS Stat/List indtastning af de 12 tal i list1 F4 :Calc Udfylde menu<br />
Man finder x = 89. 97 og s = 0435 .<br />
Excel: Man finder de benyttede sandsynlighedsfordelinger ved<br />
På værktøjslinien foroven: Tryk f x Vælg kategorien “Statistisk”<br />
a) P( 89. 2 ≤ X ≤ 908 . ) = P( X ≤908 . ) − P( X ≤ 89. 2)<br />
=<br />
NORMFORDELING(90,8;89,6;0,5;1) - NORMFORDELING(89,2;89,6;0,5;1)=0,7799<br />
b) Middelværdien justeres til midtpunktet 90.0<br />
P( X > 908 . ) + P( X < 89. 2) = 1−P( X ≤ 908 . ) + P( X < 892 . ) =<br />
1 -NORMFORDELING(90,8;90;0,5;1) - NORMFORDELING(89,2;90;0,5;1) = 0.1096<br />
35<br />
4.3. Beregn af sandsynligheder<br />
89. 2 − 90<br />
c) Metode 1:Ved indsættelse i ligningen xp = up<br />
⋅ σ + µ fås 89. 2 = u0025<br />
. ⋅ σ + 90 ⇔ σ =<br />
u0025<br />
.<br />
σ =(89,2-90)/NORMINV(0,025;0;1)=0,408171 ≈ 0.408<br />
Metode 2: I celle A1 skrives en startværdi for σ eksempelvis 0,5.<br />
I celle B1 skrives =NORMFORDELING(89,2;90;A1;1)<br />
2003: Funktioner “Målsøgning”<br />
2007: Data Hvad-hvis analyse ”Målsøgning<br />
I “Angiv celle” skrives B1. I “Til Værdi” skrives 0,025. I “Ved ændring af celle” skrives A1.<br />
Facit :0,408444<br />
d) Med samme begrundelse som under punkt c fås:<br />
P( 90. 0 − d < X < 90. 0 + d) = 0. 95 ⇔ P( X ≤ 90. 0 − d) = 0. 025 og P( X ≤ 90. 0 + d)<br />
= 0. 975 .<br />
Vi får nedre grænse =NORMINV(0,025;90;0,5) = 89,02002 = 89.0<br />
Øvre grænse =NORMINV(0,975;90;0,5) = 90,97998 = 91.0<br />
5) Ved indtastning af de 12 tal i Excel i cellerne A1 til A12 findes<br />
x = Middel( A1: A12)<br />
= 8997 . og s = STDAFV(A1:A2) = 0.435<br />
Eksempel 4.3. Additionssætning.<br />
En boreproces fremstiller huller med en diameter X 1 , der er normalfordelt med en middelværdi µ 1<br />
og en spredning på 0.04. En anden proces fremstiller aksler med en diameter X 2 , der er<br />
normalfordelt med en middelværdi µ 2 og en spredning på 0.03.<br />
Antag, at µ 1 = 10. 00 , og at µ 2 = 994 . .<br />
Find sandsynligheden for, at en tilfældig valgt aksel har en mindre diameter end en tilfældig valgt<br />
borehul.<br />
LØSNING:<br />
P( X2 < X1) = P( X2 − X1<br />
< 0).<br />
Sættes Y = X − X er Y normalfordelt.<br />
2 1<br />
EY ( ) = E( X2) − E( X1)<br />
= 994 . − 1000 . = −006<br />
.<br />
2<br />
2<br />
2 2<br />
V( Y) = 1 V( X ) + ( − 1) V( X ) = 0. 04 + 0. 03 = 0. 025<br />
.<br />
σ ( Y ) = 0. 0025 = 0. 05<br />
2<br />
1<br />
TI89: PX ( 2 < X1) = PY ( < 0)<br />
= normCdf( − ∞ , 0, -0.06, 0.05) = 0.8849 = 88.49%<br />
Excel: P( X2 < X1) = P( Y < 0)<br />
=<br />
NORMFORDELING(0;-0,06;0,05;1) = 0.8849
4.Normalfordelingen.<br />
OPGAVER<br />
Opgave 4.1<br />
1) En stokastisk variabel X er normalfordelt med µ = 0 og σ = 1.<br />
Find P( X ≤ 075 . ), P( X > 16 . ) og P(. 075< X < 16 .).<br />
2) En stokastisk variabel X er normalfordelt med µ = 25.1 og σ = 2.4.<br />
Find P( 22. 3 < X ≤ 27. 8)<br />
.<br />
Opgave 4.2<br />
Maksimumstemperaturen, der opnås ved en bestemt opvarmningsproces, har en variation der er<br />
tilfældig og kan beskrives ved en normalfordeling med en middelværdi på 113.3 o og en spredning<br />
på 5.6 o C.<br />
1) Find procenten af maksimumstemperaturer, der er mindre end 116.1 o C.<br />
2) Find procenten af maksimumstemperaturer, der ligger mellem 115 o C og 116.7 o C.<br />
3) Find den værdi, som overskrides af 57.8% af maksimumstemperaturerne.<br />
Man overvejer at gå over til en anden opvarmningsproces. Man udfører derfor 16 gange i løbet<br />
af en periode forsøg, hvor man måler maksimumstemperaturen, der opnås ved denne nye proces.<br />
Resultaterne var<br />
116.6 , 116,6 , 117,0 , 124,5 , 122,2 , 128,6 , 109,9 , 114,8 , 106,4 , 110,7, 110,7 , 113,7 , 128,1,<br />
118,8 , 115,4 , 123,1<br />
4) Giv et estimat for middelværdien og spredningen.<br />
Opgave 4.3<br />
En fabrik planlægger at starte en produktion af rør, hvis diametre skal opfylde specifikationerne<br />
2,500 cm ± 0,015 cm.<br />
Ud fra erfaringer med tilsvarende produktioner vides, at de producerede rør vil have diametre,<br />
der er normalfordelte med en middelværdi på 2,500 cm og en spredning på 0,010 cm. Man ønsker<br />
i forbindelse med planlægningen svar på følgende spørgsmål:<br />
1) Hvor stor en del af produktionen holder sig indenfor specifikationsgrænserne.<br />
2) Hvor meget skal spredningen σ ned på, for, at 95% af produktionen holder sig indenfor<br />
specifikationsgrænserne (middelværdien er uændret på 2,500 cm).<br />
3) Fabrikken overvejer, om det er muligt at få indført nogle specifikationsgrænser (symmetrisk<br />
omkring 2,500), som bevirker, at 95% af dets produktion falder indenfor grænserne. Find disse<br />
grænser, idet det stadig antages at middelværdien er 2.500 og spredningen 0.010 cm.<br />
Opgave 4.4<br />
En automatisk dåsepåfyldningsmaskine fylder hønskødssuppe i dåser. Rumfanget er normalfordelt<br />
med en middelværdi på 800 ml og en spredning på 6,4 ml.<br />
1) Hvad er sandsynligheden for, at en dåse indeholder mindre end 790 ml?.<br />
2) Hvis alle dåser, som indeholder mindre end 790 ml og mere end 805 ml bliver kasseret, hvor<br />
stor en procentdel af dåserne bliver så kasseret?<br />
3) Bestem de specifikationsgrænser der ligger symmetrisk omkring middelværdien på 800 ml,<br />
og som indeholde 99% af alle dåser.<br />
36
37<br />
Opgaver til kapitel 4<br />
Opgave 4.5<br />
I et laboratorium lægges et nyt gulv.<br />
Det forudsættes, at vægten Y der hviler på gulvet, er summen af vægten X1 af maskiner og<br />
apparater og vægten X2 af varer og personale, dvs. Y = X1 + X2 Da både X1 og X2 er sum af mange relativt små vægte, antages det, at de er normalfordelte.<br />
Det antages endvidere at X1 og X2 er statistisk uafhængige.<br />
Erfaringer fra tidligere gør det rimeligt at antage, at der gælder følgende middelværdier og<br />
spredninger (målt i tons):<br />
E(X1) = 6.0, σ ( X 1) = 1.2, E(X2) = 3.5, σ ( ) = 0.4.<br />
1) Beregn E(Y) og σ ( Y)<br />
.<br />
X 2<br />
2) Beregn det tal y 0 , som vægten Y med de ovennævnte forudsætninger kun har en sandsynlighed<br />
på 1% for at overskride.<br />
3) Beregn sandsynligheden for, at vægten af varer og personale en tilfældig dag, efter at det nye<br />
gulv er lagt, er større end vægten af maskiner og apparater. (Vink: se på differensen X 2 - X 1)<br />
Opgave 4.6<br />
Ved fabrikation af et bestemt mærke opvaskemiddel fyldes vaskepulver i papkartoner.<br />
I middel fyldes 4020 g pulver i hver karton, idet der herved er en spredning på 12 g.<br />
Pulverfyldningen kan forudsættes ikke at afhænge af kartonernes vægt, der i middel er 250 g med<br />
en spredning på 5g.<br />
Beregn sandsynligheden p for, at en tilfældig pakke opvaskemiddel har en bruttovægt mellem<br />
4250 g og 4300 g.<br />
Opgave 4.7<br />
Et system er af sikkerhedsmæssige grunde opbygget af to apparater A, der er parallelforbundne<br />
(se figur) således, at systemet virker, så længe blot et af apparaterne<br />
virker.<br />
Svigter et af apparaterne, startes reparation. Det antages, at<br />
reparationstiden er normalfordelt med middelværdien<br />
µ rep = 10 timer og spredning σ rep = 3 timer.<br />
I reparationstiden overbelastes den anden komponent, og det<br />
antages, at dens levetid fra reparationens start (approksimativt) er normalfordelt med middelværdi<br />
µ og spredning σ = 4 timer.<br />
1) Find sandsynligheden for, at reparationen er afsluttet, inden den anden komponent fejler, hvis<br />
µ = 20 timer.<br />
2) Hvor stor skal µ være, for at sandsynligheden for, at reparationen kan afsluttes før den anden<br />
komponent fejler, er mere end 99.9%?<br />
Opgave 4.8<br />
Vægten af en (tilfældig udvalgt) tablet af en vis type mod hovedpine har middelværdien 0.65 g<br />
og spredningen 0.04 g.<br />
1) Beregn middelværdi og spredning af den sammenlagte vægt af 100 (tilfældigt udvalgte )<br />
tabletter.<br />
2) Antag, at man benytter følgende metode til at fylde tabletter i et glas. Man placerer glasset på<br />
en vægt og fylder tabletter på, indtil vægten af tabletterne i glasset overstiger 65,3 g. Beregn<br />
sandsynligheden for, at glasset kommer til at indeholde mere end 100 tabletter (se bort fra<br />
vægtens fejlvisning).
5 Stikprøver<br />
5. STIKPRØVER<br />
5.1 UDTAGNING AF STIKPRØVER<br />
I langt de fleste i praksis forekomne tilfælde vil det bl.a. af tidsmæssige og omkostningsmæssige<br />
grunde være umuligt at foretage en totaltælling af hele populationen. Helt klart er dette ved<br />
afprøvningen ødelægger emnet (åbning af konservesdåser) eller populationen i princippet er<br />
uendelig ( for at undersøge om en metode giver et større udbytte end et andet, udføres en række<br />
kemiske forsøg og her er der teoretisk ingen øvre grænse for antal delforsøg)<br />
Som det senere vil fremgå kan selv en forholdsvis lille repræsentativ stikprøve give svar på<br />
væsentlige forhold omkring hele populationen.<br />
Det er imidlertid klart, at en betingelse herfor er, at stikprøven er repræsentativ, dvs. at<br />
stikprøven med hensyn til den egenskab der ønskes er et “mini-billede” af populationen.<br />
For at opnå det, foretager man en eller anden form for lodtrækning (kaldes randomisering).<br />
Afhængig af problemet kan dette gøres på forskellig måde.<br />
Simpel udvælgelse: Den enkleste form for stikprøveudtagning er, at man nummererer<br />
populationens elementer, og så randomiserer (ved lodtrækning, evt. ved at benyttet et program<br />
der generer tilfældige tal) udtager de N elementer der skal indgå i stikprøven.<br />
Eksempel: For at undersøge om en ændring af vitaminindholdet i foderet for svin ændrede deres<br />
vægt, udvalgte man ved randomisering de svin, som fik det nye foder.<br />
Stratificeret udvælgelse.<br />
Under visse omstændigheder er det fordelagtigt (mindre stikprøvestørrelse for at opnå samme<br />
sikkerhed) at opdele populationen i mindre grupper (kaldet strada), og så foretage en simpel<br />
udvælgelse indenfor hver gruppe. Dette er dog kun en fordel, hvis elementerne indenfor hver<br />
gruppe er mere ensartet end mellem grupperne.<br />
Eksempel: Ønsker man at spørge vælgerne om deres holdning til et politisk spørgsmål (f.eks. om<br />
deres holdning til et skattestop) kunne det måske være en fordel at dele dem op i indkomstgrupper<br />
(høj, mellem og lav) .<br />
Systematisk udvælgelse:<br />
Ved en såkaldt systematisk udvælgelse, vælger man at udtage hver k’te element fra populationen.<br />
Eksempel: En detailhandler ønsker at måle tilfredsheden hos sine kunder. Der ønskes udtaget 40<br />
kunder i løbet af en speciel dag.<br />
Da man naturligvis ikke på forhånd kender de kunder der kommer i butikken, vælges en<br />
systematisk udvælgelse, ved at vælge hver 7'ende kunde der forlader butikken. Man starter dagen<br />
med ved lodtrækning at vælge et af tallene fra 1 til 7. Lad det være tallet 5. Man udtager nu kunde<br />
nr. 5, 5+ 1⋅ 7 = 12, 5+ 2⋅ 7 = 19,..., 5+ 39⋅ 7 = 278 . Derved har man fået valgt i alt 40 kunder.<br />
Problemet er naturligvis, om tallet 7 er det rigtige tal. Hvis man får valgt tallet for stort,<br />
eksempelvis sætter det til 30, så vil en stikprøve på 40 kræve, at der er 1175 kunder den dag, og<br />
det behøver jo ikke at være tilfældet. Omvendt hvis tallet er for lille, så får man måske udtaget<br />
de 40 kunder i løbet af formiddagen, og så er stikprøven nok ikke repræsentativ, da man ikke får<br />
eftermiddagskunderne med.<br />
38
5.2 Fordeling og spredning af gennemsnit<br />
Klyngeudvælgelse (Cluster sampling)<br />
Denne metode kan med fordel benyttes, hvis populationen består af eller kan inddeles i<br />
delmængder (klynger) . Metoden består i, at man ved randomisering vælger et mindre antal<br />
klynger, som så totaltælles.<br />
Eksempel: I et vareparti på 2000 emner fordelt på 200 kasser hver med 10 emner ønsker man en<br />
vurdering af fejlprocenten.<br />
Man udtager randomiseret 5 kasser, og undersøger alle emnerne i kasserne.<br />
5.2. FORDELING OG SPREDNING AF GENNEMSNIT<br />
Udtages en stikprøve fra en population er det jo for, at man ud fra stikprøven kan fortælle noget<br />
centralt om hele populationen.<br />
I eksempel 1.5 var vi således interesseret i koncentrationen af brintioner (pH) i ledvæsken i knæet<br />
hos patienter, der led af denne sygdom.<br />
Som led i en nordisk medicinsk undersøgelse udtog man blandt patienter der led af denne sygdom<br />
tilfældigt en stikprøve på 75.<br />
På basis heraf beregnede man gennemsnittet af pH værdierne til x = 7.2868 og spredningen<br />
s = 0.134355 .<br />
Man vil nu sige, at et estimat (skøn) for den “sande” middelværdi µ for hele populationen er 7.29<br />
og den “sande” spredning” σ er 0.134.<br />
Det er imidlertid klart, at disse tal er behæftet med en vis usikkerhed.<br />
Havde vi valgt 75 andre patienter havde vi uden tvivl fået lidt andre tal.<br />
Det er derfor ikke nok, at angive at den “sande” middelværdi er x , vi må også angive et<br />
“usikkerhedsinterval”.<br />
For at kunne beregne et sådant interval er det nødvendigt at kende fordelingen.<br />
Her spiller den tidligere nævnte centrale grænseværdisætning en vigtig rolle, idet den jo (løst<br />
sagt) siger, at selv om man ikke kender fordelingen af den kontinuerte stokastiske variabel, så vil<br />
gennemsnittet af værdierne i en stikprøve på n tal vil være tilnærmelsesvis normalfordelt, hvis<br />
blot n er tilstrækkelig stor ( i praksis over 30).<br />
Dette er af stor praktisk betydning, idet det så ikke er så vigtigt, om selve populationen er<br />
normalfordelt. Ofte er det jo kun af interesseret at kunne forudsige noget om hvor middelværdien<br />
af fordelingen er placeret.<br />
σ<br />
Endvidere fremgik det af sætning 3.1 , at spredningen på x er σ(<br />
x)<br />
= , hvor σ er<br />
n<br />
spredningen på den enkelte værdi i stikprøven.<br />
Heraf fremgår, at gennemsnittet kan man “stole” mere på end den enkelte måling, da den har en<br />
mindre spredning.<br />
39
5 Stikprøver<br />
Eksempel 5.1. Fordeling af gennemsnit<br />
Den tid, et kunde må venter i en lufthavn ved en check-in disk, er givet at være en stokastisk<br />
variabel med en ukendt fordeling. Man har dog erfaring for, at ventetiden i middel er på 8.2<br />
minutter med en spredning på 3 minutter.<br />
Udtages en stikprøve på 50 kunder, ønskes fundet sandsynligheden for, at den gennemsnitlige<br />
ventetid for disse kunder er mellem 7 og 9 minutter<br />
Løsning:<br />
Da antallet n i stikprøven på 50 er større end 30, kan vi antage at gennemsnittet er approksimativt<br />
σ 3<br />
normalfordelt med en middelværdi på 8.2 og en spredning på σ = = = 0. 424<br />
x<br />
.<br />
n 50<br />
Vi har derfor<br />
P( 7< X < 9)<br />
=<br />
TI89: normCdf(7,9,8.2,0.424) = 0.9681 = 96.8%<br />
Excel: P( 7< X < 9) = P( X < 9) − P( X < 7)<br />
=<br />
NORMFORDELING(9;8,2;0,424;1)-NORMFORDELING(7;8,2;0,429;1) =0,9681 = 96.8%<br />
5.3. KONFIDENSINTERVAL FOR MIDDELVÆRDI<br />
5.3.1 Definition af konfidensinterval<br />
Udtages en stikprøve fra en population er det jo for, at man ud fra stikprøven kan fortælle noget<br />
centralt om hele populationen.<br />
Man vil eksempelvis beregne gennemsnittet x og angive det som et estimat (skøn) for den<br />
“sande” middelværdi µ for hele populationen<br />
Det er imidlertid klart, at selv om et gennemsnit har en mindre spredning end den enkelte måling,<br />
så er det stadig behæftet med et vis usikkerhed<br />
Det er derfor ikke nok, at angive at den “sande” middelværdi er x , vi må også angive et<br />
“usikkerhedsinterval”.<br />
Et interval indenfor hvilket den “sande værdi” µ med eksempelvis 95% “sikkerhed” vil ligge,<br />
kaldes et 95% konfidensinterval for middelværdien.<br />
Mere præcist gælder det, at hvis man for et stort antal stikprøver på den samme stokastiske<br />
variabel angav 95% konfidensintervaller, så ville den sande middelværdi tilhøre 95% af disse<br />
intervaller. 1<br />
1<br />
Præcis definition af konfidensinterval. Lad være givet en stikprøve for en stokastisk variabel X, lad være et tal<br />
mellem 0 og 1. Lad endvidere Θ være en punktestimator for parameteren θ og lad L og U være stokastiske variable,<br />
for hvilke det gælder, at PL ( ≤θ ≤ U)<br />
= β . På basis af den givne stikprøve findes tal l og u som bestemmer det ønskede<br />
interval l ≤θ≤u. Dette kaldes et 100 ⋅ β procent konfidensinterval for den ukendte parameter θ .<br />
40<br />
β
5.3.2. Populationens spredning kendt eksakt<br />
Et 95% konfidensinterval [ x − r; x + r]<br />
må ligge symmetrisk<br />
omkring gennemsnittet, og således, at<br />
Px ( −r≤ X≤ x+ r)<br />
= 095 . .<br />
Heraf følger, at hvis den sande middelværdi µ ligger i et af<br />
de farvede områder på figur 5.1, så er der mindre end 2.5%<br />
chance for, at vi ville have fået det fundne gennemsnit x .<br />
For at finde grænsen for intervallet, må vi finde en middelværdi<br />
µ så P( X ≤ x)<br />
= 0. 025 .<br />
Man kan vise, at der gælder følgende formel<br />
5.3 Konfidensinterval for middelværdi<br />
2<br />
I celle A1 skrives en startværdi for µ eksempelvis 90. I celle B1 skrives<br />
=NORMFORDELING(90;A1;0,5/0.1443;1) Funktioner “Målsøgning” I “Angiv celle” skrives B1. I “Til<br />
Værdi” skrives 0,025. I “Ved ændring af celle” skrives A1. Resultat 90,2841<br />
41<br />
x − r x x + r<br />
Fig 5.1. 95% konfidensinterval<br />
Er spredningen eksakt kendt er et 95% konfidensinterval bestemt ved formlen<br />
σ<br />
σ<br />
x −u0. 975 ⋅ ≤ µ ≤ x + u0.<br />
975 ⋅<br />
(1)<br />
n<br />
n<br />
Forklaring på formel for 95% konfidensinterval<br />
Lad gennemsnittet af 12 målinger være x = 90 , og lad os antage, at spredningen kendes eksakt<br />
til σ = 0.5.<br />
σ 05 .<br />
Vi ved, at spredningen på gennemsnittet er “standardfejlen” σ(<br />
X ) = = = 01443 . .<br />
n 12<br />
Hvis den sande middelværdi µ afviger stærkt fra 90 er det yderst usandsynligt, at vi ville have fået<br />
et gennemsnittet på 90.<br />
Eksempelvis, hvis µ = 92 er P( X ≤ 90)<br />
= 0.0000<br />
TI89: P( X ≤ 90) = normCdf( −∞ ,90, 92, 0.1443) = 0<br />
Excel: NORMFORDELING(90;92;0,5/KVROD(12);1) = 0<br />
P( X ≤ 90)<br />
=<br />
dvs. det er ganske usandsynligt at den sande middelværdi var 92.<br />
For at finde grænsen kunne man finde µ af ligningen PX ( ≤ 90) = 0. 025<br />
TI89: solve(normCdf ( −∞ ,90, x, 0.1443) =0.025,x) hvilket giver 90.283<br />
Excel 2<br />
Da der er symmetri omkring x<br />
fås konfidensintervallet [89.717 ; 90.283]
5 Stikprøver<br />
Lettere er det at benytte formlen xp = µ + up<br />
⋅σ<br />
som ved benyttelse af, at σ(<br />
X ) =<br />
σ<br />
giver<br />
n<br />
µ = x −u0. 025 ⋅<br />
σ<br />
. Indsættes fra tabel 1 u0. 025 =−196<br />
. (eller =NORMINV(0,025;0;1)) fås, at øvre<br />
12<br />
grænse for konfidensintervallet er µ = x + 196⋅<br />
σ<br />
= 90 + 196⋅ 12<br />
= .<br />
05<br />
. .<br />
.<br />
90. 283<br />
12<br />
Da der er symmetri omkring x fås konfidensintervallet [89.717 ; 90.283]<br />
Sædvanligvis udtrykkes de generelle formler ved signifikansniveauet α , som er sandsynligheden<br />
for at begå en fejl . α sættes sædvanligvis til 10%, 5%, 1 % eller 0.1% svarende til henholdsvis<br />
90%, 95%, 99% og 99.9% konfidensintervaller.<br />
σ<br />
σ<br />
x −u x u<br />
I så fald bliver formlen (udtrykt ved α ) α ⋅ ≤ µ ≤ + α ⋅<br />
− n<br />
− n<br />
(2)<br />
Eksempel 5.3. Konfidensinterval hvis spredningen er kendt eksakt<br />
Lad os antage, at vi spredningen for en population kendes eksakt til σ = 58 ,<br />
Bestem et 95% konfidensinterval for en stikprøve på 5 elementer, der har gennemsnittet x = 774 .<br />
Løsning:<br />
“Radius” r i et 95% konfidensinterval er r = u0975⋅<br />
= 196⋅ =5.08<br />
n n<br />
58<br />
σ .<br />
. .<br />
95% konfidensinterval: 774 . −508 . ≤ µ ≤ 774 . + 508 . ⇔266 . ≤ µ ≤1282<br />
.<br />
Lettere er det at finde konfidensintervallet ved at benytte<br />
TI89: APPS STAT/LIST F7, 2: Z-Interval Vælg Stats Udfyld menuen med 5.8 7.74 osv.<br />
Resultat [2.66 ; 12.82 ]<br />
Excel: På værktøjslinien foroven: Tryk på = eller f x Vælg kategorien “Statistisk” Vælg “konfidensinter-<br />
val” udfylde menuen : KONFIDENSINTERVAL(0,05;5,8;5)=5,08<br />
95% konfidensinterval: 774 . −508 . ≤ µ ≤ 774 . + 508 . ⇔266 . ≤ µ ≤1282<br />
.<br />
Vi ved derfor med 95% “sikkerhed”, at populationens sande middelværdi ligger indenfor disse<br />
intervaller 3 .<br />
3<br />
Mere præcist, at af de 100 stikprøver med tilhørende 95% konfidensintervaller, vil i middel kun 5 af disse<br />
intervaller ikke indeholde den sande værdi.<br />
42<br />
1 2<br />
1 2
43<br />
5.3 Konfidensinterval for middelværdi<br />
5.3.3. Populationens spredning ikke kendt eksakt<br />
Sædvanligvis er populationens spredning σ jo ikke eksakt kendt, men man regner et estimat s<br />
ud for den.<br />
Da s jo også varierer fra stikprøve til stikprøve, giver dette en ekstra usikkerhed, så konfidensintervallet<br />
for µ bliver bredere.<br />
Hvis stikprøvestørrelsen er over 30 er denne usikkerhed dog uden væsentlig betydning, så i<br />
sådanne tilfælde kan man i formel (1) (eller formel (2)) blot erstatte σ med s.<br />
Er stikprøvestørrelsen under 30 bliver denne usikkerhed på s så stor, at man i formel (1) må<br />
erstatte U- fraktilen med en såkaldt t - fraktil t0.975(f) (også benævnt ) hvor<br />
u0975 . t0975 . , f<br />
frihedsgradstallet f = n - 1, og n = antal målinger).<br />
(eller udtrykt ved i formel (2) erstatte U- fraktilen med t - fraktilen t .)<br />
α u<br />
1− 2<br />
α<br />
Er spredningen ukendt er et 95 % konfidensinterval bestemt ved formlen:<br />
x−t0, 975( n−1)<br />
⋅<br />
s<br />
≤ µ<br />
≤ x+ t0. 975(<br />
n−1)<br />
⋅<br />
n<br />
s<br />
n<br />
1− f<br />
2<br />
α ,<br />
(eller udtrykt ved α x − t ⋅ ≤ µ ≤ x + t ⋅<br />
(4)<br />
s<br />
n<br />
α α<br />
1− , n−1 1− , n−1<br />
2<br />
2<br />
t-fordelinger<br />
En t - fordeling har samme klokkeformede udseende som en U - fordeling (en normalfordeling<br />
med middelværdi 0 og spredning 1)<br />
I modsætning til U - fordelingen afhænger dens udseende imidlertid af antallet n af tal i<br />
stikprøven.<br />
Er frihedsgradstallet f = n -1 stort (over 30) er forskellen mellem en U- fordeling og en tfordeling<br />
uden praktisk betydning.<br />
Er f lille bliver t - fordelingen så meget bredere end U - fordelingen, at t-fordelingen må anvendes<br />
i stedet for U-fordelingen.<br />
Grafen viser tæthedsfunktionen for t-fordelingerne for f = 1, 5 og 30.<br />
s<br />
n<br />
(3)
5 Stikprøver<br />
Eksempel 5.4. Beregning af t-værdier.<br />
1) Find t0. 975( 12)<br />
og t0025 . ( 12)<br />
.<br />
2) Find P( X ≥ 1)<br />
, hvor X er t - fordelt med 12 frihedsgrader.<br />
Løsning:<br />
TI-89:<br />
1) t0. 975( 12)<br />
= inv_t(0.975,12) = 2.18<br />
t0025 . ( 12)<br />
= inv_t(0.025,12) = -2.18<br />
2) P( X ≥ 1) = tCdf(1, ∞ ,12) = 0.1685 = 16.85%<br />
Excel:<br />
f x<br />
Der fremkommer en tabel med anvisning på, hvordan den skal udfyldes.<br />
På værktøjslinien foroven: Tryk på = eller Vælg kategorien “Statistisk” Vælg “TINV”<br />
Bemærk: TINV( α ; f) udregner den fraktil, der svarer til 1 -<br />
Sætter vi således α = 5% fås t0975 . , dvs. der beregnes arealet af “øverste hale” hvilket jo også altid er det man<br />
har brug for.<br />
1) t0. 975( 12)<br />
= TINV(0.05;12) = 2,178813<br />
t 0. 025 ( 12)<br />
= - 2,178813<br />
2) =TFORDELING(1;12;1) = 0,168525<br />
P( X ≥ 1)<br />
Eksempel 5.5. Konfidensinterval, hvis spredningen ikke er kendt eksakt.<br />
Ved fremstilling af et bestemt levnedsmiddel er det vigtigt, at et tilsætningsstof findes i<br />
levnedsmidlet i en koncentration på 8.50 (g/l).<br />
For at kontrollere dette udtager levnedsmiddelkontrollen 6 prøver af levnedsmidlet. Resultaterne<br />
var:<br />
Måling nr 1 2 3 4 5 6<br />
koncentration x (g/l) 8.54 7.89 8.50 8.21 8.15 8.32<br />
Idet man antager, på baggrund af tidligere lignende målinger, at resultaterne er normalfordelte,<br />
skal man besvare følgende spørgsmål:.<br />
a) Angiv et estimat for koncentrationens middelværdi og spredning.<br />
b) Angiv et 95% konfidensinterval for koncentrationen, og vurder herudfra om kravet på 8.50<br />
er opfyldt.<br />
Løsning<br />
Såvel TI89 som Excel har indbygget programmer, så man ikke behøver at anvende formlerne<br />
direkte.<br />
a) TI-89:<br />
APPS Stat/List Indtast tal i en liste F7, 2: T-Interval Vælg Data Udfyld menuen<br />
Resultater: x = 8268 . og s = 0241 . .<br />
b) C Int :[ 802 . ; 852 . ]<br />
Da intervallet indeholder 8.50, er kravet opfyldt, men da intervallet kun lige netop indeholder<br />
tallet 8.50, så det vil nok være rimeligt, at foretage en ny vurdering på basis af nogle flere<br />
målinger.<br />
44<br />
α<br />
2
Excel: Data indtastes i cellerne A1 til A6<br />
45<br />
5.3 Konfidensinterval for middelværdi<br />
Excel: 2003: Funktioner 2007: Data<br />
derefter Dataanalyse Beskrivende statistik udfyld inputområde vælg Resumestatistik og konfidensniveau<br />
Middelværdi 8,268333333<br />
Standardfejl 0,098434976<br />
Median 8,265<br />
Tilstand #I/T<br />
Standardafvigelse 0,241115463<br />
Stikprøvevarians 0,058136667<br />
Kurtosis -0,2376446<br />
Skævhed -0,500530903<br />
Område 0,65<br />
Minimum 7,89<br />
Maksimum 8,54<br />
Sum 49,61<br />
Antal 6<br />
Konfidensniveau(95,0%) 0,25303516<br />
a) Resultater: x = 8268 . og s = 0241 . .<br />
b) 95% konfidensinterval: x ± r = 49. 086 ± r hvor r = 0.253<br />
[8.268 -0.253 ; 8.268 + 0.253] =[8.02 ; 8.52]<br />
Eksempel 5.6 Konfidensinterval, hvis originale data ikke kendt<br />
Find konfidensintervallet for middelværdien , idet stikprøven er på 20 tal, som har et<br />
µ<br />
gennemsnit på 50 og en spredning på 12.<br />
Løsning:<br />
TI89:APPS Stat/List F7, 2: T-Interval Vælg Stats Udfyld menuen<br />
C Int :[44.38 ; 55.62]<br />
Excel : Har intet færdigt program, så her må man anvende formlen for konfidensinterval<br />
I kolonne D er de formler angivet, som er brugt i kolonne E, men kolonne D er naturligvis<br />
strengt taget unødvendig.<br />
A B C D E<br />
1 Eksempel 4.6 Konfidensradius r = TINV(B6;B3-1)*B5/KVROD(B3) = 5,616173<br />
2 nedre grænse = B4-E1 44,38383<br />
3 n = 20 øvre grænse = B4+E1 55,61617<br />
4 gennemsnit = 50<br />
5 spredning s = 12<br />
6 Signifikansniveau " = 0,05<br />
95% konfidensinterval: [44.38 ; 55.62]
5 Stikprøver<br />
Prædistinationsinterval. Ved mange anvendelser ønsker man at forudsige, hvor værdien af<br />
en kommende observation af den variable med 95%”sikkerhed” vil falde, snarere end at give<br />
et 95% konfidensinterval for middelværdien af den variable. Man siger, at man ønsker at<br />
bestemme et 95% prædistinationsinterval (forudsigelsesinterval).<br />
SÆTNING 4.2 ( 100 ⋅ ( 1 − α ) % prædiktionsinterval for en enkelt observation ).<br />
Et 100 ⋅( 1 −α)<br />
% prædiktionsinterval for en enkelt fremtidig observation Xn+1 er bestemt ved<br />
X n+1<br />
Bevis: Lad være en enkelt fremtidig observation. Eftersom er uafhængig af de øvrige X’er, er<br />
X n+1 også uafhængig af X .<br />
2<br />
σ 2 2<br />
Variansen af differensen X − Xn+1er følgelig V( X − Xn ) = V( X) + V( Xn<br />
) = + =<br />
⎛ 1<br />
⎜ +<br />
⎞<br />
+ 1 + 1 σ σ 1 ⎟ .<br />
n ⎝ n⎠<br />
Da man sædvanligvis først regner konfidensintervallet ud, så er den nemmeste måde at<br />
beregne det tilsvarende prædistinationsinterval at benytte, at radius rp i prædistinationsinterval<br />
fås af radius rk i konfidensintervallet ved formlen r = r ⋅ 1+<br />
n<br />
46<br />
p k<br />
Bevis: r s s<br />
n<br />
n 1 + 1 1+<br />
n s<br />
p = ⋅ 1+ = = s = 1+ n = rk1+ n<br />
n n n<br />
Eksempel 5.7. Prædistinations-interval for middelværdi af normalfordeling.<br />
Samme problem som i eksempel 5.5, men nu ønskes bestemt et 95% prædistinationsinterval<br />
for en enkelt ny måling af koncentrationen.<br />
Løsning<br />
Da konfidensintervallet har længden 8.52 - 8.02 = 0.50 er radius rk = 0.25<br />
Vi har derfor rp= 025 . ⋅ 6+ 1= 066 . og dermed<br />
95% konfidensinterval = 827 . − 066 . ; 827 . + 066 . == 761 . ; 893 . .<br />
X n+1<br />
[ ] [ ]<br />
Bestemmelse af stikprøvens størrelse<br />
Før man starter sine målinger, kunne det være nyttigt på forhånd at vide nogenlunde hvor<br />
mange målinger man skal foretage, for at få resultat med en given nøjagtighed.<br />
Hvis spredningen antages kendt , ved vi, at radius i konfidensintevallet er<br />
σ<br />
r = u α ⋅<br />
− n<br />
1 2<br />
Løses denne ligning med hensyn til n fås<br />
⎛ u<br />
⎜<br />
n = ⎜<br />
⎜<br />
⎝<br />
2<br />
α ⋅σ<br />
1− 2<br />
r<br />
1<br />
1<br />
x −t α ( n−1) ⋅s⋅ 1+<br />
≤ µ ≤ x + t α ( n−1) ⋅s⋅ 1+<br />
.<br />
− n<br />
−<br />
n<br />
⎞<br />
⎟<br />
⎟<br />
⎟<br />
⎠<br />
1 2<br />
1 2
47<br />
5.3 Konfidensinterval for middelværdi<br />
Det grundlæggende problem er her, at man næppe kender spredningen eksakt.<br />
Man kender muligvis på basis af tidligere erfaringer størrelsesordenen af spredningen. Hvis<br />
ikke må man eventuelt lave nogle få målinger, og beregne et s på basis heraf.<br />
Som en første tilnærmelse antages, at antallet af gentagelser n er over 30, så man kan bruge Ufordelingen.<br />
Hvis det derved viser sig, at n er under 30 anvendes i stedet en t-fordeling, idet vi løser<br />
ligningen<br />
⎛ t α ( n−1)<br />
⋅σ⎞<br />
⎜ 1− 2 ⎟<br />
n = ⎜<br />
⎟<br />
⎜ r ⎟<br />
⎝<br />
⎠<br />
Det følgende eksempel illustrerer fremgangsmåden.<br />
Eksempel 5.8. Bestemmelse af stikprøvens størrelse.<br />
En forstmand er interesseret i at bestemme middelværdien af diameteren af voksne egetræer i<br />
en bestemt fredet skov.<br />
Der blev målt diameteren på 7 tilfældigt udvalgte egetræer (i 1 meters højde over jorden)<br />
På basis af målingerne på de 7 træer sættes s ≈ 14 .<br />
a) Find hvor mange træer der skal måles, hvis et 95% konfidensinterval højst skal have en<br />
radius på ca. 5 cm.<br />
b) Find hvor mange træer der skal måles, hvis et 95% konfidensinterval højst skal have en<br />
radius på ca. 6 cm.<br />
Løsning:<br />
a) Da = 196 . fås<br />
u0975 .<br />
2 2<br />
⎛ u0975 . ⋅ s⎞⎛196<br />
. ⋅14⎞<br />
n = ⎜ ⎟ = ⎜ ⎟ ≈ 31<br />
⎝ r ⎠ ⎝ 5 ⎠<br />
TI89: (invNorm(0.975)*14)/5)^2 = 30.1 = 31<br />
Excel: (NORMINV(0,975;0;1)*14/5)^2 = 30.1<br />
Da n > 30 er det rimeligt, at benytte en U- fordeling frem for en t-fordeling.<br />
Der skal altså tilfældigt udvælges ca. 32 egetræer.<br />
2 2<br />
⎛ u0975 . ⋅ s⎞<br />
b)<br />
⎛ 196 . ⋅14⎞<br />
n = ⎜ ⎟ = ⎜ ⎟ ≈ 21<br />
⎝ r ⎠ ⎝ 6 ⎠<br />
2<br />
⎛ t0975 . n− ⋅s<br />
Da n < 30 burde man have anvendt en t - fordeling. ,( 1)<br />
⎞<br />
n = ⎜<br />
⎟<br />
⎝ r ⎠<br />
TI 89: solve(x=(invt(0.975,x-1)*14/6)^2,x) x>21<br />
Efter nogen tid fås x = 23.37<br />
Excel: I celle A1 skrives en startværdi for n eksempelvis 21.<br />
I celle B1 skrives= (TINV(0,05;A1)*14/6)^2-A1<br />
2003: Funktioner “Målsøgning”<br />
2007: Data Hvad-hvis analyse ”Målsøgning<br />
I “Angiv celle” skrives B1. I “Til Værdi” skrives 0. I “Ved ændring af celle” skrives A1. Facit :23,29865<br />
Der skal altså tilfældigt udvælges ca. 24 egetræer.<br />
2
5 Stikprøver<br />
Da overslaget jo er afhængigt af om vurderingen af s er korrekt, bør man dels for en<br />
sikkerheds skyld vælge s lidt rigelig stor, dels efter at man har målt de 31/24 træer lige<br />
kontrollere beregningen af konfidensintervallet.<br />
5.4 KONFIDENSINTERVAL FOR SPREDNING<br />
I visse situationer ønsker man at finde et konfidensinterval for spredningen.<br />
Vi vil ikke gå nærmere ind på teorien herfor, men blot henvise til formlerne i appendix 5.1.<br />
2<br />
2<br />
( n−1) s 2 ( n−1) s<br />
Formel 4 i appendix 5.1 benyttes:<br />
≤σ≤ 2<br />
2<br />
χ ( n −1)<br />
χ ( n −1)<br />
χ 2<br />
1<br />
Definition af -fordelingen. Lad U1, U2,..., U f være uafhængige normerede normalfor-delte variable.<br />
Sandsynlighedsfordelingen for den stokastiske variabel χ kaldes -fordelingen med<br />
2 2 2 2<br />
= U1+ U2+ ,..., U f χ 2<br />
frihedsgradstallet f og betegnes χ 2 ( f )<br />
α α<br />
1− 2<br />
2<br />
I formlerne indgår den såkaldte χ - fordeling, (udtales ki i anden) .<br />
2<br />
χ 2<br />
-fordelinger<br />
χ -fordelingen benyttes ved beregninger omkring varianser, når disse er erstattet af et<br />
2<br />
estimat s 2 . 1<br />
På figuren er afbildet tæthedsfunktionen for χ - fordelingerne , og .<br />
2<br />
χ 2 () 5 χ 2 ( 10)<br />
χ 2 ( 20)<br />
Det ses, at χ kun er defineret for tal større end eller lig nul, og at -fordelinger ikke er<br />
2<br />
χ 2<br />
symmetriske om middelværdien. Jo større frihedsgradstallet bliver jo mere symmetriske bliver<br />
de dog, og for store f - værdier - i praksis f > 30 - kan en χ -fordeling approksimeres<br />
2<br />
χ 2 ( f )<br />
med normalfordelingen n( µ , σ ), hvor µ = f og σ = 2 ⋅ f .<br />
TI89 og Excel har en kumuleret - fordeling ligesom naturligvis alle statistikprogrammer<br />
χ 2<br />
har det.<br />
48
Eksempel 5.9. Beregning af χ - værdier.<br />
2<br />
2<br />
2<br />
1) Find χ0. 025()<br />
8 og χ 0. 975()<br />
8 .<br />
2) Find P( X ≤ 5)<br />
,<br />
hvor X er χ - fordelt med 8 frihedsgrader.<br />
2<br />
Løsning:<br />
2<br />
TI89: 1) χ0. 025()<br />
8 =invChi2(0.025, 8) = 2.18<br />
2<br />
χ 0. 975()<br />
8 =invChi2(0.975, 8) = 17.5<br />
(se det skraverede areal på figuren)<br />
2) P( X ≤ 5)<br />
= chi2Cdf(0, 5, 8) = 0.242<br />
2<br />
Excel:1) χ0. 025()<br />
8 =CHIINV(0,975;8)=2.18<br />
2<br />
χ 0. 975()<br />
8 =CHIINV(0,025;8)=17.5<br />
P( X ≤ 5)<br />
2) =1-CHIFORDELING(5;8) = 0.242<br />
Bemærk Excel beregner den “øvre hale”<br />
49<br />
5.4 konfidensinterval for spredningen<br />
Eksempel 5.10. Konfidensinterval for varians og spredning af normalfordeling.<br />
En virksomhed ønsker at kontrollere med hvilken spredning en bestemt målemetode angiver<br />
saltindholdet i en opløsning. Der foretages følgende 12 målinger af en opløsning af det<br />
pågældende salt. Resultaterne var:<br />
Måling nr 1 2 3 4 5 6 7 8 9 10 11 12<br />
% opløsning 6.8 6.0 6.4 6.6 6.8 6.1 6.4 6.3 6.0 6.2 5.8 6.2<br />
a) Angiv på basis af måleresultaterne et estimat for opløsningens spredning.<br />
b) Angiv et 95% konfidensinterval for variansen og for spredningen.<br />
Løsning:<br />
TI-89 og Excel har intet færdigt program.<br />
2<br />
2<br />
( n−1) s 2 ( n−1) s<br />
Begge må anvende formel 4 i appendix 5.1 :<br />
≤σ≤ 2<br />
2<br />
χ ( n −1)<br />
χ ( n −1)<br />
α α<br />
1− 2<br />
2<br />
TI89: a) Data indtastes i list 1 F4 1 var Stats menu udfyldes<br />
b)<br />
Vi finder s = 0.3162 .<br />
Nedre grænse: (11*0.3162^2/ invChi2(0.975,11) = 0.0502<br />
Øvre grænse : (11*0.3162^2/ invChi2(0.025,11) = 0.288<br />
2<br />
0. 0502 ≤σ≤0. 288 . 0. 0502 ≤σ ≤ 0. 2880 ⇔ 0. 2241≤σ ≤05366<br />
. .<br />
Excel: a) Data indtastes i cellerne A1 til A12<br />
På værktøjslinien foroven: Tryk på f x Vælg kategorien “Statistisk” Vælg “STDAFV”<br />
Tabel udfyldes: s =STDAFV(A1:A7)= 0,316228<br />
b) Lad s være gemt i A14<br />
Nedre grænse := (12-1)*A14^2/CHIINV(0,025;11) = 0,050182 gemt i A16<br />
Øvre grænse: =(12-1)*A14^2/CHIINV(0,975;11) = 0,288279 gemt i A 17<br />
95% konfidensinterval for variansen: [0.0502 ; 0.288]<br />
95% konfidensinterval for spredningen:<br />
KVROD(A16) = 0.2241 KVROD(A17) =0.5366<br />
95% konfidensinterval for spredningen:[0.2241 ; 0.5366]
5 Stikprøver<br />
5.5. OVERSIGT over centrale formler i kapitel 5<br />
n( µ , σ )<br />
x<br />
X antages normalfordelt .Givet stikprøve af størrelsen n med gennemsnit og spredning s<br />
Oversigt over konfidensintervaller<br />
nr Forudsætninger Estimat for parameter 100 (1 - α ) % konfidensinterval for parameter<br />
1<br />
2<br />
3<br />
4<br />
µ ukendt.<br />
σ kendt<br />
µ ukendt.<br />
σ ukendt<br />
µ kendt<br />
σ ukendt.<br />
µ ukendt<br />
σ ukendt.<br />
For µ : x<br />
For µ : x<br />
For σ :<br />
2<br />
n − 1 s + n x −<br />
n<br />
2 ( ) ( µ )<br />
s µ =<br />
For σ :<br />
2 s 2<br />
2 2<br />
Oversigt over prædistinationsintervaller<br />
σ<br />
σ<br />
x −u α ⋅ ≤ µ ≤ x + u α ⋅<br />
− n<br />
− n<br />
50<br />
1 2<br />
1 2<br />
TI89 :F7: Z-interval<br />
Excel: Konfidensinterval (= radius)<br />
s<br />
x −t α ( n−1)<br />
⋅ ≤ µ ≤ x + t α ( n−1)<br />
⋅<br />
− n<br />
−<br />
1 2<br />
1 2<br />
TI89 :F7: t-interval<br />
Excel: Konfidensniveau (= radius)<br />
2 2<br />
( n − 1) s + n( x − µ ) 2 ( n − 1)<br />
s + n( x − µ )<br />
2<br />
≤ σ ≤<br />
2<br />
χ ( n)<br />
χ ( n)<br />
α α<br />
1− 2<br />
2<br />
2<br />
2<br />
( n − 1)<br />
s 2 ( n − 1)<br />
s<br />
2 ≤ σ ≤ 2<br />
χ ( n − 1)<br />
χ ( n − 1)<br />
α α<br />
1− 2<br />
2<br />
2 2<br />
nr Forudsætninger Estimat for parameter 100 (1 - α ) % konfidensinterval for parameter<br />
1<br />
2<br />
µ ukendt.<br />
σ kendt<br />
µ ukendt.<br />
σ ukendt<br />
For µ : x<br />
For µ : x<br />
σ<br />
radius i konfidensinterval rk = u α ⋅<br />
− n<br />
1 2<br />
radius i prædistinationsinterval r = r 1+<br />
n<br />
p k<br />
radius i konfidensinterval rk = t α ( n−1)<br />
⋅<br />
1− 2<br />
s<br />
n<br />
radius i prædistinationsinterval r = r 1+<br />
n<br />
p k<br />
Bestemmelse af stikprøvens størrelse n.<br />
Ønsket værdi af radius r i 100 (1 - α ) % konfidensinterval konfideninterval<br />
1<br />
2<br />
σ kendt<br />
eller n > 30<br />
σ ukendt, men antag<br />
den højst er s n<br />
⎛ u<br />
⎜<br />
n = ⎜<br />
⎜<br />
⎝<br />
2<br />
α ⋅σ<br />
⎞<br />
TI89: (invNorm(1- α /2)* σ /r)^2<br />
⎟ Excel:(NORMINV(1- α /2);0;1)* σ /r)^2<br />
⎟<br />
r ⎟<br />
⎠<br />
1− 2<br />
2<br />
⎛ t α ( n−1) ⋅s⎞<br />
Løs ligning , se eksempel 5.8<br />
⎜ 1− 2 ⎟<br />
= ⎜<br />
⎟<br />
⎜ r ⎟<br />
⎝<br />
⎠<br />
s<br />
n
OPGAVER<br />
51<br />
Opgaver til kapitel 5<br />
Opgave 5.1<br />
Lad der være givet 10 uafhængige observationer af en syres koncentration (i %).<br />
12.4 10.8 12.1 12.0 13.2 12.6 11.5 11.9 12.8 12.0<br />
1) Find et estimat for koncentrationens middelværdi µ og spredning σ .<br />
2) Angiv et 95% konfidensinterval for µ .<br />
3) Angiv et 95% prædistinationsinterval for en enkelt ny måling af koncentrationen..<br />
4) Angiv et 95% konfidensinterval for µ , idet det antages, at man fra tidligere målinger ved,<br />
at σ = 0.65.<br />
Opgave 5.2<br />
Trykstyrken i beton blev kontrolleret ved at man støbte 12 betonklodser og testede dem.<br />
Resultatet var:<br />
2216 2225 2318 2237 2301 2255 2249 2281 2275 2204 2263 2295<br />
1) Find et estimat for trykstyrkens middelværdi µ og spredning σ .<br />
2) Angiv et 95% konfidensinterval for µ .<br />
3) Angiv et 95% prædistinationsinterval for en enkelt måling af trykstyrken på en ny<br />
betonklods.<br />
4) Man fandt, at radius i konfidensintervallet var for stor.<br />
Bestem med tilnærmelse antallet af målinger der skal udføres, hvis radius højst skal være<br />
15.<br />
Opgave 5.3<br />
En fabrik producerer stempelringe til en bilmotor. Det vides, at stempelringenes diameter er<br />
approksimativt normalfordelt. Stempelringene bør have en diameter på 74.036 mm og en<br />
spredning på 0.001 mm. For at kontrollere dette udtog man tilfældigt 15 stempelringe af<br />
produktionen og målte diameteren. I resultaterne har man for simpelheds skyld, kun angivet de<br />
3 sidste cifre, altså 74.0365 angives som 365.<br />
Man fandt følgende resultater<br />
342 364 370 361 351 368 357 374 340 362 378 384 354 356 369<br />
1) Find et estimat for ringenes diameter µ og spredning σ .<br />
2) Angiv et 99% konfidensinterval for µ .<br />
Opgave 5.4<br />
En polymer produceres i batch. Viskositetsmålinger udført på hver batch gennem et stykke tid<br />
har vist, at variationen i processen er meget stabil med spredning σ = 20.<br />
På 15 batch gav viskositetsmålingerne følgende resultater:<br />
724 718 776 760 745 759 795 756 742 740 761 749 739 747 742<br />
1) Find et estimat for viskositetens middelværdi µ .<br />
2) Angiv et 95% konfidensinterval for µ idet man antager spredningen er 20.<br />
3) Find et estimat for viskositetens spredning σ .<br />
4) Angiv et 95% konfidensinterval for σ , for at kontrollere påstanden om, at σ<br />
= 20.
5 Stikprøver<br />
Opgave 5.5<br />
Ved en fabrikation af et bestemt sprængstof er det vigtigt, at en reaktoropløsning har en pHværdi<br />
omkring 8.0. Der foretages 6 målinger på en bestemt reaktantopløsning.<br />
Resultaterne var:<br />
pH 8.42 7.36 8.04 7.71 7.65 7.82<br />
Den benyttede pH-målemetode antages på baggrund af tidligere lignende målinger at give<br />
normalfordelte resultater.<br />
1) Angiv et estimat for opløsningens middelværdi og spredning.<br />
2) Angiv et 95% konfidensinterval for pH.<br />
3) Man finder, at radius i konfidensintervallet er for bredt.<br />
Angiv med tilnærmelse antallet af målinger der skal foretages, hvis radius skal være 0.1.<br />
Opgave 5.6<br />
Samme tal som i opgave 5.2<br />
Find et 95% konfidensinterval for trykprøvens spredning.<br />
Opgave 5.7<br />
Samme tal som i opgave 5.3<br />
Find ud fra stikprøven et 99% konfidensinterval for diameterens spredning.<br />
Opgave 5.8<br />
De 10 øverste ark papir i en pakke med printerpapir har følgende vægt<br />
4.21 4.33 4.26 4.27 4.19 4.30 4.24 4.24 4.28 4.24<br />
a) Angiv et 95%-konfidensinterval for middelværdi af papirets vægt.<br />
b) Angiv med tilnærmelse antallet af ark, der skal anvendes, hvis radius i konfidensintervallet<br />
højst skal være r = 0.02<br />
c) Angiv et 95%-prædistinationsinterval for en enkelt nyt ark papir.<br />
d) Angiv et 95%-konfidensinterval for spredningen af papirets vægt.<br />
Opgave 5.9<br />
Til undersøgelse af alkoholprocenten i en persons blod foretages 4 uafhængige målinger, som<br />
gav følgende resultater (i ‰):<br />
108 102 107 98<br />
1) Opstil et 95% konfidensinterval for personens alkoholkoncentration.<br />
2) Opstil et 95% konfidensinterval for målemetodens spredning.<br />
52
53<br />
6.1 Grundlæggende begreber<br />
6 HYPOTESETEST<br />
(ÉN NORMALFORDELT VARIABEL)<br />
6.1 GRUNDLÆGGENDE BEGREBER<br />
Ofte vil man se vendinger som” Stikprøven viser, at udbyttet ved den ny metode er signifikant<br />
større end ved den hidtidig anvendte metode”<br />
Statistiske problemer, hvor man på basis af en stikprøve ønsker med eksempelvis 95% “sikkerhed”<br />
at bevise en påstand om hele populationen kaldes hypotesetest.<br />
De forskellige begreber der indgår i en hypotesetest vil blive gennemgået i forbindelse med<br />
følgende eksempel.<br />
Eksempel 6.1. Hypotesetest.<br />
En fabrik har gennem mange år benyttet en metode, der på basis af en given mængde råmateriale<br />
gav et middeludbytte af et produceret stof på µ 0 = 69.2 kg og spredningen σ = 1.0 kg.<br />
En nyansat ingeniør får til opgave at søge at forøge middeludbyttet ved en passende (billig)<br />
modifikation af procesbetingelserne.<br />
Efter en række lovende eksperimenter i laboratoriet synes opgaven at være lykkedes, men det<br />
endelige bevis herfor er, ud fra et passende antal driftsforsøg statistisk at kunne “bevise”, at<br />
middeludbyttet er blevet forøget.<br />
Ud fra kendskab til de forskellige mulige støjfaktorer antages spredningen at være uændret på<br />
1.0 kg.<br />
Da driftsforsøgene er meget ressourcekrævende, bevilges der kun 12 delforsøg.<br />
Der foretages 12 uafhængige delforsøg og udbyttet x måltes:<br />
Forsøg nr 1 2 3 4 5 6 7 8 9 10 11 12<br />
x 68.8 70.7 70.3 70.1 70.7 68.7 69.2 68.9 70.0 69.6 71.0 69.1<br />
1) Kan man ud fra disse data bevise på signifikansniveau α = 0.05 , at middeludbyttet er blevet<br />
forøget ?<br />
2) Hvis svaret i spørgsmål 1 er bekræftende, så angiv et estimat for det nye middeludbytte, og<br />
angiv et 95% konfidensinterval herfor.
Hypotesetestning (1 normalfordelt variabel)<br />
Løsning:<br />
1) Løsningen opdeles for overskuelighedens skyld i en række trin<br />
1a) Definition af stokastisk variabel X.<br />
X = udbyttet ved den modificerede proces.<br />
1b) Valg af X’s fordelingstype.<br />
X antages at være approksimativt normalfordelt n( µ , 10 . ) .<br />
1c) Opstilling af nulhypotese og alternativ hypotese.<br />
Der opstilles en såkaldt Nulhypotesen H0 : µ = 69.2 kg.<br />
Nulhypotesen skal indeholde en konkret påstand (her et lighedstegn). Påstanden er, at<br />
modifikationen ingen (nul) virkning har<br />
Der opstilles endvidere en alternativ hypotese H: µ > 69.2 kg.<br />
Den alternative hypotese skal så vidt muligt indeholde det, der ønskes bevist. I dette<br />
tilfælde ønskes vist, at middeludbyttet er vokset, dvs. µ > 69.2 kg.<br />
Testen kaldes en ensidet test i modsætning til en tosidet test :<br />
H0 : µ = 69.2 kg contra H: µ ≠ 69.2 kg,<br />
hvor vi blot ønsker at vise, at middeludbyttet har ændret sig.<br />
1d) Angivelse af testens signifikansniveau.<br />
Hvis stikprøvens gennemsnit x er meget større end 69.2 kg ( måske helt op mod 100<br />
kg), så er der stor sandsynlighed for at udbyttet er steget. Man siger så, at nulhypotesen<br />
forkastes, eller at x ligger i forkastelsesområdet (se figur 6.1).<br />
Hvis derimod x kun ligger lidt over 69.2 kg, så kan det skyldes tilfældige udsving, og<br />
man kan ikke med nogen stor sikkerhed konkludere, at udbyttet er steget. Man siger, at<br />
nulhypotesen accepteres, eller at x ligger i acceptområdet.<br />
x 0<br />
Fig. 6.1 Accept- og forkastelsesområde<br />
Lad være grænsen mellem acceptområdet og forkastelsesområdet. skal bestemmes<br />
sådan, at forudsat H0 : µ = 69.2 kg er sand, så er det yderst usandsynligt, at en<br />
stikprøves gennemsnit x vil komme til at ligge i forkastelsesområdet. Hvis stikprøvens<br />
gennemsnit alligevel ligger i forkastelsesområdet, må det være forudsætningen H0 der<br />
er forkert, d.v.s. middeludbyttet må være blevet større.<br />
Det er naturligvis ikke entydigt bestemt, hvad det vil sige, at noget er yderst usandsynligt.<br />
Man starter derfor enhver test med at fastlægge det såkaldte signifikansniveau α .<br />
Er α valgt til 5% ,så har man derved fastlagt, at sandsynligheden for fejlagtigt at<br />
påstå, at middeludbyttet er steget, er under 5%.<br />
Da det kan have alvorlige økonomiske konsekvenser fejlagtigt at påstå at middeludbyttet<br />
54<br />
x 0
Fig 6.2 P-værdi<br />
55<br />
6.1 Grundlæggende begreber<br />
er steget (produktionen omstilles osv.) ,så er man naturligvis interesseret i, at dette ikke<br />
sker.<br />
Det normale i industriel produktion er, at sætte α = 5%, men er det eksempelvis medi-<br />
cinske forsøg, hvor det kan have alvorlige menneskelige konsekvenser, sættes α måske<br />
så lavt som 1% eller 0.1%, mens man i andre situationer måske sætter signifikansniveauet<br />
til 10%.<br />
I dette eksempel er α sat til 5%.<br />
1e) Beregning af P - værdi<br />
Gennemsnittet af de 12 resultater giver x = 69.76 kg.<br />
Under forudsætning af at nulhypotesen H0 : µ = 69.2 kg er sand, så er X er normalforσ<br />
10 .<br />
delt med middelværdi µ 0 = 69.2 og spredning = = 0. 2887 .<br />
n 12<br />
Vi kan derfor nemt finde den præcise adskillelse mellem accept og forkastelsesområdet,<br />
da den jo er bestemt ved at arealet skal være 95%<br />
TI89: invNorm(0.95,69.2,1.0/12)= 69.67<br />
Da 69.76 > 69.76 ligger det målte gennemsnit altså i forkastelsesområdet.<br />
Imidlertid vælger man i stedet at beregne den såkaldte P-værdi (Probability value) som<br />
er sandsynligheden for at få en værdi på det fundne stikprøvegennemsnit 69.76 eller<br />
derover, dvs. P-værdi = P( X ≥ 69. 76)<br />
Er denne P-værdi er mindre end α =0.05 må x = 69.76 ligge i forkastelsesområdet (se<br />
figur 6.2)<br />
Hvis P-værdien ligger over α ligger x = 69.76 i acceptområdet, dvs. vi kan ikke bevise<br />
at middeludbyttet er steget.<br />
TI89: P - værdi = normCdf(69.76, 6921 12 =0.0262<br />
P( X ≥ 69. 76) =<br />
∞, . , / ( ))<br />
Excel: P - værdi = 1-NORMFORDELING(69,76;69,2;1/KVROD(12);1)=0,026196<br />
P( X ≥ 69. 76)<br />
=<br />
1f) Konklusion<br />
Da P - værdi = 2.62% < 5% forkastes H0 ,<br />
Vi har et statistisk bevis for, at den modificerede proces giver et større middeludbytte.
Hypotesetestning (1 normalfordelt variabel)<br />
Alternativt kunne vi have benyttet nogle testfunktioner:<br />
TI-89: APPS STAT/LIST data indtastes i list1 F6, 1: Z-Test<br />
Menu udfyldes : µ 0 = 69. 2 , σ =1 , list =list1, Alternate Hyp: µ > µ 0 , Calculate<br />
Excel: Data indtastes i A1 til A12 fx Statistisk Z-test ZTEST(A1:A12;69,2;1)<br />
Vi får i begge tilfælde P-værdi = 0.0265, dvs. samme værdi som før.<br />
2) Udbyttet kan i middel forventes at være ca. x = 69. 76 kg<br />
99% konfidensinterval:<br />
TI-89: APPS STAT/LIST data indtastes i list1 F7, 2: Z-Interval C Int : [ 6919 . ; 70. 32]<br />
Excel: f x Statistisk konfidensinterval KONFIDENSINTERVAL(0,05;1;12) 0,565793<br />
[69.76 - 0.57;69.76+0.57] = [69.19 ; 70.32]<br />
At konfidensintervallet indeholder tallet 69.2 er klart i modstrid med at vi lige har vist, at<br />
middelværdien er større end 69.2.<br />
Det skyldes, at konfidensintervallet forkaster med 2.5% til hver side, mens en ensidet test<br />
forkaster kun til en side med 5%.<br />
Mere logisk ville det være, at lave en ensidet 95% konfidensinterval,<br />
⎡<br />
⎤ ⎡<br />
⎤<br />
⎢x<br />
−u095⋅ ∞⎥<br />
= ⎢69<br />
76 −165⋅ ∞⎥<br />
= [ ∞]<br />
⎣ n ⎦ ⎣<br />
⎦<br />
10<br />
σ<br />
.<br />
. ; . . ; 69. 28;<br />
12<br />
Det er imidlertid ikke standard, nok fordi det er sværere at forklare en udenforstående, at<br />
middelværdien med 95% sikkerhed ligger over 69.28 .<br />
Eksempel 6.2. Hypotesetest, hvor man får accept af H0. Samme problem som i eksempel 6.1, men nu er signifikansniveauet α =1%.<br />
Løsning:<br />
H0: µ = 69.2 mod H: H0: µ > 69.2<br />
I eksemplet fandt vi på basis af 12 forsøg, at P-værdi = 2.6%.<br />
Konklusion: H0 accepteres , dvs.<br />
vi kan ikke på et signifikansniveau på 1% bevise, at middelværdien var steget.<br />
Bemærk: Vi skriver ikke at vi har bevist den ikke er steget, det kan meget vel være tilfældet.<br />
Vi kan bare ikke bevise det med den ønskede sikkerhed.<br />
56
6.2 Eksempler på hypotesetest regnet med TI89 og Excel<br />
6.2 EKSEMPLER PÅ HYPOTESETEST REGNET MED TI89 OG EXCEL<br />
I eksempel 6.1 blev baggrunden for testen gennemgået. Samtidig antog vi, at spredningen var<br />
kendt eksakt. Dette er sjældent tilfældet, men havde vi haft over 30 målinger i stikprøven, ville<br />
det være tilladeligt, at erstatte den eksakte værdi med den beregnede spredning s, og foretage de<br />
samme beregninger<br />
Havde vi under 30 målinger bliver det for upræcist, og man må i stedet benytte en t-fordeling.<br />
Eksempel 6.2. Ensidet hypotesetest om middelværdi (spredning ikke kendt eksakt)<br />
Samme problem som i eksempel 6.1, men nu er spredningen ikke kendt eksakt.<br />
Løsning:<br />
1) X = udbyttet ved den modificerede proces.<br />
X antages at være approksimativt normalfordelt n( µ , 10 . ) .<br />
H0 : µ = 69.2 kg. H: µ > 69.2 kg.<br />
Beregning<br />
TI89: APPS STAT/LIST data indtastes i list1 F6, 2: T-Test<br />
Menu udfyldes : = 69. 2 , list =list1, Alternate Hyp: µ µ , Calculate<br />
µ 0<br />
P-værdi = 0.0185 =1.85%.<br />
Excel Her benyttes formlen i appendix 6.1.<br />
( x − µ 0)<br />
⋅ n<br />
PT ( ≥ t)<br />
, hvor t =<br />
og T er t-fordelt med n -1 frihedsgrader<br />
s<br />
Data indtastes i A1 til A12<br />
x streg = MIDDEL(A1:A12) 69,75833<br />
s= STDAFV(A1:A12) 0,816265<br />
Ho 0= 69,2<br />
t= (E1-E3)*KVROD(12)/E2 2,369481<br />
P-værdi= TFORDELING(ABS(E5);11;1) 0,018593<br />
Da P-værdi < 5% forkastes H 0 , dvs. vi har et statistisk bevis for, at den modificerede proces<br />
giver et større middeludbytte.<br />
2) TI-89: APPS Stat/List F7, 2: T-Interval Vælg Data Udfyld menuen C Int :[69.24 ; 70.28]<br />
Excel: 2003: Funktioner 2007: Data<br />
Dataanalyse Beskrivende statistik udfyld inputområde vælg konfidensniveau<br />
Resultat : Konfidensniveau(95,0%) 0,51863<br />
Konfidensinterval [69.758-0.517;69.758-0.5179] = [69.24 ; 70.28]<br />
57<br />
> 0
Hypotesetestning (1 normalfordelt variabel)<br />
Eksempel 6.3 Tosidet hypotesetest om middelværdi (spredning ikke kendt eksakt).<br />
Ved fremstilling af et bestemt levnedsmiddel er det vigtigt, at et tilsætningsstof findes i<br />
levnedsmidler i en koncentration på 8.40 (g/l).<br />
For at kontrollere om tilsætningsstoffet har en koncentration på ca. 8.40, udtager levnedsmiddelkontrollen<br />
6 prøver af levnedsmidler. Resultaterne var:<br />
Måling nr 1 2 3 4 5 6 7 8<br />
Koncentration x (g/l) 8.54 7.89 8.50 8.21 8.15 8.32 8.45 8.31<br />
Det ønskes på denne baggrund undersøgt om koncentrationen har den ønskede værdi.<br />
Signifikansniveau sættes til 5%.<br />
Løsning:<br />
Lad X være koncentrationen af tilsætningsstoffet i levnedsmidlet.<br />
Det antages, at X er normalfordelt<br />
n( µ , σ )<br />
Da det både er uønsket, at koncentrationen er for lille og at den er for stor, bliver nulhypotesen<br />
H0: µ = 8.4 mod H: µ ≠ 84 . , dvs. vi har en tosidet test.<br />
Bemærk, at selv om man vel egentlig hellere ville bevise, at koncentrationen er 8.4 og derfor<br />
helst ville have denne påstand i den alternative hypotese, er dette ikke muligt, da nulhypotesen<br />
skal indeholde et lighedstegn.<br />
TI-89: APPS STAT/LIST data indtastes i list1 F6, 2: T-Test<br />
Menu udfyldes : µ 0 = 84 . , list =list1, Alternate Hyp: µ ≠ µ 0 , Calculate<br />
Vi får P-værdi = 0.2117 =21.78%.<br />
Da P-værdi > 5% accepteres nulhypotesen , dvs. vi kan ikke bevise, at koncentrationen<br />
afviger signifikant fra 8.4 g/l<br />
Bemærk, at TI-89 beregner begge “haler” , så vi skal sammenligne med 5% .<br />
Excel Benytter formler i appendix 6.1<br />
Data indtastes i A1 til A8<br />
x streg = MIDDEL(A1:A8) 8,29625<br />
s= STDAFV(A1:A8) 0,213537<br />
Ho 0= 8,4<br />
n= 8<br />
t= (E1‐E3)*KVROD(e4)/E2 ‐1,37423<br />
P‐værdi= TFORDELING(ABS(E5);e4‐1;1) 0,105877<br />
Da P-værdi > 2.5 % accepteres nulhypotesen , dvs. vi kan ikke bevise, at koncentrationen<br />
afviger signifikant fra 8.4 g/l<br />
Bemærk, at da det er en tosidet test hvor man forkaster til begge sider sammenlignes<br />
med 2,5%<br />
58
59<br />
6.3 Fejl af type I og type II<br />
Eksempel 6.7. Test af spredning<br />
En fabrikant af læskedrikke har købt en automatisk “påfyldningsmaskine”.<br />
Ved købet af maskinen har man betinget sig, at rumfanget af den påfyldte væske i middel skal<br />
have en spredning, der ikke overstiger 0.20 ml.<br />
Efter kort tids anvendelse får man mistanke om, at spredningen er for stor. Mange klager over<br />
underfyldte flasker.<br />
Derfor foretages en kontrol, hvor man tilfældigt udtager 20 flasker med læskedrik, og måler<br />
rumfanget af væsken i flasken. Det viser sig, at stikprøvens spredning er s = 0.24 ml.<br />
Med et signifikansniveau på 5% er det da et statistisk bevis for, at den nye maskine ikke opfylder<br />
det stillede krav?<br />
Løsning:<br />
Lad X = rumfang af drik i flaske.<br />
X antages normalfordelt n( µ , σ ) , hvor såvel µ som σ er ukendte.<br />
Ho: σ = 02 . imod H: σ > 0.2,<br />
eller udtrykt ved variansen σ :<br />
2<br />
2 2<br />
2 2<br />
Ho: σ = 02 . mod H: σ > 02 . .<br />
Ifølge appendix 6.3 ses, at vi skal beregne teststørrelsen χ , hvor<br />
2<br />
2<br />
2 ( n−1) ⋅s<br />
χ =<br />
dvs. i det foreliggende tilfælde χ .<br />
2<br />
σ<br />
2<br />
2<br />
( 20 −1) ⋅0.<br />
24<br />
=<br />
= 27. 36<br />
2<br />
02 .<br />
0<br />
TI 89: P- værdi = PQ ( ≥ 27. 36) = chiCdf(27.36, ∞ ,19) = 0.0965 = 9.65%<br />
Excel:<br />
chi i anden= (20-1)*0,24^2/0,2^2 27,36<br />
P-værdi= CHIFORDELING(C1;19) 0,096543<br />
Da P-værdi=9.65% > 5 %, accepteres H0 , dvs. det er ikke påvist, at spredningen ved påfyldningen<br />
er for stor, men der er dog nær ved at være signifikans.<br />
6.3. FEJL AF TYPE I OG TYPE II:<br />
Ved enhver test kan der være to typer fejl, hvoraf vi hidtil kun har taget hensyn til den ene<br />
type. For bedre at forstå problemstillingen vil vi se på følgende skema.<br />
Beslutning<br />
Forudsætning<br />
H 0 accepteres H 0 forkastes<br />
H 0 er sand Rigtig beslutning Forkert beslutning<br />
Type I fejl<br />
H 0 er falsk Forkert beslutning<br />
Type II fejl<br />
Rigtig beslutning<br />
Det må være et krav til en god test, at der kun er en lille sandsynlighed for at begå en fejl af<br />
type I eller type II.
Hypotesetestning (1 normalfordelt variabel)<br />
I eksempel 6.1 ville en type I fejl være, hvis man konkluderer, at den modificerede proces<br />
giver et større udbytte, selv om det ikke er tilfældet. Virksomheden bruger måske millionbeløb<br />
på at omlægge produktionen, og det er ganske forgæves.<br />
En type II fejl ville være, at man ikke opdager, at den modificerede proces giver et større udbytte.<br />
Dette er naturligvis uheldigt, men hvis det skyldes, at forbedringen ikke blev opdaget,<br />
fordi den er ganske ringe, har det muligvis ingen praktisk betydning.<br />
Hvis en test har signifikansniveau α og den beregnede P-værdi < α så forkastes Ho .<br />
Vi ved hermed, at P(type I fejl) ≤ α , dvs. vi rimelig sikre på, at have foretaget en korrekt<br />
beslutning.<br />
P-værdien angiver jo nogenlunde sandsynligheden for at vi træffer en forkert beslutning.<br />
Hvis α = 5% og P-værdien er 4.25% forkastes H0. Det samme sker, hvis P-værdi = 0.001%,<br />
men vi er her unægtelig noget sikrere på, at vi at vi træffer en korrekt beslutning.<br />
Hvis vi accepterer H o er det blot udtryk for, at vi ikke kan forkaste(svag konklusion: "H o<br />
frikendes på grund af bevisets stilling").<br />
Man kan have begået en type II fejl, dvs. ikke opdaget, at den alternative hypotese var sand.<br />
Eksempel 6.8. Fejl af type 2<br />
Samme problem som i eksempel 6.1, men nu er signifikansniveauet α =1%<br />
Løsning:<br />
H0: µ = 69.2 mod H: H0: µ > 69.2<br />
I eksemplet fandt vi på basis af 12 forsøg, at P-værdi = 2.6%.<br />
Konklusion: H0 accepteres , dvs.<br />
vi kan ikke på et signifikansniveau på 1% bevise, at middelværdien var steget.<br />
Imidlertid kan middeludbyttet meget vel være steget, men vi kunne bare ikke bevise det med<br />
den ønskede sikkerhed. Vi kan have begået en fejl af type 2.<br />
Som det ses af eksempel 6.8, så vil en formindskelse af muligheden for at begå en type 1 fejl<br />
( α formindskes) forøge sandsynligheden for at begå en type 2 fejl.<br />
Den eneste måde hvorpå begge kan formindskes er at øge antallet n af forsøg.<br />
Problemet hermed er, at man derved måske opdager en så lille forbedring, at det ikke er rentabelt<br />
at foretage en dyr ændring af fremstillingsprocessen.<br />
Først når udbyttet overstiger en bagatelgrænse ∆ vil man reagere.<br />
Dimensionering af forsøg (vælge stikprøvestørrelse n).<br />
Lad os antage, at virksomheden i eksempel 6.1 finder, at hvis stigningen i udbyttet ved den<br />
modificerede proces er mindre end ∆ = 0.5 kg, så har det ingen praktisk interesse ( ∆ = 0.5<br />
kg er bagatelgrænsen), og derfor gør det intet, hvis man ikke opdager det (begår en type II<br />
fejl).<br />
Hvis derimod stigningen ∆ er større end 0.5 kg, så har det stor betydning, og sandsynligheden<br />
for at begå en type II fejl må derfor være lille. Lad os sætte den til højst β = 10%.<br />
Problemet er nu, hvor stor en stikprøvestørrelse n (antallet af delforsøg) der skal udføres, for<br />
at ovennævnte krav er opfyldt.<br />
60
61<br />
6.3 Fejl af type I og type II<br />
En sådan vurdering kaldes en dimensionering af forsøget. Udfører man det ud fra en dimensionering<br />
nødvendige antal forsøg, vil en accept af nulhypotesen nu betyde, at nok kan udbyttet<br />
være steget, men ikke så meget, at det har praktisk interesse.<br />
I appendix 6.1 og 6.2 er angivet de formler, der skal anvendes ved en dimensionering.<br />
De følgende 2 eksempler viser anvendelsen heraf.<br />
Eksempel 6.9. Dimensionering (kendt spredning).<br />
Inden man i eksempel 6.1 begyndte at lave de dyre delforsøg, vil ingeniøren gerne have en<br />
vurdering af, hvor mange driftsforsøg der er nødvendige, når det vides, at det først er økonomisk<br />
rentabelt at gå over til den nye metode, hvis middeludbyttet er steget med mindst 0.5 kg.<br />
1) Find stikprøvestørrelsen n, i det tilfælde, hvor ∆ = 0.5 kg og β = 10%.<br />
Det antages stadig, at σ = 1.0 kg og signifikansniveauet er α = 5 %.<br />
Lad n være den i spørgsmål 1 fundne stikprøvestørrelse.<br />
2) Idet der udføres n delforsøg skal man besvare følgende spørgsmål:<br />
a) Hvilken konklusion kan drages, hvis man finder, at x = 69.8<br />
b) Hvilken konklusion kan drages, hvis man finder, at x = 69.4<br />
Løsning<br />
1) X = udbyttet ved den modificerede proces.<br />
X antages at være approksimativt normalfordelt n( µ , 10 . ) .<br />
H0 : µ = 69.2 kg. H: µ > 69.2 kg.<br />
⎛ u1−α + u1−β ⎞ ⎛ u + u<br />
Da testen er ensidet fremgår det af appendix 6.2) at: n ≥ ⎜ ⎟ = ⎜ 05 .<br />
⎝ ⎠ ⎝<br />
∆<br />
σ<br />
TI89: ((invNorm(0.95)+invNorm(0.90))/(0.5/1.0))^2 = 34.25 , dvs. n = 35 .<br />
2<br />
095 . 090 .<br />
Excel: =((NORMINV(0,95;0;1)+NORMINV(0,9;0;1))/(0,5/0,1))^2 Resultat 0,342554 dvs. n = 35<br />
2a) H0: µ = 69.2 mod H: H0: µ > 69.2<br />
TI89: APPS STAT/LIST F6, 1: Z-Test Vælg Stats, da data ikke kendt<br />
Menu udfyldes : µ 0 = 69. 2 , σ =1 , x = 69.8, n = 35, Alternate Hyp: µ > µ 0 , Calculate<br />
P-værdi = 0.019%,<br />
Excel: P-værdi = =1 - NORMFORDELING(69,8;69,2;1/KVROD(35);1) = 0,000193<br />
Da P_værdi < 0.05 forkastes H0: µ = 69.2 kg , dvs. vi er på et Signifikansniveau på 5%<br />
sikre på at middelværdien er over 69.2 kg.<br />
Imidlertid kan vi ikke være sikre på at den er over bagatelgrænsen 69.2 + 0.5 = 69.7 kg<br />
Lad H0: µ = 69.7 mod H: H0: µ > 69.7<br />
Vi finder på samme måde som ovenfor, at P-værdi = 27.7%, dvs. en påstand om at middeludbyttet<br />
ligger over 69.7 kg vil være fejlagtig i ca. 28% af tilfældene.<br />
Vi vil derfor næppe på den baggrund gå over til den nye metode.<br />
2b) H0: µ = 69.2 mod H: H0: µ > 69.2<br />
Vi finder på samme måde som i punkt 2a) , at P-værdi = 11.8%%,<br />
H0: µ = 69.2 kg accepters, dvs. vi kan ikke vise, at middeludbyttet er steget, men da vi<br />
har dimensioneret er vi rimeligt sikre på, at en eventuel stigning ikke har praktisk interesse.<br />
10 .<br />
⎞<br />
⎟<br />
⎠<br />
2
Hypotesetestning (1 normalfordelt variabel)<br />
Eksempel 6.10. Dimensionering, (ukendt spredning)<br />
En virksomhed bliver af miljøkontrollen pålagt at formindske indholdet i sit spildevand af et<br />
stof A, der mistænkes for at kunne forurene grundvandet. Indholdet af stoffet A i spildevandet<br />
skal under 1.7 mg/l, og miljøkontrollen henviser til en ny metode, som burde kunne formindske<br />
indholdet til det ønskede niveau. For at vurdere den nye metode ønskes foretaget en række<br />
delforsøg.<br />
Hvor mange forsøg skal der mindst foretages, hvis α = 5%, β = 10%, ∆ = 0.10 mg/l og et<br />
overslag over hvor stor σ er sætter denne til 0.15 mg/l.<br />
Løsning:<br />
Lad X = indhold af A (i mg/l) efter benyttelse af den ny metode.<br />
X antages normalfordelt n( µ , σ ) , hvor såvel µ som σ er ukendte.<br />
Da indholdet af stoffet A ønskes formindsket, bliver<br />
nulhypotesen H0: µ = 17 . mg/l mod H: µ < 17 . mg/l, dvs. vi har en ensidet test.<br />
Da σ ikke er kendt (kun et løst skøn kendes), er testen en t - test.<br />
Formlen i appendix 6.1 anvendes:<br />
2<br />
⎛ u + u ⎞<br />
Først beregnes 095 . 090 .<br />
n ≥ ⎜ ⎟<br />
∆<br />
⎝ σ ⎠<br />
TI89: ((invnorm(0.95)+invnorm(0.90))/(0.10/0.15))^2 Resultat n = 19.27<br />
2<br />
⎛ t095 . ( n−1)<br />
⎞<br />
Da n < 30 løses nu ligningen n = 19. 27⋅⎜<br />
⎟<br />
⎝ u095<br />
. ⎠<br />
solve(x = 19.27 ⋅ (inv_t(0.95,x-1)/invnorm(0.95))^2,x) x > 19<br />
Heraf følger x = 21.17, dvs. n = 22<br />
Den ønskede dimensionering kræver altså 22 forsøg.<br />
Excel: ((NORMINV(0,95;0;1)+NORMINV(0,9;0;1))/(0,1/0,15))^2 Resultat n = 19.27<br />
2<br />
⎛ t095 . ( n−1)<br />
⎞<br />
Da n < 30 løses nu ligningen 19. 27⋅<br />
⎜ ⎟ − n = 0<br />
⎝ u ⎠<br />
095 .<br />
Resultatet 19.27 anbringes i celle A1<br />
I celle B1 skrives som startværdi for n tallet 19 .<br />
I celle C1 skrives =A1*(TINV(0,10;B1-1)/NORMINV(0,95;0;1))^2-B1<br />
2003: Funktioner “Målsøgning”<br />
2007: Data Hvad-hvis analyse ”Målsøgning<br />
I “Angiv celle” skrives C1. I “Til Værdi” skrives 0.<br />
“Ved ændring af celle” skrives B1<br />
Resultat: I celle B1står 21,18523 dvs. n = 22<br />
62
6.4. OVERSIGT over centrale formler i kapitel 6<br />
n( µ , σ )<br />
x<br />
63<br />
6.4 Oversigt<br />
X antages normalfordelt .Givet stikprøve af størrelsen n med gennemsnit og spredning s<br />
Signifikansniveau: α . er en given konstant<br />
µ 0<br />
Oversigt over test af middelværdi µ<br />
T er en stokastisk variabel der er t - fordelt med f = n - 1.<br />
σ<br />
Y er en stokastisk variabel, der er normalfordelt n(<br />
µ 0 ,<br />
n<br />
Forudsætninger Alternativ<br />
hypotese H<br />
σ ukendt.<br />
( x − µ 0)<br />
⋅ n<br />
t =<br />
.<br />
s<br />
σ kendt eks-<br />
akt<br />
P - værdi Beregning H 0 forkastes<br />
H: µ > µ 0 PT ( ≥ t)<br />
TI89: tCdf (, t ∞, n −1)<br />
eller F6: t-test<br />
Excel:tfordeling(t,n-1,1)<br />
H: µ < µ 0 PT ( ≤ t)<br />
TI89: tCdf ( −∞, t, n −1)<br />
eller F6: t-test<br />
Excel:1-tfordeling(t,n-1,1)<br />
H: µ ≠ µ 0 PT ( ≥ t)<br />
for x > µ 0<br />
PT ( t)<br />
for<br />
som række 1<br />
som række 2<br />
H: µ > µ PY ( ≥ x)<br />
0<br />
H: µ < µ 0<br />
H: µ ≠ µ 0<br />
≤ x ≤ µ 0<br />
PY ( ≤ x)<br />
PY ( x)<br />
for<br />
≥ x > µ 0<br />
PY ( x)<br />
for<br />
≤ x ≤ µ 0<br />
σ<br />
TI89: normCdf ( x,<br />
∞ , µ 0 , )<br />
n<br />
eller F6: Z-test<br />
⎛ σ<br />
Excel:1-normfordeling x,<br />
µ ,<br />
eller ztest<br />
⎜<br />
⎝<br />
0<br />
⎞<br />
⎟<br />
n ⎠<br />
⎛ σ ⎞<br />
TI89: normCdf ⎜−∞,<br />
x,<br />
µ 0 , ⎟<br />
⎝<br />
n ⎠<br />
eller F6: Z-test<br />
⎛ σ ⎞<br />
Excel:normfordeling x,<br />
µ ,<br />
eller ztest<br />
som række 1<br />
som række 2<br />
⎜<br />
⎝<br />
0<br />
⎟<br />
n ⎠<br />
P - værdi < α<br />
P - værdi < 1<br />
2 α<br />
dog hvis t-test<br />
P - værdi < α<br />
P - værdi < α<br />
P - værdi < 1<br />
2 α<br />
dog hvis Z-test<br />
anvendes<br />
P - værdi < α
Hypotesetestning (1 normalfordelt variabel)<br />
Dimensionering<br />
∆ = −<br />
µ µ 0 µ<br />
er den mindste ændring i der har praktisk interesse.<br />
α =P(type I fejl), β = P(type II fejl)<br />
Forudsætning Hypotese Formel Beregning<br />
σ kendt eksakt<br />
σ er ukendt,<br />
men erstattes i<br />
formlerne af<br />
det bedste estimat<br />
eller gæt<br />
for spredningen.<br />
Ensidet<br />
Tosidet<br />
⎛<br />
⎜ u + u<br />
n ≥ ⎜<br />
⎜<br />
∆<br />
⎝ σ<br />
1−α 1−β<br />
⎛ u + u<br />
⎜ 1− 2<br />
n ≥ ⎜<br />
⎜<br />
∆<br />
⎝ σ<br />
α 1−<br />
β<br />
⎞<br />
⎟<br />
⎟<br />
⎟<br />
⎠<br />
⎞<br />
⎟<br />
⎟<br />
⎟<br />
⎠<br />
2<br />
2<br />
TI89: ((invNorm(1- α )+invNorm(1- β ))/( ∆ / σ ))^2<br />
Excel: =((NORMINV(1- α ;0;1)+NORMINV(1- β ;0;1))/ ( ∆ / σ ))^2<br />
TI89: ((invNorm(1- α /2)+invNorm(1- β ))/( ∆ / σ ))^2<br />
Excel: =((NORMINV(1- α /2;0;1)+NORMINV(1- β ;0;1))/ ( ∆ / σ ))^2<br />
Ensidet 2<br />
Løse ligning, se eksempel 6.10<br />
Tosidet<br />
⎛ ⎞<br />
⎜ u + u ⎟<br />
1−α 1−β<br />
⎛ t1−α( n−1)<br />
⎞<br />
n ≥ ⎜ ⎟ ⋅⎜<br />
⎟<br />
⎜ ∆<br />
u<br />
⎜<br />
⎟ ⎝ 1−α<br />
⎠<br />
⎟<br />
⎝ σ ⎠<br />
⎛ u + u ⎞ t n<br />
⎜ α 1−β<br />
⎛<br />
⎟ α ( −1)<br />
⎞<br />
1− ⎜ 1− ⎟<br />
2<br />
2<br />
n ≥ ⎜ ⎟ ⋅⎜<br />
⎟<br />
⎜ ∆<br />
u<br />
⎜<br />
⎟ ⎜ α ⎟<br />
⎝ ⎠ ⎝ 1− σ<br />
2 ⎠<br />
2<br />
64<br />
2<br />
2<br />
Løse ligning, se eksempel 6.10
Oversigt over test af varians<br />
χ 2<br />
Q er fordelt med f = n - 1.<br />
er en given konstant<br />
σ 0<br />
σ 2<br />
65<br />
6.4 Oversigt<br />
Forudsætning Alternativ<br />
hypotese H<br />
P - værdi Beregning H0 forkastes<br />
µ ukendt<br />
2<br />
H:σ<br />
2<br />
> σ0<br />
2<br />
PQ ( ≥ χ )<br />
TI89:<br />
2<br />
chi2Cdf ( χ , ∞, n −1)<br />
2<br />
χ<br />
2<br />
( n − 1)<br />
s<br />
= 2<br />
σ 0<br />
2 2<br />
H:σ < σ0PQ<br />
( ≤ χ )<br />
Excel: se eksempel 6.7 P-værdi< α<br />
2 TI89:<br />
2<br />
chi2Cdf ( −∞, χ , n −1)<br />
µ kendt<br />
2 ( n − 1)<br />
s + n( x − µ )<br />
χ =<br />
2<br />
σ<br />
2 2<br />
0<br />
2 2<br />
H:σ ≠ σ PQ ( ≥ χ ) for<br />
2<br />
0<br />
PQ ( ) for<br />
≤ χ 2<br />
2 2<br />
H:σ > σ0PQ<br />
( ≥ χ )<br />
2 2<br />
H:σ < σ0PQ<br />
( )<br />
2 2<br />
H:σ ≠ σ PQ ( ≥ χ ) for<br />
2<br />
0<br />
χ 2<br />
χ 2<br />
χ 2<br />
≥ n −<br />
< n −<br />
1<br />
1<br />
som række 1<br />
som række 2<br />
2 TI89:<br />
2<br />
chi2Cdf ( χ , ∞,<br />
n)<br />
≤ χ 2 TI89:<br />
≥ n −<br />
1<br />
PQ ( ≤ χ ) for<br />
2<br />
χ 2<br />
< n −<br />
1<br />
P-værdi< 1<br />
2 α<br />
Excel: se eksempel 6.7 P-værdi< α<br />
2<br />
chi2Cdf ( −∞, χ , n)<br />
som række 1<br />
som række 2<br />
P-værdi< 1<br />
2 α
Hypotesetestning (1 normalfordelt variabel)<br />
OPGAVER<br />
Opgave 6.1<br />
Et levnedsmiddel (“corned beef”) forhandles i pakker på 100 g.<br />
Ved fabrikationen tilsættes traditionelt et konserveringsmiddel B (nitrit).<br />
Da man har mistanke om, at B anvendt i større mængder kan have uønskede bivirkninger, må<br />
der højst tilsættes 2.5 mg B pr. 100 g.<br />
Fabrikanten reklamerer med, at der i middel højst er 2 mg B pr. pakke.<br />
En konkurrent tvivler herpå, og vil teste påstanden.<br />
Der købes i forskellige butikker i alt 36 pakker, og indholdet af B blev målt.<br />
x<br />
Man fandt et gennemsnit af B på = 2.10 mg med et estimat på spredningen på s = 0.30 mg<br />
.<br />
Kan man ud fra disse data bevise på signifikansniveau α = 0.01, at reklamen lyver.<br />
Opgave 6.2<br />
Et flyselskab overvejer at lukke en flyrute, såfremt µ = “middelværdien af antal solgte pladser<br />
pr. afgang” er under 60.<br />
På de sidste n = 100 afgange er der i gennemsnit solgt x = 58.0 pladser med en standardafvi-<br />
gelse på s =11.0 pladser.<br />
1) Kan man ud fra disse data bevise på signifikansniveau α = 0.05, at der i middel er solgt<br />
under 60 pladser pr. afgang? (Husk at anføre: Hvad X er. Antagelser. Nulhypotese. Beregninger.<br />
Konklusion.).<br />
2) Angiv et estimat ~µ for middelværdien µ .<br />
3) Forudsat, at man i spørgsmål 1 kan bevise, at der er solgt under 60 pladser, skal der angives<br />
et 95% konfidensinterval for middelværdien µ .<br />
Opgave 6.3<br />
En fabrikation er baseret på en kemisk reaktion, hvor processen forudsætter tilstedeværelse af<br />
en katalysator. Med den hidtil benyttede katalysatortype C1 udnyttes i middel kun ca. 70% af<br />
den dyreste råvare. Firmaet overvejer at gå over til en mere effektiv katalysatortype C2 ved<br />
produktionen. Omlægning hertil vil imidlertid kræve betydelige etableringsomkostninger,<br />
hvorfor firmaet kun vil lægge produktionen om, såfremt i middel mindst 80% af den dyreste<br />
råvare udnyttes, når C2 benyttes. Til vurdering heraf foretoges en række forsøg med benyttelse<br />
af C2. Følgende udnyttelsesprocenter fandtes:<br />
68.3 87.7 80.0 84.2 84.0 83.6 76.4 79.9 89.3 75.8<br />
96.1 88.0 79.8 83.7 84.4 95.5 84.2 92.1 92.4 83.9<br />
1) Lad X = udnyttelsesprocenten når C2 benyttes.<br />
Beregn estimater x og s for middelværdi E(X) og spredning σ ( X ) .<br />
2) Vurder, om de opnåede forsøgsresultater kan opfattes som et eksperimentelt bevis for, at i<br />
middel over 80% af den dyreste råvare udnyttes, når C2 benyttes.<br />
3) Forudsat, at man i spørgsmål 2 kan bevise, at i middel over 80% udnyttes. Skal opstilles et<br />
(tosidet) 95% konfidensinterval for E(X).<br />
Vi antager i det følgende, at X (approksimativt) er normalfordelt nxs ( , ) .<br />
4) Beregn sandsynligheden for, at udnyttelsesprocenten X er mindre end 80%, når C 2 benyttes.<br />
66
67<br />
Opgaver til kapitel 6<br />
Opgave 6.4<br />
Et kemikalium fremstilles industrielt ved inddampning af en bestemt opløsning. Det var vigtigt,<br />
at denne opløsning var svagt basisk med pH = 8.0. Man foretog derfor kontrolmæssigt<br />
nogle pH-bestemmelser for den benyttede opløsning. Følgende værdier fandtes:<br />
8.2 8.3 7.9 8.2 7.8 8.6 8.9 7.8 8.2<br />
a) Foretag en testning af om opløsningen kan antages at opfylde kravet til pH-værdi<br />
b) Forudsat, at man i spørgsmål a kan bevise, at opløsningen ikke opfylder kravet, skal opstilles<br />
et 95% konfidensinterval for pH-værdien.<br />
Opgave 6.5<br />
Man frygter, at den såkaldte “ syreregn er årsag til, at en bestemt skov er stærkt medtaget.<br />
Man måler SO 2 - koncentrationen forskellige steder i skovbunden (i g/m 3 ) og finder:<br />
µ<br />
32.7 23.9 21.7 18.6 27.6 35.1 42.2 36.5 13.4 41.8 34.3 30.0<br />
I ubeskadede skove er SO2 - koncentrationen 20 g/m 3 µ .<br />
a) Giver forsøgene et bevis for, at middelkoncentrationen af SO2 i den beskadigede skov er<br />
større end normalt?<br />
b) Forudsat, at man i spørgsmål a kan bevise, at middelkoncentrationen af SO2 i den beskadigede<br />
skov er større end normalt, skal man angive et tosidet 95%-konfidensinterval for SO2 - koncentrationen.<br />
Opgave 6.6<br />
Et nyt måleapparat påstås at give måleresultater med spredningen σ = 1.8 mg/l ved måling af<br />
salt-indholdet i en opløsning. Da dette er mindre end det sædvanlige, køber et laboratorium et<br />
eksemplar af apparatet for at kontrollere påstanden.<br />
Der foretages 15 målinger med følgende resultater:<br />
3.4 7.7 6.0 8.1 8.4 2.7 4.9 1.2 2.1 5.4 3.5 1.5 5.2 4.1 3.9<br />
Test på basis af disse resultater, om spredningen afviger fra 1.8 mg/l.<br />
(Husk altid at anføre: Hvad X er. Antagelser. Nulhypotese. Beregninger. Konklusion.).<br />
Opgave 6.7<br />
En medicinalvarefabrik overvejer at indføre en ny analysemetode.<br />
Det formodes, at spredningen er mindre end 2.0 mg/l.<br />
Man ved, at den nye metode er uden systematiske fejl.<br />
Der fremstilles ved afvejning et præparat med nøjagtig 40.5 mg/l, dvs. middelværdien er kendt.<br />
Følgende måleresultater (i mg/l) findes med den nye metode:<br />
42.8 39.3 41.2 40.9 40.2 40.7 40.6 40.0 41.5<br />
1) Bekræfter de foretagne observationer forhåndsformodningen om spredningen.<br />
(Husk altid at anføre: Hvad X er. Antagelser. Nulhypotese. Beregninger. Konklusion.).<br />
2) Angiv et estimat for spredningen.<br />
3) Angiv et 95% konfidensinterval for spredningen.
Hypotesetestning (1 normalfordelt variabel)<br />
Opgave 6.8<br />
Ved indkøbet af et nyt måleapparat oplystes det, at apparatet målte med en spredning på 2.8<br />
enheder. Efter at have brugt apparatet et stykke tid nærede køberen mistanke om, at apparatet<br />
målte med større spredning end oplyst.<br />
For at få spørgsmålet undersøgt lod køberen en bestemt måling udføre et antal gange.<br />
Følgende resultater fandtes:<br />
18.8 15.5 12.2 14.8 4.80 1.20 1.43 9.60 1.39 1.17 5.60 1.27 1.35<br />
8.70 1.23 1.40 1.02 1.65 1.91 1.14 1.46 1.59 1.54 1.01 1.80<br />
Hvilke konklusioner kan køberen drage ud fra en statistisk analyse af de fundne forsøgsresultater?<br />
Opgave 6.9<br />
En sukkerfabrik leverer sukkeret i 1 kg-poser og 2 kg-poser. Vægten af de fyldte poser varierer.<br />
1) For 1 kg-posernes vedkommende antages vægten at have en middelværdi på 1000 gram.<br />
En række forsøg har vist, at sandsynligheden for, at en tilfældig udtaget 1 kg-pose vejer<br />
mere ned 1025 gram, er 10%. Giv på det grundlag en vurdering af spredningen.<br />
2) For 2 kg-posernes vedkommende bør middelværdien være 200 gram, og spredningen må<br />
ikke overstige 25 gram. For at kontrollere, om en ny pakkemaskine overholder disse normer,<br />
udtages tilfældigt 100 pakker af denne maskines produktion. Gennemsnittet beregnes<br />
til x = 2008 gram, og et estimat for spredningen til s = 25 gram.<br />
Det formodes på forhånd, at den nye maskine overholder de ovennævnte normer. Foretag<br />
en statistisk vurdering af, om dette kan antages at være tilfældet.<br />
Opgave 6.10<br />
Under produktionen forekommer blandt en fabriks affaldsprodukter 1,5 mg/l af et stof A,<br />
som i større mængder kan være kræftfremkaldende. Man håber ved en ny og mere kostbar<br />
metode, at formindske indholdet af det pågældende stof.<br />
1) Inden man lavede forsøgene, foretog man en dimensionering. Hvis formindskelsen er under<br />
0.2 mg/l, er det ikke rimeligt at gå over til den nye metode. Man ønsker derfor at finde<br />
det mindste antal målinger, der skal indgå i undersøgelsen, for at man ved en ændring i<br />
indholdet af A på ∆ = 0.2 mg/l højst har, at P (type II fejl) = β = 10%.<br />
Man har en begrundet formodning om, at spredningen i resultaterne højst kan være 0.21<br />
mg/l ( α = 0.05 ).<br />
2) Ved en række kontrolmålinger efter tilsætning af additivet fandtes følgende resultater (i<br />
mg/l)<br />
1.12 1.47 1.35 1.27 1.17 1.26 1.83 1.10 1.39 1.25 1.44 1.14<br />
Test på 5% niveau, om målingerne beviser, at der er sket en formindskelse af middelindholdet<br />
af stoffet A. (Husk altid at anføre: Hvad X er. Antagelser. Nulhypotese. Beregninger.<br />
Konklusion.).<br />
3) Er det på basis af resultaterne muligt at vurdere, om den fundne formindskelse er stor nok<br />
til, at man vil gå over til den nye metode?<br />
68
69<br />
Opgaver til kapitel 6<br />
Opgave 6.11<br />
På et kraftvarmeværk mener man, at en ny metode vil kunne formindske svovlindholdet i de<br />
slagger, der bliver tilbage efter kulfyringen. Med en bestemt kvalitet kul, har det hidtidige svovlindhold<br />
været 2.70 %.<br />
For at vurdere den nye metode ønsker ingeniøren at foretage en række forsøg.<br />
1) Hvor mange forsøg skal der mindst foretages, hvis α = 5%, β = 10%, ∆ = 0.05 og et over-<br />
slag over spredningens størrelse sætter den til højst 0.08%.<br />
2) Uanset resultatet af dimensioneringen i spørgsmål 1), er der kun praktiske muligheder for at<br />
lave 16 forsøg. Følgende værdier af svovlindholdet fandtes (%).<br />
2.58 2.64 2.80 2.50 2.52 2.69 2.60 2.73 2.61 2.62 2.65 2.58 2.70 2.67 2.62 2.64<br />
Test om disse måleresultater beviser, at svovlindholdet ved den nye metode i middel er blevet<br />
mindre.<br />
3) Er det på basis af resultaterne muligt at vurdere, om den fundne formindskelse er stor nok til,<br />
at man vil gå over til den nye metode?<br />
Opgave 6.12<br />
På pakken af en iscreme står, at portionen indeholder 14 gram fedt. For at kontrollere dette købes<br />
n pakker is, og fedtindholdet måles.<br />
1) Bestem den nødvendige stikprøvestørrelse n, for at man ved en forskel i fedtindhold på ∆<br />
= 0.50 gram højst har, at P (type I fejl) = α = 0.01 og P (type II fejl) = β = 0.05.<br />
( σ ≈ 042 . gram).<br />
2) Man finder et gennemsnit på 13.1 gram og et estimat s for spredningen på 0.42 gram.<br />
Kan man ud fra disse data bevise på signifikansniveau α = 0.01, at middelindholdet afviger<br />
fra 14 gram? (Husk altid at anføre: Hvad X er. Antagelser. Nulhypotese. Beregninger.<br />
Konklusion.).<br />
2) Angiv et estimat for middelindholdet.<br />
3) Forudsat, at man i spørgsmål 1 kan bevise, at middelindholdet afviger fra 14 gram, skal angives<br />
et 95% konfidensinterval for middelindholdet.
7. Hypotesetest 2 variable<br />
7 . HYPOTESETEST<br />
TO NORMALFORDELTE VARIABLE<br />
7.1 INDLEDNING<br />
I dette kapitel benyttes følgende eksempel til at forklare problemstilling, metode osv.<br />
Eksempel 7.1. Sammenligning af 2 normalfordelte variable<br />
To produktionsmetoder M1 og M2 ønskes sammenlignet. Der udvælges tilfældigt 20 personer,<br />
hvoraf de 10 bliver sat til at arbejde med den ene metode, og de 10 andre med den anden.<br />
Efter 2 ugers forløb, beregnede man for hver person det gennemsnitlige tidsforbrug pr. enhed.<br />
Da metode 1 er mere kostbar end metode 2, ønsker man kun at gå over til den, hvis tidsforbruget<br />
pr. enhed ved metode 1 er mindst 2 minutter mindre end ved metode 2.<br />
Man fik følgende resultater.<br />
87.8 91.9 89.8 89.0 92.6 89.4 91.4 88.7 90.1 92.4<br />
M 1<br />
M 2<br />
92.4 94.6 93.0 94.0 92.4 92.9 96.4 92.1 92.8 93.4<br />
For at forsøgsresultaterne skal være “statistisk gyldige”, skal målingerne være uafhængige og<br />
repræsentative for det man skal undersøge.<br />
Det er således ikke korrekt, hvis man i eksempel 7.1 først udtager 10 personer, foretager målingerne,<br />
laver en test, opdager man ikke kan vise at metode 1 giver 2 minutters lavere tidsforbrug,<br />
udtager yderligere 10 personer , tester på de samlede fremkomne tal, osv. indtil man opnår den<br />
ønskede signifikans.<br />
Forsøg bør udføres så der er lige mange gentagelser.<br />
Det er klart, at det ville være forkert, at udtage 2 personer til at arbejde med metode M 1 og 18<br />
personer til at arbejde med metode M 2.<br />
Hvis en af personerne bliver syg under arbejdet, så der kun er 9 på det ene hold, ødelægger det<br />
dog ikke testen.<br />
Ved sammenligning af 2 normalfordelte variable er der afhængigt af hvordan stikprøven er<br />
indsamlet valg mellem 2 metoder.<br />
Er stikprøverne for de to variable som i eksempel 7.1 indsamlet ” uafhængigt af hinanden “<br />
benyttes sædvanligvis den i appendix 7.1 angivne metode.<br />
Er observationerne indsamlet “parvist” skal man benytte den i eksempel 7.3 angivne metode.<br />
70
7.2 Sammenligning af 2 normalfordelte variable<br />
7.2. SAMMENLIGNING AF 2 NORMALFORDELTE VARIABLE<br />
Eksempel 7.1. Sammenligning af 2 normalfordelte variable<br />
To produktionsmetoder M1 og M2 ønskes sammenlignet. Der udvælges tilfældigt 20 personer,<br />
hvoraf de 10 bliver sat til at arbejde med den ene metode, og de 10 andre med den anden.<br />
Efter 2 ugers forløb, beregnede man for hver person det gennemsnitlige tidsforbrug pr. enhed.<br />
Da metode 1 er mere kostbar end metode 2, ønsker man kun at gå over til den, hvis tidsforbruget<br />
pr. enhed ved metode 1 er mindst 2 minutter mindre end ved metode 2.<br />
Man fik følgende resultater.<br />
87.8 91.9 89.8 89.0 92.6 89.4 91.4 88.7 90.1 92.4<br />
M 1<br />
M 2<br />
92.4 94.6 93.0 94.0 92.4 92.9 96.4 92.1 92.8 94.6<br />
1) Undersøg på basis af disse resultater, om det på et signifikansniveau på 5% kan påvises at<br />
tidsforbruget ved metode M1 er 2 minutter mindre end ved metode M2 2) Hvis dette kan påvises, skal der angives et 95% konfidensinterval for differensen i tidsforbrug.<br />
Løsning:<br />
a) Lad X1 = udbyttet ved anvendelse af metode M1 og<br />
X2 = udbyttet ved anvendelse af metode M2. X1 og X2 antages approksimativt normalfordelte med middelværdi og spredning henholdsvis<br />
µ , σ og µ , σ .<br />
1 1 2 2<br />
H0: µ 2 − µ 1 = 2<br />
H: µ 2 − µ 1 > 2<br />
Begrundelse: Nulhypotesen udtrykker jo, at intet er ændret (nul virkning),<br />
så den angiver, at differensen i middeltidsforbruget er præcist 2.<br />
Begrundelse: Den alternative metode udtrykker jo det vi ønsker at bevise,<br />
så den angiver, at differensen i middeltidsforbruget er større end 2.<br />
Såvel TI89 som Excel anvender et færdigt program, der anvender en testmetode (Satterthwaites metode), som<br />
er robust overfor mindre afvigelser fra kravet om normalitet, når blot antallet af gentagelser er (næsten) den<br />
samme.<br />
Er det ikke tilfældet kan man stadig foretage testen, men så stilles der større krav til, at de variable X 1 og X 2<br />
virkelig er normalfordelte.<br />
Formlen for Satterthwaites metode kan findes i oversigt 7.<br />
TI89: Hypoteserne omskrives til<br />
: µ + 2 = µ H: µ + 2 < µ<br />
H 0 1 2<br />
1 2<br />
APPS, STAT/LIST , indtast data i list1 og list 2 F6, 4: 2 - SampTtest ENTER<br />
I den fremkomne menu vælg Data ok<br />
71<br />
µ < µ<br />
I menu for “list 1" skrives list1+2, for “alternative Hyp”<br />
Man får P-værdi = 0.0464.<br />
Excel: Tallene for metode 1 indtastes i A1 til A10<br />
Tallene for metode 2 indtastes i B1 til B10<br />
1 2 og pooled til “NO” OK<br />
I C1 til C10 indsættes tallene fra A-kolonnen +2 (Skriv i C1 =A1+2 , og kopiere resultat ned)<br />
På værktøjslinien foroven: Tryk på f x Vælg kategorien “Statistisk” Vælg “TTEST”<br />
Tabel udfyldes: =TTEST(C1:C10;B1:B10;1;3)<br />
P-værdi= 0,0464<br />
Da P-værdi =4.64% < 5% forkastes H 0, dvs. vi har bevist, at tidsforbruget ved metode M 1 er 2<br />
minutter mindre end ved metode M 2.
7. Hypotesetest 2 variable<br />
2) 95% Konfidensinterval for differens<br />
TI89: F7, 4: 2 - SampTint ENTER I den fremkomne menu vælg Data ok<br />
I menu for “list 1" skrives blot list2, osv. poole til “No” OK<br />
Differensen er 3.21 og 95% konfidensinterval for differensen er [1.77 ; 4.64]<br />
Excel:<br />
Excel har intet program til beregning af konfidensinterval, så man må benytte formlen<br />
µ 1 − µ 2:<br />
x1− x2− t0975 , ( f ) ⋅ c ≤ µ 1− µ 2 ≤ x1− x2+ t0975 , ( f ) ⋅<br />
2<br />
s1<br />
c , hvor c = +<br />
n<br />
2<br />
s2<br />
n<br />
c<br />
og frihedsgradstallet f er det nærmeste hele tal der er større end g =<br />
⎛ s ⎞ s<br />
⎜ ⎟<br />
⎝ n ⎠ n<br />
n − n<br />
+<br />
2<br />
2<br />
2<br />
2<br />
2<br />
⎛ ⎞<br />
1<br />
2<br />
⎜ ⎟<br />
1 ⎝ 2 ⎠<br />
1 −1<br />
xA streg= MIDDEL(A1:A10) 90,31<br />
xB streg= MIDDEL(B1:B10) 93,52<br />
vA= VARIANS(A1:A10) 2,785444<br />
VB= VARIANS(B1:B10) 1,839556<br />
n1= 10<br />
n2= 10<br />
c= G3/G5+G4/G6 0,4625<br />
f= AFRUND.LOFT(G7^2/((G3/G5)^2/(G5-1)+(G4/G6)^2/(G6-1));1) 18<br />
Differens G2-G1 3,21<br />
Nedre grænse G2-G1-TINV(0,05;G8)*KVROD(G3/G5+G4/G6) 1,781219<br />
Øvre grænse G2-G1+TINV(0,05;G8)*KVROD(G3/G5+G4/G6) 4,638781<br />
Differensen er 3.21 og 95% konfidensinterval for differensen er [1.77 ; 4.64]<br />
Gemmes ovenstående excelfil, kan man nu hurtigt finde konfidensinterval for andre data.<br />
Eksempel 7.2. Sammenligning af 2 normalfordelte variable (oprindelige data ikke givet)<br />
Et luftfartsselskab A hævder, at dets fly til USA i gennemsnit afgår mere præcist end et konkurrerende<br />
luftfartsselskab.<br />
En forbrugergruppe undersøger denne påstand ved i en given periode at bestemme forsinkelserne<br />
for samtlige flyafgange til USA for hver af de to selskaber.<br />
Man fandt følgende tal:<br />
Luftfartsselskab Antal afgange x s<br />
A 100 55 minutter 30 minutter<br />
B 80 60 minutter 35 minutter<br />
Støtter undersøgelsen luftfartsselskab A's påstand?<br />
72<br />
1<br />
2<br />
1<br />
2
7.2 Sammenligning af 2 normalfordelte variable<br />
Løsning:<br />
XA = forsinkelsen i minutter for luftfartselskab A.<br />
XB =forsinkelsen i minutter for luftfartselskab B.<br />
XA og XB antages approksimativt normalfordelte med middelværdi og spredning henholdsvis µ A, σ A<br />
og µ B, σ B .<br />
Da vi ønsker at vise, at A er mere præcise end B, så haves:<br />
H : µ = µ H:<br />
µ < µ<br />
0<br />
A B A B<br />
TI89 Da antal forsøg er over 30 kunne man strengt taget nøjes med at lave en Z - test, i stedet<br />
for den normale t - test.<br />
t - test: APPS STAT/LIST F6, 4 2 - SampTtest ENTER<br />
I den fremkomne menu vælg STATS OK (da forsøgsresultaterne resultater ikke er kendt)<br />
µ < µ<br />
Menuen udfyldes bl.a. “alternative Hyp” 1 2 og poole til “N” OK<br />
P-værdi = 0.156<br />
Konklusion: Da P-værdi > 0.05 accepteres H 0 , dvs.<br />
vi kan ikke vise, at A er mere præcis end B.<br />
Excel har intet program til beregning af P-værdi, så man må benytte formlen fra oversigt 7<br />
x1 −x2 −d<br />
t =<br />
c<br />
2<br />
s1<br />
, hvor c = +<br />
n<br />
2<br />
s2<br />
P-værdi = P(T < t)<br />
n<br />
1<br />
2<br />
c<br />
=<br />
⎛ s ⎞ s<br />
⎜ ⎟<br />
⎝ n ⎠ n<br />
n − n<br />
+<br />
2<br />
2<br />
2<br />
2<br />
2 ⎛ ⎞<br />
1<br />
2<br />
⎜ ⎟<br />
1 ⎝ 2 ⎠<br />
1 1 2 −1<br />
A B C D E<br />
1<br />
2<br />
Eksempel 7.2<br />
3 XA =forsinkelsen for luftfartselskab A XA er normalfordelt med middelværdi :A<br />
4 XB =forsinkelsen for luftfartselskab A XB er normalfordelt med middelværdi :B<br />
5 H0: :A =B H: A < B<br />
6 Data Beregning<br />
7 nA = 100 a= B9^2/B7 9<br />
8 x-streg-A= 55 b= B12^2/B10 15,3125<br />
9 sA = 30 c= E7+E8 24,3125<br />
10 nB = 80 t= (B8-B11-B13)/KVROD(E9) -1,01404<br />
11 x-streg-B= 60 g= E9^2/(E7^2/(B7-1)+E8^2/(B10-1)) 156,1194<br />
12 sB = 35 f = RUND.OP(E11;0) 157<br />
13 d= 0 P-værdi= TFORDELING(ABS(E10);E12;1) 0,156062<br />
14 Konklusion: Da p -værdi > 0.05 accepteres H0, dvs.<br />
15 det kan ikke på dette grundlag vises, at A er mere præcis end B<br />
og frihedsgradstallet f er det nærmeste hele tal der er større end g<br />
73
7. Hypotesetest 2 variable<br />
Parvise observationer<br />
Parvise observationer (Matched pairs samples) kan anvendes, hvis det har mening at sammen<br />
ligne observationerne to og to (i par)<br />
Som et eksempel herpå vil vi igen betragte problemstillingen i eksempel 7.1, men nu antage, at<br />
forsøget er foretaget på en anden måde.<br />
Eksempel 7.3. Parvise observationer<br />
To produktionsmetoder M1 og M2 ønskes sammenlignet. Der udvælges tilfældigt 10 personer.<br />
Efter lodtrækning bliver 5 personer sat til først i 2 uger, at arbejde med produktionsmetode M1<br />
og derefter i de næste 2 uger med produktionsmetode M2.<br />
De øvrige 5 personer arbejder omvendt først med metode M2 og derefter med metode M1.<br />
Efter 2 ugers forløb, beregnede man for hver person det gennemsnitlige tidsforbrug pr. enhed.<br />
Da metode 1 er mere kostbar end metode 2, ønsker man kun at gå over til den, hvis tidsforbruget<br />
pr. enhed ved metode 1 er mindst 2 minutter mindre end ved metode 2.<br />
Man fik følgende resultater.<br />
Person nr. 1 2 3 4 5 6 7 8 9 10<br />
M 1 87.8 91.9 89.8 89.0 92.6 89.4 91.4 88.7 90.1 92.4<br />
M 2 92.4 94.6 93.0 94.0 92.4 92.9 96.4 92.1 92.8 93.4<br />
1) Undersøg på basis af disse resultater, om det på et signifikansniveau på 5% kan påvises at<br />
tidsforbruget ved metode M 1 er 2 minutter mindre end ved metode M 2<br />
2) Angiv endvidere et 95% konfidensinterval for differensen mellem de to middeludbytter.<br />
Forklaring på metode:<br />
Da en forsøgsperson kan være hurtig og en anden langsom (person 1 er således hurtigere end<br />
person 2) kan spredningen på M 1 og M 2 være så stor, at man intet kan vise.<br />
Hvis man i stedet tager differenserne M2 - M1 vil disse forskelle jo udjævnes, da person 1 jo er<br />
hurtig under arbejdet med begge metoder, mens person 2 er langsom ved begge.<br />
Person nr. 1 2 3 4 5 6 7 8 9 10<br />
M 1 87.8 91.9 89.8 89.0 92.6 89.4 91.4 88.7 90,1 92,4<br />
M 2 92.4 94.6 93.0 94.0 92.4 92.9 96.4 92.1 92,8 94,6<br />
D = M 2 - M 1 4.6 2.7 3.2 5 -0.2 3.5 5 3.4 2,7 2,2<br />
I stedet for at benytte metoden i eksempel 7.1 kan vi nu teste nulhypotesen<br />
H : D=<br />
2 mod H: D > 2 ved metoden i eksempel 6.2 (en variabel)<br />
0<br />
Løsning:<br />
1) D = forskellen i tidsforbruget ved metode M2 og metode M1 D antages approksimativt normalfordelt med middelværdi µ og spredning σ .<br />
H 0: D = 2 H: D > 2<br />
TI89:Data indtastes (de samme som i eksempel 6.1)<br />
APPS STAT/LIST data indtastes i list 1 og list 2 Cursor på list 3 list2 - list 1<br />
Enter F6 t-test menu udfyldes<br />
P-værdi = 0.0178<br />
74
7.2 Sammenligning af 2 normalfordelte variable<br />
Excel<br />
Tallene for metode 1 indtastes i A1 til A10<br />
Tallene for metode 2 indtastes i B1 til B10<br />
I C1 til C10 indsættes tallene fra A-kolonnen +2 (Skriv i C1 =A1+2 , og kopiere resultat ned)<br />
På værktøjslinien foroven: Tryk på f x Vælg kategorien “Statistisk” Vælg “TTEST”<br />
Tabel udfyldes: =TTEST(C1:C10;B1:B10;1;1)<br />
P-værdi= 0,017836<br />
Konklusion: Da P-værdi < 0.05 forkastes H 0, dvs.<br />
M1 er signifikant 2 minutter lavere end M2, dvs. man vil gå over til at benytte metode M1<br />
2) Konfidensinterval for differens:<br />
TI89:F6 t-interval menu udfyldes<br />
Differens = 2.31 KONFIDENSINTERVAL [2.10 ; 4.32 ]<br />
Excel: Danner en kolonne D1 til D10 med differenserne mellem A og B kolonner.<br />
På værktøjslinien foroven: Tryk på f x Vælg kategorien “Statistisk” Middel<br />
Excel: 2003: Funktioner 2007: Data<br />
derefter Dataanalyse Beskrivende statistik udfyld inputområde vælg konfidensniveau<br />
Resultat<br />
x streg 3,21<br />
Konfidensniveau(95,0%) 1,10896985<br />
nedre grænse 2,1011<br />
øvre grænse 4,3190<br />
75
7. Hypotesetest 2 variable<br />
7.3 OVERSIGT over centrale formler i kapitel 7<br />
Test af middelværdier µ og µ og konfidensinterval for differens µ − µ for 2 normalfordelte<br />
1 2<br />
1 2<br />
variable .<br />
X1 og X2 antages normalfordelte henholdsvis n( µ 1, σ1)<br />
og n( µ 2, σ2)<br />
.<br />
Givet 2 stikprøver af X1 og X2. Størrelse, gennemsnit og spredning henholdsvis n1, x1 , s1 og n2, x2 , s2. Signifikansniveau er Lad d være en given konstant.<br />
α<br />
Forudsætninger Alternativ<br />
hypotese H<br />
σ , σ ukendte<br />
1 2<br />
x1 − x2 − d<br />
t =<br />
c<br />
f er det nærmeste<br />
hele tal, som<br />
er større end g<br />
Forudsætninger<br />
s<br />
n<br />
2<br />
1<br />
s<br />
n<br />
2<br />
2<br />
Forkortelser: a =<br />
1<br />
, b =<br />
2<br />
c<br />
, c = a + b, g =<br />
a b<br />
n − n<br />
+<br />
2<br />
2<br />
2<br />
1 1 2 −1<br />
T er t - fordelt med frihedsgradstallet f.<br />
P - værdi Beregning H 0 forkastes<br />
µ 1 > µ 2 +d PT ( ≥ t)<br />
TI89: tCdf (, t ∞,<br />
f ) eller<br />
F6: 2-sampTtest,pooled, No<br />
Excel:TTEST(se eksempel 7.1)<br />
µ 1 < µ 2 +d PT ( t)<br />
≤ TI89: tCdf ( −∞,<br />
t, f ) eller<br />
µ 1 ≠ µ 2 +d PT ( ≥ t)<br />
for x1 > x2 + d<br />
PT ( ≤ t)<br />
for x < x + d<br />
1 2<br />
76<br />
F6: 2-sampTtest,pooled, No<br />
Excel:TTEST(se eksempel 7.1)<br />
som række 1<br />
som række 2<br />
100⋅ ( 1−<br />
α )% konfidensinterval for differens µ 1 − µ 2 :<br />
x − x − t ( f ) ⋅ c ≤ µ − µ ≤ x − x + t ( f ) ⋅ c<br />
1 2<br />
α 1 2 1 2 α<br />
1− 1− 2<br />
2<br />
TI89: F7, 2-SampTint Excel: Formel benyttes: se eksempel 7.1<br />
2 2<br />
σ1σ2 Forkortelser: x = x1 −x2 −d<br />
σ = + Y er normalfordelt<br />
n n<br />
Alternativ<br />
hypotese H<br />
1<br />
2<br />
P - værdi x2 + d<br />
PY ( ≤ x)<br />
for x < x + d<br />
1 2<br />
normCdf ( −∞ , x,<br />
µ , σ )<br />
eller F6: 2-sampZtest<br />
Excel: ZTEST<br />
som række 1<br />
som række 2<br />
100⋅( 1−α<br />
)% konfidensinterval for differens µ 1 − µ 2 :<br />
x −x −u ⋅σ ≤ µ −µ ≤ x − x + u ⋅σ<br />
1 2<br />
α 1 2 1 2 α<br />
1− 1− 2<br />
2<br />
TI89: F7, 2-SampZint Excel: Formel benyttes:<br />
P - værdi
OPGAVER<br />
77<br />
Opgaver til kapitel 7<br />
Opgave 7.1<br />
Det påstås at modstanden i en tråd af type A er større end modstanden i en tråd af type B. Til afklaring af denne<br />
påstand udtages tilfældigt 6 tråde af hver type og deres modstande måles.<br />
Følgende resultater fandtes:<br />
Modstand i tråd A (i ohm) 0.140 0.138 0.143 0.142 0.144 0.137<br />
Modstand i tråd B (i ohm) 0.135 0.140 0.142 0.136 0.138 0.140<br />
Hvilke konklusioner kan drages med hensyn til påstanden?<br />
Opgave 7.2<br />
Et levnedsmiddelfirma havde udviklet en diæt, som har lavt indhold af fedt, kulhydrater og kolesterol. Diæten er<br />
udviklet med henblik på patienter med hjerteproblemer, men firmaet ønsker nu at undersøge diætens virkning på folk<br />
med vægtproblemer.<br />
To stikprøver på hver 100 personer med vægtproblemer blev udtaget tilfældigt. Gruppe A fik den nye diæt, mens<br />
gruppe B fik den diæt, man normalt gav. For hver person blev registreret størrelsen af vægttabet i en 3 ugers periode.<br />
Man fandt følgende værdier for gennemsnit og spredning:<br />
Gruppe A: x A = 931 . kg , sA = 467 .<br />
Gruppe B: xB = 740 . kg , sB = 404 . .<br />
α = 5%<br />
1) Undersøg om vægttabet for gruppe A er signifikant større end for gruppe B. Signifikansniveau .<br />
2) I tilfælde af signifikans beregn da et 95% konfidensinterval for differensen mellem de to gruppers middelværdier.<br />
Opgave 7.3<br />
I et laboratorium foretoges 15 uafhængige bestemmelser af furfurols kogepunkt, idet 8 af bestemmelserne foretoges<br />
af én kemiingeniør, de resterende bestemmelser af en anden kemiingeniør. Resultaterne var ( 0 C ) :<br />
1. ingeniør 162.2 161.3 161.9 161.2 163.4 162.4 162.5 162.0<br />
2. ingeniør 163.3 162.6 161.8 163.8 163.0 163.2 164.1<br />
Undersøg, om de to ingeniørers resultater i middel er ens.<br />
Opgave 7.4<br />
På et laboratorium undersøgtes filtreringstiden for en opløsning af et bestemt gødningsstof ved benyttelsen af to<br />
forskellige filtertyper (F1) og (F2). Følgende stikprøveværdier observeredes:<br />
(F1) 8 10 12 13 13 9 14 10<br />
(F2) 9 10 10 7 9 11 7<br />
Det antages, at filtreringstiderne X1 og X2 er normalfordelte n( µ , σ ) og<br />
Test om det kan antages, at filtreringstiderne i middel er forskellige.<br />
1 1 n( µ , σ )<br />
Opgave 7.5<br />
En produktion af plastikvarer må omlægges på grund af bestemmelser i en ny miljølov.<br />
Ved den fremtidige produktion kan inden for miljølovens rammer vælges mellem 2 pro- duktionsmetoder I og II.<br />
Metode I er den dyreste, og fabrikanten har regnet ud, at det (kun) kan betale sig at benytte metode I, såfremt den<br />
giver et middeludbytte, som er mindst 10 måleenheder (udbytteprocenter) større end udbyttet ved benyttelse af metode<br />
II.<br />
Ved et fuldstændigt randomiseret forsøg fandtes følgende måleresultater:<br />
Metode I 35.2 38.1 37.6 37.6 34.9 37.9 36.5 40.0 36.2 37.4 37.2 37.9<br />
Metode II 26.2 22.2 24.3 24.5 22.0 27.6 23.8 22.8 23.4 20.8<br />
Fabrikanten valgte herefter at benytte metode I.<br />
a) Foretag en undersøgelse af, om valget var statistisk velmotiveret.<br />
b) Hvis forslaget er velmotiveret skal der opstilles et 95% - konfidensinterval for differensen mellem middeludbytterne<br />
ved benyttelse af metoderne l og II.<br />
2 2
7. Hypotesetest 2 variable<br />
Opgave 7.6<br />
To sjællandske fabrikker producerer begge en bestemt type kvægfoder, for hvilken det ønskes, at proteinindholdet i<br />
færdigvaren skal være 26%. På de 2 fabrikkers driftslaboratorier foretoges følgende målinger af proteinindholdet i en<br />
uges produktion:<br />
Fabrik 1 27.3 26.1 26.9 24.8 26.2 25.7 26.5<br />
Fabrik 2 26.0 26.7 25.6 26.1 26.2 25.5 26.0 26.1 26.2 25.9<br />
Foretag en statistisk vurdering af, om de to produktioner kan antages i middel at give kvægfoder med samme proteinindhold.<br />
Opgave 7.7<br />
Måling af intelligenskvotient på 16 tilfældigt udvalgte studerende ved en diplom-retning (med mere end 200 stu-<br />
2<br />
derende) viste et gennemsnit på = 107 og en empirisk varians på =100, medens en tilsvarende måling på 14<br />
x1 s1 tilfældigt udvalgte studerende fra en anden diplomretning viste et gennemsnit på x2 =112 og en empirisk varians på<br />
2<br />
s2 = 64.<br />
Tyder disse tal på en forskel på studentermaterialet på de to retninger?<br />
Opgave 7.8<br />
Et bestemt medikament ønskes testet for dets effekt på blodtrykket. 12 mænd fik deres blodtryk målt før og efter<br />
indtagelse af medikamentet. Resultaterne var:<br />
mand nr 1 2 3 4 5 6 7 8 9 10 11 12<br />
Før 120 124 130 118 140 128 140 135 126 130 126 127<br />
Efter 128 131 131 127 132 125 141 137 118 132 129 135<br />
Udfør en testning af, om disse tal tyder på, at medikamentet påvirker blodtrykket.<br />
Opgave 7.9<br />
Et diætprodukt påstår i en reklame, at brug af produktet i en måned vil resultere i et vægttab på 3 kg.<br />
En forbrugerorganisation ønsker at teste denne påstand, dvs. om vægttabet er netop 3 kg<br />
8 personer bruger produktet i en måned, og resultatet fremgår af nedenstående tabel:<br />
Person nr 1 2 3 4 5 6 7 8<br />
Startvægt 81 101 98 99 78 71 75 93<br />
Slutvægt 79 95 95 97 73 69 71 89<br />
1) Undersøg på grundlag af disse tal, om det på basis af disse tal på et signifikansniveau på 5% kan vises, at reklamens<br />
påstand er fejlagtig, dvs. om vægttabet afviger signifikant fra 3 kg?<br />
2) Opstil et 95% tosidet konfidensinterval for middelværdien af vægttabet, og giv på grundlag heraf en vurdering af<br />
virkningen af diætproduktet.<br />
78
79<br />
Opgaver til kapitel 7<br />
Opgave 7.10 (parvise observationer).<br />
En producent af malervarer har laboratorieresultater, der tyder på, at en ny lak A, har en større slidstyrke end den<br />
sædvanlige lak B. Han ønsker en afprøvning i praksis og aftaler med ejerne af 6 bygninger med mange trapper, at han<br />
må lakere deres trapper. Efter 3 måneders forløb måles graden af slid (i %) i hver bygning.<br />
1) Angiv hvorledes du ville foretage forsøget.<br />
2) De målte værdier af slid efter valg af plan var<br />
Bygning nr 1 2 3 4 5 6<br />
Ny lak 20.3 25.1 21.8 19.6 18.9 23.5<br />
Sædvanlig lak 19.5 28.4 21.6 22.0 20.9 25.8<br />
Undersøg om observationerne leverer et eksperimentelt bevis for, at den nye lak er mere slidstærk end den sædvanlige<br />
lak.
8. Regneregler for sandsynlighed, Kombinatorik<br />
8. REGNEREGLER FOR SANDSYNLIGHED,<br />
KOMBINATORIK<br />
8.1 REGNEREGLER FOR SANDSYNLIGHEDER<br />
Vi har tidligere omtalt sandsynlighed.<br />
I dette kapitel omtales nogle af de grundlæggende definitioner og begreber<br />
Det følgende eksempel blive benyttet til illustration af definitioner og begreber.<br />
Eksempel 8.1. Gennemgående eksempel.<br />
To skytter Anders og Brian skyder hver ét skud mod en skydeskive. Sandsynligheden for at<br />
Anders rammer skiven er 0.80 mens Brian har en træfsandsynlighed på 0,60.<br />
Et eksperiment består i at de hver skyder et skud.<br />
Lad A være hændelsen at Anders rammer skiven og lad B være sandsynligheden for at Brian<br />
rammer skiven.<br />
Vi har derfor, at P(A) = 0.80 og P(B) = 0.60.<br />
Lad os ved at sætte en streg over A forstå “ikke A”.<br />
Generelt gælder P( A)<br />
= 1 - P ( A )<br />
I eksempel 8.1 er A hændelsen at Anders ikke rammer skiven.<br />
Vi har derfor, at P( A ) = 1 - P(A) = 1 - 0.8 = 0.20<br />
Fællesmængden til A og B benævnes A ∩ B og er<br />
mængden af alle udfald i udfaldsrummet U, der tilhører<br />
både A og B (Den skraverede mængde i figur 8.1 ).<br />
Eksempelvis er A ∩ B i eksempel 8.1 hændelsen, at<br />
både Anders og Brian rammer skiven<br />
Foreningsmængden af A og B benævnes A∪B og<br />
er mængden af alle udfald i udfaldsrummet U, der<br />
enten tilhører A eller B eventuelt dem begge (den<br />
skraverede mængde på figur 8.2 )<br />
Eksempelvis er A∪B i eksempel 6.1 den hændelse,<br />
at enten rammer Anders eller også rammer Brian<br />
skiven eventuelt gør de det begge.<br />
Man kunne også udtrykke det ved at mindst en af dem<br />
rammer skiven.<br />
80<br />
Fig 8.1. Fællesmængde<br />
Fig. 8.2 Foreningsmængde
Der gælder nu følgende sætninger:<br />
Additionssætning: P( A∪ B) = P( A) + P( B) − P( A∩B). Sætningen fremgår umiddelbart ved at betragte arealerne i figur 8.3.<br />
P( AUB) PA ( )<br />
81<br />
6.2 Regneregler for sandsynligheder<br />
Statistisk uafhængighed.<br />
To hændelser A og B siges at være statistisk uafhængige, såfremt sandsynligheden for, at den<br />
ene hændelse indtræffer, ikke afhænger af, om den anden hændelse indtræffer.<br />
I eksempel 8.1 må man eksempelvis antage, at om Anders rammer skiven har ingen indflydelse<br />
på om Brian rammer, så her må man antage A og B er uafhængige.<br />
Et andet eksempel er kast med en terning. Her vil sandsynligheden for at få en sekser i andet kast<br />
være uafhængigt af udfaldet i første kast<br />
Der gælder følgende sætning:<br />
Produktsætning for uafhængige hændelser:<br />
Eksempel 8.2 (eksempel 8.1 fortsat)<br />
Lad A være hændelsen, at Anders rammer skiven, og lad B være hændelsen, at Brian rammer<br />
skiven. Det er givet, at P(A) = 0.80 og P(B) = 0.60.<br />
Find sandsynligheden for<br />
a) At både Anders og Brian rammer skiven<br />
b) At enten Anders eller Brian (evt. begge) rammer skiven, dvs. mindst en af dem rammer<br />
skiven.<br />
c) At hverken Anders elle Brian rammer skiven<br />
Løsning:<br />
a) Da hændelserne antages at være uafhængige gælder ifølge produktsætningen<br />
P( A∩ B)<br />
= 08 . ⋅ 06 . = 048 .<br />
PB<br />
Fig.8.3 Additionssætning<br />
For to uafhængige hændelser gælder P( A∩ B) = P( A) ⋅<br />
P( B)<br />
( ) PA ( I B)<br />
b) Ifølge additionssætningen gælder P( A∪ B)<br />
= 06 . + 08 . − 048 . = 092 .
8. Regneregler for sandsynlighed, Kombinatorik<br />
c) P( A∩ B) = P( A) ⋅ P( B)<br />
= ( 1−08 . )( 1− 06 . ) = 008 .<br />
Produktsætning og additionssætning kan generaliseres til flere hændelser end 2.<br />
For tre hændelser A, B og C gælder således<br />
P( A∪B∪ C) = P( A) + P( B) + P( C) − P( A∩B) − P( A∩C) − P( B∩C) I tilfælde af at hændelserne A, B og C er uafhængige gælder således:<br />
P( A∩B∩ C) = P( A) ⋅P( B) ⋅P(<br />
C)<br />
.<br />
Er hændelserne A og B ikke uafhængige, kan man som beskrevet i afsnit 11.3 udlede en mere<br />
generel produktsætning<br />
8.2. Betinget sandsynlighed<br />
Er hændelserne A og B ikke uafhængige vil PA ( ∩ B) ≠ PA ( ) ⋅ PB ( )<br />
Eksempel 8.3. Ikke uafhængige hændelser<br />
En fabrik har erfaring for, at den daglige produktion af glasfigurer indeholder 10 % misfarvede, 20% har ridser, og<br />
1 % af produktionen er både ridsede og misfarvede.<br />
Et eksperiment består i tilfældigt at udtage en glasfigur af produktionen. Lad A være hændelsen at få en misfarvet<br />
og lad B være hændelsen at få en ridset.<br />
Her er P( A) ⋅ P( B) = 01 . ⋅ 02 . = 002 . ≠ P( A∩ B)<br />
= 001 . .<br />
For at få en mere generel regel indføres PBA ( ) som kaldes sandsynligheden for, at B indtræffer, når A er indtruffet<br />
(den af A betingede sandsynlighed for B).<br />
For at forklare den følgende definition, vil vi simplificere eksempel<br />
8.3, idet vi antager, at den daglige produktion er 100 glasfigurer.<br />
I så fald er der 10 misfarvede figurer, 20 ridsede figurer, og<br />
1 figur der er både misfarvet og ridset.<br />
Hvis vi begrænser vort udfaldsrum til A, så er<br />
1<br />
1 P( A B)<br />
PBA ( ) = =<br />
100 ∩<br />
= .<br />
10 10 P( A)<br />
100<br />
Denne beregning begrunder rimeligheden i følgende definition:<br />
82<br />
Fig. 8.4 Taleksempel<br />
Den af A betingede sandsynlighed for B PBA ( ) (eller sandsynligheden for, at B indtræffer, når A er indtruffet )<br />
PA ( ∩ B)<br />
defineres ved PBA ( ) = .<br />
P( A)<br />
Ved multiplikation fås Produktsætningen: P( A∩ B) = P( A) ⋅P(<br />
B A)<br />
.<br />
Benyttes produktsætningen på eksempel 8.1 fås P( A∩ B) = P( A) ⋅ P( B A)<br />
= 01 . ⋅ 01 . = 001<br />
. .
83<br />
8.2 Betinget sandsynlighed<br />
Eksempel 8.4: Betinget sandsynlighed.<br />
En beholder indeholder 3 røde og 3 hvide kugler. Vi udtrækker successivt 2 kugler fra urnen.<br />
Vi betragter følgende 2 hændelser:<br />
A: Den først udtrukne kugle er rød. B: Den anden udtrukne kugle er rød.<br />
Beregn P( A∩B) hvis<br />
1) kugleudtrækningen foregår, ved at den først udtrukne kugle lægges tilbage før den anden udtrækkes.<br />
2) kugleudtrækningen foregår, ved at den først udtrukne kugle ikke lægges tilbage før den anden udtrækkes.<br />
Løsning<br />
1) Her er PBA ( )= og derfor ifølge produktsætningen<br />
3<br />
P( A∩ B) = P( A) ⋅ P( B A)<br />
=<br />
6<br />
1<br />
4<br />
2) Her er PBA ( )= og derfor<br />
2<br />
3 2 1<br />
5 P( A∩ B)<br />
= ⋅ = 6 5 5<br />
Bayes sætning<br />
For to hændelser A og B for hvilken P(A) > 0 gælder<br />
Bevis:<br />
P( A∩B) PB ( ∩ A)<br />
PB ( ) ⋅ PAB ( )<br />
Af definitionen på betinget sandsynlighed og produktsætningen fås PBA ( ) = = =<br />
P( A)<br />
P( A)<br />
P( A)<br />
Bayes sætning gør, at det er let at omskrive fra den ene betingende sandsynlighed til den anden.<br />
Dette er tilfældet, hvis den ene af de to betingede sandsynligheder PBA ( ) og PAB ( ) er meget lettere at<br />
beregne end den anden.<br />
PB ( ) ⋅<br />
PAB ( )<br />
Bayes sætning: PBA ( ) =<br />
P( A)<br />
Eksempel 8.5 (Bayes sætning)<br />
I en officeruddannelse kan man vælge mellem en “teknisk” linie og en “operativ”linie. På en bestemt årgang har 60<br />
% valgt den operative linie og af disse er 20% kvinder. På den tekniske linie er 10% kvinder.<br />
Ved lodtrækning vælges en elev.<br />
a) Find sandsynligheden for, at denne er en kvinde.<br />
Ved ovenstående lodtrækning viste det sig at eleven var en kvinde.<br />
b) Hvad er sandsynligheden for, at hun kommer fra den tekniske linie.<br />
Løsning:<br />
Vi definerer følgende hændelser:<br />
T: Den udtrukne er tekniker<br />
K: Den udtrukne er en kvinde.<br />
a) PK ( ) = PT ( ∩ K) + PO ( ∩ K) = PKT ( ) ⋅ PT ( ) + PKO ( ) ⋅ PO ( ) = 01 . ⋅ 04 . + 02 . ⋅ 06 . = 016 . = 16%<br />
PKT ( ) ⋅ PT ( ) 01 . ⋅04<br />
. 1<br />
b) Af Bayes sætning fås: PTK ( ) =<br />
= = = 25%<br />
PK ( ) 016 . 4<br />
En anden metode ville det være, at antage, at der bliver optaget 100 elever.<br />
Vi har så følgende skema<br />
Kvinder I alt<br />
Operativ 12 60<br />
Teknisk 4 40<br />
16<br />
4<br />
Heraf fås umiddelbart PK ( ) = = 16% og PTK ( ) = = 25%<br />
100<br />
16
8. Regneregler for sandsynlighed, Kombinatorik<br />
8.3. Kombinatorik<br />
8.3.1. Indledning:<br />
Såfremt et udfaldsrum U indeholder n udfald som alle er lige sandsynlige, vil sandsynligheden<br />
for hvert udfald være ( ) = . 1<br />
Pu n<br />
En hændelse A som indeholder a udfald vil da have sandsynligheden a P( A) = .<br />
n<br />
Dette udtrykkes ofte kort ved at sige, at sandsynligheden for A er antal gunstige udfald i A<br />
divideret med det totale antal udfald i udfaldsrummet.<br />
I sådanne tilfælde, bliver problemet derfor, hvorledes man let kan optælle antal udfald. Dette kan<br />
ofte gøres ved benyttelse af kombinatorik.<br />
8.3.2. Multiplikationsprincippet<br />
Multiplikationsprincippet: Lad et valg bestå af n delvalg, hvoraf det første valg<br />
har valgmuligheder, det næste valg har valgmuligheder, . . . og det n’te valg har<br />
r n<br />
r 1<br />
valgmuligheder.<br />
Det samlede antal valgmuligheder er da r1⋅r2⋅.... ⋅rn<br />
Multiplikationsprincippet illustreres ved følgende eksempel.<br />
Eksempel 8.6. Multiplikationsprincippet<br />
En mand ejer 2 forskellige jakker, 3 slips og 4 forskellige fabrikater skjorter.<br />
På hvor mange forskellige måder kan han sammensætte sin påklædning af jakke, slips og skjorte.<br />
Løsning:<br />
1) Valg af jakke giver 2 valgmuligheder<br />
2) Valg af slips giver 3 valgmuligheder<br />
3) Valg af skjorte giver 4 valgmuligheder<br />
Ifølge multiplikationsprincippet giver det i alt 234 ⋅ ⋅ = 24muligheder<br />
Man kunne illustrere løsningen ved følgende “forgreningsgraf”<br />
r 2<br />
84
Eksempel 8.7 Fakultet<br />
På hvor mange måder kan 5 personer opstilles i en kø (i rækkefølge)<br />
Løsning:<br />
Pladserne i køen nummereres 1,2,3,4,5.<br />
Plads nr. 1 i køen besættes 5 valgmuligheder<br />
Plads nr. 2 i køen besættes 4 valgmuligheder<br />
Plads nr. 3 i køen besættes 3 valgmuligheder<br />
Plads nr. 4 i køen besættes 2 valgmuligheder<br />
Plads nr. 5 i køen besættes 1 valgmulighed<br />
I alt 5⋅4⋅3⋅2⋅ 1 = 120 forskellige rækkefølger.<br />
Ved n fakultet (n udråbstegn) forstås n! = n⋅( n−1) ⋅ ( n−2)<br />
⋅ ... ⋅ 2⋅1 Endvidere defineres 0! = 1.<br />
TI89: 5 MATH Probability ! 5! = 120<br />
Excel: f x Math/trig FAKULTET(5) 120<br />
85<br />
8.4 Kombinatorik<br />
8.3.3 Ordnet stikprøveudtagelse<br />
Lad os tænke os vi har en beholder indeholdende 9 kugler med numrene 1, 2, 3, ..., 9 .<br />
Vi udtager nu en stikprøve på 4 kugler. Det kan ske<br />
1) uden tilbagelægning: En kugle er taget op, nummeret noteres, men den lægges ikke tilbage inden man tager en<br />
ny kugle op.<br />
2) med tilbagelægning: En kugle tages op, nummeret noteres, og derefter lægges kuglen tilbage inden man tager en<br />
ny kugle op. Man kan følgelig få den samme kugle op flere gange.<br />
Ved en ordnet stikprøveudtagelse lægges vægt på den rækkefølge hvori kuglerne udtages, .<br />
dvs. der er forskel på 2,1,3,5 og 3,1,2,5<br />
a) Uden tilbagelægning<br />
Eksempel 8.8. Ordnet uden tilbagelægning<br />
I en forening skal der blandt 10 kandidater vælges en bestyrelse<br />
På hvor mange forskellige måder kan man sammensætte denne bestyrelse, hvis<br />
1) Bestyrelsen består af en formand og en kasserer<br />
2 Bestyrelsen består af en formand, en næstformand, en kasserer og en sekretær.<br />
Løsning:<br />
1) En formand vælges blandt 10 kandidater 10 valgmuligheder<br />
En Kasserer vælges blandt de resterende 9 kandidater 9 valgmuligheder<br />
Da der for hvert valg af formand er 9 muligheder for kasserer, følger af multiplikationsprincippet, at det totale<br />
antal forskellige bestyrelser er 10⋅ 9 = 90 .<br />
2) Analogt fås ifølge multiplikationsprincippet at antal forskellige bestyrelser er 10987 ⋅ ⋅ ⋅ = 5040<br />
TI89: MATH Probability nPr(10,4) . Resultat: = 5040<br />
Excel: f x Statistisk PERMUT(10;4) 5040<br />
Eksempel 8.8 begrunder følgende definition<br />
Permutationer. Antal måder (rækkefølger eller “permutationer”) som m elementer kan udtages (ordnet og<br />
uden tilbagelægning) ud af n elementer er Pnm ( , ) = n⋅( n−1) ⋅( n−2)...( ⋅ ⋅ n− m+<br />
1)
8. Regneregler for sandsynlighed, Kombinatorik<br />
b) Med tilbagelægning<br />
Eksempel 8.9. Ordnet, med tilbagelægning<br />
I en forening skal 4 tillidshverv fordeles mellem 10 personer. En person kan godt have flere tillidshverv. På<br />
hvor mange forskellige måder kan disse hverv fordeles.?<br />
Løsning:<br />
Tillidshverv 1 placeres. 10 valgmuligheder<br />
Tillidshverv 2 placeres 10 valgmuligheder<br />
Tillidshverv 3 placeres 10 valgmuligheder<br />
Tillidshverv 4 placeres 10 valgmuligheder<br />
I alt (ifølge multiplikationsprincippet) 10 10 10 10 10 4<br />
⋅ ⋅ ⋅ =<br />
8.3.4. Uordnet stikprøveudtagelse<br />
Eksempel 8.10 Uordnet uden tilbagelægning<br />
En beholder indeholdende 5 kugler med numrene k1, k2, k3, k4, k5<br />
Vi udtager nu en stikprøve på 3 kugler uden tilbagelægning. Rækkefølgen kuglen tages op er<br />
uden betydning, dvs. der er ikke forskel på eksempelvis k1, k4, k2og<br />
k4, k1, k2<br />
Hvor mange forskellige stikprøver kan forekomme?<br />
Løsning:<br />
Antallet er ikke flere end man kan foretage en simpel optælling:<br />
k , k , k , k , k , k k , k , k k , k , k k , k , k k , k , k k , k , k k , k , k k3, k , k<br />
{ } { }{ }{ }{ }{ }{ }{ }{ }<br />
1 2 3 1 2 4 1 2 5 1 3 4 1 3 5 2 3 4 2 3 5 2 4 5 4 5<br />
Antal stikprøver = 10<br />
Det er klart, at ren optælling er uoverkommeligt, hvis mængden er stor.<br />
Definition af kombination<br />
Lad M være en mængde med n elementer.<br />
En kombination af r elementer fra M er et udvalg af r elementer udtaget af M uden at tage<br />
hensyn til rækkefølgen af elementer<br />
⎛n<br />
Antallet af kombinationer med r elementer betegnes K(n,r) eller ⎜ (n over r).<br />
⎝r<br />
⎞<br />
⎟<br />
⎠<br />
Sætning 8.1 (Antal kombinationer).<br />
Antal kombinationer med r elementer fra en mængde på n elementer er Knr<br />
86<br />
n!<br />
( , ) =<br />
r!( ⋅ n−r)! Bevis: Beviset knyttes for enkelheds skyld til et taleksempel, som let kan generaliseres.<br />
Lad os antage, vi på tilfældig måde udtager 3 kugler af en kasse, der indeholder 5 kugler med numrene<br />
k1, k2, k3, k4, k5.<br />
5!<br />
Vi skal nu vise, at k( 53 ,) =<br />
3! ⋅2!<br />
Lad os først gå ud fra, at rækkefølgen hvori kuglerne trækkes er af betydning, Der er altså eksempelvis forskel på k1, k3, k4<br />
og k , k , k . Dette kan gøres på P(5,3) = 5⋅4⋅3 måder.<br />
3 1 4
87<br />
8.4 Kombinatorik<br />
Hvis de 3 kugler udtages, så rækkefølgen ikke spiller en rolle, har vi vedtaget, det kan gøres på K(5,3) måder. Lad<br />
en af disse måder være k1, k3, k4.<br />
Disse 3 elementer kan ordnes i rækkefølge på 3! = 3⋅2⋅1måder. P(,)<br />
53<br />
543 54321 5!<br />
Vi har følgelig, at P(,) 53 = K(,) 53 ⋅3! ⇔ K(,)<br />
53 = ⇔ K(,)<br />
53 =<br />
3!<br />
3!<br />
3! 2!<br />
3! 2!<br />
⋅ ⋅ ⋅ ⋅ ⋅ ⋅<br />
= =<br />
⋅ ⋅<br />
Eksempel 8.11. Antal kombinationer<br />
I en forening skal der blandt 10 kandidater vælges 4 personer til en bestyrelse<br />
På hvor mange forskellige måder kan man sammensætte denne bestyrelse?<br />
Løsning:<br />
Antal måder man kan sammensætte bestyrelsen er<br />
10!<br />
10987 ⋅ ⋅ ⋅<br />
K(10,4) = = = 10⋅3⋅ 7 = 210 måder<br />
4! ⋅6!<br />
4!<br />
TI89: MATH Probability nCr(10,4) . Resultat: = 210<br />
Excel: f x Matematik og trig KOMBIN(10;4) 210
8. Regneregler for sandsynlighed, Kombinatorik<br />
OPGAVER<br />
Opgave 8.1<br />
I en mindre by viser en undersøgelse, at 60% af alle husstande holder en lokal avis, mens 30%<br />
holder en landsdækkende avis. Endvidere holder 10% af husstandene begge aviser.<br />
Lad en husstand være tilfældig udvalgt, og lad A være den hændelse, at husstanden holder en<br />
lokal avis, og B den hændelse, at husstanden holder en landsdækkende avis.<br />
Beregn sandsynlighederne for følgende hændelser.<br />
C: Husstanden holder begge aviser .<br />
D: Husstanden holder kun den lokale avis.<br />
E: Husstanden holder mindst én af aviserne.<br />
F: Husstanden holder ingen avis<br />
G: Husstanden holder netop én avis.<br />
Opgave 8.2<br />
1) I figur 1 er vist et elektrisk apparat, som kun fungerer, hvis enten alle komponenter 1a, 1b og<br />
1c i den øverste ledning eller alle komponenter 2a, 2b og 2c i den nederste ledning fungerer.<br />
Sandsynligheden for at hver komponent fungerer er vist på tegningen, og det antages, at<br />
sandsynligheden for at en komponent fungerer er uafhængig af om de øvrige komponenter<br />
fungerer.<br />
88<br />
1) Hvad er sandsynligheden for at apparatet<br />
i figur 1 fungerer.<br />
2) I figur 2 er vist et andet elektrisk apparat,<br />
som tilsvarende kun fungerer, hvis alle de<br />
tre kredsløb I, II og III fungerer, og det er<br />
kun tilfældet hvis enten den øverste eller<br />
den nederste komponent fungerer.<br />
Hvad er sandsynligheden for at apparatet<br />
i figur 2 fungerer.
89<br />
Opgaver til kapitel 8<br />
Opgave 8.3<br />
Tre skytter skyder hver ét skud mod en skydeskive. De har træfsandsynligheder 0.75, 0.50 og<br />
0.30.<br />
Beregn sandsynligheden for<br />
1) ingen træffere, 2) én træffer, 3) to træffere, 4) tre træffere.<br />
Opgave 8.4<br />
En “terning” har form som et regulært polyeder med 20 sideflader. På 4 sideflader er der skrevet<br />
1, på 8 sideflader er der skrevet 6 mens der er skrevet 2, 3 , 4 og 5 på hver 2 sideflader.<br />
Find sandsynligheden for i tre kast med denne terning at få<br />
1) tre seksere<br />
2) mindst én sekser<br />
3) enten tre seksere eller tre enere<br />
Opgave 8.5<br />
Fire projektgrupper på en virksomhed antages at have sandsynlighederne 0.6, 0.7, 0.8 og 0.9 for at få succes med<br />
deres projekt. Grupperne antages at arbejde uafhængigt af hinanden. Find sandsynligheden for, at<br />
a) alle grupper får succes,<br />
b) ingen grupper får succes,<br />
c) mindst 1 gruppe får succes,<br />
d) i alt netop 1 gruppe får succes,<br />
e) i alt netop 3 grupper får succes,<br />
f) i alt netop 2 grupper får succes.<br />
Opgave 8.6<br />
En klasse med 21 elever skal under en øvelse fordeles på 5 grupper. 4 af grupperne skal være på 4 elever, og 1 gruppe<br />
skal være på 5 elever.<br />
På hvor mange måder kan fordelingen af eleverne på de 5 grupper foregå?<br />
Opgave 8.7<br />
Af en forsamling på 8 kvinder og 4 mænd skal udtages en arbejdsgruppe på 5 personer.<br />
a) Gør rede for, at gruppen kan udvælges på 448 forskellige måder, når det forlanges, at den skal bestå af højst 3<br />
kvinder og højst 3 mænd.<br />
b) Beregn antallet af måder, hvorpå gruppen kan udvælges, når det forlanges, at de 5 personer ikke alle må være af<br />
samme køn.<br />
Opgave 8.8<br />
a) Bestem det antal måder, hvorpå bogstaverne A, B og C kan stilles rækkefølge.<br />
b) Samme opgave for A, B, C og D.<br />
Opgave 8.9.<br />
På et spisekort er opført 6 forretter, 10 hovedretter og 4 desserter.<br />
1) Hvor mange forskellige middage bestående enten af forret og hovedret eller af hovedret og dessert kan man<br />
sammensætte.<br />
2) Hvor mange forskellige middage bestående af en forret, en hovedret og en dessert kan man sammensætte.<br />
Opgave 8.10<br />
Bestem antallet af 5-cifrede tal, der kan skrives med to l-taller, et 2- tal og to 3-taller.
8. Regneregler for sandsynlighed, Kombinatorik<br />
Opgave 8.11<br />
En virksomhed fremstiller en bestemt slags apparater. Hvert apparat er sammensat af 5 komponenter. Heraf er 3<br />
tilfældigt udvalgt blandt komponenter af typen a og 2 blandt komponenter af typen b. Det vides, at 10% af akomponenterne<br />
er defekte og 20% af b-komponenterne er defekte. Et apparat fungerer hvis og kun hvis det ikke<br />
indeholder nogen defekt komponent.<br />
Der udtages på tilfældig måde et apparat fra produktionen. Lad os betragte hændelserne:<br />
A: Det udtagne apparat indeholder mindst 1 defekt a-komponent.<br />
B: Det udtagne apparat indeholder mindst 1 defekt b-komponent.<br />
1) Find P( A), P( B)<br />
og P( A∩B) .<br />
2) Find sandsynligheden for, at et apparat, der på tilfældig måde udtages af produktionen ikke fungerer.<br />
3) Et apparat udtages på tilfældig måde fra produktionen og det konstateres ved afprøvning at det ikke fungerer. Find<br />
sandsynligheden for, at apparatet ikke indeholder nogen defekt a-komponent.<br />
Opgave 8.12<br />
En test består af 40 spørgsmål, der alle skal besvares med ,'ja'. 'nej' og 'ved ikke'. På hvor mange forskellige måder<br />
kan prøven besvares?<br />
Opgave 8.13<br />
I en virksomhed skal der installeres et kaldesystem. I hvert lokale<br />
opsættes et batteri af n lamper, og hver af de ansatte har sin bestemte<br />
lampekombination.<br />
1) Hvis n = 5, hvor mange ansatte kan da have deres eget kaldesystem<br />
(se figuren)<br />
2) Hvis virksomheden har 500 ansatte, hvor stor skal n så være.<br />
Opgave 8.14<br />
Normale personbilers indregistreringsnumre består af to bogstaver og et nummer mellem 20000 og 59999 .<br />
Lad os antage, at man er nået til numre der begynder med UV. Et eksempel på en nummerplade er da UV 54755<br />
Hvad er sandsynligheden for, at en nyindregistreret bil får et registreringsnummer med lutter forskellige cifre, når<br />
vi antager, at alle cifre har samme sandsynlighed?<br />
Opgave 8.15<br />
Hvor mange forskellige telefonnumre på 8 cifre kan man danne, når første ciffer ikke må være nul?<br />
90
91<br />
9.2 Hypergeometrisk fordeling<br />
9. VIGTIGE DISKRETE FORDELINGER<br />
9.1 INDLEDNING<br />
Vi vil i dette kapitel betragte diskrete stokastiske variable, hvis værdier er hele tal.<br />
Vi vil især behandle de diskrete fordelinger:<br />
“Den hypergeometriske fordeling”, “Binomialfordelingen” og “Poissonfordelingen”<br />
9.2 HYPERGEOMETRISK FORDELING<br />
Den “hypergeometriske fordeling”, finder bl.a. anvendelse ved kvalitetskontrol af varepartier<br />
(jævnfør eksempel 9.2), ved markedsundersøgelser, hvor man uden tilbagelægning udtager en<br />
repræsentativ stikprøve på eksempelvis 500 personer<br />
I det følgende eksempel “udledes” formlen for den hypergeometriske fordeling.<br />
Eksempel 9.1. Hypergeometrisk fordeling<br />
I en forening skal der blandt 5 kvindelige og 8 mandlige kandidater vælges en bestyrelse på 4<br />
personer. Find sandsynligheden for, at der er netop 1 kvinde i bestyrelsen..<br />
Løsning:<br />
X = antal kvinder i bestyrelsen<br />
At der skal være netop 1 kvinde i bestyrelsen forudsætter, at vi udtager 1 kvinde ud af de 5<br />
kvinder og 3 mænd ud af de 8 mænd.<br />
At udtage 1 kvinde ud af 5 kvinder kan gøres på K(5,1) måder<br />
At udtage 3 mænd ud af 8 mænd kan gøres på K(8,3) måder.<br />
Antal gunstige udfald er ifølge multiplikationsprincippet K(5,1) ⋅K(8,3)<br />
Det totale antal udfald fås ved at udtage 4 personer ud af de 13 kandidater<br />
Dette kan gøres på K(13,4) måder.<br />
K(,) 51 ⋅ K(,)<br />
83<br />
P( X = 1)<br />
=<br />
K(<br />
13, 4)<br />
TI-89: Vælg MATH\Probability\nCr nCr(5,1) ⋅ nCr(8,3)/nCr(13,4) =0.3916<br />
Excel: Vælg f x Matematik og trig KOMBIN(5;1)*KOMBIN(8;3)/KOMBIN(13;4) =0,391608<br />
Karakteristisk for en hypergeometrisk fordeling er, at elementerne i udfaldsrummet (kugler i en<br />
beholder) kan opdeles i to grupper.<br />
En opdeling kunne som i eksempel 9.1 være kvinder og mænd eller som i kvalitetskontrol være<br />
i defekte varer og ikke-defekte varer.
9. Vigtige diskrete fordelinger<br />
Lad os antage, at vi har en beholder med N kugler, hvoraf de M er røde og resten har en anden<br />
farve.<br />
Der udtrækkes en stikprøve på n kugler uden tilbagelægning.<br />
Lad X være antallet af røde kugler blandt de n kugler.<br />
X er hypergeometrisk fordelt med parametrene N, M, n (kort skrevet h(N,M,n))<br />
P(X = x) er sandsynligheden for at netop x kugler er røde blandt de n udtrukne kugler.<br />
X siges at være hypergeometrisk fordelt med parametrene N, M, n (kort skrevet h(N,M,n))<br />
hvor<br />
K( M, x) ⋅K( N − M, n−x) PX ( = x)<br />
=<br />
K( N, n)<br />
Formlen udledes på samme måde som det skete i eksempel 9.1<br />
Sætte x = 0, 1, 2, ... finder vi forskellige værdier af tæthedsfunktionen.<br />
I “Supplement til statistiske <strong>grundbegreber</strong>” afsnit 9A bevises, at den hypergeometriske fordeling<br />
N − n<br />
har middelværdien E( X) = n⋅ p og spredningen σ ( X) = n⋅ p⋅( 1−<br />
p) ⋅ , hvor p .<br />
N − 1<br />
M<br />
=<br />
N<br />
Eksempel 9.2: Hypergeometrisk fordeling h (10, 6, 3 ).<br />
I en urne findes 10 kugler, hvoraf 6 er sorte, 4 er hvide.<br />
Vi betragter det tilfældige eksperiment: "Udtrækning af en kugle og observation af farven på<br />
kuglen”. Eksperimentet gentages 3 gange, idet den udtrukne kugle ikke lægges tilbage mellem<br />
hver udtrækning.<br />
Lad X betegne antallet af udtrukne sorte kugler.<br />
Find og skitser tæthedsfunktionen for X, og beregn middelværdi og spredning for X.<br />
LØSNING:<br />
X er en diskret stokastisk variabel, der som er hypergeometrisk fordelt h (10, 6, 3) med<br />
tæthedsfunktionen f (x) = P(X = x):<br />
⎧ K( 60 , ) ⋅ K(<br />
43 , ) 4<br />
⎪<br />
= = 0. 033 for x = 0<br />
K(<br />
10, 3)<br />
120<br />
⎪<br />
⎪<br />
K(,) 61 ⋅ K(,)<br />
42 36<br />
= = 0. 300 for x = 1<br />
⎪ K(<br />
10, 3)<br />
120<br />
⎪<br />
f ( x) = P( X = x)<br />
= ⎨ K( 62 , ) ⋅ K(<br />
41 , ) 60<br />
⎪<br />
= = 0500 . for x = 2<br />
K(<br />
10, 3)<br />
120<br />
⎪<br />
K( 63 , ) ⋅ K(<br />
40 , ) 20<br />
⎪<br />
= = 0167 . for x = 3<br />
⎪ K(<br />
10, 3)<br />
120<br />
⎩⎪<br />
0<br />
ellers<br />
Stolpediagram for h (10, 6, 3).<br />
92
Sættes p er middelværdien og<br />
M<br />
= =<br />
N<br />
6<br />
E( X) = n⋅ p=<br />
3⋅ = .<br />
10<br />
6<br />
10 18<br />
N − n<br />
N − 1<br />
⎛<br />
3 ⎜<br />
⎝<br />
6<br />
10 1<br />
spredningen σ ( X) = n⋅ p⋅( 1−<br />
p) ⋅ = ⋅ ⋅ − = 0.748<br />
93<br />
6 ⎞ 10 − 3<br />
⎟ ⋅<br />
10⎠<br />
10 − 1<br />
9.2 Hypergeometrisk fordeling<br />
Den hypergeometriske fordeling finder bl.a. anvendelse i kvalitetskontrol, hvilket følgende<br />
eksempel viser.<br />
Eksempel 9.3: Stikprøveudtagning (kvalitetskontrol)<br />
En producent fabrikerer komponenter, som sælges i æsker med 600 komponenter i hver.<br />
Som led i en kvalitetskontrol udtages hvert kvarter tilfældigt en æske produceret indenfor de<br />
sidste 15 minutter, og 25 tilfældigt udvalgte komponenter i denne undersøges, hvorefter det<br />
foregående kvarters produktion godkendes, såfremt der højst er én defekt komponent i stikprøven.<br />
Hvor stor er acceptsandsynligheden p, hvis æsken indeholder i alt 10 defekte komponenter,<br />
såfremt udtrækningen sker uden mellemliggende tilbagelægninger ?<br />
Løsning:<br />
X = antal defekte blandt de 25 komponenter<br />
Da partiet godkendes, hvis der enten er 0 defekte eller 1 defekt, følger af additionssætningen at<br />
p = P (X = 0) + P (X = 1).<br />
Hændelsen "X = 0" forudsætter, at vi i alt udtager 0 af de 10 defekte og 25 forskellige af de 590<br />
K( 10, 0) ⋅ K(<br />
590, 25)<br />
ikke-defekte, dvs. P( X = 0)<br />
=<br />
= 06512 . .<br />
K(<br />
600, 25)<br />
Hændelsen "X = 1" forudsætter, at vi i alt udtager 1 af de 10 defekte og 24 forskellige af de 590<br />
K( 10, 1) ⋅ K(<br />
590, 24)<br />
ikke-defekte, dvs. P( X = 1)<br />
=<br />
= 0. 2876 .<br />
K(<br />
600, 25)<br />
Vi har altså p = 0.6512 + 0.2876 = 0.9388 = 93.88%.<br />
TI-89: Vælg MATH\Probability\nCr<br />
(nCr(10,0) nCr(590,25)+nCr(10,1) nCr(590,24))/nCr(600,25) = 0.9388<br />
⋅ ⋅<br />
Excel: Vælg f x Statistik HYPGEOFORDELING Udfyld menu<br />
HYPGEOFORDELING(0;25;10;600)+HYPGEOFORDELING(1;25;10;600) = 0,938876
9. Vigtige diskrete fordelinger<br />
9.3 BINOMIALFORDELING<br />
Binomialfordelingen benyttes som model for antallet af "succeser" ved n uafhængige gentagelser<br />
af et eksperiment, som hver gang har samme sandsynlighed p for "succes".<br />
Problemstillingen fremgår af følgende eksempel.<br />
Eksempel 9.4. En binomialfordelt variabel.<br />
En drejebænk producerer 1 % defekte emner.<br />
Lad X være antallet af defekte blandt de næste 5 emner der produceres.<br />
Vi ønsker at finde sandsynligheden for at finde netop 2 defekte blandt disse 5, det vil sige<br />
P( X = 2)<br />
.<br />
Løsning:<br />
Lad et eksperiment være at udtage et emne fra produktionen.<br />
Resultatet af eksperimentet har to udfald: defekt, ikke defekt.<br />
Eksperimentet gentages 5 gange uafhængigt af hinanden.<br />
Der er en bestemt sandsynlighed for at få en defekt, nemlig p = 0.01.<br />
Lad d være det udfald at få en defekt, og d være det udfald at få en fejlfri.<br />
Vi opskriver nu samtlige forløb, der giver 2 defekte ud af 5<br />
ddddd , , , ,<br />
ddddd , , , ,<br />
ddddd , , , ,<br />
ddddd , , , ,<br />
ddddd , , , ,<br />
ddddd , , , ,<br />
ddddd , , , , .<br />
ddddd , , , ,<br />
ddddd , , , ,<br />
ddddd , , , ,<br />
Da eksperimenterne gentages uafhængigt af hinanden, følger det af produktsætningen (både -og),<br />
at det første forløb må have sandsynligheden<br />
2 3<br />
0. 01⋅0. 01⋅( 1−0. 01) ⋅( 1−0. 01) ⋅( 1− 0. 01) = 0. 01 ⋅( 1−0. 01)<br />
.<br />
Det næste forløb må have sandsynligheden<br />
2 3<br />
001 . ⋅( 1−001 . ) ⋅001 . ⋅( 1−001 . ) ⋅( 1− 001 . ) = 001 . ⋅( 1−001 . )<br />
Vi ser, at alle gunstige forløb har samme sandsynlighed.<br />
Antal forløb må være lig antal måder man kan placere 2 d’er på 5 tomme pladser (eller antal<br />
måder man kan tage 2 kugler ud af en mængde på 5).<br />
Dette ved vi kan gøres på K(5,2)=10 måder (svarende til de 10 forløb).<br />
2 3<br />
Vi får følgelig, at p = K(,)<br />
52 ⋅001 . ⋅( 1− 001 . ) = 000097 .<br />
TI-89: CATALOG\F3\binomPdf(5, 0.01,2) = 0.00097<br />
Excel: Vælg f x Statistik BINOMIALFORDELING Udfyld menu BINOMIALFORDELING(2;5;0,01;0) =<br />
0,00097<br />
94
95<br />
9.3 Binomialfordelingen<br />
DEFINITION af binomialfordeling.<br />
1) Lad et tilfældigt eksperiment have 2 udfald “succes” og “fiasko”<br />
2) Lad eksperimentet blive gentaget n gange uafhængigt af hinanden, og lad<br />
sandsynligheden for succes være en konstant p<br />
Lad X være antallet af succeser blandt de n gentagelser<br />
X er en diskret stokastisk variabel med tæthedsfunktionen<br />
⎧<br />
x n−x ⎪Knx<br />
( , ) ⋅p⋅( 1− p) f ( x) = P( X = x)<br />
= ⎨<br />
⎩⎪ 0<br />
X siges at være binomialfordelt b ( n, p).<br />
for<br />
ellers<br />
x∈{ 012 , , ,..., n}<br />
I eksemplet har vi “udledt” den såkaldte binomialfordeling, som er defineret på følgende måde:<br />
SÆTNING 9.1. (middelværdi og spredning for binomialfordeling).<br />
Lad X være binomialfordelt b (n, p).<br />
Der gælder da E ( X )= n ⋅ p<br />
og σ σ ( X ) = n ⋅ p ⋅ ( 1<br />
−<br />
p<br />
)<br />
. .<br />
Bevis:<br />
Lad os betragte et eksperiment, hvor resultatet “succes” har sandsynligheden p for at ske.<br />
Lad os foretage n uafhængige gentagelser af eksperimentet. At gentagelserne er uafhængige betyder, at udfaldet<br />
af et eksperiment ikke afhænger af udfaldet af de forrige eksperimenter.<br />
Lad os betragte n stokastiske variable X1, X2,..., Xn, hvor X i = ⎧1 hvis i' te gentagelse af eksperimentet giver succes.<br />
⎨<br />
⎩0<br />
ellers<br />
Vi har E( Xi) = ∑ xi f ( xi) = 1⋅ p+ 0⋅( 1−<br />
p) = p,<br />
og<br />
i<br />
2 2 2 2<br />
V( Xi) = ∑ ( xi − µ ) f ( xi) = ( 1− p) ⋅ p+ ( 0− p) ⋅( 1− p) = p− p = p⋅( 1−<br />
p)<br />
i<br />
Idet X = X1 + X2 + ... + Xner binomialfordelt b ( n, p) fås af linearitetsreglen (kapitel 1afsnit 5), at<br />
E( X) = E( X1) + E( X2) + E( X3) + ... + E( Xn) = p+ p+ p+ ... + p= n⋅ p.<br />
Endvidere fås af kvadratreglen i kapitel 1 afsnit 5, idet vi har uafhængige gentagelser, at<br />
V( X) = V( X1) + V( X2) + ... + V( Xn) = p⋅( 1− p) + p⋅( 1− p) + ... + p⋅( 1−<br />
p)<br />
,<br />
eller V( X) = n⋅ p⋅( 1 − p)<br />
.
9. Vigtige diskrete fordelinger<br />
Eksempel 9.5: Tæthedsfunktion for binomialfordelt variabel .<br />
Lad der på to af sidefladerne på en terning være skrevet tallet 1, på to andre sideflader være<br />
skrevet tallet 2 og på de sidste to sideflader være skrevet tallet 3.Vi betragter det tilfældige<br />
eksperiment:<br />
"7 kast med en terningen og observation af det fremkomne tal.<br />
Lad X betegne antallet af toere ved de 7 kast. X antages at være binomialfordelt b( 7 ) . 1 , 3<br />
1) Angiv tæthedsfunktionen f (x) for X (3 betydende cifre), og tegn et stolpediagram for f (x).<br />
2) Find middelværdi og spredning for X<br />
En person foretager eksperimentet 11 gange, d.v.s. foretager 11 gange en serie på 7 kast med<br />
terningen. Stikprøven gav følgende resultat<br />
Antal toere i en serie 0 1 2 3 4 5 6 7<br />
Antal gange dette skete 1 2 4 3 1 0 0 0<br />
3) Giv på grundlag af stikprøven et estimat for p i binomialfordelingen.<br />
4) Giv på grundlag af stikprøven et estimat for middelværdi og spredning<br />
Løsning:<br />
x n x<br />
1) f ( x) = P( X = x) = K( , x)<br />
⋅ ⎛<br />
⎜<br />
⎝<br />
⎞<br />
−<br />
1 ⎛ ⎞<br />
7 ⎟ ⋅⎜1− ⎟<br />
3⎠<br />
⎝ ⎠<br />
1<br />
3<br />
TI89: binomPdf(7,1/3,x) x = 0 og derefter x = 1 osv.<br />
Excel:BINOMIALFORDELING(0;7;1/3;0), og derefter BINOMIALFORDELING( 1;7;1/3;0) osv.<br />
⎧0059<br />
. for x = 0<br />
⎪<br />
⎪<br />
205<br />
⎪0307<br />
.<br />
⎪<br />
⎪0.<br />
256<br />
⎪<br />
f ( x) = P( X = x)<br />
= ⎨0128<br />
.<br />
⎪0.<br />
038<br />
⎪<br />
⎪0.<br />
006<br />
⎪<br />
⎪<br />
0. 000<br />
⎩⎪<br />
for<br />
for<br />
for<br />
for<br />
for<br />
for<br />
for<br />
ellers 0<br />
x = 1<br />
x = 2<br />
x = 3<br />
x = 4<br />
x = 5<br />
x = 6<br />
x = 7<br />
0<br />
Stolpediagram for binomialfordelingen<br />
2) E( X) = n⋅ p=<br />
7 ⋅ = . og<br />
1<br />
⎛ ⎞<br />
233 σ ( X) = n⋅ p⋅( 1− p)<br />
= 7⋅ ⋅⎜− ⎟ = .<br />
3<br />
⎝ ⎠<br />
1<br />
1<br />
3<br />
1<br />
125<br />
3<br />
3) Der er i alt 10 ⋅ + 21 ⋅ + 42 ⋅ + 33 ⋅ + 14 ⋅ = 23 toere i 77 kast.<br />
23<br />
Et estimat for p er p $ = = 0299 .<br />
77<br />
23<br />
4) Stikprøvens middelværdi er x = = 209 . , og stikprøvens spredning er<br />
11<br />
⎛ ⎞<br />
σ ( X) = n⋅ p⋅( 1− p)<br />
= 7⋅ ⋅⎜− ⎟ = .<br />
⎝ ⎠<br />
23 23<br />
1 121<br />
77 77<br />
96
97<br />
9.3 Binomialfordelingen<br />
Hypotesetest for binomialfordelt variabel.<br />
I kapitel 6 gennemgik vi ved en række eksempler de grundlæggende begreber for<br />
hypotesetestning for én normalfordelt variabel. Disse begreber kan uændret overføres til<br />
hypotesetestning for binomialfordelt variabel.<br />
Konfidensintervaller.<br />
Som beskrevet i appendix er det ofte muligt at approksimere med en normalfordeling.<br />
Derved fremkommer de formler som er beskrevet i appendix 4.1 punkt 5.<br />
Kan approksimationen ikke anvendes, kan man ved løsning af en passende ligning finde de<br />
eksakte grænser for konfidensintervallerne. Da det er ret besværligt, foretrækkes så vidt muligt<br />
(selv i statistikprogrammer) at anvende approksimationen med normalfordelingen.<br />
De følgende to eksempler viser anvendelser heraf.<br />
Eksempel 9.6. Ensidet binomialfordelingstest.<br />
En levnedsmiddelproducent fremstiller et levnedsmiddel A, som imidlertid har en ret ringe<br />
holdbarhed. Efter en række eksperimenter lykkedes det at frembringe et produkt B, som i alt<br />
væsentligt er identisk med A, men som har en bedre holdbarhed. Af markedsmæssige grunde er<br />
det vigtigt, at der ikke er forskel på smagen af B og af det velkendte produkt A. For at undersøge<br />
dette, lader producenten et panel af 24 ekspertsmagere vurdere, om man kan smage forskel. Man<br />
foretog derfor følgende smagsprøvningseksperiment.<br />
Hver ekspertsmager fik 3 ens udseende portioner, hvoraf en portion var af det ene levnedsmiddel<br />
og de to andre portioner var af det andet levnedsmiddel.<br />
Hvilket af de 3 portioner der skulle indeholde et andet levnedsmiddel end de to andre, og om det<br />
skulle være levnedsmiddel A eller B , afgjordes hver gang ved lodtrækning. Kun forsøgslederen<br />
havde kendskab til resultatet.<br />
Hver ekspertsmager fik besked på, at de skulle fortælle forsøgslederen hvilken af de tre portioner<br />
der smagte anderledes. Hvis man ikke kunne smage forskel, skulle man gætte.<br />
Resultatet viste, at af de 24 svar var 13 svar rigtige.<br />
1<br />
Ved ren gætning kunne man forvente ca. 3 dvs. ca. 8 rigtige svar. 13 rigtige svar er betydeligt<br />
flere, men kan det alligevel tilskrives tilfældigheder ved gætning?<br />
Kan der på et signifikansniveau på 5% statistisk påvist, at ekspertsmagerne kan smage forskel<br />
på smagen af A og B?<br />
Løsning:<br />
Lad X = antallet af rigtige svar.<br />
X er binomialfordelt b (n, p), hvor n = 24 og p er ukendt.<br />
1<br />
Nulhypotese H0: p = mod den alternative hypotese Hp : ><br />
3<br />
1<br />
3<br />
TI89: P - værdi = P( X ≥ 13)<br />
= binomCdf(24, 1/3, 13, 24) = 0.0284 = 2.84%<br />
Excel: P - værdi = 1− P( X ≤12)<br />
= 1-BINOMIALFORDELING(12;24;1/3;1) = 0,028441<br />
Da P - værdi < 5% forkastes nulhypotesen (enstjernet), dvs. der må konkluderes, at der er en<br />
smagsforskel mellem produkt A og B.
9. Vigtige diskrete fordelinger<br />
Eksempel 9.7. Konfidensinterval for parameteren p i binomialfordeling.<br />
En plastikfabrik har udviklet en ny type affaldsbeholdere. Man overvejer at give en 6 års garanti<br />
for holdbarheden. For at få et skøn over om det er økonomisk rentabelt, bliver 100 beholdere<br />
udsat for et accelereret livstidstest som simulerer 6 års brug af beholderne. Det viste sig, at af de<br />
100 beholdere overlevede de 85 testen.<br />
Idet antallet af overlevende beholdere antages at være binomialfordelt, skal man<br />
1) Angive et estimat for sandsynligheden p for at en beholder “overlever” i 6 år .<br />
2) Angive et 95% konfidensinterval for p.<br />
Løsning:<br />
1) Lad X være antallet af “overlevende” beholdere.<br />
X forudsættes binomialfordelt b (100, p).<br />
Appendix 4.1 punkt 5 anvendes. Et estimat for p er ~ x 85<br />
p = = = 085 .<br />
n 100<br />
2) Da 10 ≤ x ≤n−10 er forudsætningerne for at benytte normalfordelingsapproksimation opfyldt.<br />
Vi får:<br />
~<br />
~ p⋅( 1−<br />
~ p)<br />
085 . ⋅( 1−085 . )<br />
p ± u α ⋅<br />
= 085 . ± 196 . ⋅<br />
= 085 . ± 007 .<br />
− n<br />
100<br />
1 2<br />
dvs. 078 . ≤ p ≤092<br />
.<br />
TI 89 og Excel benytter denne formel, dvs. man skal altid først undersøge om forudsætningen<br />
er opfyldt.<br />
TI89: APPS\STATS/List\F7\5:1-PropZInt\ENTER<br />
Menuen udfyldes med x: 85 n: 100 C-level: 0.95 ENTER<br />
Resultat: C Int : [0.78 ; 0.92 ]<br />
Excel:<br />
radius= NORMINV(0,975;0;1)*KVROD(0,85*(1-0,85)/100) 0,069985<br />
Nedre grænse 0,85-I3 0,780015<br />
Øvre grænse 0,85+I3 0,919985<br />
Eksakt løsning:<br />
Er betingelsen ikke opfyldt (eller vil man have det “eksakte” resultat) benyttes formel i appendix 4.1 nr 6.<br />
Øvre grænse: Løs ligningen P( X ≤ 85)<br />
= 0.025 med hensyn til p.<br />
TI89: solve(binomCdf(100, p,0,85)=0.025,p) p > 0 Resultatet blev p = 0.914.<br />
Nedre grænse: Løs ligningen P( X ≥ 85)<br />
= 0.025 med hensyn til p.<br />
TI89: solve(binomCdf(100, p,85,100)=0.025,p) p > 0 Resultatet blev p = 0.765.<br />
95% Konfidensinterval: [0.765; 0.914]<br />
Bemærk, at konfidensintervallet ikke ligger helt symmetrisk omkring 0.85, da binomialfordelingen ikke er<br />
helt symmetrisk omkring 0.85<br />
Forklaring på formlen:<br />
Udenfor et 95% konfidensinterval ligger 5%, og af symmetrigrunde ligger der 2,5% på hver side. (jævnfør<br />
figuren)<br />
Jo større den sande værdi p er i forhold til 0.85 jo mindre bliver sandsynligheden for at 85 eller færre<br />
overlevede testen. Vi leder derfor i grænsen efter et p > 0.85 , så P( X ≤ 85)<br />
= 0.025.<br />
Dernæst findes nedre grænse ved at lade p falde, indtil PX ( ≥ 85) ≈ 0. 025<br />
Bestemmelse af stikprøvens størrelse<br />
98
99<br />
9.3 Binomialfordelingen<br />
Før man starter sine målinger, kunne det være nyttigt på forhånd at vide nogenlunde hvor<br />
mange målinger man skal foretage, for at få resultat med en given nøjagtighed.<br />
Hvis man antager, at man kan approksimere med normalfordelingen, ved vi, at radius for et<br />
p$ ⋅( 1−<br />
p$)<br />
95% konfidensinterval er r = u0975<br />
. ⋅<br />
.<br />
n<br />
Løses denne ligning med hensyn til n fås<br />
u<br />
n = p p<br />
r<br />
⎛ 0975 . ⎞<br />
⎜ ⎟ $ ⋅( 1−<br />
$)<br />
⎝ ⎠<br />
2<br />
Det grundlæggende problem er her, at man næppe kender $p eksakt.<br />
Man kender muligvis på basis af tidligere erfaringer størrelsesordenen af $p . Hvis ikke<br />
kunne man eventuelt udtage en lille stikprøve, og beregne et $p på basis heraf.<br />
Endelig er der den mulighed, at sætter $p = 0.5, som er maksimumsværdien af p$ ⋅( 1−<br />
p$)<br />
Benyttes denne værdi får man den størst mulige værdi af n for en given værdi af r.<br />
Ulempen er, at dette fører til en større stikprøvestørrelse end nødvendigt.<br />
Det følgende eksempel illustrerer fremgangsmåden.<br />
Eksempel 9.8. Bestemmelse af antal i stikprøve.<br />
I en opinionsundersøgelse vil man spørge et repræsentativt antal vælgere om hvilket parti de<br />
vilde stemme på, hvis der var valg i morgen.<br />
I denne undersøgelse ønskes inden udtagning af stikprøven, at antallet skal være så stort, at<br />
radius i konfidensintervallet højst er 2%.<br />
Løsning:<br />
Metode 1. For at få en øvre grænse, sættes $p = 0.5.<br />
2 2<br />
Vi får<br />
u<br />
n = p p<br />
r<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ − =<br />
⎝ ⎠<br />
⎛<br />
0975 . 196 . ⎞ 1 1<br />
$ ( 1 $) ⎜ ⎟ ⋅ = 2401<br />
⎝ 002 . ⎠ 2 2<br />
Metode 2 Da man på forhånd ved, at ved sidste valg fik ingen partier mere end 30% af<br />
stemmerne sættes $p = 0.3.<br />
2 2<br />
u<br />
n = p p<br />
r<br />
⎛ ⎞<br />
⎜ ⎟ ⋅ − =<br />
⎝ ⎠<br />
⎛<br />
0975 . 196 .<br />
$<br />
⎞<br />
( 1 $) ⎜ ⎟ 03 . ⋅ 07 . = 2017<br />
⎝ 002 . ⎠
9. Vigtige diskrete fordelinger<br />
Approksimation af hypergeometrisk fordeling med binomialfordeling.<br />
At erstatte den hypergeometriske fordeling h (N, M, n) med binomialfordelingen b (n, p) vil<br />
for de fleste anvendelser kunne gøres med en passende nøjagtighed, hvis stikprøvestørrelsen n<br />
N n 1<br />
er mindre end eller lig 10% af partistørrelsen N ( n ≤ ⇔ ≤ ).<br />
10 N 10<br />
I så fald sættes i binomialfordelingen p .<br />
M<br />
=<br />
N<br />
Eksempel 9.9. Approksimation af hypergeometrisk fordeling til binomialfordeling.<br />
I eksempel 9.3, hvor man udtog 25 komponenter fra æsker på 600 komponenter, skete<br />
udtagningen logisk nok uden tilbagelægning. Imidlertid er det klart, at da æskerne indeholder<br />
mange komponenter vil sandsynligheden for at få en defekt ikke ændrer sig meget, hvis man i<br />
stedet havde foretaget udtagningen med tilbagelægning.<br />
Der blev antaget, at der var 10 defekte i en sådan æske med 600, og dette antal defekte vil så<br />
være konstant, under hver udtrækning.<br />
10 1<br />
Vi har derfor, at P(at få en defekt) = = . Betingelserne for at benytte<br />
600 60<br />
binomialfordelingen er nu til stede.<br />
Løsningen af problemet i eksempel 9.3 vil derfor nu være:<br />
TI89: pa = P( X ≤ 1) = P( X = 0) + P( X = 1)<br />
= binomCdf(25,1/60,0,1) = 0.9353<br />
Det ses, at vi får praktisk samme resultat som i eksempel 9.3.<br />
9.4 POISSONFORDELINGEN<br />
Poissonfordelinger benyttes ofte som statistisk model for antallet af "impulser" pr. tidsenhed.<br />
Disse impulser antages at komme tilfældigt og uafhængigt af hinanden.<br />
Som eksempler kan nævnes: Antal trafikuheld på en bestemt vejstrækning i løbet af et år,<br />
antal biler, der passerer en militær kontrolpost, antal varevogne der ankommer pr. time til et<br />
stort varehus og antal telefonsamtaler der føres fra en telefoncentral, der er oprettet under en<br />
øvelse.<br />
Modellen kan dog også anvendes på andet end pr. tidsenhed, eksempelvis også på antal<br />
revner pr. km kabel, hvis disse revner forekommer tilfældigt og uafhængigt af hinanden.<br />
Under sådanne omstændigheder kan man ofte benytte den i det følgende omtalte<br />
Poissonfordeling som statistisk model for antallet af "impulser" pr. tidsenhed eller<br />
volumenenhed eller længdeenhed osv.<br />
100
101<br />
9.4 Poissonfordelingen<br />
SÆTNING 9.2 (Poissonfordeling). Lad X være en stokastisk variabel, som angiver antallet<br />
af impulser i et givet tidsrum (eller areal, volumen, produktionsenhed osv.), idet ethvert<br />
tidspunkt i tidsrummet har samme mulighed for at være impulstidspunkt som ethvert andet<br />
tidspunkt. Endvidere skal impulserne indtræffe tilfældigt og uafhængigt af hinanden * ) .<br />
Hvis det gennemsnitlige antal impulser i tidsrummet er µ > 0 , så siges X at være<br />
Poissonfordelt p ( µ ) med sandsynlighedsfordelingen (tæthedsfunktionen) f(x) = P(X = x)<br />
bestemt ved<br />
⎧ x<br />
⎪<br />
µ − µ<br />
f ( x) = P( X = x) =<br />
⋅e for x ∈{,,,...}<br />
012<br />
⎨ x!<br />
⎩<br />
⎪ 0 ellers<br />
Middelværdien for p( µ ) er E ( X ) = µ og spredningen er σ ( X ) = µ .<br />
I formuleringen af de ovennævnte betingelser kan efter behov "et lille tidsrum ∆ t" erstattes<br />
med "en lille længde ∆ l ", "et lille areal ∆ A" eller "et lille volumen ∆ V".<br />
*) Præcis formulering: Følgende 3 betingelser skal være opfyldt:<br />
1) Sandsynligheden for netop én impuls i et meget lille tidsrum ∆ t er med tilnærmelse proportional med ∆ t<br />
.<br />
P( X = 1)<br />
(Matematisk formulering lim = λ ( λ er en positiv konstant)<br />
∆t→0 ∆t<br />
2) Sandsynligheden for 2 eller flere impulser i det meget lille tidsrum ∆ t er lille sammenlignet med ∆ t .<br />
P( X > 1)<br />
(Matematisk formulering lim = 0 )<br />
∆t→0 ∆t<br />
3) Antal impulser i forskellige, ikke overlappende tidsrum er statistisk uafhængige.<br />
En bevisskitse for sætningen kan ses i “Supplement til statistiske <strong>grundbegreber</strong>” afsnit<br />
9.C.<br />
Eksempel 9.10: Antal revner p. meter i et tyndt kobberkabel.<br />
På en fabrik fremstilles kobberkabler af en bestemt tykkelse. Mikroskopiske revner<br />
forekommer tilfældigt langs disse kabler. Man har erfaring for, at der i gennemsnit er 12.3 af<br />
den type revner p. 10 meter kabel.<br />
Beregn sandsynligheden for, at der<br />
1) ingen ridser er i 1 meter tilfældigt udvalgt kabel.<br />
2) er mindst 2 ridser i 1 meter tilfældigt udvalgt kabel.<br />
3) er højst 4 ridser i 2 meter tilfældigt udvalgt kabel<br />
Fabrikken går nu over til en anden og billigere produktionsmetode. For at få et estimat for<br />
middelværdien ved den nye metode måltes antallet af revner på 12 kabelstykker på hver 10<br />
meter.<br />
Resultaterne var<br />
Kabel nr. 1 2 3 4 5 6 7 8 9 10 11 12<br />
Antal revner 8 4 14 6 8 10 10 16 2 2 6 8<br />
4) Angiv på basis heraf et estimat for middelværdien af antal revner pr. 10 m kabel.
Vigtige diskrete fordelinger<br />
Løsning:<br />
X = antal revner i 1 meter kabel.<br />
X antages Poissonfordelt p ( µ ). (idet vi med tilnærmelse kan antage, at betingelserne i<br />
sætning 9.2 er opfyldt (impuls er her ridser).<br />
12. 3<br />
Da det gennemsnitlige antal revner pr. 1m kabel er µ = = 123 . fås:<br />
10<br />
0<br />
123 . −123<br />
.<br />
1) P( X = 0)<br />
= ⋅ e = 0. 292 .<br />
0!<br />
TI89: PoissPdf(1.23,0) = 0.292<br />
Excel: POISSON(0;1,23;0) =0,292293<br />
2) TI-89: P( X ≥ 2) = 1− P( X ≤ 1)<br />
= 1-PoissCdf(1.23, 0, 1) = 0.3482<br />
Excel: P( X ≥ 2) = 1− P( X ≤ 1)<br />
= 1 - POISSON(1;1,23;1) = 0,348188<br />
3) Y = antal revner i 2 meter kabel.<br />
Da der i gennemsnit er 2,46 revner i 2 meter kabel, er 2.46 et estimat for µ .<br />
Vi har derfor TI89: = poissCdf(2.46, 0, 4) = 0.8965<br />
P( X ≤ 4)<br />
Excel: P( X ≤ 4)<br />
=POISSON(4;2,46;1) = 0,896458<br />
4) Der er i alt 94 revner i 12 kabelstykker på hver 10 meter. Et estimat for µ er derfor<br />
~ 94<br />
µ = = 783 . .<br />
12<br />
Hypotesetest for Poissonfordelt variabel.<br />
I kapitel 5 gennemgik vi ved en række eksempler de grundlæggende begreber for<br />
hypotesetestning for én normalfordelt variabel. Disse begreber kan uændret overføres til<br />
hypotesetestning for Possonfordelt variabel.<br />
Har man rådighed over en lommeregner med kumuleret Poissonfordeling kan testene<br />
gennemføres eksakt. (se appendix 5.5)<br />
Konfidensintervaller.<br />
Som beskrevet i næste afsnit er det ofte muligt at approksimere med en normalfordeling.<br />
Derved fremkommer de formler som er beskrevet i appendix 4.1 punkt 5.<br />
Eksempel 9.11. Ensidet Poissontest.<br />
I eksempel 9.8 betragtede vi mikroskopiske revner i et kobberkabel. Fabrikken gik over til en<br />
anden og billigere produktionsmetode.<br />
1) Test, om den nye metode giver færre revner end den gamle metode.<br />
2) Forudsat, den nye metode giver signifikant færre revner end den gamle metode, skal man<br />
2a) Angiv et 95% konfidensinterval for middelværdien µ af antal revner pr. 120 meter<br />
kabel .<br />
2b) Angiv et 95% konfidensinterval for middelværdien µ 1 af antal revner pr. 10 meter<br />
kabel.<br />
102
103<br />
9.6 Polynomialfordelingen<br />
Løsning:<br />
1) Lad X betegne antallet af revner i 120 meter kabel ved ny metode<br />
X antages Poissonfordelt p( µ ) , hvor vi i eksempel 9.8 fandt at et estimat for µ var<br />
~<br />
µ = 94 .<br />
Ved gammel metode er antal revner i 120 m kabel i middel 12. 3⋅ 12 = 147. 6<br />
Nulhypotese H0: µ = 147. 6 mod den alternative hypotese H: µ < 147. 6 .<br />
TI89:P - værdi = PY ( ≤ 94)<br />
= PoissCdf(147.6, 0 , 94) = 0.000002<br />
Excel:P - værdi = PY ( ≤ 94)<br />
= Poisson(94;147,6;1) = 1,52403E-06<br />
Da P - værdi < 0.05 forkastes nulhypotesen (stærkt) ,dvs. vi er sikre på, at middelantallet af<br />
revner er blevet formindsket ved at anvende den nye metode<br />
2a) Idet m= 94>10 kan formel 6 i appendix 4.1 anvendes.<br />
Antal revner pr 120 m kabel:<br />
Idet<br />
94<br />
x = = 94<br />
1<br />
er et 95% konfidensinterval for µ<br />
x ± u0.<br />
975 ⋅<br />
x<br />
= 94 ± 196 . ⋅<br />
n<br />
94<br />
1<br />
2b) Antal revner pr 10 m kabel:<br />
⎡75<br />
113⎤<br />
⎢ ; [ 625 . ; 941 . ]<br />
⎣12<br />
12 ⎥<br />
⎦<br />
=<br />
. [75 ; 113].<br />
9.5 Den generaliserede hypergeometriske fordeling.<br />
Den hypergeometriske fordeling benyttes som model ved stikprøveudtagning uden tilbagelægning, hvor hvert<br />
element har enten en bestemt egenskab (defekt) eller ikke har denne egenskab (ikke defekt). Hvis der foreligger<br />
flere end to egenskaber, f.eks. udtagning af møtrikker, hvis diameter enten tilhører et givet toleranceinterval eller<br />
er for stor eller for lille, kan man generalisere den hypergeometriske fordeling. Dette illustreres ved følgende<br />
eksempel:<br />
Eksempel 9.12. Generaliseret hypergeometrisk fordeling.<br />
I en urne findes 12 kugler, hvoraf 5 er sorte, 4 er hvide og 3 er røde.<br />
Vi betragter det tilfældige eksperiment: "Udtrækning af 6 kugler uden tilbagelægning og observation af farven<br />
på kuglerne”. Beregn sandsynligheden for at få 2 sorte, 3 hvide og 1 rød kugle.<br />
LØSNING:<br />
Lad X1 være antallet af sorte kugler, X2 være antallet af hvide kugler og X3 være antallet af røde kugler.<br />
Analogt med begrundelsen for den hypergeometriske fordeling fås:<br />
K(,) 52 ⋅K(,) 43 ⋅K(,)<br />
31 10⋅ 4 ⋅ 3<br />
P( X1 = 2, X2 = 3, X3<br />
= 1)<br />
=<br />
= =<br />
013 .<br />
K(<br />
12, 6)<br />
924
Vigtige diskrete fordelinger<br />
9.6 Polynomialfordelingen.<br />
Binomialfordelingen benyttes som model ved uafhængige gentagelser af samme eksperiment. Eksperimentet har<br />
to udfald succes eller ikke succes og der er en konstant sandsynlighed for succes. Hvis der foreligger flere end to<br />
udfald, f.eks. udtagning af møtrikker fra en løbende produktion, hvor diameter enten tilhører et givet<br />
toleranceinterval eller er for stor eller for lille, kan man generalisere til polynomialfordelingen. Idet formlen for<br />
binomialfordelingen kan skrives<br />
n x n x n!<br />
x n x n!<br />
x x<br />
f ( x)<br />
= p ( p)<br />
p ( p)<br />
p p , hvor<br />
x<br />
x!( n x)!<br />
x ! x !<br />
⎛<br />
⎜<br />
⎝<br />
⎞<br />
− −<br />
1 2<br />
⎟ ⋅ ⋅ 1− =<br />
⋅ ⋅ 1−<br />
= ⋅ 1 ⋅ 2<br />
⎠<br />
⋅ −<br />
⋅<br />
p1 + p2<br />
= 1 og x1 + x2 = n fås analogt<br />
104<br />
1 2<br />
DEFINITION af polynomialfordeling.<br />
p1 + p2+ ... + pk= 1 x + x + ... + x = n<br />
Lad n være et positivt helt tal, og lad og hvor alle pér er positive tal<br />
1 2<br />
og alle xér er hele tal.<br />
Sandsynlighedsfordelingen for en polynomialfordelt stokastisk variabel er<br />
( X1, X2,..., Xk) n!<br />
x1 x2<br />
P( X1 = x1, X2 = x2,..., Xk = xk)<br />
=<br />
p1 ⋅ p2 ⋅... ⋅p<br />
x ! ⋅x ! ⋅... ⋅x<br />
!<br />
1 2<br />
Dette illustreres ved følgende eksempel:<br />
Eksempel 9.11. Polynomialfordelingen<br />
En stor produktion af glaskugler indeholder 40% sorte, 35% hvide og 25% røde kugler.<br />
Vi betragter det tilfældige eksperiment: "Udtrækning af 6 kugler observation af farven på kuglerne”.<br />
Beregn sandsynligheden for at få 2 sorte, 3 hvide og 1 rød kugle.<br />
LØSNING:<br />
Lad X1 være antallet af sorte kugler, X2 være antallet af hvide kugler og X3 være antallet af røde kugler.<br />
6!<br />
2 3 1<br />
Vi får nu P( X1 = 2, X2 = 3, X3<br />
= 1)<br />
= 0. 4 ⋅0. 35 ⋅ 0. 25 = 01029 .<br />
2! ⋅3! ⋅1!<br />
9.7 APPROKSIMATIONER<br />
Vi har undertiden benyttet os af, at det under visse forudsætninger er muligt med en rimelig<br />
nøjagtighed, at foretage approksimationer, f.eks. at approksimere en binomialfordeling eller<br />
en Poissonfordeling med en normalfordeling.<br />
Dette kan give nogle simplere beregninger, eksempelvis når man approksimerer en<br />
hypergeometrisk fordeling med en binomialfordeling eller når man ved udregning af<br />
konfidensintervaller for binomialfordeling approksimerer med normalfordeling.<br />
I appendix 9.1 er angivet en samlet oversigt over de mulige approksimationer.<br />
k<br />
k<br />
xk k
9.8. OVERSIGT over centrale formler i kapitel 9<br />
9.8 Oversigt over centrale formler i kapitel 9<br />
X er binomialfordelt bnp ( , ) , hvor n er kendt og p ukendt. Givet stikprøveværdi x<br />
Konfidensinterval<br />
Forudsætninger Estimat for parameter 100 (1 - α ) % konfidensinterval for parameter<br />
10 ≤ x ∧<br />
x ≤n−10 For p: ~ p =<br />
x<br />
n<br />
~ p − u ⋅<br />
105<br />
~ p( 1−~ p)<br />
~<br />
~<br />
p( 1−~<br />
p)<br />
≤ p ≤ p + u ⋅<br />
n<br />
n<br />
α α<br />
1− 1− 2<br />
2<br />
TI89: F7: 1-prop Z-interval<br />
Excel: Se eksempel 9.7<br />
eksakt α<br />
nedre grænse:Løs ligning P( X ≥ x)<br />
= 1− med hensyn til p.<br />
2<br />
øvre grænse: Løs ligning P( X ≤ x)<br />
= α − med hensyn til p<br />
Test af parameter p for binomialfordelt variabel<br />
Der foreligger en stikprøve på X . Observeret stikprøveværdi x. Signifikansniveau er α .<br />
Y er binomialfordelt bnp ( , ) , hvor er en given konstant.<br />
Alternativ<br />
hypotese H<br />
H p p<br />
: > 0 P Y x<br />
H: p< p0<br />
H: p p<br />
0<br />
p 0<br />
P - værdi Beregning H 0 forkastes<br />
( ≥ )<br />
TI89:binomCdf(n, p0, x, ∞ )<br />
Excel:1-Binomialfordeling(x-1;n;p,1) P-værdi < α<br />
P( Y ≤ x)<br />
TI89:binomCdf(n, p0,- ∞ , x)<br />
Excel: Binomialfordeling(x;n;p;1)<br />
P( Y ≥ x)<br />
P( Y ≤ x)<br />
x > n⋅ p0<br />
for x ≤ n⋅ p0<br />
= 0 for<br />
som række 1<br />
som række 2<br />
1 2<br />
P-værdi < 1<br />
2 α
Vigtige diskrete fordelinger<br />
X er Poissonfordelt p( µ ) , hvor µ ukendt. Stikprøve er af størrelsen n, og der optælles i alt m impulser<br />
Konfidensinterval<br />
Forudsætninger Estimat for parameter 100 (1 - α ) % konfidensinterval for parameter<br />
m ≥ 10<br />
For :<br />
µ x m<br />
= x<br />
n x − u α ⋅ ≤ µ ≤ x + u α ⋅<br />
− n<br />
−<br />
Test af parameter µ for Poissonfordelt variabel .<br />
Der foreligger en stikprøve på X af størrelsen n med gennemsnit x . Signifikansniveau er α .<br />
Y er Poissonfordelt pn ( ) , hvor er en given konstant.<br />
Alternativ<br />
hypotese H<br />
H: µ µ<br />
H: µ µ<br />
H: µ ≠ µ 0<br />
> 0 PY n x<br />
⋅ µ 0<br />
µ 0<br />
106<br />
1 2<br />
P - værdi Beregning på TI 89 H 0 forkastes<br />
( ≥ ⋅ )<br />
TI89: poissCdf ( n⋅µ 0 , n⋅x, 1000)<br />
Excel: 1-Poisson( n x -1; ;1)<br />
< 0 PY n x<br />
1 2<br />
⋅ n⋅ µ 0<br />
( ≤ ⋅ )<br />
poissCdf ( n⋅µ 0 , 0,<br />
n⋅x) Excel: Poisson( n x ; ;1)<br />
≥ ⋅µ 0<br />
< ⋅µ 0<br />
PY ( ≥n⋅x) for x n<br />
PY ( ≤n⋅x) for x n<br />
som række 1<br />
som række 2<br />
⋅ n⋅ µ 0<br />
x<br />
n<br />
P - værdi<br />
< α<br />
P-værdi < 1<br />
2 α
OPGAVER<br />
107<br />
APPENDIX 7.1<br />
Opgave 9.1<br />
Ved en lodtrækning fordeles 3 gevinster blandt 25 lodsedler. En spiller har købt 5 lodsedler.<br />
1) Beregn sandsynligheden for at spilleren vinder netop én gevinst.<br />
Lad den stokastiske variable X være bestemt ved<br />
X = Spilleren vinder x gevinster<br />
2) Find og skitser tæthedsfunktionen for X<br />
3) Beregn middelværdien for X<br />
Opgave 9.2<br />
I en urne findes 2 blå, 3 røde og 5 hvide kugler. 3 gange efter hinanden optages tilfældigt en<br />
kugle fra urnen uden mellemliggende tilbagelægning.<br />
1) Find sandsynligheden for hændelsen A, at der højst optages 2 hvide kugler,<br />
2) Find sandsynligheden for, at de tre kugler har samme farve,<br />
Opgave 9.3<br />
En fabrikant fremstiller en bestemt type radiokomponenter. Disse leveres i æsker med 30<br />
komponenter i hver æske. En køber har den aftale med fabrikanten, at hvis en æske<br />
indeholder 4 defekte komponenter eller derover, kan køberen returnere æsken, i modsat fald<br />
skal den godkendes. Køberen kontrollere hver æske ved en stikprøve, idet han af æsken<br />
udtager 10 komponenter tilfældigt. Lad X være antal defekte i stikprøven. Der overvejes nu to<br />
planer:<br />
1) Hvis X = 0, så godkendes æsken, ellers undersøges æsken nærmere.<br />
2) Hvis X ≤ 1,<br />
så godkendes æsken, ellers undersøges æsken nærmere.<br />
Hvad er sandsynligheden for, at en æske, der indeholder netop 4 defekte komponenter, bliver<br />
godkendt af køberen ved metode 1 og ved metode 2.<br />
Opgave 9.4<br />
En tipskupon har 13 kampe med 3 mulige tegn - 1, x og 2 - for hver kamp. En person<br />
bestemmer tegnet, der skal sættes for hver kamp, ved tilfældig udtrækning af en seddel fra 3<br />
sedler med tegnene henholdsvis 1, x og 2.<br />
Angiv sandsynligheden for, at personen opnår netop 8 rigtige tippede kampe på sin kupon.<br />
Opgave 9.5<br />
I et elektrisk specialapparat indgår 30 komponenter, som hver er indkapslet i et heliumfyldt<br />
hylster. Beregn, idet sandsynligheden for, at et komponenthylster lækker, er 0.2%,<br />
sandsynligheden for, at mindst ét af de 30 komponenthylstre lækker.<br />
Opgave 9.6<br />
En “sypigetipper” (M/K) deltog i tipning 42 gange i løbet af et år. På hver tipskupon var der<br />
13 kampe, ved hver af hvilke tipperen ved systematisk gætning satte et af de 3 tegn: 1, x, 2.<br />
Beregn sandsynligheden p for, at tipperen det pågældende år tippede mindst 200 kampe<br />
rigtigt.<br />
Opgave 9.7<br />
Blandt familier med 3 børn udvælges 50 familier tilfældigt. Angiv sandsynligheden for, at der<br />
i mindst 8 af disse familier udelukkede er børn af samme køn.
Vigtige diskrete fordelinger<br />
Opgave 9.8.<br />
Ved en fabrikation af plastikposer leveres disse i æsker med 100 poser i hver. Ved en<br />
godkendelseskontrol af et parti plastikposer udtages og undersøges en tilfældigt udtaget æske,<br />
og partiet godkendes, såfremt æsken højst indeholder én defekt pose.<br />
Vi antager, at den løbende produktion af poser er således, at hver produktion med<br />
sandsynligheden 2% giver en pose, der er defekt; vi vil senere formulere dette således, at<br />
produktionen er i statistisk kontrol med fejlsandsynligheden p = 2%.<br />
Hvor stor er sandsynligheden for, at partiet under disse omstændigheder accepteres?<br />
Opgave 9.9<br />
Det er oplyst, at der for en given vaccine er 80% sandsynlighed for, at den ved anvendelse har<br />
den ønskede virkning.<br />
På et hospital foretoges vaccination af 100 personer med den pågældende vaccine.<br />
Beregn sandsynligheden for, at 15 eller færre af de foretagne vaccinationer er uden virkning.<br />
Opgave 9.10<br />
En ny vaccine formodes med en sandsynlighed på mindst 85% at have en forebyggende<br />
virkning over for en bestemt influenzatype.<br />
Før en truende influenzaepedemi vaccineres et hospitalspersonale på 600 personer med den<br />
pågældende vaccine. 125 af disse bliver smittet af sygdommen.<br />
Kan dette opfattes som en eksperimentel påvisning af, at vaccinen er mindre virksom end<br />
ventet?<br />
Opgave 9.11<br />
1) Antag, at en vis type af fostermisdannelse normalt forekommer med hyppigheden 164<br />
tilfælde p. 100000 fødsler. Beregn sandsynligheden for 3 eller flere fostermisdannelser<br />
blandt 256 fødsler.<br />
2) For at undersøge om forholdene i et bestemt arbejdsmiljø forøger hyppigheden af denne<br />
type misdannelse, undersøgte man hyppigheden af misdannelser for mødre, som under<br />
graviditeten havde haft den aktuelle type af arbejde, og fandt 3 misdannelser blandt 256<br />
fødsler. Kan den forøgede relative hyppighed i dette materiale skyldes tilfældigheder?<br />
Opgave 9.12<br />
Udsættes planterne af en bestemt sort roser for meldugssmitte, bliver i middel brøkdelen p<br />
angrebet, hvor p er mindst 0.20. En rosengartner fremavler en rosenstamme, som han påstår<br />
er mere modstandsdygtig over for meldugssmitte. For at kontrollere denne påstand bliver 100<br />
roser af den nye stamme udsat for meldugssmitte. Det viser sig, at 12 roser bliver angrebet.<br />
1) Bekræfter dette resultat rosengartnerens påstand? (Husk altid at anføre: Hvad X er.<br />
Antagelser. Nulhypotese. Beregninger. Konklusion.).<br />
2) Angiv et estimat ~ p for den nye stammes p.<br />
3) Angiv et 95% konfidensinterval for den nye stammes p.<br />
108
109<br />
Opgaver til kapitel 9<br />
Opgave 9.13<br />
En fabrikant af chip til computere reklamerer med, at højst 2% af en bestemt type chip, som<br />
fabrikken sender ud på markedet er defekte.<br />
Et stort computerfirma vil købe et meget stort parti af disse chip, hvis påstanden er rigtigt. For<br />
at teste påstanden købes 1000 af dem. Det viser sig, at 33 ud af de 1000 er defekte.<br />
Kan fabrikantens påstand på denne baggrund forkastes på signifikansniveau 5% ?<br />
Opgave 9.14<br />
En producent af billigt plastiklegetøj får mange klager over at en bestemt type legetøj er<br />
defekt ved salget. Legetøjet sælges til butikkerne i kasser på 10 stk, og som et led i en<br />
kvalitetetskontrol udtages 100 kasser og antallet x af defekt legetøj optaltes. Følgende<br />
resultater fandtes:<br />
x 0 1 2 3 4 5 6<br />
Antal kasser 34 38 19 6 2 0 1<br />
Lad p være sandsynligheden for at få et defekt stykke legetøj.<br />
1) Find et estimat ~ p for p.<br />
2) Angiv et 95% konfidensinterval for p.<br />
Opgave 9.15<br />
Af 1000 tilfældigt udvalgte patienter, der led af lungekræft, var 823 døde senest 5 år efter<br />
sygdommen blev opdaget.<br />
Angiv på dette grundlag et 95% konfidensinterval for sandsynligheden for at dø af denne<br />
sygdom senest 5 år efter at sygdommen bliver opdaget.<br />
Opgave 9.16<br />
En fabrikant af lommeregnere vurderer, at ca. 1% af de producerede lommeregnere er defekte.<br />
For at få en nøjere vurdering heraf ønskes udtaget en stikprøve, der er så stor, at radius i et<br />
95% konfidensinterval for fejlprocenten p er højst 0.5%.<br />
Find stikprøvens størrelse n.<br />
Opgave 9.17<br />
Ved et køb af 100000 plastikbægre aftaltes med leverandøren, at det skal være en<br />
forudsætning for købet, at partiet godkendes ved en stikprøvekontrol.<br />
Kontrollen udøves ved, at 100 bægre udtages tilfældigt af partiet og kontrolleres. Partiet<br />
godkendes, såfremt ingen af de 100 bægre er defekte.<br />
Beregn sandsynligheden for, at partiet godkendes, hvis det i alt indeholder 250 defekte bægre.<br />
Opgave 9.18<br />
En fabrikant får halvfabrikata hjem i partier på 200000 enheder. Fra hvert parti udtages en<br />
stikprøve på 100 enheder og antallet af fejlagtige blandt disse noteres.<br />
Hvis dette antal er mindre end eller lig med 2, accepteres hele partiet; i modsat fald<br />
undersøges partiet yderligere.<br />
1) Hvad er sandsynligheden for, at et parti med en fejlprocent på 1 vil blive yderligere<br />
undersøgt.<br />
2) Hvor stor er sandsynligheden for, at et parti med en fejlprocent på 5 vil blive accepteret.
Vigtige diskrete fordelinger<br />
Opgave 9.19<br />
En maskinfabrikant påtænker at købe 100000 møtrikker af en bestemt type. Man beslutter sig<br />
til at købe et tilbudt parti af den nævnte størrelse, såfremt en stikprøve på 150 møtrikker højst<br />
indeholder 4% defekte møtrikker.<br />
1) Beregn sandsynligheden for, at partiet bliver godkendt af maskinfabrikken, såfremt det<br />
indeholder<br />
a) 4% defekte møtrikker,<br />
b) 2,5% defekte møtrikker,<br />
c) 7,5% defekte møtrikker,<br />
2) Bestem, for hvilken procentdel defekte møtrikker det ovennævnte parti (approksimativt)<br />
har 50% sandsynlighed for at blive godkendt af maskinfabrikken.<br />
Opgave 9.20<br />
På en fabrik fremstilles gulvtæpper, som har størrelsen 20 m 2 . Ved fabrikationen er der<br />
gennemsnitlig 6 vævefejl p. 100 m 2 klæde.<br />
1) Beregn sandsynligheden for, at et tilfældigt gulvtæppe ingen vævefejl har.<br />
2) Beregn sandsynligheden for, at et tilfældigt gulvtæppe højst har 2 vævefejl.<br />
Fabrikken køber en ny væv. For at få et estimat for middelværdien måltes antallet af vævefejl<br />
i 12 gulvtæpper hver på 20 m 2 . Resultaterne var<br />
Gulvtæppe nr 1 2 3 4 5 6 7 8 9 10 11 12<br />
Antal vævefejl 4 2 7 3 4 5 5 8 1 1 3 5<br />
3) Find et estimat for middelværdien af antal vævefejl p. 20 m 2 klæde.<br />
Opgave 9.21<br />
Et radioaktivt præparat undergår gennemsnitligt 100 desintegrationer (sønderdelinger) p.<br />
minut. Lad X betegne antal desintegrationer i et sekund (som er lille i forhold til præparatets<br />
halveringstid).<br />
Find P( X ≤ 1)<br />
.<br />
Opgave 9.22<br />
Ved en TV-fabrikation optælles som led i en godkendelseskontrol antal loddefejl p. 5 TVapparater.<br />
Fabrikanten ønsker at få et overblik over antal loddefejl, og optalte derfor antal<br />
loddefejl på 24 tilfældigt udtagne TV apparater. Resultatet fremgår af skemaet:<br />
Antal loddefejl 0 1 2 3 4 5 6 7 8 9<br />
Antal TV apparater 3 2 4 6 5 2 1 0 1 0<br />
Lad X være antallet af loddefejl i 5 TV apparater.<br />
1) Angiv den sandsynlighedsfordeling X approksimativt kan antages at følge, og giv et<br />
estimat for parameteren i fordelingen.<br />
2) Beregn på basis af svaret i spørgsmål 1 sandsynligheden for, at der på 5 tilfældigt udtagne<br />
TV-apparater højst er i alt 18 loddefejl?<br />
110
111<br />
Opgaver til kapitel 9<br />
Opgave 9.23<br />
På et teknisk universitet er et centralt edb-anlæg i konstant brug. Man har erfaring for, at<br />
anlægget i løbet af en 20 ugers periode har gennemsnitligt 7 maskinstop.<br />
Beregn sandsynligheden p for, at anlægget i en 4 ugers periode har mindst ét maskinstop.<br />
Opgave 9.24<br />
På en fabrik indtræffer i gennemsnit 72 ulykker om året. Antag, at de forskellige ulykker<br />
indtræffer uafhængigt af hinanden, og at de er nogenlunde jævnt fordelt over året.<br />
Beregn, idet et arbejdsår sættes lig med 48 uger, sandsynligheden for at der i en uge<br />
indtræffer flere end 3 ulykker.<br />
Opgave 9.25<br />
Til et bestemt telefonnummer er der i løbet af aftenen i middel 300 opkald i timen.<br />
Beregn sandsynligheden for, at der i løbet af et minut er højst 8 opkald.<br />
Opgave 9.26<br />
En fabrikation af fortinnede plader finder sted ved en kontinuerlig elektrolytisk proces.<br />
Umiddelbart efter produktionen kontrolleres for pladefejl. Man har erfaring for, at der i<br />
middel er 1 pladefejl hvert 5'te minut.<br />
Beregn sandsynligheden for, at der højst er 5 pladefejl ved en halv times produktion.<br />
Opgave 9.27<br />
Lastbiler med affald ankommer tilfældigt og indbyrdes uafhængigt til en losseplads.<br />
Lossepladsens maksimale kapacitet er beregnet til, at der i middel ankommer 90 lastbiler p.<br />
time. Ledelsen af pladsen føler, at travlheden er blevet større i den sidste tid, således at<br />
antallet af lastbiler overskrider den maksimale kapacitet. For at undersøge dette, foretages en<br />
optælling af lastbiler i perioder à 10 minutter. Følgende resultater fremkom:<br />
13 16 17 15 18 12 22 16 21 18<br />
1) Bekræfter disse resultater ledelsens formodning? (Husk altid at anføre: Hvad X er.<br />
Antagelser. Nulhypotese. Beregninger. Konklusion.).<br />
2) Angiv et estimat ~µ for middelværdien µ [lastbiler/time].<br />
3) Angiv et 95% konfidensinterval for middelværdien µ [lastbiler/time].<br />
Opgave 9.28<br />
Nedenstående tabel viser fordelingen af 400 volumenenheder med hensyn til antal gærceller<br />
p. volumenenhed.<br />
Antal gærceller 0 1 2 3 4 5 6 7 8 9 10 11 12<br />
Antal volumenenheder 0 20 43 53 86 70 54 37 18 10 5 2 2<br />
Lad X være antal gærceller p. volumenenhed. Det antages, at X er en stokastisk variabel der er<br />
Poissonfordelt p ( µ ).<br />
1) Find et estimat ~µ for µ .<br />
2) Angiv et 95% konfidensinterval for µ .<br />
3) Forudsat at X er Poissonfordelt p ( ~µ ) ønskes beregnet det forventede antal<br />
volumenenheder, hvori der forekommer 5 gærceller (for x = 5).
Vigtige diskrete fordelinger<br />
Opgave 9.29<br />
Ved inspektion af en produktion med isolering af kobberledning taltes der i løbet af 50<br />
minutter i alt 11 isoleringsfejl.<br />
Idet antallet af isoleringsfejl p. 50 minutter antages at være Poissonfordelt p ( µ 1 ), skal man<br />
1a) angive et estimat for .<br />
µ 1<br />
µ 1<br />
1b) angive et 95% konfidensinterval for .<br />
Det oplyses nu, at man i hver 5 minutters periode i den ovenfor omtalte 50 minutters periode<br />
havde observeret følgende antal isoleringsfejl:<br />
Periode 1 2 3 4 5 6 7 8 9 10<br />
Antal fejl 1 0 2 2 1 1 3 0 1 0<br />
Idet antallet af isoleringsfejl p. 5 minutter antages at være Poissonfordelt p ( ), skal man<br />
2a)<br />
2b)<br />
angive et estimat for µ 2 .<br />
angive et 95% konfidensinterval for .<br />
µ 2<br />
Opgave 9.30<br />
I en urne findes 10 røde kugler, 5 hvide kugler og 3 sorte kugler.6 gange efter hinanden optages tilfældigt en kugle fra urnen.<br />
Bestem sandsynligheden for, at der i alt er optaget 1 rød, 2 hvide og 3 sorte kugler, når<br />
1) kuglerne optages uden tilbagelægning<br />
2) kuglerne optages med tilbagelægning.<br />
Opgave 9.31<br />
En virksomhed fabrikerer farvede glasklodser til dekorationsbrug. Defekte glasklodser frasorteres. Man har erfaring for, at af<br />
de frasorterede klodser har i middel 50% kun revner, 35% kun farvefejl, medens resten har begge disse fejl.<br />
Beregn sandsynligheden for, at af 12 tilfældige defekte klodser har 6 kun revner, 4 kun farvefejl og 2 begge disse fejl.<br />
Opgave 9.32<br />
I et kortspil med de sædvanlige 52 spillekort har en spiller modtaget 13 kort. Angiv i procent med 2 decimaler<br />
sandsynligheden for, at 3 af disse er esser og 5 er billedkort.<br />
112<br />
µ 2
113<br />
10.2 Den rektangulære fordeling<br />
10 ANDRE KONTINUERTE FORDELINGER<br />
10.1 INDLEDNING<br />
Vi vil i dette kapitel kort orientere om en række fordelinger, som er vigtige i specielle<br />
sammenhænge,<br />
10.2 DEN REKTANGULÆRE FORDELING<br />
DEFINITION af rektangulær fordeling med parametrene a og b.<br />
Lad a og b være to reelle tal, hvor a
Eksempel 10.1 Kontinuert variabel.<br />
Lad randen af en roulette være ækvidistant inddelt efter en<br />
skala fra 0 til 12, jævnfør figuren.<br />
Ved et roulettespil bringes roulettens viser til at rotere,<br />
hvorefter den standser ud for et tilfældigt punkt på skalaen.<br />
Lad X være det tal som roulettens viser peger på.<br />
Idet X må kunne antage ethvert tal mellem 0 og 12, må X<br />
være en kontinuert variabel.<br />
Angiv tæthedsfunktion og fordelingsfunktion for X og<br />
skitser disse.<br />
LØSNING:<br />
x<br />
Da P( 0 ≤ X ≤ x)<br />
= for 0≤ x ≤12<br />
12<br />
er fordelingsfunktionen for X<br />
⎧0<br />
for x ≤ 0<br />
⎪ x<br />
F( x)=<br />
⎨ for 0≤ x ≤12<br />
⎪12<br />
⎪<br />
⎩1<br />
for x ≥ 12<br />
Ved differentiation fås tæthedsfunktionen<br />
⎧ 1<br />
⎪ for 0≤ x ≤12<br />
f ( x)=<br />
⎨12<br />
⎪<br />
⎩0<br />
ellers<br />
114
10.3 EKSPONENTIALFORDELINGEN<br />
115<br />
10.3 Eksponentialfordelingen<br />
I kapitel 7 betragtede vi antallet N af revner pr. meter langs et kobberkabel. Vi antog, at N var<br />
Poissonfordelt. Hvis vi i stedet havde betragtet afstanden X mellem revnerne, havde vi fået en ny<br />
stokastisk variabel, som må være kontinuert. Som det fremgår af følgende sætning er X<br />
eksponentialfordelt.<br />
SÆTNING 10.2 (Eksponentialfordeling).<br />
Lad W være en Poissonfordelt stokastisk variabel.<br />
Lad det gennemsnitlige antal impulser i en tidsenhed være λ . Lad X være tiden indtil<br />
næste impuls.<br />
X er da en kontinuert stokastisk variabel med sandsynlighedsfordelingen<br />
(tæthedsfunktionen)<br />
f ( x ) = P ( X = x) bestemt ved<br />
x ⎧ 1 −<br />
µ<br />
⎪ ⋅ e for x><br />
0<br />
f ( x)=<br />
⎨ µ<br />
⎪<br />
⎩0<br />
ellers<br />
hvor<br />
Bevis:<br />
I tidsrummet fra x0 til x0 + x er der I gennemsnit λ ⋅ x impulser. Lad W være det aktuelle antal impulser i tidsrummet<br />
[x0 ; x0 + x ]. W er da Poissonfordelt p( λ ⋅ x)<br />
.<br />
Idet X er tiden fra én impuls til den næste, er P( X > x) = P( W = 0)<br />
, da der ingen impulser er i tidsrummet<br />
[x0 ; x0 + x ].<br />
0<br />
( λ ⋅ x) −λ⋅x −λ⋅x − ⋅x<br />
Da PW ( = 0)<br />
= ⋅ e = e , er P( X > x)<br />
= e .<br />
0!<br />
λ<br />
− ⋅x<br />
Vi har derfor F( x) = P( X ≤ x) = 1− P( X > x)<br />
= 1−e . λ<br />
−λ⋅x Ved differentiation fås tæthedsfunktionen: f ( x) = F'( x)<br />
= λ ⋅e. Sættes λ = fås formlen.<br />
µ<br />
1<br />
Bevis for middelværdi og spredning:<br />
∞<br />
∞<br />
−λ⋅x ⎡ −λ⋅x 1 ⎤ 1<br />
E( X) = ∫ λ ⋅x⋅ e dx = -e ( x−<br />
= = µ<br />
0<br />
⎣⎢<br />
− λ⎦⎥ λ<br />
∞<br />
2 2 ⎡ ⎛<br />
⎞ ⎤<br />
2 −λ⋅x 2<br />
V( X) = E( X ) − ( E( X) ) = ∫ λ ⋅x ⋅e dx − µ = ⎜ − + ⎟<br />
0<br />
⎢<br />
⎣ ⎝<br />
⎠ ⎥<br />
⎦<br />
−<br />
− ⋅<br />
-e λ x 2 2x2 x<br />
2<br />
λ λ<br />
0<br />
µ =<br />
λ<br />
1<br />
X siges at være eksponentialfordelt exp ( µ ) med parameteren µ<br />
.<br />
∞<br />
0<br />
2 2<br />
2<br />
2 2<br />
µ = − µ = µ .<br />
λ<br />
Som det fremgår af beviset for sætning 10.2, er fordelingsfunktionen for en eksponentialfordelt<br />
variabel bestemt ved udtrykket<br />
x<br />
⎧ −<br />
⎪ µ<br />
F( x) = P( X ≤ x)<br />
=<br />
1− e for x > 0<br />
⎨<br />
⎩<br />
⎪0<br />
ellers
Andre kontinuerte fordelinger<br />
På nedenstående graf er afbildet tæthedsfunktionen for eksponentialfordelingerne exp(1.0) og<br />
exp(2.0)<br />
1<br />
0,8<br />
0,6<br />
0,4<br />
0,2<br />
0<br />
0 2 4 6 8 10 12<br />
Fig 10.1 Eksponentialfordelingerne exp(1) og exp(2)<br />
Eksempel 10.2. Afstanden mellem successive revner i kabel.<br />
Vi betragter det i eksempel 5.1 omtalte problem, hvor man fandt, at antallet N af mikroskopiske<br />
revner i et kobberkabel er Poissonfordelt. Der var i gennemsnit 12.3 af den type revner pr. 10<br />
meter. Lad X være afstanden mellem to på hinanden følgende revner.<br />
Beregn sandsynligheden for, at der er mere end 1 meter mellem to revner.<br />
LØSNING:<br />
1<br />
Da der i gennemsnit er 1.23 revner pr. meter, må der i gennemsnit være = 0812 . meter mellem<br />
123 .<br />
to revner. Vi har derfor at X er eksponentialfordelt med µ = 0.813.<br />
1<br />
⎛ − ⎞ 0813 .<br />
−123<br />
.<br />
P( X > 1) = 1− P( X ≤ 1) = 1− ⎜1<br />
− e ⎟ =e = 0. 2923<br />
⎝ ⎠<br />
Levetider. I apparater, som består af elektroniske komponenter (eksempelvis lommeregnere),<br />
er der et meget ringe mekanisk slid. Apparatets fremtidige levetid vil derfor (næsten ikke)<br />
afhænge af, hvor længe det har fungeret indtil nu. I sådanne tilfælde vil eksponentialfordelingen<br />
erfaringsmæssigt være en god approksimativ model for apparatets levetid.<br />
Det kan nemlig vises, at eksponentialfordelingen er den eneste kontinuerte fordeling, som har<br />
ovennævnte egenskab (er uden hukommelse)<br />
Bevis: Lad X være eksponentialfordelt med middelværdi µ og lad b > a > 0 være vilkårlige konstanter. Der gælder<br />
da:<br />
( ( > + ) ∧ ( > ) )<br />
P X a b X a<br />
P( X > a + bX > a)<br />
=<br />
P( X > a)<br />
116<br />
a b<br />
− +<br />
µ<br />
P( X > a + b)<br />
e<br />
−<br />
µ<br />
=<br />
= b =e = P( X > b)<br />
P( X > a)<br />
−<br />
µ<br />
e<br />
b
1)<br />
Γ ( x)<br />
10.6 Den 2-dimensionale normalfordeling<br />
Eksempel 10.3. Levetid for elektriske pærer.<br />
Man har erfaring for, at en bestemt type elektriske pærer har en "brændtid" T (målt i timer), som<br />
approksimativt er eksponentialfordelt. På basis af et stort antal målinger ved man , at<br />
middellevetiden er µ = 1500 timer.<br />
1) Hvor stor er sandsynligheden for, at en tilfældig pære brænder over, inden den har været tændt<br />
i 1200 timer?<br />
2) Find sandsynligheden for, at en tilfældig pære brænder i mere end 1800 timer.<br />
3) En pære har brændt i 800 timer. Hvad er sandsynligheden for, at den brænder i mindst 1800<br />
timer mere.<br />
LØSNING:<br />
1) PT ( < ) = F(<br />
) = − . .<br />
−<br />
1200<br />
1500<br />
1200 1200 1 e = 1- 0.449 = 551%<br />
1800<br />
−<br />
2) 1500<br />
PT ( > 1800) = 1− F(<br />
1800) = e = 3012% .<br />
3) Da eksponentialfordelingen ingen hukommelse har, vil svaret blive som i spørgsmål 2, dvs.<br />
30.12%.<br />
10.4 WEIBULLFORDELINGEN<br />
Hvis komponenterne i et elektronisk apparat ikke “slides”, dvs. den fremtidige levetid ikke<br />
afhænger af den foregående tid, er som nævnt i afsnit 10.3 eksponentialfordelingen velegnet som<br />
model for apparatets levetid.<br />
Hvis derimod de pågældende komponenters eventuelle svigten afhænger af den forløbne tid, kan<br />
man ofte med fordel benytte den i det følgende nævnte Weibullfordeling som approksimativ<br />
model for apparatets levetid (model for apparatets pålidelighed).<br />
DEFINITION af Weibulfordeling. Lad k og µ være positive tal. Sandsynlighedsfordelingen<br />
for en kontinuert stokastisk variabel X med tæthedsfunktionen f ( x ) bestemt ved<br />
x<br />
k k<br />
f x<br />
x for x<br />
k<br />
ellers<br />
k<br />
⎧<br />
−<br />
⎪<br />
−<br />
( ) =<br />
⋅ ⋅ ><br />
⎨<br />
⎪<br />
⎩<br />
⎛ ⎞<br />
⎜ ⎟<br />
1 ⎝ µ ⎠<br />
e<br />
0<br />
µ<br />
0<br />
siges at være Weibullfordelingen wei( k,<br />
µ<br />
) .<br />
⎛ k + 1⎞<br />
µ E( X)<br />
= µ ⋅Γ⎜<br />
⎟<br />
⎝ k ⎠<br />
⎛ k + 2⎞⎛⎛k+ 1⎞⎞ Γ⎜⎟−⎜ ⎟<br />
⎝ k ⎠<br />
⎜ Γ<br />
⎝ ⎝ k ⎠<br />
⎟<br />
⎠<br />
2<br />
Det kan vises, at Weibullfordelingen wei( k,<br />
) har middelværdien<br />
og spredningen σ ( X ) = µ ⋅<br />
Det ses, at Weibullfordelingen kan opfattes som en generalisation af eksponentialfordelingen,<br />
idet wei( 1 , µ ) = exp( µ ) .<br />
Såfremt levetiderne for komponenter i et apparat aftager jo længere tid apparatet har været i<br />
funktion (på grund af slid), kan man benytte en Weibullfordeling med k > 1 som approksimativ<br />
model for apparatets levetid.<br />
Gammafunktionen<br />
<strong>grundbegreber</strong>” 3A<br />
er defineret i “Supplement til statistiske<br />
117<br />
1 )
Andre kontinuerte fordelinger<br />
10.5 DEN LOGARITMISKE NORMALFORDELING<br />
Indenfor det biokemiske eller biologiske område (forsøgsdyrs reaktionstid, cellevækst m.v.) er<br />
den stokastiske variabel X ikke normalfordelt, men hvis man foretager en logaritmisk<br />
transformation Y = ln X er Y (approksimativt) normalfordelt.<br />
Man siger så, at X er logaritmisk normalfordelt.<br />
Tæthedsfunktionen for X er bestemt ved f x<br />
for x > 0.<br />
x e<br />
2<br />
1 ⎛ ln x−<br />
µ ⎞<br />
1 1 − ⋅⎜<br />
⎟<br />
2 ⎝ σ ⎠<br />
( ) =<br />
2π<br />
⋅σ<br />
Det kan vises, at mens Y = ln X har middelværdi µ og spredning σ har X middelværdi<br />
µ 2<br />
E( X) = e ⋅e<br />
2µ<br />
σ<br />
og V( X)<br />
= e ⋅e σ<br />
⋅( e −1)<br />
.<br />
Nedenfor er tegnet en logaritmisk normalfordeling med middelværdi 8 og spredning 5.<br />
density<br />
1 2<br />
− ⋅σ<br />
0,15<br />
0,12<br />
0,09<br />
0,06<br />
0,03<br />
0<br />
Lognormal Distribution<br />
0 10 20 30 40<br />
x<br />
2 2<br />
118<br />
Mean,Std. dev<br />
8,5<br />
10.6 DEN 2-DIMENSIONALE NORMALFORDELING<br />
Flerdimensionale fordelinger vil blive omtalt nærmere i kapitel 9. Her nævnes uden forklaring<br />
et eksempel herpå.<br />
DEFINITION af 2-dimensional normalfordeling Lad µ 1, µ 2 være reelle tal og σ1, σ 2 være<br />
positive tal. Sandsynlighedsfordelingen for 2-dimensional kontinuert stokastisk variabel (X1,X2) med tæthedsfunktion bestemt ved<br />
1<br />
−<br />
⋅ −<br />
⎛<br />
2<br />
2<br />
⎛ x − ⎞ x − x − ⎛ x − ⎞ ⎞<br />
⋅⎜<br />
1 µ 1<br />
⎜ ⎟ −2<br />
1 µ 1⋅2<br />
µ 2 + 2 µ<br />
ρ<br />
2<br />
⎜ ⎟ ⎟<br />
σ ⎝ ⎠ ⎟<br />
2 σ 2 ⎠<br />
1<br />
f ( x) =<br />
2π ⋅σ1⋅σ2 2<br />
1−<br />
ρ<br />
2 ( 1<br />
⋅ e<br />
2<br />
ρ ) ⎜<br />
⎝ ⎝ σ1<br />
⎠ σ1<br />
kaldes den 2-dimensionale normalfordeling med<br />
parametrene µ µ , og .<br />
1, 2 σ 1 σ 2<br />
Det kan vises, at E( X1)<br />
= µ 1,<br />
E( X2)<br />
= µ 2,<br />
σ( X 1) = σ1,<br />
σ( X 2) = σ 2 og ρ( X1, X2<br />
) = ρ<br />
( defineres i kapitel 9).<br />
Grafen ses overfor.
119<br />
Opgaver til kapitel 10<br />
OPGAVER<br />
Opgave 10.1<br />
På et betalingsnummer måltes man i tidsrummet fra kl 20 til 22 tiden t (antal minutter) mellem<br />
på hinanden følgende telefonopkald. Følgende resultater fandtes:<br />
Beliggenhed af t ]0;1] ]1;2] ]2;3] ]3;4] ]4;5] ]5;6] ]6;7] ]7;8] ]8;9] ]9;10] ]10; ∞ [<br />
Antal observationer. 36 21 16 13 7 9 6 1 2 6 0<br />
Det antages, at antallet N af telefonopkald til nummeret er Poissonfordelt. Lad T være tiden<br />
mellem to opkald.<br />
1) Angiv fordelingsfunktionen for T, og giv et estimat for middelværdien µ .<br />
Vink: Antage, at for alle observationer i et interval er tidsrummet mellem observationerne<br />
intervallets midterværdi.<br />
2) På baggrund af den i spørgsmål 1 fundne estimat for µ , ønskes bestemt P( 2< T ≤3)<br />
.<br />
3) Af tabellen ses, at i intervallet ]2; 3] forekommer i alt 16 observationer. Angiv hvor mange<br />
observationer man må forvente, ud fra resultatet i spørgsmål 2.<br />
Opgave 10.2<br />
Om en bestemt type elektriske komponenter vides, at deres levetider er eksponentialfordelte med<br />
en middellevetid på 800 timer.<br />
1) Find sandsynligheden for, at en komponent holder mindst 200 timer.<br />
2) Find sandsynligheden for, at en komponent holder mellem 600 og 800 timer.<br />
3) En komponent har holdt i 900 timer. Find sandsynligheden for, at den kan holde i mindst 200<br />
timer mere.<br />
4) I et elektrisk system indgår netop én komponent af denne type. Hver gang komponenten<br />
svigter, udskiftes den øjeblikkeligt med en ny komponent af samme type. Find<br />
sandsynligheden for, at komponenten udskiftes 12 gange i løbet af 8000 timer.<br />
Opgave 10.3<br />
Antag, at levetiderne for en bestemt slags elektroniske komponenter er uafhængige og alle er<br />
eksponentialfordelt med en middellevetid på 3 (år). Betragt et delsystem bestående af 3 sådanne<br />
komponenter i seriekobling:<br />
(en seriekobling ophører at fungere, når én af komponenterne ophører at fungere).<br />
Bestem middellevetiden for et sådant system.<br />
Opgave 10.4<br />
Nedbrydningstiden i den menneskelige organisme for et givet kvantum af et bestemt stof antages<br />
at være eksponentialfordelt med middelværdien 5 timer.<br />
Ved et forsøg indsprøjtes stoffet samtidig i 10 patienter.<br />
1) Beregn sandsynligheden (afrundet til et helt antal procent) for, at stoffet hos en tilfældig valgt<br />
patient vil være nedbrudt efter 8 timers forløb.<br />
2) Beregn sandsynligheden for, at stoffet efter 8 timers forløb vil være nedbrudt hos mindst 5 af<br />
patienterne.<br />
3) Efter hvor mange timers forløb vil der være ca. 90% sandsynlighed for, at stoffet er nedbrudt<br />
hos samtlige 10 patienter?<br />
4) Hvor mange patienter skal indgå i en ny undersøgelse, hvis der skal være ca. 95%<br />
sandsynlighed for, at der er mindst en patient, hvis organisme efter 8 timers forløb endnu ikke<br />
har nedbrudt stoffet?
Bjarne Hellesen:<br />
11 FLERDIMENSIONAL<br />
STOKASTISK VARIABEL<br />
ESSENS<br />
Kovariansen V( Xi, X j) = E ( Xi − µ 1) ⋅( X2<br />
− µ 2)<br />
er et mål for to variables tendens til<br />
at variere i takt med hinanden (samvarians). Kovariansen er f.eks. positiv(negativ), når afvigelsen<br />
X i − µ i har en tendens til at være positivt (negativt) proportional med afvigelsen X j − µ j.<br />
Er<br />
X og X i j statistisk uafhængige, bliver kovariansen 0 (men man kan ikke slutte den anden vej).<br />
V( Xi, X j)<br />
Korrelationskoefficienten ρ(<br />
Xi, X j)<br />
≡<br />
er normeret , så − 1≤ρ( Xi, X j)<br />
≤ 1 .<br />
σ ⋅σ<br />
X2<br />
95<br />
85<br />
75<br />
65<br />
55<br />
45<br />
150 160 170 180 190 200<br />
X1<br />
( )<br />
X3<br />
45<br />
150 160 170 180 190 200<br />
X1<br />
Stikprøve viser positiv<br />
Stikprøve viser ingen<br />
korrelation: ρ( X1, X2)<br />
≈ 084 . . korrelation: ρ( X , X ) = .<br />
.<br />
85<br />
75<br />
65<br />
55<br />
120<br />
i j<br />
1 2 000<br />
X4<br />
64<br />
54<br />
44<br />
34<br />
24<br />
14<br />
150 160 170 180 190 200<br />
X1<br />
Stikprøve viser negativ<br />
korrelaton: ρ( X , X ) ≈− . .<br />
1 2 084<br />
2<br />
Poolet estimat spool<br />
=<br />
2 2 2<br />
fs 1 1+<br />
fs 2 2 + ... + fs k k<br />
med fpool f1 + f2+ ... + fk<br />
= f1 + f2 + ... + fkfrihedsgrader<br />
benyttes,<br />
når man har k uafhængige estimater for den samme varians σ :<br />
2<br />
2 SAK1<br />
2 SAK2<br />
2 SAKk<br />
s1<br />
= , s2<br />
= ,..., sk<br />
= ,<br />
f1<br />
f 2<br />
f k<br />
2<br />
Har to stikprøver givet estimaterne s1 2<br />
= 2345 . , s2 = 3456 . med f1 = 6, f2<br />
= 4 frihedsgrader,<br />
2<br />
bliver det poolede estimat spool<br />
=<br />
2<br />
fs 1 1 +<br />
f1 +<br />
2<br />
fs 2 2<br />
=<br />
f2<br />
6 ⋅ 2. 345 + 4 ⋅3456<br />
.<br />
= 2. 7894 ≈ 2. 789<br />
6+ 4<br />
med f pool = f1 + f2<br />
= 6+ 4 = 10<br />
frihedsgrader.
121<br />
11.1 Indledning<br />
Linearitetsreglen E( a0 + a1X1 + a2X2+ ... + akXk) = a0 + a1E( X1) + a2E( X2) + ... + akE( Xk)<br />
,<br />
(a’erne er konstanter).<br />
Er E( X1)<br />
= 2 , E( X2)<br />
= 3 fås<br />
E( 4+ 5X + 6X ) = 4+ 5E( X ) + 6E( X ) = 4+ 5⋅ 2+ 6⋅ 3= 32.<br />
1 2 1 2<br />
Kvadratreglen V( a + a X + a X + ... + a X )<br />
0 1 1 2 2<br />
k k<br />
2<br />
2<br />
2<br />
= aV( X) + aV( X ) + ... + aV( X ) + 2 aaV( X, X )<br />
1<br />
1 2<br />
2<br />
k<br />
∑<br />
∑<br />
k k i j i j<br />
i=<br />
1 j=+ i 1<br />
Er V( X1) = 2, V( X2) = 3, V( X1, X2)<br />
= 15 . , fås<br />
2<br />
2<br />
V( 4 + 5X1 + 6X2) = 5 V( X1) + 6 V( X2) + 2⋅5⋅6⋅V( X1, X2)<br />
2 2<br />
= 5 ⋅ 2 + 6 ⋅ 3+ 2⋅5⋅6⋅ 15 . = 248<br />
11.1 INDLEDNING<br />
Ved anvendelserne optræder der ofte rflere<br />
stokastiske variable X1, X2,..., Xkad gangen. Det kan da være<br />
naturligt at samle dem i et ordnet sæt X = ( X1, X2,..., Xk) , som kaldes en k-dimensional stokastisk variabel.<br />
Eksempelvis:<br />
* Et levnedsmiddel kan af en tilfældig r udtaget forbruger bedømmes ved en karakter for smagen og en<br />
karakter for lugten. Så er X = ( X , X ) = ( ) en 2-dimensional stokastisk variabel.<br />
X 2<br />
1 2 Smag,Lugt<br />
* Et tilfældigt eksperiment r går ud på at udtage en tilfældig person og måle vedkommendes højde og masse<br />
X 2 . Så er X = ( X , X ) = ( ) en 2-dimensional stokastisk variabel.<br />
1 2 Højde, Masse<br />
r<br />
* Ugens 7 lottotal udgør en 7-dimensional stokastisk variabel X = ( X , X ,..., X ) .<br />
1 2 7<br />
r<br />
* Et tilfældigt eksperiment går ud på at kaste en rød og en hvid terning. Så er X = ( X , X ) = (Antal øjne op<br />
1 2<br />
på rød terning, Antal øjne op på hvid terning) en 2-dimensional stokastisk variabel.<br />
For hver af de 1-dimensionale stokastiske variable X1, X2,..., Xkhar vi tidligere defineret:<br />
* Fordelingsfunktioner F1, F2,..., Fk: F( X ) ≡ P( X ≤ x ), F ( X ) ≡ P( X ≤ x ), . . . , F ( X ) ≡ P( X ≤ x ) .<br />
1 1 1 1<br />
2 2 2 2<br />
k<br />
k k k k<br />
* Tæthedsfunktioner f1, f2,..., fk, når X X X er diskrete variable:<br />
1, 2,...,<br />
k<br />
f ( x ) ≡ P( X = x ) , f ( x ) ≡ P( X = x ) , . . . , f ( x ) ≡ P( X = x ) ,<br />
1 1 1 1<br />
2 2 2 2<br />
og når de er kontinuerte variable:<br />
dF1( x1)<br />
dF2( x2)<br />
dFk( x k)<br />
f1( x1)<br />
≡ , f2( x2)<br />
≡ , . . . , f k( xk)<br />
≡ .<br />
dx<br />
dx<br />
dx<br />
1<br />
2<br />
k k k k<br />
* Middelværdier, når X1, X2,..., Xker diskrete variable:<br />
E( g( X ) ≡ g( x ) ⋅ f ( x ) , . . . , E( g( X ) ≡ g( x ) ⋅ f ( x ) ,<br />
( )<br />
∑ ( )<br />
1 1 1 1<br />
x1<br />
∑<br />
k<br />
k k k k<br />
xk og når de er kontinuerte variable:<br />
E( g( X ) ≡<br />
∞<br />
g( x ) ⋅ f ( x ) dx , . . . , E( g( X ) ≡<br />
∞<br />
g( x ) ⋅ f ( x ) dx ,<br />
( )<br />
∫ ( )<br />
1 1 1 1 1<br />
−∞<br />
∫<br />
k k k k k<br />
−∞<br />
specielt<br />
µ 1 ≡ E( X1) ≡ ∑ x1⋅ f1( x1)<br />
, . . . , µ k ≡ E( X2) ≡ ∑ xk ⋅ fk( xk)<br />
,<br />
og<br />
x1<br />
xk<br />
≡ E X ≡<br />
∞<br />
x ⋅ f x dx , . . . , ≡ E( X ) ≡<br />
∞<br />
x ⋅ f ( x )<br />
dx .<br />
∫<br />
µ 1 ( 1) 1 1( 1) 1 µ k k k k k k<br />
−∞<br />
−∞<br />
∫<br />
.<br />
X 1<br />
X 1
Flerdimensional statistisk variabel<br />
Af definitionen på middelværdi følger linearitetsreglen:<br />
Ea ( ⋅ gX ( i) + bhX ⋅ ( i) ) = a⋅ EgX ( ( i) ) + bEhX ⋅ ( ( i)<br />
) .<br />
r<br />
For en k-dimensional stokastisk variabel X = ( X X X definerer vi analogt:<br />
1, 2,...,<br />
k )<br />
* Fordelingsfunktionen F : ( ∧ betyder “både og”)<br />
F( x1, x2, ..., xk) ≡ P( X1 ≤ x1) ∧ P( X2 ≤ x2) ∧... ∧P( X k ≤ xk)<br />
.<br />
* Tæthedsfunktionen f, når X1, X2,..., X k er diskrete variable:<br />
f ( x1, x2, ..., xk) ≡ P( X1 = x1) ∧ P( X2 = x2) ∧... ∧ P( X k = xk)<br />
k<br />
F( x1, x2,..., xk)<br />
og når de er kontinuerte variable: f ( x1, x2, ..., xk)<br />
≡ .<br />
x1 x2,..., xk<br />
∂<br />
∂ ∂ ∂<br />
* Middelværdier, når X1, X2,..., Xker diskrete variable:<br />
E g( X , X ,..., X ) = ... g( x , x ,..., x ) ⋅ f ( x , x ,..., x )<br />
( )<br />
∑∑<br />
∑<br />
1 2 k 1 2 k 1 2<br />
x1 x2<br />
xk<br />
og når de er kontinuerte variable:<br />
( )<br />
∫<br />
∞<br />
∞<br />
∫ ∫<br />
∞<br />
EgX ( 1, X2,..., X k) = dx1 dx2... gx ( 1, x2,..., xk) ⋅ f( x1, x2,..., xk) dxk<br />
−∞ −∞<br />
−∞<br />
r r r r<br />
Af definitionen på middelværdi følger linearitetsreglen: Ea ( ⋅ gX ( ) + bhX ⋅ ( ) ) = a⋅ EgX ( ( ) ) + bEhX ⋅ ( ( ) )<br />
De variable X1, X2,..., Xkkaldes stokastisk uafhængige, såfremt de for alle værdier af x1, x2,..., xkopfylder betingelsen: f ( x , x ..., x ) = f ( x ) ⋅ f ( x ) ⋅... ⋅ f ( x ) ,<br />
1 2 k 1 1 2 2<br />
k k<br />
der kan vises at være ækvivalent med betingelsen: Fx ( , x..., x) = F( x) ⋅F( x) ⋅... ⋅F(<br />
x)<br />
.<br />
122<br />
k<br />
1 2 k 1 1 2 2<br />
k k<br />
r<br />
En rstikprøve r raf<br />
størrelsen n på en stokastisk variabel X = ( X , X ,..., X defineres som<br />
1 2 k )<br />
( X1, X2,..., Xn) = ( ( X11, X21,..., Xk1),( X12, X22,..., Xk2),...,( X1n, X2n,..., Xkn)<br />
r r r<br />
) r<br />
hvor X1, X2,..., Xner statistisk uafhængige variable, der hver har samme fordeling som X .<br />
Eksempel 11.1. 2-dimensional stokastisk variabel.<br />
Et levnedsmiddel kan af en tilfældig forbruger bedømmes ved en karakter for smagen og en karakter for<br />
X 1<br />
lugten. Karakteren kan antage værdierne 0, 1 og 2, mens kun kan antage værdierne 0 og 2.<br />
a) Antag, at man teoretisk kender tæthedsfunktionen f ( x , x ) :<br />
x 2<br />
f ( x1, x2)<br />
x1 1 2<br />
X 2<br />
X 1<br />
0 1 2<br />
0 0.2 0.1 0.1<br />
2 0.1 0.2 0.3<br />
a1) Find de 1-dimensionale tæthedsfunktioner f1( x1)<br />
og f2( x2)<br />
.<br />
a2) Er X 1 og X 2 statistisk uafhængige ?<br />
a3) Find middelværdierne µ 1 = E( X1)<br />
og µ 2 = E( X2)<br />
samt spredningerne σ1 = σ(<br />
X1) og σ 2 = σ(<br />
X 2)<br />
.<br />
a4) Find middelværdien E( X1, X2)<br />
.<br />
b) Antag, at man i stedet kender en stikprøve på ( X1, X2)<br />
:<br />
(1,2), (0,0), (2,2), (2,2), (1,0), (2,2), (0,2), (2,2), (0,2 ), (2,2).<br />
b1) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a3).<br />
LØSNING:<br />
a1) Ved summation ned gennem de lodrette søjler i tabellen for tæthedsfunktionen<br />
f ( x1, x2) ≡ P( X1 = x1 ∧ X2 = x2)<br />
fås den 1-dimensionale tæthedsfunktion f1( x1) = P( X1 = x1)<br />
:<br />
f1( 0) = 02 . + 01 . = 03 . , f1() 1 = 01 . + 02 . = 03 . , f1( 2) = 01 . + 03 . = 04 . .<br />
Ved summation hen gennem de vandrette rækker i tabellen for tæthedsfunktionen f ( x1, x2)<br />
fås analogt den<br />
1-dimensionale tæthedsfunktion f2( x2)<br />
:<br />
f 2( 0) 02 . 01 . 01 . 04 . , ( ) = . + . + . =<br />
. .<br />
= + + = f 2 2 01 02 03 06<br />
X 2
123<br />
11.1 Indledning<br />
a2) De variable X 1 og X 2 er statistisk uafhængige, hvis og kun hvis f ( x1, x2) = f1( x1) ⋅ f2( x2)<br />
for alle<br />
værdier af ( x1, x2)<br />
i definitionsmængden. Men da f.eks. f1( 0) ⋅ f2(<br />
0) = 03 . ⋅ 04 . = 012 . er forskellig fra<br />
f (,) 00 02 . , er og ikke statistisk uafhængige.<br />
= X 1 X 2<br />
a3) Vi finder<br />
µ 1 = E( X1) = ∑ x1 ⋅ f1( x1) = 0⋅ f1( 0) + 1⋅ f1( 1) + 2⋅ f1(<br />
2)<br />
= 003 ⋅ . + 103 ⋅ . + 204 ⋅ . = 11 .<br />
= E( X ) = x ⋅ f ( x ) = 0⋅ f ( 0) + 2⋅ f ( 2) = 0⋅ 04 . + 2⋅ 06 . = 12 .<br />
∑<br />
µ 2 2 2 2 2 2 2<br />
2 ( )<br />
2<br />
σ = σ ( X ) ≡ V( X ) ≡ E ( X − µ ) = ( x − µ ) ⋅ f ( x )<br />
1 1 1 1 1<br />
∑<br />
1 1<br />
2 2 2<br />
= ( 0 −11 . ) ⋅ 0. 3 + ( 1−11 . ) ⋅ 0. 3 + ( 2 −11 . ) ⋅ 0. 4 = 0. 69 = 083067 .<br />
2 ( )<br />
1 1<br />
2<br />
σ = σ ( X ) ≡ V( X ) ≡ E ( X − µ ) = ( x − µ ) ⋅ f ( x )<br />
2 2 2 2 2<br />
∑<br />
2 2<br />
2 2<br />
=<br />
2 2<br />
( 0 −12 . ) ⋅ 0. 4 + ( 2 −12 . ) ⋅ 0. 6 = 0. 96 = 0. 97980<br />
a4) Vi finder<br />
E( X1 ⋅ X2) ≡ ∑ ∑ x1 ⋅ x2 ⋅ f ( x1, x2)<br />
= 00 ⋅ ⋅ f ( 00 , ) + 10 ⋅ ⋅ f ( 10 , ) +<br />
x1<br />
x2<br />
2⋅0⋅ f (,) 20 + 0⋅2⋅ f (,) 02 + 1⋅2⋅ f (,) 12 + 2⋅ 2⋅ f (,) 22<br />
= 0⋅ 02 . + 0⋅ 01 . + 0⋅ 01 . + 0⋅ 01 . + 2⋅ 02 . + 4⋅ 03 . = 16 . .<br />
b1) Stikprøvens x1 -værdier 1, 0, 2, 2, 1, 2, 0, 2, 0, 2 kan indtastes på en lommeregner, der finder gennemsnittet<br />
x1 og standardafvigelsen s1 som tilnærmelser til middelværdi µ 1 og spredning σ1 for X 1 . Man finder:<br />
µ 1 ≡ E( X1) ≈ x1=<br />
12 . , σ1 = σ(<br />
X1) ≈ s1<br />
= 09189 . .<br />
x 2<br />
Analogt indtastes stikprøvens - værdier 2, 0, 2, 2, 0, 2, 2, 2, 2, 2, og man finder<br />
µ 2 ≡ E( X2) ≈ x2=<br />
16 . , σ = σ(<br />
X ) ≈ s = .<br />
2 2 2 08433<br />
Det ses, at estimaterne har en vis lighed med de eksakte værdier i spørgsmål a3).<br />
11.2 KOVARIANS OG KORRELATIONSKOEFFICIENT<br />
Vi har omtalt, at hver stokastisk variabel har en varians. Men et par variable og kan have en tendens til at<br />
variere i overensstemmelse med hinanden (samvarians), således at afvigelserne X1 − µ 1 og X 2 − µ 2 overvejende<br />
har samme fortegn (positiv korrelation) eller overvejende har modsat fortegn (negativ korrelation). Eksempelvis kan<br />
en høj forekomst af ét vitamin i et levnedsmiddel ofte være ledsaget af en høj forekomst af et andet vitamin (positiv<br />
korrelation).<br />
Og studerendes højde og masse kan også have en positiv rkorrelation.<br />
Vi betragter igen en k-dimensional stokastisk variabel X = ( X X X . For et par af variable og<br />
1, 2,..., k )<br />
X X i j<br />
defineres kovariansen (“samvariansen”)<br />
( µ µ )<br />
V( X , X ) ≡ E ( X − ) ⋅( X − )<br />
i j i i j j<br />
(den giver jo et vist mål for, om afvigelserne X i − µ og X i<br />
j − µ j i middel har samme fortegn eller modsat<br />
fortegn).<br />
Sættes i = j, fås V( Xi, Xi) = E( ( Xi<br />
− µ i)<br />
) , som er identisk med variansen for variablen<br />
2<br />
V( Xi) X i<br />
( )<br />
2 2<br />
Man kan vise (se nedenfor), at V( Xi, X j) = E Xi ⋅X j − i ⋅ j,<br />
som for i = j giver V( X ) = E X − µ .<br />
X 1<br />
X 2<br />
µ µ ( )<br />
i i i<br />
Bevis:<br />
V( Xi, X j) ≡ E( ( Xi − µ i) ⋅( X j − µ j) ) = E( XiX j − µ iX j −<br />
Anvendes linearitetsreglen kan sidste led omformes:<br />
Xiµ<br />
j + µ iµ j)<br />
.<br />
= E( X X ) − µ E( X ) − E( X ) µ + µ µ = E( X X ) − µ µ − µ µ + µ µ = E( X X ) − µµ<br />
i j i j i j i j i j i j i j i j<br />
i j i j
Flerdimensional stokastisk variabel<br />
For bedre at kunne vurdere hvor meget de variable varierer i “takt” med hinanden, divideres kovariansen med<br />
spredningerne, så man får den såkaldte korrelationskoefficient:<br />
V( Xi, X j)<br />
ρ(<br />
Xi, X j)<br />
≡<br />
σ ⋅ σ<br />
1 2<br />
Man kan vise (se nedenfor) , at −1≤ ρ( Xi, X j)<br />
≤ 1.<br />
Bevis: Vi har<br />
2<br />
0 ≤ E<br />
⎛⎜<br />
⎝ ( λ ⋅ X − + X −<br />
⎞ ) ⎟<br />
i µ i j µ j ⎠ = E λ ⋅( Xi − µ i) + 2λ<br />
( Xi − µ i)( X j − µ j) + ( X j − µ j)<br />
2 2 2<br />
( ) ( ) ( )<br />
2<br />
( ( i i) ) 2 ( ( i i)( j j) ) ( ( j j)<br />
) = λ ⋅ V Xi + 2V<br />
Xi X j λ + V X j<br />
= λ ⋅ E X − µ + λ E X − µ X − µ + E X − µ<br />
2 2 2<br />
λ<br />
124<br />
( ) ( , ) ( )<br />
Da dette andengradspolynomium i aldrig er negativt, kan diskriminanten ikke være positiv, dvs.<br />
( )<br />
2<br />
V( Xi, X j)<br />
2<br />
4( V( Xi, X j) ) −4⋅V( Xi) ⋅V( X j)<br />
≤0⇔ ≤1⇔ ( ρ( Xi, X j)<br />
) ≤1<br />
⇔−1≤ρ( Xi, X j)<br />
≤1<br />
.<br />
V( X ) ⋅V(<br />
X )<br />
i j<br />
Man kan (som det ses nedenfor) vise, at<br />
X 1 og X 2 stat. uafhængige ⇒ E( X ⋅ X ) = E( X ) ⋅ E( X ) ⇔ V( X , X ) = 0 ⇔ ρ(<br />
X , X ) = 0<br />
Bevis: Vi har<br />
og stat. uafhængige<br />
X 1 X 2 ⇔ f xi x j = fi xi ⋅ f j x j<br />
2<br />
i j i j i j i j<br />
( , ) ( ) ( )<br />
∑∑ ∑∑<br />
⇒ E( X ⋅ X ) = x ⋅x ⋅ f ( x , x ) = x ⋅x ⋅ f ( x ) ⋅ f ( x )<br />
∑<br />
i j i j i j<br />
xi<br />
x j<br />
xi<br />
x j<br />
∑<br />
i j i i j j<br />
= xi ⋅ fi( xi) xj ⋅ f j( xj) = E( Xi) ⋅E(<br />
X j)<br />
xi x j<br />
⇔ V( Xi, X j) = E( Xi ⋅ X j) − µ i ⋅ µ j =<br />
V( Xi, X j)<br />
E( Xi) ⋅ E( X j) − µ i ⋅ µ j = 0 ⇔ ρ(<br />
Xi, X j)<br />
=<br />
= 0.<br />
σ ⋅ σ<br />
Estimater for kovarians, varians og korrelationskoefficient<br />
Ud fra en stikprøve ( x1, y1),( x2, y2), ...,( xn, yn)<br />
kan man beregne<br />
SAPXY n<br />
≡ ∑ ( xi − x) ⋅( yi − y)<br />
,<br />
n<br />
2<br />
SAKX ≡ ∑ ( xi − x)<br />
,<br />
n<br />
SAKX ≡ ∑ ( xi − x)<br />
i=<br />
1<br />
( SAP = “Sum af Afvigelsers Produkter” , SAK = “Sum af Afvigelsers Kvadrater” )<br />
og heraf danne estimater for kovarians, varianser og korrelationskoefficient:<br />
SAPXY<br />
SAK X SAKY<br />
kovarians: V( X, Y)<br />
≈ og varianser: V( X)≈<br />
, VY ( )≈<br />
n − 1<br />
n − 1 n − 1<br />
korrelationskoefficient: ρ( XY , ) ≈r≡ i=<br />
1<br />
SAPXY<br />
SAK ⋅ SAK<br />
X Y<br />
Det kan således vises (for enhver fordelingstype), at<br />
E , ,<br />
SAP ⎛ XY ⎞<br />
⎜ ⎟ = V( X, Y)<br />
⎝ n − 1 ⎠<br />
E SAK ⎛ X ⎞<br />
⎜ ⎟ = V( X)<br />
⎝ n − 1 ⎠<br />
E SAK ⎛ Y ⎞<br />
⎜ ⎟ = VY ( )<br />
⎝ n − 1 ⎠<br />
i=<br />
1<br />
2<br />
i j
Bevis: Vi har<br />
n<br />
n<br />
∑ ( )( ) ∑ ( ( i µ x) ( µ x) ( ( i µ Y) ( µ Y)<br />
)<br />
SAP = X − X Y − Y = X − − X − ⋅ Y − − Y −<br />
XY i i<br />
i=<br />
1 i=<br />
1<br />
n<br />
n<br />
∑ ∑<br />
∑ ∑<br />
= ( X − µ )( Y − µ ) + ( X − µ )( Y − µ ) − ( X − µ )( Y − µ ) − ( X − µ )( Y − µ )<br />
i x i Y<br />
x Y i x Y<br />
x i Y<br />
i=<br />
1 i=<br />
1<br />
i=<br />
1 i=<br />
1<br />
n<br />
∑ ( Xi i=<br />
1<br />
n<br />
µ x)( Yi µ Y)<br />
n ( X µ x)( Y µ Y) ( nX n µ x)( Y µ Y) ( X µ x)( nY n µ Y)<br />
= − − + ⋅ − − − − ⋅ − − − − ⋅<br />
= ∑ ( Xi − µ x)( Yi − µ Y)<br />
− n⋅( X − µ x)( Y − µ Y)<br />
.<br />
i=<br />
1<br />
Altså fås ved hjælp af linearitetsreglen:<br />
n<br />
E( SAPXY ) = ∑ E ( Xi− µ x )( Yi− µ Y ) − n⋅E ( X − µ x )( Y − µ Y )<br />
i=<br />
1<br />
( ) ( )<br />
n<br />
1<br />
= ∑ V( Xi, Yi)<br />
− ⋅ E ( X1 + X2+ ... + Xn − n⋅ i=<br />
1 n<br />
x)( Y1 + Y2+ ... + Yn − n⋅<br />
Y)<br />
n<br />
⎛ n<br />
n<br />
1<br />
⎞<br />
= ∑V( X, Y)<br />
− ⋅E⎜∑( Xi− µ x) ∑(<br />
Yj<br />
− µ Y ) ⎟<br />
i=<br />
1 n ⎝ i=<br />
1 j=<br />
1 ⎠<br />
n<br />
( µ µ )<br />
n n<br />
n n<br />
1 1<br />
= nV ⋅ ( XY , ) − ∑∑<br />
E( ( Xi − µ x)( Yj − µ Y) = n⋅V( X, Y)<br />
− ∑∑V(<br />
Xi, Yj)<br />
n<br />
n<br />
i=<br />
1 j=<br />
1<br />
n<br />
1<br />
= nV ⋅ ( XY , ) − ∑V(<br />
Xi, Yi)<br />
n<br />
i=<br />
1<br />
125<br />
i=<br />
1 j=<br />
1<br />
( idet V( X , Y )= 0 for i ≠ j i en stikprøve)<br />
i j<br />
n<br />
11.1 Indledning<br />
1<br />
= nV ⋅ ( XY , ) − ⋅nV ⋅ ( XY , ) = ( n−1) ⋅V(<br />
XY , ) , dvs. E .<br />
n SAP ⎛ XY ⎞<br />
⎜ ⎟ = V( X, Y)<br />
⎝ n − 1 ⎠<br />
Erstattes Y med X i beviset, bliver SAPXY erstattet med SAK X , og V( X, Y)<br />
bliver erstattet med V( X)<br />
,<br />
hvorved vi også får bevist, at E . Erstattes X med Y , fås endelig<br />
SAK ⎛ X ⎞<br />
⎜ ⎟ = V( X)<br />
E<br />
⎝ n − 1 ⎠<br />
SAK ⎛ Y ⎞<br />
⎜ ⎟ = VY ( )<br />
⎝ n − 1 ⎠<br />
Poolet estimat<br />
Som nævnt er SAK en forkortelse for “Sum af Afvigelsers Kvadrater”. De afvigelser der tænkes på er de n differenser<br />
X1 − X, X2 − X,..., Xn− X . De har summen 0, så når n - 1 af dem er kendt, er den sidste fastlagt. Da SAK således<br />
kun er baseret på n - 1 uafhængige differenser, siger man, at SAK har f = n - 1 frihedsgrader. Det er også antallet<br />
2 SAKX<br />
af frihedsgrader der optræder i estimatet for varians: s =<br />
f<br />
Ofte har man taget k stikprøver på variable med samme varians σ , så vi får k uafhængige estimater for den samme<br />
2<br />
varians σ : 2<br />
2 SAK1<br />
2 SAK2<br />
2 SAKk<br />
s1<br />
= , s2<br />
= ,. . . . . ., sk<br />
=<br />
f1<br />
f 2<br />
f k<br />
og det er da fordelagtigt at forene dem i et såkaldt fællesestimat eller poolet estimat:<br />
2<br />
spool<br />
=<br />
2 2 2<br />
fs 1 1+<br />
fs 2 2+<br />
... + fs k k<br />
f1 + f2 + ... + fk<br />
med f pool = f1 + f2+ ... + fkfrihedsgrader<br />
.<br />
Dette kan også skrives<br />
2 SAK1 + SAK2+ ... + SAKk<br />
spool<br />
=<br />
, med fpool =<br />
f1 + f2+ ... + fk<br />
f1 + f2 + ... + fkfrihedsgrader.<br />
2<br />
Det ses, at spool har den rigtige middelværdi σ , idet linearitetsreglen giver<br />
2<br />
2<br />
Es ( pool ) =<br />
2<br />
2 2<br />
fEs 1 ( 1)<br />
+ fEs 2 ( 2)<br />
+ ... + fkEs ( k)<br />
=<br />
f + f + ... + f<br />
2 2 2<br />
f1σ + f2σ + ... + fkσ<br />
2<br />
= σ<br />
.<br />
f + f + ... + f<br />
1 2<br />
k<br />
1 2<br />
k
Flerdimensional stokastisk variabel<br />
Eksempel 11.2. Kovarians. Korrelationskoefficient.<br />
Vi betragter igen den 2-dimensionale fordeling fra eksempel 11.1.<br />
a5) Find kovariansen og korrelationskoefficienten.<br />
b2) Benyt stikprøven til at finde estimater for kovariansen og korrelationskoefficienten.<br />
LØSNING:<br />
a5) Idet vi i eksempel 11.1 har fundet µ 1 = 11 .,µ 2 = 12 . , σ = 069 . og σ = 096 . , finder vi nu kovariansen<br />
V( X1, X2)<br />
og korrelationskoefficienten ρ( X1, X2)<br />
:<br />
( )<br />
V( X , X ) ≡ E ( X − µ ) ⋅( X − µ ) = ( x − µ )( x − µ ) f ( x , x )<br />
i j i i j j<br />
∑∑<br />
x1<br />
x2<br />
1 1 2 2 1 2<br />
= ( 0− µ 1) ⋅( 0− µ 2) ⋅ f ( 00 , ) + ( 1− µ 1) ⋅( 0− µ 2) ⋅ f ( 10 , ) + ( 2−µ 1) ⋅ ( 0−µ 2)<br />
⋅ f ( 20 , )<br />
+ ( 0− µ 1) ⋅( 2 − µ 2) ⋅ f ( 02 , ) + ( 1− µ 1) ⋅( 2 − µ 2) ⋅ f ( 12 , ) + ( 2 − µ 1) ⋅ ( 2 − µ 2)<br />
⋅ f ( 22 , )<br />
= ( 0−11 . ) ⋅( 0−1.. 2) ⋅ 02 . + ( 1−11 . ) ⋅( 0− 12 . ) ⋅ 01 . + ( 2− 11 . ) ⋅ ( 0− 12 . ) ⋅ 01 .<br />
+ ( 0− 11 . ) ⋅( 2 − 1.. 2) ⋅ 01 . + ( 1− 11 . ) ⋅( 2 − 12 . ) ⋅ 02 . + ( 2 − 11 . ) ⋅ ( 2 − 12 . ) ⋅ 03 . = 028 .<br />
V( X1, X2)<br />
028 .<br />
ρ(<br />
X1, X2)<br />
≡<br />
=<br />
= 0. 3440 .<br />
σ( X ) ⋅σ(<br />
X ) 069 . ⋅ 096 .<br />
1 2<br />
b2) Stikprøvens værdier (1,2), (0,0), (2,2), (2,2), (1,0), (2,2), (0,2), (2,2), (0,2), (2,2) kan indtastes på en<br />
lommeregner, der finder tilnærmelser (estimater) til kovariansen V( X1, X2)<br />
og korrelationskoefficienten<br />
ρ( X , X ) :<br />
1 2<br />
n<br />
∑<br />
( x1i − x1)( x2i − x2)<br />
SAP12<br />
i=<br />
1<br />
V( X1, X2)<br />
≈ =<br />
= 03111 .<br />
n − 1 n − 1<br />
ρ( X , X ) ≈ r ≡<br />
1 2<br />
SAP12<br />
SAK ⋅ SAK<br />
1 2<br />
=<br />
i=<br />
1<br />
n<br />
∑<br />
i=<br />
1<br />
n<br />
∑<br />
( x − x )( x − x )<br />
1i 1 2i 2<br />
( x − x ) ⋅ ( x − x )<br />
n<br />
∑<br />
1i 1 j<br />
j<br />
2<br />
2 2 2<br />
= 1<br />
126<br />
= 04015 .<br />
Det ses, at estimaterne har en vis lighed med de eksakte værdier i spørgsmål a5).<br />
11.3 LINEARKOMBINATION<br />
Når vi skal tage en stikprøve ( X1, X2,..., Xn) på en 1-dimensional stokastisk variabel X, så skal vi n gange skaffe<br />
et r tal X fra et tilfældigt eksperiment. Derfor kan vi opfatte stikprøven som en n-dimensional stokastisk variabel<br />
X = ( X X X .<br />
1, 2,...,<br />
n )<br />
X X X<br />
Vi bruger ofte stikprøven til at danne gennemsnittet X<br />
n n X<br />
n X<br />
n X<br />
1 + 2+<br />
... + n 1 1 1<br />
=<br />
= 1 + 2+<br />
... + n<br />
som er en speciel linearkombination af X1, X2,..., Xn. r<br />
Ved en linearkombination L for en k-dimensional stokastisk variabel X = ( X X X forstås et udtryk af<br />
1, 2,...,<br />
k )<br />
formen<br />
L = a0 + a1X1 + a2X2 + ... + akXk , hvor a0, a2, a3,..., aker konstanter.<br />
For middelværdien af L giver linearitetsreglen:<br />
E( L) = a0 + a1E( X1) + a2E( X2) + ... + akE( Xk)<br />
.<br />
Eksempelvis kan vi se, at et gennemsnit X altid har den “rigtige” middelværdi µ :<br />
1 1 1 1 1 1<br />
E( X)<br />
= E( X1)<br />
+ E( X2<br />
) + ... + E( Xn)<br />
= µ + µ + ... + µ = µ .<br />
n n n n n n<br />
For variansen af en linearkombination L gælder kvadratreglen:<br />
2<br />
2<br />
2<br />
V( L) = a ⋅ V( X ) + a ⋅ V( X ) + ... + a ⋅ V( X ) + 2<br />
a a V( X , X )<br />
1<br />
1 2<br />
2<br />
k<br />
k k i j i j<br />
i=<br />
1 j=+ i 1<br />
k<br />
∑ ∑<br />
.
127<br />
11.3 Linearkombination<br />
Eksempelvis:<br />
2 2<br />
a) V( a + bX + cY) = b V( X) + c V( Y) + 2bcV(<br />
X, Y)<br />
b) V( a + bX + cY + dZ)<br />
2 2 2<br />
= b V ( X ) + c V ( Y) + d V ( Z) + 2bcV ( X , Y) + 2cdV( Y, Z) + 2dbV<br />
( Z, X ) .<br />
c) V X V X V X<br />
(X’erne statistisk uafhængige)<br />
n n n V X 1 1 1<br />
( ) = 2 ( 1) + 2 ( 2) + ... + 2 ( n)<br />
2<br />
1 2 1 2 1 2 σ<br />
σ(<br />
X )<br />
= + + + = , dvs. .<br />
2 σ 2 σ ... 2 σ<br />
σ(<br />
X ) =<br />
n n n n<br />
n<br />
Den sidste ligning viser, at spredningen på et gennemsnit kun er omvendt proportional med kvadratroden på<br />
stikprøvestørrelsen n. For at få et gennemsnit med en 10 gange mindre spredning, skal stikprøven altså gøres 100 gange<br />
større!<br />
Bevis for kvadratreglen. Vi finder<br />
( 2)<br />
( 0 1 1 k k 0 1µ 1 kµ k<br />
2)<br />
( ( µ ) ... (<br />
2<br />
µ ) )<br />
V( L) ≡ E ( L− E( L)) = E ( a + a X + ... + a X − a − a −... −a<br />
)<br />
( 1 1 1<br />
k k k )<br />
= E a X − + + a X −<br />
⎛<br />
k k<br />
⎞<br />
2<br />
2 2 2<br />
= E⎜a X − + + a X − + ∑ ∑ a a X − X − ⎟<br />
1 ( 1 µ 1)<br />
... k( k µ k) 2<br />
i j( i µ i)( j µ j)<br />
⎝<br />
i=<br />
1 j=<br />
1<br />
⎠<br />
k k<br />
2 2 2<br />
( ( 1 µ 1)<br />
) ... k ( ( k µ k) ) 2∑<br />
∑ i j ( ( i µ i)( j µ j)<br />
)<br />
2<br />
= a E X − + + a E X − + a a E X − X −<br />
1<br />
∑ ∑<br />
i=<br />
1 j=<br />
1<br />
2<br />
2<br />
= aV( X) + ... + aV( X ) + 2 aaV( X, X ).<br />
1<br />
1<br />
k<br />
k k i j i j<br />
i=<br />
1 j=<br />
1<br />
k<br />
Eksempel 11.3. Linearkombination af stokastiske variable.<br />
Et levnedsmiddel leveres i poser. Lad X 1 og X 2 [mg/kg] betegne koncentrationerne af to stoffer A og B i en<br />
tilfældig udvalgt pose. Det vides, at E( X1)<br />
= 20. 0,<br />
E( X2)<br />
= 30. 0 , σ( X 1)<br />
= 20 . , σ( X 2 ) = 40 . og<br />
V( X1, X2)<br />
= −40 . . Holdbarheden Y er teoretisk givet ved Y = 5+ 4X1 + 3X2[dage]<br />
.<br />
Find holdbarhedens middelværdi EY ( ) og spredning σ( Y)<br />
.<br />
LØSNING:<br />
Vi finder<br />
EY ( ) = E( 5+ 4X1 + 3X2) = 5+ 4⋅ E( X1) + 3⋅E(<br />
X2<br />
) = 5 + 4 ⋅ 20. 0 + 3⋅ 30. 0 = 1750 .<br />
2<br />
2<br />
VY ( ) = V( 5+ 4X1 + 3X2) = 4 ⋅ V( X1) + 3 ⋅ V( X2) + 243 ⋅ ⋅ ⋅V(<br />
X1, X2)<br />
2 2 2 2<br />
= 4 ⋅ 20 . + 3 ⋅ 40 . + 2⋅4⋅3⋅( − 40 . ) = 112<br />
σ( Y) ≡ V( Y)<br />
= 112 = 105830<br />
. .
Flerdimensional stokastisk variabel<br />
OPGAVER<br />
Opgave 11.1.1 (2-dimensional stokastisk variabel)<br />
Et spil i et casino går ud på at trække en tilfældig seddel fra en urne (og lægge sedlen tilbage igen). Urnen indeholder<br />
10 sedler, og på hver seddel står 2 tal ( X1, X2)<br />
:<br />
(1,0) (3,0) (4,0)<br />
(1,0) (3,3) (4,3)<br />
(1,3)<br />
(1,3)<br />
(1,3)<br />
(4,3)<br />
a1) Find den 2-dimensionale tæthedsfunktion f ( x1, x2)<br />
:<br />
a2) Find de 1-dimensionale tæthedsfunktioner f1( x1)<br />
og f2( x2)<br />
.<br />
a3) Er X 1 og X 2 statistisk uafhængige ?<br />
a4) Find middelværdierne µ 1 = E( X1)<br />
og µ 2 = E( X2)<br />
samt spredningerne σ1( X 1)<br />
og σ 2( X 2)<br />
.<br />
2<br />
a5) Find middelværdien E( X1⋅X2) .<br />
b) Antag, at man i stedet kender en stikprøve på ( X1, X2)<br />
:<br />
(1,3), (1,0), (1,0), (4,3), (3,0), (4,3), (1,0), (3,0), (3,3 ), (1,3).<br />
b1) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a4).<br />
Opgave 11.1.2 (kovarians, korrelationskoefficient)<br />
a6) Find kovariansen V( X1, X2)<br />
og korrelationskoefficienten ρ( X1, X2)<br />
.<br />
b2) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a6).<br />
Opgave 11.1.3 (linearkombination)<br />
For det i opgave 11.1.1 og 11.1.2 omtalte casino aftales et spil, hvor gevinsten er<br />
G = 20 + 10X1 + 5X2.<br />
a7) Find gevinstens middelværdi E( G)<br />
og spredning σ( G)<br />
.<br />
b3) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a7).<br />
Opgave 11.2.1 (2-dimensional stokastisk variabel)<br />
Under en produktion kan der optræde fejl. Lad ( X1, X2)<br />
=( Antal gange der optræder fejl af type 1, Antal gange der<br />
optræder fejl af type 2) i en tilfældig produktion. Variablen X 1 kan antage værdierne 0, 1 og 2, mens X 2 kun kan antage<br />
værdierne 0 og 1.<br />
a) Antag, at man teoretisk kender tæthedsfunktionen f ( x , x ) :<br />
1 2<br />
f ( x1, x2)<br />
x1 0 1 2<br />
x2 0 0.3 0.1 0.1<br />
1 0.1 0.2 0.2<br />
a1) Find de 1-dimensionale tæthedsfunktioner f1( x1)<br />
og f2( x2)<br />
.<br />
a2) Er X 1 og X 2 statistisk uafhængige ?<br />
a3) Find middelværdierne µ 1 = E( X1)<br />
og µ 2 = E( X2)<br />
samt spredningerne σ1( X 1)<br />
og σ 2( X 2)<br />
.<br />
a4) Find middelværdien E( X1 + X2)<br />
.<br />
b) Antag, at man i stedet kender en stikprøve på ( X1, X2)<br />
:<br />
(0,1), (0,0), (1,1), (1,1), (0,0), (0,0), (0,1), (2,1), (0,0 ), (2,1).<br />
b1) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a3).<br />
Opgave 11.2.2 (kovarians, korrelationskoefficient)<br />
Vi betragter igen produktionsprocessen fra opgave 11.2.1.<br />
a5) Find kovariansen V( X1, X2)<br />
og korrelationskoefficienten ρ( X1, X2)<br />
.<br />
b2) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a5).<br />
128
Opgave 11.2.3 (linearkombination)<br />
For den i opgave 11.2.1 og 11.2.2 omtalte produktionsproces er fortjenesten<br />
F = 20000 − 3000X1 − 4000X2.<br />
a6) Find fortjenestens middelværdi E( F)<br />
og spredning σ( F)<br />
.<br />
b3) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a6).<br />
129<br />
Opgaver til kapitel 11<br />
Opgave 11.3.1 (2-dimensional stokastisk variabel)<br />
År 4001. En sonde er vendt hjem med oplysninger om individer på en fremmed planet. De kan have 2, 4 eller 6 øjne,<br />
og 2 eller 4 ører. Lad ( X , X ) = (Antal øjne, Antal ører) for et tilfældigt udtaget individ på planeten.<br />
1 2<br />
a) Professor Cosmussen har teoretisk opstillet tæthedsfunktionen f ( x , x ) :<br />
f ( x1, x2)<br />
x 2<br />
x 1<br />
1 2<br />
2 4 6<br />
2 0.1 0.2 0.1<br />
4 0.1 0.3 0.2<br />
a1)<br />
a2)<br />
a3)<br />
Find de 1-dimensionale tæthedsfunktioner f1( x1)<br />
og f2( x2)<br />
.<br />
Er X 1 og X 2 statistisk uafhængige ?<br />
Find middelværdierne µ 1 = E( X1)<br />
og µ 2 = E( X2)<br />
samt spredningerne σ1( X 1)<br />
og σ 2( X 2)<br />
.<br />
⎛ 1<br />
a4) Find middelværdien E⎜ ⎝ X<br />
1 ⎞<br />
+ ⎟ .<br />
X ⎠<br />
1 2<br />
b) Antag, at man i stedet kender en stikprøve på ( X1, X2)<br />
:<br />
(6,2), (2,4), (6,4), (2,2), (6,4), (4,4), (2,2), (4,2), (4,4 ), (4,4).<br />
b1) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a3).<br />
Opgave 11.3.2 (kovarians, korrelationskoefficient)<br />
Vi betragter igen individerne fra opgave 11.2.1.<br />
a5) Find kovariansen V( X1, X2)<br />
og korrelationskoefficienten ρ( X1, X2)<br />
.<br />
b2) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a5).<br />
Opgave 11.3.3 (linearkombination)<br />
For de i opgave 11.3.1 og 11.3.2 omtalte individer har professor Cosmussen opstillet en formel for deres masse:<br />
M = 200 + 20X1 + 10X2<br />
kg.<br />
a6) Find massens middelværdi E( M)<br />
og spredning σ( M)<br />
.<br />
b3) Benyt stikprøven til at finde estimater for størrelserne i spørgsmål a6).<br />
Opgave 11.4.1 (2-dimensional stokastisk variabel)<br />
Lad ( X1, X2)<br />
= ( Højde [cm], Masse [kg] ) af en tilfældigt udtaget studerende på 3. halvår.<br />
Der foreligger følgende stikprøve:<br />
(178,63), (186,85), (180,68), (183,75), (164,55), (193,77),<br />
(193,84), (160,55), (165,63), (180,84), (169,74), (189,79) .<br />
Find estimater for middelværdierne = E X og = E X samt spredningerne ( ) og ( X ) .<br />
µ 1 ( 1)<br />
µ 2 ( 2)<br />
σ1 X 1 σ 2 2<br />
Opgave 11.4.2 (kovarians, korrelationskoefficient)<br />
Benyt stikprøven i opgave 11.4.1 til at finde estimater for kovariansen V( X1, X2)<br />
og korrelationskoefficienten<br />
ρ( X , X ) .<br />
1 2<br />
Opgave 11.4.3 (linearkombination)<br />
Vi betragter igen de i opgave 11.4.1 og 11.4.2 omtalte studerende. En frugtavler har opstillet en formel for den timeløn,<br />
han vil give dem som frugtplukkere:<br />
L = 100 + 0. 3X1 − 0. 2 X2<br />
kroner/time.<br />
Benyt stikprøven til at finde estimater for timelønnens middelværdi E( L)<br />
og spredning σ( L)<br />
.
Flerdimensional stokastisk variabel<br />
Opgave 11.5 (poolet estimat)<br />
Koncentrationen af et stof A blev målt i 3 partier råvarer:<br />
Råvare 1: 56, 60, 54, 49, 61<br />
Råvare 2: 78, 73, 80<br />
Råvare 3: 66, 62, 70, 72, 60<br />
Det antages, at der er samme spredning i de 3 tilfælde. Find et estimat for spredningen .<br />
Opgave 11.6 (poolet estimat)<br />
Koncentrationen af et stof A blev målt i 2 levnedsmidler:<br />
Levnedsmiddel 1: 87, 89, 94, 86, 89, 95 Levnedsmiddel 2: 93, 99, 94, 91, 98 .<br />
Det antages, at der er samme spredning i de 2 tilfælde. Find et estimat for spredningen .<br />
Opgave 11.7 (poolet estimat)<br />
Koncentrationen af et stof A blev målt i mælken fra 5 køer:<br />
Ko 1: 44, 48, 46, 43, 45 Ko 2: 40, 38, 41<br />
Ko 3: 43, 45, 42, 42<br />
Ko 5: 50<br />
Ko 4: 36, 32<br />
Det antages, at der er samme spredning i de 5 tilfælde. Find et estimat for spredningen .<br />
130<br />
s pool<br />
s pool<br />
s pool<br />
σ<br />
σ<br />
σ
Statistiske beregninger på lommeregner og PC-er<br />
STATISTISKE BEREGNINGER PÅ LOMMEREGNERNE TI89<br />
og TI83 SAMT PÅ PC-PROGRAMMERNE EXCEL, MAPLE OG<br />
MATHCAD<br />
TI 89<br />
1) Generelt:<br />
Metode 1: Vælg HOME\ CATALOG,, F3\ vælg den ønskede fordeling\ENTER<br />
(benyt evt. ALPHA,+ forbogstav for hurtigt at komme til det ønskede navn).<br />
Fordel: Hurtig ved beregning af sandsynligheder, såsom P(X < 0.87) da resultatet straks<br />
indsættes på HOME-linien.<br />
Ulempe: Man skal huske parametrenes rækkefølge (de kan dog ses nederst på skærmen<br />
Metode 2: Vælg APPS\ Stats/List\ indtast eventueller data i eksempelvis “list1" \ vælg en relevant “F- knap”.<br />
Fordel: Der fremkommer nu en menu, som er næsten selvforklarende.<br />
Ulempe: Skal resultatet ned på HOME-linien (man vil regne videre), bliver det lidt besværligt:<br />
HOME, Var-Link\I StatsVar mappen markeres den ønskede størrelse, ENTER<br />
Oprette en “Folder”: VAR-Link\ F1\ 5: Create Folder\ Skriv navn på folder.<br />
Vælg en mappe som den aktuelle mappe: MODE\ Current Folder\navn<br />
Formål: Det kan være praktisk ikke at gemme alle sine resultater i MAIN.<br />
2) Sandsynlighedsfordelinger.<br />
Normalfordeling n( µ , σ )<br />
a) Find p = P( a ≤ X ≤b)<br />
, hvor a ,b, µ , σ er givne konstanter. p = normcdf( ab , , µ , σ )<br />
Eksempel: p = P( X ≤116<br />
. ) , hvor µ = 113 ., σ = 5 p = normcdf( − ∞ ,11.6, 11.3,5) = 0.524<br />
b) Find : ( ≤ ) = , hvor p, µ , σ er givne konstanter. x p =invNorm( p, µ , σ )<br />
x p<br />
P X xp p<br />
Eksempel: P( X ≤ xp) = 07 . ,hvor µ = 11,, 4 σ = 6 x p =invNorm(0.7,11.4,6) =14.55<br />
t - fordeling. Lad T være t - fordelt med frihedsgradstallet f.<br />
a) Find p = P( a ≤T ≤b)<br />
, hvor a og b er givne konstanter. tCdf(a,b,f)<br />
Eksempel: p = P( T ≤ −13<br />
. ) , med f = 14 p = tCdf(- ∞ ,-1.3,14) = 0.1073<br />
b) Find tα ( f ): P( T ≤ tα ( f )) = α ( α given konstant). invt( α ,f )<br />
Eksempel: t0975 . ( 12)<br />
= invt(0.975,12) = 2.179<br />
χ fordeling. Lad Q være fordelt med frihedsgradstallet f.<br />
2 − χ 2 −<br />
a) Find p= P( a ≤Q≤b) , hvor a og b er givne konstanter. p = chi2Cdf(a,b,f)<br />
Eksempel:Find p = P( Q≥27.<br />
3)<br />
, med f = 19 p = chi2Cdf(27.3, ∞ ,19) = 0.0979<br />
2<br />
b) Find fraktilen χα ( f ) : PQ ( ≤ χ ( f))<br />
= α ( given konstant). invChi2( ,f)<br />
α 2 α α<br />
2<br />
Eksempel: χ 0. 025 () 8 = invChi2(0.025,8) = 2.18<br />
Binomialfordeling. Lad X være binomialfordelt b(n,p)<br />
Find Pl ( ≤ X≤m) , hvor 0 ≤ l < m∧m≤n og l og m er hele tal. binomtCdf(n,p,l,m)<br />
Eksempel :p = P( 3≤X ≤ 6)<br />
hvor n = 10 og p = 0.3 p = binomtCdf(10, 0.3, 3, 6) = 0.6066<br />
µ<br />
Poissonfordeling. Lad X være Poissonfordelt p( )<br />
Find Pl ( ≤ X≤m) , hvor 0 ≤ l < m og l og m er hele tal. poissCdf( µ ,l,m)<br />
Eksempel: p = P( X ≤ 94 ) , hvor µ<br />
= 147.6 p = poissCdf(147.6,0,94) = 0.00002<br />
131
Statistiske beregninger på lommeregner og PC-er<br />
3) Gennemsnit, varians og spredning<br />
Find gennemsnit , varians og spredning af tallene 1, 3, 4, 8<br />
Metode 1. HOME\ MATH\6.Statistics\ Anvendes med få tal og kun ønsker beregning af en enkelt størrelse.<br />
Gennemsnit: Mean (liste) Eksempel : Mean({1,3,4,8}) = 4<br />
Varians: Variance(liste) Eksempel : Variance({1,3,4,8}) = 8.667<br />
Spredning: stdDev (liste) Eksempel : stdDev({1,3,4,8}) = 2.944<br />
Metode 2. APPS\ Stats/List\ Data indtastes i “list1"\ F4\ 1: 1-Var Stats<br />
I menu sættes “List” til “List1" (Benyt evt. Var-Link til at finde List1)<br />
Udskriften består af en række statistiske størrelser. Man finder =4, =2.944<br />
x σ x<br />
4) Hypotesetest og konfidensintervaller<br />
APPS\ STAT/LIST hvorefter eventuelle data indtastes i list1<br />
4.1. Normalfordeling. 1 variabel<br />
a1) Hypotesetest; σ kendt: F6\ 1: Z-Test\<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8} , σ = 3 og H: µ < 5<br />
Vælg Data: I menu: µ 0 =5 , σ = 3 , list = list1, Altern. Hyp µ < µ 0 P-værdi = 0.25<br />
x = 4, σ = 3, n = 10 µ < 5<br />
Eksempel: Opgivet , H:<br />
Vælg Stats: I menu: µ 0 =5 , σ = 3 , x = 4, n = 10 , Altern. Hyp µ < µ 0 P-værdi = 0.145<br />
a2) Konfidensinterval σ kendt: F7\ 1: Z-Interval<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8} , σ = 3<br />
Vælg Data: I menu: σ = 3 , list = list1, C Level =.95<br />
Eksempel: Opgivet x = 5, σ = 3, n = 10,<br />
C Int =[1,05; 6.54]<br />
Vælg Stats: I menu: σ = 3 , x = 5, n = 10<br />
C Int =[3.14;6.85]<br />
b1) Hypotesetest; σ ukendt: F6\ 2: T - Test\<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8} H: µ < 5<br />
µ 0 µ µ<br />
Vælg Data: I menu: =5 , list = list1, Altern. Hyp < 0<br />
P-værdi = 0.27<br />
Eksempel: Opgivet x = 4, s= 3, n = 10,<br />
H: µ < 5<br />
Vælg Stats: I menu: µ 0 =5 , x = 4, s= 3, n = 10,<br />
Altern. Hyp µ < µ 0 P-værdi = 0.160<br />
b2) Konfidensinterval σ ukendt: F7\ 1: T-Interval<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8}<br />
Vælg Data: I menu: list = list1, C Level =.95 C Int =[-0.684; 8.684]<br />
Eksempel: Opgivet x = 4, s= 3, n = 10,<br />
Vælg Stats: I menu: x = 4, s= 3, n = 10<br />
C Int =[1.85;6.15]<br />
4.2. Binomialfordeling.<br />
a1) Hypotesetest: F6, 5: 1-Prop-ZTest (Kræver der kan approksimeres til normalfordeling)<br />
Eksempel: X er binomialfordelt b(24, p) , x = 13, H: p > 0.3<br />
Vælg: p0= 0.3, Successes = 13, n= 24, Alternate Hyp : prop > po P -værdi = 0.00489<br />
a2) Konfidensinterval: F7, 5: 1-Prop-ZInt (Kræver der kan approksimeres til normalfordeling)<br />
Eksempel: Af 24 forsøg de 13 en succes:<br />
Vælg: Successes = 13, n= 24, C Int =[0.34; 0.74]<br />
Poissonfordeling: findes ikke, så her må formel for konfidensinterval benytttes<br />
5. Normalfordeling. 2 variable<br />
a1) Hypotesetest; F6\ 4: 2-SampTtest\ udfyld menu (se eksempel 7.1 eller 7.2)<br />
Konfidensinterval: F7\ 4: 2-SampTint\ udfyld menu(se eksempel 7.1)<br />
132
133<br />
Excel<br />
Excel<br />
1) Generelt<br />
Forudsætninger.<br />
Da ikke alle de anvendte statistiske funktioner er indbygget fra starten, skal man først vælge et tilføjelsesprogram:<br />
I Excel 2003: Vælg “Funktioner”, “Tilføjelsesprogrammer”, marker “Problemløser”<br />
I Excel 2007: Vælg “Excel-Office-knappen”, “Excel indstillinger (findes forneden)”, Tilføjelsesprogrammer”,<br />
”Udfør”, ”marker Problemløser”, “Installer”.<br />
Inddata.<br />
Vi vil i det følgende for kortheds skyld antage, at den første stikprøves værdier står i cellerne A1, A2, A3 . . . A10.<br />
Kræves der flere variable vil den næste stå i cellerne B1, B2, B3 . . . B8, osv.<br />
Man angiver “udskriftsområdet” eller “inputområdet” f.eks en søjle placere i cellerne A1:A10 ved<br />
a) at markere området A1 til A10<br />
b) at skrive eksempelvis A1:A10<br />
c) at give det et navn: Vælg “Indsæt” i Excel 2003: Navn i Excel 2007:Formler Definer i menu skriv søjlens<br />
navn og (nederst)A1:A10<br />
Skrive , beregne og kopiere formler.<br />
Vælg den celle hvor resultatet skal stå. Lad det være B1: På værktøjslinien foroven skriv = formel skrives<br />
ENTER Resultatet står nu i celle B1<br />
Hvis selve formlen skal stå i en anden celle. Lad det være A1: Cursor placeres i B1 I formelfelt markeres formlen<br />
uden lighedstegn og man kopierer den (CTRL C)” ENTER (så formlen igen er beregnet i B1 Cursor over i A1<br />
og paste (CTRL V)<br />
Udskrive gitterlinier og række og kolonneoverskrifter<br />
Excel 2003: Vælg Filer Sideopsætning Ark Marker gitterlinier marker række- og kolonneoverskrifter.<br />
Excel 2007: Vælg Sidelayout Under“Gitterlinier” marker “Udskriv” Under “Overskrifter” marker “Udskriv”<br />
2: Indsætte og tegne diagrammer<br />
Lagkage eller søjle: se eksempel 2.1 side 2<br />
Kurve: se eksempel 2.4 side 4<br />
Tegne histogram: se eksempel 2.5 side 6<br />
3: Beregne statistiske størrelser og funktioner<br />
Beregning af “Karakteristiske tal” (se evt. side 11)<br />
Data indtastes i eksempelvis søjle A1 til A10<br />
Excel 2003: Funktioner Dataanalyse Beskrivende statistik udfyld inputområde Resumestatistik<br />
Excel 2007: Data Dataanalyse Beskrivende statistik udfyld inputområde Resumestatistik<br />
Valg af statistiske størrelser (funktioner)<br />
1) Vælg den celle hvor resultatet skal stå (eksempelvis A1).<br />
2) På værktøjslinien foroven:<br />
2a) Tryk på<br />
f x<br />
2b) På den fremkommne menu vælges den ønskede funktion eksempelvis “NORMALFORDELING”<br />
2c) Der fremkommer en menu med anvisning på, hvordan den skal udfyldes.<br />
Gennemsnit, spredning, median, kvartil<br />
Navnene anføres nedenunder, men den fremkomne menu gør det let at indsætte de rette parametre.<br />
Gennemsnit x = MIDDEL(A1:A10)<br />
Spredning s = STDAFV (A1:A10)<br />
Median m = MEDIAN(A1:A10) (= KVARTIL(A1:A10;2) )<br />
1. Kvartil = KVARTIL(A1:A10;1)<br />
Fakultet, kombination, Permutation (se evt. side 80)<br />
Fakultet n! = FAKULTET(n) Eksempel: 5! =FAKULTET(5) = 120
Statistiske beregninger på lommeregner og PC-er<br />
Kombination K(n,p) = KOMBIN(n;p) Eksempel: K(5,3)==KOMBIN(5;3) = 10<br />
Permutation P(n,p = PERMUT(n;p) Eksempel: P(5,3) = PERMUT(5;3) = 60<br />
Normalfordeling.<br />
Lad X være normalfordelt med middelværdi µ og spredning σ<br />
1) P( X ≤ x)<br />
= NORMFORDELING(x ; µ ; σ ;1)<br />
2) P( X ≥ x)<br />
= 1 - NORMFORDELING(x ; µ ; σ ;1)<br />
3) Pa ( ≤ X≤ b) = P( X≤ b) − P( X≤ a)<br />
= NORMFORDELING(b ; µ ; σ ;1) -NORMFORDELING(a ; µ ; σ ;1)<br />
Fraktil x p : P( X ≤ x ) = p⇔<br />
NORMINV(p; µ ; σ )<br />
p<br />
Eksempel: u0975 . = NORMINV(0,975;0;1) = 1,959961<br />
t - fordeling. (se evt. side 44)<br />
Lad T være t - fordelt med f frihedsgrader..<br />
1) PT ( ≥ t)<br />
= TFORDELING(abs(t); f ;1)<br />
(bemærk: TFORDELING(abs(t); f ;1) udregner “øvre hale” af fordelingen)<br />
2) PT ( ≤−t) + PT ( ≥ t)<br />
= TFORDELING(abs(t); f ;2) (udregner “halen” til begge sider)<br />
Fraktil<br />
tα ( f ) = TINV(2(1 - α ) ; f) , α > 0.5<br />
tα ( f ) = - TINV(2 α ; f) , α < 0.5<br />
α<br />
Bemærk: TINV( α ;f) udregner “øvre hale”, svarende til 1 -<br />
2<br />
Bemærk: Man må må udnytte symmetrien i t-fordelingen, for værdier mindre end 0 (svarende til α < 0.5)<br />
Eksempel:<br />
Lad T være t - fordelt med 12 frihedsgrader<br />
1) P( X ≤−1) = P( X ≥ 1)<br />
= TFORDELING(abs(-1);12;1) = 0,168525<br />
2) t0 975 12 = TINV(0,05;12) = 2,178813<br />
. ( )<br />
t0. 025 ( 12)<br />
χ - fordeling. (se evt.side 49)<br />
2<br />
= - TINV(0,05;12) = - 2,178813<br />
Lad X være χ - fordelt med f frihedsgrader<br />
2<br />
P( X ≥ x)<br />
= CHIFORDELING(x;f)<br />
(bemærk: CHIFORDELING(x;f) udregner “øvre hale” af fordelingen)<br />
Fraktil<br />
2<br />
χα ( f ) =CHIINV(1- α ;f)<br />
(bemærk: CHIINV( α ;f) udregner “øvre hale”)<br />
Eksempel:<br />
Lad X være χ - fordelt med 8 frihedsgrader<br />
2<br />
1) P( X ≤ 5)<br />
= 1- CHIFORDELING(5;8) = 0,242424<br />
2)<br />
2<br />
() 8 =CHIINV(0,025;8) = 17,53454<br />
χ 0. 975<br />
2<br />
χ 0. 025<br />
() 8 =CHIINV(0,975;8) = 2,179725<br />
Hypergeometrisk fordeling (se evt. side 88)<br />
Lad X være hypergeometrisk fordelt med parametrene N, M og n<br />
P( X = x)<br />
= HYPGEOFORDELING(x ; n ; M ; N)<br />
Eksempel: Lad N = 600, M = 10 og n = 25<br />
P( X ≤ 1)<br />
= HYPGEOFORDELING(1;25;10;600)+HYPGEOFORDELING(0;25;10;600) = 0,938876<br />
Binomialfordeling ( se evt. side 91)<br />
Lad X være binomialfordelt med parametrene n og p<br />
P( X = x)<br />
= BINOMIALFORDELING(x ; n; p; 0)<br />
P( X ≤<br />
x)<br />
= BINOMIALFORDELING(x ; n; p; 1)<br />
134
Eksempel (jævnfør eksempel 72)<br />
Lad X være binomialfordelt med n = 6 og p = 0.15<br />
P( X = 3)<br />
= BINOMIALFORDELING(3;6;0,15;0) = 0,041453<br />
P( X ≥ 3) = 1- P( X ≤ 2)<br />
=1 - BINOMIALFORDELING(2;6;0,15;1) = 0,047339<br />
Poissonfordeling (se evt. side 97)<br />
Lad X være Poissonfordelt med middelværdien µ<br />
P( X = x)<br />
= POISSON(x; µ ; 0)<br />
P( X ≤ x)<br />
= POISSON(x; µ ; 1)<br />
Eksempel<br />
Lad X være Poissonfordelt med middelværdien 10<br />
P(X = 4) = POISSON(4; 10;0) = 0.018917<br />
P( X ≥ 4)<br />
= 1 - POISSON(4;10;1) = 0,970747<br />
Eksponentialfordeling<br />
Lad T være eksponentialfordelt med middelværdien µ .<br />
PT ( ≤ t)<br />
= EKSPFORDELING(t,1/ µ ,1)<br />
Eksempel:<br />
Lad T være eksponentialfordelt med middelværdi µ =2<br />
PT ( ≤ 3)<br />
=<br />
Konfidensintervaller<br />
EKSPFORDELING(3;1/2;1) = 0,77687<br />
Konfidensinterval middelværdi for 1 normalfordelt variabel. kendt eksakt<br />
σ<br />
Radius r i et 95% konfidensinterval for µ : x ± r = x ± u0975<br />
. (se evt. side 42)<br />
n<br />
r = KONFIDENSINTERVAL(0,05; σ , n).<br />
Eksempel. Lad stikprøven have n =6 værdier, lad spredning σ = 0.25 og gennemsnit x =8<br />
r =KONFIDENSINTERVAL(0,05;0,25;6). Resultat 0,200038<br />
95% konfidensinterval: 8,0 ± 0.200<br />
Konfidensinterval for middelværdi for 1 normalfordelt variabel . σ ikke kendt eksakt<br />
se side 45<br />
Konfidensinterval for sandsynlighed p for 1 binomialfordelt variabel.<br />
se side 93<br />
Hypotesetest<br />
1 normalfordelt variabel<br />
σ kendt eksakt se eksempel 6.1 side 55<br />
σ ikke kendt eksakt se eksempel 6.2 side 56<br />
2 normalfordelte variable<br />
1) Ikke parvise observationer:<br />
data givet: se Excel-program i eksempel 7.1 side 67<br />
data ikke givet: se Excel-program i eksempel 7.2 side 69<br />
2) Parvise observationer:<br />
se Excel-program i eksempel 7.3 side 70<br />
1 binomialfordelt variabel<br />
se eksempel 9.6 side 92<br />
135<br />
σ<br />
Excel
Statistiske beregninger på lommeregner og PC-er<br />
TI 83<br />
1) Sandsynlighedsfordelinger.<br />
Man vælger 2nd DISTR<br />
Normalfordeling n( )<br />
µ , σ<br />
a) Find p = P( a ≤ X ≤b)<br />
, hvor a ,b, µ , σ er givne konstanter. p = normcdf( ab , , µ , σ )<br />
Eksempel: p = P( X ≤116<br />
. ) , hvor µ = 113 ., σ = 5<br />
Bemærk: nedre grænse er sat til -1000<br />
p = normcdf(-1000,11.6, 11.3,5) = 0.524<br />
b) Find x p : P( X ≤ x ) = p,<br />
hvor p, µ , σ er givne konstanter. x p =invNorm( p, µ , σ)<br />
p<br />
Eksempel: P( X ≤ xp) = 07 . ,hvor µ = 11,, 4<br />
t - fordeling.<br />
Lad T være t - fordelt med frihedsgradstallet f.<br />
σ = 6<br />
x p =invNorm(0.7,11.4,6) =14.55<br />
a) Find p = P( a ≤T ≤b)<br />
, hvor a og b er givne konstanter. tCdf(a,b,f)<br />
Eksempel: p = P( T ≤ −13<br />
. ) , med f = 14 p = tCdf(- ∞ ,-1.3,14) = 0.1073<br />
b) Find tα ( f ): P( T ≤ tα ( f )) = α ( α given konstant).<br />
Kan ikke findes dirkte (mærkværdigt) så lettest at slå op i tabel.<br />
Kan dog besværligt findes ved at løse den tilsvarende ligning:<br />
χ 2<br />
Eksempel: Find t0975 . ( 12)<br />
Vi løser ligningen tCdf(-100,x,12)-0.975=0 med hensyn til x, idet vi som startgæt vælger 1<br />
CATALOG, solve(tCdf(-100,x,12)-0.975,x,1) Resultat: 2.179<br />
fordeling.<br />
a) Find p= P( a ≤Q≤b) , hvor a og b er givne konstanter. p = chi2Cdf(a,b,f)<br />
Eksempel:Find p = P( Q≥27.<br />
3)<br />
, med f = 19 p = chi2Cdf(27.3,1000,19) = 0.0979<br />
2<br />
b) Find fraktilen χα ( f ) : PQ ( ≤<br />
som ovenfor.<br />
χ ( f))<br />
= α ( given konstant).Findes ikke, så enten tabelopslag eller løse ligning<br />
α 2 α<br />
Binomialfordeling.<br />
Lad X være binomialfordelt b(n,p)<br />
Find Pl ( ≤ X≤m) , hvor 0 ≤ l < m∧m≤n og l og m er hele tal. binomtCdf(n,p,l,m)<br />
Eksempel :p = P( 3≤X ≤ 6)<br />
hvor n = 10 og p = 0.3<br />
p = binomtCdf(10, 0.3, 6)- binomtCdf(10, 0.3, 2)= 0.6066<br />
Poissonfordeling.<br />
Lad X være Poissonfordelt p( µ )<br />
Find Pl ( ≤ X≤m) , hvor 0 ≤ l < m og l og m er hele tal. poissCdf( µ ,l,m)<br />
Eksempel: p = PX ( ≤ 94 ) , hvor µ = 147.6 p = poissCdf(147.6,94) = 0.00002<br />
Find gennemsnit , varians og spredning af tallene 1, 3, 4, 8<br />
Metode 1. List\ MATH\<br />
Anvendes hvis man har få tal og kun ønsker beregning af en enkelt størrelse.<br />
Gennemsnit: Mean (liste) Eksempel : Mean({1,3,4,8}) = 4<br />
Varians: Variance(liste) Eksempel : Variance({1,3,4,8}) = 8.667<br />
Spredning: stdDev (liste) Eksempel : stdDev({1,3,4,8}) = 2.944<br />
Metode 2. STAT\ Edit<br />
I listen L1 skrives 1 ENTER 3 ENTER 4 ENTER 8 ENTER (slet eventuelle allerede indtastede tal med DEL<br />
STAT hvorved cursor står på CALC. ENTER vælg 1 -Var STATS ENTER<br />
2nd L1 ENTER Resultat blandt meget andet: =4 og = 2.9439<br />
136<br />
x s x<br />
Beregn binomialkoefficient K(8,3) = 8 MATH, PROB, nCr 3. ENTER Resultat 560<br />
2. Hypotesetest og konfidensintervaller<br />
Eventuelle data indtastes i list1. Derefter vælges STAT, TESTS
2.1. Normalfordeling.<br />
a1) Hypotesetest\ σ kendt: 1: Z-Test<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8} , σ = 3 og H: µ < 5<br />
137<br />
TI - 83<br />
Vælg Data: I menu: µ 0 =5 , σ = 3 , List = L1, µ < µ 0 CALCULATE P-værdi = 0.25<br />
x = 4, σ = 3, n = 10 µ < 5<br />
Eksempel: Opgivet , H:<br />
Vælg Stats: I menu: µ 0 =5 , σ = 3 , x = 4, n = 10 , µ < µ 0<br />
P-værdi = 0.145<br />
a2) Konfidensinterval σ kendt: 7: Z-Interval<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8} ,σ = 3<br />
Vælg Data: I menu: σ = 3 , list = L1, C Level =.95<br />
Eksempel: Opgivet x = 5, σ = 3, n = 10,<br />
C Int =[1,05; 6.54]<br />
Vælg Stats: I menu: σ = 3 , x = 5, n = 10<br />
C Int =[3.14;6.86]<br />
b1) Hypotesetest; σ ukendt: 2: T - Test\<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8} H: µ < 5<br />
µ 0 µ µ<br />
Vælg Data: I menu: =5 , list = L1, < 0<br />
P-værdi = 0.27<br />
Eksempel: Opgivet x = 4, s= 3, n = 10,<br />
H: µ < 5<br />
Vælg Stats: I menu: µ 0 =5 , x = 4, s= 3, n = 10,<br />
µ < µ 0<br />
P-værdi = 0.160<br />
b2) Konfidensinterval σ ukendt: 8: T-Interval<br />
Eksempel: Lad data være gemt i list1: {1,3,4,8}<br />
Vælg Data: I menu: list = list1, C Level =.95 C Int =[-0.684; 8.684]<br />
Eksempel: Opgivet x = 4, s= 3, n = 10,<br />
Vælg Stats: I menu: x = 4, s= 3, n = 10<br />
C Int =[1.85;6.15]<br />
2.2. Binomialfordeling.<br />
a1) Hypotesetest: 5: 1-Prop-ZTest (Kræver der kan approksimeres til normalfordeling)<br />
Eksempel: X er binomialfordelt b(24, p) , x = 13, H: p > 0.3<br />
Vælg: p0= 0.3, x = 13, n= 24, prop > po P -værdi = 0.00489<br />
a2) Konfidensinterval: A: 1-Prop-ZInt (Kræver der kan approksimeres til normalfordeling)<br />
Eksempel: Af 24 forsøg er de 13 en succes:<br />
Vælg: x = 13, n= 24, C Int =[0.34; 0.74]<br />
Poissonfordeling: findes ikke, så her må formel for konfidensinterval benyttes
Statistiske beregninger på lommeregner og PC-er<br />
MAPLE<br />
Beregn gennemsnit og spredning af tallene 1 3 4 8<br />
> with(stats):<br />
data:=[1,3,4,8];<br />
data := [1, 3, 4, 8]<br />
> describe[mean](data);<br />
4<br />
> describe[standarddeviation[1]](data);<br />
Beregne korrelationskoefficient for den i eksempel 9.2 nævnte stikprøve<br />
(1,2), (0,0), (2,2), (2,2), (1,0), (2,2), (0,2), (2,2), (0,2), (2,2) .<br />
Programudførelse:<br />
> data1:=[1,0,2,2,1,2,0,2,0,2]; x- værdier<br />
data1 := [1, 0, 2, 2, 1, 2, 0, 2, 0, 2] udskrift<br />
> data2:=[2,0,2,2,0,2,2,2,2,2]; y-værdier<br />
data2 := [2, 0, 2, 2, 0, 2, 2, 2, 2, 2] udskrift<br />
> describe[linearcorrelation](data1,data2): evalf(");<br />
.4014775343 resultat<br />
Normalfordeling.<br />
Find for n(113.3,5.6) P( X ≤ 116.1) .<br />
Programudførelse:<br />
> with(stats):<br />
> with(statevalf):<br />
> cdf[normald[113.3,5.6]](116.1);<br />
Facit .6914624613<br />
χ 2<br />
fordeling.<br />
Find en tests P-værdi: P( Q ≥ 27.26) idet frihedsgradstallet er 19 (jævnfør eksempel 5.6)<br />
Programudførelse:<br />
> with(stats):<br />
> with(statevalf):<br />
> 1-cdf[chisquare[19]](27.36);<br />
Facit: .0965431211<br />
t - fordeling.<br />
Find en tests P-værdi: PT ( ≤ -1.31) idet frihedsgradstallet er 14 (jævnfør eksempel 5.5)<br />
Programudførelse:<br />
> with(stats):<br />
> with(statevalf):<br />
> cdf[studentst[14]](-1.31);<br />
Facit: .1056420798<br />
Find for binomialfordelingen b(100,0.3) P( X ≤ 35)<br />
Programudførelse:<br />
> with(stats):<br />
> with(statevalf):<br />
> dcdf[binomiald[100,0.3]](35);<br />
Facit: .8839213940<br />
138
MATHCAD<br />
1) Generelt:<br />
Sandsynlighedsfunktioner :<br />
Skriv funktionens navn eller vælg fra (øverste) værktøjslinie<br />
f ( x)<br />
\Probability Density (dfunktionsnavn). Tæthedsfunktion PX ( = a)<br />
,<br />
f ( x)<br />
\Probability Distribution (pfunktionsnavn). Fordelingsfunktion PX ( ≤ a)<br />
eller<br />
f ( x)<br />
\Probability Distribution (qfunktionsnavn) Invers tæthedsfunktion: P( X ≤ xp) = pFind<br />
x p .<br />
Rækkefølgen af parametrene kan findes ved at placere cursor på navnet og trykke på tasten F1.<br />
2) Sandsynlighedsfordelinger.<br />
Normalfordeling n( µ , σ )<br />
p = P( a ≤ X ≤b)<br />
µ , σ<br />
139<br />
MATHCAD<br />
a) Find , hvor a ,b, er givne konstanter.<br />
p= P( a≤ X ≤ b) = P( X ≤b) − P( X ≤ a)<br />
= pnorm(b, µ , σ ) - pnorm(a, µ , σ )<br />
Eksempel: p = P( X ≤116<br />
. ) , hvor µ = 113 ., σ = 5<br />
p = pnorm(11.6, 11.3,5) = 0.524<br />
b) Find x p : P( X ≤ x ) = p,<br />
hvor p, µ , σ er givne konstanter. x p =qnorm( p, µ , σ )<br />
p<br />
Eksempel: P( X ≤ xp) = 07 . ,hvor µ = 11,, 4 σ = 6<br />
x p =qnorm(0.7,11.4,6) =14.55<br />
t - fordeling.<br />
Lad T være t - fordelt med frihedsgradstallet f.<br />
a) Find p = P( a ≤T ≤b)<br />
, hvor a og b er givne konstanter.<br />
p= P( a≤ X ≤ b) = P( X ≤b) − P( X ≤ a)<br />
= pt(b,f) -pt(a,f)<br />
Eksempel: p = P( T ≤ −13<br />
. ) , med f = 14 p = pt(-1.3,14) = 0.1073<br />
b) Find tα ( f ): P( T ≤ tα ( f )) = α ( α given konstant). tα ( f ) = qt( α ,f )<br />
Eksempel: t0975 . ( 12)<br />
= qt (0.975,12) = 2.179<br />
χ 2 −<br />
fordeling.<br />
Lad Q være χ fordelt med frihedsgradstallet f.<br />
2 −<br />
a) Find p= P( a ≤Q≤b) , hvor a og b er givne konstanter. p = pchisq(b,f) - pshisq(a,f)<br />
Eksempel:Find p = P( Q≥27.<br />
3) , med f = 19 p= 1− P( Q≤273<br />
. ) =1- pchisq(27.3,19) = 0.0979<br />
2<br />
b) Find fraktilen χα ( f ) : PQ ( ≤ χ ( f))<br />
= α ( given konstant). f = qchisq( α ,f )<br />
α 2 α χ α 2 ( )<br />
2<br />
Eksempel: χ 0. 025 () 8 = qchisq(0.025,8) = 2.18<br />
Binomialfordeling.<br />
Lad X være binomialfordelt b(n,p)<br />
a) P(X=x) =dbinom(x,n,p)<br />
P( X ≤ x)<br />
= pbinom(x,n,p)<br />
Eksempel :q = P( 3≤ X ≤6)<br />
, hvor n = 10 og p = 0.3<br />
q = P( X≤6) − P( X≤2)<br />
= pbinom(6,10, 0.3)-pbinom(2,10,0.3) = 0.6066<br />
b) Find det hele tal m for hvilket P( X≤ m)<br />
=α m = qbinom(p, n, α )<br />
Eksempel: Lad X være binomialfordelt med p = 0.3 og n = 10.<br />
Find det hele tal m for hvilket PX ( ≤ m)<br />
=095<br />
.<br />
m = qbinom(0.3, 10,0.95 ) = 9
Statistiske beregninger på lommeregner og PC-er<br />
Poissonfordeling.<br />
Lad X være Poissonfordelt p( )<br />
µ<br />
a) P(X=x) =dpois(x, µ )<br />
P( X ≤ x)<br />
= ppois(x, µ )<br />
Eksempel: p = , hvor = 147.6 p = ppois(94,147.6) = 1.54 10-6 P( X≤<br />
94 ) µ ⋅<br />
b) Find det hele tal m for hvilket P( X≤ m)<br />
=α m = qpois( α , µ )<br />
Eksempel: Lad X være Poissonfordelt med = 147.6.<br />
µ<br />
Find det hele tal m for hvilket PX ( ≤ m)<br />
=095 .<br />
m = qpois(0.95, 147.6 ) =168<br />
Hypergeometrisk fordeling:<br />
Lad X være hyprgeometrisk fordelt h(N,M,n)<br />
a) P(X=x) =dhypgeo(x,M, N-M,n)<br />
P( X ≤ x)<br />
= phypgeo(x,M,N-M,n)<br />
3) Gennemsnit, varians og spredning<br />
Find gennemsnit , varians og spredning af tallene 1, 3, 4, 8<br />
⎛1⎞<br />
⎜ ⎟<br />
⎜ 3⎟<br />
Opret en søjlematrix v:=<br />
⎜4⎟<br />
⎜ ⎟<br />
⎝8⎠<br />
Vælg fra værktøjslinie f ( x)<br />
\ Category: Statistics \ Function Name: eksempelvis mean<br />
Eksempel : Gennemsnit: mean (v) =4 Mean({1,3,4,8}) = 4<br />
Varians: Var(v) = 8.667<br />
Spredning: Stdev (v) = 2.944<br />
140
APPENDIX . Oversigt over approksimationer.<br />
1<br />
10<br />
n<br />
N<br />
p ≤ 1<br />
10<br />
≤ 1<br />
10<br />
9<br />
< p< ∧5≤n⋅p≤n−5 10<br />
n 1 M 1<br />
1) Når > og ≤ benyttes, at hNMn ( , , ) = hNnM ( , , ) .<br />
N 10 N 10<br />
141<br />
M<br />
N<br />
APPENDIX<br />
2) For p ≥ benyttes, i stedet for at tælle Xgammel = “antal af successer”, så at tælle X = antal fiaskoer dvs.<br />
9<br />
10<br />
p = 1 − pgammel<br />
og X = n − Xgammel<br />
.<br />
3) Husk heltalskorrektion ved approksimation med normalfordeling. (se næste side)
APPENDIX<br />
Approksimation af binomialfordeling til normalfordeling.<br />
Det kan vises, at tæthedsfunktionen for binomialfordelingen b (n, p) nærmer sig ubegrænset til normalfordelingen<br />
, hvor og , når n vokser ubegrænset1) n( µ , σ ) µ = n ⋅ p σ = n⋅ p⋅( 1−<br />
p)<br />
.<br />
Approksimation af en binomialfordeling med en normalfor-<br />
1 9<br />
deling anses, når < p < i praksis for at være tilfreds-<br />
10 10<br />
stillende, såfremt n⋅ p≥5(og<br />
n⋅( 1− p)<br />
≥5).<br />
Da binomialfordelingen kun antager heltalsværdier,<br />
medens en normalfordeling kan antage alle værdier på<br />
talaksen, svarer hvert helt tal ved binomialfordelingen til et<br />
interval af længden 1 ved normalfordelingen. På figur 1 er<br />
derfor tegnet en firkant, der har bredden 1, og hvis højde er<br />
P( X = 4)<br />
udregnet ved binomialfordelingen. Arealet<br />
under normalfordelingskurven fra x = 3.5 til x = 4,5 er med<br />
tilnærmelse lig firkantens areal. Man siger, at man ved<br />
approksimationen må heltalskorrigere (korrigeres for<br />
Fig. 1. Heltalskorrektion<br />
kontinuitet).<br />
Ved approksimationen benyttes derfor følgende anførte formler, gældende for en binomialfordelt variabel X fordelt<br />
1 9<br />
b (n, p), hvor ≤ p ≤ og 5≤n⋅ p≤n−5. 10 10<br />
Eksempel 7.13: Approksimation af binomialfordeling med normalfordeling.<br />
En kunde til de i eksempel 2.3 producerede plastikkasser køber kasserne i partier på 2000. Kunden godkender<br />
et parti efter en stikprøvekontrol, hvor der udtages 100 kasser. Hvis antallet af defekte kasser i stikprøven højst<br />
er 14 godkendes hele partiet. I modsat fald kasseres partiet.<br />
Hvor stor er sandsynligheden for at et parti bliver godkendt, hvis der er 300 defekte kasser i hele partiet på de<br />
2000.<br />
Løsning:<br />
Lad X være antallet af defekte kasser i stikprøven. Vi ønsker at udregne P( X ≤ 14)<br />
.<br />
Umiddelbart er X hypergeometrisk fordelt med N = 2000, M = 300, og n = 100.<br />
⎛ n 100 1 ⎞<br />
Da stikprøvestørrelsen er lille ⎜ = < ⎟ kan fordelingen af X umiddelbart approksimeres med<br />
⎝ N 2000 10⎠<br />
binomialfordelingen b (100, p), hvor p . Dette giver ved benyttelse af en lommeregner som<br />
M 300<br />
= = = 015 .<br />
N 2000<br />
TI-89 at P( X ≤ 14)<br />
= 45.72%.<br />
Idet n⋅ p=<br />
15 > 5 , kan i stedet for approksimeres med normalfordelingen med µ = 15 og σ = 15⋅ 085 . = 357 . .<br />
Ved hjælp af denne approksimation kan vi beregne:<br />
P( X ≤ 14)<br />
= normCdf( −∞,<br />
14.5, 15, 3.57) = 44.43%<br />
Det ses, at der er ca. 1.5 % afvigelse, hvilket normalt ingen betydning har.<br />
1) Matematisk formulering: Når X er fordelt b(n, p), vil for den tilsvarende normerede variabel<br />
Y =<br />
X −n⋅ p<br />
n⋅ p⋅( 1 − p)<br />
gælde, at PY ( ≤ y) ⎯ ⎯→∞→ ( y)<br />
for ethvert tal y.<br />
Φ<br />
n<br />
142
u p<br />
Tabel over fraktiler i normeret normalfordeling<br />
Tabel over fraktiler i normeret normalfordeling n( 01 , ) . PU ( ≤ u ) = p.<br />
Bemærk: u p = - u 1 - p<br />
p 0.0005 0.001 0.005 0.01 0.025 0.05 0.10<br />
u p<br />
-3.291 -3.090 -2.576 -2.326 -1.960 -1.645 -1.282<br />
p 0.90 0.95 0.975 0.99 0.995 0.999 0.9995<br />
u p<br />
Eksempel: u 0.975 = 1.960<br />
1.282 1.645 1.960 2.326 2.576 3.090 3.291<br />
143<br />
p
Facitliste<br />
FACITLISTE<br />
KAPITEL 2<br />
2.1 -<br />
2.2 -<br />
2.3<br />
2.4 (1) - (2) ca 24%<br />
2.5 (1) - (2) ca 0.052<br />
2.6 (1) - (2) ca 13%<br />
2.7 (1) - (2) 24.8 24.5<br />
2.8 (1) - (2) - (3) -<br />
KAPITEL 3<br />
3.1 (1) - (2) - (3) 0.833 0.3056 0.5528 (4) 0.1641<br />
3.2 (1) - (2) - (3) 1.5 0.75 0.866 (4) 0.088<br />
3.3 65 0.4<br />
3.4 1658.76 57.31 3.46%<br />
3.5 103.32 2.6 2.52%<br />
3.6 996.3 46.36 4.65%<br />
3.7 (a) 515 10 (b) 41.8% (c ) (d) 20.9%<br />
6 −<br />
. ⋅<br />
258 10 4 −<br />
. ⋅<br />
KAPITEL 4<br />
4.1 (1) 0.7734 0.0548 0.1718 (2) 0.7480<br />
4.2 (1) 69.15% (2) 10.88% (3) 112.2 (4) 117.3 6.535<br />
4.3 (1) 86.64% (2) 0.008 (3) 0.020<br />
4.4 (1) 5.94% (2) 27.71% (3) [783.51; 816.49]<br />
4.5 (1) 9.5 1.265 (2) 12.45 (3) 2.41%<br />
4.6 (1) 92.8%<br />
4.7 (1) 97.71% (2) 25.45<br />
4.8 (1) 65 0.4 (2) 77.34%<br />
KAPITEL 5<br />
5.1 (1) 12.13 0.6783 (2) [11.65 ; 12.61] (3) [10.52 ; 13.74] (4) [11.73 ; 12.53]<br />
5.2 (1) 2259.92 35.569 (2) [2237 ; 2283] (3) [2178 ; 2341]<br />
5.3 (1) 74.0362 0.00124 (2) [74.035; 74.037] (3) [74.036 ; 74.037]<br />
5.4 (1) 750.2 (2) [740.1 ; 760.3] (3) 19.13 (4) [14.0 ; 30.2]<br />
5.5 (1) 7.83 0.363 (2) [7.45 ; 8.22] (3) 53<br />
5.6 [25.21 ; 60.36]<br />
5.7 [0.00083 ; 0.00231]<br />
5.8 (a) [4.23 ; 4.29] (b) 22 (c ) [4.16 ; 4.36] (d) [0.028 ; 0.076]<br />
5.9 (1) [0.965 ; 1.111] (2) [0.0263; 0.1714]<br />
144
145<br />
Facitliste<br />
KAPITEL 6<br />
6.1 (1) nej P-værdi = 2.28% (2.67%)<br />
6.2 ja 3.45% (2) 58.0 (3) [55.84; 60.16]<br />
6.3 (1) 84.47 6.85 (2) ja P-værdi = 0.44% (3) [81.27 ; 87.67] (4) 25.7%<br />
6.4 (a)nej P-værdi = 12.1% (b) [7.93 ; 8.49 ]<br />
6.5 (a) ja P-værdi = 0.157% (b) [24.07 ; 35.56]<br />
6.6 nej P-værdi = 6.45%<br />
6.7 (1) ja, P-værdi = 0.012 (2) 0.987 (3) [0.68 ; 1.80 ]<br />
. ⋅<br />
6.8 ja, P-værdi =18 10 9 −<br />
6.9 (1) 19.5 (2) nej, P-værdi =0.1% , (eller P-værdi =0.135%)<br />
6.10 (1) 12 (2) ja P-værdi = 0.48 (3) nej<br />
6.11 (1) 24 (2) ja P-værdi = 0.16% (3) nej [2.59 ; 2.67]<br />
6.12 (1) 26 (2) ja P-værdi = 25 10 (3) ja<br />
13 −<br />
. ⋅<br />
KAPITEL 7<br />
7.1 P - værdi = 0.1044<br />
7.2 (1) P - værdi = 0.001 (2) [0.70 ; 3.12]<br />
7.3 P - værdi = 0.0204<br />
7.4 (1) P - værdi = 0.0714 (2) P - værdi = 0.401<br />
7.5 (1) 18 (2) P - værdi = 0.00017 , [11.9 ; 15.0]<br />
7.6 P - værdi = 0.589<br />
7.7 P - værdi = 0.1398<br />
7.8 (1) nej P-værdi =14.95%<br />
7.9 (1) nej, P-værdi =9.85% (2) [0.22 ;7.28 ]<br />
7.10 (1) - (2) Ja, P-værdi =3.63%<br />
KAPITEL 8<br />
8.1 0.1 0.8 0.2 0.7<br />
8.2 (1) 0.9134 (2) 0.9678<br />
8.3 (1) 8.75% (2) 38.75% (3) 41.25% (4)11.25%<br />
8.4 (1) 6.4% (2) 78.4% (3) 7.2%<br />
8.5 (a) 30.24% (b) 0.24% (c ) 99.76% (d) 4.04% (e) 44.04% (f) 21.44%<br />
8.6 1.283 ⋅ 10 12<br />
8.7 (a) - (b) 736<br />
8.8 (a) 6 (b) 24<br />
8.9 (a) 100 /b) 2400<br />
8.10 60<br />
8.11 (1) 27.1% 36.0% 9.756% (2) 53.34% (3) 49.20%<br />
8.12 3 40<br />
8.13 (1) 5 (2) 9<br />
8.14 30.24%<br />
8.15 910 7<br />
⋅
Facitliste<br />
KAPITEL 9<br />
9.1 (1) - )2) 0.6<br />
9.2 (1) 91.67% (2) 9.167%<br />
9.3 (1) 17.68% (2) 59.28%<br />
9.4 2.58%<br />
9.5 5.83%<br />
9.4 (1) 0.988%<br />
9.5 (1) - 73.75 30.08 (2) 221.25 kr 57.48%<br />
9.6 5.6%<br />
9.7 94.9%<br />
9.8 40.87%<br />
9.9 13%<br />
9.10 nej, P-værdi =0.08%<br />
9.11 (1) 0.9% (2) nej<br />
9.12 (1) ja, P-værdi = 2.53% (2) 0.12 (3) [0.056 ; 0.184]<br />
9.13 ja p = 0.43%<br />
9.14 (1) 0.108 (2) [0.089 ; 0.127]<br />
9.15 [0.799 ; 0.847]<br />
9.16 1522<br />
9.17 77.86%<br />
9.18 (1) 7.94% (2) 11.8%<br />
9.19 (1) (a) 60.6% (b) 91.6% (c) 6.2% (2) 4.4%<br />
9.20 (1) 30.1% (2) 87.9% (3) 4<br />
9.21 50.37%<br />
9.22 (1) 15 (2) 81.9%<br />
9.23 75.3%<br />
9.24 6.56%<br />
9.25 92.2%<br />
9.26 44.6%<br />
9.27 (1) nej P-værdi = 7.84% (2) 100.8 (4) [85.56 ; 116.04]<br />
9.28 (1) 4.68 (2) [4.47 ; 4.89] (3) 69.44<br />
9.29 (1a) 11 (1b) [4.5 ; 17.5] (2a) 1.1 (2b) [0.45 ; 1.75]<br />
9.30 (1) 0.539% (2) 0.119%<br />
9.31 7.31%<br />
9.32 0.188%<br />
KAPITEL 10<br />
10.1 (1) 2.90 (2) 14.6% (3) 16.98<br />
10.2 (1) 77.88% (2) 10.45% (3) 77.88% (4) 9.48%<br />
10.3 1<br />
10.4 (1) 79.8% (2) 99.33% (3) 22.8 (4) 14<br />
146
147<br />
Facitliste<br />
KAPITEL 11<br />
11.1.1 (a1) - (a2) - (a3) nej (a4) 2.3 1.8 1.345 1.470 (a5) 12.6 (b1) 2.2 1.5 1.316<br />
1.5811<br />
11.1.2 (a6) 0.06 0.0304 (b2) 0.6667 0.3203<br />
11.1.3 (a7) 52 15.52 (b3) 53.33 17.51<br />
11.2.1 (a1) - (a2) nej (a3) 0.9 0.5 0.830 0.5 (a4) 0.9707 (b1) 0.6 0.6 0.843<br />
0.516<br />
11.2.2 (a5) 0.15 0.36 (b2) 0.2667 0.6124<br />
11.2.3 (a6) 15300 3716.18 (b3) 15800 4131.18<br />
11.3.1 (a1) - (a2) nej a3) 4.2 3.2 1.4 0.9798 (a4) 0.625 (b1) 4 3.2 1.633 1.033<br />
11.3.2 (a5) 0.16 0.0342 (b2) 0.4444 0.2635<br />
11.3.3 (a6) 316 44.36 (b3) 300 28.28<br />
11.4.1 178.33 71.833 11.428 10,870<br />
11.4.2 100.97 0.8128<br />
11.4.3 139.13 2.089<br />
11.5 4.6344<br />
11.6 3.559<br />
11.7 3.3466
Stikord<br />
STIKORDSREGISTER<br />
A<br />
acceptområde 54<br />
additionssætning<br />
for sandsynligheder 81<br />
for linearkomb. af normalf. variable 30, 35<br />
alternativ hypotese 58<br />
approksimation 104<br />
binomial til normalfordeling 141<br />
binomial til Poissonfordeling 141<br />
hypergeometrisk til binomialford. 100, 141<br />
Poisson til normalfordeling 141<br />
B<br />
bagatelgrænse 60<br />
Bayes sætning 83<br />
betinget sandsynlighed 82<br />
binomialfordeling<br />
binomialfordelingstest 97, 105<br />
både A og B 80<br />
C<br />
centrale grænseværdisætning 39<br />
chi i anden fordeling 49<br />
D<br />
deskriptiv statistik 2<br />
dimensionering 60, 64<br />
diskret variabel 16, 91<br />
E<br />
eksperiment, tilfældigt 15<br />
eksponentialfordeling 115<br />
ensfordelte variable 21<br />
ensidet<br />
binomialtest 97, 105<br />
chi-i-anden test 59<br />
Poissontest 102, 106<br />
t -test 57, 63<br />
test 53<br />
enten A eller B 80<br />
estimat 7<br />
Excel, oversigt 133<br />
148<br />
F<br />
fakultet 85<br />
fejl af type I 59<br />
fejl af type II 59<br />
flerdimensional variabel 120<br />
fordeling<br />
binomial- 94<br />
chi i anden- 49<br />
eksponential- 115<br />
hypergeometrisk- 91<br />
kontinuert 17<br />
logaritmisk normal- 119<br />
normal- 28<br />
rektangulær 113<br />
t- 43<br />
To-dimensional normal- 118<br />
Weibull- 117<br />
fordelingsfunktion<br />
kontinuert variabel 20<br />
foreningsmængde 80<br />
forkastelsesområde 54<br />
fraktil 9, 20<br />
fraktiltabel for normalfordeling 144<br />
frihedsgrad 10<br />
fællesmængde 80<br />
G<br />
Galton apparat 29<br />
Gauss fordeling 29<br />
generaliseret hypergeometrisk ford. 103<br />
gennemsnit 7, 32, 39<br />
H<br />
heltalskorrektion 142<br />
histogram 5, 17<br />
hypergeometrisk fordeling 91<br />
hypotesetest<br />
1 normalfordelt variabel 53<br />
2 normalfordelte variable 70<br />
binomialfordeling 97<br />
Poissonfordeling 102<br />
hyppighed, relativ 7, 15<br />
hændelse 15<br />
additionssætning 81<br />
både A og B 80<br />
enten A eller B 80
Stikord<br />
foreningsmængde 80<br />
fællesmængde 80<br />
ikke A 80<br />
uafhængige 81<br />
I,J<br />
ikke A 80<br />
inferentiel statistik 1<br />
K<br />
karakteristiske tal 7<br />
kombination 86<br />
kombinatorik 84<br />
konfidensinterval 40, 42 , 44, 48, 49<br />
konfidensinterval<br />
1 normalfordelt variabel 40, 42, 44, 48, 49<br />
2 normalfordelte variable , differens 72, 76<br />
binomialfordeling 98, 105<br />
Poissonfordeling 103, 106<br />
kontinuert stokastisk variabel 17<br />
korrelationskoefficient 120, 123<br />
kovarians 120, 23<br />
kvadratregel 21<br />
kvalitative data 2<br />
kvalitetskontrol 34<br />
kvantitative data 4<br />
kvartil 8<br />
kvartilafstand 11<br />
kvartilafstand, relativ 11<br />
L<br />
lagkagediagram 2<br />
levetid 116<br />
linearitetsregel 21<br />
linearkombination 21<br />
logaritmisk normalfordeling 118<br />
lommeregner<br />
TI - 83 137<br />
TI - 89 132<br />
M<br />
Maple 138<br />
Mathcad 139<br />
median 8<br />
middelværdi 7<br />
diskret variabel 91, 95, 191<br />
kontinuert variabel 19<br />
multiplikationsprincip 84<br />
149<br />
N<br />
nedre kvartil 9<br />
n fakultet 85<br />
normalfordeling 28<br />
logaritmisk 118<br />
normeret 31<br />
todimensional 118<br />
nulhypotese 54<br />
O<br />
observationer, parvise 74<br />
opgaver kapitel<br />
2 12<br />
3 26<br />
4 36<br />
5 51<br />
6 66<br />
7 77<br />
8 88<br />
9 107<br />
10 119<br />
11 128<br />
ophobningslov 24<br />
oversigt<br />
kap 5 50<br />
kap6 63<br />
kap 7 76<br />
kap 9 105<br />
P<br />
parvise observationer 74<br />
Poissonfordeling 100<br />
Poissonfordelingstest 102<br />
polynomialfordeling 104<br />
population 1, 17<br />
produktsætning 81, 82<br />
prædistinationsinterval 46<br />
P-værdi 55<br />
R<br />
randomisering 38<br />
rektangulær fordeling 113<br />
relativ hyppighed 7<br />
relativ usikkerhed 23<br />
repræsentativ stikprøve 38<br />
Facitliste
Stikord<br />
S<br />
SAK 10<br />
sandsynlighed 16, 80<br />
additionssætning 81<br />
betinget 82<br />
produktsætning 81<br />
Satterwaithes metode 71<br />
signifikansniveau 54<br />
simpel udvælgelse 38<br />
spredning 9, 32<br />
på gennemsnit 28<br />
SS 10<br />
standard deviation 9<br />
statistisk uafhængige 81<br />
stikprøve 17 , 38<br />
gennemsnit 7, 32<br />
ordnet 85<br />
spredning 9, 32<br />
udvælgelse 38<br />
uordnet 86<br />
varians 9<br />
stikprøvestørrelse 46, 99<br />
stokastisk variabel 16<br />
stratificeret udvælgelse 38<br />
systematisk udvælgelse 38<br />
søjlediagram 3<br />
T<br />
tabel over fraktiler i normalfordeling 143<br />
test<br />
af middelværdi 53, 63<br />
af spredning 59, 65<br />
fejl af type I 59<br />
fejl af type II 59<br />
P-værdi 53<br />
testfunktioner<br />
χ 2<br />
- fordeling 49<br />
t - fordelingen 43<br />
t-fordeling 43<br />
to-dimensional normalfordeling 118<br />
tosidet test 58<br />
Ti-83 136<br />
TI - 89 131<br />
t-test, ensidet 57<br />
tæthedsfunktion<br />
diskret variabel 92, 96<br />
kontinuert variabel 17<br />
150<br />
U<br />
uafhængige hændelser 15<br />
uafhængige stokastiske variable 15<br />
udfald 15<br />
udfaldsrum 15<br />
usikkerhed<br />
maksimal 23<br />
relativ 23<br />
statistisk 23<br />
usikkerhedsberegning 23<br />
U-fordeling 31<br />
V<br />
variabel<br />
binomialfordelt 94<br />
diskret 1<br />
kontinuert 17<br />
stokastisk 16<br />
varians 9<br />
diskret variabel 16, 91<br />
kontinuert variabel 19<br />
variationsbredde 5<br />
W<br />
Weibullfordeling 117<br />
Z<br />
Z - fordeling 31<br />
Ø<br />
øvre kvartil 9